Вообще, тема неисчерпаемая. Ковыряется как-то Лёшка (наш инженер) в стойке в ЦОДе повышенной ответственности, где стоит несколько банков. В соседнем ряду наблюдает совершенно дикую картину: парень подошёл к блейду. Выдернул жёсткий диск, что-то записал, ВОТКНУЛ ЕГО НАЗАД, выдернул второй, записал, поставил, выдернул третий. Лёша ему: «Пссс, парень, ты чего?» Он: «Ну так инвентаризация же!» И сразу как-то всё стало понятно.
Я работаю в департаменте вычислительных систем КРОК, мы поддерживаем всё то, что можно кинуть в стену. То есть сервера, системы хранения данных и прочее дорогое железо в дата-центрах. Ну и то, что на нём — операционки, базовую инфраструктуру. Простейшая базовая услуга — ЗИП, то есть замена комплектующих вовремя. Более сложные — это заменять сисадминов заказчика.
Самый страшный момент контракта — это составление техзадания. Расскажу про те грабли, которые мы ощупали вместе с клиентами и о том, как их избежать. Ну и приложу пример шаблона ТЗ, который используем мы.
Самый первый косяк всех ТЗ — это банальное незнание какое у вас среднемесячное количество заявок. Выглядит это так: вы хотите отдать администрирование на аутсорсинг, дальше надо понять, сколько это будет стоить. Если вы просто приложите описание парка оборудования, то мы, как участник конкурса, прикинем вилку на объём работ, выездов, если требуется, и поставим с некоторым запасом. А вот если вы будете точно знать, сколько и каких тикетов было в прошлом году, то цена сильно может снизиться — ведь можно будет посмотреть по факту, что и как ломается и насколько часто вносятся изменения в инфраструктуру. Кто-то, например, виртуалки каждый день добавляет, а кто-то раз в год — цена при этом в первом приближении будет одинаковая.
Часто у заказчика задача выглядит как «Вот администрируйте нам теперь всё». А что всё-то? Поставщику услуг (то есть нам) непонятен объём, всё перезакладывается по трудозатратам. Если мы перезаложимся, вы переплатите. Если вдруг ценник вырастет по ходу контракта — будут конфликты. Если же вдруг что-то случится, и мы возьмём контракт дешевле, чем он стоит в реальности, то постараемся отказаться, и в итоге придётся ещё раз искать исполнителя.
Иногда бывает, что заказчик вообще не знает свою инфраструктуру (например, после слияния-поглощения или скоропостижного ухода прошлого админа). Да и просто если это филиал, и туда долго не заглядывали. В таком случае нужно делать аудит в самом начале. Аудит, конечно, сам по себе стоит денег, но очень экономит деньги на последующем контракте. Да и результаты аудита можно показывать в конкурсе, если хочется сравнить поставщиков по цене за единицу услуги. Мы ведь как считаем: есть цена работы (ремонта, выезда), есть понимание, сколько и каких устройств. Дальше смотрим: на такую-то единицу будет столько-то отказов в месяц, столько-то времени потратим на это. Ну или берём систему резервного копирования. Здесь кому-то достаточно настроить один раз и только проверять, чтобы все бэкапы прошли. А кто-то бесконечно меняет политики, добавляет, убирает, снова добавляет. Мы админим с 90-х и по всему копим статистику, поэтому предсказываем довольно точно. А когда «есть столько серверов непонятной набивки, сколько-то виртуалок, непонятные ОС и что-то ещё там, надо админить, парень уволился» — гарантированно получаются негуманные ценники. Тем более что к нам часто встают со старым оборудованием, на которое поддержки производителя давно нет.
Дальше надо разбить контракт на регулярные работы и редкие. Дело вот в чём: если это какие-то постоянные работы с фиксированной длительностью — выделяем в отдельный блок и прописываем регулярность. Для редких задач — формируем список систем-решений, по которым нужны компетенции (даже если нужны будут раз в год). Исполнитель подготовит спецов. И не будет включать это в основной прайс. Просто пропишет ставки на такие работы.
