
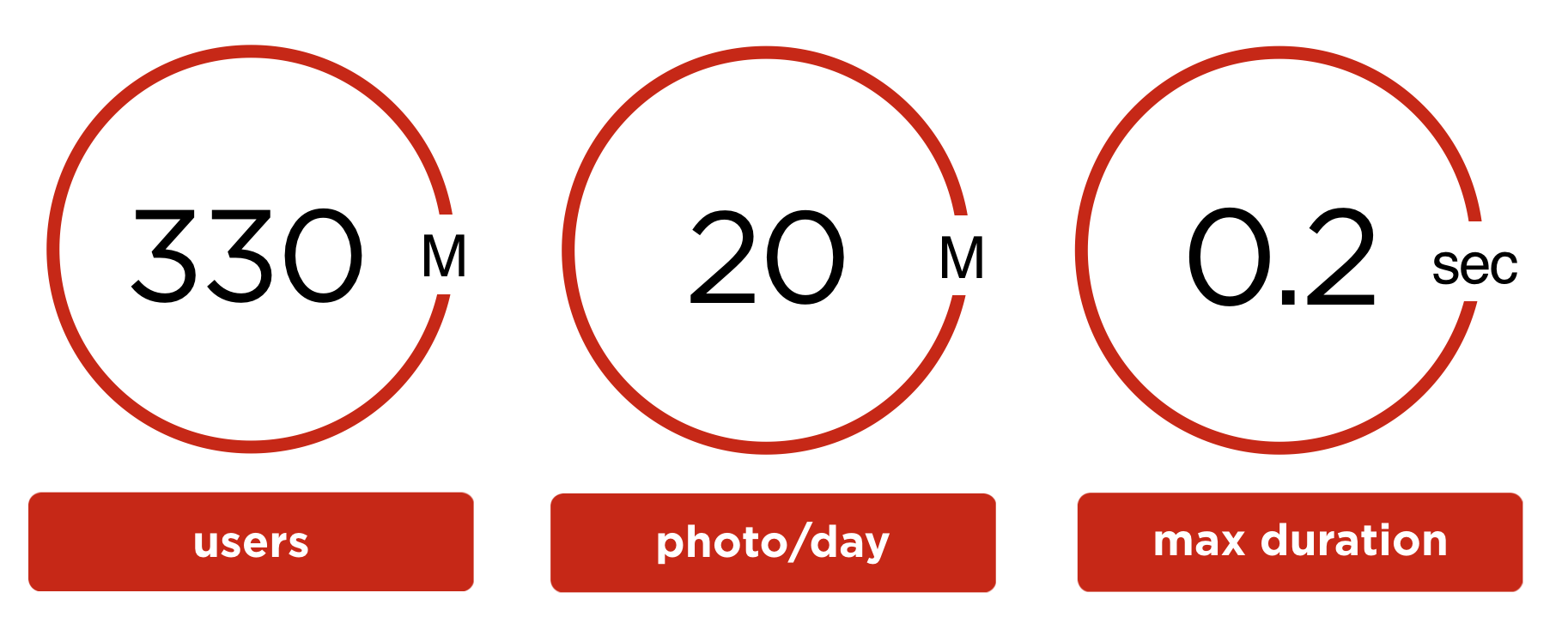
Распознаванием лиц в 2018 году никого не удивишь – каждый студент, может, даже школьник, его делал. Но всё становится немного сложнее, когда у вас не датасет на 1 млн пользователей, а:
- 330 миллионов пользовательских аккаунтов;
- ежедневно заливается 20 млн пользовательских фотографий;
- максимальное время на обработку одного фото не должно превышать 0.2 сек;
- ограниченные объемы оборудования для решения задачи.

В этой статье мы поделимся опытом разработки и запуска системы распознавания лиц на пользовательских фотографиях в социальной сети Одноклассники и расскажем про все ”от А до Я”:
- математический аппарат;
- техническую реализацию;
- результаты запуска;
- и акцию StarFace, которую мы использовали для PR-а нашего решения.
Задача
Более 330 млн аккаунтов зарегистрировано в Одноклассниках, в этих аккаунтах содержится более 30 млрд фото.
