

Отказоустойчивость и высокая доступность — большие темы, так что посвятим RabbitMQ и Kafka отдельные статьи. Данная статья о RabbitMQ, а следующая — о Kafka, в сравнении с RabbitMQ. Статья длинная, так что устраивайтесь поудобнее.
Рассмотрим стратегии отказоустойчивости, согласованности и высокой доступности (HA), а также компромиссы, на которые приходится идти в каждой стратегии. RabbitMQ может работать на кластере узлов — и тогда классифицируется как распределенная система. Когда речь заходит о распределенных системах, мы часто говорим о согласованности и доступности.
Эти понятия описывают, как система ведет себя при сбое. Сбой сетевого соединения, сбой сервера, сбой жесткого диска, временная недоступность сервера из-за сборки мусора, потеря пакетов или замедление сетевого соединения. Все это может привести к потере данных или конфликтам. Оказывается, практически невозможно поднять систему, одновременно и полностью непротиворечивую (без потери данных, без расхождения данных), и доступную (будет принимать операции чтения и записи) для всех вариантов сбоя.
Мы увидим, что согласованность и доступность находятся на разных концах спектра, и вам нужно выбрать, в какую сторону оптимизировать. Хорошая новость в том, что с RabbitMQ такой выбор возможен. У вас эдакие «нердовские» рычажки, чтобы сдвигать баланс в сторону большей согласованности или большей доступности.
Особое внимание уделим тому, какие конфигурации приводят к потере данных из-за подтвержденных записей. Есть цепочка ответственности между паблишерами, брокерами и потребителями. После того, как сообщение передано брокеру, это его работа — не потерять сообщение. Когда брокер подтверждает паблишеру получение сообщения, мы не ожидаем, что оно будет потеряно. Но мы увидим, что такое действительно может произойти в зависимости от конфигурации вашего брокера и издателя.
Примитивы устойчивости одного узла
Устойчивые очереди/маршрутизация
В RabbitMQ два типа очереди: длительные/устойчивые (durable) и неустойчивые (non-durable). Все очереди сохраняются в базе данных Mnesia. Устойчивые очереди повторно объявляются при запуске узла и, таким образом, переживают перезапуск, сбой системы или сбой сервера (до тех пор, пока сохраняются данные). Это означает, что пока вы декларируете маршрутизацию (exchange) и очередь устойчивыми, инфраструктура очередей/маршрутизации вернется в оперативный режим.
Неустойчивые очереди и маршрутизация удаляются при перезапуске узла.
Устойчивые сообщения
Одно то, что очередь долговечна, не означает, что все её сообщения переживут перезапуск узла. Будут восстановлены только сообщения, установленные паблишером как устойчивые (persistent). Устойчивые сообщения действительно создают дополнительную нагрузку на брокера, но если потеря сообщения неприемлема, то другого выхода нет.
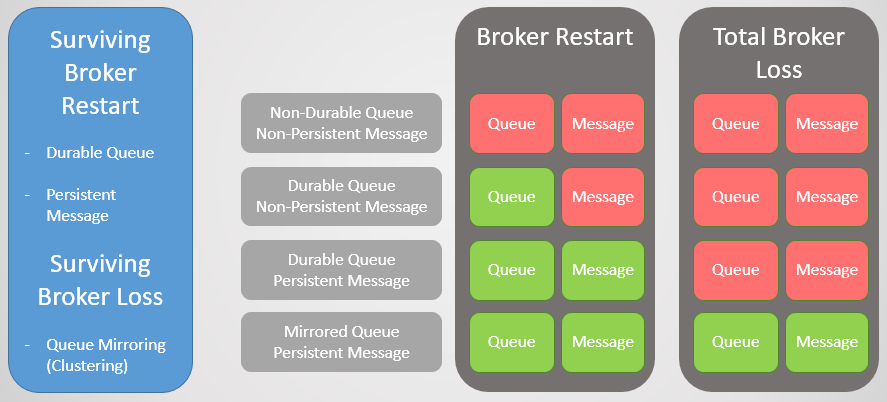
Рис. 1. Матрица устойчивости
Кластеризация с зеркалированием очереди
Чтобы пережить потерю брокера, нам нужна избыточность. Можем объединить несколько узлов RabbitMQ в кластер, а затем добавить дополнительную избыточность путём репликации очередей между несколькими узлами. Таким образом, если падает один узел, мы не теряем данные и остаёмся доступными.