Мой любимый пример — это когда заказчик решил, что в администрирование входит полная миграция сервисов, на которых работал сайт, в другой ЦОД на расстоянии 1000 км вместе с серверами. Типа, берите сервера и всё с ними вместе взятое (сеть, хранилки, данные на них…) и везите, мы же платим за их администрирование. Но это, скорее, из ряда вон. Обычно мы такие вещи выделяем в отдельные проекты и прорабатываем детально миграцию.
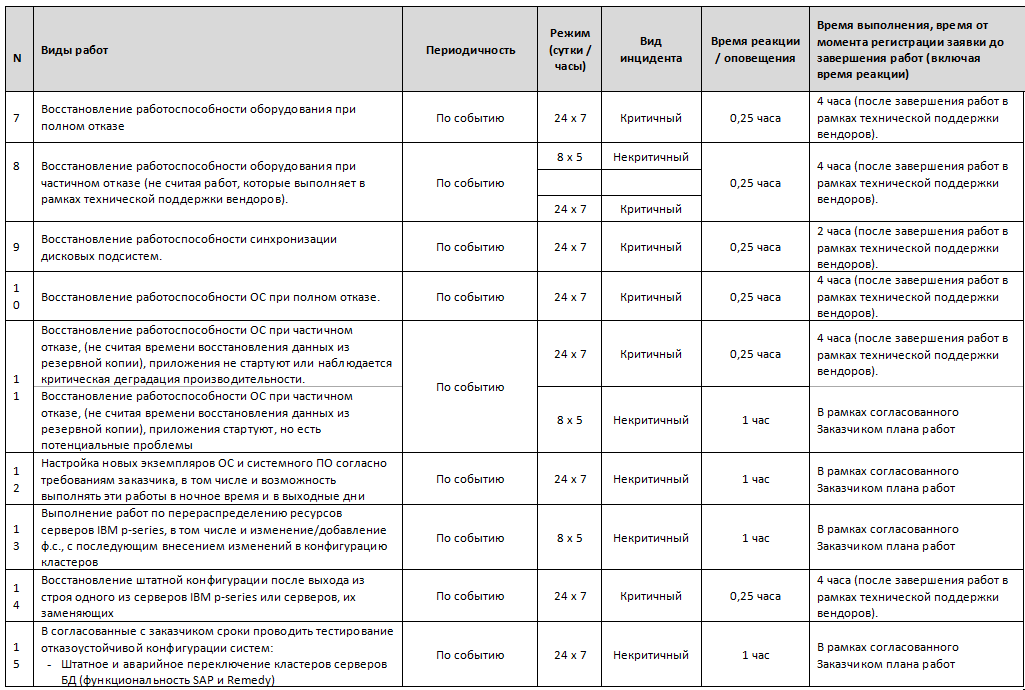
Я регулярно вижу заказчиков, которые прописывают время реакции неправильно или вообще не прописывают. Здесь лучше всё зафиксировать, чтобы ожидания совпадали с реальностью. Суперважно на критичное оборудование писать жёсткие SLA: у нас обычно это время реакции 15 минут, замена — четыре часа. Только вот если так сделать для всего железа в ЦОДе — ценник снова получится негуманный. Бывают и более сложные контракты. У нас есть производства, где средний ценник выше обычного, но при этом мы подписываемся под тем, что платим по несколько миллионов рублей за час простоя. Потому что на эти узлы завязан производственный цикл. Не заметил наш дежурный, что память переполняется на сервере или задержался в дороге с запчастью — можно по итогам года ещё и заказчику остаться должным.
