
Всем привет. Меня зовут Александр, я Java-разработчик в группе компаний Tinkoff.
В данной статье хочу поделиться опытом решения проблем, связанных с синхронизацией состояния кэшей в распределенных системах. Мы столкнулись с ними, разбивая наше монолитное приложение на
В статье я расскажу про наш опыт перехода на сервис-ориентированную архитектуру, сопровождающуюся переездом в Kubernetes, и про решение сопутствующих проблем. Будет рассмотрен подход к организации системы распределенного кэширования In-Memory Data Grid (IMDG), его преимущества и недостатки, из-за которых мы решили написать собственное решение.
В статье рассматривается проект, бэкэнд которого написан на Java. Поэтому речь также пойдет про стандарты в области временного In-memory-кэширования. Обсудим спецификацию JSR-107, несостоявшуюся спецификацию JSR-347, а также особенности кэширования в Spring. Добро пожаловать под кат!
А давайте распилим приложение на сервисы...
Перейдем на сервис-ориентированную архитектуру и переедем в Kubernetes — так решили мы чуть больше 6 месяцев назад. Долгое время наш проект был монолитом, накопилось множество проблем, связанных с техническим долгом, а новые модули приложения мы и вовсе писали отдельными сервисами. В итоге переход на сервис-ориентированную архитектуру и распил монолита был неизбежен.
Приложение у нас нагруженное, на веб-сервисы приходит в среднем 500 rps (в пике доходит до 900 rps). Чтобы в ответ на каждый запрос собрать всю модель данных, приходится несколько сотен раз ходить за данными в различные кэши.
Мы стараемся ходить в удаленный кэш не более трех раз за запрос, в зависимости от необходимого набора данных, а на внутренних JVM-кэшах нагрузка достигает 90 000 rps на один кэш. Таких кэшей у нас порядка 30 под самые разные сущности и DTO-шки. На некоторых нагруженных кэшах мы даже не можем себе позволить удалить значение, так как это может привести к увеличению времени ответа веб-сервисов и к сбою в приложении.

Так выглядит мониторинг нагрузки, снимаемый с внутренних кэшей на каждом узле в течение дня. По профилю нагрузки легко заметить, что большая часть запросов приходится на чтение данных. А равномерная нагрузка на запись обусловлена обновлением значений в кэшах с заданной частотой.
Downtime для нашего приложения недопустим. Поэтому с целью бесшовного деплоя мы всегда балансировали весь входящий трафик на два узла и деплоили приложение по методу Rolling Update. Идеальным инфраструктурным решением при переходе на сервисы для нас стал Kubernetes. Таким образом мы решали сразу несколько проблем.
Проблема постоянного заказывания и настройки инфраструктуры для новых сервисов
Нам выдали namespace в кластере для каждого контура, которых у нас три: dev — для разработчиков, qa — для тестировщиков, prod — для клиентов.
С выделенным namespace добавление нового сервиса или приложения сводится к написанию четырех манифестов: Deployment, Service, Ingress и ConfigMap.
Высокая толерантность к возрастанию нагрузки
Бизнес расширяется и постоянно растет — еще год назад средняя нагрузка была в два раза меньше текущей.
Горизонтальное масштабирование в Kubernetes позволяет нивелировать эффект масштаба при росте нагрузки разрабатываемого проекта.
Обслуживание, сбор логов и мониторинг
Жизнь становится гораздо проще, когда отсутствует необходимость при добавлении каждого узла пробрасывать логи в систему логирования, настраивать забор метрик (если только у вас не push система мониторинга), выполнять сетевые настройки и просто устанавливать необходимое для работы ПО.
Конечно, это все можно автоматизировать, используя Ansible или Terraform, но в конечном итоге написать несколько манифестов для каждого сервиса гораздо проще.
Высокая надежность
Встроенный в k8s механизм Liveness- и Readiness-проб позволяет не беспокоиться, что приложение начало тормозить или вовсе перестало отвечать.
Теперь жизненным циклом подов, содержащих контейнеры приложений, а также направляемым на них трафиком, управляет Kubernetes.