Зеркалирование очереди:
- одна главная очередь (мастер), которая получает все команды на запись и чтение
- одно или несколько зеркал, которые получают все сообщения и метаданные из главной очереди. Эти зеркала существуют не для масштабирования, а исключительно для избыточности.

Рис. 2. Зеркалирование очереди
Зеркалирование устанавливается соответствующей политикой. В ней можно выбрать коэффициент репликации и даже узлы, на которых должна размещаться очередь. Примеры:
-
ha-mode: all
-
ha-mode: exactly, ha-params: 2(один мастер и одно зеркало)
ha-mode: nodes, ha-params: rabbit@node1, rabbit@node2
Подтверждение паблишеру
Для достижения последовательной записи необходимы подтверждения паблишеру (Publisher Confirms). Без них есть вероятность потери сообщений. Подтверждение отправляется паблишеру после записи сообщения на диск. RabbitMQ записывает сообщения на диск не при получении, а на периодической основе, в районе нескольких сотен миллисекунд. Когда очередь зеркалируется, подтверждение отправляется только после того, как все зеркала также записали свою копию сообщения на диск. Это означает, что использование подтверждений добавляет задержку, но если безопасность данных важна, то они необходимы.
Отказоустойчивая очередь
Когда брокер завершает работу или падает, все ведущие очереди (мастера) на этом узле отваливаются вместе с ним. Затем кластер выбирает самое старое зеркало каждого мастера и продвигает его в качестве нового мастера.
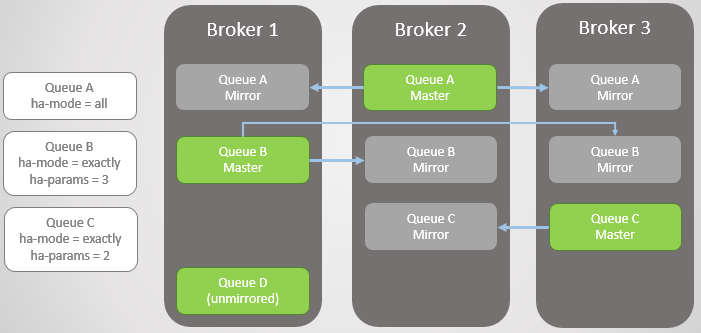
Рис. 3. Несколько зеркалированных очередей и их политики
Брокер 3 падает. Обратите внимание, что зеркало Очереди С на Брокере 2 повышается до мастера. Также обратите внимание, что для Очереди C создано новое зеркало на Брокере 1. RabbitMQ всегда пытается поддерживать коэффициент репликации, указанный в ваших политиках.
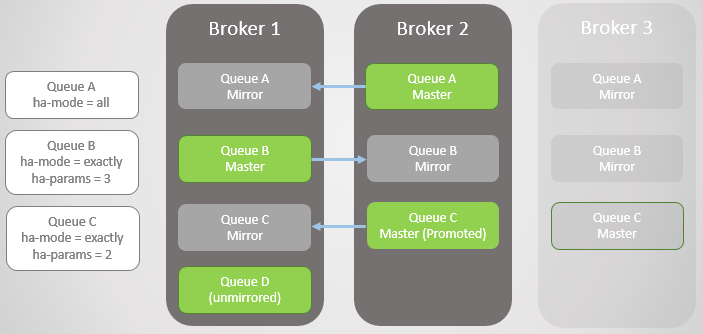
Рис. 4. Брокер 3 отваливается, что вызывает отказ очереди C
Падает следующий Брокер 1! У нас остался только один брокер. До мастера повышается зеркало Очереди B.
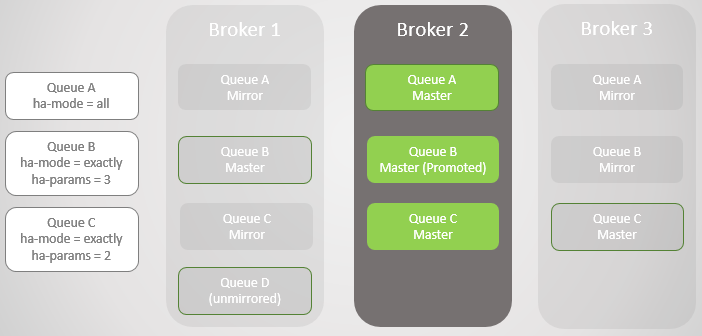
Рис. 5
Мы вернули Брокера 1. Независимо от того, насколько успешно данные пережили потерю и восстановление брокера, все зеркалированные сообщения очереди отбрасываются при перезапуске. Это важно отметить, поскольку будут последствия. Мы скоро рассмотрим эти последствия. Таким образом, Брокер 1 теперь снова является членом кластера, а кластер пытается соблюдать политики и поэтому создает зеркала на Брокере 1.
