
Широко известной новостью в узких кругах стало появление в релизе Junos 16.1 механизмов расширенной очередизации на фиксированных 10G портах платформ MX80/MX104.
Как это иногда случается, техническая документация по новым возможностям выходит с некоторой задержкой, даже сейчас разделы посвященные этой теме оставляют ощущение недосказанности. К счастью, коллеги из московского представительства Juniper на конференции Juniper Networks Summit помогли найти ответы, за что им большое спасибо.
Ресурсы QX чипа Trio первого поколения (а именно на нем и построены эти платформы) распределяются между интерфейсами на модульных картах не тривиальным образом, это значит что заявленную производителем плотность абонентов в расчете на шасси можно получить только в определенных условиях.
Буферная память QX чипа делится между двумя блоками планировщиков, каждый из которых способен обслуживать по 32000 очередей. В свою очередь, каждый планировщик работает с двумя группами интерфейсов на разных модульных картах, предоставляя в распоряжение каждой группе не более половины своих очередей.

В том случае когда в шасси всего одна модульная карта, каждый блок планировщика работает с отдельной группой портов на этой карте в монопольном режиме, тем самым повышая доступное количество очередей.
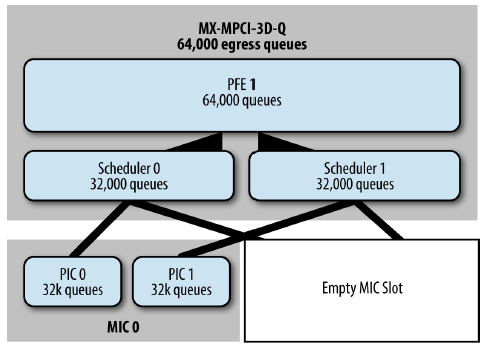
В случае фиксированных портов, дело обстоит несколько иначе — порты разбиты на пары (0, 2) и (1, 3), и каждая пара портов работает с одним из двух планировщиков. Т.е. каждая пара портов способна обслуживать не более чем 32000 очередей.
Отсюда следует несколько простых правил для достижения заявленной плотности абонентов в расчете на шасси:
Как это иногда случается, техническая документация по новым возможностям выходит с некоторой задержкой, даже сейчас разделы посвященные этой теме оставляют ощущение недосказанности. К счастью, коллеги из московского представительства Juniper на конференции Juniper Networks Summit помогли найти ответы, за что им большое спасибо.
Ресурсы QX чипа Trio первого поколения (а именно на нем и построены эти платформы) распределяются между интерфейсами на модульных картах не тривиальным образом, это значит что заявленную производителем плотность абонентов в расчете на шасси можно получить только в определенных условиях.
Буферная память QX чипа делится между двумя блоками планировщиков, каждый из которых способен обслуживать по 32000 очередей. В свою очередь, каждый планировщик работает с двумя группами интерфейсов на разных модульных картах, предоставляя в распоряжение каждой группе не более половины своих очередей.
В том случае когда в шасси всего одна модульная карта, каждый блок планировщика работает с отдельной группой портов на этой карте в монопольном режиме, тем самым повышая доступное количество очередей.
В случае фиксированных портов, дело обстоит несколько иначе — порты разбиты на пары (0, 2) и (1, 3), и каждая пара портов работает с одним из двух планировщиков. Т.е. каждая пара портов способна обслуживать не более чем 32000 очередей.
Отсюда следует несколько простых правил для достижения заявленной плотности абонентов в расчете на шасси:
- если вы приземляете абонентов на двух модульных картах — делите их по картам и по группам портов на карте;
- если в шасси одна модульная карта — делите абонентов по группам портов;
- если вы приземляете абонентов на фиксированных портах — делите их по группам портов.
Поделиться с друзьями