Как сделать крутые, полностью интерактивные графики с помощью одной строки Python
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
За последние несколько месяцев я понял, что единственная причина, по которой я использую matplotlib, — это сотни часов, которые я потратил на изучение сложного синтаксиса. Эти сложности приводят к часам разочарования, выясняя на StackOverflow, как форматировать даты или добавить вторую ось Y. К счастью, это прекрасное время для построения графиков в Python, и после изучения вариантов, явным победителем — с точки зрения простоты использования, документации и функциональности — является библиотека plotly. В этой статье мы погрузимся прямо в plotly, изучая, как создавать лучшие графики за меньшее время — часто с помощью одной строки кода.
Весь код для этой статьи доступен на GitHub. Все графики являются интерактивными и могут быть просмотрены на NBViewer.
Пакет plotly для Python — это библиотека с открытым исходным кодом, построенная на plotly.js, которая, в свою очередь, построена на d3.js. Мы будем использовать обертку над plotly под названием cufflinks, предназначенную для работы с Pandas DataFrame Итак, наш стек cufflinks > plotly > plotly.js> d3.js — это означает, что мы получаем эффективность программирования на Python с невероятными интерактивными графическими возможностями d3.
(Сама Plotly — графическая компания с несколькими продуктами и инструментами с открытым исходным кодом. Библиотека для Python бесплатна для использования, и мы можем создавать неограниченное количество диаграмм в автономном режиме плюс до 25 диаграмм в онлайн-режиме, чтобы поделиться ими со всем миром.)
