На самом деле, почти всегда доступна альтернатива в виде распараллеливания выполняемой задачи. Конечно, параллельные алгоритмы несколько сложнее — балансировка нагрузки, синхронизации между потоками, а так же, в случае разделяемых ресурсов, борьба с ожиданием на блокировках и избегание deadlock’ов. Но, как правило, оно того стоит.
Об этом мы сегодня и поговорим… в контексте 1С Предприятия.
Практически во всех современных языках есть необходимый инструментарий для реализации параллелизма. Но не везде этот инструментарий удобен для использования. Кто-то скажет: «Ну и что тут сложного и не удобного? Платформенный механизм фоновых заданий в руки и вперед!». На практике оказалось не так все просто. А что если задача бизнес-критичная? Тогда нужно обеспечить, во-первых, гарантированное выполнение заданий и, во-вторых, мониторинг работы подсистемы выполнения заданий.
Ничего из этого механизм фоновых заданий не предоставляет.
Фоновое может “упасть” в любой момент. Вот только небольшой список возможных ситуаций:
- администратор для проведения регламентных работ завершил все сессии;
- внешний ресурс, требуемый на момент выполнения задания, был недоступен в течении какого-то времени;
- у части заданий после очередного обновления могут появится ошибки в коде, фоновое будет остановлено по эксепшену и, кроме записи в журнал регистрации, никому ничего не сообщит.
Получается, что необходимо отслеживать работу фоновых, исправлять проблемы и ставить «упавшие» задания на повторное выполнение. Ручное управление этим добром без автоматизации сценариев управления и централизованного контроля, мягко говоря, еще то «удовольствие».
Хочется иметь возможность гибкого управления запускаемыми заданиями с обратной связью, с учетом ошибок, с гарантированным запуском, и все это примерно с той же легкостью, какая существует в других языках и фреймворках для параллельных заданий.
Для облегчения собственной жизни была разработана универсальная библиотека, позволяющая легко создавать параллельные алгоритмы с гарантированным выполнением в среде 1С Предприятия на базе фоновых заданий.
Область применения
- Использование параллельных вычислений в автоматизации бизнес процессов;
- Параллельное выполнение запросов в долгих отчетах/обработках;
- Процессы загрузки/выгрузки данных;
- Организация нагрузочного тестирования.
Основной принцип работы
Добавляется задание очень просто — нужно указать точку входа (путь к экспортному методу с серверным контекстом в общем модуле или модуле менеджера) и кортеж с параметрами в виде структуры:
мзЗадания.ДобавитьЗадание("Тестирование.Уснуть", Новый Структура("Секунды", 3));
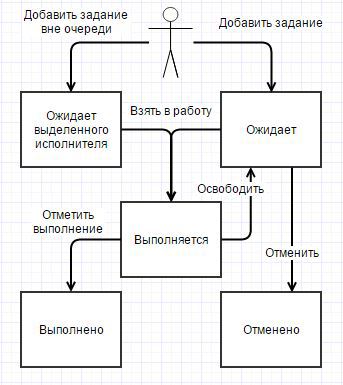
При этом происходит запись в регистр сведений мзЗадания. Первоначально задание имеет состояние Ожидает. Метод возвращает КлючЗадания для возможного отслеживания прогресса в основном клиентском потоке. Кортеж с параметрами так же расширяется свойством КлючЗадания, чтобы при выполнении задания был контекст, он иногда может быть полезен.
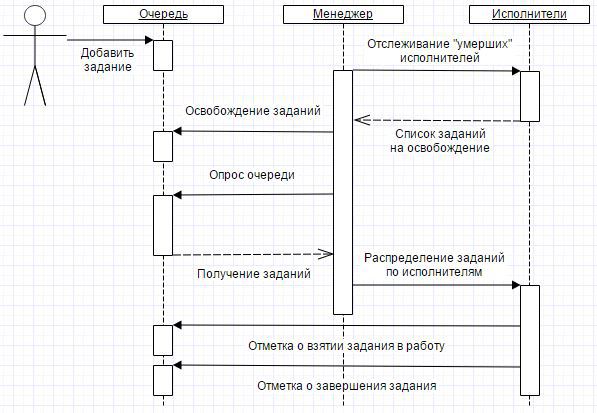
Далее, раз в минуту просыпается Менеджер, который первым делом проверяет исполнителей и освобождает задания, исполнители которых «умерли». Проверка заключается в следующем. Если задание в состоянии Выполняется и прописанное в качестве исполнителя фоновое не активно (удалено администратором, возникла исключительная ситуация в коде и т.д.), то задание возвращается в очередь. Для этого у задания выставляется состояние Ожидает.
