У меня в тот момент не было в досягаемости ни принтера, ни смартфона, так что меня заинтересовали два аспекта задачи:
- Как проще всего расшифровать спектрограмму без дополнительных устройств и без дополнительного софта — желательно, прямо в браузере?
- Можно ли её расшифровать вообще без софта — «на глаз»?
(Для тех, кто видит спектрограммы впервые, стоит пояснить, что это график, где по горизонтальной оси идёт время воспроизведения, по вертикальной (она логарифмическая) — частота звука, а степень черноты точки обозначает мощность данной частоты в данный момент времени.)
Готовых скриптов для воспроизведения спектрограмм я не нашёл, хотя для обратного преобразования — звука в спектрограмму — легко* находятся примеры, благодаря тому, что функциональность
AnalyserNode.getByteFrequencyData() встроена в Web Audio API. А вот для преобразования массива частот в массив PCM для воспроизведения — не обойтись без реализации в скрипте обратного преобразования Фурье (DFT).*В первом примере в качестве аудиозаписи для спектрального анализа предлагается фрагмент трека "" от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.По поводу реализации DFT сразу ясно, что такая «числодробилка» на чистом JavaScript будет работать медленно и печально; к счастью, я обнаружил готовый порт библиотеки FFTW («Fastest Fourier Transform in the West») на asm.js — это форма представления низкоуровневого кода, обычно написанного на Си, которую современные браузеры обещают выполнять со скоростью почти как у скомпилированного в машинный код. Обвязку для FFTW, превращающую чёрно-белое изображение в WAV-файл, я взял из ARSS и собственноручно переписал на JavaScript. ARSS принимает изображения, инвертированные по сравнению с PhonoPaper, и я не стал это менять.
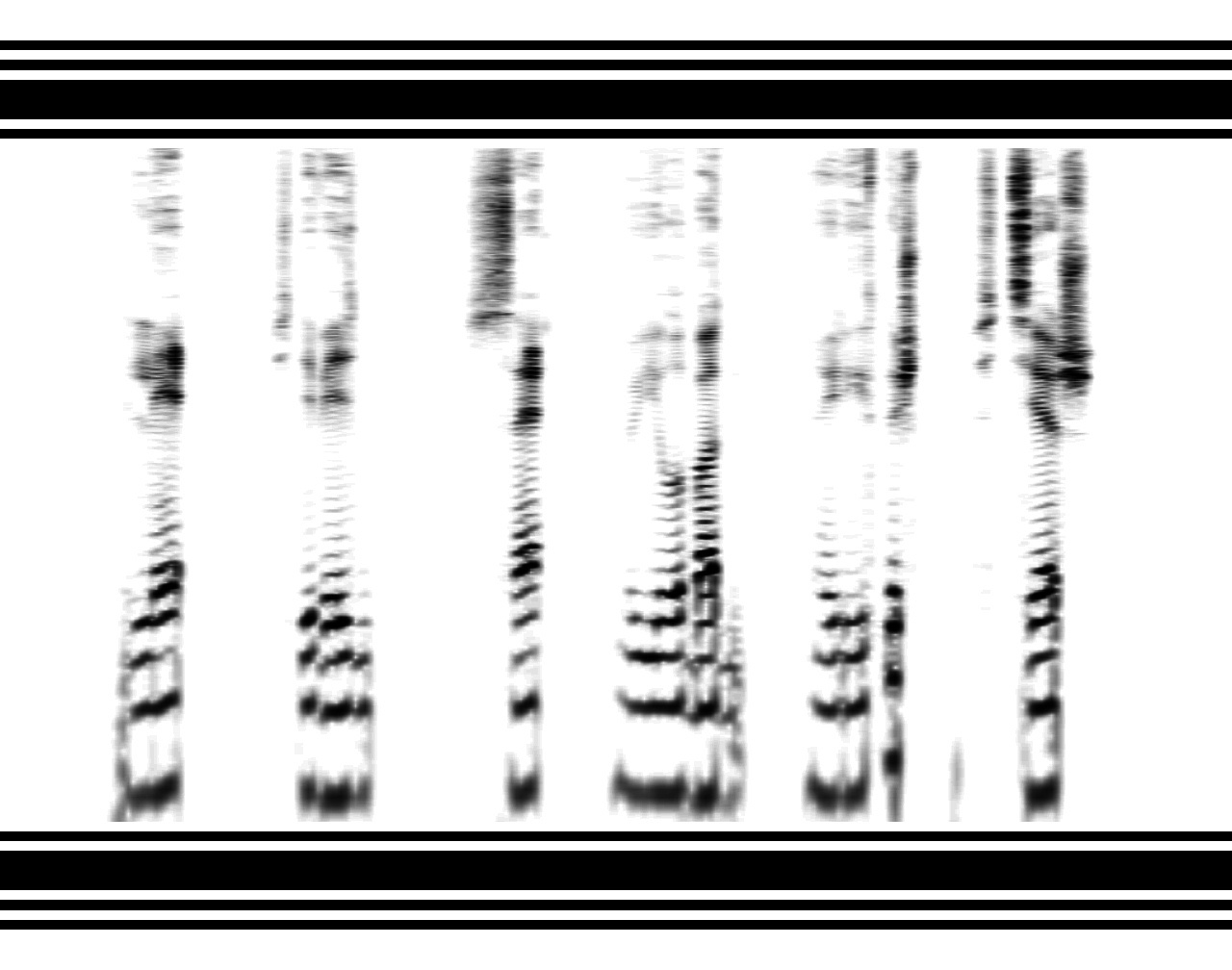
Результатом вы можете полюбоваться на tyomitch.github.io/#meklon.png
Внизу видны повторяющиеся горизонтальные полосы — форманты, по положению которых распознаются гласные. Вверху — вертикальные «всплески», соответствующие шумным согласным: более широкие — щелевым (фрикативным), более узкие — смычным. Сонорным же согласным ([р] и [л]) соответствуют «облака» в средних частотах.