Вся работа в этой статье была выполнена в Jupyter Notebook с plotly + cufflinks, работающими в автономном режиме. После установки plotly и cufflinks с помощью
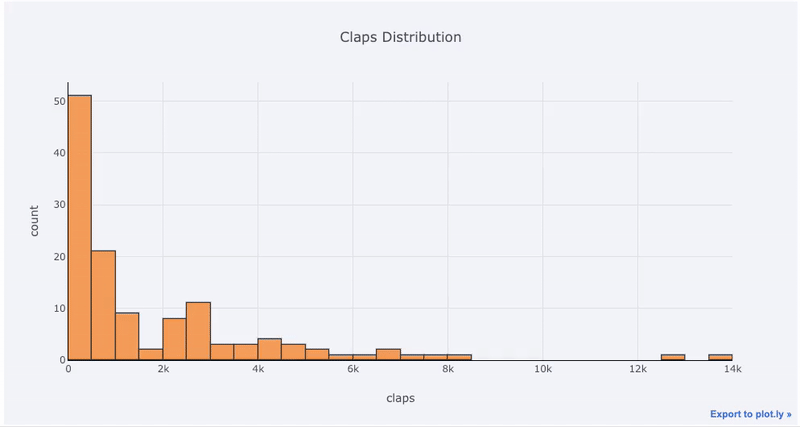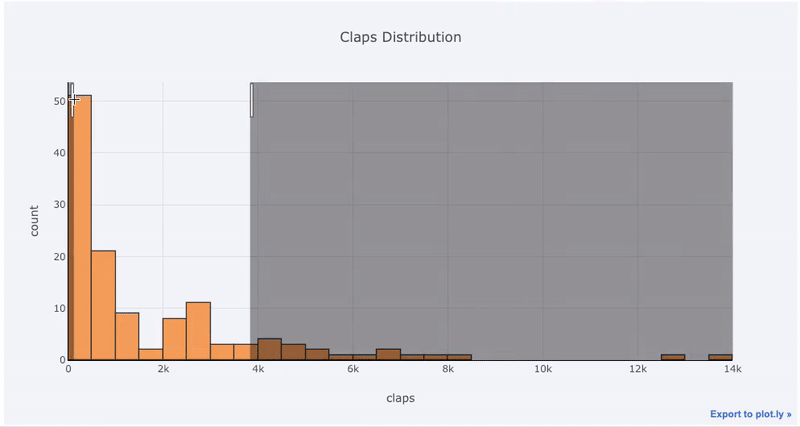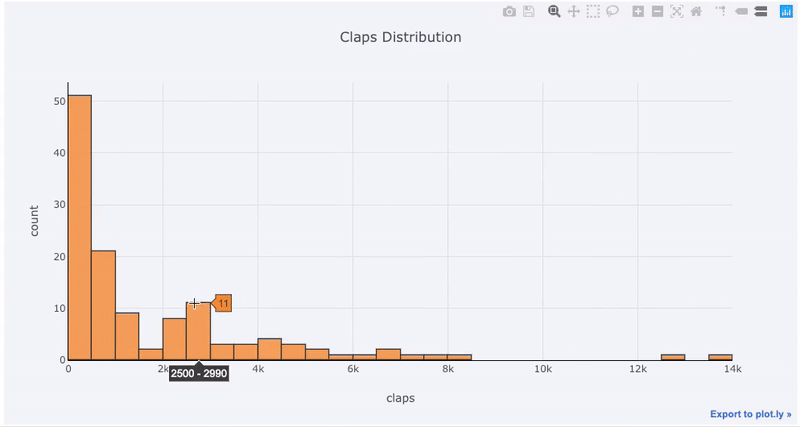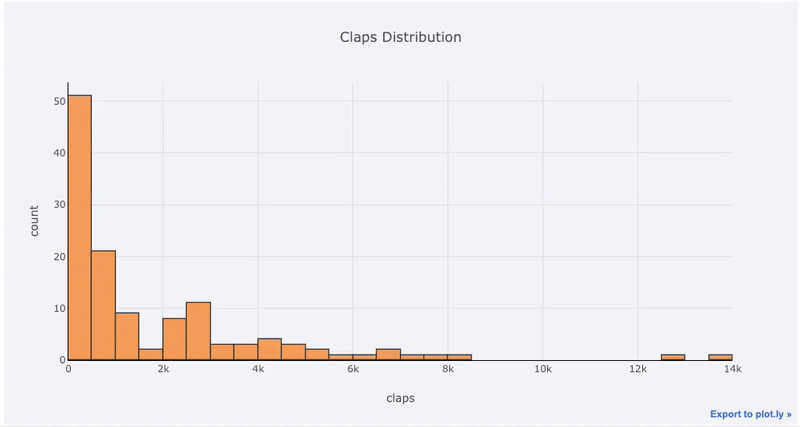
Графики с одной переменной — одномерный — это стандартный способ начать анализ, а гистограмма-это график перехода (хотя и с некоторыми проблемами) для построения графика распределения. Здесь, используя мою среднюю статистику по статьям (Вы можете увидеть, как получить свою собственную статистику здесь или использовать мою), давайте сделаем интерактивную гистограмму количества хлопков на статьях (
Для тех, кто привык к
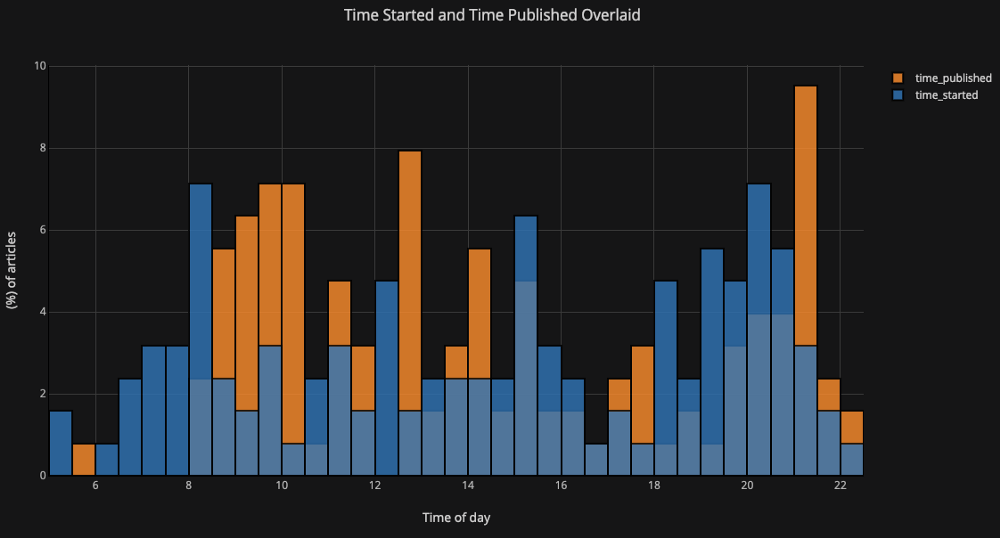
Если мы хотим построить наложенные гистограммы, это так же просто:
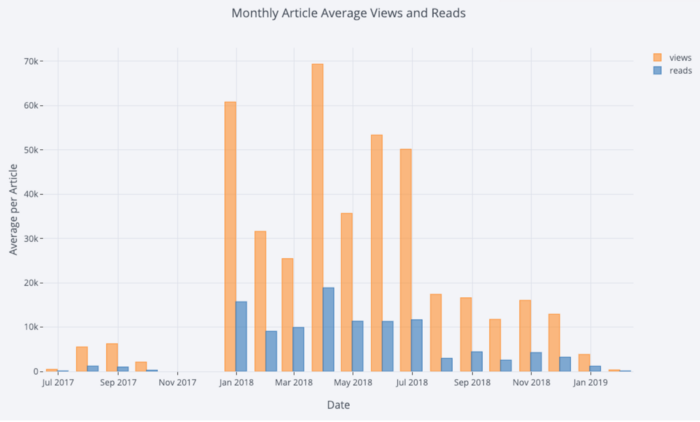
Немного манипулируя
как мы уже видели, мы можем объединить силу Pandas с plotly + cufflinks. Для боксплота распределение фанов по публикациям, мы используем
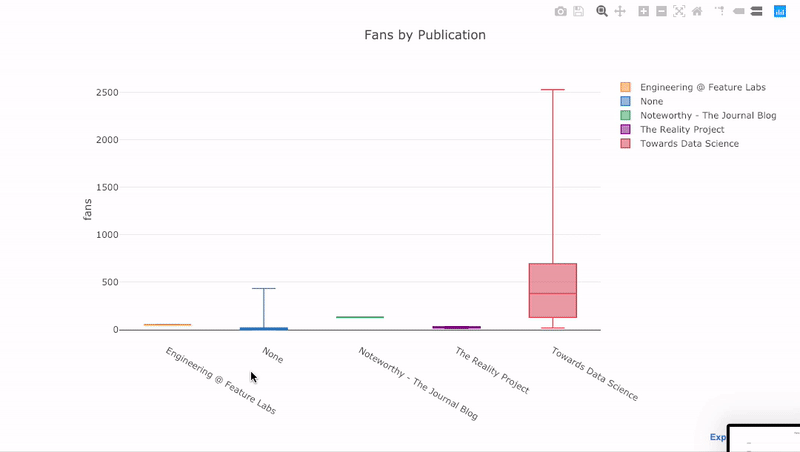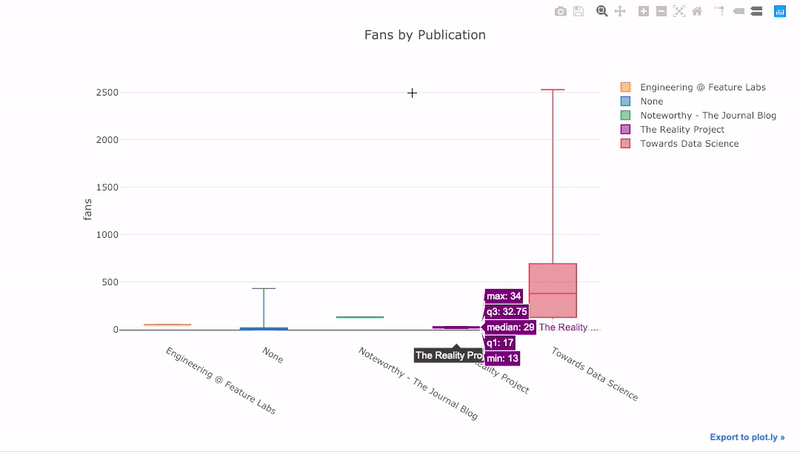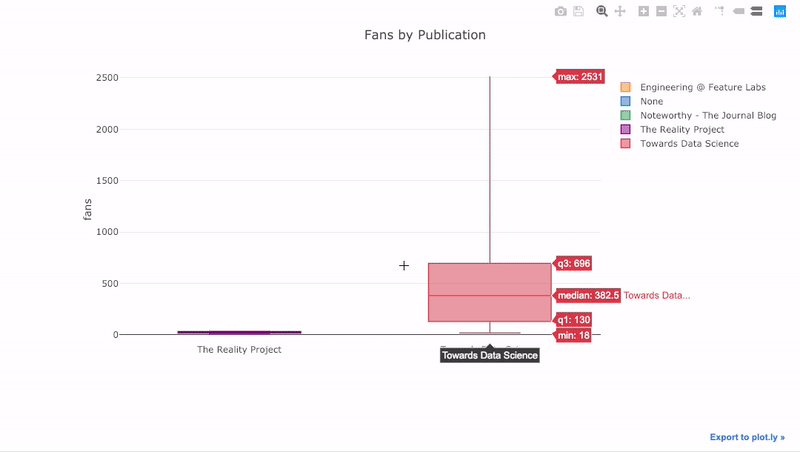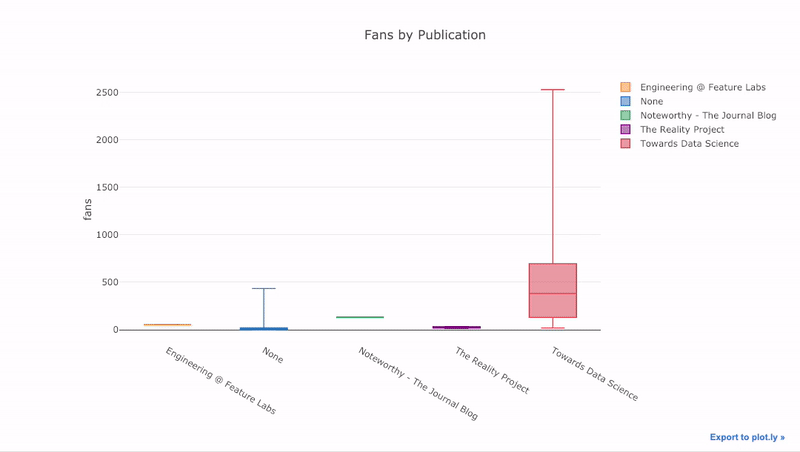
Преимущества интерактивности заключаются в том, что мы можем исследовать и размещать данные по своему усмотрению. В бокс-плоте много информации, и без возможности видеть цифры мы упустим большую ее часть!