Вместе с описанными удобствами нам необходимо было разрешить ряд вопросов, чтобы сделать сервисы пригодными для горизонтального масштабирования и использования общей модели данных для множества сервисов. Нужно было решить две проблемы:
- Состояние приложения. При деплое проекта в k8s-кластере начинают создаваться поды с контейнерами новой версии приложения, не связанные с состоянием подов предыдущей версии. Новые поды приложения могут быть подняты на произвольных серверах кластера, удовлетворяющих заданным ограничениям. Также теперь каждый контейнер приложения, работающий внутри Kubernetes пода, в любой момент может быть уничтожен, если Liveness-проба скажет, что под необходимо перезапустить.
- Консистентность данных. Необходимо поддерживать согласованность и целостность данных друг с другом на всех узлах. Это особенно актуально, если несколько узлов работают в рамках единой модели данных. Недопустимо, чтобы при запросах к разным узлам приложения в ответе клиенту приходили несогласованные данные.
В современной разработке масштабируемых систем Stateless-архитектура является решением вышеуказанных проблем. От первой проблемы мы избавились, переместив всю статику в облачное S3-хранилище.
Однако из-за необходимости агрегировать непростую модель данных и сохранять время ответа наших веб-сервисов, мы не смогли отказаться от хранения данных в In-memory кэшах. Для решения второй проблемы написали библиотеку для синхронизации состояния внутренних кэшей отдельных узлов.
Синхронизируем кэши на отдельных узлах
В качестве исходных данных мы имеем распределенную систему, состоящую из N узлов. На каждом узле около 20 In-memory кэшей, данные в которых обновляются несколько раз в час.
Большинство кэшей имеют TTL (time-to-live) политику обновления данных, некоторые данные обновляются CRON-операцией каждые 20 минут — ввиду высокой нагрузки. Рабочая нагрузка на кэши разнится от нескольких тысяч rps ночью до нескольких десятков тысяч днем. Пиковая нагрузка, как правило, не превышает 100 000 rps. Количество записей во временном хранилище не превышает нескольких сотен тысяч и помещается в heap одного узла.
Наша задача — достичь консистентности данных между одноименными кэшами на разных узлах, а также минимально возможного времени ответа. Рассмотрим, какие вообще есть способы решения данной проблемы.
Первое и наиболее простое решение, которое приходит в голову, — вынести всю информацию в удаленный кэш. В этом случае можно полностью избавиться от состояния приложения, не думать о проблемах достижения консистентности и иметь единую точку доступа к временному хранилищу данных.
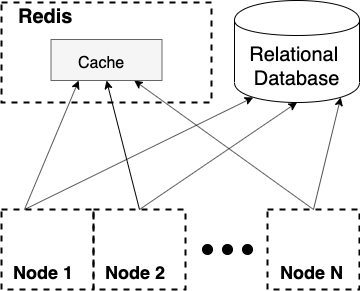
Такой метод временного хранения данных довольно прост, и у нас он используется. Мы кэшируем часть данных в Redis, представляющий собой NoSQL-хранилище данных в оперативной памяти. В Redis мы, как правило, записываем каркас ответа веб-сервиса, и на каждый запрос мы должны обогатить эти данные актуальной информацией, для чего приходится отправлять несколько сотен запросов в локальный кэш.
Очевидно, что данные внутренних кэшей мы не можем вынести на удаленное хранение, так как затраты на передачу по сети такого объема трафика не позволят нам уложиться в требуемое время ответа.
Второй вариант — использование In-Memory Data Grid (IMDG), который представляет собой распределенный In-memory кэш. Схема такого решения следующая:
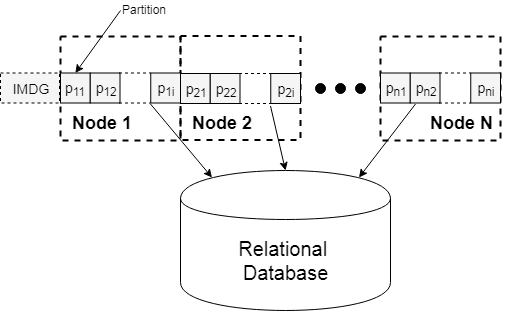
Архитектура IMDG построена на принципе секционирования данных (Data Partitioning) внутренних кэшей отдельных узлов. По сути, это можно назвать распределенной на кластер узлов хэш-таблицей. IMDG считается одной из самых быстродействующих реализаций временного распределенного хранилища.