Пользователи ОК заливают 20 млн фото в сутки. На 9 млн загруженных за сутки фотографий присутствуют лица, а всего детектируется 23 млн лиц. То есть, в среднем 2.5 лица на фотографию, содержащую хотя бы одно лицо.
У пользователей есть возможность отмечать людей на фотографии, но обычно они ленятся. Мы решили автоматизировать поиск друзей на фотографиях, чтобы увеличить информированность пользователя о загруженных с ним фотографиях и объем фидбека для пользовательских фотографий.
Для того чтобы после загрузки фото автор мог моментально подтвердить друзей, обработка фотографии в худшем случае должна укладываться в 200 миллисекунд.
Система распознавания пользователей в соц сети
Распознавание лиц на загруженном фото
Пользователь загружает фото с любого клиента (с браузера или мобильных приложений iOS, Android), оно попадает на детектор, задача которого найти лица и выровнять их.
После детектора нарезанные и предобработанные лица попадают на нейросетевой распознаватель, который строит характеристический профиль лица пользователя. После этого происходит поиск наиболее похожего профиля в базе. Если степень похожести профилей больше граничного значения, то пользователь автоматически детектируется, и мы отсылаем ему уведомление, что он есть на фото.
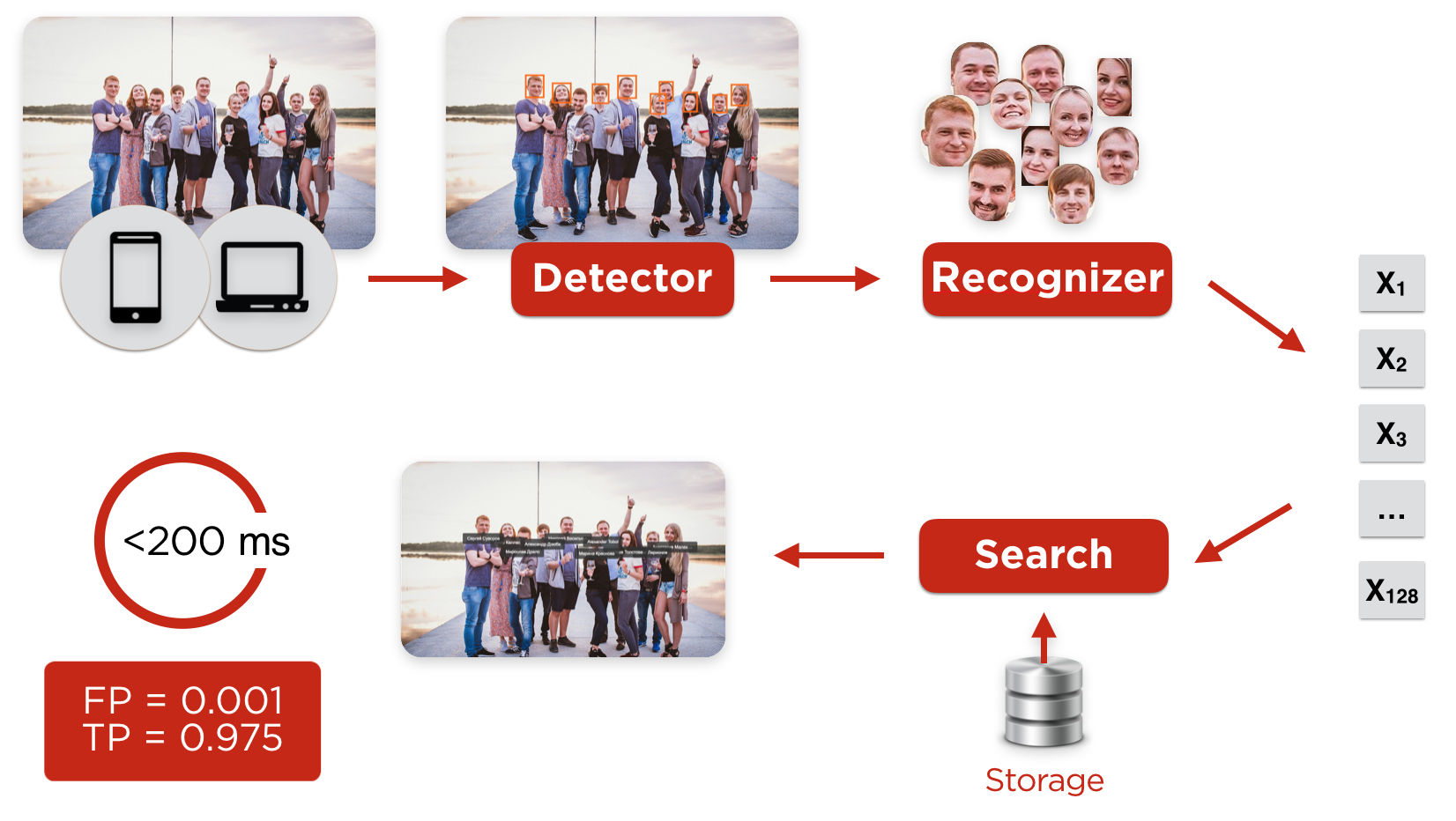
Рисунок 1. Распознавание пользователей на фото
Перед тем, как запустить автоматические распознавание, нужно создать профиль каждого пользователя и заполнить базу.