В этом случае потеря Брокера 1 была полной, как и данных, поэтому незеркалированная Очередь D потеряна полностью.
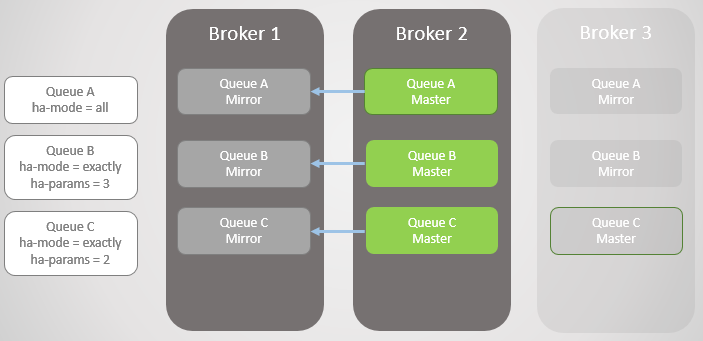
Рис. 6. Брокер 1 возвращается в строй
Брокер 3 вернулся в строй, так что очереди A и B получают обратно созданные на нём зеркала, чтобы удовлетворить своим политикам HA. Но теперь все главные очереди на одном узле! Это не идеально, лучше равномерное распределение между узлами. К сожалению, здесь нет особых вариантов для перебалансировки мастеров. Вернемся к этой проблеме позже, так как сначала нужно рассмотреть синхронизацию очереди.

Рис. 7. Брокер 3 возвращается в строй. Все главные очереди на одном узле!
Таким образом, теперь у вас должно быть представление, как зеркала обеспечивают избыточность и отказоустойчивость. Это гарантирует доступность в случае отказа одного узла и защищает от потери данных. Но мы еще не закончили, потому что на самом деле всё гораздо сложнее.
Синхронизация
При создании нового зеркала все новые сообщения всегда будут реплицироваться на это зеркало и любые другие. Что касается существующих данных в главной очереди, мы можем их реплицировать в новое зеркало, которое становится полной копией мастера. Мы также можем не реплицировать существующие сообщения и позволить главной очереди и новому зеркалу сходиться во времени, когда новые сообщения поступают в хвост, а существующие сообщения уходят из головы главной очереди.
Такая синхронизация выполняется автоматически или вручную и управляется с помощью политики очередей. Рассмотрим пример.
У нас две зеркалированные очереди. Очередь A синхронизируется автоматически, а Очередь B — вручную. В обеих очередях по десять сообщений.

Рис. 8. Две очереди с разными режимами синхронизации
Теперь мы теряем Брокера 3.

Рис. 9. Брокер 3 упал
Брокер 3 возвращается в строй. Кластер создает зеркало для каждой очереди на новом узле и автоматически синхронизирует новую Очередь А с мастером. Однако зеркало новой Очереди В остается пустым. Таким образом, у нас полная избыточность Очереди A и только одно зеркало для существующих сообщений Очереди B.
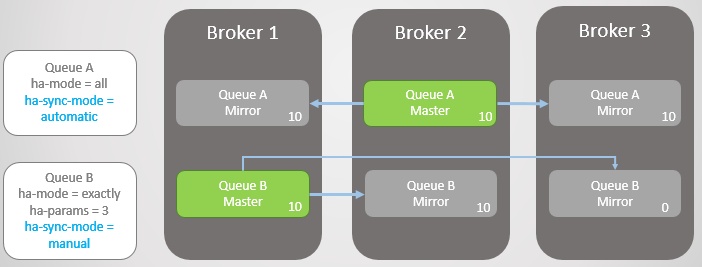
Рис. 10. Новое зеркало Очереди А получает все существующие сообщения, а новое зеркало Очереди B — нет
В обе очереди поступает ещё по десять сообщений. Затем Брокер 2 падает, а Очередь А откатывается к самому старому зеркалу, которое находится на Брокере 1. При сбое не происходит потери данных. В Очереди B двадцать сообщений в мастере и только десять в зеркале, поскольку эта очередь никогда не реплицировала исходные десять сообщений.