Диаграмма рассеяния является сердцем большинства анализов. Это позволяет нам увидеть эволюцию переменной во времени или связь между двумя (или более) переменными.
Значительная часть реальных данных имеет элемент времени. К счастью, plotly + cufflinks был разработан с учетом визуализации временных рядов. Давайте сделаем фрейм данных из моих статей TDS и посмотрим, как изменились тенденции.
Здесь мы видим довольно много разных вещей:
Для получения дополнительной информации мы также можем довольно легко добавлять текстовые аннотации:
Для двухпеременной точечной диаграммы, окрашенной третьей категориальной переменной, мы используем:
Давайте немного усложним задачу, используя логарифмическую ось, заданную как макет plotly — (см. документацию Plotly по спецификациям макета), и определив размер пузырьков числовой переменной:
Немного поработав (Подробнее см. NoteBook), мы можем даже поместить четыре переменные (это не рекомендуется) на один график!
Как и раньше, мы можем комбинировать Pandas с plotly+cufflinks для полезных графиков
Дополнительные примеры функциональности смотрите в notebook или документации. Мы можем добавлять текстовые аннотации, опорные линии и наиболее подходящие линии к нашим диаграммам с помощью одной строки кода и по-прежнему со всеми взаимодействиями.
Теперь мы перейдем к несколькимграфикам, которые вы, вероятно, не будете использовать так часто, но которые могут быть весьма впечатляющими. Мы будем использовать plotly figure_factory, чтобы делать даже эти невероятные гафики в одну строку.