Обычно производство, когда хочет разовые работы (по мере отказов), старается прописать SLA 15 минут, не понимая, что за этим стоит. Чтобы отправить инженера с таким допуском, нужно, чтобы он весь год дежурил, а на Новый год ещё и не пил (или пил строго по шахматке с коллегами). А это стоит денег — и совсем не как разовая услуга.
Был контракт, когда нужно было удерживать 99 % аптайма, и платили за это со штрафами за выход из показателя. Мы посмотрели инфраструктуру, решили, что она в принципе не потянет, и надо всё переделать. В контракт не вошли, но знаем тех, кто решил, что прокатит. Не прокатило.
Третьи любимые грабли — заказчик не устанавливает формат отчётности. Разработайте формат отчётности, который вы хотите видеть. И укажите в контракте её периодичность. Если у вас все задачи выполняются по ставкам, то лучше, чтобы исполнитель перед началом работ оповещал о предварительной оценке длительности работ.
Это к вопросу «А почему у вас тут два часа, а не полтора?» — это вечный спор. Мы решаем его так: перед ремонтом даём заказчику оценку с погрешностью плюс-минус 10 % в стороны. Крупные задачи выносим в проекты с планом работ и сроками этапов.
Понятно, что нужен контроль с обеих сторон, что происходит с затратами времени: мы пускаем заказчика в свои системы и фанатично нарезаем отчёты, чтобы не было никаких сюрпризов. Потому что мы заинтересованы в продлении на год, два, три и пять. И знаем, что если ощущения полного контроля и предсказуемости нет, продления контракта тоже не будет.
Ещё полезно прописывать регулярные встречи. Первый месяц каждую неделю, чтобы отстроить процесс, потом реже, чтобы поставщик делился с вами рекомендациями, что он видит. Дальше раз в месяц, минимум — раз в квартал. У нас есть заказчик, который уходит от своего аутсорсера через месяц, а тот даже не в курсе. Потому что диалога нет. Заказчика не слушают и делают всё как пять лет назад. То есть без учёта его новых требований бизнеса. Заказчик было пытался донести, но потом плюнул, начал искать нового контрагента.
Грабли номер четыре — это практическое отсутствие документации на объекте. Да, я знаю, что никто не любит вносить изменения в документацию по инфраструктуре. Если не прописать это в договоре, то там что-то сделал, здесь что-то переделал, а сказать забыл — обычная ситуация. Альтернатива — взять кого-то, кто будет за вас поддерживать её в актуальном состоянии (что-то поменял, отразил). Будет просто менять исполнителей или передавать сопровождение обратно внутренним специалистам.
Мы сотни раз приходили туда, где из документов — только DRP примерно 2011 года. И пользоваться им нельзя. На моей памяти как минимум два случая, когда у таких заказчиков вставало производство. Помогали разобраться в чём дело, оказалось — DRP не сработал, потому что поменялись IP.
Продвинутые аутсорсеры ведут CMDB: проинсталлировали новое оборудование, внесли в базу. Всё поддерживается в актуальном состоянии. Если своей CMDB-базы нет, то у сервисных организаций она всегда есть. Ну так вот, если речь не о вашей — попросите в неё доступ. И обязательно добавьте в контракт пункт — чтобы накопленные данные потом передали вам в момент расторжения договора. У нас есть заказчик, который радовался, что за него следят где какая гарантия, где какая лицензия. Но когда договор закончился, пришлось самому срочно всё инвентаризировать. Это была первая наша услуга вместе с аудитом — прошлый контрагент ну никак не хотел делиться данными.
Нормальный исполнитель хорошо к ним относится. Готовность под них подписаться — показатель того, что поставщик уверен в соблюдении SLA. Единственный момент — если передаёте прямо контроль за снижением производительности и фиксируете процент доступности, сделайте, например, месяц на переходный период, когда штрафы не действуют. Месяц нужен, чтобы вникнуть в ИТ-инфраструктуру, актуализировать документацию, получить все доступы и после этого уже гарантировать доступность. Если кто-то подписывается без этого — ваша инфраструктура первый месяц под угрозой.
