
При работе программных модулей, хранящих в оперативной памяти большое количество данных, способ их хранения оказывает сильное влияние на потребление памяти и быстродействие. Один из способов ускорения системы и экономии ресурсов может заключаться в использовании более примитивных структур данных – структур вместо классов и примитивных типов вместо структур. Конечно, такой подход ломает ООП и возвращает к использованию «старых» методов программирования. Однако, в некоторых случаях такая примитизация может решить множество проблем. Простой тест показал возможность сокращения потребляемой памяти более чем в три раза.
Затрагиваемые вопросы:
- Влияние программной архитектуры на потребление памяти и производительность;
- Различия при работе в 32 и 64 битных режимах;
- Различия между указателями и индексами массива;
- Влияние выравнивания данных внутри классов/структур;
- Влияние кеша процессора на производительность;
- Оценка стоимости поддержки ООП в языках высокого уровня;
- Признание факта необходимости учитывать низкоуровневые особенности платформы даже при разработке на языках высокого уровня.
Практическая задача
Впервые данную методику я применил при разработке поиска оптимального пути для портала www.GoMap.Az. Новый алгоритм использовал больше оперативной памяти и при установке на тестовый сервер приложение начинало серьезно заедать. Обновление железа в данном случае требовало нескольких дней, а ее решение оптимизацией структур данных позволило быстро решить проблему. Чтобы поделиться полученным опытом я решил в простой форме описать что было сделано и какие преимущества были получены.
Организация хранения большого количества структур данных и доступа к ним является неотъемлемой задачей для информационных систем работающих с картографическими данными. Подобные проблемы все чаще возникают также при создании других типов современных информационных систем.
Рассмотрим хранение данных и доступ к ним на примере дорог – рёбер графа. В упрощенном виде дорога может быть представлена классом Road, тогда как хранилище дорог классом RoadsContainer. Кроме того, имеется класс узла сети Node. Касательно Node – нам нужно просто знать что это — класс. Примем во внимание, что наши структуры данных не содержат методов и не участвуют в наследовании и т.п., то есть используются только для хранения и манипуляции с данными.
Мы будем рассматривать реальзацию метода на языке C#, хотя изначально она была применена на С++. Строго говоря проблема и ее решение находится несколько в области системного программирования. Однако, данное исследование также показывает насколько высокими могут быть затраты на поддержку ООП в высокоуровневом программировании. C# может лучшим способом показать эти скрытые затраты, не являясь языком системного программирования.
// Основная структура данных – класс Road
public class Road
{
public float Length;
public byte Lines ;
// Где-то описан класс Node и Road ссылается
// на два объекта этого класса
public Node NodeFrom;
public Node NodeTo;
// Другие члены класса
}
// Контейнер структур данных дорог
public class RoadsContainer
{
// Другие члены класса
// Выдача дорог, находящихся в указанном прямоугольнике
public Road[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Другие члены класса
}
Память и производительность
При оценке потребляемой памяти и производительности следует учесть влияние особенностей архитектуры платформы, включая:
- Выравнивание данных. Выравнивание данных производится для правильного и быстрого доступа центрального процессора к ячейкам памяти. В зависимости от разрядности системы расположение классов/структур в памяти может начинаться с адресов кратных 32 или 64 битам. Внутри самих классов/структур поля также могут выравниваться по границе 32, 16 или 8 бит (например, поле Lines класса Road может занять в памяти не 1 байт, а 4). При этом возникают неиспользуемые пространства памяти, что увеличивает ее потери.;
- Кеш процессора. Как известно задача кеша – ускорить доступ к наиболее часто используемым ячейкам памяти. Размер кеша очень мал, так как это самая дорогая память. При обработке классов/структур неиспользуемые пространства памяти, возникшие в результате выравнивания данных также попадают в кеш процессора и засоряют его, так как не несут полезной информации. Как результат – снижение эффективности кеширования.;
- Размер указателей. В 32-битных системах указатель на объект в памяти также обычно 32-битный, что ограничивает возможности работы с оперативной памятью более 4Гб. 64- разрядные системы позволяют адресовать существенно большие объемы памяти, но используют 64-битные указатели. Объекты всегда имеют указатели на них (в противном случае это будет потеряная память или объект для удаления сборщиком мусора). В нашем примере поля NodeFrom и NodeTo в классе Road будут занимать по 8 байт каждый в 64-битной системе и по 4 байта в 32-битной.