Существует множество реализаций IMDG, самая популярная — Hazelcast. Распределенный кэш позволяет хранить данные в RAM на нескольких узлах приложения с приемлемым уровнем надежности и сохранением консистентности, которая достигается путем репликации данных.
Задача построения такого распределенного кэша непростая, однако использование готового IMDG-решения для нас могло стать неплохой заменой JVM-кэшей и избавить от проблем репликации, консистентности и распределения данных между всеми узлами приложения.
Большинство вендоров IMDG для Java-приложений реализуют JSR-107, стандартный Java API для работы с внутренними кэшами. Вообще у этого стандарта довольно большая история, о которой я подробнее расскажу далее.
Когда-то давно были идеи реализовать свой интерфейс для взаимодействия с IMDG — JSR 347. Но реализация такого API не получила достаточной поддержки со стороны Java-сообщества, и теперь мы имеем единый интерфейс для взаимодействия с In-memory-кэшами вне зависимости от архитектуры нашего приложения. Хорошо это или плохо — другой вопрос, но это позволяет нам полностью абстрагироваться от всех сложностей реализации распределенного In-memory-кэша и работать с ним как с кэшем монолитного приложения.
Несмотря на очевидные преимущества использования IMDG, такое решение все же медленнее, чем стандартный JVM-кэш, из-за накладных расходов на обеспечение постоянной репликации данных, распределенных между несколькими JVM-узлами, а также резервирования этих данных. В нашем случае объем данных для временного хранения был не таким большим, данные с запасом умещаются в памяти одного приложения, поэтому их распределение на несколько JVM казалось избыточным решением. А дополнительный сетевой трафик между узлами приложения на больших нагрузках может сильно ударить по производительности и увеличить время ответа веб-сервисов. В итоге мы решили написать собственное решение для этой проблемы.
Мы оставили в качестве временного хранилища данных In-memory кэши, а для поддержания консистентности использовали менеджер очередей RabbitMQ. Мы взяли на вооружение поведенческий шаблон проектирования «Издатель — Подписчик», а актуальность данных поддерживали путем удаления измененной записи из кэша каждого узла. Схема решения выглядит следующим образом:
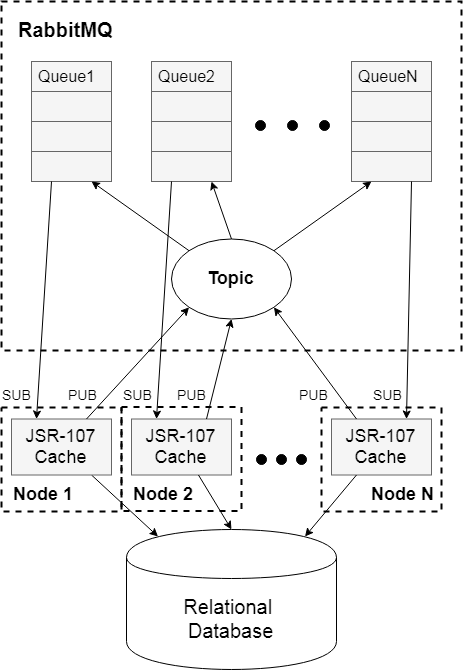
На схеме представлен кластер из N узлов, на каждом из которых установлен стандартный In-memory кэш. Все узлы используют общую модель данных и должны быть консистентны. При первом обращении к кэшу по произвольному ключу значение в кэше отсутствует, и мы кладем в него актуальное значение из БД. При любом изменении — удаляем запись.
Актуальная информация в ответе кэша здесь обеспечивается путем синхронизации удаления записи при ее изменении на любом из узлов. За каждым узлом системы закреплена очередь в менеджере очередей RabbitMQ. Запись во все очереди осуществляется через общую точку доступа Topic-типа. Это значит, что сообщения, отправляемые в Topic, попадают во все связанные с ним очереди. Так, при изменении значения на любом узле системы это значение удалится из временного хранилища каждого узла, а последующее обращение инициирует запись актуального значения в кэш из БД.