Рис. 11. Очередь А откатывается Брокера 1 без потери сообщений
В обе очереди поступает еще по десять сообщений. Теперь падает Брокер 1. Очередь A без проблем переключается на зеркало без потери сообщений. Однако у Очереди В возникают проблемы. На этом этапе мы можем оптимизировать либо доступность, либо согласованность.
Если мы хотим оптимизировать доступность, то политику ha-promote-on-failure следует установить в always. Это значение по умолчанию, поэтому можно просто не указывать политику вообще. В таком случае, по сути, мы допускаем сбои в несинхронизированных зеркалах. Это приведет к потере сообщений, но очередь остается доступной для чтения и записи.
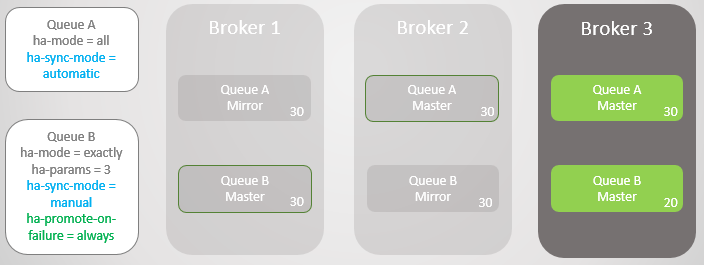
Рис. 12. Очередь А откатывается на Брокера 3 без потери сообщений. Очередь B откатывается на Брокера 3 с потерей десяти сообщений
Мы также можем установить
ha-promote-on-failure в значение when-synced. В этом случае вместо отката на зеркало очередь будет дожидаться, пока Брокер 1 со своими данными вернётся в оперативный режим. После его возвращения главная очередь снова оказывается на Брокере 1 без потери данных. Доступность приносится в жертву безопасности данных. Но это рискованный режим, который может привести даже к полной потере данных, что мы рассмотрим в ближайшее время.
Рис. 13. Очередь B остается недоступной после потери Брокера 1
Вы можете задать вопрос: «Может, лучше никогда не использовать автоматическую синхронизацию?». Ответ заключается в том, что синхронизация является блокирующей операцией. Во время синхронизации главная очередь не может выполнять никаких операций чтения или записи!
Рассмотрим пример. Сейчас у нас очень большие очереди. Как они могут вырасти до такого размера? По нескольким причинам:
- Очереди не используются активно
- Это высокоскоростные очереди, а прямо сейчас потребители работают медленно
- Это высокоскоростные очереди, произошел сбой, и потребители догоняют
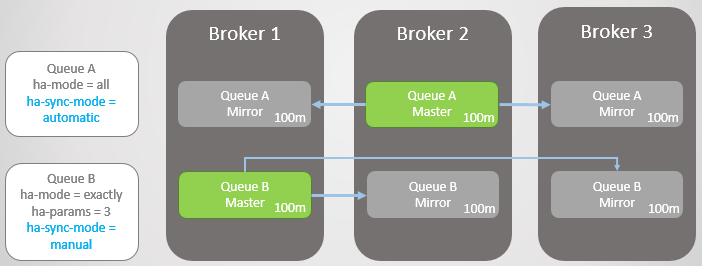
Рис. 14. Две большие очереди с разными режимами синхронизации
Теперь падает Брокер 3.
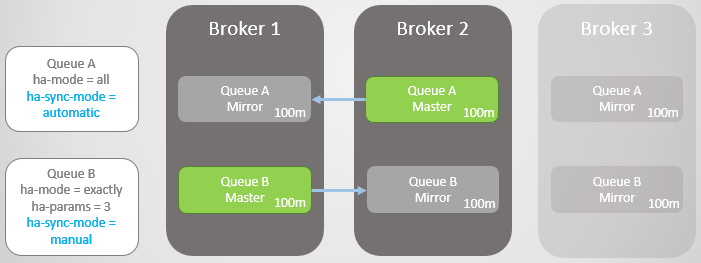
Рис. 15. Брокер 3 падает, оставляя по одному мастеру и зеркалу в каждой очереди
Брокер 3 возвращается в строй, и создаются новые зеркала. Главная Очередь А начинает реплицировать существующие сообщения на новое зеркало, и в течение этого времени Очередь недоступна. Для репликации данных требуется два часа, что приводит к двум часам простоя для этой Очереди!
