
Скачать файл с кодом и данные можно в оригинале поста в моем блоге
Существует очень интересный проект — «Розеттский Код». Их цель — «представить решение одинаковых задач на максимально возможном числе различных языков программирования для того, чтобы продемонстрировать их общие места и различия и помочь человеку обладающему знаниями по решению проблемы одним методом узнать другой».
Этот ресурс предоставляет уникальную возможность сравнить коды программ на разных языках, этим мы и займемся в этой статье. Она является полной переработкой и доработкой статьи Джона Маклуна "Code Length Measured in 14 Languages".
Импорт и парсинг данных
Начнем с создания модификации функции Import которая будет хранить данные для дальнейшего использования чтобы не запрашивать их потом у сервера.
Clear[importOnce];
importOnce[args___]:=importOnce[args]=Import[args];
If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "importOnce.mx"}]Создадим парсер для импорта данных.
Clear[createPageLinkDataset];
createPageLinkDataset[baseLink_]:=createPageLinkDataset[baseLink]=Cases[Cases[Import[baseLink, "XMLObject"], XMLElement["div", {"class"->"mw-content-ltr", "dir"->"ltr", "lang"->"en"}, data_]:>data, Infinity], XMLElement["li", {}, {XMLElement["a", {___, "href"->link_, ___}, {name_}]}]:><|"name"->name, "link"->"http://rosettacode.org"<>link|>, Infinity];
If[FileExistsQ[#], Get[#], Null]&@FileNameJoin[{NotebookDirectory[], "createPageLinkDataset.mx"}]Импортируем список всех языков программирования, поддерживаемых проектом (их уже более 750):
$Languages=createPageLinkDataset["http://rosettacode.org/wiki/Category:Programming_Languages"];
Dataset@$Languages
Создадим функции перевода имени в ссылку и наоборот, это нам потом пригодится:
langLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Languages, #[["link"]]==link&]["name"];
langNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Languages, #[["name"]]==name&]["link"];Подгрузим список задач, решенных на каждом из языков программирования. Парсинг устроен так, что не все ссылки на страницы будут являться задачами. Мы прочистим их позднее.
$LangTasksAllPre=Map[<|"name"->#["name"], "link"->#["link"], "tasks"->createPageLinkDataset[#["link"]][[All, "link"]]|>&, $Languages];
Dataset@$LangTasksAllPre
Вычислим список всех потенциальных задач, решение которых есть в проекте (их чуть более 2600):
$TasksPre=DeleteDuplicates[Flatten[$LangTasksAllPre[[;;, "tasks"]]]];
Length[$TasksPre]
Создадим функцию, которая выцепляет все фрагменты кода на странице задачи.
ClearAll[codeExtractor];
codeExtractor[link_String]:=Module[{code, positions, rawData},
code=importOnce[link, "XMLObject"];
positions=Map[{#[[1, 1;;-2]], Partition[#[[;;, -1]], 2, 1]}&,
DeleteCases[
Gather[
Position[code, XMLElement["h2", _, title_]],
And[Length[#1]==Length[#2], #1[[1;;-2]]==#2[[1;;-2]]]&],
x_/;
Length[x]==1]];
rawData=Framed/@Flatten[Map[
With[{pos=#[[1]]}, Map[Extract[code, pos][[#[[1]];;#[[2]]-1]]&, #[[2]]]]&, positions],
1];
Association@DeleteCases[Map[langLinkToName[("link"/.#)]->("code"/.#)&, Map[
KeyValueMap[If[#1==="link", #1->#2[[1]], #1->#2]&, Merge[SequenceSplit[Cases[#, Highlighted[x_, ___]:>x, Infinity], {"Output"}][[1]], Identity]]&,
rawData/.{XMLElement["h2", _, title_]:>Cases[title, XMLElement["a", {___, "href"->linkInner_/;
MemberQ[$Languages[[;;, "link"]], "http://rosettacode.org"<>linkInner], ___}, {___}]:>Highlighted[<|"link"->"http://rosettacode.org"<>linkInner|>], Infinity],
XMLElement["div", {}, x_/;
Not[FreeQ[x, "Output:"]]]:>Highlighted["Output"],
XMLElement["pre", _, code_]:>Highlighted[<|"code"->Check[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]], Echo[StringJoin@Flatten[code//.XMLElement["span", _, codeFragment_]:>codeFragment//.XMLElement["br", {"clear"->"none"}, {}]:>"\n"//.XMLElement["a", {___}, codeFragment_]:>codeFragment//.XMLElement["b", {}, {x_}]:>x//.XMLElement["big", {}, {x_}]:>x//.XMLElement["sup", {}, x_]:>Flatten[x]//.XMLElement["sub", {}, x_]:>Flatten[x]//.XMLElement[_, {___}, x_]:>Flatten[x]]]]|>, Background->Red]}
]], _->"code"]];Теперь обработаем все страницы:
ClearAll[taskCodes];
taskCodes[link_]:=taskCodes[link]=Check[codeExtractor[link], Echo[link]];
If[FileExistsQ[#], Get[#], taskCodes/@$TasksPre;
DumpSave[#, taskCodes]]&@FileNameJoin[{NotebookDirectory[], "taskCodes.mx"}];Пример того, что выдает функция:
Dataset[taskCodes[$TasksPre[[20]]]]
Выделим страницы задач (те, на которых есть хотя бы один фрагмент кода):
$taskLangs=DeleteCases[{#, taskCodes[#]}&/@$TasksPre, {_, <||>}];$langTasks=Map[<|"name"->#[["name"]], "link"->#[["link"]], "tasks"->With[{lang=#[["name"]]}, Select[$taskLangs, MemberQ[Keys[#[[2]]], lang]&][[;;, 1]]]|>&, $Languages];
Dataset[$langTasks]
Список задач и функции, переводящие имя задачи в ссылку, и наоборот:
$Tasks=<|"name"->StringReplace[URLDecode[StringReplace[#, "http://rosettacode.org/wiki/"->""]], {"_"->" ", "/"->" -> "}], "link"->#|>&/@$taskLangs[[;;, 1]];
taskLinkToName[link_String]:=langLinkToName[link]=SelectFirst[$Tasks, #[["link"]]==link&]["name"];
taskNameToLink[name_String]:=langNameToLink[name]=SelectFirst[$Tasks, #[["name"]]==name&]["link"];Простая статистика
Для ряда языков пока ещё нет ни одной решенной задачи:
WordCloud[1/StringLength[#]->#&/@Select[$langTasks, Length[#["tasks"]]==0&][[All, "name"]], ImageSize->{1200, 800}, MaxItems->All, WordOrientation->{{-Pi/4, Pi/4}}, FontTracking->"Extended", Background->GrayLevel[0.98], FontFamily->"Intro"]
Список языков у которых есть решенные задачи:
$LanguagesWithTasks=Select[$langTasks, Length[#["tasks"]]=!=0&][[All, "name"]];
Length[$LanguagesWithTasks]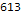
Распределение количества решенных задач по языкам:
