
попутно понять работу простой нейросети на практике, а также улучшить ее результаты.
Сразу оговоримся, что не будем погружаться в размышления о том, как работает нейрон и что с этим всем делать, статья не претендует на научность, а только предоставляет небольшой туториал.
Плясать от печки. Вместо вступления
Возможно повторятся чьи-то слова, но большинство книг по Deep Learning действительно начинаются с того, что читателю предлагаются заранее заготовленные данные, с которыми он начинает работать. Как-то MNIST — 60 000 рукописных цифр, CIFAR-10 и т.п. После прочтения человек выходит подготовленным… к этим наборам данных. Совершенно не ясно, как использовать свои данные и главное, как что-то улучшить при построении своей собственной нейросети.
Поэтому очень кстати вышла статья на pyimagesearch.com о том как работать со своими собственными данными, а также ее перевод.
Но, как говорится, хрен редьки не слаще: даже с переводом разжеваной статьи по keras осталось много слепых мест. Опять же предлагается заранее подготовленный датасет, только уже с котами, собаками и пандами. Придется заполнить пустоты самостоятельно.
Однако за базу будет взята эта статья и код.
Собираем данные по капчам
Здесь нет ничего нового. Нам нужны капчи-образцы, т.к. сеть будет учиться по ним под нашим руководством. Можете намайнить капч самостоятельно, а можете взять немного здесь - 29 000 капч. Теперь необходимо нарезать цифр из каждой капчи. Необязательно резать все 29 000 капч, тем более, что 1 капча дает 5 цифр. 500 капч будет более чем достаточно.
Как резать? Можно в photoshopе, но лучше иметь нож получше.
Поэтому вот код ножа на python — скачать. (для Windows. Предварительно создать папки C:\1\test и C:\1\test-out).
На выходе получится свалка из цифр от 1 до 9 (нулей в капче нет).
Далее надо разобрать этот завал из цифр по папкам от 1 до 9 и разложить в каждую папку по соответствующей цифре. Так себе занятие. Но за день можно разобрать до 1000 цифр.
Если при выборе цифры возникает сомнение какая из цифр, лучше удалить этот образец. И ничего страшного если цифры будут зашумлены или неполностью входить в «кадр»:


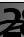
Набрать в каждую папку надо штук по 200 образцов каждой цифры. Можно эту работу поручить сторонним сервисам, но лучше сделать все самим, чтобы потом не искать неправильно соотнесенные цифры.
Нейросеть. Тестовая
Тятя, тятя, наши сети притащили мертвеца
Перед тем как начать работать с собственными данными лучше пройтись по вышеуказанной статье и запустить код, чтобы понять, что все компоненты (keras, tensorflow и т.п.) установлены и работают корректно.
Будем использовать простую сеть, синтаксис запуска которой из командной (!) строки:
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png*Tensorflow может писать при работе об ошибках в собственных файлах и устаревших методах, можно это исправить руками, а можно просто игнорировать.
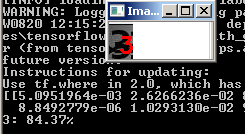
Главное, чтобы на выходе после отработки программы в папке проекта output появились два файла: simple_nn_lb.pickle и simple_nn.model, а на экран будет выведено изображение животного с надписью и процентом распознавания, например:

Нейросеть — собственные данные
Теперь, когда тест работоспособности сети проверен, можно подключить собственные данные и начать обучать сеть.
Поместим в папку dat папки с цифрами, содержащими отобранные образцы по каждой цифре.
Папку dat для удобства разместим в папке с проектом (например рядом c папкой animals).
Теперь синтаксис запуска обучения сети будет таким:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.pngОднако пока рано запускать обучение.
Необходимо поправить файл train_simple_nn.py.
1. В самый конец файла:
#model.summary()
score = model.evaluate(testX, testY, verbose=1)
print("\nTest score:", score[0])
print('Test accuracy:', score[1])Это добавит информативности.