Обычно компиляторы стараются создать наиболее эффективный код, однако достичь существенной эффективности выполнения можно только программно-архитектурными решениями.
Массивы объектов

Данные могут храниться в различных контейнерах – списках, хеш таблицах, и т.п. Хранение в виде массива возможно самый простой и понятный способ, поэтому остановимся на рассмотрении этого способа. Другие контейнеры могут быть анализированы аналогично.
В C# массивы объектов в реальности хранят ссылки на объекты, в то время как каждый объект занимает свое отдельное адресное пространство в куче. В этом случае, очень удобно манипулировать наборами объектов, так как в действительности приходится работать с указателями, а не с объектами целиком. Например, в нашеи примере функция getRoads класса RoadsContainer передает набор определенных объектов класса Road – не копиями объектов, а ссылками. Такое поведение возникает ввиду того что объекты в C# — это ссылочные типы данных.
Недостатки хранения данных в виде массивов объектов – это прежде всего затраты на хранение самих указателей и выравнивание объектов в куче. В 64-разрядных системах каждый указатель забирает 8 байт памяти и каждый объект выравнивается по адресу кратному 8 байтам.
Массивы структур

Классы хранения дорог и узлов сети могут быть преобразованы в структуры (как было упомянуто в нашем примере на это нет ограничений со стороны ООП). Вместо указателей на них могут быть использованы целочисленные индексы. Код, который при этом получится может иметь вид:
public struct Road
{
public float Length;
byte Lines ;
Int32 NodeFrom;
Int32 NodeTo;
// Другие поля
}
public class RoadsContainer
{
// Другие члены класса
// Дороги будем хранить в массиве, а не в куче
Road[] Roads;
// Выдача дорог, находящихся в указанном прямоугольнике
public Int32[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Выдача дороги по индексу
public Road getRoad(Int32 Index)
{
return Roads[Index];
}
// Другие члены класса
}
// По аналогии с хранилищем дорог
// устроено хранилище узлов
public class NodesContainer
{
// Другие члены класса
Node []Nodes;
// Выдача узла по индексу
public Node getNode (Int32 Index)
{
return Nodes[Index];
}
// Другие члены класса
}
Что нам это дало? Рассмотрим подробно.
Структуры данных дорог хранятся уже как программные структуры ( structs в C# ), а не как объекты. Для их хранения использован массив Roads в классе RoadsContainer. Для доступа к отдельным структурам используется функция getRoad того же класса. 32-битный целочисленный индекс принимает на себя роль указателя на структуру данных определенной дороги. Таким же образом преобразованы узлы и представлен фрагмент класса-хранилища узлов NodesContainer.
Использование 32-разрядного индекса вместо 64-разрядного указателя облегчает как используемую им память так и операции манипулирования им. Использование индексов для ссылки на узлы NodeFrom и NodeTo в структуре Road сокращает размер потребляемой ею памяти на 8 байт ( при выравнивании в 32, 16, или 8 бит ).
Выделение памяти ( посредством вызова оператора new ) для хранения дорог происходит за один раз. При этом резервируется только массив структур Road в котором все структуры создаются за раз. В случае хранения ссылок на объекты каждый объект должен создаваться отдельно. На создание отдельного объекта не только уходит время, но также расходуется некоторый объем служебной памяти на выравнивание, регистрирование объекта в куче и системе сбора мусора.
Недостаток использования структур вместо объектов — это строго говоря невозможность использования указателей на структуру ( структура – это тип «по значению», а класс тип «по ссылке» ). Данный факт приводит к ограничению возможности манипулировать наборами объектов. Ввиду этого, функция getRoads класса RoadsContainer теперь возвращает индексы соответствющих структур в массиве. При этом получить саму структуру можно функцией getRoad. Однако, данная функция приведет к копированию возвращаемой структуры целиком, что приведет к расходу памяти и времени процессора.
