
Если рассматривать сегодняшние алгоритмы машинного обучения с движением от невежества (низ) к осознанию (верх) то текущие алгоритмы похожи на прыжок. После прыжка происходит замедление скорости развития (обучающая способность) и неминуемый разворот и падение (переобучение). Все усилия сводятся к попыткам приложить как можно больше сил к прыжку, что увеличивает высоту прыжка но кардинально не меняет результатов. Прокачивая прыжки мы увеличиваем высоту, но не учимся летать. Для освоения техники «контролируемого полета» потребуется переосмыслить некоторые базовые принципы.
В нейронных сетях используется статическая структура которая не позволяет выйти за рамки установленной обучающей способности всей конструкции. Зафиксировав размеры сети из фиксированного количества нейронов мы ограничиваем размер обучающей способности сети которую сеть никогда не сможет обойти. Установка за ведома большего количества нейронов при создании сети позволяет увеличить обучающую способность, но замедлит время обучения. Динамическое изменение структуры сети во время обучения и использование двоичных данных наделит сеть уникальными свойствами и позволит обойти указанные ограничения.
1. Динамическая структура сети
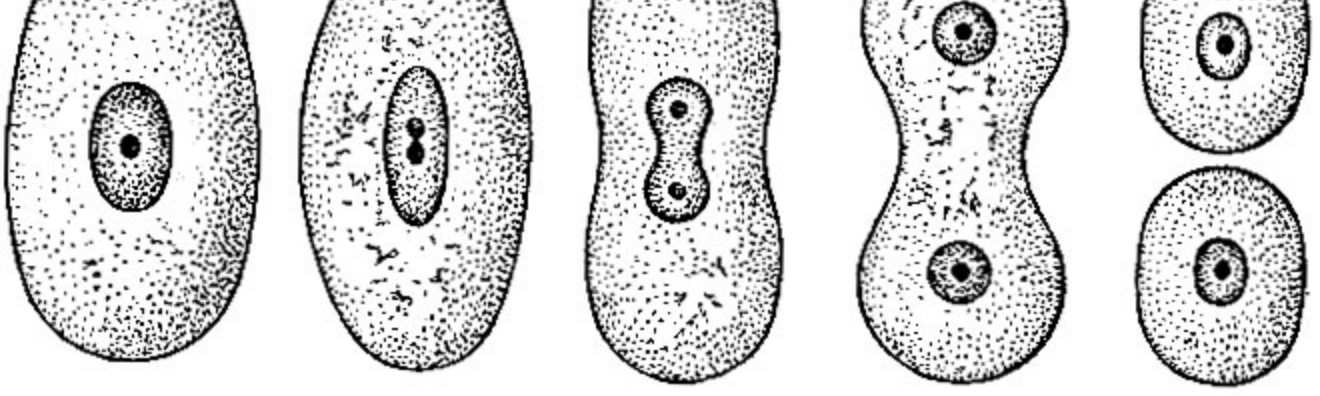
Сеть самостоятельно должна принимать решения о своих размерах. По мере необходимости расти в нужном направлении увеличивая свои размеры. Один нейрон, слой или два при создании сети мы не можем однозначно знать необходимой обучающей способности сети а следовательно и ее размеры. Наша сеть должна начинаться с нуля (полного отсутствия структуры) и должна получить возможность расширяться в нужную сторону самостоятельно при поступления новых обучающих данных.
2. Затухание сигнала
Нейронные сети занимаясь суммированием сигнала используют «аналоговый» подход к расчету. Многократные преобразования приводят к затуханию сигнала и его потере при передаче. На больших размерах сети «аналоговые» методы расчета будет неминуемо приводить к потерям. В нейронных сетях проблему затухания сигнала могут решать рекуррентные сети, по сути являясь костылем лишь уменьшая проблему, не решая ее полностью. Решением будем использование двоичного сигнала. Количество преобразований такого сигнала не приводит к его затуханию и потере при преобразованиях.
3. Обучающая способность сети

Расширяя структуру по мере обучения мы увеличиваем и ее обучающую способность. Сеть сама определяет исходя из задачи в каком направлении развиваться и какое количество нейронов необходимо для решения поставленной задачи. Размер сети ограничивает только вычислительная способность серверов и ограничения размеров жесткого диска.
4. Обучение сети
При изменении сигналов с аналоговых на двоичные сети получает возможность ускоренного обучения. Обучение дает однозначную установку сигнала на выходе. Сам процесс обучения изменяет лишь малую часть нейронов, оставляя значительную их часть без изменений. Время на обучение сокращается многократно ограничиваясь изменениям нескольких элементов сети.
5. Расчет сети

Для расчета нейронной сети нам необходимо расчитать все элементы. Пропуск расчета даже части нейронов может привести к эффекту бабочки где малозначительный сигнал может поменять результат всего расчета. Природа двоичных сигналов другая. На каждом из этапов можно без последствий исключить часть данных из расчета. Чем больше такая сеть, тем большее количество элементов мы можем игнорировать в расчетах. Расчеты результатов сетей сводится к расчету небольшого количества элементов вплоть до долей процента от сети. Для расчета достаточно 3.2% (32 нейрона) при сети в тысячу нейронов, 0.1% (1 тыс) при миллионе «нейронов» в сети и 0.003% (32 тыс) при сети размером в миллиард «нейронов». С увеличением размеров сети процент обязательных для расчета нейронов уменьшается.
6. Интерпретация результатов
В нейронных сетях веса помноженные на коэффициенты не дают возможности установить источник сигнала. Все входящие сигналы нейронной сети без исключения оказывают влияние на результат, усложняя понимание причин приведших к его формированию. Влияние двоичных сигналов на результат может быть нулевым, частичным или полным, что однозначно говорит об участии исходных данных в расчете. Двоичные методы расчета сигналов позволяют отследить связь входящих данных с результатом и определить степень влияния исходных данных на формирование результата.
Все вышесказанное говорит о необходимости изменения подходов к алгоритмам машинного обучения. Классические методы не дают полного контроля сети и однозначного понимания происходящих в ней процессов. Для достижения «контролируемого полета» требуется обеспечить надежность преобразования сигналов внутри сети и динамическое формирования структуры «на лету».
Комментарии (83)

toyban
08.11.2019 05:50Так я так и не понял, а где же, собственно, сам "двоичный алгоритм"?
Сеть самостоятельно должна принимать решения о своих размерах. По мере необходимости расти в нужном направлении увеличивая свои размеры.
Я так понимаю, Вы плохо разбираетесь в нейронных сетях. Если позволить сети самостоятельно расти, то она и дорастет до размера, когда количества весов будет достаточно, чтоб просто "запомнить" все обучающие примеры.

mpakep Автор
08.11.2019 06:33-1Я не утверждал что являюсь специалистом в «нейронных сетях» просто на их основе показал несколько фатальных недостатков которые бросаются в глаза даже не специалистам.

roryorangepants
08.11.2019 09:50Вы показали несколько «фатальных» недостатков, которые вы «видите» именно из-за того, что вы не специалист, простите за прямоту.
mpakep Автор
08.11.2019 10:15Позвольте спросить Вы много разработали алгоритмов машинного обучения?
roryorangepants
08.11.2019 11:28Формулировка «разрабатывать алгоритмы машинного обучения» мне не очень понятна. Но мы, вроде, про вашу статью говорили? Вы утверждаете, что высветили ряд «фатальных недостатков» нейросетей. Разумеется, в статье я их не вижу. Я вижу только размытые утверждения, основанные на биологических аналогиях (кстати, не особо актуальных для современного deep learning), и такие же голословные (потому что не приведены никакие эксперименты на реальных данных) утверждения про ваш подход, который этими «фатальными недостатками» вроде как обделен.
mpakep Автор
08.11.2019 12:04Ситуация в которой алгоритм перестает обучаться а потом и совсем ломается по вашему не выглядет недостатком? Из за переобучения и из за ряда других фатальных недостатков нейронные сети нельзя обучать в потоковых задачах. Надеюсь вы это их преимущества и не станете называть?