2.
image = cv2.resize(image, (32, 32)).flatten()поменять на
image = cv2.resize(image, (16, 37)).flatten()Кроме того, загоняем это изменение в try:
try:
image = cv2.resize(image, (16, 37)).flatten()
except:
continueТ.к. некоторые картинки программа не может переварить и выдает None, поэтому они пропускаются.
3.Теперь самое важное. Там где комментарий в коде
определим архитектуру 3072-1024-512-3 с помощью Keras
Архитектура сети в статье определена как 3072-1024-512-3. Это означает, что сеть получает на вход 3072 (32 пикселя * 32 пикселя * 3), далее слой 1024, слой 512 и на выходе 3 варианта — кот, собака или панда.
В нашем случае вход 1776 (16 пикселей*37 пикселей*3), далее слой 1024, слой 512, на выходе 9 вариантов цифр.
Поэтому наш код:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
*9 выходов дополнительно указывать не нужно, т.к. программа сама определяет количество выходов по количеству папок в датасете.
Запускаем
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.pngТак как картинки с цифрами маленькие, сеть обучается очень быстро (5-10 мин) даже на слабом железе, используя только CPU.
После прогона программы в командой строке посмотрим результаты:
Это означает, что на обучающем наборе достигнута верность — 82,19%, на контрольном — 75,6 % и на тестовом — 75,59 %.
Нам надо ориентироваться на последний показатель большей частью. Почему остальные также важны будет пояснено далее.
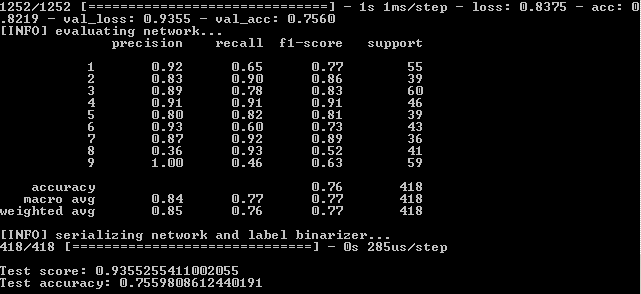
Посмотрим также графическую часть работы нейросети. Она в папке output проекта simple_nn_plot.png:
Быстрее, выше, сильнее. Улучшаем результаты
Совсем коротко о настройке нейросети можно посмотреть здесь.
Вариант подлиннее следующий.
Добавим эпох.
В коде меняем
EPOCHS = 75на
EPOCHS = 200Увеличим «количество раз», которое сеть пройдет обучение.
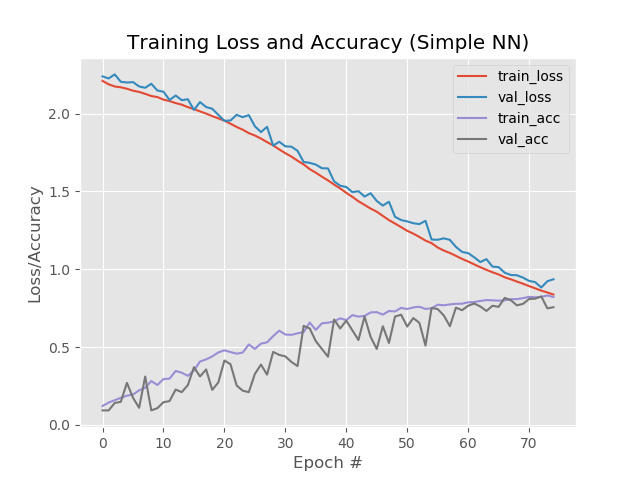
Результат:
Таким образом, 93,5%, 92,6%, 92,6%.