Массивы данных примитивных типов

Массивы структур могут быть преобразованы в отдельные массивы полей этой структуры. Иными словами, структуры могут быть декапсулированы и упразднены. К примеру после декапсуляции и упразднения структуры Road мы получим следующий код:
public class RoadsContainer
{
// Другие члены класса
// Поля структуры данных Road
float[] Lengths;
byte[] Lines;
Int32[] NodesFrom;
Int32[] NodesTo;
// Другие члены класса
// Выдача дорог, находящихся в указанном прямоугольнике
public Int32[] getRoads(float X1, float Y1, float X1, float Y1)
{
// Реализация
}
// Выдача длины дороги по индексу
public float getRoadLengt(Int32 Index)
{
return Lengths[Index];
}
// Выдача количества полос дороги по индексу
public byte getRoadLines(Int32 Index)
{
return Lines[Index];
}
// Выдача начального узла дороги по индексу
public Int32 getRoadNodeFrom(Int32 Index)
{
return NodesFrom[Index];
}
// Выдача конечного узла дороги по индексу
public Int32 getRoadNodeTo(Int32 Index)
{
return NodesTo[Index];
}
// Другие члены класса
}
Что мы получили? Рассмотрим подробно.
Вместо хранения программных структур в одном массиве, поля этой структуры хранятся по отдельности в разных массивах. Доступ к полям также производится раздельно по индексу.
Пустой расход памяти на выравнивание полей внутри структуры устраняется, так как поля структуры примитивных типов хранятся вплотную друг к другу. Память запрашивается у системы не одним большим куском для хранения всех структур сразу, а несколькими кусками для хранения массивов полей соответственно. В некотором смысле такое разбиение полезно, так как системе часто легче предоставить несколько относительно небольших непрерывных участков памяти, чем один большой непрерывный участок.
Доступ к каждому полю каждый раз требует использование индекса, в то время как для доступа к струтуре целиком требуется использование индекса только один раз. В реальности данная особенность может рассматриваться и как недостаток и как преимущество. Дело в том, что при обращении только к части полей, например только трем полям Lengths, NodesFrom и NodesTo структуры Road в случае их расположения в отдельных массивах можно получить более оптимальное использование кеша процессора. Использование всех преимуществ кеша зависит от алгоритма доступа к данным, но в любом случае выигрыш может быть заметным.
Сборка мусора и управление памятью

Рассматриваемая проблема относится к технологиям управления памятью. Ведь именно от расположения объектов в памяти в первую очередь зависит скорость доступа к ним. В настоящее время имеется огромное количество способов организации управления памятью, включая системы автоматической сборки мусора. Эти автоматические системы не только следят за чисткой памяти, но и проводят дефрагментацию ( подобно файловой системе ).
Системы управления памяти в основном работают с указателями на объекты, расположенные в куче. В случае использования массивов структур или полей системы управления памяти не смогут работать с элементами этих массивов и вся работа по их созданию и уничтожению ляжет на плечи программиста. Таким образом, использование массивов структур или полей в определенном смысле деактивирует сборщика мусора для них. Это ограничение в зависимости от задачи может рассматриваться как преимущество (если требуется экономия ресурсов) или как недостаток (если требуется упрощение кола и труда программиста).
Замеры

Как видно наиболее расточительным для хранения является массив объектов. При этом на 64-битной системе издержки на хранение резко возрастают. Хранение в виде массивов структур или полей в целом одинаково затратно для 32 и 64-битного режима. Хранение в виде полей имеет некоторый выигрыш в размере занимаемой памяти, однако этот выигрыш не критический. Этот выигрыш включает издержки выравнивания данных внутри структур.
Память
Занимаемая память, 32 битный режим
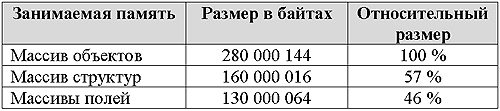
Занимаемая память, 64 битный режим

Как видно наиболее расточительным для хранения является массив объектов. При этом на 64-битной системе издержки на хранение резко возрастают. Хранение в виде массивов структур или полей в целом одинаково затратно для 32 и 64-битного режима. Хранение в виде полей имеет некоторый выигрыш в размере занимаемой памяти, однако этот выигрыш не критический. Этот выигрыш включает издержки выравнивания данных внутри структур.