Построение пользовательских профилей
Для работы алгоритмов распознавания лиц, достаточно всего одной фотографии, например аватарки. Но будет ли эта аватарка содержать фото профиля? Пользователи ставят на аватарки фотографии звёзд, а профили изобилуют мемасиками или содержат только групповые фотографии.

Рисунок 2. Трудный профиль
Рассмотрим профиль пользователя, состоящий только из групповых фотографий.
Определить владельца аккаунта (рис. 2) можно если учитывать его пол и возраст, а также друзей, профили которых были построены ранее.
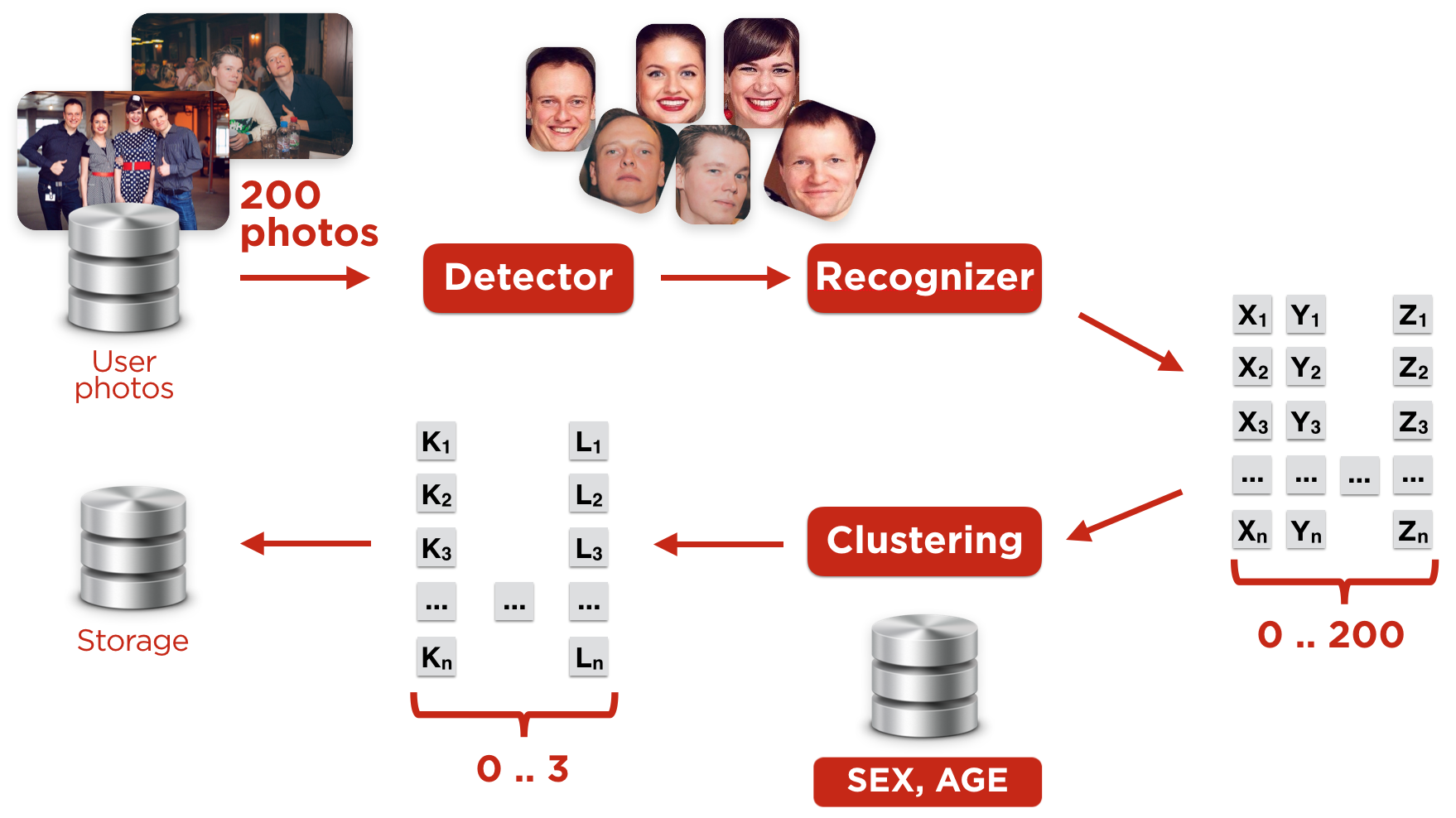
Рисунок 3. Построение пользовательских профилей
Мы строили профиль пользователя следующим образом (Рис. 3):
1) Выбирали наиболее качественные фотографии пользователя
Если фотографий было слишком много, мы использовали не более ста лучших.
Качество фотографий определяли на основе:
- наличия отметок пользователей на фото (фотопинов) ручным способом;
- метаинформации фотографии (фото загружено с мобильного телефона, снято на фронтальную камеру, в отпуске, ...);
- фото было на аватарке
2) Искали на этих фотографиях лица
- не страшно, если это будут другие пользователи (на шаге 4 мы их отфильтруем)
3) Вычисляли характеристический вектор лица
- такой вектор называется эмбеддингом
4) Производили кластеризацию векторов
Задача этой кластеризации – определить, какой именно набор векторов принадлежит владельцу аккаунта. Основная проблема – это наличие друзей и родственников на фотографиях. Для кластеризации мы используем алгоритм DBScan.