Arech
08.11.2019 15:40> Из за переобучения и из за ряда других фатальных недостатков нейронные сети нельзя обучать в потоковых задачах.
Щто? Что вы называете «потоковыми задачами»?

buriy
10.11.2019 11:551) «алгоритм» — не обучается, обучается модель (с помощью алгоритма).
2) при правильно выбранном Learning Rate нейросеть (модель) не «ломается» по мере обучения.
3) Не увидел в вашей статье и комментариях никаких «фатальных» недостатков, да и вообще недостатков. Сплошная вода без малейшей конкретики.
Предлагаю вам решить хоть одну задачу с помощью нейронных сетей, потом уже критиковать, указывая на конкретные проблемы конкретной сети.mpakep Автор
10.11.2019 15:42-1Вот об этом и речь. Что все работает только при «правильно выбранном Learning Rate». Весь разговор о различиях. Есть ситуация чтобы не сломаться нужно очень хорошо подбирать параметры и постоянно следить чтобы небыло недообучения и переобучения. И о том, что не может сломаться в принципе. Вот вам 37 причин а не две почему нейросеть не работает — habr.com/ru/post/334944 Но у большей части сейчас стадия отрицания, пока не хотят или не могут принять что что-то пошло не так. Когда поймут начнут задумываться над тем как это можно исправить. Вот тогда то и начнется полноценный разговор.
— Чуваки, вы делаете это не правильно.
— Мы всегда все делаем правильно!
— Вот эту штуку можно было бы улучшить.
— Мы всегда все делаем правильно!buriy
10.11.2019 18:37+1Мне можете не пересказывать чужие посты, я в курсе, я курс по нейросетям веду.
Тем не менее, даже с этими ограничениями и «невообразимыми» сложностями (а где их нет!) нейросети позволяют хорошо решать многие практические задачи, зачастую, значительно лучше других методов. Так что смысл вашей критики по-прежнему от меня ускользает, и весьма напоминает рассказ про хакера и солонку.
Ладно бы вы говорили, что нейросети что-то не могут делать, но вы по сути лишь рассказываете, что вы не умеете нейросети настраивать, чтобы они нормально работали. Да на здоровье, не настраивайте — у меня больше заказчиков будет.mpakep Автор
11.11.2019 18:33То, что вы умеете хорошо настраивать НС это очень хорошо. Но представьте если этого даже не требуется делать. Опять же картинку видели где специалисты катят повозку на квадратных колесах? Они отлично научились ее «таскать» вопреки всем законам физики и превзошли всех на этом поприще. Смысла что-то менять не видят. Их сложно убедить в том, что они заблуждаются. Уверен, что у вас работы в ближайшее время будет много. Но на далекую перспективу я бы не стал загадывал. Мир слишком быстро меняется, чтобы быть настолько самоуверенным. И каждый новый этап оставлял за бортом куча специалистов в своих областях, отличных специалистов по тасканию тачек с квадратными колесами.
habrastorage.org/webt/ma/eo/am/maeoamm7d-cgnya6lf4nsubljbg.pngburiy
11.11.2019 18:50+1Уверен, что вы не представляете, сколько тысяч научных исследований по нейросетям проводится каждый месяц. Результат наиболее успешных из них — научные работы. В этих научных работах каждый первый пытается что-то менять, чтобы нейросети работали лучше.
В том числе, работ по бинаризации нейросетей — десятки и сотни каждый месяц. По спайковым нейросетям — даже ещё больше работ.
Но, увы, анализируя средний и топовый уровень этих работ и скорость прогресса, а также принимая во внимание уровень знаний, которые демонстрируют эти учёные и сравнивая его с вашим, я скорее поверю в то, что вы искренне заблуждаетесь в возможностях собственных изобретений, нежели в то, что вы сделали что-то намного лучше них. Поэтому вам и предлагается метод экспериментальной проверки ваших результатов, ведь без него всем скорее кажется, что вы очередной шарлатан, который предлагает товары из «магазина на диване», безапелляционно и уверенно увещевающий, что без этой квадратной сковородки, которая сама равномерно распределяет по ней блинчики во время приготовления еды, мы не сможем жить. И приводит в подтверждение эту картинку с квадратными колёсами, а вовсе не формулы, из которых следует, насколько улучшится жизнь обладателя этой сковородки — сколько часов и денег он сэкономит на этой покупке. Вместо того, чтобы давить нас логикой, вы давите на эмоции. Задумайтесь, почему вы так поступаете?mpakep Автор
11.11.2019 19:21Как раз это и удивляет. Почему она за пятьдесят лет кроме перделок и свистелок ничего более существенного не может сделать. Вам не кажется, что в этом есть какой то сокральный смысл. Если мы мятьдесят лет делаем одно и тоже но ничего не происходит, то нужно менять свои подходы а не продолжать всех убеждать что все просто «не умеют их готовить». Ну если круглые колеса которые ну нужно учиться двадцать лет настраивать по вашему что-то ненужное то я сдаюсь. Я вам сейчас говорю об алгориме который не нужно настраивать. Все работает из коробки. В нем потолка за которым он перестает работать а «просто работает дальше» какой бы большой файл с обучающими данными у вас не был. Научившись передвигать не катаемые колеса можно хоть на лыжах все перетащить летом но на круглых колесах удобнее. Предлагаю выбрать алгоритм и обучить. Пусть победит сильнейший.
roryorangepants
11.11.2019 19:24Как раз это и удивляет. Почему она за пятьдесят лет кроме перделок и свистелок ничего более существенного не может сделать.
На случай, если вы не заметили мой комментарий ниже, а не специально проигнорировали, повторюсь: современные computer vision, NLP, speech recognition и т.д. работают чуть менее, чем полностью на нейросетях.
Предлагаю выбрать алгоритм и обучить. Пусть победит сильнейший.
Разве это не то, что мы вам как раз предлагаем, советуя пойти со своим алгоритмом на кагл?mpakep Автор
11.11.2019 19:31Идти куда то без единого шанса победить? Просто в правилах написано, что я победить не смогу. Чет не торкает меня от таких перспектив. Ну реально как то это ненормально. Есть отечественные соревнования. Думаю в них поучаствовать, но опять же внимательно прочитав правила.
roryorangepants
11.11.2019 19:40В правилах не написано, что вы не можете победить. В правилах написано, что победитель должен открыть свой код организаторам.
Но как я уже сказал, вам это не грозит (как минимум, в ближайшее время).
Впрочем, не понимаю, что вам мешает открыть код? Ну или даже, подумаешь, победите, откажетесь открывать код, и вас дисквалифицируют с лидерборда. Зато всем докажете, что ваши алгоритмы работают.mpakep Автор
11.11.2019 19:46Об этом и речь. Я не могу открыть код следовательно по правилам я не могу победить. Смысл участвовать в соревнованиях в которых не можешь победить? Думаете будет хорошо звучать «Меня дисквалифицировали на кагле»?
roryorangepants
11.11.2019 19:50Об этом и речь. Я не могу открыть код следовательно по правилам я не могу победить.
Я же прямо спросил: что вам мешает открыть алгоритм?
Думаете будет хорошо звучать «Меня дисквалифицировали на кагле»?