Время доступа
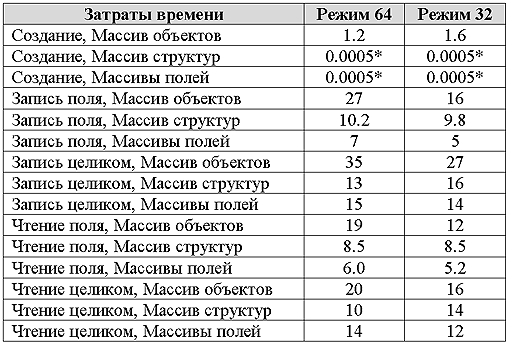
Примечания:
* — число слишком мало в сравнении с точностью теста.
Время доступа к структурам данных при хранении в массиве объектов показывает самые высокие затраты времени. Также наблюдается более быстрый доступ к полям в случае их расположения в отдельных массивах. Это ускорение является результатом более эффективного использования кеша процессора. Следует упомянуть что в тесте доступ осуществляется последовательным перебором элементов массива и в этом случае использование кеша близко к оптимальному.
Итоги
Этот небольшой обзор позволяет создать представление о проблеме и сделать первые выводы:
- Отказ от использования ООП в работе с большими объемами данных может привести к 3-х кратной экономии оперативной памяти на 64-битных системах и 2-х кратной экономии на 32-битных системах. Данная проблема возникает из-за особенностей аппаратной архитектуры, поэтому в той или иной степени она актуальна для всех языков программирования.
- Время доступа в С# к структурам данных посредством индекса массива существенно меньше времени доступа посредством указателя.
- Повышение уровня технологии программирования требует затрат ресурсов. Низкий уровень ( системный ) и работа с примитивными данными ( получаемыми после декапсуляции классов/структур ) использует меньше всего ресурсов, но требуют больше строк исходного кода и времени программиста.
- Переход к работе с примитивными типами является этапом оптимизации кода. Поэтому такая архитектура может быть использована не как начальный дизайн, а как меры в случае необходимости сокращать потребление ресурсов.
- В C++ многие описанные проблемы могут быть решены прозрачно, в то время как в C# многое скрыто в ниже-лежащей реализации. Помимо того при изучении C# влияние платформы рассматривается далеко не на первых порах.
- При разработке в C# там где это возможно, нужно использовать структуры, а не классы.
Ссылки:
Исходники тестов на GitHub
Пример успешного коммерческого использования методики — портал GoMap.Az
Разница между структурами и объектами (MSDN)
Хорошая статья о структурах «Mastering C# structs»
Статья на похожую проблематику «Храним 300 миллионов объектов в CLR процессе»
Комментарии (46)
gurinderu
03.08.2015 17:29+2Не совсем понял как это относится к c++. Насколько я помню struct и class в с++ занимают одинаковое количество памяти.

dgakh
03.08.2015 18:26В С++ также имеет место выравнивание в структурах и классах. Например если процессору легче взять из памяти за 1 раз 8 байт ( зависит от архитектуры ) то желательно сразу взять то, что нужно или пригодиться потом. Если класс или структура будут иметь нерелевантные данные ( потерянное место ввиду выравнивания или же соседнее ненужное вданное время поле ) или же выравнивание будет несоответствующее — у процессора уйдет больше времени на доступ к памяти. Плюс кеш. В итоге массивы простых данных работают быстрее. Хотя С++ намного более гибок и является системным языком программирования, даже выбор/создание аллокатора и хранилища требуют хорошего понимания платформы, т.е. кеша, режима доступа к памяти и т.п. Не задумываясь об этом иногда можно быстро израсходовать ресурсы системы.
gurinderu
03.08.2015 19:07+1Не совсем понял на что вы отвечаете? Естественно cpu возьмет из памяти сразу cache line. Естественно примитив занимает меньший объем памяти и с большой долей вероятности в кэш попадет больше значений. Только вот sizeof(struct)=sizeof(class). В c# совершенно все по другому скорее всего, т.к. class содержит кучу информации помимо данных.
dgakh
03.08.2015 19:44Внутри структур/классов поля выравниваются. Это приводит к появлению «пустот». Если поля хранить в отдельных массивах, выравнивание внутри массивов не производится. Суммарно массивы полей занимают меньше памяти чем один массив структур. Возможно эффект небольшой, ведь компилятор оптимизирует код, но при нехватке ресурсов и определенной ситуации может быть полезен.