Histogram[Length/@$langTasks[[;;, "tasks"]], 50, PlotRange->All, BarOrigin->Bottom, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {"Количество задач", lg["Количество языков"]}], ScalingFunctions->"Log10", PlotLabel->Style["Распределение количества решенных задач по языкам", 20]]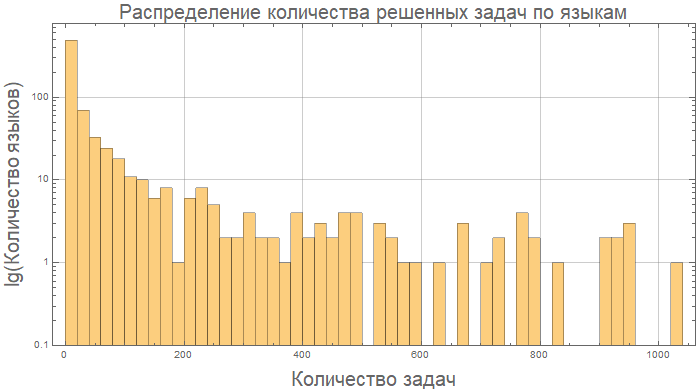
Распределение количества языков по решенным задачам:
Histogram[Length/@$taskLangs[[;;, 2]], 50, PlotRange->All, AspectRatio->1/2, ImageSize->700, Background->White, Frame->True, GridLines->Automatic, FrameLabel->Map[Style[#, 20]&, {"Количество языков", "Количество задач"}], PlotLabel->Style["Распределение количества языков по решенным задачам", 20]]
Языки, в которых больше всего решенных задач:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.1, BarOrigin -> Left, AspectRatio -> 1, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{"Количество решенных задач", "Количество решенных задач"}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last], {_, x_/;
x<200}]
Задачи, решенные на наибольшем числе языков программирования:
BarChart[#1[[;;, 2]], PlotRangePadding->0, BarSpacing -> 0.2, BarOrigin -> Left, AspectRatio -> 1.6, ImageSize -> 1000, ChartLabels -> #1[[;;, 1]], Frame -> True, GridLines -> {Range[0, 10^3, 50], None}, ColorFunction -> ColorData["Rainbow"], FrameLabel->{{None, None}, Style[#, FontFamily->"Open Sans Light", 16]&/@{"Количество языков программирования", "Количество языков программирования"}}, FrameTicks->{Automatic, {All, All}}, Background->White] &@DeleteCases[SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last], {_, x_/;
x<100}]
Задачи, имеющие решение для заданного набора языков программирования
Функция, которая выводит задачи, решенные на одном или нескольких языках программирования сразу:
commonTasks[lang_String]:=commonTasks[lang]=Sort[SelectFirst[$langTasks, #["name"]==lang&][["tasks"]]];
commonTasks["Mathematica"]:=commonTasks["Mathematica"]=Union[commonTasks["Wolfram Language"], Sort[SelectFirst[$langTasks, #["name"]=="Mathematica"&][["tasks"]]]];
commonTasks[lang_List]:=commonTasks[lang]=Sort[Intersection@@(commonTasks/@lang)];Задачи, общие для первых 25 самых популярных языков (размер шрифта соответствует относительному количеству языков, на которых задача решена):
WordCloud[With[{tasks=taskLinkToName/@commonTasks[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-25;;-1]][[;;, 1]]]}, Transpose@{tasks, tasks/.Rule@@@SortBy[{taskLinkToName[#[[1]]], Length[#[[2]]]}&/@$taskLangs, Last]}], ImageSize->{1000, 1000}, MaxItems->All, WordOrientation->{{-Pi/4, Pi/4, 0, Pi/2}}, Background->GrayLevel[0.98], FontFamily->"Intro"]
Функциия для измерения длины кода
Далее нам необходима метрика для оценки длины кода. Обычно считается, что это количество строк кода:
SetAttributes[lineCount, Listable]
lineCount[str_String]:=StringCount[StringReplace[StringReplace[str, {" "->"", "\t"->""}], "\n"..->"\n"], "\n"]+1;Но так как на этот параметр существенно влияет разметка кода (в конце концов, скажем, в Wolfram Langiuage (Mathematica) Вы можете в одной строчке написать сразу несколько команд), мы будем использовать в качестве метрики число символов которые не являются пробелами.
SetAttributes[characterCount, Listable]
characterCount[str_String]:=StringLength[StringReplace[str, WhitespaceCharacter->""]];Такая метрика играет не на руку Mathematica с ее длинными описательными именами команд (что несомненно большой плюс за пределами этого блога) поэтому также реализуем метрику основанную на подсчете токенов («знаковых» объектов), в качестве которых будем брать отдельные слова разделенные любым символом не являющимся буквой.
SetAttributes[tokens, Listable]
tokens[str_String]:=DeleteCases[StringSplit[str, Complement[Characters@FromCharacterCode[Range[1, 127]], CharacterRange["a", "z"], CharacterRange["A", "Z"], CharacterRange["0", "9"], {"."}]], ""];
tokenCount[str_String]:=Length[tokens[str]];Измерение длины кода
Получим набор данных относительно каждой задачи:
$taskData=Map[<|"name"->#[[1]], "lineCount"->Map[lineCount, #[[2]]], "characterCount"->Map[characterCount, #[[2]]], "tokens"->Map[Flatten[tokens[#]]&, #[[2]]]|>&, $taskLangs];
Dataset[$taskData]
Функция, которая собирает статистику по каждому языку относительно всех задач, решенных на нем:
Clear[langData];
langData[name_]:=langData[name]=<|"name"->name,
"lineCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "lineCount"]], name]]],
"characterCount"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "characterCount"]], name]]],
"tokens"->If[name==="Mathematica", DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]~Join~DeleteMissing[AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], "Wolfram Language"]]], AssociationThread[#[[;;, "name"]]->Lookup[#[[;;, "tokens"]], name]]]|>&@(With[{task=#}, SelectFirst[$taskData, #[["name"]]==task&]]&/@commonTasks[name]);
Map[langData, $LanguagesWithTasks];Функция, вычисляющая метрики сравнения для двух (или более) языков программирования на основе всех общих для них задач:
ClearAll[compareLanguagesData, compareLanguages];
compareLanguagesData[langs_List/;
Length[langs]>=2]:=compareLanguagesData[langs]=Module[{tasks, data},
tasks=commonTasks[langs];
data=langData/@langs;
<|"lineCount"->Transpose[Lookup[#[["lineCount"]], tasks][[;;, 1]]&/@data],
"characterCount"->Transpose[Lookup[#[["characterCount"]], tasks][[;;, 1]]&/@data],
"tokensCount"->Transpose[Lookup[Map[Length, #[["tokens"]]], tasks]&/@data]|>
];
compareLanguages[langs_List/;
Length[langs]>=2, function_]:=Module[{data},
data=compareLanguagesData[langs];
Map[Map[function, #]&, data]
];Анализ и визуализации
Теперь мы можем получить массу аналитики.
