Когда вопросы аналитики выходят за рамки готовых инструментов, вам, вероятно, пришло время выбрать базу данных для аналитики. Не стоит писать скрипты запросов к рабочей базе данных, потому что вы можете изменить порядок данных и, скорее всего, замедлить работу приложения.
Вы также можете случайно удалить важную информацию, если там работают аналитики или инженеры.
Для анализа нужен отдельный вид базы данных. Но какой из них верный?
В этом посте мы рассмотрим предложения и лучшие практики для средней компании, которая только начинает работать. Какую бы настройку вы ни выбрали, вы можете найти компромисс в дальнейшем, чтобы улучшить производительность по сравнению с тем, что мы обсуждаем здесь.
Работая с большим количеством клиентов, мы обнаружили, что наиболее важными критериями, которые необходимо учитывать, являются:
- Тип анализируемых данных
- Сколько у вас данных
- Фокус вашей инженерной команды
- Как быстро вам нужна информация
Какие типы данных вы анализируете?
Подумайте о данных, которые вы хотите проанализировать. Они хорошо вписывается в строки и столбцы, как огромная электронная таблица Excel? Или будет больше смысла, если вы поместите их в документ Word?
Если Вы ответили Excel, реляционная база данных как Postgres, MySQL, Amazon Redshift или BigQuery будет соответствовать вашим потребностям. Эти структурированные реляционные базы данных отлично подходят, когда вы точно знаете, какие данные вы собираетесь получать и как они связывают друг с другом — в основном, как связаны строки и столбцы. Для большинства типов пользовательского анализа реляционные базы данных работают хорошо. Такие признаки пользователя, как имена, электронные письма и планы выставления счетов, прекрасно вписываются в таблицу, как пользовательские события и их свойства.
С другой стороны, если ваши данные лучше помещаются на листе бумаги, вам следует обратиться к нереляционной (NoSQL) базе данных, такой как Hadoop или Mongo.
Нереляционные базы данных отличаются чрезвычайно большим количеством частных значений (миллионы) полуструктурированных данных. Классическими примерами полуструктурированных данных являются тексты, такие как электронная почта, книги и социальные сети, аудиовизуальные данные и географические данные. При выполнении большого объема интеллектуального анализа текста, языковой обработки или обработки изображений, скорее всего, потребуется использовать нереляционные хранилища данных.

С каким объемом данных вы имеете дело?
Следующий вопрос, который нужно задать себе, с каким количеством данных вы имеете дело. Чем больше у вас данных, тем полезнее будет нереляционная база данных, потому что она не будет накладывать ограничений на входящие данные, что позволит вам быстрее делать запись в базу.

Это не строгие ограничения, и каждый может обрабатывать больше или меньше данных в зависимости от различных факторов, но мы обнаружили, что каждая из баз данных отлично работает в этих пределах.
Если у вас меньше 1 ТБ данных, то с Postgres вы получите хорошую производительность. Но она замедляется на объемах около 6 ТБ. Если вам нравится MySQL, но нужны немного большие масштабы, Aurora (собственная версия Amazon) может достичь 64 ТБ. Для размера в петабайт Amazon Redshift обычно является хорошим выбором, поскольку он оптимизирован для выполнения аналитики до 2PB. Для параллельной обработки или даже данных MOAR, скорее всего, пора взглянуть на Hadoop.
Тем не менее, AWS сообщила нам, что они запускают Amazon.com на Redshift, так что если у вас есть первоклассная команда DBA, вы, возможно, вы сможете масштабироваться сверх 2PB «предела».
На чем сосредоточена ваша инженерная команда?
Это еще один важный вопрос, который нужно задать себе при обсуждении базы данных. Чем меньше ваша общая команда, тем больше вероятность того, что ваши инженеры сосредоточатся в основном на создании продукта, а не на обработке данных и управлении. Количество людей, которые вы можете посвятить этим проектам, сильно повлияет на ваши варианты.
С некоторыми инженерными ресурсами у вас есть больше вариантов выбора — вы можете перейти на реляционную или нереляционную базу данных. Реляционные БД отнимают меньше времени, чем NoSQL.
Если у вас есть несколько инженеров, которые работают над установкой, но не можете никого привлекать к обслуживанию, выбирайте что-то вроде Postgres, Google SQL (опционально хостинг MySQL) или Segment Warehouses (хостинг Redshift), вероятно, лучший вариант, чем Redshift, Aurora или BigQuery, поскольку они требуют периодического исправления обработки данных. Если у вас будет больше времени на обслуживание, выбор Redshift или BigQuery обеспечит более быстрые запросы в больших масштабах.