Думаю, все ваши последние комментарии звучат, как отмазка, потому что вы понимаете, что на реальной задаче ничего у вас не работает.
А жаль, я даже надеялся, что вы сами не осознаёте проблемы, и, может, удастся вам действительно помочь.
buriy
12.11.2019 11:27Ещё раз: шанс победить у вас есть, никто юридически не обязывает вас открывать алгоритм после победы.
Читайте условия внимательно.roryorangepants
12.11.2019 11:32Ещё раз: шанс победить у вас есть, никто юридически не обязывает вас открывать алгоритм после победы.
Ну вообще это зависит от конкурса. В большинстве случаев победитель должен предоставить код организаторам под permissive лицензией, если не хочет быть удаленным с лидерборда.
Впрочем, во многих конкурсах это несет в себе только цель отсеять читеров (которые использовали прямо запрещенные лики, ручную разметку и так далее).buriy
12.11.2019 11:36Именно: всегда после победы, при нежелании участника показывать код, можно сказать организаторам, чтобы удалили результат с лидерборда. Юридическое обязательство раскрыть код после победы не возникает, есть лишь постмодерация победителей без исходных кодов.
buriy
12.11.2019 11:20Нет, за счёт этих миллионов попыток в год, есть рост качества на почти всех задачах, и, если усреднить, то где-то порядка 5-10% уменьшения ошибки в год. Поэтому некоторые задачи, которые 50 лет назад или 10 лет назад были не решены, теперь находятся в статусе «решённых» — качества достаточно на практике. Другие же ещё в «нерешённых», но это нормально.
Это не ноль, но и не «решим все задачи влёт».
>Я вам сейчас говорю об алгориме который не нужно настраивать. Все работает из коробки. В
Во-первых, всегда нужно учитывать время работы и затраты ресурсов. Никого не интересует алгоритм, который нельзя потом никак применить. Всегда есть какие-то практические ограничения, например, распознавание речи или видео не может нормально работать на мобильном телефоне из-за слабых процессоров и быстрого жора батарейки. А какие-то задачи — на компьютере без ускоряющей вычисления видюшки, или без кластера на N машин в облаке (как Альфа-Го Старкрафт 2).
Во-вторых, я уверен, что оно у вас так хорошо «работает» лишь на трейн-сете, а не на валидационном сете. Таких фальстартов я как преподаватель видел сколько угодно.
Так что проверьте всё как следует, а потом уже пишите, что нашли на поверхности то, что другие ископали уже вдоль и поперёк. (Работы по последовательному добавлению нейронов и по модификациям метода обратного распространения я тоже читал, да, рекордов они не ставят обычно).
mpakep Автор
08.11.2019 12:26Даже сам термин нейронные сети это биологический термин. Поэтому и удобно его показывать на биологических аналогиях, так сказать на кошачках. Но вы и на этих терминах не поняли о чем речь.
roryorangepants
08.11.2019 15:23Даже сам термин нейронные сети это биологический термин. Поэтому и удобно его показывать на биологических аналогиях, так сказать на кошачках.
А термин «лес» — это термин из природоведения, но недостатки random forest-а на примере древообрабатывающей промышленности никто не показывает. Это, конечно, гипербола, но суть, надеюсь, ясна: биологические аналогии в приложении к современному DL могут нести максимум иллюстративную роль.
Из за переобучения и из за ряда других фатальных недостатков нейронные сети нельзя обучать в потоковых задачах.
Я фразу «ряд фатальных недостатков» слышу от вас не в первый раз, а самого ряда почему-то не вижу.
Давайте так. Дайте реальную задачу (конкретный датасет, например), на котором нейросети плохо работают по заявленным вами причинам (сначала их неплохо бы внятно сформулировать, кстати), а потом реализуйте и продемонстрируйте на этой задаче ваш алгоритм хотя бы на уровне proof-of-concept. Тогда можно будет о чем-то говорить. А пока же статья ни о чем.
mpakep Автор
08.11.2019 18:19Давайте для примера такую. Ту которая у меня на серваке уже месяц стоит и расчитывается. Есть два хеша первый случайный (40 бит). Из него получаем хеш (40 бит) алгоритм SHA1 нужно предсказать первый бит из первого хеша из которого получен второй. Второй даем алгоритму в качестве исходных данных. Данные для обучения естественно первый бит первого хеша. Попробуйте решить эту задачу на нейронных сетях. Напишите какой обьем структуры сети вам может потребоваться для решения этой задачи? Берите с запасом это же благоприятно скажется на результате. Озвучте цифру. Это и есть пример потоковой задачи. Данные которой при нашей жизни могут больше не повториться ни разу. И данные обьем которых нам сложно даже вообразить. При этом алгоритм должен каждый раз обучаться а не ломаться и не уходить в максимумы. Чем больше мы скармливаем данных алгоритму, тем более точное предсказание он выдает.
Arech
08.11.2019 18:36Гм. Знаете, такие задачи, я подозреваю, никто, кроме вас, даже пытаться не станет решать с помощью НС… Вот вообще…
Но если вы придумали как это эффективно делать в парадигме НС — опишите это внятно с конкретным кодом, раз уж у вас это уже работает. Там уже будет видно, какое отношение ваше решение имеет к НС… Может статься, что почти никакого, но если оно эффективно решает (а под эффективно я имею в виду лучше стандартных криптоаналитических методовов) — почему нет? тоже интересно.mpakep Автор
08.11.2019 18:42-1Если заметили, то я писал вообще не о НС они только котики на прмиерах фатальных недостатков которых можно обсудить что-то реально работающее. Мое решение действительно имеет мало общего с НС но для того чтобы показать пробелму каую то общую концепцию знакомую большей части аудитории нужно было озвучить. Ну так какого размера структуру сети должна иметь НС чтобы решить такую задачу? Или у вас все ломается если задачи выходят за пределы школьной программы?
Судя по всему даже озвучить решения не получится, уже слили. Это происходит не первый раз подозреваю что хабр окупировали те самые 95% серой массы. Буду рассказывать на семинарах, возле доски с фломастером как в старые добрые времена.roryorangepants
08.11.2019 19:16Мое решение действительно имеет мало общего с НС но для того чтобы показать пробелму каую то общую концепцию знакомую большей части аудитории нужно было озвучить.
Судя по описанию вашей задачи, я очень сомневаюсь, что и ваше решение работает.
Впрочем, если работает — прошу. Давайте датасет, давайте код вашего решения и код альтернативного решения на основе deep learning (наверное, оно у вас было, раз вы начали вообще сравнивать ваш гениальный алгоритм с нейросетями? Я вот не особо представляю, как оно могло выглядеть). И тогда будет, о чем говорить.
Впрочем, такую задачу и с кодом обсуждать мало смысла. Я и так вам заранее скажу, что если вы хотите попробовать «обращать» хэш-функцию с хорошей энтропией каким-то около-ML-ным подходом, это гиблая затея.mpakep Автор
08.11.2019 19:20Никакого датасета нет. Есть скрипт который каждый раз генерирует новые данные. Данные никогда не повторяются. Вот об этой гиблой затее все это делать на НС я и говорил. Изменение общих подходов дает возможность расчитывать подобные задачи спокойно. Ведь от разработчика не требуется создавать структуру любое обучение начинается с нуля и сам алгоритм решает в какую стороне он будет расширять структуру. Можно только наблюдать за ростом самой сети и изменением вероятности предсказаний.
roryorangepants
08.11.2019 19:44Никакого датасета нет.
Machine learning algorithms build a mathematical model based on sample data, known as «training data», in order to make predictions or decisions without being explicitly programmed to perform the task.
