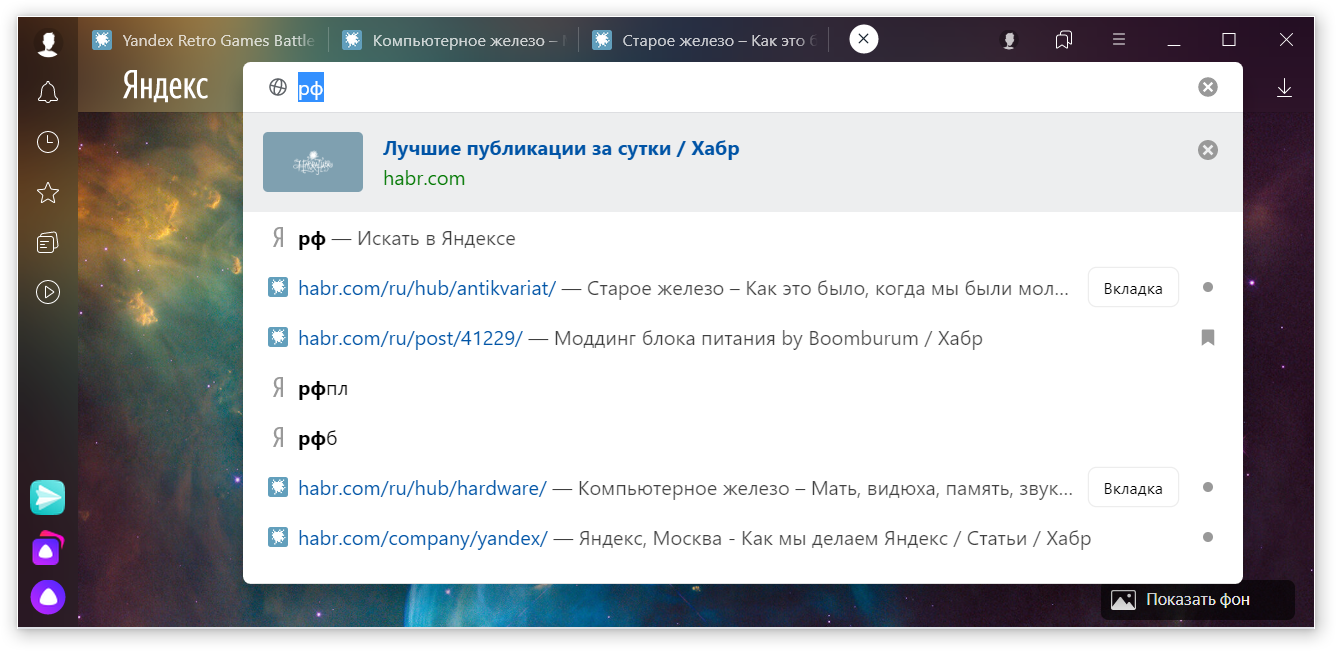
Давненько я ничего не рассказывал о Яндекс.Браузере и Chromium, а ведь интерес к этой теме на Хабре был нешуточный. Пора исправляться. Сегодня хочу поднять тему подсказок, которые мы видим под адресной строкой по мере вводе текста (этот блок ещё называют саджестом). Об этом почти никто не задумывается, но их работа исторически основана на ручных эвристиках и константах. Недавно с помощью коллег из поиска Яндекса нам удалось применить ML-ранжирование к этим подсказкам. Получилось не с первого раза, но результат того стоил.
Для лучшего погружения в контекст начнём с истории. Помните ли вы первый браузер в мире? Тот самый, который создал Тим Бернерс-Ли. Честно говоря, и я не помню, но хорошие люди сделали веб-версию для любопытных. Этот браузер умел отображать текст… и всё. Даже картинки на старте не поддерживал. А ещё там не было адресной строки в привычном для нас месте. Сайты открывались через меню, как документы в офисном редакторе. При этом было важно вводить точный адрес желаемой страницы. Забыли про http:// в начале? Получите Bad request. Никакого дружелюбия к пользователям не требовалось, потому что пользователями выступали учёные и технари.
Но затем интернет пришёл в дома «обычных» пользователей. Интерфейсы стали упрощаться: адресная строка поселилась у всех на виду, а рядом с ней добавили ещё одну — для поисковых запросов. Браузеры научились не только подставлять http://, но и подсказывать людям адреса уже посещённых страниц или введённые ранее запросы.