Реляционные базы данных имеют еще одно преимущество: для запроса к ним можно использовать SQL. SQL хорошо известен как аналитикам, так и инженерам, и его легче изучать, чем большинство языков программирования.
С другой стороны, для выполнения аналитики полуструктурированных данных обычно требуется, как минимум, опыт объектно-ориентированного программирования или, что лучше, опыт написания кода для работы с большими данными. Даже с появлением совсем недавно таких аналитических инструментов, как Hunk для Hadoop или Slamdata для MongoDB, для анализа этих типов баз данных потребуется опытный аналитик или специалист по данным.
Как быстро вам нужны эти данные?
В то время как «аналитика в реальном времени» очень популярна для случаев, таких как обнаружение мошенничества и мониторинг системы, большинство анализов не требуют данных в реальном времени или или немедленного анализа.
Когда вы отвечаете на вопросы, например, что вызывает отток пользователей или как люди переходят из вашего приложения на ваш веб-сайт, доступ к вашим данным с небольшой задержкой (ежечасные или ежедневные интервалы) вполне приемлем. Ваши данные не меняются минута за минутой.
Поэтому, если вы в основном работаете над фактическим анализом, вам следует обратиться к базе данных, оптимизированной для аналитики, такой как Redshift или BigQuery. Такие базы данных спроектированы так, чтобы вместить большой объем данных и быстро считывать и объединять данные, что делает запросы быстрыми. Они также могут загружать данные достаточно быстро (ежечасно), пока кто-то выполняет процесс очистки, изменяет размер и мониторит кластер.
Если вам абсолютно необходимы данные в режиме реального времени, вам следует обратиться к неструктурированной базе данных, такой как Hadoop. Вы можете спроектировать базу данных Hadoop так, чтобы данные в нее загружались очень быстро, хотя запросы к ней могут занять больше времени в зависимости от использования ОЗУ, доступного дискового пространства и структуры данных.
Postgres vs. Amazon Redshift vs. Google BigQuery
Вы, наверное, уже поняли, что для анализа большинства типов поведения пользователей лучшим выбором будет реляционная база данных. Информация о том, как ваши пользователи взаимодействуют с вашим сайтом и приложениями, может легко вписаться в структурированный формат.
analytics.track('Completed Order') — select * from ios.completed_order
Итак, вопрос в том, какую SQL базу данных использовать? Необходимо учитывать четыре критерия.
Размер vs. скорость
Когда вам нужна скорость, стоит рассмотреть Postgres: для базы менее 1TB, Postgres довольно быстра для загрузки данных и запросов. Плюс, она доступна. По мере приближения к размеру в 6TB (унаследованному от Amazon RDS) ваши запросы будут выполняться медленнее.
Поэтому, когда вам нужен больший размер, мы обычно рекомендуем Redshift. Наш опыт показывает, что Redshift имеет наилучшее соотношение цены и качества.
Изюминка SQL
Redshift построен на разновидности Postgres, и оба поддерживают старый добрый SQL. Redshift не поддерживает все типы данных и функции, которые поддерживает postgres, но он намного ближе к отраслевому стандарту, чем BigQuery, который имеет собственный SQL.
В отличие от многих других систем на основе SQL, BigQuery использует синтаксис с запятой для обозначения объединения таблиц, а не в соответсвии с документацией SQL. Это означает, что без осторожности запросы SQL могут привести к ошибкам или привести к неожиданным результатам. Поэтому многие команды, с которыми мы встречались, не могут убедить своих аналитиков изучать BigQuery SQL.
Third-party экосистема
Редко ваше хранилище данных живет самостоятельно. Вам нужно поместить данные в базу данных, и, кроме того, вам нужно использовать какое-то программное обеспечение для их анализа. (Если только вы не запускаете SQL-запрос из командной строки).
Поэтому людям часто нравится, что Redshift имеет очень большую экосистему сторонних инструментов. У AWS есть такие возможности, как Segment Data Warehouse для загрузки данных в Redshift из API-интерфейса аналитики, и они также работают практически со всеми инструментами визуализации данных на рынке. Меньше сторонних сервисов подключаются к Google, поэтому для переноса тех же данных в BigQuery может потребоваться больше времени на разработку, и у вас не будет столько вариантов для программного обеспечения BI.
Вы можете посмотреть партнеров Amazon здесь и Google здесь.