В картинках:
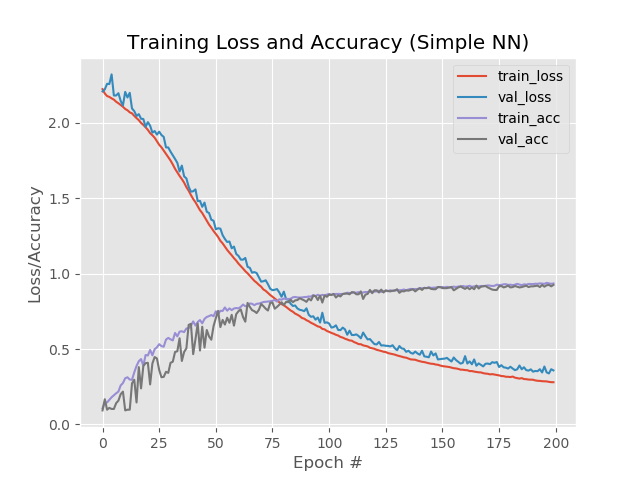
Здесь заметно, что синяя и красные линии после 130 эпохи начинают разъезжаться друг от друга и это говорит, что дальнейшее увеличение числа эпох ничего не даст. Проверим это.
В коде меняем
EPOCHS = 200на
EPOCHS = 500и снова прогоняем.
Результат:
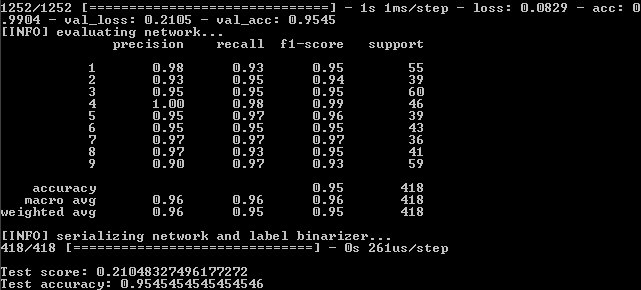
Итак, имеем:
99%,95,5%,95,5%.
И на графике:
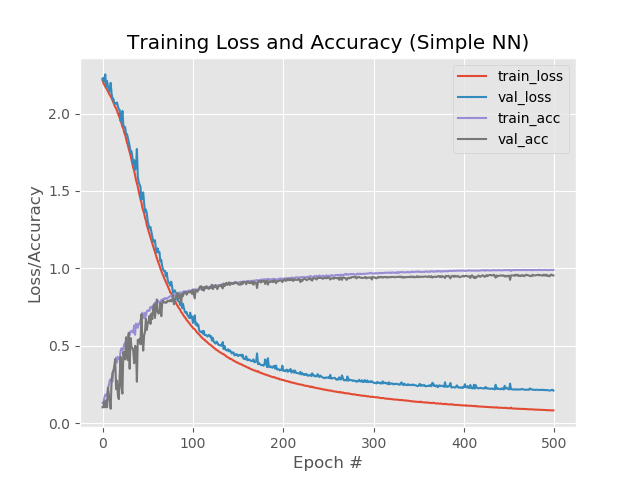
Что ж, увеличение числа эпох, явно пошло сети на пользу. Однако этот результат обманчив.
Проверим работу сети на реальном примере.
Для этих целей в папке проекта есть скрипт predict.py. Перед запуском подготовимся.
В папку images проекта положим файлы с изображениями цифр с капчи, ранее не попадавшиеся сети в процессе обучения. Т.е. надо взять цифры не из набора датасета dat.
В самом файле поправим две строки для размера изображений по умолчанию:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width")
ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")Запускаем из коммандной строки:
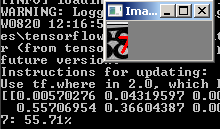
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1И видим результат:
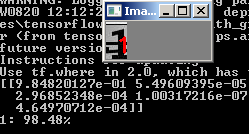
Другая картинка:
Однако не со всеми зашумленными цифрами работает:
Что здесь можно сделать?
- Увеличить количество экземпляров цифр в папках для обучения.
- Попробовать другие методы.