Для того, чтобы можно было поиграть со спектрограммой, я приделал примитивную рисовалку, почти целиком скопированную из туториала по рисованию на canvas. Кнопка «Copy» позволяет перевести изображение в красный канал (он игнорируется синтезатором) и попытаться «обвести» звуки.
Википедия пишет: «Считается, что для характеристики звуков речи достаточно выделения четырёх формант». Обведём форманты F2-F4 (F1 почему-то игнорируется синтезатором), и убедимся, что гласные вполне распознаются:

Затем обведём шумные согласные: аффриката [ч] — это [т], плавно переходящее в [ш]; а звонкое [д] от глухого [т] отличается наличием среднечастотных формант. Теперь уже можно различить цифры «шесть» и «де'ить»:
Добавляем тёмно-серым сонорные согласные: заодно заметим, что [р] немного «приподнимает» гласные форманты, а [л] — наоборот, опускает.

Остались недорисованными только губные согласные [б] и [в], но и без них пароль более-менее ясен.
А можно ли нарисовать звук с чистого листа, не обводя спектрограмму аудиозаписи? Скажу честно, у меня не получилось. Может быть, хотите попробовать сами?
Комментарии (13)

Quiensabe
04.10.2019 17:34+1Очень любопытно!
Жаль не получается подгрузить свою картинку со спектрограммой, для экспериментов. Пробовал указать ссылку вместо имени файла в ссылке (пример), в редакторе изображение появляется, но воспроизведение не работает, увы.
tyomitch Автор
04.10.2019 17:57Тут сразу две проблемы: во-первых, размер спектрограммы у меня захардкожен (400х225), потому что я боялся, что для больших изображений FFTW не будет успевать отрабатывать «в реальном времени»; во-вторых, правила безопасности запрещают JS-коду, пришедшему с одного домена, работать с данными, пришедшими с другого домена.
Если хотите поиграть со своими собственными изображениями, то проще всего сохранить мой код (HTML-файл и FFTW.js) на локальный диск, и открывать оттуда. Хрому при этом нужен ещё и флаг--allow-file-access-from-files. Именно так — открывая с локального диска — я свой скрипт и отлаживал.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

TimeCoder
04.10.2019 21:11+1Спасибо! Пара вопросов:
- Какова ширина окна? Ну в смысле, если по горизонтали время, а вертикали — частоты, мы же не можем построить спектр по одному отчёту сигнала? Как я понимаю, есть скользящее окно (и наверное ещё и домножаемое на оконную функцию Хэмминга), но какова его ширина? Для сигнала 44100 Hz.
- Про форманты, можете хотя бы кратко? Просто, я в университете занимался 3й формантой, это было лет 15 назад, и может забыл, но в упор не помню, чтобы в голосе видел 4-ю.
tyomitch Автор
04.10.2019 22:47- Хороший вопрос! Код DSP я взял из ARSS, не слишком в него вникая — вероятно, именно из-за этого у меня синтезатор игнорирует самые низкие частоты, включая F1. Судя по тому, что в комментариях к генерации фильтра упоминается «Blackman function», то для окна используется именно она, а ширина окна задаётся параметром
tbw, в моём случае равным 27 сэмплам. При этом у меня строится не спектр по сигналу, а наоборот, сигнал по спектру; и окно используется только для интерполяции спектра (от 50 пикселей в секунду — к 44100 сэмплам). - Форманта — это просто узкая полоса частот, в которой в какой-то промежуток времени сконцентрировано много энергии. Формант можно выделить очень много (в слове «эс» на КДПВ видно больше десятка), но для анализа речи достаточно первых трёх или четырёх, у остальных просто нет практического применения.
- Хороший вопрос! Код DSP я взял из ARSS, не слишком в него вникая — вероятно, именно из-за этого у меня синтезатор игнорирует самые низкие частоты, включая F1. Судя по тому, что в комментариях к генерации фильтра упоминается «Blackman function», то для окна используется именно она, а ширина окна задаётся параметром

buriy
05.10.2019 01:07А зачем рисовать спектрограмму в логарифмическом виде? Так же ничего не понятно!

FocusReactive
05.10.2019 14:44Интересно! Помню был другой проект, наоборот звук рисовать. Весело pixelscommander.com/interactive-revolution/funkyphone-webaudio-api-music-instrument
DimPal
Возможно для синтеза речи «на глаз» такая визуализация не самая лучшая. Осмелюсь предположить, что слоги лучше могут быть лучше видны на банальной огибающей громкости. Что касается формант (и причудливое правило поиска четырех формант), то мне это больше напоминает аккорд. Знаете, аккорд в музыке можно записать одной буквой, а гармоник там может быть много, причем в разных октавах по разному. На мой взгляд, если свести гласные к какому-то аналогу музыкальных нот, то будет чуть нагляднее. Только хроматических нот в октаве 12, а для визуализации речи наверно лучше разбить помельче. Тембральный же окрас нужно как то цветами что ли передавать. IMHO подобная визуализация была бы нагляднее.