Ещё, кстати, нужно прямо на живой инфраструктуре замерить то, что вы считаете нормальным уровнем производительности. Потом будет с чем сравнивать и предъявлять исполнителю, что производительность снизилась. Иначе не докажете.
Это настолько важно, что часто определяет проект вообще. Давайте ещё раз: сразу подключайте к процессу проработки ИБ-специалиста. Если вы вдруг это не сделали, ждите беды. Чаще всего админят удалённо, поэтому поставщику нужно понимать какие требования будут. Например, есть клиенты, для которых критично видеонаблюдение за выделенным рабочим местом, с которого идёт подключение. У банков ещё серьезнее — там есть прям ГОСТы и требования ЦБ. Лучший способ составить ТЗ, которое резко повысит ценник, — прямо в нём сослаться на внутренний регламент и не предоставить его.
У нас был случай, как-то три месяца не могли подписать договор, ИТ-директор вешался. Безопасник хотел реализации ГОСТа, мы хотели, чтобы он показал, как он сейчас реализован (подозревая, что никак), и предлагали прислать вариант. Он не присылал. В итоге написали, что «если в течение трёх дней от вас не поступят комментарии к предложенному тексту технического задания, то мы его считаем согласованным», и поставили в копию руководителя компании. ИБ прислали одну фразу: «Установка обновлений и патчей, устраняющих критические уязвимости ИБ, должна производиться не позже 48 часов». И всё. Можно сказать, пронесло.
Вообще, тема ИБ жирная и скользкая. Безопасники живут в своём мире. Всё классно и здорово, инфраструктурщики между собой договорились, контрагенты реализуют. И тут приходишь ты в компанию, а тебе: вот идите в первый отдел договариваться. А там сажают на табуретку и задают вопросы, потому что до них никто не довёл, что что-то происходит.
А, да, и не забывайте отмечать, что админы должны иметь доступ на объект. А то сложно менять запчасти в сервере удалённо. У нас были на одном из проектов ожидания по пять-шесть часов из-за того, что нужно было, чтобы глобальная команда компании (ИТ-глава в Индии) апрувила заявки на физический доступ инженера.
Если хотите видеть заявки онлайн, не поленитесь прописать возможность интеграции системы Service Desk вашей и исполнителя или необходимость web-портала. Так вы сможете прозрачно контролировать исполнение. Многим заказчикам, работающим через почту, приходит только отбивка «Ваш тикет очень важен для нас, и скоро мы им займёмся». И всё, дальше чёрный ящик. А если кейс критичный, все хотят видеть приоритет, хотят видеть, кто работает, микростатусы. Некоторые просили каждые десять минут звонить. Теперь у нас есть выделенный человек, который стоит рядом с инженером, не мешает ему решать задачу, но при этом информирует заказчика о статусе по критичным кейсам, когда всё встало, ничего не работает и все нервничают.
Ещё очень классно было в одном банке, где регламент реакции на инциденты описывался во внутреннем стандарте. Нам, к счастью, его дали. Там было 300 страниц, написанных в далёком 2005 году и обновлённых в 2018 поверх набором костылей. В общем, среди всего прочего логичного, там была процедура реакции на инциденты с собиранием чата из важных людей исключительно в Скайпе. Ночью нужно всех заинтересованных созвать и туда отписывать. А Скайп не так что бы очень живой. Пришлось его заново ставить.
Простой совет: убедитесь в профессионализме исполнителя, это сертификаты и опыт работы в компании.
Совет посложнее: убедитесь, что именно эти люди будут на вашем проекте. Есть компании, которые прям пишут в ТЗ кого можно подключать к работам, а кого нет. Стажёры не подходят под работу с критичными системами. Можете так и прописать: «Тестирование спецов силами наших специалистов». Я вот видела, как на железку приехал человек с пачкой инструкций. Говорит: «Меня на Юду нашли за 5 тысяч рублей».
