Расшифровка доклада Дмитрия Костичева с Backend-stories // Видеоверсия внутри
Если вдруг у вас появилась необходимость интеграции на стороннем интернет-ресурсе, а разбираться в нем нет времени, на помощь придет Selenium. Дмитрий Костичев рассказал на примере своего проекта, как автоматизировать работу в браузере, не выходя из вашего сервиса.
Привет всем. Меня зовут Дмитрий и я сегодня поделюсь опытом использования Selenium в Backend-разработке. Для чего это вообще нужно? Selenium нужен для автоматизации взаимодействия с какими-то интернет-ресурсами, чтобы нивелировать человеческие факторы заполнений каких-то данных и т.д. Для разработки это может понадобиться в таких случаях, когда, например, на интернет-ресурсе не бывает API и так далее. И на примере моего проекта была задача — заполнить клиентские данные (перед этим сервис должен был правильно подготовить всю информацию) и зарегистрировать их на этом сайте, в данном случае MasterCard.
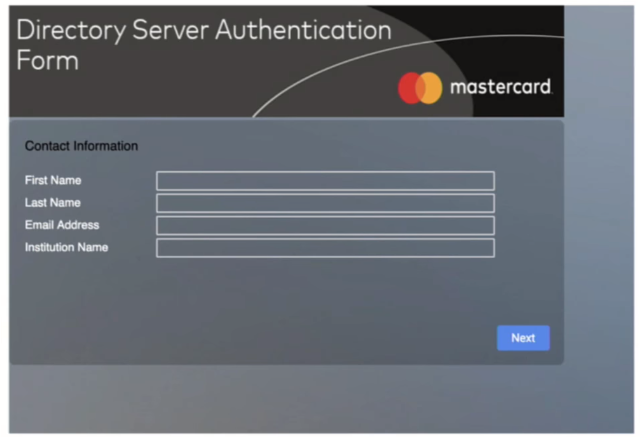
При дальнейшем рассмотрении этого сайта было выявлено, что тут нет api, к которому мы можем достучаться и все сделать. Вся обработка производится в JS-cкриптах, в которых ничего не понятно и данные все кодируются. Решение было принято — попробовать Selenium в этих целях, то есть мы прикрутим к Selenium весь наш сервис, который будет в какие-то определенны моменты проводить эту регистрацию.
В итоге, что же такое Selenium и как с ним работать? Проект Selenium состоит из библиотеки, которая общается с интерфейсом веб-драйвера под определенный браузер. Список доступных библиотек и браузеров приведен на слайде. И сейчас я покажу, как это примерно работает на моем проекте.
Посмотреть скринкаст или подробное видео в конце поста.
Сейчас сервис будет генерить файлик, сразу же его закачает на этот сайт и проверит, все ли успешно было зарегистрировано. Вот, собственно, он проклеивает, загружает и так далее. И сейчас он, наверное, прыгнет на то, что все будет успешно. Автоматизация достаточно быстро работает и не требует каких-то больших ресурсов. Все, как видно, отлично зарегистрировалось.
Как же все это приготовить? Библиотека Selenium имеет такие основные команды, как:
Веб-драйвер позволяет получать сессии и куки как в обычном браузере. Также их можно изменить и кастомизировать под себя. Еще можно выполнять js-скрипты на страничке. Есть библиотека, расширяющая этот функционал самого Selenium, под названием Selenide. Основная его фишка — скрывать создание Instance драйверов. На примере мы видим, что мы просто вызываем команду open, даем какую-то ссылку и браузер уже запускается, не нужно ничего настраивать. А еще библиотечка расширяет работу с элементами, какие-то дополнительные пресеты. Выглядит все это удобно, можно быстро со всем этим разобраться и использовать.
При работе с интернет-ресурсами, и в конечном итоге с Selenium есть некоторые паттерны проектирования. И один из них — page objects. Суть его заключается в том, что мы описываем в определенном классе все эти элементы. И дальше можем его переиспользовать и это выглядит проще. Вот, примерно так: вызываем команду open, даем page objects class и дальше можем использовать все его методы, например, работу с элементами.

Поиск элементов у нас осуществляется по DOM модели HTML страницы по таким селекторам, как xpath, css и другие. Основные их отличия, например между xpath и css, так это то, что xpath может ходить «вглубь», а также вверх и вниз. А css, наоборот, только вниз. То есть, это самые используемые селекторы.

В конечном итоге нам потребуется непосредственно браузер, в чем нам может помочь непосредственно Selenoid. По сути, это фреймворк, который управляет созданием и изменением этих контейнеров с браузерами. Но он рассчитан больше для нагруженных систем, где эти браузеры создаются в большом количестве. И в нашей ситуации это не сильно потребуется, а только сам контейнер использовать. И сейчас я покажу, как это должно работать уже на сервере.