Кстати, похожий механизм PUB/SUB есть и в Redis. Но, на мой взгляд, для работы с очередями все же лучше использовать менеджер очередей, и RabbitMQ прекрасно подошел для нашей задачи.
Стандарт JSR 107 и его реализации
У стандартного Java Cache API для временного хранения данных в памяти (спецификация JSR-107) довольно долгая история, его разрабатывали в течение 12 лет.
За столь длительное время успели поменяться подходы к разработке ПО, на смену монолитам пришла микросервисная архитектура. Ввиду столь долгого отсутствия спецификации для Cache API были даже запросы на разработку API-кэшей распределенных систем JSR-347 (Data Grids for the Java Platform). Но после долгожданного релиза JSR-107 и выхода в свет JCache запрос на создание отдельной спецификации для распределенных систем был отозван.
За долгие 12 лет на рынке место для временного хранения данных сменилось с HashMap на ConcurrentHashMap при выходе в свет Java 1.5, а позже появилось множество готовых опенсорсных реализаций In-memory кэширования.
После релиза JSR-107 вендорные решения начали постепенно реализовывать новую спецификацию. Для JCache даже появились провайдеры, специализирующиеся на распределенном кэшировании — те самые Data Grids, спецификация для которых так и не была реализована.
Рассмотрим, из чего же состоит пакет javax.cache, и как получить экземпляр кэша для нашего приложения:
CachingProvider provider =
Caching.getCachingProvider("org.cache2k.jcache.provider.JCacheProvider");
CacheManager cacheManager = provider.getCacheManager();
CacheConfiguration<Integer, String> config =
new MutableConfiguration<Integer, String>()
.setTypes(Integer.class, String.class)
.setReadThrough(true)
. . .;
Cache<Integer, String> cache = cacheManager.createCache(cacheName, config);
Здесь Caching представляет собой загрузчик для CachingProvider’а.
В нашем случае JCacheProvider, являющийся cache2k-реализацией SPI провайдера JSR-107, будет загружен из ClassLoader’a. Для загрузчика можно и не указывать реализацию провайдера, но тогда он попытается загрузить реализацию, лежащую в
META-INF/services/javax.cache.spi.CachingProvider
В любом случае в ClassLoader’е по итогу должна быть единственная имплементация CachingProvider’а.
Если использовать библиотеку javax.cache без какой-либо реализации, то при попытке создать JCache будет выброшено исключение. Назначение провайдера — это создание и управление жизненным циклом CacheManager’а, который, в свою очередь, отвечает за управление и конфигурирование кэшей. Таким образом, чтобы создать кэш, необходимо пройти следующий путь:

Созданные с помощью CacheManager’а стандартные кэши должны иметь совместимую с реализацией конфигурацию. Стандартная параметризованная конфигурация CacheConfiguration, предоставляемая javax.cache, может быть расширена под конкретную реализацию CacheProvider’a.
На сегодняшний день существуют десятки различных реализаций спецификации JSR-107: Ehcache, Guava, caffeine, cache2k. Многие реализации представляют собой In-Memory Data Grid в распределенных системах — Hazelcast, Oracle Coherence.
Также есть множество реализаций временных хранилищ, не поддерживающих стандартное API. Долгое время в своем проекте мы использовали Ehcache 2, не совместимый с JCache (реализация спецификации появилась с Ehcache 3). Потребность в переходе на JCache-совместимую реализацию появилась с необходимостью мониторинга состояния In-memory-кэшей. Используя стандартный MetricRegistry без проблем получилось прикрутить мониторинг только с помощью реализации JCacheGaugeSet, собирающей метрики со стандартного JCache.
Как же выбрать подходящую для вашего проекта реализацию In-memory-кэша? Пожалуй, стоит обратить внимание на следующее:
- Нужна ли вам поддержка спецификации JSR-107.
- Стоит также обратить внимание на быстродействие выбранной реализации. При больших нагрузках быстродействие внутренних кэшей может оказать существенное влияние на время отклика вашей системы.
- Поддержка в Spring. Если в своем проекте вы используете всеми известный фреймворк, стоит учитывать тот факт, что не каждая реализация JVM-кэша имеет совместимый CacheManager в Spring.