5) Определяли лидирующий кластер
Для каждого кластера мы считали вес на основании:
- размера кластера;
- качества фотографий, по которым построены эмбеддинги в кластере;
- наличия фотопинов, привязанных к лицам из кластера;
- соответствия пола и возраста лиц в кластере с информаций из профиля;
- близость центроида кластера к профилям друзей, вычисленным ранее.
Коэффициенты параметров, участвующих в вычислении веса кластера обучим линейной регрессией. Честный пол и возраст профиля – отдельная сложная задача, об этом расскажем далее.
Чтобы кластер считался лидером, нужно чтобы его вес был больше ближайшего конкурента на константу, рассчитанную на обучающей выборке. Если лидер не найден, мы еще раз переходим к пункту 2, но используем большее число фотографий. Для некоторых пользователей мы сохраняли два кластера. Такое бывает для совместных профилей — некоторые семьи имеют общий профиль.
6) Получали эмбеддинги пользователя по его кластерам
- Наконец, строим вектор, который будет характеризовать внешность владельца аккаунта, – “эмбеддинг пользователя”.
Эмбеддинг пользователя – это центроид отобранного для него (лидирующего) кластера.
Строить центроиды можно множеством разных способов. После многочисленных экспериментов мы вернулись к самому простому из них: усреднение входящих в кластер векторов.
Как и кластеров, эмбеддингов у пользователя может быть несколько.