При этом, если вы уже используете Google Cloud Storage вместо Amazon S3, вам может быть выгодно остаться в экосистеме Google. Обе службы упрощают загрузку данных, если они уже существуют в соответствующем репозитории облачных хранилищ, так что, хотя это и не будут нарушать условия использования, будет намного проще, если вы остановитесь на использовании одного из этих провайдеров.
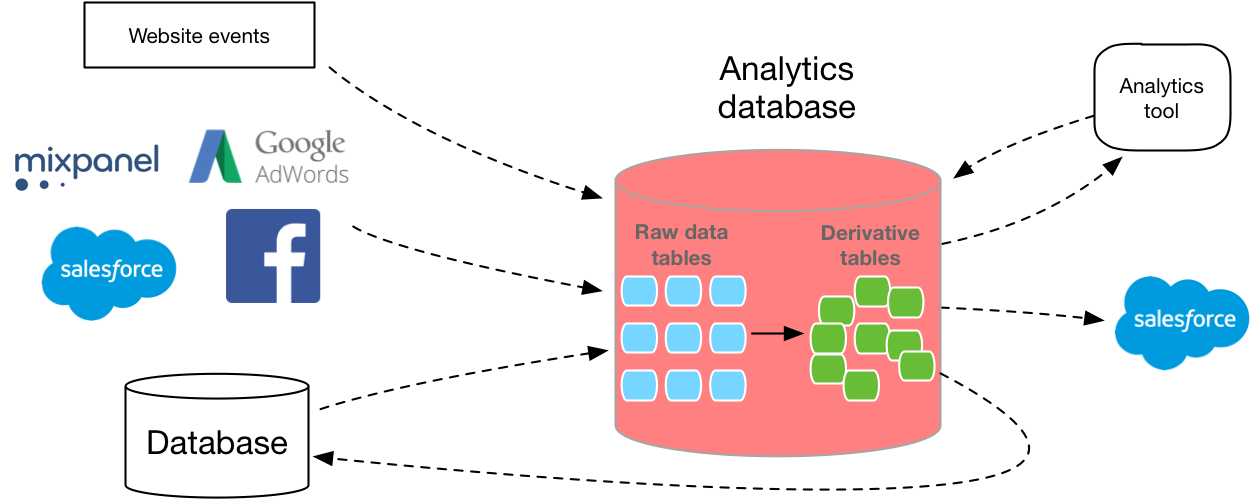
Подготовка
Теперь, когда у вас есть более четкое представление о том, какую базу данных использовать, следующим шагом будет выяснение того, как вы будете собирать данные в базу.
Многие новички в разработке баз данных недооценивают, насколько сложно построить масштабируемый конвейер данных. Вы должны написать свой собственный слой извлечения, API сбора данных, запросов и слой преобразования. И каждый должен масштабироваться. Кроме того, вам необходимо определить правильную схему с учетом размера и типа каждого столбца. MVP реплицирует вашу рабочую базу данных в новый экземпляр, но это обычно означает использование базы данных, которая не оптимизирована для аналитики.
К счастью, на рынке есть несколько вариантов, которые могут помочь обойти некоторые из этих препятствий и автоматически сделать ETL для вас.
Но будь то собственная разработка или покупка, получение данных в SQL того стоит.
На основании исходных пользовательских данных, только с помощью гибкого формата SQL вы сможете детально ответить на вопросы о том, что делают ваши клиенты, точно оценить распределение, понимать межплатформенное поведение, создавать панели мониторинга для конкретной компании и многое другое.

sshikov
>нереляционной (NoSQL) базе данных, такой как Hadoop
Hadoop не является и не позиционирует себя как база данных какого-либо типа. В том числе и NoSQL.
nehaev
Может имелся в виду HDFS? Сформулировано не очень корректно, да.
puyol_dev2 Автор
Мне кажется автор имел схожие принципы работы с NoSQL и Hadoop
sshikov
Ну опять же, если совсем строго — то в хадупе есть только HDFS и MR, чем они схожи с noSQL — я не улавливаю.
puyol_dev2 Автор
Именно принципы работы со стороны пользователя (аналитика). Загрузка и обработка данных, например. Но это другое конечно
sshikov
А с чего вдруг вполне обычная файловая система вдруг стала базой данных? Базой там работает Hive (скорее реляционная, чем не), или Hbase (скорее key-value, чем что-либо другое, и то поверх нее вполне прикручен SQL). И в общем-то никто из них не часть хадупа, если уж совсем строго подойти.
А хадуп — это тупо yarn, который планировщик задач (и вообще не база), HDFS (которая тоже не база совсем), и движок MR — ну и он тоже не база, с какой стороны ни посмотри.
В общем, ученый изнасиловал журналиста…