Если в своем проекте вы так же, как и мы, активно используете Spring, то для кэширования данных вы, вероятнее всего, придерживаетесь аспектно-ориентированного подхода (AOP) и используете аннотацию @Cacheable. Для работы аспектов в Spring использует собственный CacheManager SPI. Для работы спринговых кэшей необходим следующий бин:
@Bean
public org.springframework.cache.CacheManager cacheManager() {
CachingProvider provider = Caching.getCachingProvider();
CacheManager cacheManager = provider.getCacheManager();
return new JCacheCacheManager(cacheManager);
}
Чтобы работать с кэшами в парадигме AOP, необходимо также учитывать транзакционность. Спринговый кэш в обязательном порядке должен поддерживать управление транзакциями. С этой целью спринговый CacheManager наследует свойства AbstractTransactionSupportingCacheManager, с помощью которого можно синхронизировать put-/evict-операции, выполняемые внутри транзакции, и выполнить их только после успешного коммита транзакции.
В примере выше показано использование обертки JCacheCacheManager для кэш менеджера спецификации. Это значит, что любая реализация JSR-107 имеет также совместимость со спринговым CacheManager‘ом. Это еще один повод выбрать для своего проекта In-memory-кэш с поддержкой спецификации JSR. Но если эта поддержка все же не нужна, а использовать @Cacheable очень хочется, то для вас есть поддержка еще двух решений внутренних кэшей: EhCacheCacheManager и CaffeineCacheManager.
Выбирая реализацию In-memory-кэша, мы не учитывали поддержку IMDG для распределенных систем, о чем было упомянуто ранее. Чтобы сохранить производительность JVM-кэшей в нашей системе, мы написали собственное решение.
Очистка кэшей в распределенной системе
Современные IMDG, используемые в проектах с микросервисной архитектурой, позволяют распределить данные в памяти между всеми рабочими узлами системы, используя масштабируемое секционирование данных с необходимым уровнем резервирования.
В этом случае возникает множество проблем, связанных с синхронизацией, консистентностью данных и так далее, не говоря уже про увеличение времени доступа к временному хранилищу. Такая схема является избыточной, если количество используемых данных умещается в оперативной памяти одного узла, а для поддержания консистентности данных достаточно при любом изменении значения в кэше удалять эту запись на всех узлах.
При реализации такого решения первым в голову приходит идея использовать какой-нибудь EventListener, в JCache на событие удаления записи из кэша есть CacheEntryRemovedListener. Кажется, что достаточно добавить свою реализацию Listener’а, который будет отправлять сообщения в топик при удалении записи, и эвикт кэшей на всех узлах готов — при условии, что каждый узел слушает события из очереди, связанной с общим топиком, как было показано на схеме выше.
При использовании такого решения данные на различных узлах будут неконсистентны из-за того, что EventListener’ы в любой реализации JCache отрабатывают после наступления события. То есть, если в локальном кэше по заданному ключу записи нет, а на любом другом узле по такому же ключу запись есть, событие в топик не отправится.
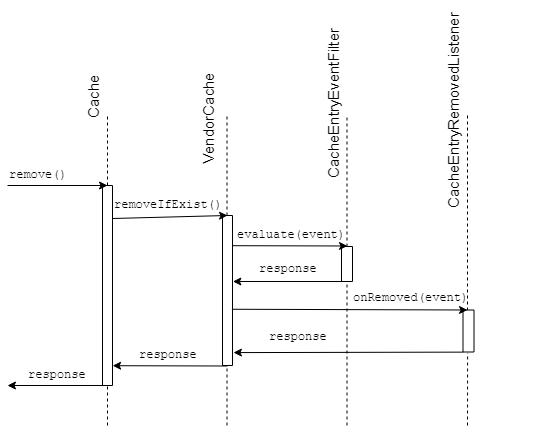
Рассмотрим, какие еще есть способы отловить событие об удалении значения из локального кэша.