Затем в Chrome адресную строку объединили с поисковой — так родился омнибокс, который умел переваривать как адреса, так и запросы. Причём саджест тоже стал единый. Браузерам пришлось учиться ранжированию подсказок. Поставить на первое место сайт из истории? Или из закладок? Или сходить в облако и предложить окончание запроса? Или оставить WYT (What You Typed) и отправить в поиск?
Добавьте к этому, что вариантов подсказок со временем становилось всё больше и больше. К примеру, в Яндекс.Браузере лет семь-восемь назад впервые предложили подсказки с быстрыми ответами. Это когда пользователь вводит [курс доллара], [погода] или [сколько лет илону маску] и сразу получает ответ в подсказке под строкой, без необходимости загружать страницу поисковой системы.

Ещё в англоязычном мире почему-то не знают о проблеме переключения раскладок. В своём браузере мы ещё на старте это решили. Например, если человек вводит [ьфшд], то браузер догадывается предложить не только поиск, но и адреса, начинающиеся с mail.

В общем, подсказок много, все они по отдельности полезны. Но если не суметь их качественно отранжировать, то толку будет мало.
Как мы ранжировали раньше
Яндекс.Браузер основан на проекте Chromium, мы его любим, регулярно правим там баги, иногда оптимизируем, а если очень повезёт, то и наши продуктовые фишки туда прорастают. Поэтому мы изначально использовали логику ранжирования саджеста именно оттуда. Уверен, большинство из вас никогда не задумывались о том, как она работает. Давайте я расскажу.
Подсказки бывают двух типов: локальные и серверные. Для серверных нужно отправить запрос в облако и дождаться ответа. Для локальных, соответственно, не нужно. Прямо сейчас эта деталь неважна, но чуть ниже по тексту это станет важно. Итак, за каждую подсказку отвечает свой компонент. В Chromium их называют провайдерами. Все они действуют независимо друг от друга. На вход каждого провайдера подаётся вводимый пользователем текст. На выходе — подсказки с рассчитанной по своему алгоритму релевантностью. Этот алгоритм уникален для каждого провайдера и может учитывать частоту перехода по подсказке, когда это происходило последний раз, есть ли эта подсказка в закладках или только в истории и т. д.
Покажу это на примере.
Предположим, что пользователь вводит первую букву. Пусть это будет уже любимая нами буква m. Сразу после этого провайдеры начинают независимо друг от друга формировать подсказки и рассчитывать их релевантность.

Затем браузер объединяет эти подсказки в список, убирает дубликаты, сортирует по релевантности и показывает первые 10 результатов.

Вроде бы всё логично, да? Но у такого подхода есть недостаток: каждый провайдер вычисляет релевантность только на основе своих данных и никак не учитывает информацию, поступающую из других источников. Провайдеры неплохо ранжируют свои подсказки, но как соотнести релевантность одних подсказок с релевантностью других? В Chromium для этого ввели разные сложные эвристики, эмпирически подобрали коэффициенты для балансировки тех или иных источников. Со временем вмешиваться в эту логику стало просто страшно: слишком многое было захардкожено. При этом развивать ранжирование как-то нужно, ведь сами подсказки развиваются (появляются, исчезают, меняют форму). Если этим не заниматься, то сам инструмент со временем станет всё менее полезным.
Как мы собрали концепт нового ранжирования
Ну что же. Отсортировать несколько документов по релевантности — это классическая задача для машинного обучения, которая решается в поиске Яндекса каждый день. Тем более что в поисковой строке на yandex.ru тоже есть саджест и команда накопила существенный опыт в этом месте. Поэтому мы решили провести эксперимент, в котором будем смешивать подсказки от разных провайдеров с помощью ML.
Базовая идея первого подхода к снаряду состояла в том, чтобы взять все параметры, на основе которых провайдеры уже и так рассчитывают релевантность, обучить ML-модель и получить профит. Но не вышло.
Причина в том, что каждый провайдер работает с 1–2 параметрами. И в итоговой модели было всего 6–8 фич. Слишком мало для ML, хотя даже так получилось лучше, чем набор эвристик и констант. «Нужно больше золота», — подумали мы и пошли искать дополнительные фичи.
