Кодируйте? ?одни? ?и? ?те? ?же? ?данные? ?гораздо? ?меньшим? ?количеством? ?байт.? ?
?
Данные? ?хранятся? ?в? ?памяти? ?в? ?виде? ?структур? ?данных,? ?таких? ?как? ?объекты,? ?списки,? ?массивы? ?и? ?т.д.? ?Но? ?если? ?вы? ?хотите? ?отправить? ?данные? ?по? ?сети? ?или? ?в? ?файле,? ?вам? ?нужно? ?закодировать? ?их? ?в? ?виде? ?последовательности? ?байтов.? ?Перевод? ?из? ?представления? ?в? ?памяти? ?в? ?последовательность? ?байтов? ?называется? ?кодированием,? ?а? ?обратное? ?преобразование? ?–? ?декодированием.? ?Со? ?временем? ?схема? ?данных,? ?обрабатываемых? ?приложением? ?или? ?хранящихся? ?в? ?памяти,? ?может? ?эволюционировать,? ?туда? ?могут? ?добавляться? ?новые? ?поля? ?или? ?удаляться? ?старые.? ?Следовательно,? ?используемая? ? кодировка? ?должна? ?иметь? ?как? ?обратную? ?(новый? ?код? ?должен? ?быть? ?способен? ?читать? ?данные,? ?написанные? ?старым? ?кодом),? ?так? ?и? ?прямую? ?(старый? ?код? ?должен? ?быть? ?способен? ?читать? ?данные,? ?написанные? ?новым? ?кодом)? ?совместимость.? ?
?
В? ?этой? ?статье? ?мы? ?обсудим? ?различные? ?форматы? ?кодирования,? ?выясним? ?почему? ?двоичное? ?кодирование? ?лучше,? ?чем? ?JSON? ?и? ?XML,? ?и? ?как? ?методы? ?двоичного? ?кодирования? ?поддерживают? ?изменения? ?в? ?схемах? ?данных.? ?
?
Существует? ?два? ?типа? ?форматов? ?кодирования:? ?
?Текстовые форматы в некоторой степени человекочитаемы. Примеры распространенных форматов — JSON, CSV и XML. Текстовые форматы просты в использовании и понимании, но имеют определенные проблемы:
JSON-кодировка этого примера после удаления всех символов пробела занимает 82 байта.
Для анализа данных, которые используются только внутри организации, вы можете выбрать более компактный или более быстрый формат. Несмотря на то, что JSON менее многословен, чем XML, оба они все равно занимают много места по сравнению с двоичными форматами. В этой статье мы обсудим три различных бинарных формата кодирования:
Все они обеспечивают эффективную сериализацию данных с использованием схем и имеют инструменты для генерации кода, а также поддерживают работу с разными языками программирования. Все они поддерживают эволюцию схем, обеспечивая как обратную, так и прямую совместимость.
Thrift разработан Facebook, а Protocol Buffers – Google. В обоих случаях для кодирования данных требуется схема. В Thrift схема определяется с помощью собственного языка определения интерфейса (IDL).
Эквивалентная схема для Protocol Buffers:
Как видите, у каждого поля имеется тип данных и номер тега (1, 2 и 3). У Thrift есть два различных формата двоичной кодировки: BinaryProtocol и CompactProtocol. Двоичный формат прост, как показано ниже, и занимает 59 байт для кодирования данных, приведенных выше.