Собственно, взаимодействие странички выглядит примерно так, это достаточно линейная обработка данных. В этом случае я разделил на шаги — переходы на странички. Здесь происходит заполнение данными и, непосредственно, загрузка файлами. В принципе, все достаточно просто. Примерно вот так выглядит pageobject-class, достаточно напоминает ДТО-шку. Просто описываем элементы, например, здесь в текущем случае PCSS Selectum. Это синтаксис Selenide.
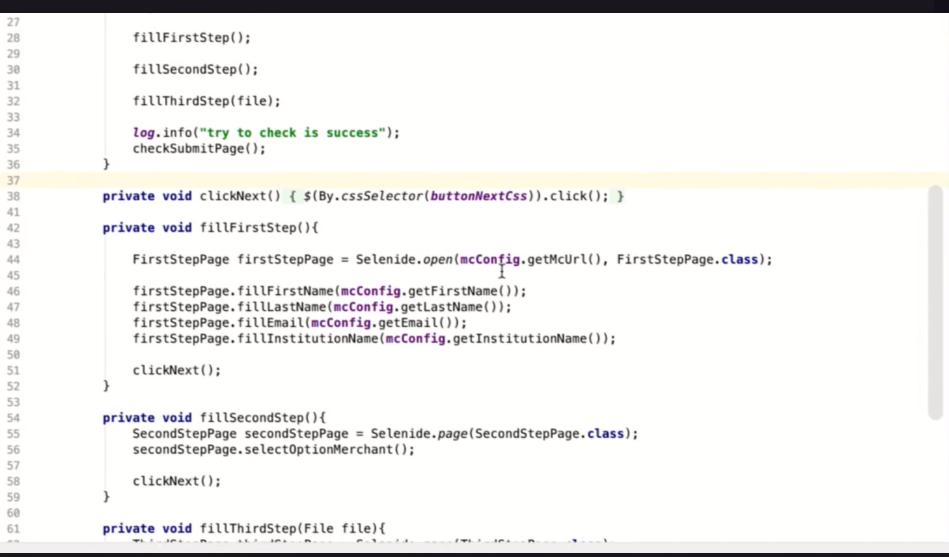
Чтобы это все заработало, нам понадобится описание Remote-драйвера, чтобы подключиться к докер-контейнеру. Основные настройки, которые туда нужно прокинуть, это выбор браузера, который мы будем использовать и, собственное, разрешение и другие важные строки для браузера. Но для того, чтобы работать с докер-контейнером потребуются еще такие настройки как headless-режим. То есть, в текущем виде это будет крутиться на сервере. Этот режим отключает графику в браузере, поэтому он будет работать быстрее и занимать меньше ресурсов.
Далее это будет no Sandbox, который отключается безопасностью Chromium в этом случае, и можно будет исполнять свой код, JS или другой. Третий параметр нужен для того, чтобы Chromium нормально работал на unix машинах, правильно записывал темповые файлы. И четвертый, собственно, нужен для того, чтобы нам загружать файлы. И самое главное, у Remote-драйвера есть флаг, который позволяет загружать файл из локального хранилища, где работает приложение, уже через Remove драйвер.

Сейчас я покажу, как это работает с докер-контейнером. Загружаем докер-контейнер и само приложение. Он примерно также будет запускаться, то есть, в принципе, ничего нового не будет. Только здесь мы будем видеть взаимодействие в каких-то логах. В принципе, их также можно мониторить, с ними работать и так далее. Поэтому можно понять взаимодействие, что происходит. Это вывод из докер-контейнера с Chromium непосредственно, где браузер стоит.