Что ж. Засучив рукава, мы начали сами формулировать новые фичи, которые можно было бы отдать машине. Например, длина адреса, его тип (https, ftp, file, about или что-то ещё), частота кликов пользователя по подсказкам такого типа и т. п. Всего мы напридумывали порядка 80 фич. Машине уже было где развернуться. Хотя в итоге и пришлось умерить наши аппетиты, но об этом чуть позже.
Итак, мы сформулировали десятки параметров, которые потенциально могли помочь машине отранжировать подсказки в саджесте с максимальной пользой для человека. Придумать мало — нужно ещё и в коде Браузера реализовать их учёт, чтобы и модель работала, и данные для её обучения были. На всякий случай напомню, что лог использования фич не только обезличен (даже urls передавались для обучения не явные, а в виде солёного хэша), но и не отправляется, если не стоит галочка про статистику в настройках. Кстати, этот шаг помог нам окончательно убедиться в необходимости доработок. В данных нашлись разнообразные стьюпиды. К примеру, подсказка из истории с десятками переходов могла неожиданно оказаться ниже, чем почти заброшенная закладка.
Чтобы предугадать дальнейшие шаги, достаточно прочитать несколько туториалов по машинному обучению. Буквально за пару дней собрали proof of concept на базе CatBoost. Более подробно об этой технологии мы уже рассказывали, когда выкладывали её в опенсорс. Напомню только, что эта ML-библиотека хорошо подходит для работы с разнородными фичами, что нам и было нужно. Далее обучили модель на сырых данных, без какой-либо обработки. Удивительно, но даже такое, сырое решение оказалось в среднем лучше, чем предыдущее. Хотя и не без проблем, поэтому нужно было перейти от концепта к нормальному решению.
Как мы шлифовали наше решение
В сырых данных, используемых для обучения модели, было много шума и мусора. Например, некоторые сессии работы с саджестом адресной строки длились 20 минут (очевидно, что человек открыл саджест и ушёл пить кофе — это не признак плохого саджеста). Или более 1000 открытий саджеста за короткий промежуток времени (а это вообще не люди, а боты какие-то). Всё это нужно было вычистить из данных, чтобы не искажать результат. Это несложно, но об этом было важно не забыть.
Затем мы обучили модель на чистых данных, перенесли её в код в Браузера и начали тестировать. И да, опять наступили на грабли.
Помните, чуть выше я рассказывал про то, что провайдеры бывают локальные и серверные? Если провайдер по своей природе может отрабатывать слишком долго, то его ответ не блокирует расчёт релевантности и отрисовку подсказок. Как только асинхронный провайдер соизволит ответить, происходит перерасчёт и перерисовка. Кстати, это касается не только серверных провайдеров, но и локального исторического, потому что он обращается к достаточно медленной базе SQLite. Из-за этого случился казус: подсказки в саджесте могли начать прыгать с места на место по мере набора букв. Опишу это на примере.
Допустим, пользователь вводит слово yandex.ru. Он набирает слово по буквам. На букве y в саджесте появляется десяток подсказок, несколько из которых это yandex.ru, mail.yandex.ru и maps.yandex.ru. По мере ввода yandex.ru оставался на первой позиции, но вот mail.yandex.ru и maps.yandex.ru прыгали и постоянно менялись местами. И это логично с технической точки зрения: асинхронность так и работает. Но это неприятно для пользователя, а значит, плохо для продукта.
Как такое побороть? Отказаться от асинхронности провайдеров? Это худший вариант, потому что тогда продукт начнёт тормозить в глазах человека. К счастью, мы нашли альтернативу. Методом проб и ошибок мы поняли, что 80 фич для ML — это даже избыточно. Многие из них не вносили существенной пользы в качество ранжирования, но при этом провоцировали прыжки подсказок. В итоге мы оптимизировали модель так, чтобы она работала на 40 наиболее полезных фичах, почти без потери качества, но зато — со стабильностью результатов.
На этом наша модель была готова. Результат — новый алгоритм, который на выходе формирует новую релевантность для подсказок. По сути, это число в диапазоне от 0,99...9 до 0,00...1. Чем больше, тем выше вероятность, что именно эту подсказку выберет человек. Но оставалось сделать ещё кое-что важное.