Попробуем другие методы
Как видно из последнего графика, синяя и красная линии расходятся примерно на 130 эпохе. Это означает, что, обучение после 130 эпохи неэффективно. Зафиксируем результат на 130 эпохе: 89,3%,88%,88% и посмотрим, работают ли другие методы улучшения работы сети.
Снизим скорость обучения.
INIT_LR = 0.01INIT_LR = 0.001Результат:
41%,39%,39%
Что ж, мимо.
Дабавим дополнительный скрытый слой.
model.add(Dense(512, activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
model.add(Dense(258, activation="sigmoid"))Результат:
56%,62%,62%
Получше, но нет.
Однако, если увеличить количество эпох до 250:
84%,83%,83%
При этом красная и синяя линия не отрываются друг от друга после 130 эпохи:
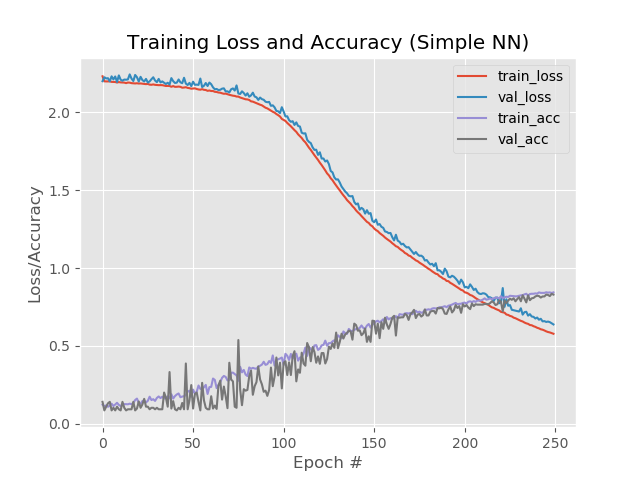
Сохраним 250 эпох и применим прореживание:
from keras.layers.core import DropoutМежду слоями вставим прореживание:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))
model.add(Dropout(0.3))
model.add(Dense(512, activation="sigmoid"))
model.add(Dropout(0.3))
model.add(Dense(258, activation="sigmoid"))
model.add(Dropout(0.3))Результат:
53%,65%,65%
Первое значение ниже остальных, это говорит о том, что сеть не обучается. Для этого рекомендуют увеличить количество эпох.
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))
model.add(Dropout(0.3))
model.add(Dense(512, activation="sigmoid"))
model.add(Dropout(0.3))
Результат:
88%,92%,92%
С 1 дополнительным слоем, прореживанием и 500 эпохами:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))
model.add(Dropout(0.3))
model.add(Dense(512, activation="sigmoid"))
model.add(Dropout(0.3))
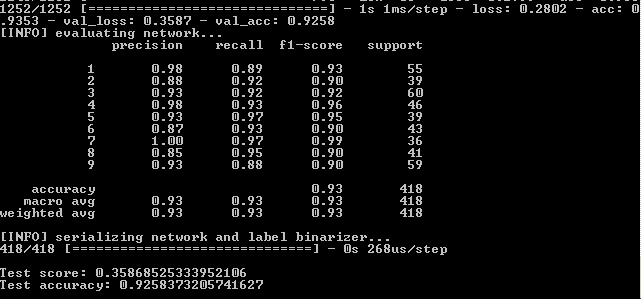
model.add(Dense(258, activation="sigmoid"))Результат:
92,4%,92,6%,92,58%
Несмотря на более низкий процент по сравнению с простым увеличением эпох до 500, график выглядит более ровным:
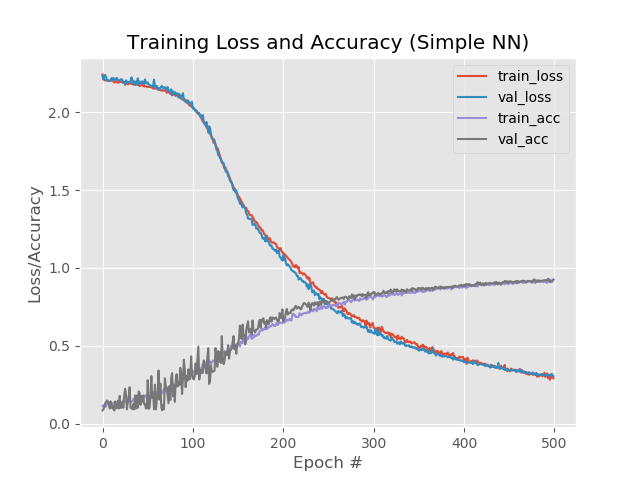
И сеть обрабатывает изображения, которые ранее выпадали:
Соберем теперь все в один файл, который нарежет изображение с капчей на входе на 5 цифр, прогонит каждую цифру через нейросеть и выдаст результат в интерпретатор python.
