Хотим представить наш новый инструмент для токенизации текста — YouTokenToMe. Он работает в 7–10 раз быстрее других популярных версий на языках, похожих по структуре на европейские, и в 40–50 раз — на азиатских языках. Рассказываем о YouTokenToMe и делимся им с вами в open source на GitHub. Ссылка в конце статьи!

Сегодня значительная доля задач для нейросетевых алгоритмов заключается в обработке текстов. Но, поскольку нейросети работают с числами, до передачи в модель текст нужно преобразовать.
Перечислим популярные решения, которые обычно для этого используются:
У каждого из них свои недостатки:
В последнее время популярен подход Byte Pair Encoding. Изначально этот алгоритм предназначался для компрессии текстов, но несколько лет назад его стали использовать для токенизации текста в машинном переводе. Сейчас он применяется для широкого круга задач, в том числе используется в моделях BERT и GPT-2.
Наиболее эффективными реализациями BPE были SentencePiece, разработанная инженерами Google, и fastBPE, созданная исследователем из Facebook AI Research. Но нам удалось доказать, что токенизацию можно существенно ускорить. Мы оптимизировали алгоритм BPE и опубликовали исходный код, а также выложили готовый пакет в репозиторий pip.
Ниже можно сравнить результаты измерения скорости нашего алгоритма и других версий. В качестве примера мы взяли первые 100 MB корпуса данных из «Википедии» на русском, английском, японском и китайском языках.
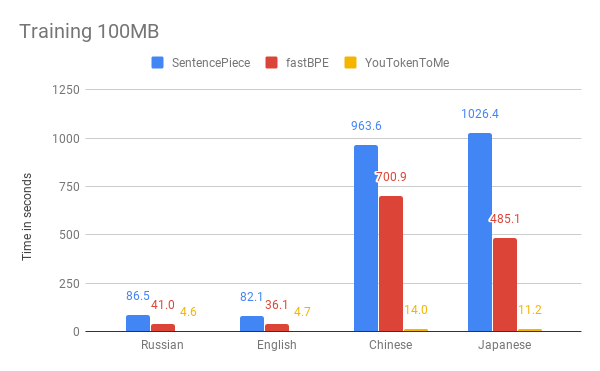

На графиках видно, что время работы существенно зависит от языка. Это объясняется тем, что в азиатских языках алфавиты больше, а слова не разделены пробелами. YouTokenToMe работает в 7–10 раз быстрее на языках, похожих по структуре на европейские, и в 40–50 раз — на азиатских. Токенизация была ускорена как минимум в два раза, а на некоторых тестах более чем в десять раз.
Таких результатов мы достигли благодаря двум ключевым идеям:
Использовать YouTokenToMe можно через интерфейс для работы из командной строки и напрямую из Python.
Больше информации вы можете найти в репозитории: github.com/vkcom/YouTokenToMe
Сегодня значительная доля задач для нейросетевых алгоритмов заключается в обработке текстов. Но, поскольку нейросети работают с числами, до передачи в модель текст нужно преобразовать.
Перечислим популярные решения, которые обычно для этого используются:
- разбиение по пробелам;
- алгоритмы на основе правил: spaCy, NLTK;
- стемминг, лемматизация.
У каждого из них свои недостатки:
- нельзя контролировать размер словаря токенов. От этого напрямую зависит размер слоя с эмбеддингами в модели;
- не используется информация о родстве слов, которые отличаются суффиксами или приставками, например: polite — impolite;
- зависят от языка.
В последнее время популярен подход Byte Pair Encoding. Изначально этот алгоритм предназначался для компрессии текстов, но несколько лет назад его стали использовать для токенизации текста в машинном переводе. Сейчас он применяется для широкого круга задач, в том числе используется в моделях BERT и GPT-2.
Наиболее эффективными реализациями BPE были SentencePiece, разработанная инженерами Google, и fastBPE, созданная исследователем из Facebook AI Research. Но нам удалось доказать, что токенизацию можно существенно ускорить. Мы оптимизировали алгоритм BPE и опубликовали исходный код, а также выложили готовый пакет в репозиторий pip.
Ниже можно сравнить результаты измерения скорости нашего алгоритма и других версий. В качестве примера мы взяли первые 100 MB корпуса данных из «Википедии» на русском, английском, японском и китайском языках.
На графиках видно, что время работы существенно зависит от языка. Это объясняется тем, что в азиатских языках алфавиты больше, а слова не разделены пробелами. YouTokenToMe работает в 7–10 раз быстрее на языках, похожих по структуре на европейские, и в 40–50 раз — на азиатских. Токенизация была ускорена как минимум в два раза, а на некоторых тестах более чем в десять раз.
Таких результатов мы достигли благодаря двум ключевым идеям:
- новый алгоритм имеет линейное время работы в зависимости от размера корпуса для обучения. У SentencePiece и fastBPE — менее эффективная асимптотика;
- новый алгоритм может эффективно использовать несколько потоков как в процессе обучения, так и в процессе токенизации — это позволяет получить ускорение ещё в несколько раз.
Использовать YouTokenToMe можно через интерфейс для работы из командной строки и напрямую из Python.
Больше информации вы можете найти в репозитории: github.com/vkcom/YouTokenToMe
david_mz
А можно как-то в двух словах рассказать, что это за BPE и чем оно полезно на практике?
pavel_kalaidin
vk.com/tech?w=wall-147415323_3421
Вот в этом видео рассказывают, например, чем он полезен для суммаризации. Конкретно BPE минуты с 13-й.
david_mz
Спасибо!