Т.е. в статье 2 шага. 1 — от классов к структурам. Если в С++ дизайн правильный, тут эффекта может не быть или он будет небольшой 2-я часть — разбиение массива структур на массивы их полей. Тут можно немного выиграть и на С++.gurinderu
03.08.2015 20:10+1Вам поможет #pragma pack(push, 1)
dgakh
03.08.2015 20:26В выравнивании и экономии памяти поможет. Но скорость доступа будет меньше чем при разбиении на массивы полей. И если не ошибаюсь меньше и при доступе к полям структуры — ведь их выравнивают для оптимизации доступа.
gurinderu
04.08.2015 10:11+1За счет чего, простите?
dgakh
04.08.2015 10:19Железо. В общих словах — обращение к данным, не находящимся по кратным разрядности адресам требует дополнительных операций процессора.
gurinderu
04.08.2015 11:18+1А как вам поможет при этом массив?)
Не проще ли написать Struct в котором все поля будут идти в правильном порядке (без padding)?dgakh
04.08.2015 12:01Если в определенном месте алгоритма, например каком-то цикле нужна только часть полей структуры, а не она вся, массив тут оптимальнее. Но выигрыш тут правда небольшой — у меня на С++ в релизе с оптимизацией на скорость выигрыш составил порядка 0.6% по времени. Но разбиение конечно усложняет код и это серьезный аргумент в пользу структур. Дело случая.
А так, — я как-то стараюсь создавать структуры с полями в 32 байта — не сильно напрягает, но упаковка лучше.gurinderu
04.08.2015 13:41+1С чего это? Покажите методику вашего теста пожалуйста. И желательно опишите железо.
dgakh
04.08.2015 14:11Алгоритм Поиска Пути. Тест простой — разница во времени между началом и концом вычислений для одинаковых путей. Т.е. 0.6% — не только время доступа, но и другие внутренние операции. Цифра грязная, но соответствует только одному изменению — разбиению на массивы полей.
Железо — Intel i7, 4 Gb RAM. Но тестировал в режиме x86 ( 32 бита ). Тестировал много раз, так как долго отлаживал.
Не являются ли постоянные малые положительные показания доказательством хотя бы малого, но положительного эффекта? Может я зацикливаюсь и что-то не учел?gurinderu
04.08.2015 15:12+1Ну это не тест вовсе.
Давайте попробуем написать полноценный benchmark. Мне кажется там проблема, что у вас данные не влазили в cacheline. и скорее всего ваши 0.6 это просто погрешность)dgakh
04.08.2015 15:26Ок. Мне самому интересно. Пока я вижу только выигрыш, так как он полностью соответствует теории. Т.е. если я только лишь улучшаю структуру данных и после этого имею выигрыш при каждом запуске, это скорее всего наведёт на мысль о взаимосвязи, ведь погрешность бы скакала и отрицательные значения компенсировали бы время в случае если ничего не улучшилось.
Но все-же более интересен другой вопрос. Если дело идет о широком использовании, надо тестировать точнее, увереннее и на разных платформах. А то уверенность что тут я выиграл не дает гарантии что на другой платформе или алгоритме не будет проигрыша. Т.е. более понять вклад в цифру разных факторов.

maaGames
03.08.2015 19:52+1Если уж заговорили о выравнивании, то нужно сразу сказать и о порядке объявления данных-членов. Порой, можно существенно уменьшить размер структур, просто переупорядочив данные-члены. Если кратко, то наиболее компактным будет расположить данные от типов максимального размера к типам минимального, тогда будут минимальные затраты на выравнивание «пустыми» байтами.
dgakh
03.08.2015 20:17Откровенно говоря не хотел усложнять статью — больше текста и сам запутаюсь. Там по ссылкам есть на эту тему касательно C#. А программисты С++ более вероятно знают проблематику. Если в записи много полей различных типов — можно поиграться. А так — хотелось просто обратить внимание на влияние выравнивания.
Потом как ни крути — доступ в случае массивов полей более благожелатален для кеша чем через структуры. Пусть в С++ выигрыш небольшой, но он есть. Т.е. я как-то эти два преимущества ( отсутствие выравнивания и доступ к однотипным данным ) вместе рассматриваю.maaGames
03.08.2015 20:29+2Говорю только за С++.