Зачем вы вообще упоминаете нейросети и рассказываете глупости о каких-то недостатках, если датасета нет?
Но, так уж и быть, я вам подскажу: это провокационный вопрос. Датасет есть — вашим скриптом можно сгенерировать приличных размеров обучающую выборку, а также тестовый холдаут.
Поэтому идем дальше.
Вот об этой гиблой затее все это делать на НС я и говорил.
Нейросети не нужно, чтобы данные повторялись, о чем вы? У вас же не временные ряды какие-нибудь, где паттерны меняются. Обучили один раз в оффлайне, а дальше на инференс она работает на новых данных, и всё ок.
Как? На вашей задаче не работает?
Да что вы?
Может, это потому что хэши специально задумываются необратимыми? И поэтому для хорошей хэш-функции не должно быть возможно предсказать по выходному хэшу биты входных данных?
Поймите, это не задача для алгоритмов типа нейросетей. Не из-за того, что у них есть «затухание сигнала», не из-за того, что у них «фиксированный размер». Это просто в целом не задача для недетерминированных предсказательных алгоритмов.
Смешнее другое — вы утверждаете, что ваш «двоичный алгоритм машинного обучения» с этой задачей справляется? Уж простите, но попахивает ошибкой в эксперименте (в том самом, код которого вы не хотите публиковать), потому что если вам удается по выходу хэша эффективно предсказывать биты входа хэша, вы, пожалуй, сделали прорыв в криптографии.mpakep Автор
08.11.2019 19:52Наверно сложно такие задачи. Давайте попроще. Пусть предсказывает crc32 ну вроде обратимая, значительно легче. Такую задачку смоет решить нейросеть или тоже слишком сложная? Просто выше меня все убеждали что нет проблем и нет нерешаемых задач а тут выясняется что есть которые никто решать не хочет а проблемы на самом деле фишками называются и я их использовать не умею. Обойдемся без прорывов. Итак какой размер структуры мы возьмем для решения этой задачи? Три слоя нам хватит штук по сто? Или брать больше? Или не три?
Вообще я бы задумался вот над чем. За 50 лет существования нейросети по хорошему кроме погремушек хвалится нечем. Исходя только из этого факта я бы уже задумался что тут что-то не число. Или просто никто не умеет фишки НС использовать?
А вот это я забыл упоминуть. Берем десять разных алгоритмов. Обучаем все. И потом просто выкидываем те, которые хуже. Если бы так матиматики к своей работе подходили то бы мы число pi сейчас на генераторах случайных числе вычисляли а потом брали просто который ближе. Нет проблем с расчетами числа пи, просто у тебя недостаточно быстрый генератор случайных чисел.roryorangepants
08.11.2019 20:07Пусть предсказывает crc32 ну вроде обратимая, значительно легче.
Пардон, а зачем вам решать детерминированную алгоритмическую задачу нейросетями? Вы вообще понимаете, какой критерий для задачи должен соблюдаться, чтобы она относилась к классу ML-задач?
Или мы говорим о решении вообще произвольных задач? Ну тогда нейросети плохи в разгрузке вагонов с углём. Какой ужас…
Нет уж, давайте возьмём какую-нибудь реальную задачу классификации или регрессии. Идите на kaggle, например, и выбирайте.
Просто выше меня все убеждали что нет проблем
Никто не писал, что у нейросетей нет проблем. У нейросетей есть проблемы. Вам пишут, что ничто из перечисленного в вашей статьей не относится к проблемам нейросетей, а работоспособность и качество вашего «альтернативного» алгоритма в статье никак не описываются и не демонстрируются.
нет нерешаемых задач
Ну, чтобы так переврать тред, надо быть или глупым, или очень жирным троллем.
Вы описали задачу, которая заведомо не решается вообще, и предложили на ней сравнивать два алгоритма. Да я вам и так скажу, как они (оба) на ней будут перформить — очень плохо.
Вообще я бы задумался вот над чем. За 50 лет существования нейросети по хорошему кроме погремушек хвалится нечем. Исходя только из этого факта я бы уже задумался что тут что-то не число. Или просто никто не умеет фишки НС использовать?
Выходите из пещеры в современный мир. У нас тут есть computer vision, NLP, speech recognition и много других областей, где нейросети держат state-of-the-art.
Хотите позиционировать вашгениальныйалгоритм как решение каких-либо недостатков нейросетей?
Возьмите любую реальную задачу из какого-нибудь из этих доменов и решите её с помощью вашей модели. Побьёте топовые результаты — честь вам и хвала.mpakep Автор
08.11.2019 20:17Именно этим и собираюсь заняться.
roryorangepants
08.11.2019 21:43Этим стоило заняться до написания статьи. Тогда бы и статью писать не пришлось.
mpakep Автор
11.11.2019 07:01Уже часть датасетов с кагла расчитались. Пока не на 100% процентов только на 70 но достижение 100% это просто вопрос времени. биморф.рф/bmf/concrete пока задача расчитывается можно и пописать.
toyban
08.11.2019 20:22+1Просто выше меня все убеждали что нет проблем и нет нерешаемых задач а тут выясняется что есть которые никто решать не хочет
Такого Вам никто не говорил. Я, возможно, Вас удивлю, но есть задачи, которые звучат, будто они должны иметь алгоритмическое решение, но на самом деле его не существует. И даже нейронные сети Вам его не предоставят и не просчитают ответ. Просто потому, что нейросеть — это алгоритм, который решает определенный класс задач, а не золотой ключик, который должен вскрывать любую проблему.
Напишите какой обьем структуры сети вам может потребоваться для решения этой задачи?
Я вам могу сразу заявить — порядка 2^40, чтоб "запомнить" все входные хеши.
Данные которой при нашей жизни могут больше не повториться ни разу. И данные обьем которых нам сложно даже вообразить.
2^40 — это не так уж и много.
mpakep Автор
08.11.2019 20:49Ну хоть что-то а то думал из стадии «отрицания» не получится выйти. В сети можно найти информацию о самой большоей неронной сети 1.12^10 www.dailytechinfo.org/infotech/7173-sozdana-samaya-bolshaya-neyronnaya-set-prednaznachennaya-dlya-realizacii-tehnologiy-iskusstvennogo-intellekta.html это значительно меньше 2^40 так что пока это очень большая сеть как и количество которое на наш век хватит не повторяться. Но проблема тут не в том, что она большая. Проблема в том, что ее никто не контролирует. Часть ее либо не используется что довольно части, либо не хватает и из за этого обучение останавливается что тоже часто.
toyban
08.11.2019 21:10Больших нейронных сетей не существует не потому, что это невозможно, а потому что никто в здравом уме не будет делать подобную сеть с текущими технологическими возможностями. Да и нет особой нужды, так как отсутствуют задачи, которые требовали бы подобных сетей.
Это я к тому, что никто в сознательном состоянии не станет решать задачу предсказания битов хешей, да еще и с помощью НС! Ваша задача решается просто созданием словаря всех 2^40 входов в хеш-функцию. И не надо никакой НС. Не надо пихать сети, где они не нужны.
Нужно решать задачи тем инструментом, который их решает, а не "ой, а давайте возьмем микроскоп, забьем им гвозди, и посмотрим, что получится". То есть я уверен, что есть люди, которые делают это, но здравыми людьми мне их тяжело назвать.

VDG
09.11.2019 05:15Есть скрипт который каждый раз генерирует новые данные. Данные никогда не повторяются. Вот об этой гиблой затее все это делать на НС я и говорил.
Так это все знают, и никто не делает это на НС.
Изменение общих подходов дает возможность расчитывать подобные задачи спокойно.