Когда мы хотим исследовать отношения между многими переменными, матрица рассеяния (также называемая splom) является отличным вариантом:
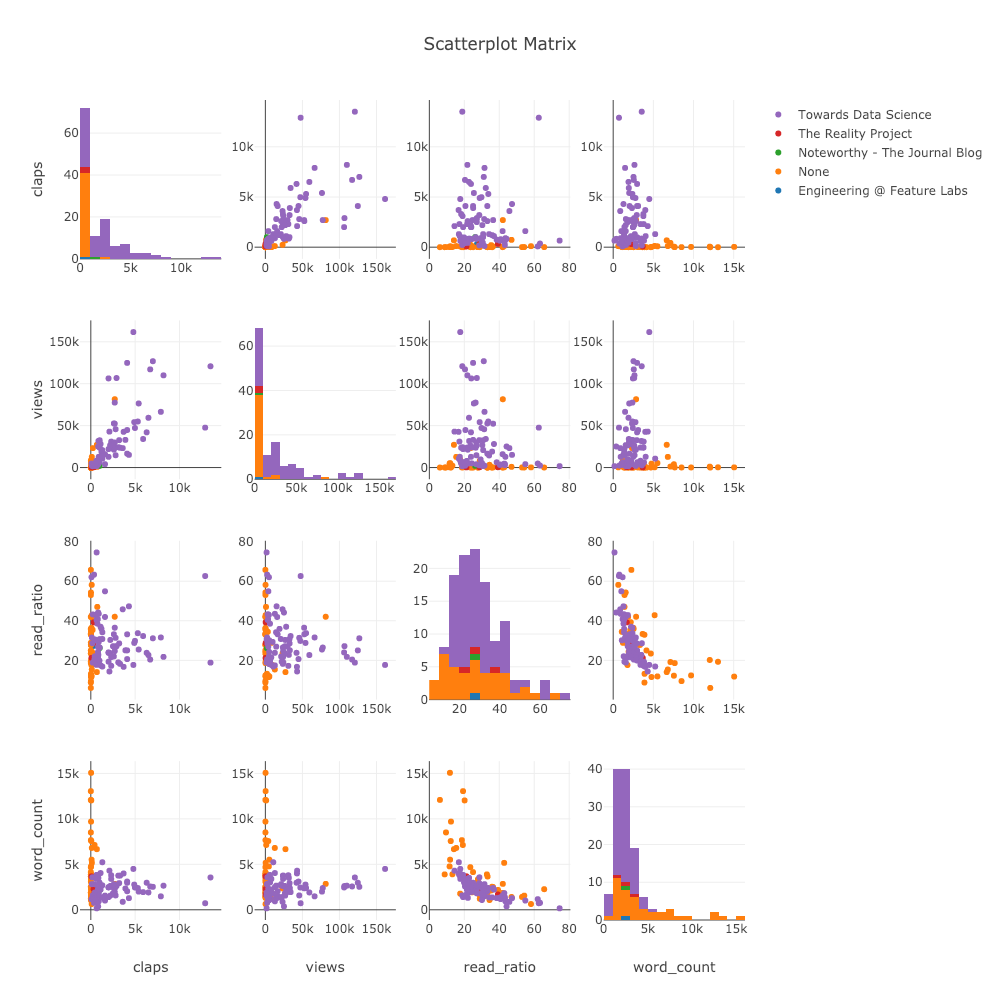
Даже этот график полностью интерактивный, что позволяет нам исследовать данные.
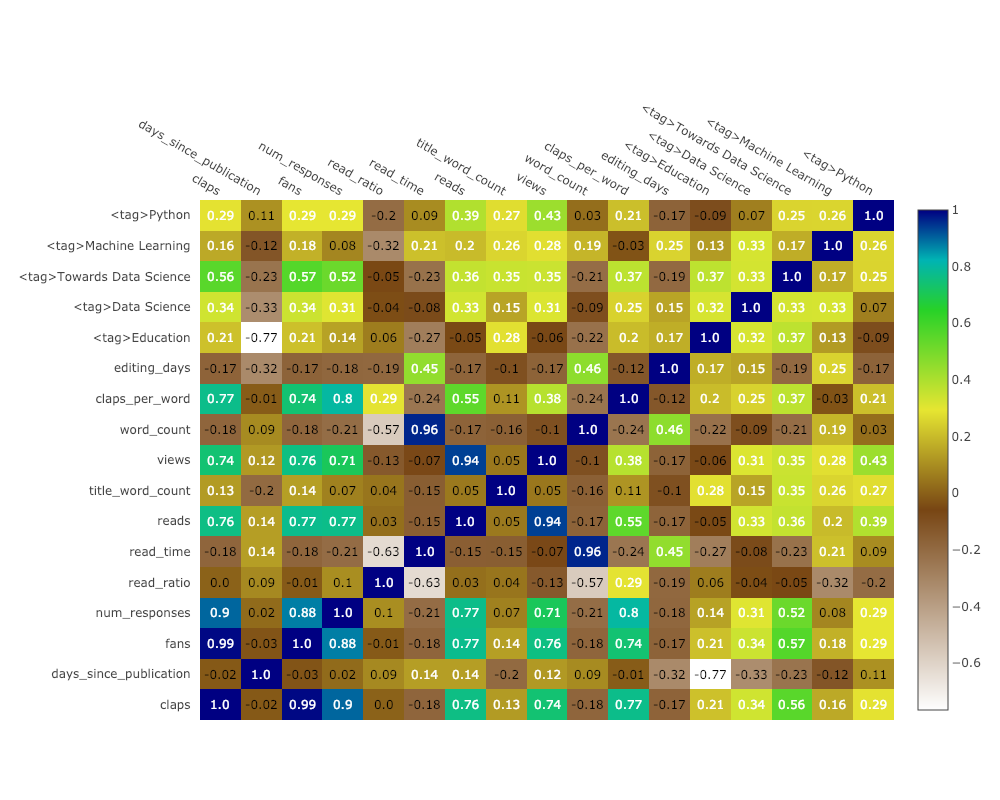
Чтобы визуализировать корреляции между числовыми переменными, мы вычисляем корреляции, а затем делаем аннотированную тепловую карту:
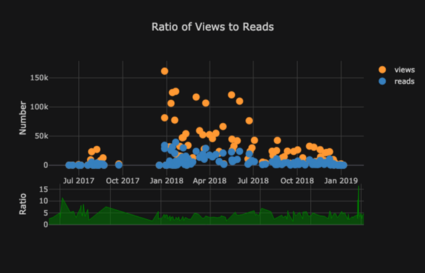
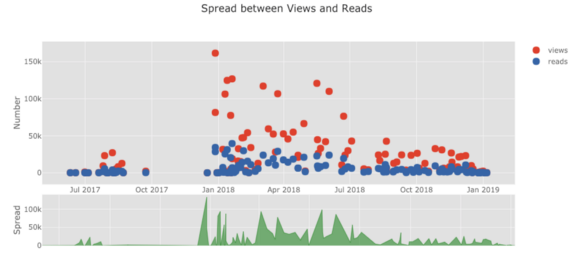
Список графиков можно продолжать и продолжать. cufflinks также имеют несколько тем, которые мы можем использовать, чтобы получить совершенно другой стиль без каких-либо усилий. Например, ниже у нас есть график соотношения в теме «space” и график распространения в “ggplot”:
Мы также получаем 3D-графики (поверхности и пузырьковый):
Для тех, кому хочется, можно даже сделать круговую диаграмму:
Когда вы сделаете эти графики в NoteBook Jupiter, вы заметите небольшую ссылку в правом нижнем углу графика “Export to plot.ly», если вы нажмете на эту ссылку, то попадете в Chart Studio где сможете подправить свой график для окончательной презентации. Вы можете добавить аннотации, указать цвета и вообще очистить все для отличного графика. Затем вы можете опубликовать свой график в интернете, чтобы любой желающий мог найти его по ссылке.