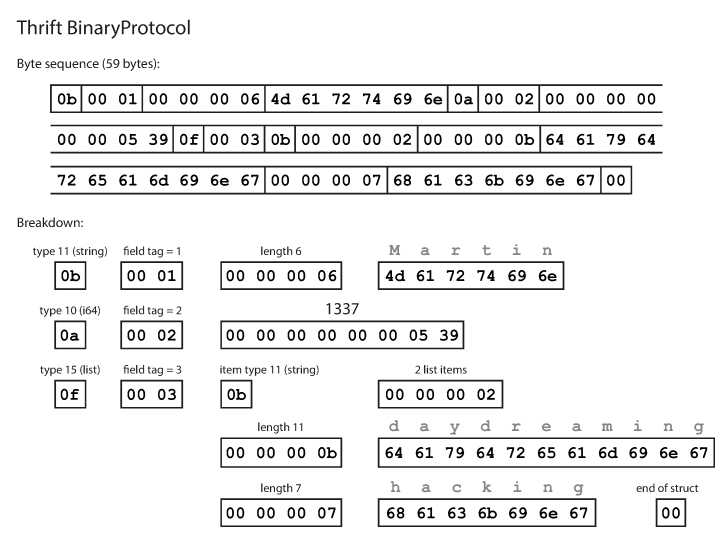
Кодирование с использованием двоичного протокола Thrift
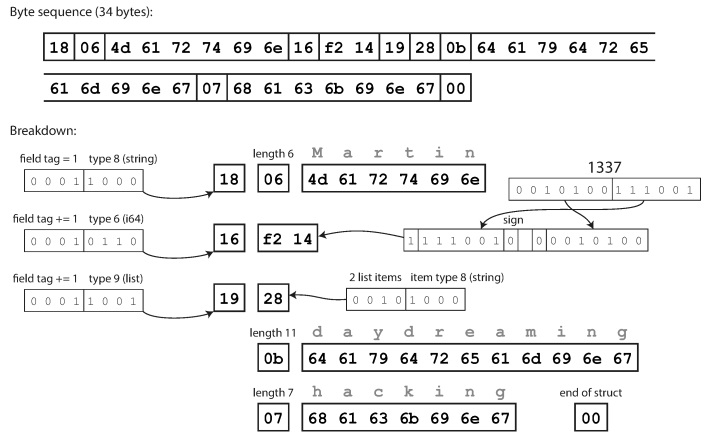
Компактный протокол семантически эквивалентен бинарному, но упаковывает одну и ту же информацию всего в 34 байта. Экономия достигается за счет упаковки типа поля и номера метки в один байт.
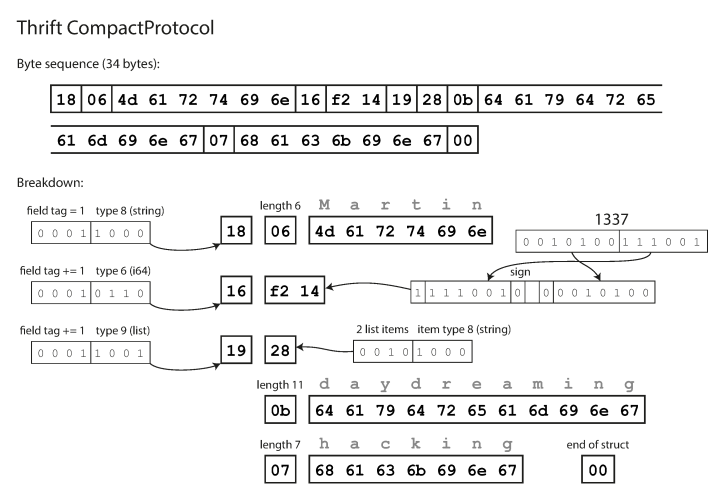
Кодирование с использованием протокола Thrift Compact
Protocol Buffers кодирует данные аналогично компактному протоколу в Thrift, и после кодирования эти же данные занимают 33 байта.
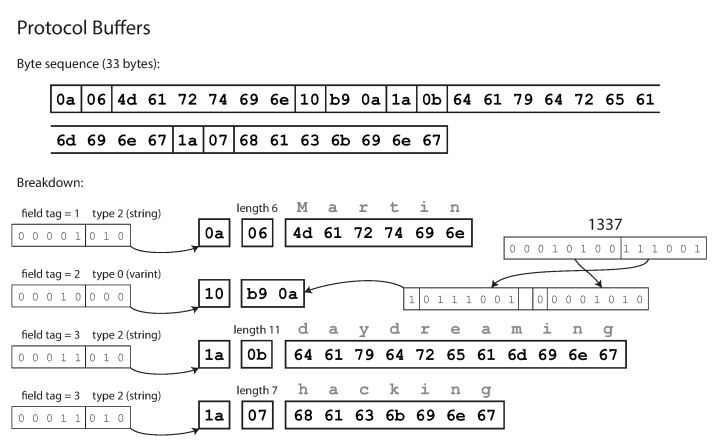
Кодирование с использованием Protocol Buffers
Номера тегов обеспечивают эволюцию схем в Thrift и Protocol Buffers. Если старый код попытается прочитать данные, записанные с новой схемой, он просто проигнорирует поля с новыми номерами тегов. Аналогично, новый код может прочитать данные, записанные по старой схеме, пометив значения как null для пропущенных номеров тегов.