Следующим шагом запрашиваются из очереди задания в соответствии с настройками балансировки нагрузки (сейчас это только ограничение на количество одновременно работающих исполнителей).
После этого Менеджер под каждое задание запускает Исполнителя. В качестве исполнителей выступают те самые фоновые задания платформы 1С.
При запуске Исполнитель делает отметку, что взял задание в работу — прописывает свой уникальный идентификатор у задания в свойстве КлючИсполнителя и выставляет состояние задания в Выполняется.
Когда задание выполнено, Исполнитель так же делает соответствующую отметку в задании — состояние Выполнено.
Для использования подсистемы в оперативном режиме есть метод ДобавитьЗаданиеВнеОчереди. При этом сразу запускается Исполнитель, минуя Менеджера, и забирает новое задание. Сигнатура такая же, как у основного метода ДобавитьЗадание. На такие задания ограничение на количество исполнителей НЕ распространяется, НО квота используется.
Так же есть возможность отменять задания в очереди методом ОтменитьЗадание. При этом отменять можно только задания, находящиеся в состоянии Ожидает. Уже запущенные задания не отменяются, поскольку:
- У фоновых заданий вроде как есть метод отмены, но он работает для меня не прозрачно. Очень часто наблюдал картину, когда длительное фоновое задание дорабатывало до конца несмотря на отправленную команду отмены;
- Не хочется оставлять систему в неконсистентном состоянии. Кто знает, как именно написан код задания и что он делает в базе данных?
Для удобного управления рабочим процессом предусмотрены следующие методы:
- ДождатьсяВыполнения(КлючиЗаданий, Таймаут = 5) — усыпляет текущий поток до выполнения указанного списка заданий, либо до истечения указанного времени;
- ОжидатьСостояниеЗадания(КлючЗадания, ОжидаемоеСостояние, Таймаут = 5) — усыпляет текущий поток до установления указанного состояния у задания, либо до истечения указанного времени;
- ОжидатьИзмененияСостояния(КлючЗадания, ТекущееСостояние, Таймаут = 5) — усыпляет текущий поток до изменения состояния у задания с указанного на любое другое, либо до истечения указанного времени.
Исходя из сказанного выше, жизненный цикл задания выглядит следующим образом:
Настройка
Для настройки есть специальная обработка «Управление менеджером заданий»:

Доступные настройки:
- Ограничение на количество исполнителей — для балансировки нагрузки на сервере 1С. Принимает значение от 0 до 9999. При значении 0 задания в работу браться не будут.
- Глубина хранения истории (дни) — если указано значение отличное от 0, тогда подсистема сама будет чистить информацию по старым выполненным заданиям оставляя последние N дней указанных в настройке.
Запуск подсистемы, остановка и очистка очереди выполняется верхними, говорящими за себя кнопками.
В качестве индикатора работы подсистемы выступает флаг Менеджер запущен.
Тут же есть поверхностный мониторинг, который может показать, насколько система справляется с заданиями. Показатели:
- Количество активных исполнителей;
- Количество заданий в очереди (в состоянии Ожидает);
- Всего активных заданий (п.1 + п.2).
Показатели автоматически обновляются раз в минуту. Можно явно обновить, нажав на соответствующую кнопку. При желании, можно заглянуть в сам регистр заданий. Там есть возможность посмотреть, когда задания брались в работу и как долго выполнялись, там же есть счетчик количества попыток выполнения задания.
Расширенный мониторинг сильно зависит от области применения и оставлен на откуп потребителям подсистемы.