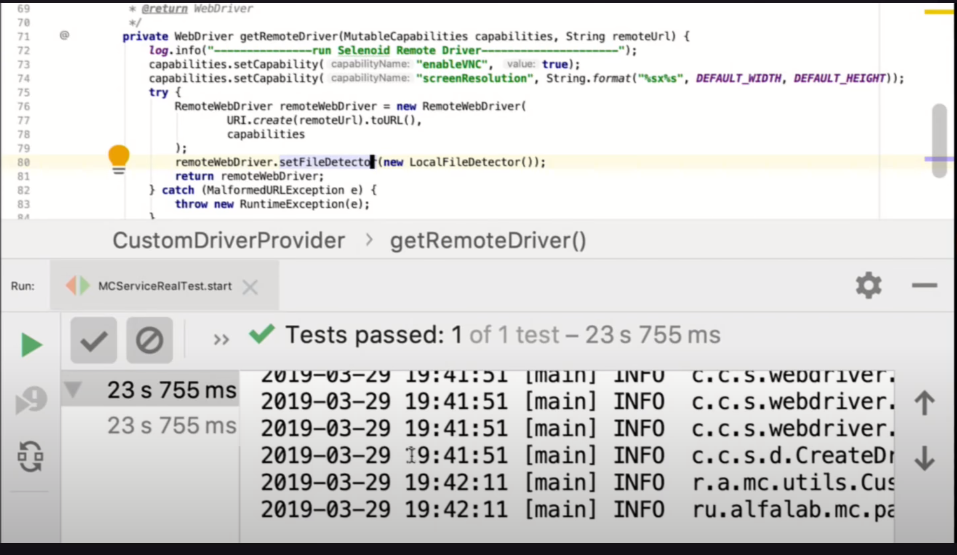
В принципе, все отлично работает с докер-контейнером. Также все проверяется и успешно завершена регистрация. Далее, какие вообще проблемы можно было бы встретить в таком подходе? У меня была не столько проблема, сколько незнание. Передачи файлов в докер-контейнере как обычно все делают — черед volume. Но в этом случае, если еще хочется локально запускать, то нужно иметь две конфигурации для проекта, но, как оказалось, Remote драйвер умеет через флаг настраиваться. Он может передавать этот файл непосредственно через себя, и не нужны никакие дополнительные телодвижения.
Также придется следить за страничкой, с которой мы работаем — интернет-ресурсом. Потому что, в моем случае, это другая система, к которой никто не имеет отношения из моей команды, и за этим нужно тоже следить, мониторить по логам и так далее. Так же и с браузером, он постоянно обновляется, за ним нужно следить, поддержка может упасть. Ну в принципе, по логам можно как-то настроить и никаких проблем не будет.
В итоге, насколько все стало проще? Как мне показалось, я смог решить проблему взаимодействия с этим сайтом намного быстрее, чем если бы я разбирался в js-коде. То есть, разобраться в Selenium и во взаимодействии можно быстрее, чем с тем, что данные кодируются и неизвестно, как их перекодировать обратно. Основная штука — скорость в разработке.
Видео доклада — с 16.30
Если вдруг у вас появилась необходимость интеграции на стороннем интернет-ресурсе, а разбираться в нем нет времени, на помощь придет Selenium. Дмитрий Костичев рассказал на примере своего проекта, как автоматизировать работу в браузере, не выходя из вашего сервиса.
Привет всем. Меня зовут Дмитрий и я сегодня поделюсь опытом использования Selenium в Backend-разработке. Для чего это вообще нужно? Selenium нужен для автоматизации взаимодействия с какими-то интернет-ресурсами, чтобы нивелировать человеческие факторы заполнений каких-то данных и т.д. Для разработки это может понадобиться в таких случаях, когда, например, на интернет-ресурсе не бывает API и так далее. И на примере моего проекта была задача — заполнить клиентские данные (перед этим сервис должен был правильно подготовить всю информацию) и зарегистрировать их на этом сайте, в данном случае MasterCard.
При дальнейшем рассмотрении этого сайта было выявлено, что тут нет api, к которому мы можем достучаться и все сделать. Вся обработка производится в JS-cкриптах, в которых ничего не понятно и данные все кодируются. Решение было принято — попробовать Selenium в этих целях, то есть мы прикрутим к Selenium весь наш сервис, который будет в какие-то определенны моменты проводить эту регистрацию.
В итоге, что же такое Selenium и как с ним работать? Проект Selenium состоит из библиотеки, которая общается с интерфейсом веб-драйвера под определенный браузер. Список доступных библиотек и браузеров приведен на слайде. И сейчас я покажу, как это примерно работает на моем проекте.
Посмотреть скринкаст или подробное видео в конце поста.
Сейчас сервис будет генерить файлик, сразу же его закачает на этот сайт и проверит, все ли успешно было зарегистрировано. Вот, собственно, он проклеивает, загружает и так далее. И сейчас он, наверное, прыгнет на то, что все будет успешно. Автоматизация достаточно быстро работает и не требует каких-то больших ресурсов. Все, как видно, отлично зарегистрировалось.
Как же все это приготовить? Библиотека Selenium имеет такие основные команды, как:
- Создание Instance веб-драйвера для определенного браузера;
- Переходы по ссылкам;
- Работа с элементами: клики и др.
Веб-драйвер позволяет получать сессии и куки как в обычном браузере. Также их можно изменить и кастомизировать под себя. Еще можно выполнять js-скрипты на страничке. Есть библиотека, расширяющая этот функционал самого Selenium, под названием Selenide. Основная его фишка — скрывать создание Instance драйверов. На примере мы видим, что мы просто вызываем команду open, даем какую-то ссылку и браузер уже запускается, не нужно ничего настраивать. А еще библиотечка расширяет работу с элементами, какие-то дополнительные пресеты. Выглядит все это удобно, можно быстро со всем этим разобраться и использовать.