Однако Очередь B остается доступной в течение всего периода. Она пожертвовала некоторой избыточностью ради доступности.

Рис. 16. Очередь остается недоступной во время синхронизации
Через два часа Очередь A тоже становится доступной и может снова начать принимать операции чтения и записи.
Обновления
Такое блокирующее поведение во время синхронизации затрудняет обновление кластеров с очень большими очередями. В какой-то момент узел с мастером нужно перезапустить, что означает либо переход на зеркало, либо отключение очереди во время обновления сервера. Если мы выберем переход, то потеряем сообщения, если зеркала не синхронизированы. По умолчанию во время отключения брокера переход на несинхронизированное зеркало не выполняется. Это означает, что как только брокер возвращается, мы не теряем никаких сообщений, единственным ущербом стал только простой очереди. Правила поведения при отключении брокера задаются политикой
ha-promote-on-shutdown. Можно установить одно из двух значений:-
always= включен переход на несинхронизированные зеркала
-
when-synced= переход только на синхронизированное зеркало, иначе очередь становится недоступной для чтения и записи. Очередь возвращается в строй, как только вернется брокер
Так или иначе, с большими очередями приходится выбирать между потерей данных и недоступностью.
Когда доступность повышает безопасность данных
Прежде чем принимать решение, нужно учесть еще одно осложнение. Хотя автоматическая синхронизация лучше для избыточности, как она влияет на безопасность данных? Конечно, благодаря лучшей избыточности RabbitMQ с меньшей вероятностью потеряет существующие сообщения, но что насчет новых сообщений от паблишеров?
Здесь нужно учесть следующее:
- Может ли паблишер просто вернуть ошибку, а вышестоящая служба или пользователь позже повторят попытку?
- Может ли паблишер сохранить сообщение локально или в базе данных, чтобы повторить попытку позже?
Если паблишер способен лишь отбросить сообщение, то, на самом деле, улучшение доступности также повышает и безопасность данных.
Таким образом, нужно искать баланс, а решение зависит от конкретной ситуации.
Проблемы с ha-promote-on-failure=when-synced
Идея ha-promote-on-failure= when-synced заключается в том, что мы предотвращаем переключение на несинхронизированное зеркало и тем самым избегаем потери данных. Очередь остается недоступной для чтения или записи. Вместо этого мы пытаемся вернуть упавший брокер с неповрежденными данными, чтобы он возобновил работу в качестве мастера без потери данных.
Но (и это большое но) если брокер потерял свои данные, то у нас большая проблема: очередь потеряна! Все данные пропали! Даже если у вас есть зеркала, которые в основном догоняют главную очередь, эти зеркала тоже отбрасываются.
Чтобы заново добавить узел с тем же именем, мы говорим кластеру забыть потерянный узел (командой rabbitmqctl forget_cluster_node) и запустить новый брокер с тем же именем хоста. Пока кластер помнит потерянный узел, он помнит старую очередь и несинхронизированные зеркала. Когда кластеру говорят забыть потерянный узел, эта очередь также забывается. Теперь нужно заново его объявить. Мы потеряли все данные, хотя у нас были зеркала с частичным набором данных. Лучше было бы перейти на несинхронизированное зеркало!
Поэтому ручная синхронизация (и невыполнение синхронизации) в сочетании с
ha-promote-on-failure=when-synced, на мой взгляд, довольно рискованна. Документы говорят, что такой вариант существует для безопасности данных, но это обоюдоострый нож.Перебалансировка мастеров
Как и было обещано, возвращаемся к проблеме скопления всех мастеров на одном или нескольких узлах. Это может произойти даже в результате «скользящего» (rolling) обновления кластера. В кластере с тремя узлами все главные очереди скопятся на одном или двух узлах.
Перебалансировка мастеров может оказаться проблематичной по двум причинам:
- Нет хороших инструментов для выполнения перебалансировки
- Синхронизация очередей
Для перебалансировки есть сторонний плагин, который не поддерживается официально. Относительно сторонних плагинов в руководстве RabbitMQ сказано: «Плагин предоставляет некоторые дополнительные инструменты настройки и отчётности, но не поддерживается и не проверен командой RabbitMQ. Используйте на свой страх и риск».