Здесь попроще. В файл, который нарезал нам цифры из капчи добавим файл, который занимается предсказаниями.
Теперь программа не только нарежет капчу на 5 частей, но и выведет все распознанные цифры в интерпретатор:

Опять же надо иметь в виду, что программа не дает 100% результата и зачастую одна из 5 цифр неверна. Но и это неплохой результат, если учесть, что в обучающем наборе всего по 170-200 экземпляров для каждого числа.
Распознавание капчи длится 3-5 сек на компьютере средней мощности.
Как еще можно попытаться улучшить работу сети можно почитать в книге «Библиотека Keras — инструмент глубокого обучения» А. Джулли, С.Пала.
Итоговый скрипт, который режет капчу и распознает — здесь.
Запускается без параметров.
Переработанные скрипты для тренировки и теста сети.
Капчи для теста, в том числе с ложным срабатыванием — здесь.
Модель для работы — здесь.
Цифры, разложенные по папкам — здесь.
Комментарии (25)

TheGodfather
20.08.2019 19:02Распознавание капчи длится 28 сек на компьютере средней мощности. 2 сек можно выиграть благодаря применению в скрипте многопоточности, но это, как говорится, что мертвому припарка.
Распознавание 30 сек??? Капчи??? Вроде нынче автомобильные номера в реалтайме распознаются, а у вас капча 30 секунд?Groramar
20.08.2019 20:05питон же :) да и без gpu, но всё равно как-то вяло.
TheGodfather
20.08.2019 22:07в смысле питон? Мне всегда казалось, что подобные штуки типа TensorFlow или там MKL — у них из питона только bindings, а основной код все равно C/C++. Или тут само распознавание и нейронка на чистом питоне? ОМФГ тогда, я не понимаю, куда катится мир.

Celsius
20.08.2019 21:57Скорее всего, основное время занимает инициализация TF, при первом запуске библиотека всегда долго раскочегаривается.
В горячем режиме, с загруженной моделью, результат выдается моментально.
zoldaten Автор
21.08.2019 09:25
Пока это лучший результат с «прогретым» TF на слабом железе без CUDA. Опять же надо учитывать, что по факту распознается 5-ть разных цифр отдельно, т.е. на 1 цифру приходится по 3,52 сек.midvikus
21.08.2019 10:29def prescript(file): cmdCommand = "python predict-captcha.py --image "+ file +" --model simple_nn.model --label-bin simple_nn_lb.pickle --flatten 1" process = subprocess.Popen(cmdCommand.split(), stdout=subprocess.PIPE) output, error = process.communicate() print (str(output)[2])
1. Тут скорее дело в том, что вы для распознавания каждой картинки вызываете скрипт predict-captcha.py и таким образом каждый раз заново загружаете модель, хотя достаточно это сделать один раз.
2. Не понятно зачем вообще вызывать это как скрипт, когда можно оформить как модуль и импортировать.
3. Предыдущий пункт заодно позволит не сохранять картинки на диск, а использовать питоновские file-like объекты.