Примеры использования
Использование параллельных вычислений в автоматизации бизнес процессов
Например, расчет заработной платы можно распараллелить по сотрудникам, потому что расчет зарплаты одного сотрудника, как правило, не зависит от расчета зарплаты другого сотрудника. (Приведенный код всего лишь иллюстрирует возможности подсистемы, и никак не связан с типовыми конфигурациями 1С.)
Процедура ВыполнитьРасчетЗаработнойПлаты(Месяц) Экспорт
Сотрудники = ПолучитьДействующихСотрудников();
ПараметрыЗадания = Новый Структура("ПериодРасчета, Сотрудник", Месяц);
Для каждого Сотрудник Из Сотрудники Цикл
ПараметрыЗадания.Сотрудник = Сотрудник;
КлючЗадания = мзЗадания.ДобавитьЗадание("Обработка.РасчетЗаработнойПлаты.ВыполнитьРасчетПоСотруднику", ПараметрыЗадания);
КонецЦикла;
КонецПроцедуры
Параллельное выполнение запросов в долгих отчетах/обработках
Процедура ВыполнитьОтчет(ПараметрыОтчета) Экспорт
Задания = Новый Массив;
Задания.Добавить(мзЗадания.ДобавитьЗадание("РегистрНакопления.Остатки.ПолучитьОстаткиНаНачалоМесяца", ПараметрыОтчета));
Задания.Добавить(мзЗадания.ДобавитьЗадание("РегистрНакопления.Продажи.ПолучитьОборотыЗаМесяц", ПараметрыОтчета));
Задания.Добавить(мзЗадания.ДобавитьЗадание("РегистрНакопления.Остатки.ПолучитьОстаткиНаКонецМесяца", ПараметрыОтчета));
Успех = мзЗадания.ДождатьсяВыполнения(Задания);
Если Успех Тогда
ЭкономическиеПоказатели = РассчитатьЭкономическиеПоказатели(Задания);
ВывестиНаЭкран(ЭкономическиеПоказатели);
Иначе
Сообщить("Отчет все еще строится, по мере готовности он будет доступен в интерфейсе ""Долгие отчеты""");
мзЗадания.ДобавитьЗадание("Отчеты.ЭкономическиеПоказатели.ДоделатьИОпубликоватьВДолгихОтчетах", Новый Структура("Задания", Задания));
КонецЕсли;
КонецПроцедуры
Процессы загрузки/выгрузки данных
Процедура ЗагрузитьЦеныПоставщиков() Экспорт
Поставщики = ПолучитьАктивныхПоставщиков();
ПараметрыЗадания = Новый Структура("Поставщик");
Для каждого Поставщик Из Поставщики Цикл
ПараметрыЗадания.Поставщик = Поставщик;
КлючЗадания = мзЗадания.ДобавитьЗадание("Обработка.РаботаСПоставщиками.ЗагрузитьЦеныПоставщика", ПараметрыЗадания);
КонецЦикла;
КонецПроцедуры
Организация нагрузочного тестирования
Процедура ЗапуститьНагрузочныйТестПриходнойНакладной(ВозможныеСценарииПриходнойНакладной) Экспорт
ГенераторСлучайныхЧисел = Новый ГенераторСлучайныхЧисел();
Для Сч = 1 По 10000 Цикл
ИндексСценария = ГенераторСлучайныхЧисел.СлучайноеЧисло(0, ВозможныеСценарииПриходнойНакладной.ВГраница());
Сценарий = ВозможныеСценарииПриходнойНакладной[ИндексСценария];
КлючЗадания = мзЗадания.ДобавитьЗадание("Документы.ПриходнаяНакладная.ЗапуститьСценарий", Сценарий);
КонецЦикла;
КонецПроцедуры
Исходники и прочее
Подсистема доступна на github/TaskManagerFor1C. CF файл открыт, так что можно ознакомиться с исходными кодами.
Подсистема разрабатывалась через тестирование (TDD), тесты доступны во внешней обработке /Тесты/Тесты_МенеджерЗаданий.epf. Для запуска тестов нужен инструментарий xUnitFor1C.