Ниже приведены два графика, которые я подправил в Chart Studio:
Несмотря на все сказанное здесь, мы все еще не изучили все возможности библиотеки! Я бы посоветовал вам посмотреть как документацию plotly, так и документацию cufflinks для построения более невероятных графиков.
Самое худшее в заблуждении о заниженной стоимости заключается в том, что вы осознаете, сколько времени вы потратили впустую, только после того, как бросили это дело. К счастью, теперь, когда я совершил ошибку, слишком долго оставаясь с matploblib, вам не придется этого делать!
Когда мы думаем о plot библиотеках, есть несколько вещей, которые мы хотим:
На данный момент лучшим вариантом для выполнения всего этого в Python является plotly. Plotly позволяет нам быстро делать визуализации и помогает нам лучше понять наши данные через интерактивность. Кроме того, давайте признаем, что построение графиков должно быть одной из самых приятных частей науки о данных! С другими библиотеками построение графиков превратилось в утомительную задачу, но с plotly снова есть радость в создании великой фигуры!

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Когнитивное искажение о невозвратных затратах (sunk cost fallacy) является одним из многих вредных когнитивных предубеждений, жертвой которых становятся люди. Это относится к нашей тенденции продолжать посвящать время и ресурсы проигранному делу, потому что мы уже потратили — утонули — так много времени в погоне. Заблуждение о заниженной стоимости применимо к тому, чтобы оставаться на плохой работе дольше, чем мы должны, рабски работать над проектом, даже когда ясно, что он не будет работать, и да, продолжать использовать утомительную, устаревшую библиотеку построения графиков — matplotlib — когда существуют более эффективные, интерактивные и более привлекательные альтернативы.
За последние несколько месяцев я понял, что единственная причина, по которой я использую matplotlib, — это сотни часов, которые я потратил на изучение сложного синтаксиса. Эти сложности приводят к часам разочарования, выясняя на StackOverflow, как форматировать даты или добавить вторую ось Y. К счастью, это прекрасное время для построения графиков в Python, и после изучения вариантов, явным победителем — с точки зрения простоты использования, документации и функциональности — является библиотека plotly. В этой статье мы погрузимся прямо в plotly, изучая, как создавать лучшие графики за меньшее время — часто с помощью одной строки кода.
Весь код для этой статьи доступен на GitHub. Все графики являются интерактивными и могут быть просмотрены на NBViewer.
Plotly Краткий Обзор
Пакет plotly для Python — это библиотека с открытым исходным кодом, построенная на plotly.js, которая, в свою очередь, построена на d3.js. Мы будем использовать обертку над plotly под названием cufflinks, предназначенную для работы с Pandas DataFrame Итак, наш стек cufflinks > plotly > plotly.js> d3.js — это означает, что мы получаем эффективность программирования на Python с невероятными интерактивными графическими возможностями d3.
(Сама Plotly — графическая компания с несколькими продуктами и инструментами с открытым исходным кодом. Библиотека для Python бесплатна для использования, и мы можем создавать неограниченное количество диаграмм в автономном режиме плюс до 25 диаграмм в онлайн-режиме, чтобы поделиться ими со всем миром.)
Вся работа в этой статье была выполнена в Jupyter Notebook с plotly + cufflinks, работающими в автономном режиме. После установки plotly и cufflinks с помощью
pip install cufflinks plotly импортируйте следующее для запуска в Jupiter:# Standard plotly imports
import plotly.plotly as py
import plotly.graph_objs as go
from plotly.offline import iplot, init_notebook_mode
# Using plotly + cufflinks in offline mode
import cufflinks
cufflinks.go_offline(connected=True)
init_notebook_mode(connected=True)Распределения одиночных переменных: гистограммы и бокс-плоты
Графики с одной переменной — одномерный — это стандартный способ начать анализ, а гистограмма-это график перехода (хотя и с некоторыми проблемами) для построения графика распределения. Здесь, используя мою среднюю статистику по статьям (Вы можете увидеть, как получить свою собственную статистику здесь или использовать мою), давайте сделаем интерактивную гистограмму количества хлопков на статьях (
df — это стандартный фрейм данных Pandas):df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')Для тех, кто привык к
matplotlib, все, что нам нужно сделать, это добавить еще одну букву (iplot вместо plot), и мы получим гораздо более красивый и интерактивный график! Мы можем кликать на данные, чтобы получать более подробную информацию, увеличить масштаб участков графика и, как мы увидим позже, выбирать различные категории.Если мы хотим построить наложенные гистограммы, это так же просто:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')Немного манипулируя
Pandas, мы можем сделать барплот:# Resample to monthly frequency and plot
df2 = df[['view','reads','published_date']]. set_index('published_date'). resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')как мы уже видели, мы можем объединить силу Pandas с plotly + cufflinks. Для боксплота распределение фанов по публикациям, мы используем
pivot, а затем plot:df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')Преимущества интерактивности заключаются в том, что мы можем исследовать и размещать данные по своему усмотрению. В бокс-плоте много информации, и без возможности видеть цифры мы упустим большую ее часть!