4. Не понятно почему не использовалась сверточная архитектура, хотя она лучше подходит для распознавания изображений.
5. И даже ваш подход можно попробовать улучшить если использовать transfer learning.zoldaten Автор
21.08.2019 11:331,2.Да это колхоз, через subprocess, именно он все тормозит. Временная «изолента».
3. Вы про pickle.dumps?
4.Вы правы. Но интерес был выжать из простой сети максимум.
5.Каким образом это реализуется?midvikus
21.08.2019 11:45Про file-like я например про BytesIO.
Про transfer learning — мелькнула мысль, что если предварительно обучить на MNIST, а потом заморозить нижние слои, кроме предпоследнего и обучить уже на капчах. Вот, например, тут правда CNN.
А колхоз убрать не долго и тогда смысл в замерах хоть какой-то появится.zoldaten Автор
21.08.2019 13:22C BytesIO скорее всего не выйдет, т.к. изображение необходимо сначала открыть в rb режиме. В коде капча считывается в стандартном режиме, иначе ее потом не нарезать.
Такой вариант дает ошибку:
f = open(«img1», «rb»)midvikus
21.08.2019 13:50Сохраняем в буффер:
import io from PIL import Image img = Image.open('capcha.jpg') area1=(27,0,51,37) img1 = img.crop(area1) buffered_img1 = io.BytesIO() img1.save(buffered_img1)
Передаем в функцию и читаем из буффера:
import cv2 import numpy as np img1 = cv2.imdecode(np.fromstring(buffered_img1.read(), np.uint8), 1)
Только проще сразу img1 передать))zoldaten Автор
21.08.2019 15:09Спасибо за поддержку, но нет.
Переписал парсер, чтобы он вместо image.jpg принимал из буфера, но там дальше по коду идет resize img и построение массива из картинки. Вообщем, по нарастающей.
Если есть желание, можете покрутить.
YuraLia
21.08.2019 11:52Баловался подобной задачкой, на компе средней мощности (без GPU) почти мгновенно сетка распознавала, за секунды, или может доли секунд, даже не замечал лага особо никогда. Причем капча была посложнее, с шумами/дисторсией/поворотами. Сеть имела десятки слоев чтобы уверенно распознавать, архитектура типа resnet.
Может дело в том что в моей версии tensorflow-cpu использовались AVX-инструкции?

Xobotun
20.08.2019 20:46М-м-м. Мне кажется, что большей точности можно было бы добиться, заменив простейший "нож" по геометрическим координатам на хоть какой-то классификатор, который позволил бы избежать проблемы как тут:
Когда на одной картинке две половины двух разных цифр.zoldaten Автор
20.08.2019 21:59В этом-то и фикус, что сеть учится на захламленных капчах. Ниже та же картинка, но уже распознанная сетью.
vadimmikhonov
21.08.2019 11:15Как сделать лучше, исходя из этой картинки капчи. Нужно написать генератор капчи, код обучения сделать так, чтобы генератор на лету во время обучения поставлял картинки капчи. Отпадёт необходимость собирать и размечать датасет, к тому же он будет бесконечен. На сеть подавать картинку капчи целиком. Архитектуру сети делать на основе рекуррентной сети с использованием слоя LSTM или GRU. Распознавать будет доли секунды (на CPU), точность выше 95%.
zoldaten Автор
21.08.2019 15:171.Зачем нужен генератор капч, если их и так более чем достаточно — 29 000?
2. Как вы видите обучение без разметки датасета?
3. 4 секунд в данном случае вполне достаточно, точность 90% и это еще не CNN.

gofat
21.08.2019 11:33Можно заморозить получившийся граф, выгрузив его из keras'а и использовать tensorflow-serving: github.com/tensorflow/serving
Через serving должно побыстрее заработать.

Neusser
Уж пару строк-то в скрипт можно было бы добавить, чтобы он создавал…