Кое-что важное
Машинное обучение — это инструмент, который позволяет добиться результата там, где человеческой памяти и ресурсов уже просто не хватает. Но он не идеален, поэтому человек всегда должен контролировать осмысленность происходящего. Например, в подсказках Браузера всегда должен быть пункт «Искать в [название поисковика]». Иначе ломается сама суть омнибокса. Другой пример: если человек вводит в строку адрес страницы, то на первом месте всегда должен быть вариант перейти по этому адресу, даже если машина посчитала такую подсказку менее полезной. Потому что вы вряд ли обрадуетесь, если привычное нажатие Enter отправит вас вовсе не туда, куда вы хотели. Подобные вещи не должны отдаваться на откуп машине. Их нужно учесть в продукте руками разработчика, а потом обязательно перепроверить глазами QA-инженера.
Итоги
Эксперимент с новым ранжированием показал, что люди стали кликать на более высокие позиции в саджесте, что сказывается и на времени ввода запросов. Например, CTR второй подсказки вырос аж на 15%. Кстати, это подтвердилось и другим нашим экспериментом: суть его заключалась в уменьшении количества подсказок, которые показывали пользователю (с 10 до 8 штук). Эксперимент показал, что для пользователей изменение подсказок критично: в экспериментальной группе увеличилось число закрытий саджеста без перехода по подсказке. Но когда мы провели этот эксперимент с новым ранжированием, такого эффекта больше не наблюдалось. (На всякий случай скажу, что отказываться от девятой и десятой подсказки мы не стали: незачем сокращать выбор без явной пользы для человека.)
Конечно же, финальную точку ставить рано. Подсказки развиваются, а значит, их ранжирование должно развиваться тоже. У нас уже есть идеи на будущее. Например, добавить немного персонализации или поэкспериментировать с размером модели. Надеюсь, расскажем об этом в ближайшем будущем.
iDm1
Вот бы еще Яндекс.Браузер перестал быть единственным в мире графическим интернет-браузером, не умеющим создавать URL файлы путём перетаскивания favicon'а сайта из адресной строки в директорию файлового менеджера или на рабочий стол.
Данная функция нужна редко, но метко. А сейчас у вас «браузер с ограниченными возможностями».
BarakAdama Автор
Честно говоря, не понял ваш запрос. Только что схватил адрес в строке и перетащил его на рабочий стол — появился ярлык с адресом. А фавиконок у нас в строке вообще нет (они в заголовках вкладок используются).
iDm1
По приведённому вами же изображению как раз видно, что вы всё прекрасно поняли.
Вы схватили не адресную строку или иконку шифрования (которые вполне себе есть), как можно во всех других графических браузерах. А сначала кликнули в неё, чтобы отобразилось поле ввода адреса и затем уже схватили выделенный текст текущей URL, и перетащили уже его. Потому что вы очевидно знаете, что в Яндекс.Браузере по какой-то неведомой миру причине это работает только так.
Какова же цель отхода единой общепринятой практики?
BarakAdama Автор
Теперь понял. Но не согласен, что в любом браузере можно схватить строку и сразу вынести её на рабочий стол. Проверил сейчас в Chrome, Opera и Firefox: везде нужно «провалиться» в редактирование адреса и выделить его, чтобы появилась возможность перетащить его. Как и у нас. Разница только в том, что у них можно схватить ещё за замочек. На мой вкус: что попасть в маленькую иконку, что совершить дополнительный клик — разница небольшая для редкой потребности. Но я в любом случае сохраню это замечание, обсудим.
selivanov_pavel
Проверил сейчас на Firefox на Linux, замочек можно схватить и тащить сразу, не переводя фокус в адресную строку. iDm1 прав.
BarakAdama Автор
Да, ровно это я и написал. За замочек можно. За строку — нет :)
Paranoich
Нет такой практики и не было никогда. И быть не могло. Потому как при клике по адресной строки адрес как правило выделяется автоматически. По второму клику — выделение снимается и возможно редактирование.
Что васается favicon, который вы привыкли перетаскивать — то это у вас привычка от IE осталась. Он до последнего умел это делать.
Судя по последнему ответу вы уже поняли, что favicon где то в прошлом остался. Но и перетаскивание значка защиты вместо адреса логичным назвать трудно.
iDm1
Есть такая практика. Назовите ещё графический браузер, где перетаскивание иконки сайта или шифрования, которая сейчас располагается вместо первой, не работает? В прошлом, говорите? Подтвердите свои слова? В Edge от этого отказалась? В Chrome? В Firefox?