Диаграмма рассеяния
Диаграмма рассеяния является сердцем большинства анализов. Это позволяет нам увидеть эволюцию переменной во времени или связь между двумя (или более) переменными.
Временные ряды
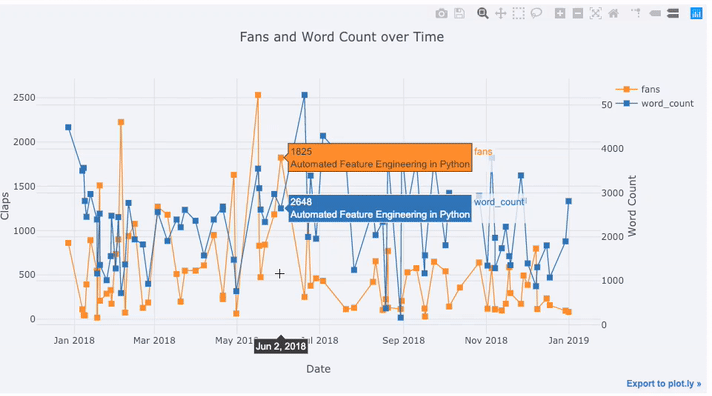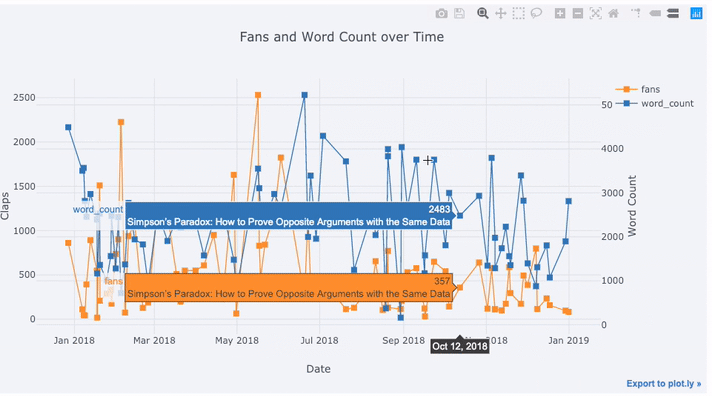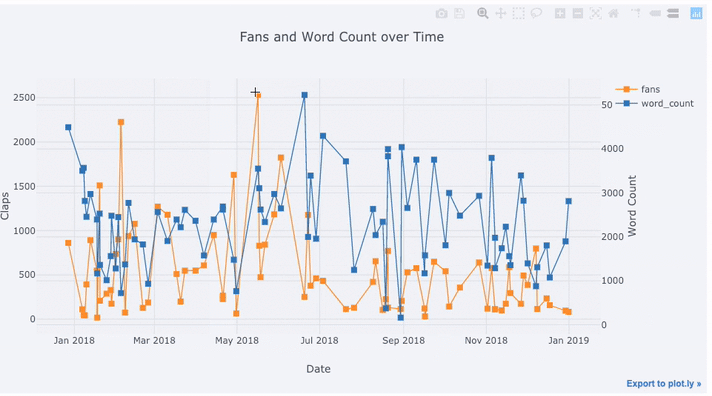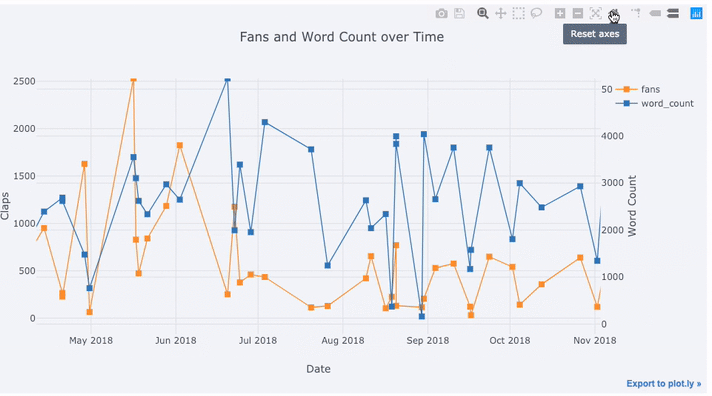
Значительная часть реальных данных имеет элемент времени. К счастью, plotly + cufflinks был разработан с учетом визуализации временных рядов. Давайте сделаем фрейм данных из моих статей TDS и посмотрим, как изменились тенденции.