Для начала сравним абсолютные показатели. Функция, приведенная ниже, строит график, на котором точками показано соответствующее значения для двух языков. Если точка находится под линией диагонали (масштаб по осям разный, часто, если длина кода сильно разнится), то это означает, что язык снизу «выиграл», иначе — язык «сверху».
compareGraphic[{lang1_, lang2_}]:=
Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[Graphics[{Map[{If[#[[1]]<#[[2]], Orange, Darker@Green], Point[#]}&, #2], AbsoluteThickness[2], Gray, InfiniteLine[{{0, 0}, {1, 1}}]}, PlotRangePadding->0, GridLines->Automatic, AspectRatio->1, PlotRange->All, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->"Количество строк кода", "characterCount"->"Количество символов в коде", "tokensCount"->"Количество токенов в коде"}), 20, FontFamily->"Open Sans Light"])]&, compareLanguages[{lang1, lang2}, Identity]], Background->White]Явно видно, что кода на Wolfram Language всегда почти короче кода на C:
compareGraphic[{"Mathematica", "C"}]
Или Pytnon:
compareGraphic[{"Mathematica", "Python"}]
А вот, например, Kotlin и Java по сути «одинаковые» в плане длины кода:
compareGraphic[{"Kotlin", "Java"}]
Это графическое представление можно сделать более информативным:
comparePlot[{lang1_, lang2_}]:=
Grid[{#[[1;;2]], {#[[3]], SpanFromLeft}}&@KeyValueMap[ListLinePlot[Sort@#2, GridLines->Automatic, AspectRatio->1, PlotRange->{Automatic, {0, 2}}, Frame->True, ImageSize->500, Background->White, FrameLabel->(Style[#/."Mathematica"->"Wolfram Language (Mathematica)", 16, FontFamily->"Open Sans Light"]&/@{lang1, lang2}), PlotLabel->(Style[(#1/.{"lineCount"->"Количество строк кода", "characterCount"->"Количество символов в коде", "tokensCount"->"Количество токенов в коде"}), 20, FontFamily->"Open Sans Light"]), ColorFunction->(If[#2>1, Orange, Darker@Green]&), ColorFunctionScaling->False, PlotStyle->AbsoluteThickness[3]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]], Background->White]comparePlot[{"Mathematica", "R"}]
comparePlot[{"BASIC", "ALGOL 68"}]
Зададим функцию, которая будет выводить список «популярных» языков программирования (тех, на которых решено наибольшее число задач):
Clear[$popularLanguages];
$popularLanguages[n_/;
n>2]:=$popularLanguages[n]=Reverse[SortBy[{#[["name"]], Length[#[["tasks"]]]}&/@$langTasks, Last][[-n;;-1]]]$popularLanguages[25]
Визуализируем список из первых 350 языков (именно так создана заставка к этому посту в начале):
WordCloud[$popularLanguages[350], ColorNegate@Binarize@ImageCrop@Import@"D:\\YandexDisk\\WolframMathematicaRuFiles\\388-3885229_rosetta-stone-silhouette-stone-silhouette-png-transparent-png.png", ImageSize->1000, MaxItems->All, WordOrientation->{{-Pi/4, Pi/4}}, FontTracking->"Extended", Background->GrayLevel[0.98], FontFamily->"Intro"]
Функция, выводящая анализ длины кода в разных метриках для n первых по популярности языков:
ClearAll[langMetricsGrid];
langMetricsGrid[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction},
$nPL=n;
meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]];
$pl=$popularLanguages[$nPL][[;;, 1]];
tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}];
order=If[OptionValue["SortQ"],
Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]<OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]];
orderedMeans=Round[If[OptionValue["SortQ"],
Map[Mean, tableData/.""->Nothing][[order]], Map[Mean, tableData/.""->Nothing]], 1/1000]//N;
{min, max}=MinMax[Cases[Flatten[tableData], _?NumericQ]];
scale=Function[Evaluate[Rescale[#, {min, max}, {0, 1}]]];
fullTableData=Transpose[{{""}~Join~$pl[[order]]}~Join~{{"Среднее"}~Join~orderedMeans}~Join~Transpose[{Map[Rotate[#, 90Degree]&, $pl]}~Join~ReplaceAll[tableData, x_?NumericQ:>Item[Round[x, 1/100]//N, Background->Which[x<1, LightGreen, x==1, LightBlue, x>1, LightRed]]][[order]]/.""->Item["", Background->Gray]]];
Framed[Labeled[Style[Row[{"Медианное значение отношения количества ", Style[type/.{"lineCount"->"строк кода", "characterCount"->"символов в коде", "tokensCount"->"токенов в коде"}, Bold], "\nв решении задач на разных языках программирования"}], 22, FontFamily->"Open Sans Light", TextAlignment->Center], Grid[fullTableData, Background->White, ItemStyle->Directive[FontSize -> 12, FontFamily->"Open Sans Light"], Dividers->White]], FrameStyle->None, Background->White]];Медианное значение отношения количества строк кода в решении задач на разных языках программирования:
langMetricsGrid[25, "lineCount", "SortQ"->False]
Если отсортировать таблицу по столбцу «Среднее», будет более наглядно — лидирует Wolfram Language (Mathematica):
langMetricsGrid[25, "lineCount", "SortQ"->True]
Медианное значение отношения количества символов в коде в решении задач на разных языках программирования:
langMetricsGrid[25, "characterCount", "SortQ"->True]
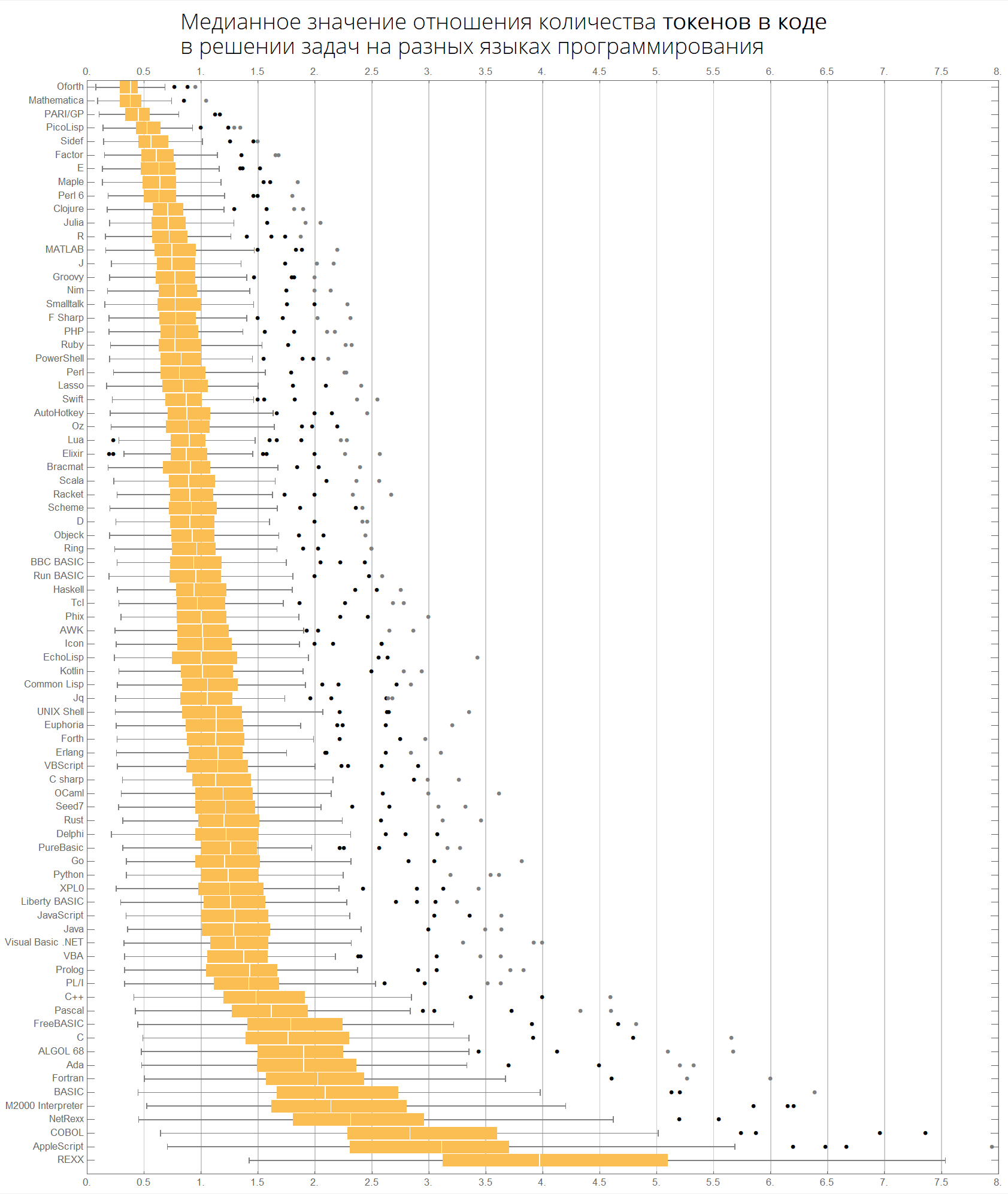
Медианное значение отношения количества токенов в коде в решении задач на разных языках программирования:
langMetricsGrid[25, "tokensCount", "SortQ"->True]
Эти же таблицы можно построить, скажем, для первых 50 по популярности языков:
langMetricsGrid[50, "lineCount", "SortQ"->True]
langMetricsGrid[50, "characterCount", "SortQ"->True]
langMetricsGrid[50, "tokensCount", "SortQ"->True]


Можем представить эту же информацию компактнее — в виде ящиков с усами (box-and-whiskers diagram):
ClearAll[langMetricsBoxWhiskerChart];
langMetricsBoxWhiskerChart[n_Integer, type_, OptionsPattern[{"SortQ"->True, "measureFunction"->Mean}]]:=Module[{$nPL, $pl, tableData, scale, notSortedTableData, order, fullTableData, min, max, orderedMeans, meanFunction},
$nPL=n;
meanFunction[{lang1_, lang2_}]:=Quiet[Map[Median[N[#]]&, compareLanguages[{lang1, lang2}, Divide[#[[1]], #[[2]]]&]/.ComplexInfinity->Nothing/.Indeterminate->Nothing]];