Andchir
Брать за иконку шифрования это как-то не логично и не интуитивно, чего не скажешь о перетаскивании адреса. Но, видимо, каждому своё.
Возможность есть, пусть и не так, как Вы привыкли. Поэтому Ваше заявление не соответствует действительности.iDm1
А вы рассуждаете с позиции исключительно своих привычек. Но упорно игнорируете тот факт, что разработчики других браузеров, как более, так и менее популярных, принципиально сохраняют данное поведение от версии к версии. Все как один едины в сохранении данного пользовательского опыта. Думаете им делать больше нечего? Или вы просто хотите показать, что ваши привычки лучше привычек других людей?
sborisov
Только что проверил в Linux на Google Chrome было поведение аналогичное Яндекс.Браузеру.
Включил-выключил «Использовать системные заголовки окна» в настройках — появилось отличное поведение — когда сразу позволяет перетянуть иконку на десктоп, без выделения строки.
Выглядит странно.
Paranoich
Угу.
Я в упор не наблюдаю «иконки сайта» в адресной строке в графическом браузерах. Кроме ИЕ, о чём уже сказал. Как мне подтвердить слова — я не знаю. Наберите в поиске «браузер такой_то» и поглядите картинки. Простите, но не я могу перетащить то, чего нету. А вы?
Что про значок защиты — так я уже выше это написал. Вы, выгодно забыв вопрос про строку адреса и favicon, переключились на значок защиты, наплевав и на первый комментарий свой, и на ответы пользователей вам.
iDm1
Слабая попытка уйти от ответственности за своё ложное утверждение. Вы в очередной раз проигнорировали тот факт, что не смотря на замену иконки сайта на иконку шифрования — функционал во всех браузерах (кроме Я.Б) старательно сохранили. Речь идет об элементе интерфейса и его поведении, а не цвете пикселей.
onaga
> в одном супер редком случае нужно сделать пару дополнительных кликов
> браузер с ограниченными возможностями
pavelpromin
Хуже пользователей яндекс браузера только пользователи майл браузера. Фумляяя...
LoadRunner
Я пользователь Я.Браузера, он мне нравится и вполне подходит под выполнение тех задач, которые я возлагаю на браузер.
Опишите, чем я хуже вас, например?
Paranoich
Вы проделали сложную работу. А насколько это вообще востребовано? Имею ввиду подсказки по поиску из интернета (SearchProvider). Ведь общее число подсказок ограничено, часть их будет извлечена из закладок и истории. И к ним примешиваются лишь несколько результатов из поиска. Нужны ли они?
И ещё: можно ли настроить вид подсказок, ограничив их, например, лишь закладками? Так умеет (или умел?) Firefox, используя символы "%" — поиск по вкладкам, "*" — позакладкам и "^" — по истории посещений.
Спасибо за интересный материал.
BarakAdama Автор
Многие пользователи используют адресную строку в первую очередь как поисковую, чтобы сразу перейти к результатам поиска. SearchProvider помогает дописать запрос, поэтому он востребован. На самом деле поиск ведь не только запросы подсказывает. Например, наш браузер был первым, кто научился сразу подсказывать адрес сайта, даже если пользователь на него ещё не заходил (и адреса нет в локальной истории или закладках). Это тоже поисковый, навигационный ответ. Как и быстрые фактовые ответы.
Таких настроек нет. Обещать ничего не буду, но подумаем, спасибо. Кстати, машинное обучение как раз и подходит для того, чтобы смещать баланс между провайдерами на основе поведения человека.
Man-Bot
Большое спасибо за ваши приятные доработки!
Но я столкнулся с невозможностью экспорта сохранённых паролей. Я перенёс все свои пароли в self-hosted Bitwarden (имплементация на Rust -bitwardenrs-server) на домашнем NAS. Но из Яндекс.Браузера пришлось то немногое (к счастью! сохранённое встроенными средствами, переносить в ручном режиме.
В старых версиях (если не ошибаюсь, то до 17) ещё можно было (через flag) включить эту возможность, но в более новых — вырезали окончательно.
Неоднократные обращения в техподдержку приносили одни и те же ответы: передадим в разработку, отключили в связи с тем, что заботимся о вашей безопасности и тд.