Доступ к полям «благожелательнее», чем к элементам массива. Потому что адрес поля известен статически, а адрес элемента может потребоваться вычислять в рантайме (если компилятор не оптимизирует). Выравнивание всегда можно настроить, чтобы поля были так же плотно расположены, как и в массиве. С точки зрения кэша абсолютно без разницы, будет считанно 4 элемента массива или четыре переменные, расположенные друг за другом.
А вообще, если на C# или Java или других высокоуровневых языках начинают заниматься байтоёбством, то это означает лишь то, что язык для данной задачи был выбран неудачно, либо пришло время немного переписать часть программы на другом языке.dgakh
03.08.2015 20:47Тут вопрос доступа к структурам в массиве и к полям в массиве. Т.е. и там и там массив.
Откровенно говоря меня иногда С# бесит, особенно когда нужно байтокамасутрится :-) В особенности отсутствие битового представления числа… Тут уж как говорится если требуется так, то уже… Просто на вопрос — куда в C# деваются 73% памяти на 64 битной системе без заглядывания вовнутрь не обойтись.
Но история началась с части кода на С++, после изменения которого возникла нехватка памяти. Вот и пошло по цепочке. Отоптимизировал код на С++ по полной ( даже кажется это уже чистый С получился ). Потом залез в C# глазами С++ — ника. И напоролся на такое обжорство…
Viacheslav01
04.08.2015 16:19Опять же если сразу читать последовательно по одному значению из каждого массива, а не из одного объекта, не факт, что кеш будет использоваться более эффективно.
dgakh
04.08.2015 16:48Да, думаю не всегда. Но и не редко. Думаю вопрос требует систематизации. Чтобы уже точно знать от чего чего ожидать. У меня пока на руках теория + один узкий показательный пример.

EvilBeaver
03.08.2015 18:57+1Вроде бы и интересно и полезно, но выводы и советы какие-то в стиле Капитана.
dgakh
03.08.2015 19:08Признаюсь столько всего в голове крутилось — книгу хотелось написать :-) Подумаю еще над этой частью текста, постараюсь систематизировать :-)

kekekeks
03.08.2015 20:43+1Эцсамое. Тут не так давно NFX-овский Heap рекламировали. Да и комментариях предложена ещё пара вариантов. Есть мнение, что вполне применимо к вашему случаю, притом позволяет не так сильно издеваться над структурами данных.
dgakh
03.08.2015 21:01Да, читал. У меня в ссылках есть. И в комментариях много интересного. Тут как говорится по задаче надо лучший метод выбирать.
Viacheslav01
04.08.2015 11:41+2При разработке где это возможно нужно использовать структуры, а не классы.
Надо убрать слово возможно, потому, что возможно почти везде, а вот нужно не везде!
Просто передайте ваш массив на обработку в метод и посмотрите на результат.dgakh
04.08.2015 12:40Я немного подкорректировал статью. В С++ данный аргумент как-то не смотрится практичным. С другой стороны при его написании я подразумевал C#. Теперь ошибку исправил: «При разработке в C# там где это возможно, нужно использовать структуры, а не классы».

kashey
04.08.2015 16:47В замене обьектов на массивы простых данных зарылась еще одна собака — векторизация и более адресный доступ к памяти.
dgakh
04.08.2015 16:57Про векторизацию помнил, но уже капнуть глубже просто не успел. Тут тоже как понимаю возникают варианты и в каждом случае мы можем получить тот или иной эффект. Но для более простых процессоров эффект от замены должен быть ощутимей.
gurinderu
04.08.2015 23:05Я сейчас честно в ступоре. Векторизация вроде бы делается для однотипных операции, причем независимых. С трудом могу представить ситуацию, когда вам нужно ко всем полям добавить 1) Ну и собственно сборка векторов не бесплатна, не всегда это дает прирост производительности.

Temp1ar
05.08.2015 14:03Дело в том, что при обращении только к части полей, например только трем полям Lengths, NodesFrom и NodesTo структуры Road в случае их расположения в отдельных массивах можно получить более оптимальное использование кеша процессора. Использование всех преимуществ кеша зависит от алгоритма доступа к данным, но в любом случае выигрыш может быть заметным.