Вот об этом и надо было писать, если нашли новый подход.
Arech
08.11.2019 15:33+1Ну, вот я разработал не то, что бы много, но вот эту библиотеку, нопремер, из опубликованного. И позвольте вам заметить, что благородные доны в коментах выше правы. Данная статья — ахинея чуть более, чем полностью, увы.
mpakep Автор
08.11.2019 18:08А знаете что обидно? Ведь мы обсуждали реально работающий алгоритм. Получается благородные доны как вы выразились уже не способны отличить работающую идею от ахинеи? Я занимаюсь этим алгоритмом уже пять лет и последние пол года он благополучно работает показывая неплохие результаты. То, что написано выше, каждый пункт это реально работающая идея. Цифры выше именно оттуда. Жаль, а могли бы обсудить работающие идеи а не ахинею которой кормят %ХабраЮзеров% благородные доны.
Arech
08.11.2019 18:27Новый алгоритм обсудить завсегда интересно, вот только мне не удалось увидеть никакого описания алгоритма в статье, ни нового, ни старого. Вообще никакого. Видел только набор деклараций, и набор необоснованных, а то и в корне неверных утверждений, показывающий только, что автор крайне скверно знаком с темой НС. В этой статье можно брать практически каждое предложение и разбирать где там правда, а где ошибка… По сути же обсуждать нет вообще ничего.
Опишите нормально алгоритм человеческим языком без пассов руками и вот этих вот «вжух! и всё стало гораздо лучше!», дайте пример реализации, раз он у вас уже работает, примеры использования, тогда и будет более содержательная беседа…
Хотите просто поговорить о недостатках обычных НС и как их исправить? Отлично, это тоже интересно. Но напишите о них хотя бы без фактических ошибок, которые адски режут глаза любому, кто хоть немного в тему погружался.mpakep Автор
08.11.2019 18:36А вы думали я вам исходные коды сразу предоставлю? Мне интересна сама идея. Если люди не способны увидеть в ней смысл то и выкладывание исходных кодов ничего вам не даст. Сейчас народ такой, что ему вылизанный текст подавай. Есть такое можно кинуть камень в мою сторону что я недостаточно маркетинговый текст написал, но я писал как понимаю а не как пипл хавает. Мы тут не в магазине на витрины смотреть я ожидал увидеть инженеров, которым интересно что внутри а не упаковка.
Arech
08.11.2019 18:38Мда…
Этот сломался, несите следующего.mpakep Автор
08.11.2019 18:50-2Так что, неужели никто не предложит решение для задачи выше? Вроде было столько людей понимающих в НС и утверждающих что они никогда не ломаются а тут даже размера структуры и количества слоев нужного для решения задачи сказать не могут.
buriy
12.11.2019 11:35Нормального решения для этой задачи не может быть.
Конечно, если вы будете проверять качество на валидационной выборке и возьмёте функцию побольше.
Криптостойкость алгоритма как раз и говорит о том, что невозможно найти такие правила, по которым можно инвертировать алгоритм за небольшое время, т.к. в процессе инвертирования у вас будет квинтилион промежуточных решений. Если бы было компактное подмножество промежуточных решений, то существовало бы разложение. Такие разложения нашли для md5 и некоторых других алгоритмов, уменьшив их сложность существенно, но всё равно, сложность осталась больше 2^40.
А то, что вы делаете с нейросетью — вы, видимо, считаете радужные таблицы для вашей функции (rainbow tables).
Этот способ работает при условии наличия памяти, а значит, проще его реализовывать наиболее эффективным по памяти алгоритмом, а это не нейросети.
И этот способ, увы, не позволяет решать другие задачи, в которых, наоборот, нужно находить эффективные правила для данных, которые (правила) пригодятся на валидационной подвыборке.
Я ждал, пока вы сами это сообразите… или пока комментаторы вам об этом скажут… но им похоже на очередной ненаучный вечный двигатель не хочется тратить много времени, они просто видят у вас те же самые проблемы, что и у остальных изобретателей: отсутствие воспроизводимости решения, отсутствие сравнимости с конкурентами, очевидные ошибки в экспериментах.
roryorangepants
08.11.2019 19:20То, что написано выше, каждый пункт это реально работающая идея. Цифры выше именно оттуда. Жаль, а могли бы обсудить работающие идеи а не ахинею которой кормят %ХабраЮзеров% благородные доны.
В общем, алгоритм следующий:
1. Берём датасет
2. ???
3. PROFIT
Господа, давайте обсудим работоспособность моего великолепного алгоритма на примере задачи взлома Пентагона в сравнении с нейросетями?mpakep Автор
08.11.2019 19:26Ну по планам была серия таких статей в каждой описание конкретного решения. Первый должен быть общим описанием. Но судя по слитой карме напсать я долго ничего не смогу, да и както желания нет. Я так понимаю реально обсуждать тут ни у кого желания нет. Всем только повыяснять что правильно «затухание сигнала» или «затухание градиента» ну так себе удовольствие выяснять это. Да и сами нейронные сети никогда не ломаются на школьных задачках. Что тут вообще обсуждать можно? А приведенные задачи могут прийти только мне никому больше в голову решать что-то подобное нет необходимости. Кому это может потребоваться вообще?
Arech
08.11.2019 15:46+1> Если позволить сети самостоятельно расти, то она и дорастет до размера, когда количества весов будет достаточно, чтоб просто «запомнить» все обучающие примеры.
Кстати, абстрагируясь от исходной темы, благодаря которой «мы все тут сегодня собрались», именно превышение количества параметров НС над величиной обучающей выборки (aka сверхпараметризованные решения) оказывает (иногда) очень благотворное влияние на качество модели. См. arXiv:1812.11118 “Reconciling modern machine learning practice and the bias-variance trade-off” Mikhail Belkin et.al
mpakep Автор
11.11.2019 02:36Все еще осталось желание проверить? Я добавил форма для добавления файла данных. После вручную запущенного расчета будет возможность подставлять входящие данные. Вот к примеру как выглядит обученная сеть Ирисы Фишера дала (100%) верных тестов на третьей минуте обучения
биморф.рф/bmf/f20b315ba9b683a8891e8a1137c9f53c
У кого есть желание свои данные добавить я готов поставить на расчет. Это можно сделать с главной страницы биморф.рф введя любое ключевое слово в форму поиска сети и уже в сети добавив обучающую выборку.buriy
11.11.2019 05:33Для простых данных нейросети обычно не используют, но используют градиентные бустинги. Попробуйте победить ещё и их, к тому же, у меня такое предположение, что вы изобрели свой метод делать то же самое (и вряд ли лучше, но надо сравнивать).
При этом, мне кажется, вы ещё не умеете сравнивать точность методов на десятке разных задач (как насчёт валидационной подвыборки? точность 100% на тренировочном датасете ни о чём не говорит, подобные алгоритмы ценят за их возможность работать на тех данных, что сеть ещё не видела), и оперируете исключительно оценками на пальцах, поэтому берёте лишь удобные для себя примеры (Как насчёт MNIST и CIFAR10 для начала? Или какого-нибудь Sentiment Analysis on IMDB, если вы умеете работать с текстами, или может возьмёте новостной корпус, что я использовал здесь: github.com/buriy/nlp_workshop. А для табличных задач тоже есть много корпусов посложнее на Kaggle, начиная с тренировочного титаника )
Думаю, мы сможем подождать ещё годик-два до момента, когда вы сможете нормально оформить свою работу и потом уже начинать писать более серьёзные статьи на Хабр.mpakep Автор
11.11.2019 06:19Вот еще одна задача с кагла www.kaggle.com/manvendramall/concrete/kernels
В параметрах два цифры до запятой, и две цифры после запятой. 60% полное совпадение. Обучается уже около месяца на 16 ядрах биморф.рф/bmf/concrete и все еще продолжает расчитываться. В сети уже 749905 нейронов (ну или чего-то отдаленно на них похожих). Хочу до 100% совпадений расчитать. Думаю, что через годик-два ни желания ни времени что-то писать не будет.roryorangepants
11.11.2019 09:38Месяц? Вы же понимаете, что это не нормально?