Я даже предлагал алгоритмы по «защите от дурака» (на свой страх и риск)…
Лично я не понимаю, почему за меня решили, что мне это не надо? Объясните свою логику не прикрываясь надуманными лозунгами о безопасности, пожалуйста.
Если я одинок в данной проблеме, то пусть вопрос останется без ответа.
BarakAdama Автор
Какое-то время назад мы перешли на полностью свою архитектуру поэтапного шифрования и хранения паролей. Переписали всё с нуля. До экспорта руки просто не дошли пока что. Прошу прощения за неудобства.
Но всё же замечу, что plaintext'овый экспорт паролей и правда добавляет риски в плане безопасности.
Man-Bot
Большое спасибо за ответ!
Несомненно — Вы проделали огромную работу! Однако Ваш менеджер паролей не обладает достаточной функциональностью (поддержка 2FA, например!), чтобы таким образом ограничивать пользователей вашего продукта.
Не хочу быть буквоедом, но моё первое обращение по этому вопросу было датировано 20 сентября 2019 года (Ticket#19091005374556674).
"Не дошли руки" тут, на мой взгляд, следует заменить на что-то другое.
Простите за резкость, но из-за этого я был вынужден потратить не один вечер на перенос моих же паролей руками из Яндекс.Браузера!
Лично мне уже этот функционал не нужен, но я уверен, что кроме меня найдутся те, кто столкнётся с подобным вопросом.
Что касается plaitext export, то, если уж за безопасность речь зашла, можно с крупными игроками на рынке (1Password, Dashline, Bitwarden, etc) обсудить механизм экспорта такой важной информации в зашифрованном виде.
Кстати, только в Яндекс.Браузере нет экспорта в сторонние Хранилки паролей (поправьте, если ошибаюсь — вдруг кому пригодится).
Mimo_progodil
«Сегодня в блоге на Хабре вы можете прочесть технологическую историю о том, как мы применили машинное обучение и опыт поиска Яндекса в подсказках Яндекс.Браузера» — иногда строка слишком умная и предлагает в поиске закладки, которые нужно видеть не всем. Автоматический переход в режим инкогнито для порно сайтов завезли, спасибо. Было бы очень круто, если бы с этим вопросом тоже что-то придумали. А то не всегда получается открывать именно рабочую версию, а коллеги уже устал улыбаться. :)
EOShipnyagov
Пользуюсь вашим браузером. Вполне доволен, правда не очень люблю, когда вендоры пытаются добавлять в браузер всякие сайдбары и прочее)
sibirier
Искренне не понимаю, почему Яндекс.Браузер не может мне предложить поиск по картинкам сразу, а не только после поиска на общей странице. Но не понимаю я не технический момент, а то, что Опера — может это делать, а Яндекс.Браузер со своей же поисковой системой такого сделать не может.
Речь про адресную строку, как раз, так что даже не оффтоп.
Писал такое предложение в поддержку — нет ответа, даже стандартной отписки.
Это же вроде бы очевидное решение. В Опере это было очевидно, честь им и хвала за это.
Часто ищу картинки в Я.Браузере и каждый раз негодую «зачем мне заходить в общий поиск, если я могу попадать сразу в раздел с картинками?»
BarakAdama Автор
А можете, пожалуйста, чуть детальнее и по шагам описать. Не понял, как именно это должно быть устроено. Спасибо.
sibirier
Возможно я видел это на работе.
BarakAdama Автор
Интересно, не видел такого раньше.
Кстати, придумал костыль, который может вам помочь. Можно в настройках поисковых систем указать удобный ключ для поиска по картинкам. Тогда достаточно написать [img котики], чтобы сразу открыть картинки с котиками.
zamboga
Мне тоже не хватает нативного поиска по картинкам из омнибокса, раньше сначала искал сабж и даже не дожидаясь окончания загрузки страницы выдачи сразу давил кнопку «картинки».