Обратная связь приветствуется. С удовольствием отвечу на все возникшие по инструменту вопросы.
Комментарии (30)

ZEEGIN
10.04.2015 00:56Распараллеливание на фоновых заданиях — это круто. Я делал синхронизацию между потоками исполнения. Но как сделать адекватное ожидание данных в потоке от другого потока так и не придумал. =(
Код#Region PublicInterface // Parameters // size - integer - count of process // comm - string - module and procedure name // param - structure - structure of parameters of the procedure // Procedure Init(size, comm, param = Undefined) Export CommParam = new Structure; CommParam.Insert("size", size); CommParam.Insert("comm", comm); JobParam = new Array; JobParam.Add(CommParam); JobParam.Add(param); For i = 1 to size Do commParam.Insert("rank", i); BackgroundJobs.Execute(comm, JobParam, i); EndDo EndProcedure // Parameters // comm - string - module and procedure name // rank - integer - key of the process if Undefined wait all process in comm // Procedure Wait(comm, rank = Undefined) Export Selection = New Structure("MethodName, State", comm, BackgroundJobState.Active); If rank <> Undefined Then Selection.Insert("Key", rank); EndIf; ArrayOfJobs = BackgroundJobs.GetBackgroundJobs(Selection); BackgroundJobs.WaitForCompletion(ArrayOfJobs); EndProcedure // Parameters // buf - any - module and procedure name // dest - integer - key of the destination process // msgtag - integer - tag to devide messege from one sourse // comm - structure - construct in Init // Procedure Send(buf, dest, msgtag, comm) Export Param = new Structure; Param.Insert("buf", buf); Param.Insert("dest", dest); Param.Insert("source", comm.rank); Param.Insert("msgtag", msgtag); Param.Insert("comm", comm.comm); Message = new UserMessage; Message.Text = ValueToStringInternal(param); Message.Message(); EndProcedure // Parameters // source - integer - key of the source process // msgtag - integer - tag to devide messege from one sourse // comm - structure - construct in Init // // Return // any // Function Recv(source, msgtag, comm) Export Selection = New Structure("MethodName, Key", comm.comm, source); ArrayOfJobs = BackgroundJobs.GetBackgroundJobs(Selection); If ArrayOfJobs.Count() < 1 Then Return Undefined; EndIf; Job = ArrayOfJobs[ArrayOfJobs.Count() - 1]; While True Do Messages = Job.GetUserMessages(); Count = Messages.Count() - 1; For i = 0 to Count Do Value = ValueFromStringInternal(Messages[i].Text); If Value.dest = comm.rank And Value.source = source And Value.comm = comm.comm And Value.msgtag = msgtag Then Return Value.buf; EndIf EndDo; EndDo; EndFunction #EndRegion

wizi4d Автор
10.04.2015 15:01Я правильно понимаю, что это 1С на английском? Очень непривычно.
Интересное у Вас решение по передаче информации между фоновыми. Я в таком направлении даже не думал.
Когда мне нужно между заданиями передать информацию, я использую общее хранилище значений. В качестве идентификатора в хранилище использую ключ задания.ZEEGIN
10.04.2015 17:51С хранилищами тоже можно. Но там разные тонкости со сборщиком мусора. По сути хранилище считается помеченным к очистке в памяти после окончания существования объекта, с чьим идентификатором запустили задание. Например если хранилище создано с идентификатором формы, то оно будет помечено к очистке только после закрытия формы. Может получиться неприятная ситуация с потерей переданных данных. А сообщения, отправленные заданием можно прочитать даже после его выполнения.
Но с общим хранилищем может быть и не важно это. Надо почитать про него по подробнее.wizi4d Автор
10.04.2015 19:10Я с названием ошибся. Имелось в виду хранилище настроек, там можно свои произвольные данные хранить. Оно в БД хранится, нужно не забывать чистить.

pvasili
10.04.2015 23:54Хорошее начинание. Когда увидим что-то из этих радостей в типовых?