$pl=Reverse@$popularLanguages[$nPL][[;;, 1]];
tableData=Quiet@Table[If[i==j, "", meanFunction[{$pl[[i]], $pl[[j]]}][[type]]], {i, 1, $nPL}, {j, 1, $nPL}];
order=If[OptionValue["SortQ"],
Ordering[tableData, All, OptionValue["measureFunction"][#1/.""->Nothing]>OptionValue["measureFunction"][#2/.""->Nothing]&], Range[1, $nPL]];
Framed[Labeled[Style[Row[{"Медианное значение отношения количества ", Style[type/.{"lineCount"->"строк кода", "characterCount"->"символов в коде", "tokensCount"->"токенов в коде"}, Bold], "\nв решении задач на разных языках программирования"}], 22, FontFamily->"Open Sans Light", TextAlignment->Center],
BoxWhiskerChart[tableData[[order]], "Outliers", ChartLabels->$pl[[order]], BarOrigin->Left, ImageSize->1000, AspectRatio->1, GridLines->{Range[0, 20, 1/2], None}, FrameTicks->{Range[0, 20, 0.5], Automatic}, PlotRangePadding->0, PlotRange->{{0, 8}, Automatic}, Background->White]
], FrameStyle->None, Background->White]];Языки отсортированы по популярности (диаграмма показывает отношение количества строк кода между языками):
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->False]
По значению медианы:
langMetricsBoxWhiskerChart[80, "lineCount", "SortQ"->True]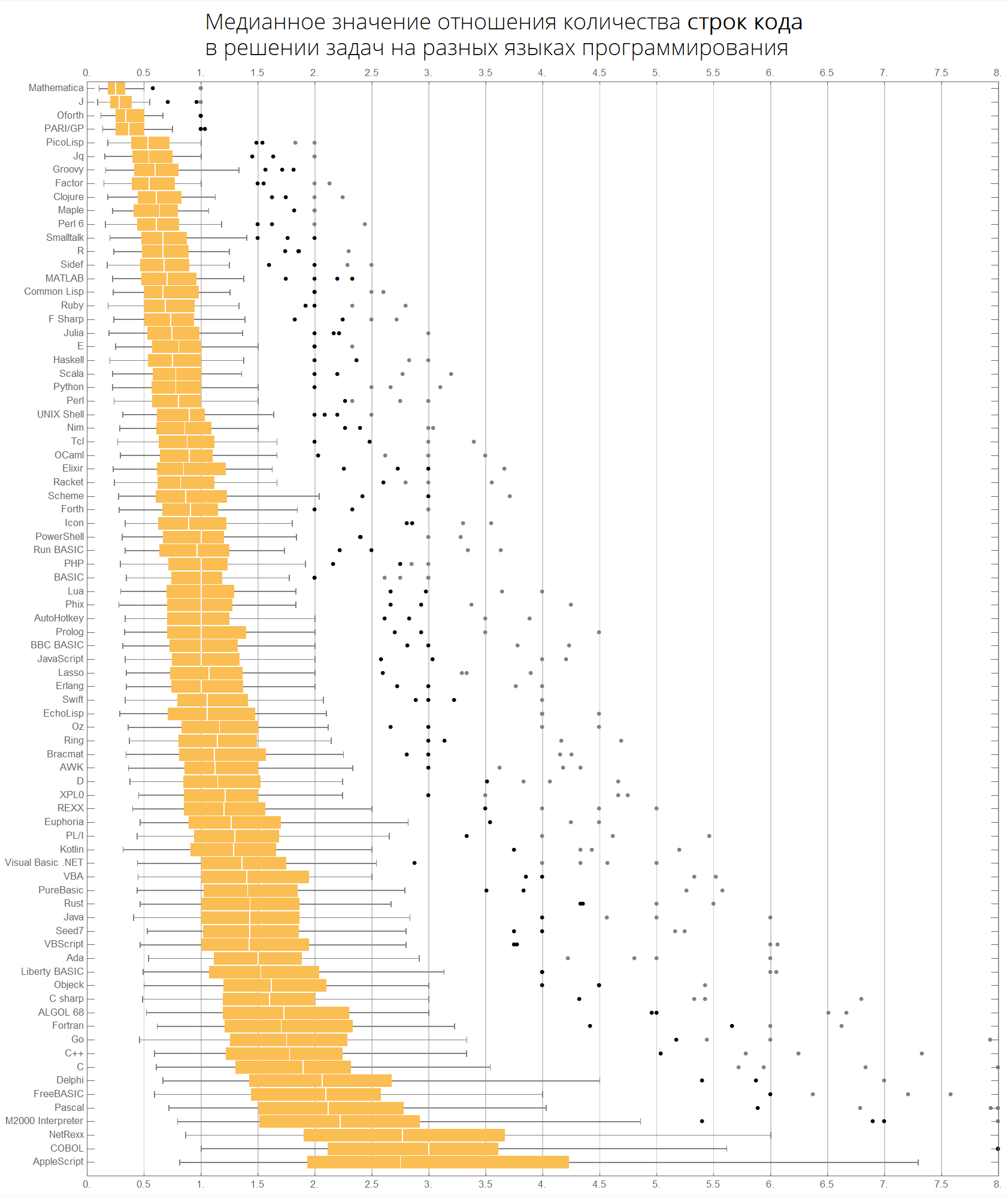
Наконец, диаграммы относительно количества символов и токенов:
langMetricsBoxWhiskerChart[80, "characterCount", "SortQ"->True]
langMetricsBoxWhiskerChart[80, "tokensCount", "SortQ"->True]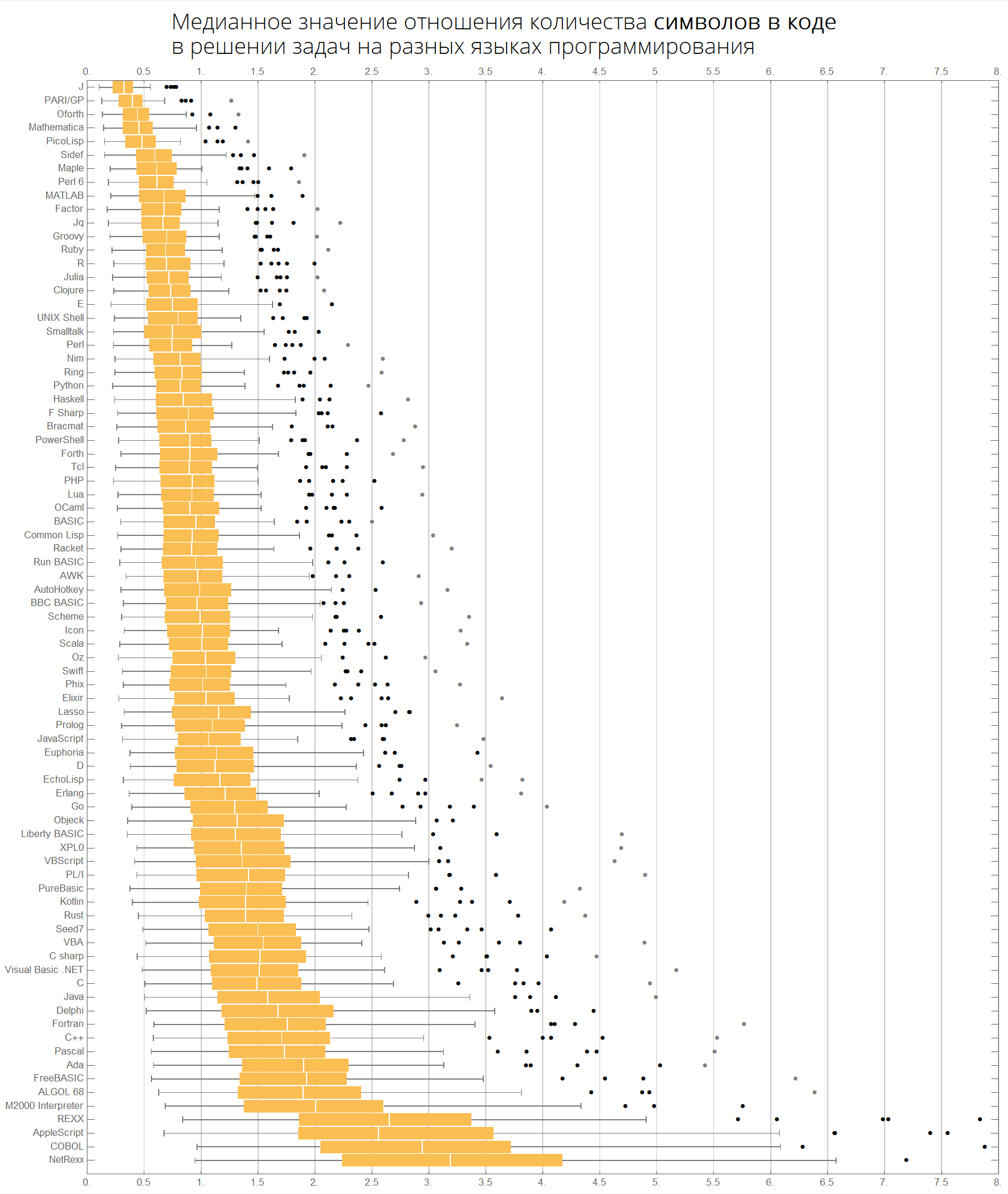
Посмотрим, какие токены популярны в разных языках:
languagePopularTokens[lang_, nMin_:50]:=Framed[Labeled[Style[Row[{"Популярные токены языка ", Style[lang, Bold]}], FontFamily->"Open Sans Light", 24], WordCloud[Cases[SortBy[Tally[Flatten[Values[langData[lang][["tokens"]]]]], -Last[#]&], {x_/;
(StringLength[x]>1&&StringMatchQ[x, RegularExpression["[a-zA-Z0-9.]+"]]&&Not[StringMatchQ[x, RegularExpression["[0-9.]+"]]]), y_/;
y>nMin}], ImageSize->{1000, 500}, MaxItems->200, WordOrientation->{{-Pi/4, Pi/4}}, Background->GrayLevel[0.98]]], FrameStyle->None, Background->White]clouds=Grid[{Image[#, ImageSize->All]&@Rasterize[languagePopularTokens[#, 10]]}&/@{"Mathematica", "C", "Python", "Go", "JavaScript"}]
И, наконец, очень интересное сравнение языков на основе близости их токенов.
Функция langSimilarity работает следующим образом: сначала отбираются «осмысленные токены» (таковыми считаются все, являющиеся строками из символов латинского алфавита, длиной не менее 2 символов, которые могут содержать точку); затем ищутся токены для пары языков lang1 и lang2; после этого считается мера их «похожести», как произведение меры Жаккара двух множеств токенов на сумму, отвечающую за близость токенов между друг другом (сумма элементов вида , где — сумма появлений токена во всех решениях задач языка lang1 и lang2, соответственно).