При работе с интернет-ресурсами, и в конечном итоге с Selenium есть некоторые паттерны проектирования. И один из них — page objects. Суть его заключается в том, что мы описываем в определенном классе все эти элементы. И дальше можем его переиспользовать и это выглядит проще. Вот, примерно так: вызываем команду open, даем page objects class и дальше можем использовать все его методы, например, работу с элементами.
Поиск элементов у нас осуществляется по DOM модели HTML страницы по таким селекторам, как xpath, css и другие. Основные их отличия, например между xpath и css, так это то, что xpath может ходить «вглубь», а также вверх и вниз. А css, наоборот, только вниз. То есть, это самые используемые селекторы.
В конечном итоге нам потребуется непосредственно браузер, в чем нам может помочь непосредственно Selenoid. По сути, это фреймворк, который управляет созданием и изменением этих контейнеров с браузерами. Но он рассчитан больше для нагруженных систем, где эти браузеры создаются в большом количестве. И в нашей ситуации это не сильно потребуется, а только сам контейнер использовать. И сейчас я покажу, как это должно работать уже на сервере.
Собственно, взаимодействие странички выглядит примерно так, это достаточно линейная обработка данных. В этом случае я разделил на шаги — переходы на странички. Здесь происходит заполнение данными и, непосредственно, загрузка файлами. В принципе, все достаточно просто. Примерно вот так выглядит pageobject-class, достаточно напоминает ДТО-шку. Просто описываем элементы, например, здесь в текущем случае PCSS Selectum. Это синтаксис Selenide.
Чтобы это все заработало, нам понадобится описание Remote-драйвера, чтобы подключиться к докер-контейнеру. Основные настройки, которые туда нужно прокинуть, это выбор браузера, который мы будем использовать и, собственное, разрешение и другие важные строки для браузера. Но для того, чтобы работать с докер-контейнером потребуются еще такие настройки как headless-режим. То есть, в текущем виде это будет крутиться на сервере. Этот режим отключает графику в браузере, поэтому он будет работать быстрее и занимать меньше ресурсов.
Далее это будет no Sandbox, который отключается безопасностью Chromium в этом случае, и можно будет исполнять свой код, JS или другой. Третий параметр нужен для того, чтобы Chromium нормально работал на unix машинах, правильно записывал темповые файлы. И четвертый, собственно, нужен для того, чтобы нам загружать файлы. И самое главное, у Remote-драйвера есть флаг, который позволяет загружать файл из локального хранилища, где работает приложение, уже через Remove драйвер.
Сейчас я покажу, как это работает с докер-контейнером. Загружаем докер-контейнер и само приложение. Он примерно также будет запускаться, то есть, в принципе, ничего нового не будет. Только здесь мы будем видеть взаимодействие в каких-то логах. В принципе, их также можно мониторить, с ними работать и так далее. Поэтому можно понять взаимодействие, что происходит. Это вывод из докер-контейнера с Chromium непосредственно, где браузер стоит.
В принципе, все отлично работает с докер-контейнером. Также все проверяется и успешно завершена регистрация. Далее, какие вообще проблемы можно было бы встретить в таком подходе? У меня была не столько проблема, сколько незнание. Передачи файлов в докер-контейнере как обычно все делают — черед volume. Но в этом случае, если еще хочется локально запускать, то нужно иметь две конфигурации для проекта, но, как оказалось, Remote драйвер умеет через флаг настраиваться. Он может передавать этот файл непосредственно через себя, и не нужны никакие дополнительные телодвижения.
Также придется следить за страничкой, с которой мы работаем — интернет-ресурсом. Потому что, в моем случае, это другая система, к которой никто не имеет отношения из моей команды, и за этим нужно тоже следить, мониторить по логам и так далее. Так же и с браузером, он постоянно обновляется, за ним нужно следить, поддержка может упасть. Ну в принципе, по логам можно как-то настроить и никаких проблем не будет.
В итоге, насколько все стало проще? Как мне показалось, я смог решить проблему взаимодействия с этим сайтом намного быстрее, чем если бы я разбирался в js-коде. То есть, разобраться в Selenium и во взаимодействии можно быстрее, чем с тем, что данные кодируются и неизвестно, как их перекодировать обратно. Основная штука — скорость в разработке.
Видео доклада — с 16.30
Wenderccc
Хорошая вещица — писал пару программ на питоне при помощи нее. Нужно было автоматизировать несколько заданий, правда вот сложные действия выполнять неудобно.