За время итерации мы обработали восемь миллиардов фото, проитерировали 330 млн профилей и построили эмбеддинги для трехсот миллионов аккаунтов. В среднем, для построения одного профиля мы обрабатывали 26 фотографий. При этом для построения вектора достаточно даже одной фотографии, но чем больше фото, тем больше наша уверенность, что построенный профиль принадлежит именно владельцу аккаунта.
Процесс построения всех профилей на портале мы производили несколько раз, так как наличие информации о друзьях повышает качество выбора кластера.
Объем данных необходимый для хранения векторов ~300 GB.
Детектор лиц
Первую версию детектора лиц ОК запустили в 2013 году на базе стороннего решения, схожего по характеристикам с детектором на базе метода Виолы — Джонса. За 5 лет это решение устарело, современные решения, основанные на MTCNN, показывают точность в два раза выше. Поэтому мы решили следовать трендам и построили свой каскад из сверточных нейронных сетей (MTCNN).
Для работы старого детектора мы использовали более 100 “стареньких” серверов с CPU. Практически все современные алгоритмы нахождения лиц на фото основаны на свёрточных нейронных сетях, которые наиболее эффективно работают на GPU. Закупить большое число видеокарт мы не имели возможности по объективным причинам: дорого все скупили майнеры. Решено было запускаться c детектором на CPU (ну не выкидывать же сервера).
Для детектирования лиц на заливаемых фотографиях мы используем кластер из 30 машин (остальные пропили сдали в утиль). Детектирование при построении пользовательских векторов (итерации по аккаунтам) мы делаем на 1000 виртуальных ядрах с низким приоритетом в нашем облаке. Облачное решение детально описано в докладе Олега Анастасьева: One-cloud — ОС уровня дата-центра в Одноклассниках.
При анализе времени работы детектора мы столкнулись с таким худшим случаем: сеть верхнего уровня пропускает слишком много кандидатов на следующий уровень каскада, и детектор начинает работать долго. Например, время поиска достигает 1.5 секунд на таких фотографиях:

Рисунок 4. Примеры большого количества кандидатов после первой сети в каскаде
Оптимизируя этот случай, мы высказали предположение, что на фотографии обычно немного лиц. Поэтому, после первого этапа каскада мы оставляем не больше 200 кандидатов, опираясь на уверенность соответствующей нейросети в том, что это лицо.
Такая оптимизация уменьшила время худшего случая до 350 мс, то есть в 4 раза.
Применив пару оптимизаций (например, заменив Non-Maximum Suppression после первой ступени каскада на фильтрацию на основе Blob detection), разогнали детектор ещё в 1.4 раза без потери качества.
Впрочем прогресс на месте тоже не стоял, и сейчас искать лица на фото принято более элегантными методами — см. FaceBoxes. Не исключаем, что в ближайшее время и мы переедем на нечто подобное.
Распознаватель лиц
При разработке системы распознавателя мы экспериментировали с несколькими архитектурами: Wide ResNet, Inception-ResNet, Light CNN.
Немного лучше остальных себя показала Inception-ResNet, пока остановились на ней.
Для работы алгоритма нужна обученная нейронная сеть. Её можно найти на просторах интернета, купить, либо обучить самим. Для обучения нейронных сетей необходим некоторый набор данных (датасет), на котором происходит обучение и валидация. Так как распознавание лиц — известная задача, для неё уже существуют готовые датасеты: MSCeleb, VGGFace/VGGFace2, MegaFace. Однако, тут вступает в дело суровая реальность: обобщающая способность современных нейросетей в задачах идентификации по лицу (да и вообще) оставляет желать лучшего.
А на нашем портале лица сильно отличаются от того, что можно найти в открытых датасетах:
- Иное распределение возрастов – на наших фото есть дети;
- Другое распределение этносов;
- Попадаются лица в очень низком качестве и разрешении (фото с телефона, снятые 10 лет назад, групповые фото).
Третий пункт легко побороть, искусственно уменьшив разрешение и наложив артефакты jpeg-а, а вот остальное качественно сэмулировать не получится.
Поэтому мы решили составить собственный датасет.