В пакете javax.cache.event рядом с EventListener’ами лежит также CacheEntryEventFilter, который, согласно JavaDoc, используется для проверки любого события CacheEntryEvent перед передачей этого события в CacheEntryListener, будь то запись, удаление, обновление или событие, связанное с истечением срока нахождения записи в кэше. При использовании фильтра наша проблема останется, потому что логика будет выполняться после регистрации события CacheEntryEvent и после выполнения CRUD операции в кэше.
И все же можно поймать инициацию события удаления записи из кэша. Для этого следует воспользоваться встроенным в JCache инструментом, позволяющим использовать API-спецификации для записи и загрузки данных из внешнего источника, при их отсутствии в кэше. В пакете javax.cache.integration для этого есть два интерфейса:
- CacheLoader — для загрузки запрашиваемых по ключу данных, если записи отсутствуют в кэше.
- CacheWriter — для использования записи, удаления и обновления данных на внешнем ресурсе при вызове соответствующих операций у кэша.
Для обеспечения консистентности методы CacheWriter являются атомарными по отношению к соответствующей операции кэша. Кажется, мы нашли решение нашей проблемы.
Теперь мы можем поддерживать консистентность ответа In-memory-кэшей на узлах при использовании нашей реализации CacheWriter’а, отправляющей события в топик RabbitMQ при любом изменении записи в локальном кэше.
Заключение
В разработке любого проекта при поиске подходящего решения возникающих проблем приходится учитывать его специфику. В нашем случае характерные особенности модели данных проекта, унаследованный легаси-код и характер нагрузки не позволили использовать ни одно из существующих решений проблемы распределенного кэширования.
Очень сложно сделать универсальную реализацию, применимую к любой разрабатываемой системе. Для каждой такой реализации существуют свои оптимальные условия использования. В нашем случае специфика проекта привела к решению, описанному в данной статье. Если у кого-то возникла схожая проблема — будем рады поделиться нашим решением и опубликовать его на GitHub.
Комментарии (17)

leventov
08.11.2019 22:56Кажется маловероятным что IMDG типа Ignite и Hazelcast не поддерживают broadcast репликацию.

alexyakovlev90 Автор
09.11.2019 08:35Если есть решение без использования репликации, почему бы не использовать его?)
leventov
09.11.2019 11:37Ваше решение — не "без репликации", а с собственноручно написанной репликацией. Есть много тонких мест, в основном вокруг устойчивости к сбоям разного типа.
alexyakovlev90 Автор
09.11.2019 14:56Я имер ввиду репликацию IMDG кластеров.
Репликация в Hazelcast довольно сложно устроена, конечно она учитывает множество тех самых "тонких мест". Но судя по отзыву коллег, использование Hazelcast влечёт за собой существенное увеличение потребления CPU и памяти. После выпиливания Hazelcast тесты показали существенное уменьшение этих показателей. Всё таки обычная реализация кэша выигрывает, как минимум отсутствует необходимость постоянной сериализации/десериализации. Также ввиду сложности устройства IMDG решений, люди сталкивались с проблемой конфигурации, когда количество узлов приложения >2. Сталкивались с проблемой дублирования и потерей информации при выкатывании новых версий приложения.
alexyakovlev90 Автор
09.11.2019 15:10Мы посторались реализовать простое легко масштабируемое решение с минимальной конфигурацией. Возможно мы не учли всех узких мест в реализации, но цель мы достигли, производительность сохранили, согласованность не потеряли. А решение можно доработать в случае обнаружения потенциальных проблем.

maxim_ge
09.11.2019 01:11Downtime для нашего приложения недопустим.
Можно про это поподробнее? Каковы будут последствия, если та часть, которая отдает динамические данные, будет недоступна в течении, скажем, пары секунд в сутки?alexyakovlev90 Автор
09.11.2019 08:29При нагрузке в 500 rps за 2 секунды мы потеряем 1000 запросов от клиентов. Клиенты, которые не получат свои данные, открыв мобильное приложение, будут жаловаться на нестабильную работу. Недоступность сервиса приведёт к недовольным клиентам
maxim_ge
09.11.2019 10:47При нагрузке в 500 rps за 2 секунды мы потеряем 1000 запросов от клиентов.
Почему потеряем? Мобильный клиент может получить код 503 и повторить запрос через секунду.