Плюс идея взять рандомный датасет, конечно, очень в вашем духе, но с чем вы собрались сравнивать? Это же не конкурс, к которому есть лидерборд, а просто залитый кем-то из участников набор данных. Я даже не представляю, как вы на него вышли.
Что вы собираетесь показать? 100% точности на ирисах — это, конечно, было смешно, но давайте серьезно. Вон, там сейчас идёт DS Bowl, например. Может, на нем продемонстрируете крутость своего подхода?
Говорю без сарказма: если он позволит зайти хотя бы в зону медалей, это будет лучший пиар, который возможен.mpakep Автор
11.11.2019 18:17-1Этот датасет есть не только на кагле. И изначально я его нашел на другом сайте archive.ics.uci.edu/ml/datasets.php и только потом увидел его на кагле.
Прочитал условия учатия, там есть пункт относительно лицензии на код.
Open Source: You hereby license and will license your winning Submission and the source code used to generate the Submission under an Open Source Initiative-approved license (see www.opensource.org) that in no event limits commercial use of such code or model containing or depending on such code. For generally commercially available software that you used to generate your submission that is not owned by you, but that can be procured by the Competition Sponsor without undue expense, you do not need to grant the license in the preceding sentence for that software.
Насколько я понял текст условием для программного обеспечения является открытый исходный код. Меня в прошлый раз похожий пункт беспокоил. В этот чет раз тоже напрягает.roryorangepants
11.11.2019 18:32Насколько я понял текст условием для программного обеспечения является открытый исходный код. Меня в прошлый раз похожий пункт беспокоил. В этот чет раз тоже напрягает.
Опенсорсная лицензия на код требуется только у победителей. Поверьте, вам это не грозит.mpakep Автор
11.11.2019 18:45Предлагаете заведомо распрощаться с возможностью победить? Поучаствовать ты можешь, но победить никогда. Ну как то так себе и условия и мотивация. Я уж лучше свои местечковые данные буду расчитывать книги там может для написания текста, капчи, хеши и курсы доллара и биткоина но где мне не будут правила запрещать побеждать. Благо, что в мире еще осталось масса хороших задач. С удовольствием поучаствовал бы в конкурсе где важен результат а не инструмент. Но пока я таких не нашел. Буду признателен если подскажите.
buriy
11.11.2019 18:55Это была просто насмешка, над вашей манерой уклоняться от сравнений с конкурентами уже насмехаются, но не обращайте внимание.
После окончания *конкурса с призами* обычно можно посылать работы — и тогда лицензия уже не требуется, при этом сравниться с другими людьми вы можете.
Обычно вы отправляете лишь результаты вычислений, а не свой код.
Возьмите конкурс про титаник, он для начинающих на Kaggle как раз подойдёт.
neurohive.io/ru/osnovy-data-science/razbor-resheniya-zadachi-titanik-na-kaggle-dlya-nachinajushhihmpakep Автор
11.11.2019 19:10Да. я уже смотрел этот датасет. Вы в курсе, что в нем есть имена пассажиров? Сеть просто привяжется к именам пассажиров. Запомнит каждого из пассажиров поименно. Набор данных не совсем корректный и минимум требует доработки (удаления некорректных полей) Я уже кучу данных пересмотрел в том числе и эту задачу. В том виде в котором данные есть сейчас они непригодны для обучения. Это все равно что задать в наборе данных уникальный идентификатор строки. Алгоритм обучившись по нему и будет все ответы выдавать.
buriy
11.11.2019 19:18+11) На практике, до 90% работы с нейросетями — препроцессинг. Убирайте имена пассажиров, настраивайте как угодно. Но… вы же говорили, что ваша версия не переобучается! И то, что настраивать вашу сеть никак не нужно…
2) Польза нейросетей — в их результате на новых данных. Какая разница, что там есть имена, главное, чтобы на тех данных, которые нейросеть не видела, она предсказывала правильные ответы.
И одна из задач хорошей технологии, решающей задачи — убирать данные, которые лишь путают. Но тут важен баланс: уберёте много данных, и сеть ничего не предскажет, уберёте мало данных, и ваша сеть переобучится. Что ж, вам придётся как-то решить и эту задачу, сделать её частью вашей победной технологии, раз уж вы считаете, что это *у нас* колёса квадратные…
roryorangepants
11.11.2019 19:18Это все равно что задать в наборе данных уникальный идентификатор строки. Алгоритм обучившись по нему и будет все ответы выдавать.
Пардон, слово «генерализация» вам о чем-то говорит? Алгоритм должен работать не на тех данных, на которых учился.
А на отдельном холдауте никаких знакомых имен или идентификаторов уже не будет.
Набор данных не совсем корректный и минимум требует доработки (удаления некорректных полей)
Удаляйте, кто ж вам мешает. Это препроцессинг на ваш выбор.
roryorangepants
11.11.2019 11:46Сразу уточню, почему я раньше предлагал вам глянуть на любой кагловский датасет, а сейчас настаиваю именно на демонстрации мощи вашего алгоритма на актуальном соревновании на кэгле.
Изначально ведь речь шла о том, что вы покажете эксперимент с кодом, который продемонстрирует качество вашей модели. Но вы вместо этого кидаете ссылку на какой-то поломанный сайт на .php, где происходит что-то и выдаются на выходе какие-то числа.
Мы, конечно, тут все джентльмены и поэтому доверяем вам в плане того, что числа берутся не с потолка, но судя по вашим познаниям в области машинного обучения вы запросто можете допустить какую-то очевидную ошибку валидации или условный дата лик. Поэтому для чистоты эксперимента было бы круто сделать честную проверку.mpakep Автор
11.11.2019 18:22Честная проверка это результат работы сети. Как раз его я на сайте и предоставляю возможность изучить. Поставляйте данные и сеть вам выдаст результаты. Разве не достаточно для проверки? Плюс справа выводится информация о сети. Затраченное время, размер сети, процент совпадений. Для проверки параметров не из обучающей выборки достаточно ввести соответствующие входящие данные. Возможно интересно будет проверить на ваших данных. Создайте сеть и загрузите данные после расчета сможете проверить точность прогнозов.
roryorangepants
11.11.2019 18:33Разве не достаточно для проверки?
Конечно, этого не достаточно, потому что я не уверен, что вы знаете, что такое train-val-test split, зачем он нужен и как его делать.
buriy
11.11.2019 18:40Чтобы проверить нейросеть, нужно загрузить туда кучу данных не из набора для обучения — так называемую валидационную выборку (обычно не меньше 2000 строк таблицы), а потом считать на ней среднее качество. Как вы предлагаете другим людям это делать с вашей технологией? В идеале это выглядело бы так: вы просто говорите, сколько у вас получилось на том или ином наборе валидационных данных (при условии одного и того же набора тренировочных и валидационных данных с конкурентами), и если у вас получается хороший результат — то это значит, что ваша технология работает.