Есть еще один трюк, чтобы переместить главную очередь через политики HA. В руководстве упоминается скрипт для этого. Он работает следующим образом:
- Удаляет все зеркала с помощью временной политики с более высоким приоритетом, чем существующая политика HA.
- Изменяет временную политику HA для использования режима «узлы» с указанием узла, на который требуется перенести главную очередь.
- Синхронизирует очередь для принудительной миграции.
- После завершения миграции удаляет временную политику. Вступает в действие исходная политика HA и создается нужное количество зеркал.
Недостаток в том, что такой подход может не сработать, если у вас большие очереди или строгие требования к избыточности.
Теперь посмотрим, как кластеры RabbitMQ работают с сетевыми разделами.
Нарушение связности
Узлы распределенной системы соединяются сетевыми связями, а сетевые связи могут и будут отключаться. Частота отключений зависит от локальной инфраструктуры или надежности выбранного облака. В любом случае, распределенные системы должны быть в состоянии справиться с ними. Снова перед нами выбор между доступностью и согласованностью, и снова хорошая новость в том, что RabbitMQ обеспечивает оба варианта (просто не одновременно).
С RabbitMQ у нас две основных опции:
- Разрешить логическое разделение (split-brain). Это обеспечивает доступность, но может спровоцировать потерю данных.
- Запретить логическое разделение. Может привести к краткосрочной потере доступности в зависимости от способа подключения клиентов к кластеру. Также может привести к полной недоступности в кластере из двух узлов.
Но что такое логическое разделение? Это когда кластер разделяется надвое из-за потери сетевых связей. На каждой стороне зеркала повышаются до мастера, так что в итоге на каждую очередь приходится несколько мастеров.
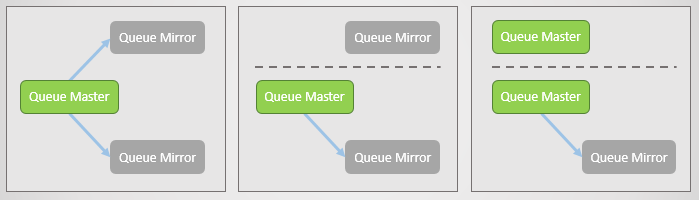
Рис. 17. Главная очередь и два зеркала, каждое на отдельном узле. Затем возникает сетевой сбой, и одно зеркало отделяется. Отделенный узел видит, что два других отвалились, и продвигает свои зеркала до мастера. Теперь у нас две главных очереди, и обе допускают запись и чтение.
Если паблишеры отправляют данные в оба мастера, у нас получится две расходящиеся копии очереди.
Различные режимы RabbitMQ обеспечивают либо доступность, либо согласованность.
Режим Ignore (по умолчанию)
Этот режим обеспечивает доступность. После потери связности происходит логическое разделение. После восстановления связности администратор должен решить, какому разделу отдать предпочтение. Проигравшая сторона будет перезапущена, и все накопленные данные с этой стороны теряются.

Рис. 18. Три паблишера связаны с тремя брокерами. Внутренне кластер направляет все запросы в главную очередь на Брокере 2.
Теперь мы теряем Брокера 3. Он видит, что другие брокеры отвалились, и продвигает свое зеркало до мастера. Так происходит логическое разделение.

Рис. 19. Логическое разделение (split-brain). Записи идут в две главные очереди, и две копии расходятся.
Связность восстанавливается, но логическое разделение остается. Администратор должен вручную выбрать проигравшую сторону. В приведенном ниже случае администратор перезагружает Брокера 3. Теряются все сообщения, которые тот не успел передать.

Рис. 20. Администратор отключает Брокера 3.

Рис. 21. Администратор запускает Брокера 3, и он присоединяется к кластеру, теряя все сообщения, которые там оставались.
Во время потери связности и после её восстановления кластер и эта очередь были доступны для чтения и записи.
Режим Autoheal
Работает аналогично режиму Ignore, за исключением того, что сам кластер автоматически выбирает проигравшую сторону после разделения и восстановления связности. Проигравшая сторона возвращается в кластер пустой, а очередь теряет все сообщения, которые были отправлены только на ту сторону.