Clear[langSimilarity];
langSimilarity[{lang1_,lang2_},clearTokens_]:=langSimilarity@@(Sort[{lang1,lang2}]~Join~{clearTokens});
langSimilarity[lang1_,lang2_,clearTokens_:False]:=langSimilarity[lang1,lang2,clearTokens]=Module[{tokens,t1,t2,t1W,t2W,intersection},
tokens[lang_]:=Module[{values,tokensPre,allValues,replacements,n},
values=Values[langData[lang][["tokens"]]];
n=Length[values];
allValues=DeleteDuplicates[Flatten[values]];
tokensPre=If[clearTokens,Cases[allValues,x_/;(StringLength[x]>1&&StringMatchQ[x,RegularExpression["[a-zA-Z0-9._$]+"]]&&Not[StringMatchQ[x,RegularExpression["[0-9.,eE]+"]]])],allValues];
replacements=Dispatch@ Thread[Complement[allValues,tokensPre]->Nothing];
Cases[Tally@Flatten@(values/.replacements),{t_,x_/;x>=n/10}:>{t,x}]];
{t1,t2}=tokens/@{lang1,lang2};
{t1W,t2W}=Dispatch/@{Rule@@@t1,Rule@@@t2};
intersection=Intersection[t1[[;;,1]],t2[[;;,1]]];
Times@@{Total[(#[[1]]+#[[2]])/(1+Abs[#[[1]]-#[[2]]])&/@Transpose@N[{intersection/.t1W,intersection/.t2W}]],Length[intersection]/Length[Union[t1[[;;,1]],t2[[;;,1]]]]}]ClearAll[langSimilarityGrid];
langSimilarityGrid[n_Integer,
OptionsPattern[{"SortQ" -> True, "measureFunction" -> Mean,
"clearTokens" -> True}]] :=
Module[{$nPL, $pl, tableData, notSortedTableData, order,
fullTableData, min, max, orderedMeans, median, rescale},
$nPL = n;
$pl = $popularLanguages[$nPL][[;; , 1]];
tableData =
Quiet@Table[
If[i == j, "",
langSimilarity[{$pl[[i]], $pl[[j]]},
OptionValue["clearTokens"]]], {i, 1, $nPL}, {j, 1, $nPL}];
{min, max} = MinMax[Flatten[tableData] /. "" -> Nothing];
median = 10^Median@Log10@Flatten[tableData /. "" -> Nothing];
rescale = Function[Evaluate[Rescale[#, {median, max}, {0, 1}]]];
order = If[OptionValue["SortQ"],
Ordering[tableData, All,
OptionValue["measureFunction"][#1 /. "" -> Nothing] >
OptionValue["measureFunction"][#2 /. "" -> Nothing] &],
Range[1, $nPL]];
fullTableData =
Transpose[{{""}~Join~$pl[[order]]}~Join~
Transpose[{Map[Rotate[#, 90 Degree] &, $pl]}~Join~
ReplaceAll[tableData[[order]],
x_?NumericQ :>
Item[Style[Round[x, 1], If[x < median, Black, White]],
Background ->
If[x < median, LightGray,
ColorData["Rainbow"][rescale[x]]]]] /.
"" -> Item["", Background -> Gray]]];
Framed[
Labeled[Style[
Row[{"Близость языков на основе анализа токенов (в условных единицах)", "\n", "(",
Style[If[OptionValue["clearTokens"], "с очищенными токенами",
"на основе всех токенов"], Bold], ")"}], 22,
FontFamily -> "Open Sans Light", TextAlignment -> Center],
Grid[fullTableData, Background -> White,
ItemStyle ->
Directive[FontSize -> 12, FontFamily -> "Open Sans Light"],
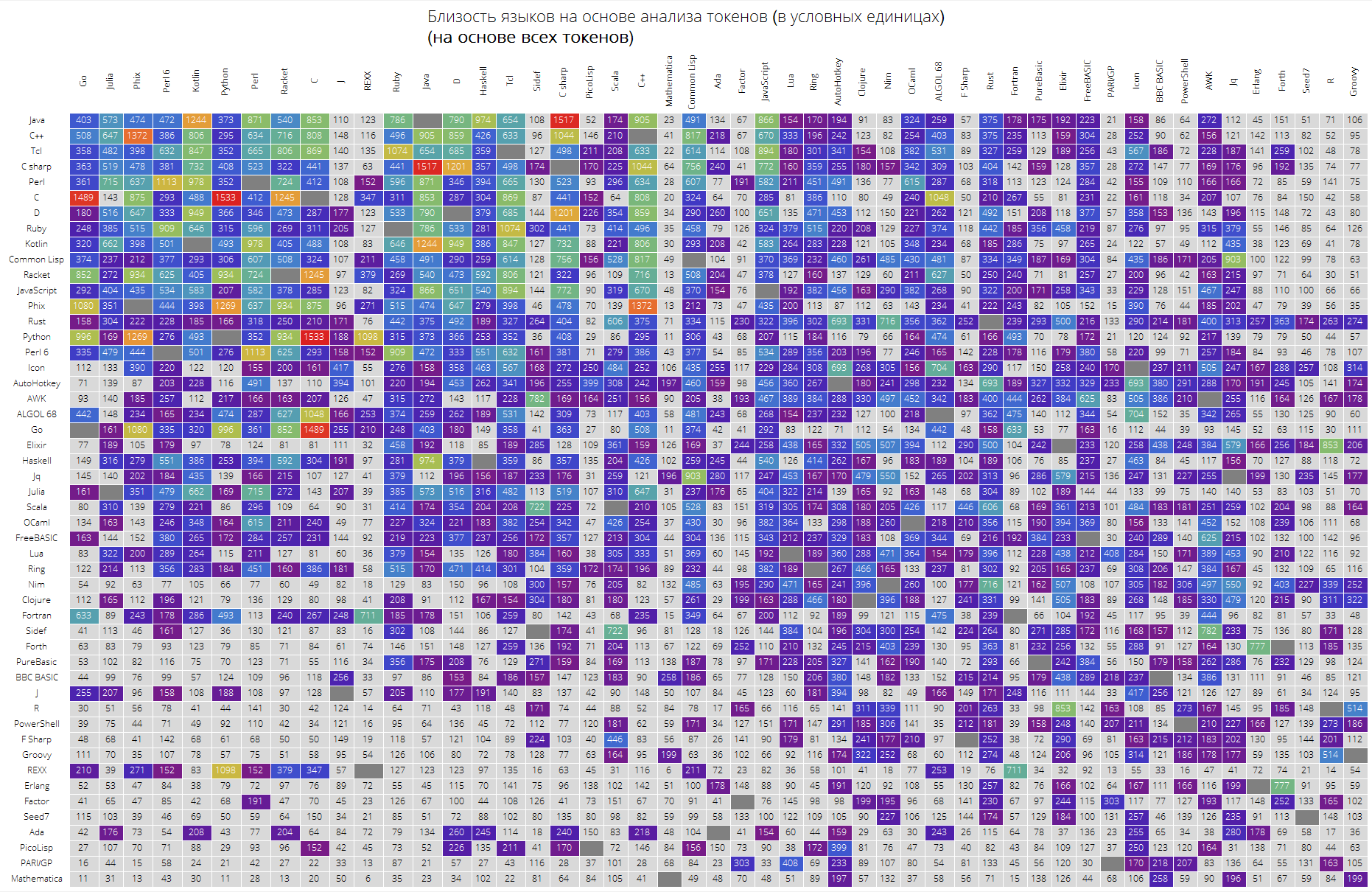
Dividers -> White]], FrameStyle -> None, Background -> White]];UPD: после ценного замечания assembled решил сделать две таблицы: с прочищенными токенами и со всеми токенами, без каких-бы то ни было очищений, чтобы как можно меньше влиять на результат. Итог слабо отличается, в чем вы можете убедиться сами, хотя некоторые зависимости стали четче.