Мы надеемся, что вы дорастёте и покажете такие цифры. Вот после этого уже и начнётся серьёзный разговор о том, что не так с нейросетями, и у вас в нём будет взрослое право голоса.mpakep Автор
11.11.2019 18:53Данные расчитываются через апи используя удобные форматы. При отсылке пост запроса на адрес сети она выдает результат в json формате. Написав небольшой скрипт в 20 строк можно с легкостью проверить данные любого обьема. Все это возможно сделать прямо сейчас, загляните во вкладку сеть консоли браузера. Если набор данных будет вашим, то вам не составит труда проверить все данные.
Создавайте сеть с главной страницы, закидывайте свой датасет указав поля для обучения я поставлю его на расчет проверим вместе.buriy
11.11.2019 18:59А вы по какой-то причине не можете это сделать сами? Это же вы нас пытаетесь убедить, что ваша идея вообще хоть как-то работает.
Не забудьте взять такую задачу, где можно сравнить ваши результаты с результатами конкурентов.
Конечно, можете нас и не убеждать.
Тогда мы останемся при своих: вы считаете, что вы — непризнанный гений, а мы — что вы шарлатан, и особенно нам доставляет при этом то, как вы изящно увиливаете от любой попытки сравнить качество вашей разработки с любыми потенциальными конкурентами.
{kind=link}
ni-co
08.11.2019 07:12Сочетание слов "двоичный алгоритм" у меня ассоциировалось почему то с бинарными опросниками. Но при чем тут нейросети?

palexab
08.11.2019 09:08Справедливости ради хочу отметить, что направление спайковых сетей (я именно так интерпретирую описанную «двоичность») вполне себе перспективно. Хотя-бы по энергетике, при правильной реализации в железе конечно.
Да и предоставить возможности структурной адаптации сети к изменениям в среде (сиречь данным) — это тоже очень заманчиво. Все-таки в биологии рост сети (дендритных деревьев) играет фундаментальную роль в обучении и памяти. Работы также ведутся, но мало и они далеки от хоть какого-то продакшена. Уж больно все непонятно.
VDG
09.11.2019 05:39Судя по проскользнувшим «паттернам» в тексте и комментариях, у меня подозрение, что автор переоткрыл нейроподобные растущие сети (Ященко). Сеть будет расти пока не запомнит все 2^40 варианта. Хеш — это не тот случай, где можно делать обобщения.
mpakep Автор
09.11.2019 12:33-2Звучит очень не плохо. Только термин «запомнит» применительно к нейронным сетям звучит в отрицательном контексте. Все бояться от запоминания сети так как это приводит к низкой сходимости сети. Если убрать негативный оттенок и допустить что от «запоминания» будет работать лучше то да. Это то что нужно. Только я по нейроподобным растущим сетям Ященко не нашел информации в сети. А из того что нашел понял что это все еще нейроны. Есть общие идеи, но различий больше. Здесь акцент на двоичность данных. Все сигналы это бит а не градиент. Жаль слили карму. Мог бы рассказать разницу в расчетах таких сигналов.
VDG
11.11.2019 00:56по нейроподобным растущим сетям Ященко не нашел информации в сети. А из того что нашел понял что это все еще нейроны.
Нет, от нейронов там только название. Информации мало, вот есть, что есть:
списокЯщенко, Виталий Александрович
Ященко, Виталий Александрович
works.doklad.ru/view/_RMzUcxdlqA.html
ІПММС — Персональна сторінка: Виталий Ященко
www.immsp.kiev.ua/perspages/yaschenko_vo/index.html
Ященко В.А. Рецепторно-эффекторные нейроподобные растущие сети эффективное средство моделирования интеллекта. I, II — // Кибернетика и сист. анализ № 4, 1995. С. 54 – 62, № 5, 1995. С. 94 — 102.
Рабинович З.Л., Ященко В.А. Подход к моделированию мыслительных процессов на основе нейроподобных растущих сетей // Кибернетика и сист. анализ № 5, 1996. С.3-20.
Нейроподобные растущие сети новая технология обработки информации
works.doklad.ru/view/CmYh00YZXbY.html
Вторичные автоматизмы в интеллектуальных системах
iai.dn.ua/public/JournalAI_2005_3/Razdel4/09_Yashchenko.pdf
Mодель естественного интеллекта и пути реализации задач искусственного интеллекта
cyberleninka.ru/article/v/model-estestvennogo-intellekta-i-puti-realizatsii-zadach-iskusstvennogo-intellekta
Размышляющие компьютеры
cyberleninka.ru/article/n/razmyshlyayuschie-kompyutery
Теория искусственного интеллекта (основные положения)
cyberleninka.ru/article/n/teoriya-iskusstvennogo-intellekta-osnovnye-polozheniya
Некоторые положения теории искусственного интеллекта
dspace.nbuv.gov.ua/bitstream/handle/123456789/57710/5-Yashchenko.pdf?sequence=1
Общая теория искусственного интеллекта
www.myshared.ru/slide/924856
Некоторые проблемные вопросы разработки искусственного мозга
www.immsp.kiev.ua/publications/articles/2018/2018_3/03_2018_Yashchenko.pdf
Некоторые аспекты «нервной деятельности» интеллектуальных систем и роботов
dspace.nbuv.gov.ua/bitstream/handle/123456789/8180/67-Yashchenko.pdf?sequence=1
Уничтожат ли человечество умные роботы
www.immsp.kiev.ua/publications/articles/2017/2017_4/04_2017_Yachenko.pdfmpakep Автор
12.11.2019 02:08Прям в точку. Действительно это очень близко. ТОлько я не понял удалось кому то до этого сделать эту сеть или нет? Не нашел эту информацию. А так, да. ОоОчень близко. Хотя много написано по другому вот к примеру это «причем mi может принимать как положительные, так и отрицательные значения.» Это уже не двоичный алгоритм. В двоичном есть только один и ноль. Нет отрицательных значений и отрицательные значения исчезают после установки входных сигналов (0 или 1) и появляются только при интерпритации расчетного значения сети опять же из (0 или 1) но многие вещи очень близко.
И вот это что такое?
«Используется обычно до 3-х уровней (слоев). Использование более 3-х слоев не осмысленно.» это из описания «нейроподобные растущие сети». Получается, что Ященко не смог сделать растущую сеть больше трех слоев? Реально в работающих сетях этот параметр уже переваливает за сотни и тысячи, хотя миллионы и миллиарды думаю реальность ближайшего времени ограничивает только производительность машины на которой происходят расчеты а не «осмысление»
Опять же а это? «Появление ложных фантомов (ложных аттракторов) – присутствует» Ничего подобного нет в уже работающей сети. Никаких фантомов. Я так понял человек был в правильном направлении, но не смог доработать свое детище до конца. У меня на это ушло пять лет первый раз сеть сложилась 13 июня 2019 года в 4 утра с тех пор просто идет оптимизация производительности.
И еще. Слово двоичная не зря выведена в заголовок. Двоичная это базовое свойство сети. А это из присутствующих я так понял осмыслить никто не смог. В двоичном представлении нет отрицательных значений, нет списков. Есть только два значения «включено» или «выключено» 1 или 0 только в таком состоянии можно полноценно интерпритировать сигналы в обе стороны и полноценно расширять сет. Любой значение больше двух дает «Появление ложных фантомов» хотя очень много в приведенных статьях сделано правильно. Ященко молодец! Спасибо автору. Теперь можно сказать не зря было все это общение.VDG
12.11.2019 03:03«Используется обычно до 3-х уровней (слоев). Использование более 3-х слоев не осмысленно.»
В таблице сравнения из той статьи это относится к «классическим» нейросетям. Сама статья из конца 90-х годов. В то время ни просчитать более 3-х слоёв ни применять их не умели. Высказывание из рода «640КБ хватит всем».