Avro отличается от Protocol Buffers и Thrift. Avro также использует схему для определения данных. Схему можно определить, используя IDL Avro (человекочитаемый формат):
Или JSON (более машиночитаемый формат):
Обратите внимание, что у полей нет номеров меток. Те же самые данные, закодированные с помощью Avro, занимают всего 32 байта.
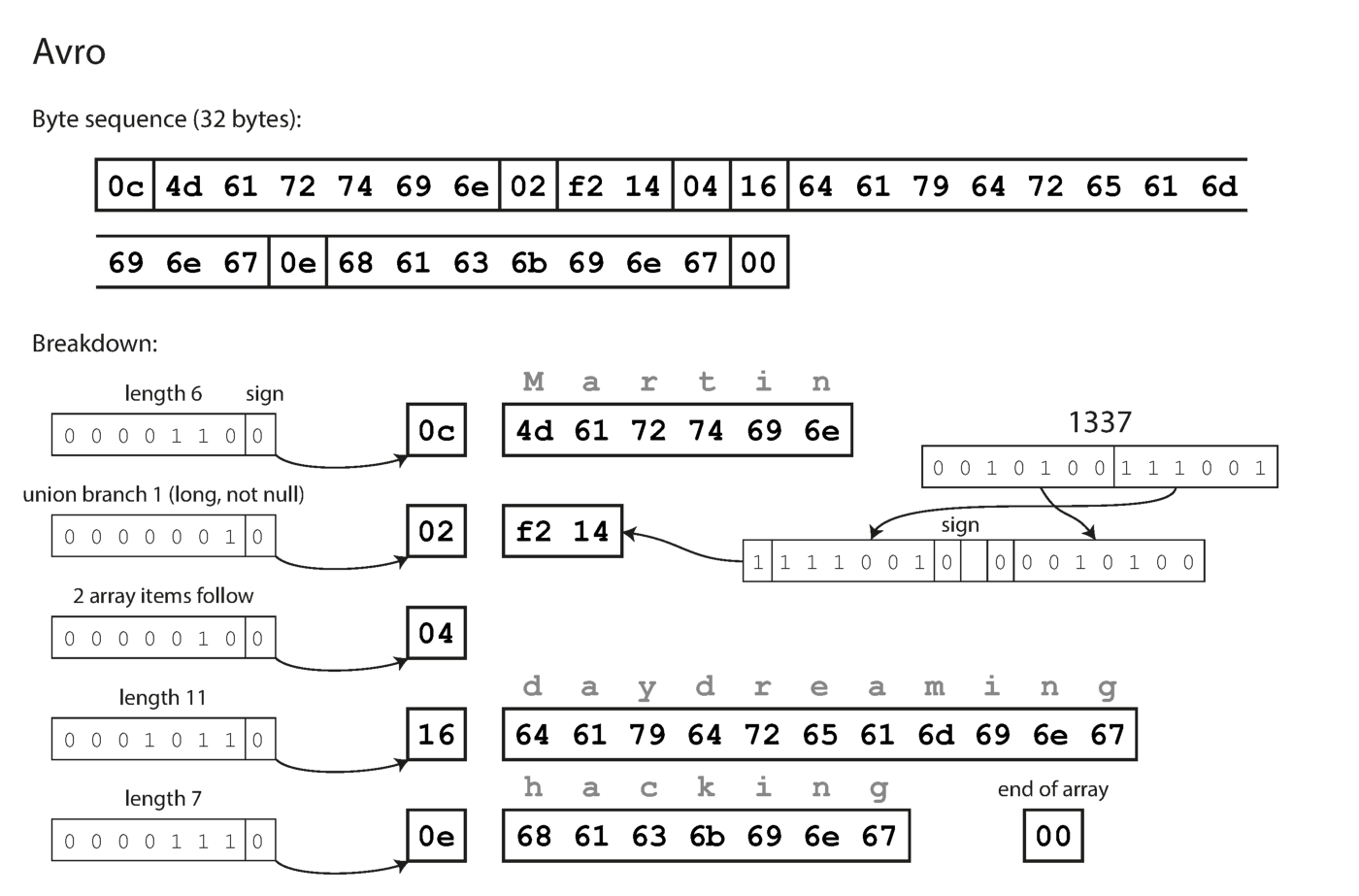
Кодирование с помощью Avro.