Супер-костыль, спасибо.
anonymous
Сторонними плагинами реализуемо, причём не только на Я.Картинки а хоть куда!
zamboga
Из омнибокса так не работает, т.е. мне надо где-то найти текстовое поле и туда написать, что нереально в большинстве случаев (например, нет текстового поля на текущей странице, нет на стартовой с табло и тд)
1dNDN
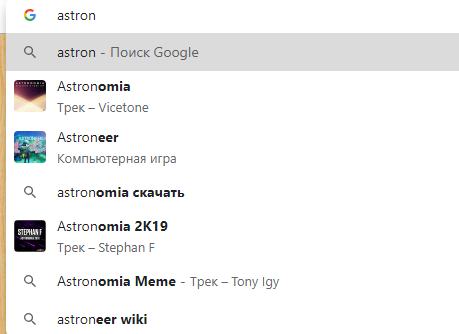
Автодополнение поискового запроса при использовании поиска Яндекса в хроме у вас слишком назойливое и по умолчанию выделяется первый элемент списка.
Это приводит к тому, что я ввожу «кросс», нажимаю enter, а попадаю на «кроссфаер» вместо нужного мне кросса.
Скрин
BarakAdama Автор
Это же логика работы саджеста в хроме. Она не от нас зависит. Вот пример там же, но не с нашим поиском.
Повторил то же самое у нас в браузере. Для чистоты эксперимента было бы круто вам попробовать и наш саджест. Интересны впечатления от человека, который раньше им не пользовался.
1dNDN
Ваш поиск в хроме
А вот гугл в хроме таким не страдает
Хотел скачать ваш браузер потестить, все-таки дополняет. Но гораздо менее назойливо, дополняя только по одному слову и только в тех случаях, когда написание очевидно (ваш поиск дополняет целыми предложениями)
При установке галочка слишком незаметная, фу так быть.
Я вроде только браузер хотел установить…
При нажатии на эту кнопку ничо не происходит
А где название у процессов?
Сколько мусора на стартовой странице…
Постоянно какие-то окошки вылазят, это точно браузер от серьезной корпорации?
Да еще и при открытии лежит где-то на заднем фоне, а не поверх открытых приложений
У гугла в вашем браузере нужно написать еще букву «о», чтобы автодополнение дополнило до «кроссовки»
При нажатии происходит ровно ничего. Да и с кнопкой отмены поиска ничем не отличается
Но вот в вашем браузере с вашим поиском автодополнение есть только по истории поиска, а если там такого запроса нет, то ничего не дополняется вообще никак.
BarakAdama Автор
А этот скриншот я выдумал? :-)
Саджест — сложная штука. В ваших примерах на него оказывает влияние ваш предыдущий опыт его использования. Ваша предыдущая статистика. Поэтому вы видите не то, что вижу я. И поэтому сравнить частные примеры точно не имеет смысла. Одно точно: в нашем Браузере можно нажать Enter и перейти к поиску ровно той фразы, что написали вы, а не предполагает машина (дисклеймер: если это не навигационный запрос). И мне, как технарю в душе, это дико удобно.
1dNDN
Я специально выбрал кросс*, потому что по этой тематике у меня нет поисковых запросов. Мне, как человеку, который пользуется другим браузером (хромом), который не сует мне в лицо тонны всяких окон и прочей дряни, дико неудобно видеть вот такое вот при использовании вашего поиска. И нет, самостоятельно я такое никогда не ввожу

Для сравнения, тот же запрос в гугле.
BarakAdama Автор
Мне кажется, спор зашёл в тупик. Вы приводите пример. Я привожу контр-пример, который опровергает пример. И т. д. Пожалуй, остановлюсь на рекомендации Яндекс.Браузера. Там саджест работает без таких странных примеров, а виджеты на главной удобно настраиваются.
hmelni
Расширьте пожалуйста функционал режима для чтения чтоб поуже колонку текст можно было бы сделать. А так ваш браузер хорош!
evil_me
Забавно, что на КДПВ браузер с отключенными виджетами, Дзеном и прочими информерами :)
В своё время перешёл с Бро на другой браузер после года обещаний сделать синхронизацию галок "отключить всё и оставить просто фон на новой вкладке". А каждый раз устраивать цирк с конями при установке браузера и выискивать, как отключить все банеры на новой ОС или компе прям надоело.
barakadama может, такое однажды завезут? Может, уже завезли, а мужики и не знали?
tundrawolf_kiba
У меня, конечно, не по теме, но вот такой вопрос: у меня после какого-то из обновлений строка с расширениями стала выглядеть вот так вот:

С шировким расстоянием между иконками. На чистои профиле то же самое. Ставил в виртуалку — там при установке все нормально было. В поддержку писал, написали, что отправят запрос разработчикам, но после этого тишина. В общем вопрос такой — возможно ли это как-то починить не переустанавливая браузер полностью?