Режим Pause Minority
Если мы не хотим допустить логического разделения, то наш единственный вариант — отказаться от чтения и записи на меньшей стороне после раздела кластера. Когда брокер видит, что находится на меньшей стороне, то приостанавливает работу, то есть закрывает все существующие соединения и отказывается от любых новых. Один раз в секунду он проверяет восстановление связности. Как только связность восстановлена, он возобновляет работу и присоединяется к кластеру.

Рис. 22. Три паблишера связаны с тремя брокерами. Внутренне кластер направляет все запросы в главную очередь на Брокере 2.
Затем Брокеры 1 и 2 отделяются от Брокера 3. Вместо того, чтобы повышать свое зеркало до мастера, Брокер 3 приостанавливает работу и становится недоступным.
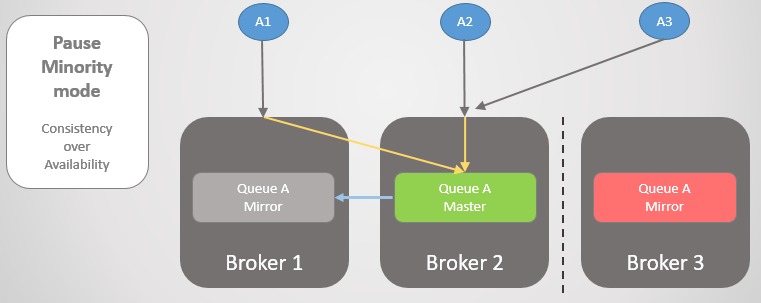
Рис. 23. Брокер 3 приостанавливает работу, отключает всех клиентов и отвергает запросы на подключение.
Как только связность восстановлена, он возвращается в кластер.
Посмотрим на другой пример, где главная очередь находится на Брокере 3.
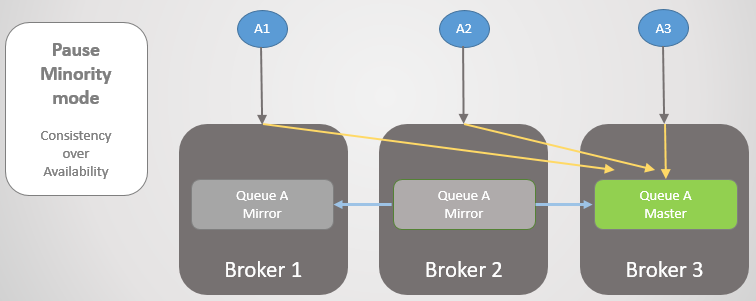
Рис. 24. Главная очередь на Брокере 3.
Затем происходит та же потеря связности. Брокер 3 встаёт на паузу, поскольку находится на меньшей стороне. На другой стороне узлы видят, что Брокер 3 отвалился, так что более старое зеркало с Брокеров 1 и 2 повышается до мастера.
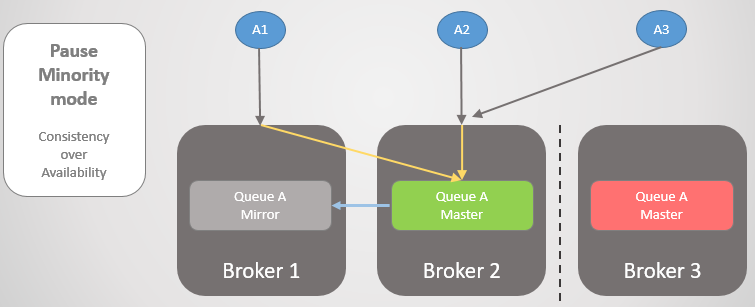
Рис. 25. Переход к Брокеру 2 при недоступности Брокера 3.
Когда связность восстановлена, Брокер 3 присоединится к кластеру.

Рис. 26. Кластер вернулся к нормальной работе.
Здесь важно понимать, что мы получаем согласованность, но также можем получить доступность, если успешно переведем клиентов на бóльшую часть раздела. Для большинства ситуаций лично я бы выбрал режим Pause Minority, но это реально зависит от конкретного случая.
Для обеспечения доступности важно убедиться, что клиенты успешно подключаются к узлу. Рассмотрим наши варианты.