Create a dataframe of Towards Data Science Articles
tds = df[df['publication'] == 'Towards Data Science']. set_index('published_date')
# Plot read time as a time series
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')Здесь мы видим довольно много разных вещей:
- Автоматическое получение красиво отформатированного временного ряда по оси x
- Добавление вторичной оси y, потому что наши переменные имеют разные диапазоны
- Вывод заголовков статей при наведении курсора мыши
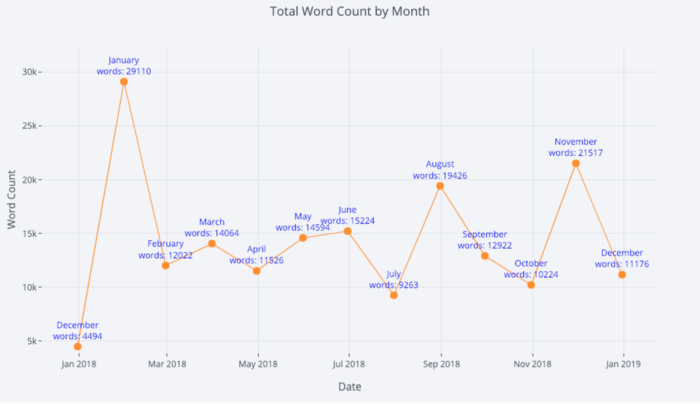
Для получения дополнительной информации мы также можем довольно легко добавлять текстовые аннотации:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')Для двухпеременной точечной диаграммы, окрашенной третьей категориальной переменной, мы используем:
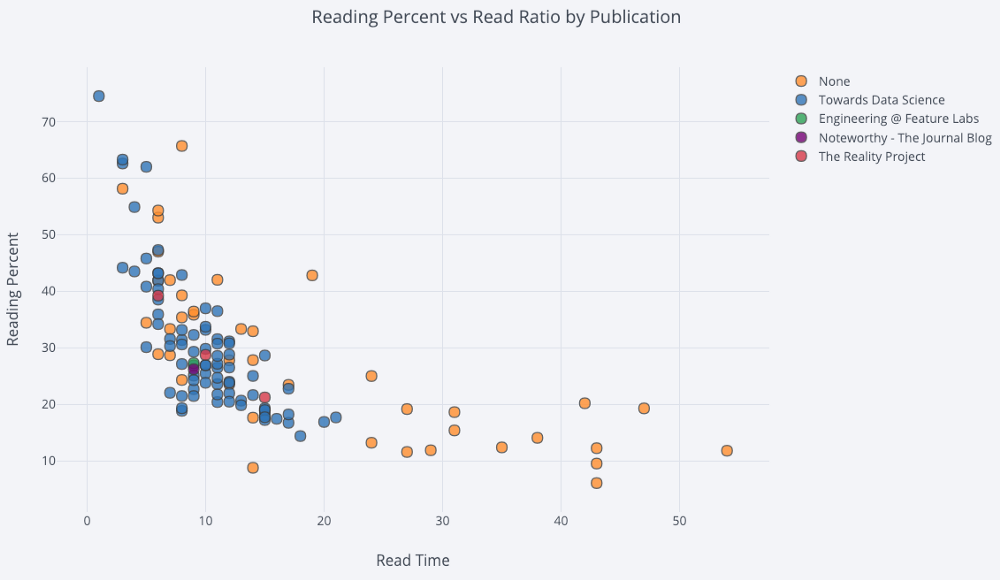
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')Давайте немного усложним задачу, используя логарифмическую ось, заданную как макет plotly — (см. документацию Plotly по спецификациям макета), и определив размер пузырьков числовой переменной:
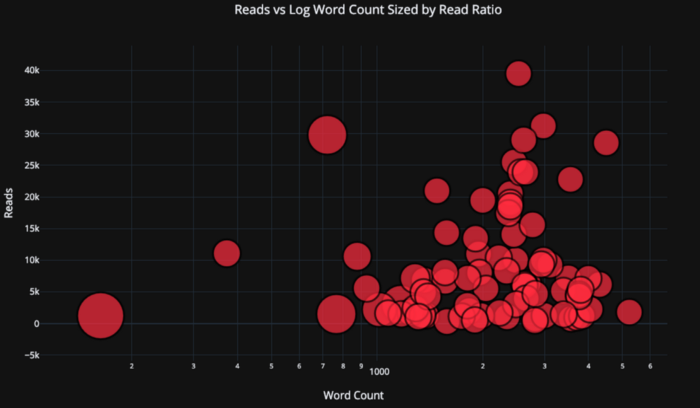
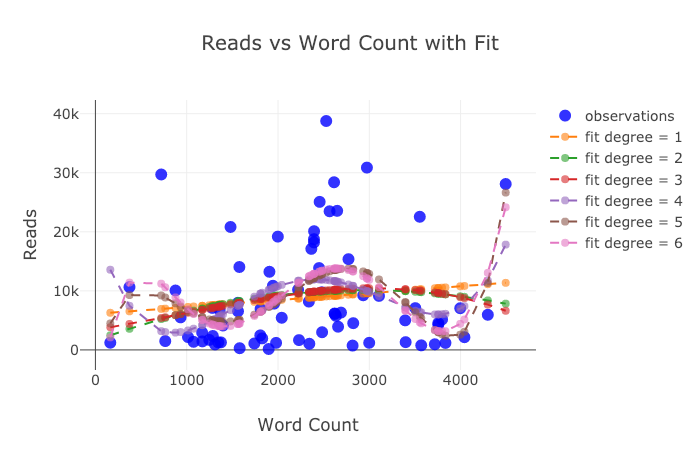
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
# Log xaxis
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))Немного поработав (Подробнее см. NoteBook), мы можем даже поместить четыре переменные (это не рекомендуется) на один график!