В процессе построения набора методом проб и ошибок мы пришли к такой процедуре:
- Выкачиваем фото из ~100k открытых профилей
Профили выбираем случайно, минимизируя количество тех, кто состоит друг с другом в дружеских отношениях. Вследствие этого считаем, что каждый человек из датасета появляется только в одном профиле - Строим вектора (эмбеддинги) лиц
Для построения эмбеддингов используем предобученную опенсорсную нейросеть (мы взяли отсюда). Кластеризуем лица в рамках каждого аккаунта
Пара очевидных наблюдений:
- Мы не знаем, сколько разных людей появляются на фото из аккаунта. Следовательно, кластеризатор не должен требовать количество кластеров в качестве гиперпараметра.
- В идеале для лиц одного и того же человека надеемся получить очень похожие вектора, образующие плотные сферические кластеры. Но Вселенной нет дела до наших чаяний, и на практике эти кластера расползаются в замысловатые формы (например, для человека в очках и без кластер обычно состоит из двух сгустков). Поэтому centroid-based методы тут нам не помогут, нужно использовать density-based.
По этим двум причинам и результатам экспериментов выбрали DBSCAN. Гиперпараметры подбирали руками и валидировали глазами, тут всё стандартно. Для самого главного из них – eps в терминах scikit-learn – придумали простенькую эвристику от количества лиц в аккаунте.
Фильтруем кластера
Основные источники загрязнения датасета и как мы с ними боролись:
- Иногда лица разных людей сливаются в один кластер (из-за несовершенства нейросети-рекогнайзера и density-based природы DBSCAN-а).
Помогла нам простейшая перестраховка: если два или более лиц в кластере пришли из одной фотографии, мы такой кластер на всякий случай выкидывали.
Это значит, любители селфи-коллажей в наш датасет не попадали, но оно того стоило, ибо количество ложных “слияний” уменьшилось в разы. - Случается и обратное: одно и то же лицо образует несколько кластеров (например, когда есть фотографии в очках и без, в макияже и без и т.д.).
Здравый смысл и эксперименты привели нас к следующему. Измеряем расстояние между центроидами пары кластеров. Если оно больше определённого порога — объединяем, если достаточно велико, но порог не проходит — выкидываем один из кластеров от греха подальше. - Бывает, детектор ошибается, и в кластерах оказываются вовсе не лица.
К счастью, нейросеть-распознаватель легко заставить фильтровать такие ложные срабатывания. Подробнее об этом ниже.
- Иногда лица разных людей сливаются в один кластер (из-за несовершенства нейросети-рекогнайзера и density-based природы DBSCAN-а).
- Дообучаем нейросеть на том, что получилось, возвращаемся с ней к пункту 2
Повторять 3-4 раза до готовности.
Постепенно сеть становится лучше, и на последних итерациях надобность в наших эвристиках для фильтрации вовсе отпадает.
Решив, что чем разнообразнее, тем лучше – подмешиваем к нашему новенькому датасету (3.7M лиц, 77K людей; кодовое название — OKFace) что-нибудь ещё.
Самым полезным чем-нибудь ещё оказался VGGFace2 – достаточно большой и сложный (повороты, освещение). Как водится, составлен из найденных в Гугле фото знаменитостей. Неудивительно, что очень “грязный”. К счастью, почистить его дообученной на OKFace нейросетью – дело тривиальное.
Функция потерь
Хорошая функция потерь для Embedding learning – всё ещё открытая задача. Мы попытались подойти к ней, опираясь на следующее положение: нужно стремиться, чтобы функция потерь максимально соответствовала тому, как модель будет использоваться после обучения
А использоваться наша сеть будет самым стандартным образом.
При нахождении на фото лица его эмбеддинг будет сравниваться с центроидами из профилей кандидатов (самого пользователя + его друзей) по косинусному расстоянию. Если , то заявляем, что на фото — кандидат номер .
Соответственно, хотим, чтобы:
- для “правильного” кандидата , превышал порог срабатывания ;
- для остальных – был ниже и даже желательно с запасом, .
Отклонение от этого идеала будем наказывать по квадрату, потому что все так делают эмпирически так оказалось лучше. То же самое на языке формул:
А сами центроиды – это просто параметры нейросети, обучаются, как и всё остальное, градиентным спуском.