Как видно из вышеприведенной последовательности байт, поля не могут быть идентифицированы (в Thrift и Protocol Buffers для этого используются метки с номерами), также невозможно определить тип данных поля. Значения просто собираются воедино. Означает ли это, что любое изменение схемы при декодировании будет генерировать некорректные данные? Ключевая идея Avro заключается в том, что схема для записи и чтения не обязательно должна быть одинаковой, но должна быть совместимой. Когда данные декодируются, библиотека Avro решает эту проблему, просматривая обе схемы и транслируя данные из схемы записывающего устройства в схему читающего устройства.
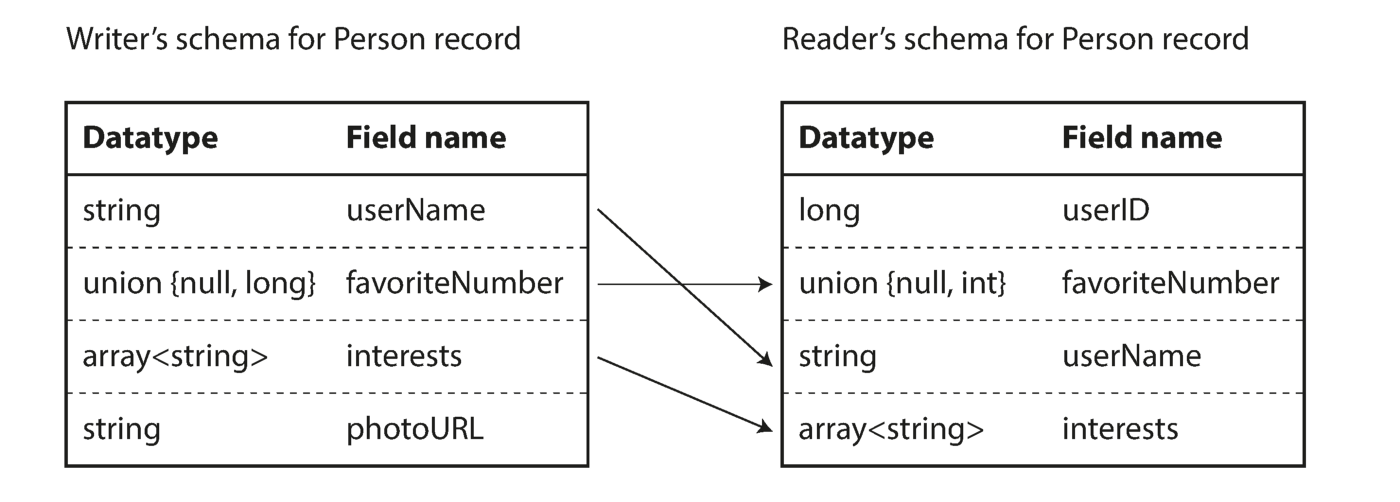
Устранение различий между схемой читающего и записывающего устройства
Вы, наверное, думаете о том, как читающее устройство узнает о схеме пишущего. Все дело в сценарии использования кодировки.
Одним из основных преимуществ использования формата Avro является поддержка динамически генерируемых схем. Так как метки с номерами не генерируются, вы можете использовать систему контроля версий для хранения различных записей, закодированных с разными схемами.