Не понял про преимущество третьего варианта, если у вас три разных массива аллоцированы в произвольных регионах памяти, как вы получите преимущество при чтении из кеша процессора? Кеш-лайн L1, L2 — допустим 64, 128 байт, общий размер несколько мегабайт максимум. Чтение из одного кешлайна даст вам преимущество как раз при использовании массива Road, где поля одной дороги лежат друг за другом, а не разнесены по памяти.dgakh
05.08.2015 14:21В примере структура короткая. Если алгоритм оперирует только частью полей (на оопределенном участке), разделение дает преимущество в особенности для длинных структур и при доступе, где вероятность работы с соседними значениями велика. Например даже если рандомно обращаться только к одному или нескольким полям при их разносе в массивы вероятность обращения к физически соседним полезным данным выше (я не имею в виду расстояние, но то, позволит ли оно например вместиться в кеш). Различия могут быть как заметными так их может и не быть — зависит от алгоритма.
В Вашем случае будет явное преимущество при не-разбиении если нужна вся структура целиком и поля в ней «хорошо» выровнены.

PsyHaSTe
06.08.2015 13:50+1Расходы на использование структур в C# нулевые, особенно если правильно ими пользоваться. Пишем небольшой атрибут:
[StructLayout(LayoutKind.Sequential, Pack = 1)] public struct RoadPacked ...
И вуаля:

Хотя доступ по выровненным данным все равно лучше, чем экономия 3 байт. Ну а случае особой битовой магии всегда есть LayoutKind.Explicit с ручным расставлением необходимых смещений. Энивей, всегда можно добиться необходимой оптимизации не вводя кучу магических констант и несвязанных между собой явно массивов.dgakh
06.08.2015 14:06Расходы памяти в этом случае — нулевые. А вот расход времени доступа увеличивается. Вопрос возникает когда чего-то начинает резко не хватать. Вот тогда и решаем чем жертвовать. Если же место есть и процессор не перегружается — можно и не думать об оптимизации.
PsyHaSTe
06.08.2015 14:14+1Единственный кейз, когда у нас массив структур, а мы постоянно из 1000 полей берем 1-2. Только это уже проблемы архитектуры, что ненужные поля засунули куда попало.
dgakh
06.08.2015 16:16Да — 1000 полей — явный кейс. Или когда полей штук 20, берем 2,, а в массиве несколько десятков миллионов записей, Плюс вероятность доступа к соседним элементам высока.
PsyHaSTe
06.08.2015 16:37Значит неправильно сделана структура, в которой 20 полей. Структура упаковывает единый неделимый набор данных. Если мы начинаем работать кусками структуры, то мы неправильно изначально объединили данные. Недаром в том же шарпе best practice обязывает структуры быть неизменяемыми.
Да — 1000 полей — явный кейс
Есть такая стилистическая фигура — гипербола…dgakh
06.08.2015 17:00Тут и кроется неудобство. Лучший дизайн может требовать рассмотрение структуры включая все поля, как одно целое. Алгоритм же в одной части может использовать 2-3 поля, в другой части другие поля. Выделить эти 2-3 поля в отделбную структуру а остальные в другую? Т.о. получим промежуточный вариант. Если так идти далее -придем к делению на примитивные данные. Деление — это уже не дизайн, а оптимизация.
Т.е. два конца палки — что упрощает работу программиста — усложняет работу железа. Лучшая практика — это для большинства случаев. Ведь си-шарп не системный язык и действительно надо делать структуры неизменяемыми. Это когда начинаешь. А деление на примитивы — частный случай оптимизации когда переписывать на С++ трудоемко, менять железо — ресурсоемко. Оптимизация, это когда логически уже работает и надо не создать, а улучшить для лучшего переваривания железом.PsyHaSTe
06.08.2015 17:16+1Т.е. два конца палки — что упрощает работу программиста — усложняет работу железа.
Известное утверждение, не переставшее от этого быть ложным. За примерами ходить не надо — посмотрите на Rust, который изначально был сделан, чтобы достичь и того, и другого. Скорее нужно сказать «ускорение работы без длительного предварительного размышления над проблемой приводит в говнокоду». Тут уж я соглашусь, сколько обычно пилятся всякие ЯП — раз-два и готово, и сколько пилился раст, сколько раз пересматривалась архитектура и т.п. То есть чтобы сделать и быстро, и красиво, нужно сначала очень напряженно подумать. А обычно заморачиваться не приходится — зачем, если мы все красиво спрячем за фасадом абстракций, а во внутренности никому лезть не надо. Потом оказывается, что надо, но это уже обычно не проблема тех, кто писал, и они забивают.