Обеспечение связности клиентов
У нас несколько вариантов, как после потери связности направить клиентов на основную часть кластера или на работающие узлы (после сбоя одного узла). Сначала давайте вспомним, что конкретная очередь размещается на определенном узле, но маршрутизация и политики реплицируются на всех узлах. Клиенты могут подключаться к любому узлу, а внутренняя маршрутизация направит их куда надо. Но когда узел приостановлен, он отвергает соединения, поэтому клиенты должны подключиться к другому узлу. Если узел отвалился, он вообще мало что может сделать.
Наши варианты:
- Доступ к кластеру осуществляется с помощью балансировщика нагрузки, который просто циклически перебирает узлы, а клиенты выполняют повторные попытки подключения до успешного завершения. Если узел не работает или приостановлен, то попытки подключения к этому узлу завершатся неудачей, но последующие попытки пойдут на другие серверы (в циклическом режиме). Это подходит для кратковременной потери связности или упавшего сервера, который будет быстро поднят.
- Доступ к кластеру через балансировщик нагрузки и удаление приостановленных/упавших узлов из списка, как только они обнаружены. Если быстро это сделать, и если клиенты способны на повторные попытки подключения, то мы получим постоянную доступность.
- Дать каждому клиенту список всех узлов, а клиент при подключении случайным образом выбирает один из них. Если при попытке подключения он получает ошибку, то переходит к следующему узлу в списке, пока не подключится.
- Убрать трафик от упавшего/приостановленного узла с помощью DNS. Это делается при помощи малого TTL.
Выводы
У кластеризации RabbitMQ свои преимущества и недостатки. Наиболее серьезные недостатки заключаются в том, что:
- при присоединении к кластеру узлы отбрасывают свои данные;
- блокирующая синхронизация приводит к недоступности очереди.
Все трудные решения вытекают из этих двух особенностей архитектуры. Если бы RabbitMQ мог сохранять данные при воссоединении кластера, то синхронизация происходила бы быстрее. Если бы он был способен на неблокирующую синхронизацию, то лучше поддерживал большие очереди. Устранение этих двух проблем серьёзно улучшило бы характеристики RabbitMQ в качестве отказоустойчивой и высокодоступной технологии обмена сообщениями. Я бы не решился рекомендовать RabbitMQ с кластеризацией в следующих ситуациях:
- Ненадёжная сеть.
- Ненадёжное хранение.
- Очень большие очереди.
Что касается настроек для высокой доступности, то рассмотрите такие:
-
ha-promote-on-failure=always
-
ha-sync-mode=manual
-
cluster_partition_handling=ignore(илиautoheal)
- устойчивые сообщения
- убедитесь, что клиенты подключаются к активному узлу, когда какой-то узел выходит из строя
Для согласованности (безопасности данных) рассмотрите следующие настройки:
- Publisher Confirms и Manual Acknowledgements на стороне потребителя
-
ha-promote-on-failure=when-synced, если издатели могут повторить попытку позже и если у вас есть очень надежное хранилище! Иначе ставьте=always.
-
ha-sync-mode=automatic(но для больших неактивных очередей может потребоваться ручной режим; кроме того, подумайте, не приведет ли недоступность к потере сообщений)
- режим Pause Minority
- устойчивые сообщения
Мы рассмотрели еще не все вопросы отказоустойчивости и высокой доступности; например, как безопасно выполнять административные процедуры (такие, как скользящие обновления). Нужно поговорить также о федерировании и плагине Shovel.
Если я еще что-то упустил, пожалуйста, дайте знать.
См. также мой пост, где я осуществляю погром в кластере RabbitMQ с помощью Docker и Blockade, чтобы проверить некоторые сценарии потери сообщений, описанные в этой статье.
Предыдущие статьи серии:
№1 — habr.com/ru/company/itsumma/blog/416629
№2 — habr.com/ru/company/itsumma/blog/418389
№3 — habr.com/ru/company/itsumma/blog/437446
Комментарии (4)

AzriMan
06.11.2019 19:41В этом случае потеря Брокера 1 была полной, как и данных, поэтому незеркалированная Очередь В потеряна полностью.
Скорее всего, имеется ввиду Очередь D?
Откуда на Рис. 12 в Broker 2 (который ещё лежит) появились новые сообщения? Их количество должно быть равно 20 (которое было во время падения), в каждой очереди.
Sjam
Спасибо за материал. Однако так и не нашел где в стате про Kafka?
AzriMan
Написано в первом абзаце.
Sjam
Благодарю. Был не внимателен.