И при пере-проведении документов или формировании какого-нибудь большого отчёта можно будет спокойно переключиться и заниматься работой дальше, а не ждать пару часов или запускать 2-ю копию.

Melex
26.04.2015 13:45В целом подход не новый, как и его проблемы. Но, попробовал такой подход на мобильной 1с, где он дал бы не малый прирост к скорости, а оказалось — что все эти процессы выполняются последовательно:)

Rupper
26.04.2015 17:00смотря что делают процессы. Если вы на множители числа раскладываете, то на мобильном одноядерном процессоре эффекта не будет. Однако, если каждый поток большую часть времени ожидает чтения из сокета, то эффект будет значительный (по количествую потоков.
Melex
26.04.2015 22:39Еще раз и внимательно прочтите что я написал :)
Повторюсь — все фоновые задания выполняются последовательно. А это значит, что как бы вы не разбивали, а на что бы вы не разбивали, и даже на 100500 ядерном процессоре — прироста не будет.
Алгоритм простой — второе фоновое задание выполняется только тогда, когда выполнилось первое :)
Есть конечно вариант попробовать запускать их из уведомлений, но тут уже дело такое, надо пробовать.Rupper
27.04.2015 10:18Т.е. в Ваших приложениях отсутствовали внутренние блокировки, и приложение часто делало вызовы к ядру, и при этом потоки выполнялись исключительно последовательно?
Возможно, это особенность мобильной платформы 1С (например блокировка есть в интерпретаторе языка).
Но еще хочу уточнить — а как Вы определили, что потоки последовательно выполняются? Может, это только кажется?
Не специалист по 1С, и до сих пор думал, что в данном случае не надо им было так косячить :)ZEEGIN
27.04.2015 10:28Ну это не косяк платформы. Ведь такое поведение документировано. По крайней мере для толстого, тонкого и веб-клиента в файловом варианте. А по сути мобильное приложение так же из себя представляет файловый вариант базы.
v8.1c.ru/o7/201305fi/index.htm
Естественно при использовании клиент-серверной архитектуры поведение будет другим, и там возможно выполнение параллельно нескольких фоновых заданий.Melex
27.04.2015 15:30Ну, с другой стороны — фоновые задания выполняются с веб сервера, если память мне не изменяет.
А вот на мобильной платформе такого нет. Тем более — если делать вызов функций уведомлениями, тут прослеживается потенциальная возможность распараллеливания процессов.
Т.е. не все так однозначно :)

noxxx
28.04.2015 15:12Прекрасная штука, взял себе, спасибо.
Есть у меня одна обработка, которая с периодичностью в N часов производит изменения в ~30 000 товаров. Последовательно это занимает около 3 часов, поэтому хочу это распараллелить. Изменения независимы друг от друга, поэтому Ваш механизм подходит. Но вот вопрос — сколько одновременных исполнителей можно ставить? Можно ли поставить 100? 500? На что это влияет? Память будет адски отжирать?ZEEGIN
28.04.2015 15:26При добавлении потоков больше чем фактически ядер в кластере, часть потоков будет выполняться последовательно вытесняя друг друга, а на синхронизации между такими потоками большая потеря времени.
wizi4d Автор
28.04.2015 15:38+1Опираться только на фактическое число ядер в кластере я бы не стал. Как правило, потоки простаивают на ожидании данных от СУБД, дисковой подсистемы, сети и т.п. При этом ядро вполне успешно может использоваться другим потоком.
Из практики, на сервере 1С с 8 ядрами постоянно работают 30 исполнителей, которые выполняют очень ресурсоемкие для задания. Значение было получено экспериментальным методом. Система в равновесном состоянии — уменьшение количества исполнителей приводит к увеличению времени обработки заданий, увеличение — не уменьшает время.
wizi4d Автор
28.04.2015 15:31По количеству исполнителей, простого ответа нет. Ресурс, который станет узким местом при распараллеливании, зависит от прикладного кода внутри заданий и железа (сервер 1С и СУБД). Кроме ресурсов, узким местом могут стать блокировки.