В этой статье мы рассмотрели текстовые и двоичные форматы кодирования, обсудили как одни и те же данные могут занимать 82 байта с кодировкой JSON, 33 байта с кодировкой Thrift и Protocol Buffers, и всего 32 байта с помощью кодировки Avro. Двоичные форматы предлагают несколько неоспоримых преимуществ по сравнению с JSON при передаче данных в сети между внутренними службами.
Чтобы узнать больше о кодировках и проектировании приложений c интенсивной обработкой данных, я настоятельно рекомендую прочитать книгу Мартина Клеппмана «Designing Data-Intensive Applications».

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
?
Почему? ?меня? ?это? ?должно? ?волновать ?
?Данные? ?хранятся? ?в? ?памяти? ?в? ?виде? ?структур? ?данных,? ?таких? ?как? ?объекты,? ?списки,? ?массивы? ?и? ?т.д.? ?Но? ?если? ?вы? ?хотите? ?отправить? ?данные? ?по? ?сети? ?или? ?в? ?файле,? ?вам? ?нужно? ?закодировать? ?их? ?в? ?виде? ?последовательности? ?байтов.? ?Перевод? ?из? ?представления? ?в? ?памяти? ?в? ?последовательность? ?байтов? ?называется? ?кодированием,? ?а? ?обратное? ?преобразование? ?–? ?декодированием.? ?Со? ?временем? ?схема? ?данных,? ?обрабатываемых? ?приложением? ?или? ?хранящихся? ?в? ?памяти,? ?может? ?эволюционировать,? ?туда? ?могут? ?добавляться? ?новые? ?поля? ?или? ?удаляться? ?старые.? ?Следовательно,? ?используемая? ? кодировка? ?должна? ?иметь? ?как? ?обратную? ?(новый? ?код? ?должен? ?быть? ?способен? ?читать? ?данные,? ?написанные? ?старым? ?кодом),? ?так? ?и? ?прямую? ?(старый? ?код? ?должен? ?быть? ?способен? ?читать? ?данные,? ?написанные? ?новым? ?кодом)? ?совместимость.? ?
?
В? ?этой? ?статье? ?мы? ?обсудим? ?различные? ?форматы? ?кодирования,? ?выясним? ?почему? ?двоичное? ?кодирование? ?лучше,? ?чем? ?JSON? ?и? ?XML,? ?и? ?как? ?методы? ?двоичного? ?кодирования? ?поддерживают? ?изменения? ?в? ?схемах? ?данных.? ?
?
Типы? ?форматов? ?кодирования?
?Существует? ?два? ?типа? ?форматов? ?кодирования:? ?
- Текстовые? ?форматы? ?
- Двоичные? ?форматы?
Текстовые? ?форматы?
??Текстовые форматы в некоторой степени человекочитаемы. Примеры распространенных форматов — JSON, CSV и XML. Текстовые форматы просты в использовании и понимании, но имеют определенные проблемы:
- Текстовые форматы могут быть очень неоднозначны. Например, в XML и CSV нельзя различать строки и числа. JSON может различать строки и числа, но не может различать целые и вещественные числа, а также не задает точности. Это становится проблемой при работе с большими числами. Так, проблема с числами, большими чем 2^53 встречается в Twitter, который использует 64-битное число для идентификации каждого твита. JSON, возвращаемый API Twitter, включает в себя ID твита дважды — в виде JSON-числа и в виде десятичной строки – все из-за того, что JavaScript-приложения не всегда верно распознают числа.
- CSV не имеет схемы данных, возлагая определение значения каждой строки и столбца на приложение.
- Текстовые форматы занимают больше места, чем двоичная кодировка. Например, одна из причин заключается в том, что JSON и XML не имеют схемы, а потому они должны содержать имена полей.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}JSON-кодировка этого примера после удаления всех символов пробела занимает 82 байта.
Двоичное кодирование
Для анализа данных, которые используются только внутри организации, вы можете выбрать более компактный или более быстрый формат. Несмотря на то, что JSON менее многословен, чем XML, оба они все равно занимают много места по сравнению с двоичными форматами. В этой статье мы обсудим три различных бинарных формата кодирования:
- Thrift
- Protocol Buffers
- Avro
Все они обеспечивают эффективную сериализацию данных с использованием схем и имеют инструменты для генерации кода, а также поддерживают работу с разными языками программирования. Все они поддерживают эволюцию схем, обеспечивая как обратную, так и прямую совместимость.