У такой функции потерь есть свои проблемы. Во-первых, она плохо подходит для обучения с нуля. Во-вторых, подбирать целых два параметра — и — довольно утомительно. Тем не менее, дообучение с её использованием позволило добиться более высокой точности, чем остальными известными нам функциями: Center Loss, Contrastive-Center Loss, A-Softmax (SphereFace), LMCL (CosFace).
И стоило оно того?
| LFW | OKFace, test set | |||
| Accuracy | TP@FP0.001 | Accuracy | TP@FP0.001 | |
| До | 0.992+-0.003 | 0.977+-0.006 | 0.941+-0.007 | 0.476+-0.022 |
| После | 0.997+-0.002 | 0.992+-0.004 | 0.994+-0.003 | 0.975+-0.012 |
цифры в таблице — средние результаты 10 замеров +-стандартное отклонение
Важный для нас показатель — TP@FP: какой процент лиц мы опознаем при фиксированной доле ложных срабатываний (здесь — 0.1%).
С лимитом ошибок 1 на 1000 и без дообучения нейросети на нашем датасете мы могли распознавать лишь половину лиц на портале.
Минимизируем ложные срабатывания детектора
Детектор порой находит лица там, где их нет, причём на пользовательских фото делает это часто (4% срабатываний ложные).
Довольно неприятно, когда такой “мусор” попадает в тренировочный датасет.
Очень неприятно, когда мы настойчиво просим наших пользователей “отметить друга” в букете роз или на текстуре ковра.
Решить проблему можно, и самый очевидный способ – собрать побольше не-лиц и прогнать через нейросеть-рекогнайзер их выявлять.
Мы же по обыкновению решили начать с быстрого костыля:
- Заимствуем из интернета десяток изображений, на которых, по-нашему мнению, лица находиться не должны

- Берём случайные кропы, строим для них эмбеддинги и кластеризуем. У нас получилось всего 14 кластеров.
- Если эмбеддинг тестируемого “лица” близок к центроиду какого-то из кластеров — считаем “лицо” нелицом.
- Радуемся, как хорошо работает наш метод
- Осознаем, что описанная схема реализуется двуслойной нейросетью (с 14-ю юнитами на скрытом слое) поверх эмбеддингов, и немного грустим.
Интересно здесь то, что сеть-распознаватель отправляет всё разнообразие не-лиц всего в несколько областей в пространстве эмбеддингов, хотя её такому никто не учил.
Все врут или определение реального возраста и пола в социальной сети
Пользователи часто не указывают свой возраст или указывают его неправильно. Поэтому возраст пользователя будем оценивать используя его граф друзей. Тут нам поможет кластеризация возрастов друзей: в общем случае возраст пользователя в наибольшем кластере возрастов его друзей, а с определением пола нам помогли имена и фамилии.
Об этом рассказывал Виталий Худобахшов: «Как узнать возраст человека в социальной сети, даже если он не указан»
Архитектура решения
Так как вся внутренняя инфраструктура ОК построена на Java, то и все компоненты мы завернем в Java. Inference на detector и recognizer работает под управлением TensorFlow через Java API. Detector работает на CPU так как удовлетворяет нашим требованиям и работает на уже имеющемся оборудовании. Для Recognizer-а мы установили 72 GPU карты, так как запуск Inception-ResNet не целесообразен на CPU с точки зрения ресурсов.
В качестве базы данных для хранения векторов пользователя используем Cassandra.
Так как суммарный объем векторов всех пользователей портала ~300Gb, то для быстрого доступа к векторам добавляем кэш. Кэш реализован в off-heap, детали можно прочитать в статье Андрея Паньгина: «Использование разделяемой памяти в Java и off-heap кеширование».
Построенная архитектура выдерживает нагрузку до 1 млрд фото в сутки при итерации по пользовательским профилям, при этом параллельно продолжается обработка новых заливаемых фотографий ~20 млн фото в сутки.

Рисунок 6. Архитектура решения
Результаты
В результате мы запилили систему, натренированную на реальных данных социальной сети, дающую хорошие результаты при ограниченных ресурсах.