Вот что мы получаем (неотсортированная таблица):
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> True]
langSimilarityGrid[30, "SortQ" -> False, "clearTokens" -> False]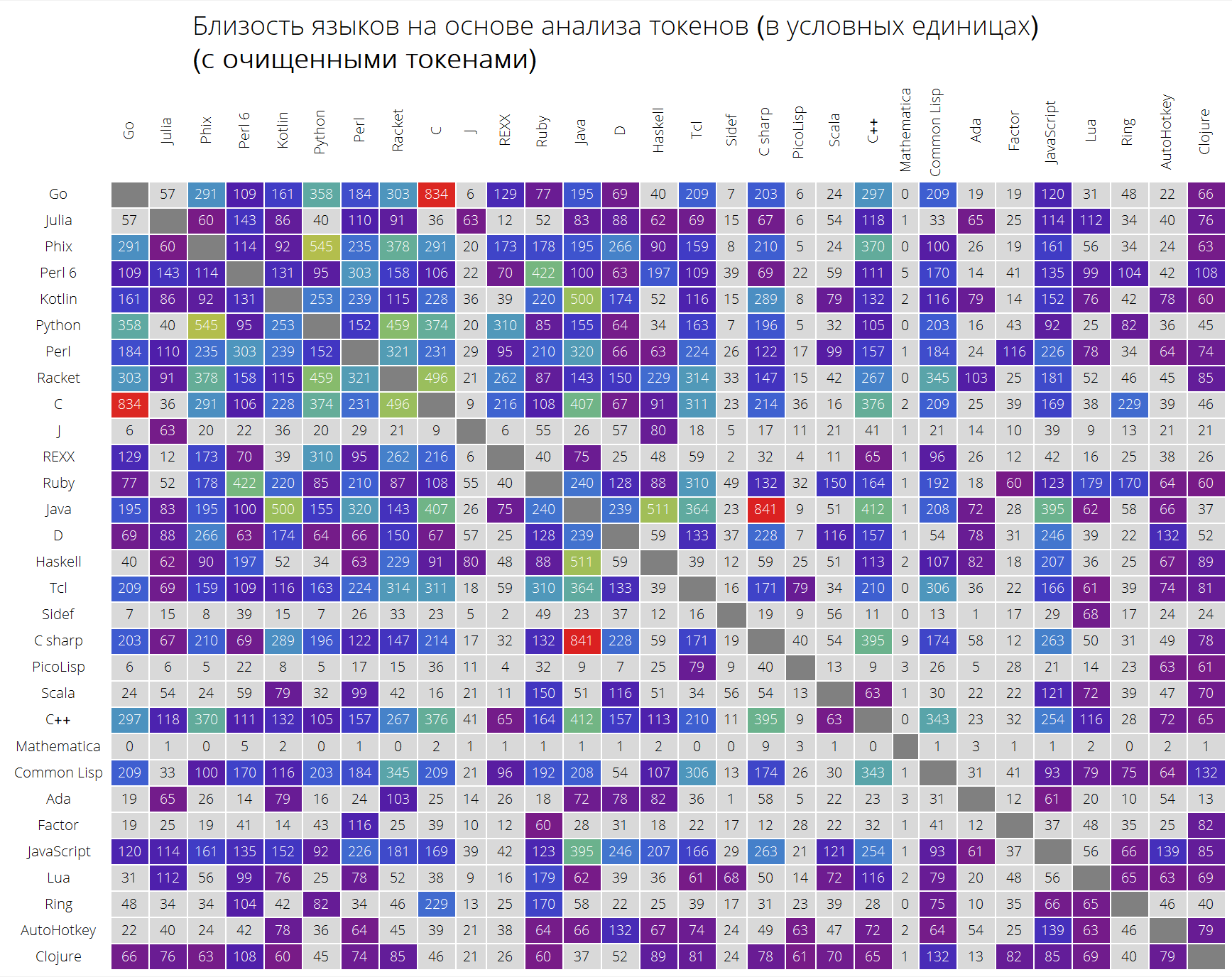

Отсортированная таблица (по среднему сходству с другими языками — чем выше строка, тем на большее число других языков программирования похож данный язык):
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> True]
langSimilarityGrid[30, "SortQ"->True, "clearTokens" -> False]

Наконец, большая таблица для первых 50 языков по популярности.
Вполне ожидаемо, что «ключевые» языки, вроде Java, С, С++, С# находятся в топе. Туда же затесался Racket (ранее — PLTScheme), одним из назначений которого является создание, разработка и реализация языков программирования.
Интересно, что Wolfram Language оказался по сути ни на что не похожим языком.
Также видны связи между языками, скажем очень хорошо видна связь между Java и C#, Go и C, С и Java, Haskell и Java, Kotlin и Java, Python и Phix, Python и Racket и другое.
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> True]
langSimilarityGrid[50, "SortQ"->True, "clearTokens" -> False]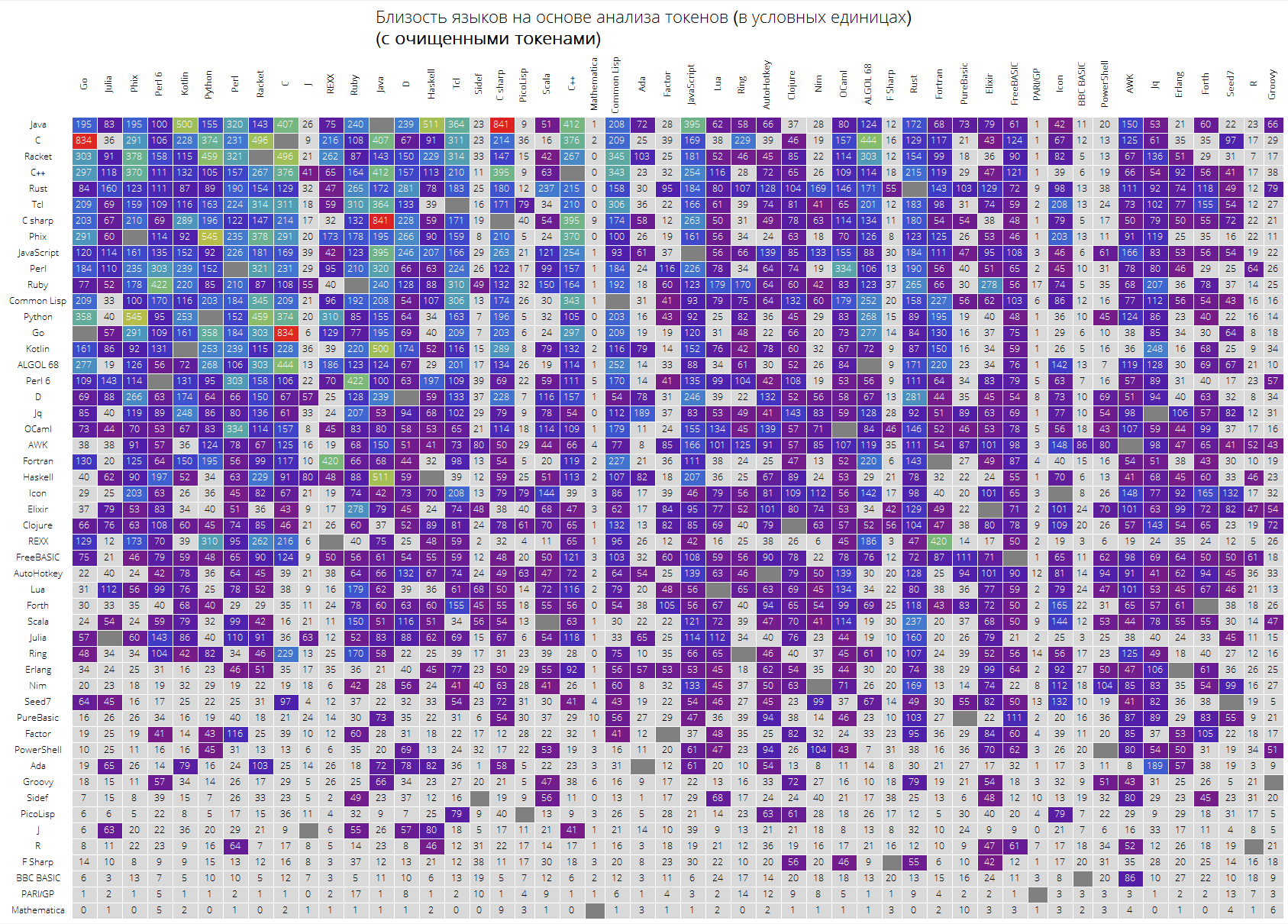
Надеюсь, что это исследование будет интересно для вас и вы сможете открыть для себя что-то новое. Для меня, как человека, постоянно использующего Wolfram Language было приятно узнать, что он получается самым «компактным» языком, с одной стороны, с другой стороны его объективная «непохожесть» на другие языки, очевидно, делает вхождение в него несколько сложнее.