Thrift и Protocol Buffers
Thrift разработан Facebook, а Protocol Buffers – Google. В обоих случаях для кодирования данных требуется схема. В Thrift схема определяется с помощью собственного языка определения интерфейса (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Эквивалентная схема для Protocol Buffers:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Как видите, у каждого поля имеется тип данных и номер тега (1, 2 и 3). У Thrift есть два различных формата двоичной кодировки: BinaryProtocol и CompactProtocol. Двоичный формат прост, как показано ниже, и занимает 59 байт для кодирования данных, приведенных выше.
Кодирование с использованием двоичного протокола Thrift
Компактный протокол семантически эквивалентен бинарному, но упаковывает одну и ту же информацию всего в 34 байта. Экономия достигается за счет упаковки типа поля и номера метки в один байт.
Кодирование с использованием протокола Thrift Compact
Protocol Buffers кодирует данные аналогично компактному протоколу в Thrift, и после кодирования эти же данные занимают 33 байта.
Кодирование с использованием Protocol Buffers
Номера тегов обеспечивают эволюцию схем в Thrift и Protocol Buffers. Если старый код попытается прочитать данные, записанные с новой схемой, он просто проигнорирует поля с новыми номерами тегов. Аналогично, новый код может прочитать данные, записанные по старой схеме, пометив значения как null для пропущенных номеров тегов.
Avro
Avro отличается от Protocol Buffers и Thrift. Avro также использует схему для определения данных. Схему можно определить, используя IDL Avro (человекочитаемый формат):
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Или JSON (более машиночитаемый формат):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Обратите внимание, что у полей нет номеров меток. Те же самые данные, закодированные с помощью Avro, занимают всего 32 байта.
Кодирование с помощью Avro.
Как видно из вышеприведенной последовательности байт, поля не могут быть идентифицированы (в Thrift и Protocol Buffers для этого используются метки с номерами), также невозможно определить тип данных поля. Значения просто собираются воедино. Означает ли это, что любое изменение схемы при декодировании будет генерировать некорректные данные? Ключевая идея Avro заключается в том, что схема для записи и чтения не обязательно должна быть одинаковой, но должна быть совместимой. Когда данные декодируются, библиотека Avro решает эту проблему, просматривая обе схемы и транслируя данные из схемы записывающего устройства в схему читающего устройства.
Устранение различий между схемой читающего и записывающего устройства
Вы, наверное, думаете о том, как читающее устройство узнает о схеме пишущего. Все дело в сценарии использования кодировки.
- При передаче больших файлов или данных, записывающее устройство может однократно включить схему в начало файла.
- В БД с индивидуальными записями каждая строка может быть записана со своей схемой. Самое простое решение – указывать номер версии в начале каждой записи и сохранять список схем.
- Для отправки записи в сети, читающее и записывающее устройства могут согласовать схему при установке соединения.
Одним из основных преимуществ использования формата Avro является поддержка динамически генерируемых схем. Так как метки с номерами не генерируются, вы можете использовать систему контроля версий для хранения различных записей, закодированных с разными схемами.
Заключение
В этой статье мы рассмотрели текстовые и двоичные форматы кодирования, обсудили как одни и те же данные могут занимать 82 байта с кодировкой JSON, 33 байта с кодировкой Thrift и Protocol Buffers, и всего 32 байта с помощью кодировки Avro. Двоичные форматы предлагают несколько неоспоримых преимуществ по сравнению с JSON при передаче данных в сети между внутренними службами.
Ресурсы
Чтобы узнать больше о кодировках и проектировании приложений c интенсивной обработкой данных, я настоятельно рекомендую прочитать книгу Мартина Клеппмана «Designing Data-Intensive Applications».
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence










usrsse2
В .NET есть как текстовый, так и бинарный XML, он поддерживается DataContractSerializer.