Самый простой способ — провести тесты с разным количеством исполнителей. В качестве отправной точки выбрать значение, которое подсказывает опыт. При этом наблюдать за работой системы и посматривать в журнал регистрации. Заодно можно выявить места для оптимизации.
Rupper
А что происходит с транзакциями при таких параллельных вычислениях в 1С?
Каждое задание в отдельной транзакции или все в одной? какой DTS используется тогда?
wizi4d Автор
Каждый исполнитель — это отдельная сессия и свои транзакции при работе с БД. Чтобы не было проблем с блокировками нужно свести к минимуму общие ресурсы между исполнителями.
Rupper
Однако, тогда данные в приведенном Вами примере сотчетом будут неконсистентными. Таблицы могут произвольным образом изменится.
wizi4d Автор
Консистентность данных, как правило, важна в алгоритмах с пишущими транзакциями. Отчеты же строятся используя запросы с хинтами NOLOCK иначе они будут сильно тормозить работу системы.
Rupper
Я о другом. У Вас данные запрашиваются в 3-х разных транзакциях. Кроме того, время реального выполнения запроса неизвестно. Так что данные у вас могут быть рассогласованы, и консолидированный отчет будет содержать билиберду.
Просто стоить отметить, что такая реализация параллельной обработки имеет весьма опасные последствия.
Во-первых кажущаяся легкость распараллеливания. Однако, из-за того, что все задачи выполняются в разных транзакциях могут возникать ошибки подобные описанной выше. Во-вторых, такие ошибки крайне сложно искать — они недетерминированны и могут не воспроизводится под дебагером, да и вообще требовать весьма специфических условий для воспроизведения (например на одном серваке есть ошибка, на другом нет).
Кроме того, ошибка может проявлять себя не как исключение (exception), а как ошибка в рассчетах, тогда это совсем гиблый случай кто и когда заметит такое.
wizi4d Автор
Разве качество отчета повысится за счет отказа от распараллеливания, при условии, что запросы будут выполнены с NOLOCK?
Rupper
Я не знаю, что такое NOLOCK. Я знаю что такое транзакции :)
Речь не про конкретный пример, а про то, что при такой реализации есть подводные камни, про которые имеет смысл сказать. Привожу более конкретный пример (просто из головы).
Процесс заключается в том, что сразу после оприходования товара на складе его необходимо списать документами продажи.
Оригинальная обработка выглядит так (мне C# ближе):
Очевидное распараллеливание:
Проблема в том, что такая реализация может великолепно отработать на тестах.
Оставлю интригу и напишу в чем проблема чуть позже :) Если меня не опередят конечно.
EvilBeaver
При написании параллельных штук, все-таки, нужно учитывать, что фоновые задания 1С это отдельные сеансы и так же, как на C# в рамках одной транзакции пример со списанием сделать не получится. А вот если данные достаточно независимы в каждой из порций, то упрощение управление заданиями (за счет фреймворка) значительно облегчит жизнь.
С отчетом, наверное, тоже. Зависит от специфицики данных в отчете.
Rupper
Ну какая разница отдельные или нет? Параметры передать можем, значит и на 1С переписать мое тоже можно.
А вот независимость данных штука очень мрачная — в приведенном примере ее не замечали месяц.
wizi4d Автор
Проблема о которой Вы пишите понятна, она связана с изменением данных.
Так же совершенно справедливо, что не каждый алгоритм можно распараллелить.
Что же касается отчетов и NOLOCK (он же READUNCOMMITTED) — хинт используется для не блокирующего чтения. В момент пока выполняется SELECT тысячи других транзакций могут изменять вычитываемые данные. Если же отказаться от не блокирующего чтения, то получим огромные проблемы с производительностью базы данных.
Rupper
Речь не о том, можно ли параллелить алгоритм, а в транзакциях. Приведенный пример отлично будет работать в MySQL без транзакций (точнее — никаких спецэффектов не появится). Его можно выполнить на MS и Oracle использованием распределенных транзакций, и его можно переписать так, что он будет выполнятся так же и без спецэффектов.
EvilBeaver
Ну так это в любом многопоточном софте )