Качество распознавания на датасете, построенном на реальных профилях из ОК, составило TP=97.5% при FP=0.1%. Среднее время обработки одной фотографии составляет 120 мс, а 99 перцентиль укладывается в 200 мс. Система самообучающаяся, и чем больше тегируют пользователя на фото, тем точнее становится его профиль.
Теперь после загрузки фото пользователи, найденные на них, получают уведомления и могут подтвердить себя на фотографии или удалить, если фото им не нравится.

Автоматическое распознавание привело к 2-кратному росту показов событий в ленте об отметках на фотографиях, а количество кликов на эти события выросло в 3 раза. Интерес пользователей к новой фиче очевиден, но мы планируем вырастить активность еще больше за счет улучшения UX и новых точек применения, таких как Starface.
Флешмоб StarFace
Для того чтобы познакомить пользователей соцсети с новой функциональностью, ОК объявили конкурс: пользователи загружают свои фотографии со звездами российского спорта, шоу-бизнеса и популярными блоггерами, ведущими свои аккаунты в Одноклассниках, и получают бейдж на аватарку или подписку на платные сервисы. Подробности тут: https://insideok.ru/blog/odnoklassniki-zapustili-raspoznavanie-lic-na-foto-na-osnove-neyrosetey
За первые дни акции пользователи уже загрузили более 10 тысяч фото со знаменитостями. Выкладывали селфи и фотографии со звездами, фото на фоне афиш и, конечно, “фотошоп”. Фото пользователей, получивших ВИП-статус:

Планы
Так как большая часть времени тратится на детектор, то дальнейшую оптимизацию скорости нужно проводить именно в детекторе: заменить его или перенести на GPU.
Попробовать комбинацию разных моделей распознавания, если это существенно улучшит качество.
С пользовательской точки зрения следующим шагом будет распознавание людей на видео. Также планируем информировать пользователя о наличии копий его профиля в сети с возможностью пожаловаться на клон.
Предлагайте свои идеи использования системы распознавания лиц в комментариях.
Комментарии (18)

argonavtt
07.03.2018 08:17+2Тот момент когда ты не студент и не школьник, а распознованием лиц не делал))

Wesha
07.03.2018 09:45+1
sergeypid
07.03.2018 13:02А сколько у вас нодов Cassandra если не секрет?
alatobol Автор
07.03.2018 13:27всего в ОК более 1200 нод Cassandr-ы более чем в 70ти кластерах, а для сервиса распознавания лиц, хватило и 6 нод
sergeypid
07.03.2018 13:30Вы за 120 мс успеваете просматривать на 6 нодах 300Гб векторов эмбеддинга для поиска? (нет конечно) Поделитесь секретами индексации?
blind_oracle
08.03.2018 10:44Так там поиск по первичному ключу скорее всего. В кассандре латенси на такую операцию более или менее константна около 5мс

Psychosynthesis
07.03.2018 20:42Предлагайте свои идеи использования системы распознавания лиц в комментариях.
Закупите сеть наружных камер, прикрутите сеть к ней и автоматически отмечайте геотеги пользователя по мере перемещения его по городу.
А если при этом ещё сеть интерактивных рекламных билбордов закупить, то можно вообще персонализированную видео-рекламу показывать.
eugenebb
07.03.2018 21:41Добавить распознавание настроения, окружающей обстановки (особенно если известные места) и советовать гео-пин и/или хэш-тэги к фоткам.
Ну а создание shadow profiles (как у facebook) наверное и так уже есть.
Gryphon88
07.03.2018 22:16-1Предлагайте свои идеи использования системы распознавания лиц в комментариях.
Извините, напрашивается:
1. Брать фото/видео с уличных камер для поиска «их разыскивает»
2. Выборы: детектирование каруселей, подсчёт явки


babylon
Видеоизображения дают дополнительную информацию для распознавания. Алгоритмика распознавания лиц сводится к узнаванию. Узнать конкретного китайца в толпе китайцев для некитайца проблематично. Если китаец не Джеки Чан конечно.