Хотите научиться программировать на языке Wolfram Language?
Смотрите еженедельные вебинары.
Регистрация на новые курсы. Готовый онлайн курс.
Комментарии (19)

Mogwaika
15.10.2019 18:58Мне кажется или в упорядоченных графиках MatLab пропал?

OsipovRoman Автор
15.10.2019 19:15Он не самый популярный на RosettaCode, он примерно на месте так 65-м выходил, насколько помню. Многие графики построены для первых 30 языков, часть для 50-ти. Только несколько для 80-ти.
Mogwaika
15.10.2019 19:17А, точно, не заметил изменения масштаба при переходе от 80 к 50… Думал это та же самая, но упорядоченная картинка.


VaalKIA
16.10.2019 02:03Из статьи стало понятно, что Дельфи и Паскаль ни на что не похожи и, конечно, гораздо меньше распространенны, чем Ада, лисп, фортран, бейсик и т.п.
kt97679
16.10.2019 03:27У вас на диаграмме hsto.org/getpro/habr/post_images/e21/c34/479/e21c344793b75590f66279ee232f5b3f.png присутствует oforth, а на последующих диаграммах его нет. Вы его специально отфильтровали?
OsipovRoman Автор
16.10.2019 11:10Там просто было 50 языков, а на неотфильтрованной — 80.
Это, безусловно, путает. Поэтому исправил, теперь на этих диаграммах с усами везде по 80 языков.kt97679
16.10.2019 17:41Спасибо! Получается, что oforth один из самых выразительных языков.
OsipovRoman Автор
16.10.2019 18:10Да, получается так. Его синтаксис действительно интересен весьма:
: fact ( n -- n1 ) ?? | i | 1 n loop: i [ i * ] ;
{kind=link}

Refridgerator
17.10.2019 07:39Wolfram Language было приятно узнать, что он получается самым «компактным» языком, с одной стороны, с другой стороны его объективная «непохожесть» на другие языки, очевидно, делает вхождение в него несколько сложнее.
Мне кажется, тут проблема скорее не в сложности, а в «чистоте стиля», чтобы код, написанный одним человеком, легко читался другим. В вашем коде используются то подстановки, то функции, то чистые, то «грязные», и сложно сходу понять, является ли выбор конкретной семантики оптимальным или же у вас просто стиль такой.
Я, например, довольно активно использую постфиксную запись — пишу не
ListPlot[Log[Abs[Fourier[data]]]],
а
ListPlot[data//Fourier//Abs//Log],
чтобы минимизировать количество вложенных скобок и выделить первичное над вторичным.OsipovRoman Автор
17.10.2019 12:18Тут много вариантов, может и префиксный быть:
ListPlot@Log@Abs@Fourier@data
Правые и левые композиции
ListPlot@*Log@*Abs@*Fourier@*data
Fourier/*Abs/*Log/*ListPlot@data
Wolfram Language просто позволяет очень свободно писать код, это правда, отсюда и свой стиль, хотя часто определенные конструкции быстрее работают, что уже с опытом приходит. А другие конструкции проще реализовать.
assembled
Насчет токенов. Вы считаете неправильно и нечестно, многие языки имеют совершенно разное лексическое строение. Например:
OsipovRoman Автор
То о чем вы говорите имеет отношение только к близости языков.
Так-то токеном считается при подсчете любая конструкция, по сути, разделенная пробелом (или другим white-space знаком).
Да, стоит учесть, хотя каких-либо критических изменений не будет.
Спасибо за четкие указания, сделаю UPD позже. Я, безусловно, на 600 языках не программирую, поэтому знать особенности каждого не могу.
assembled
Тут и кроме пробелов остается довольно много символов:
Подсчет токенов работает неправильно даже в вашем языке. Например здесь:
ваш «токенизатор» насчитал 6 токенов. Это не токенизатор, он работает только как счетчик идентификаторов в Mathematica, и к другим языкам не применим.
P.S. Еще как оказалось во многих решениях на APL и J представлен не только код, а копия команд из REPL'а и их результат. Так, например, транспонирование матрицы на J плюс вывод созданной матрицы размером 5 строк, плюс результат транспонирования размером 4 строки, превращается в 11 строк, при том что реального кода здесь 2 строки.
OsipovRoman Автор
Вы видимо пот токеном понимаете что-то «особое» (или обязательно рабочий фрагмент кода). То, что в приведенном вами примере выдается 6 токенов — вполне разумно, их там именно столько.
В моей статье (по аналогии со статьей Джона) был принят подход с токенами для того, чтобы компенсировать длину названий функций и переменных, что явно верно учитывается в количестве символов кода (а то, в одном языке что-то вызывается как sin, а в другом как mathematicalsin, условно говоря, хотя по сути это одна единица).
Этот подход себя оправдывает, потому что две другие функции (количество символов и строк) дают те же результаты.
Можно также говорить о том, что в Wolfram Language есть полная форма выражения, тогда оно будет выглядеть как
и в нем будет 11 токенов.
Можно говорить о том, что еще более «глубоко», верным будет выражение в боксах:
которое опять же выдаст 11 токенов.
То, что здесь приведено в статье вполне разумно к применению. Я согласен, что корректировки стоит внести и я их, конечно, внесу для точности.
Вы всегда можете предложить свое решение или предложить правильную версию токенизатора, учитывающую все особенности всех языков — это в целом не плохой вариант был бы вашей дебютной статьи на Хабре.
OsipovRoman Автор
Обновил функцию. Теперь есть вариант, в котором отсутствует хоть какая-то очистка. Отрадно, что как я и думал, результат изменился несущественно.
naething
Можно добавить в список: лексический анализатор Питона выдает два специальных токена INDENT и DEDENT, которые обозначают увеличение и уменьшение уровня отступа, соответсвенно. Было бы логично их тоже считать за токены.