Что шарп — не системный язык, я согласен, однако не согласен с тем, что на шарпе нельзя писать быстрые и эффективные приложения. Вот, Андрей DreamWalker выступал на конференкции этой весной, вдохнул в эту мою мысль новую жизнь. И вполне убедительно смог её аргументировать.dgakh
06.08.2015 19:18+1Мне так повезло, что на C# приходится решать многие задачи, для решения которых лучше бы подошел С++. Что мне очень нравится, что в C# уровень можно выбирать в широких пределах. Если надо заоптимизировать — можно глубоко залезть, даже до unsafe. А если надо еще глубже — пожалуйста, можно часть кода написать на нативном С++ и подключить как unmanaged DLL.
Касательно Rust — очень интересный подход в его развитии.То есть чтобы сделать и быстро, и красиво, нужно сначала очень напряженно подумать
. — уже тут зарыто много труда (чтобы упростить работу железа).
Кстати и на С++ так можно написать, что медленнее старого бейсика пойдет. Если не ошибаюсь даже просто с new/delete код на С++ можно сделать в разы медленнее чем на C#. И говнистость кода — вещь относительная. Иногда код — как бомж некрасивый, но свое дело делает четко (конечно лучше его привести и к хорошему виду). Эти вопросы наверное надо рассматривать с позиций менеджмента и дизайна.
За инфу о лекциях Андрея спасибо. Смотрю как раз запись. Тематика интересная.PsyHaSTe
06.08.2015 20:25+1. — уже тут зарыто много труда (чтобы упростить работу железа).
О чем и речь:)
Кстати и на С++ так можно написать, что медленнее старого бейсика пойдет. Если не ошибаюсь даже просто с new/delete код на С++ можно сделать в разы медленнее чем на C#.
Строго говоря, new в шарпе и так быстрее ибо это просто инкремент указателя на размер объекта, а не поиск свободного блока. Ибо на GC возлагается задача иметь всегда последовательный набор возрастающих свободных адресов. Так что что объект создать, что локальную структуру — требуется одно и то же мизерное количество операций. Вот delete да, будет быстрее, чем просмотр кучи и её переупорядочивание.
За инфу о лекциях Андрея спасибо. Смотрю как раз запись. Тематика интересная.
Всегда пожалуйста :)
maaGames
Ну и при чём тут С++? К С++ данная оптимизация не применима хотя бы в силу того, что между классом и структурой нет никакой разницы (private/public проигнорируем).
Если уж размер указателя имеет столь большой вклад в размер объекта, то эффективнее использовать собственный аллокатор и вместо указателя на объект хранить индекс этого объекта в собственном диспетчере памяти (будет 4 байта, независимо от архитектуры. Или два байта или три или полтора).
dgakh
Действительно в C++ многие проблемы решаются прозрачно. Поэтому я описал C# — там многие тонкости скрыты. В С++ на практике в Поиске Пути только лишь использование массивов простых типов вместо массивов структур дало выигрыш в скорости на 0.6%. Это крохи. Но в основном я произвел это разделение для того, резервировать в памяти не 1 большой блок для 1 массива, а несколько более мелких. Слишком уж проблема с нехваткой памяти за горло взяла. Возможно это — специфический случай, но, думаю интересный.
FoxCanFly
В таком случае в определенных кейсах вы наборот замедлили, например, последовательный доступ (в C++ варианте). Не стоит оно того. Если уж хочется не один большой кусок памяти, а несколько поменьше — есть std::deque
dgakh
Согласен — многое зависит от кейса. И если ресурсов много — труд программиста всегда ценнее. Возможно при нехватке ресурсов для определенного программно-аппаратного комплекса (например мобильное решение) следует обращать внимание на время доступа к памяти в тактах, попадание в кеш и т.п. Одна из конструкций, которую я использовал — специализированная хеш таблица. Там размерами и количеством блоков памяти можно управлять. При разбиении структуры мы действительно получаем фиксированное число и не можем просто упралять количеством и размерами выделяемях блоков памяти. Все действительно зависит от задачи и ситуации.