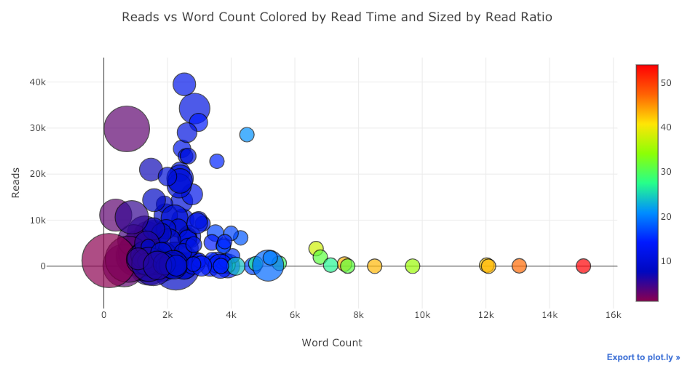
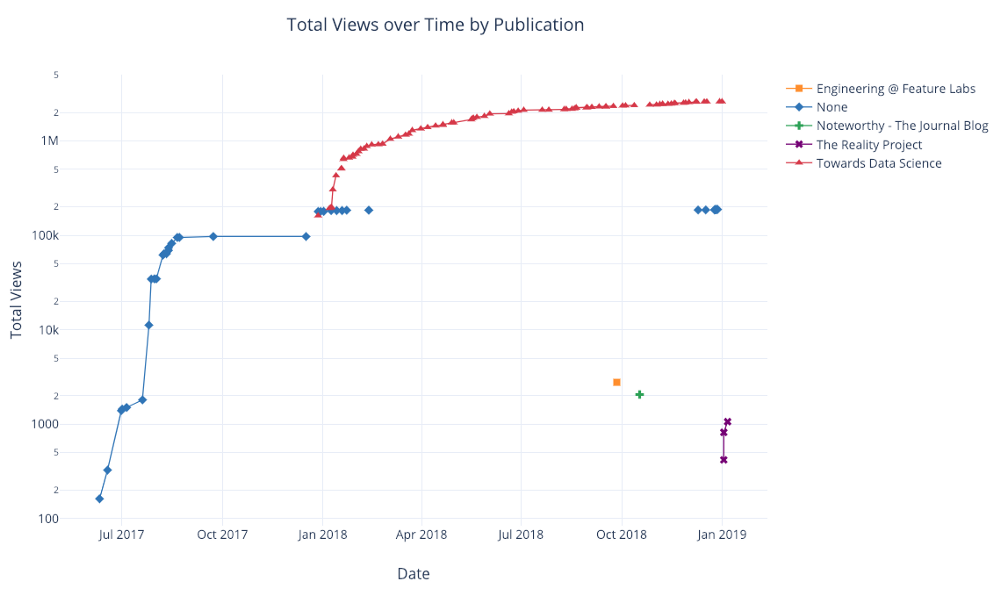
Как и раньше, мы можем комбинировать Pandas с plotly+cufflinks для полезных графиков
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))Дополнительные примеры функциональности смотрите в notebook или документации. Мы можем добавлять текстовые аннотации, опорные линии и наиболее подходящие линии к нашим диаграммам с помощью одной строки кода и по-прежнему со всеми взаимодействиями.
Продвинутые графики
Теперь мы перейдем к несколькимграфикам, которые вы, вероятно, не будете использовать так часто, но которые могут быть весьма впечатляющими. Мы будем использовать plotly figure_factory, чтобы делать даже эти невероятные гафики в одну строку.
Матрица Рассеяния
Когда мы хотим исследовать отношения между многими переменными, матрица рассеяния (также называемая splom) является отличным вариантом:
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')Даже этот график полностью интерактивный, что позволяет нам исследовать данные.
Корреляционная Тепловая Карта
Чтобы визуализировать корреляции между числовыми переменными, мы вычисляем корреляции, а затем делаем аннотированную тепловую карту:
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
Список графиков можно продолжать и продолжать. cufflinks также имеют несколько тем, которые мы можем использовать, чтобы получить совершенно другой стиль без каких-либо усилий. Например, ниже у нас есть график соотношения в теме «space” и график распространения в “ggplot”:
Мы также получаем 3D-графики (поверхности и пузырьковый):
Для тех, кому хочется, можно даже сделать круговую диаграмму:
Редактирование в Plotly Chart Studio
Когда вы сделаете эти графики в NoteBook Jupiter, вы заметите небольшую ссылку в правом нижнем углу графика “Export to plot.ly», если вы нажмете на эту ссылку, то попадете в Chart Studio где сможете подправить свой график для окончательной презентации. Вы можете добавить аннотации, указать цвета и вообще очистить все для отличного графика. Затем вы можете опубликовать свой график в интернете, чтобы любой желающий мог найти его по ссылке.
Ниже приведены два графика, которые я подправил в Chart Studio:
Несмотря на все сказанное здесь, мы все еще не изучили все возможности библиотеки! Я бы посоветовал вам посмотреть как документацию plotly, так и документацию cufflinks для построения более невероятных графиков.
Выводы
Самое худшее в заблуждении о заниженной стоимости заключается в том, что вы осознаете, сколько времени вы потратили впустую, только после того, как бросили это дело. К счастью, теперь, когда я совершил ошибку, слишком долго оставаясь с matploblib, вам не придется этого делать!
Когда мы думаем о plot библиотеках, есть несколько вещей, которые мы хотим:
- Однострочные графики для быстрого исследования
- Интерактивные элементы для подстановки/исследования данных
- Возможность копаться в деталях по мере необходимости
- Простая настройка для окончательной презентации
На данный момент лучшим вариантом для выполнения всего этого в Python является plotly. Plotly позволяет нам быстро делать визуализации и помогает нам лучше понять наши данные через интерактивность. Кроме того, давайте признаем, что построение графиков должно быть одной из самых приятных частей науки о данных! С другими библиотеками построение графиков превратилось в утомительную задачу, но с plotly снова есть радость в создании великой фигуры!
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс по Machine Learning (12 недель)
- Курс «Python для веб-разработки» (9 месяцев)
- Курс по DevOps (12 месяцев)
- Профессия Веб-разработчик (8 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence


S-e-n
Sunk cost fallacy = Невозвратные затраты.
Neusser
«Невозвратные затраты» это только первые два слова из трех.
S-e-n
Вы правы.