В начале 2000-х институт какое-то ПО разработал, но так как все разработки дотационные, а впоследствии все альтернативные разработки подмял успех глубокого обучение и свёртки, то вся эта тема киснет уже пятый десяток. Поэтому, если есть что-то работающее по этой теме, то, на мой взгляд, важно «не унести это с собой в могилу».mpakep Автор
12.11.2019 03:21Чет вы рано о могиле заговорили. Я планирую жить вечно. Надеюсь еще массу задач сделать.
VDG
12.11.2019 03:54Ну это была просто гипербола. Во всём новом каждый обо что-то спотыкается. На затыке может пропасть интерес, и это новое, что появилось в этих растущих сетях за последние 20-30 «голодных» лет будет вычеркнуто. Не забудьте рассказать про алгоритм, если основательно упрётесь в стену.
Мне сейчас кажется, что сеть просто растёт на тех данных, что Вы ей скармливаете. А рост должен замедляться по мере увеличения количества обобщений.
Вместо экзотических датасетов я бы скормил ей «Войну и Мир». Причём второй том уже должен приводить к меньшему росту сети. Новая информация должна встраиваться в предыдущие знания. Если рост нелинейный — сеть работает (обобщение присутствует). Рост линейный — ну не получилось.mpakep Автор
12.11.2019 04:32Как раз последнее время все очень хорошо. Все, на что расчитывал работает и показывает гарантированный результат. Поэтому и решил начинать потихоньку рассказывать окружающим. Действительно. Рост замедляется. По достижении 99% совпадений большая часть уходит на «перебирание» правильных прогнозов. Будь неправильных больше обучение проходило бы значительно быстрее. У меня в одной из задач 99.9% уже держится эпох десять на каждой эпохе идет расчет 1-2 неправильных примеров и снова эпоху приходится начинать сначала. Десятки раз когда оставался один неправильный прогноз, но окончательно выловить эту ошибку чуть ли не сложнее того чтобы дойти до 99%. Я так понимаю сети нужно найти и поменять какой то из верхних нейронов. Но чтобы дойти до этого изменения нужно перебрать возможные варианты во всех нижестоящих. Ошибка в установке «веса» была допущена на ранней стадии формирования сети. При этом так как это «двоичный алгоритм» весов всего два 0 или 1 Нахождение и изменение верхнего нейроны просто вопрос времени. При этом процент правильных прогнозов не уменьшается как в НС при переобучении (падает в максимумы) а стремиться к оптимальному при любом состоянии.
За время пока мы тут обсуждали статью я написал интерфейс которым можно загружать свои обучающие выборки. Хотел бы попробовать на чужих данных потренироваться. Но пока никто не воспользовался. Нужно создать сеть и загрузить в нее файл с данными. В описании указать поля для обучения. В результате появится форма как на ирисах и бетоне. Апи для автоматизированного получения результатов расчета прилагается к каждой задаче плюс дообучение больших данных теоретически «бесконечно» каждый раз повышая процент правильных прогнозов.
По поводу войны и мира тоже думал :) но я больше склоняюсь к каким то диалоговым задачам. Продажа чего нибудь или скрытый маркетинг. Чтобы алгоритм потренировавшись на диалогах пользователей сам стучался и обсуждал какую нибудь общую тему. Повысив степень «доверия» уже максимально «ненавязчиво» предлагал услугу или событие интересное собеседнику. Восприятие такого рода продвижения должен быть максимально эффективно. Да и человек от него должен получать удовольствие а не раздражение. Общение в наше время вещь востребованная. Я какое то время проработал в фирме с «продажниками» мне эта тема очень близка. Сейчас теоретически все есть для решения такого рода задачи. Производительность сильно увеличилась когда пару недель назад я решил вопрос с возможностью в нескольких потоках обучать одну задачу. Сейчас задачи на сервере расчитываются в 15-20 потоках эффективность возрастала на порядки. Потихоньку начинаю почитывать документацию по расчетам на видеокартах. Слабо пока представляю как можно к ним обычные алгоритмы прикрутить. В общем есть куда двигаться.
toyban
09.11.2019 18:50Все бояться от запоминания сети так как это приводит к низкой сходимости сети.
Как раз наоборот. Сеть, "запомнившая" обучающую выборку, даст самую лучшую сходимость — прям к нулю. Но довольно часто такие сети не способны к обобщению. Поэтому и опасаются переобучать сети.
Здесь акцент на двоичность данных. Все сигналы это бит а не градиент.
Все данные всегда двоичны, разве что Вы работаете с аналоговым устройством. Поэтому те НС, что Вы критикуете, также работают с двоичными данными, но никак не с "градиентом" данных, что бы это не значило.
Мог бы рассказать разницу в расчетах таких сигналов.
Так почему ж Вы сразу об этом не начали рассказывать?

FunnyHouse
10.11.2019 04:04Не придираясь к деталям Ваших рассуждений о нейронных сетях (в которых Вы поставили всё несколько раз с ног на голову), давайте согласимся что они имеют ряд концептуальных недостатков. Но почему же Ваша идея исправляет их?
Ну то есть совсем не понятно, почему в вашем случае не будет переобучения например. Почему время обучения сокращается, если задействована только малая часть «двоичных нейронов» на каждом проходе? Скорее наоборот. В самом деле ли хаотично растущая сеть сможет дать «полного контроля сети и однозначного понимания происходящих в ней процессов» которых нет у классических НС?
И к тому же, как вы собираетесь обучать такие сети?
Дело в том, что непрерывность (а точнее дифференцируемость) выхода нейронной сети как функции от её параметров, является ключевой идеей, позволяющей обучать НС.
Добавив гладкую функцию потерь, как функцию от выхода сети и правильного ответа, мы получаем дифференцируемую функцию потерь, как функцию от параметров сети. Теперь мы можем посчитать градиент, т.е. направление, в котором нам нужно изменять параметры, чтобы минимизировать функцию потерь (на самом деле конечно в противоположную сторону от градиента).
Что вы предлагаете взамен?
Вы конечно извините, но в целом пока только общие слова и абстрактные рассуждения; без подробностей реализации вашей идеи, не видно плюсов и не ясна даже жизнеспособность такой конструкции
mpakep Автор
10.11.2019 04:12Все вышеописанное исправляет потому что это работает. Нет смысла было говорить не проверив это все на практике. Переобучения нет, потому что достраивается только то, что нужно для правильных ответов ни больше. Время сокращается потому, что не приходится пересчитывать все данные, лишь малой части достаточно для получения общего результата. А понимание потому, что мы можем на «развилках» понять какой именно входящий сигнал привел к результату. Суммирование уровней сигналов не дает такой возможности. В замен предлагаю новый алгоритм результаты работы которого смогли бы показать эффективность. Если организовать расчет данных с возможностью проверить результаты это могло бы убедить в правильности моих утверждений? Как раз для этих целей делаю сервис по загрузке и расчету датасетов.
daiver19
Слышал звон, не знаю где он. В НС есть проблема затухания градиента, а не «сигнала». И в обычных рекуррентных сетях эта проблема как раз явно выражена, поэтому изобрели всяке LSTM/GRU итд, в которых эта проблема значительно меньше.
Сильное утверждение. Обосновывать его вы, конечно же, не будете. Да и вообще объяснять о чем вообще речь.
roryorangepants
Я бы дополнил, что даже если говорить про feed-forward сети, с ней тоже успешно борются всякими резидуал-связями, например.
Arech
Есть ещё, имхо, весьма недооценённые SELU активации с правильной иницализацией весов, которые существенно облегчают, если не вообще решают вопрос vanishing/exploding gradients. Ну и другие менее публичные методы :)