PS: Интерес не праздный, сейчас проектируем и разрабатываем highload систему, так что весьма интересно, как это делается.alexyakovlev90 Автор
09.11.2019 15:08А как быть, если мобильный клиент использует десятки различных сервисов и берет данные из сотен методов. Если несколько серверов отваливается, то клиент будет их опрашивать какое то время, расходуя трафик и ресурс. Тут нужен контракт сколько раз опрашивать, с какой периодичностью, как понять, что сервис лежит, что при этом показывать клиенту. Кажется что в таком решении ещё множество подводных камней. Проще и правильнее на мой взгляд поддерживать бесперебойную работу бэкэнда и бесшовно релизить новые версии.
К тому же большинство клиентов как только не увидят какую то информацию сразу же пишут в поддержку, а это уже влечёт расход человек часов на обслуживание таких претензий.
SlavniyTeo
11.11.2019 17:03+2К сожалению, если Вы поддерживаете бесперебойную работу бэкэнда, бесшовно релизитесь, но не готовы к ситуации, когда несколько серверов отвалятся, может случиться что-то грустное.
Мы, к примеру, встречались с ситуацией, когда DNS-сервер в нашем Kubernetes кластере начал вести себя не очень хорошо. И все поды внутри кластера просто перестали резолвить друг друга. Вот Вам и бесшовность, и бесперебойная работа.
Интересность ситуации в том, что все установленные соединения (и уже зарезолвенные IP) продолжали работать. И проблема выплыла не сразу и сначала выглядела локальной: вот я пытаюсь поднять под (обновить один сервис, к примеру), но не получается.
К счастью, дело происходило на демо-серверах.
Не поддавайтесь иллюзии, что "облака" избавляют Вас от сложностей. Они только добавляют реальность сложности в инфраструктуру, а имеющуюся сложность — прячут.
alexyakovlev90 Автор
11.11.2019 23:10Причиной нашего перехода на k8s было не обеспечение надежной бесперебойной работы бэкэнда, все прекрасно работало и на виртуалках, и с этим было довольно просто работать, бесшовно релизить, оперативно устранять неисправности и т.д.
Kubernetes нам существенно облегчил жизнь, когда вместо одного приложения, работающего на двух машинах у нас стало 10+ сервисов, часть из которых являются горизонтально масштабируемыми. Главная причина использования оркестратора это избежать обслуживания большого количество виртуалок и докер контейнеров.
А для повышения надежности можно использовать два физически разделенных k8s кластера с установленной рабочей версией приложения, а внешний балансировщик будет форвардить трафик на один исправный кластер, мы сейчас думаем переходить на такое решение.
maxim_ge
Здравствуйте, Александр!
В смысле? Каким образом k8s отменяет борьбу с «тормозами»? Просто перезапуск приложения или что-то иное?
alexyakovlev90 Автор
Тормоза в приложениях зачастую бывают если на каком то участке образуется узкое горлышко, например образуется очередь ожидания в пуле соединений к БД или очередь потоков в пуле вебсервера. В этом случае может помочь Readiness проба, временно отключив трафик на проблемный узел. Тормоза могут возникнуть также если на узле отвалился внешний кэш или же проблема с самой виртуалкой, на которой создан под, переполнился heap, и тд, мы можем дать узлу приложения какое то время чтобы придти в себя, а если это не помогло просто поднять новый под сервиса и перевести часть трафика на него. Конечно если проблема в самом приложении нас это не спасет. Но если вдруг достигнут предел пропускной способности можно так же использовать механизм Autoscaling (HorizontalPodAutoscaler) в k8s
PrinceKorwin
С Readiness пробой надо быть аккуратнее, т.к. она может не только временно отключать новый траффик на поду, но также и убивать поду которая долго не ready не смотря на то, что данная пода находится под нагрузкой (обрабатывая долгоживующие операции, например).
Andrey_Rogovsky
И потом возникает эффект лавины
Типичный антипаттерн
Stamm
Поды убиваются не от readiness, а от liveness probes.
alexyakovlev90 Автор
Резонное замечание. Мы с таким еще не сталкивались. Предполагаю, что в таком случае либо readiness-проба настроена недолжным образом, либо неправильно настроен health-check приложения. Хотя, кажется, что под может убить только liveness-проба