BarakAdama Автор
А весь остальной интерфейс при чистой установке не менялся? Мне кажется, мы уже достаточно давно изменили расстояние между иконками при обновлении интерфейса.
tundrawolf_kiba
Не, остальной не менялся. Я и так на бете сижу, и на той которую в песочниуе вин-10 — тоже последнюю бету ставил. А я правильно понял, что вот такое вот широкое расстояние — это теперь норма будет?
tundrawolf_kiba
Хотя да, вот сейчас свежую бету установил (в прошлый раз еще в апреле пробовал) и увидел, что сейчас и в чистой установке такое же. Если это действительно новое веяние интерфейса, то жаль — столько лишнего места между иконками выглядит настолько странны, что я 3 месяца принимал его за дефект, случившийся с моей установкой браузера
ezhik90
Можно я позадаю вопросу и повыдвигаю претензии?
BarakAdama Автор
Эти вопросы загнали меня в тупик. А в поддержку не писали случайно? Пригодился бы номер обращения.
ezhik90
Нет, в поддержку не писал. Это же, скорее, не ошибки, а какие-то проблемы на уровне хромиума, потому что в Хроме аналогичные проблемы имеют место. Но, возможно, в саппорт напишу, чтобы была такая хотелка зафиксирована.
zamboga
Нашлось решение? Тоже надоела частичная синхронизация.
ezhik90
Ну, я ещё не писал в саппорт. Надо бы завтра написать. Может, что и подскажут. А вы про историю или про вкладки?
tundrawolf_kiba
А, вот еще фич-реквест есть. Не думаю, что это баг, но мне кажется следующее поведение стоит как-то обрабатывать:
1) У нас открыт браузер с каким-то количеством вкладок
2) Мы выносим одну из вкладок на второе окно
3) Закрываем первое окно с кучей вкладок (обычно это происходит случайно)
4) Закрываем оставшуюся вкладку
В этом случае у нас в истории остается только последняя закрытая вкладка, а набор вкладок из первого окна не сохраняется в истории. Хотелось бы чтобы сохранялся, тем более что я видел похожий функционал по восстановлению группы вкладок иногда, когда браузер падал.
zamboga
Нажимаем CTRL+SHIFT+T, как вариант, пока не появится то самое окно с кучей одновременно случайно закрытых вкладок.
tundrawolf_kiba
У них на это сочетание клавиш есть удобный жест мыши. Но в данном случае это не поможет, потому что это должно сохраниться в истории, но часто не сохраняется, а перезаписывается вот той последней закрытой вкладкой, которую мы закрыли на шаге 4. Вот если опомниться на 3-м шаге, то да, из истории еще можно восстановить, а после 4-го шага — уже поздно.
iDm1
Мобильный Яндекс.Браузер на Android падает на турбо-страницах Яндекса, если там появляется вставка Яндекс.Директа, практически в 100% случаев. Турбо-страница перезагружается уже без рекламы и дальше работает нормально. В других случаях работает без нареканий.
Вот такая забавная ситуация, набор из чисто собственных технологий оказался самым проблемным.
BarakAdama Автор
У меня такое не воспроизводится, поэтому прошу в следующий раз сразу написать в поддержку прямо через пункт в меню браузера. Так будет проще найти причину.
paantya
У яндекс браузера есть перевод страницы, как у гугла? что бы текст на странице перевело, а картинки на месте остались?
И есть приложения для чтения медиума, как у гугла и мазилы, без подписки?
BarakAdama Автор
Конечно. Более того, у нас можно не только всю страницу целиком перевести, но и отдельные слова и фразы на странице. В основе технологии Яндекс.Переводчика.
Про подписки вопрос не понял. Если речь про расширения браузерные, то мы поддерживаем их установку из Chrome Web Store.
zamboga
При поиске символов очень не хватает автоматического копирования символа в буфер или, хотя бы, подстановки в омнибокс, чтобы скопировать ручками. А то колдунчик отлично отрабатывает запросы спецсимволов, но все равно приходится переходить на сам поисковик и копировать оттуда (кстати, там бы тоже кнопку копировать кроме крупного отображения символа)