Бывает, дали список классный, выиграли, приходят парни на установочное совещание — а там другие люди, которые не участвовали, нет пары нужных компетенций. Знаю, что на рынке были кейсы, когда три раза меняли команды. В финансах процедура простая: есть списки, кто может прикасаться к инфраструктуре. Не допускают никого просто так, только по белому списку.
Выпишите все требования свои, типы работ, типы заявок и сделайте форму в XLS с невозможностью редактирования полей. Потому что очень часто поставщики стараются вписать что-то своё, и дальше невозможно сравнивать. Знаю, совет простой, но редко кто этим пользуется. А потом тратится гора времени, чтобы разобраться, кто чего наобещал и кто выгоднее по цене.
У нас на поддержке есть компания розничной торговли с магазинами во всех регионах России (за год увеличивается на 13 % по количеству магазинов). Инфраструктура состоит из 1400 позиций разных производителей, на её базе работают критичный для бизнеса функционал. На ИТ ложится огромное число задач по развитию. Там даже поддержка инфраструктуры уже настолько большая, что ИТ-департамент один не справляется. Оборудования много, надо как-то управлять его жизненным циклом. В общем, они пять лет используют аутсорсинг для рутинных задач. Мы с ними два года. В задачах:
У нас команда: первая линия отвечает за мониторинг и заведение заявок у вендоров, вторая за работы на местах, третья — смежные области (когда прикладной софт не работает, и непонятно, где проблема). Есть выделенный технический менеджер, он контролирует и координирует всех техспецов; отдельно ответственный за CMDB; отдельно сервис-менеджер — на нём общая координация проекта.
Относительно контракта. Сразу скажу, что в нём зафиксирован SLA на все работы, а также штрафы за их невыполнение. Есть возможность ежеквартального пересмотра списка поддерживаемого оборудования с лёгким пересчётом стоимости, так как есть прайс-лист на каждую единицу. Ещё мы проводим с заказчиком регулярные встречи, где обсуждаем результаты работы и планы на будущее.
На выходе — экономия 5500 часов за год для заказчика, которые собственные сотрудники потратили на проекты по развитию. 99,9 % выполнения SLA (было два нарушения в первый месяц по срокам оповещения, скорректировали за счёт регулярной обратной связи). На 30 % снизилось число оповещений от системы мониторинга, спасибо оптимальной настройке. CIO на вопрос о том, как мы работаем, ответил: «Мы о вас не слышим». Он-то понимает, как это важно.
Шаблон ТЗ вот. Там 16 страниц адской бюрократии, которая сбережёт всем сторонам нервы и много сотен часов работы, если один раз прочитать и обсудить до подписания.
Я работаю в департаменте вычислительных систем КРОК, мы поддерживаем всё то, что можно кинуть в стену. То есть сервера, системы хранения данных и прочее дорогое железо в дата-центрах. Ну и то, что на нём — операционки, базовую инфраструктуру. Простейшая базовая услуга — ЗИП, то есть замена комплектующих вовремя. Более сложные — это заменять сисадминов заказчика.
Самый страшный момент контракта — это составление техзадания. Расскажу про те грабли, которые мы ощупали вместе с клиентами и о том, как их избежать. Ну и приложу пример шаблона ТЗ, который используем мы.
Поднимите статистику
Самый первый косяк всех ТЗ — это банальное незнание какое у вас среднемесячное количество заявок. Выглядит это так: вы хотите отдать администрирование на аутсорсинг, дальше надо понять, сколько это будет стоить. Если вы просто приложите описание парка оборудования, то мы, как участник конкурса, прикинем вилку на объём работ, выездов, если требуется, и поставим с некоторым запасом. А вот если вы будете точно знать, сколько и каких тикетов было в прошлом году, то цена сильно может снизиться — ведь можно будет посмотреть по факту, что и как ломается и насколько часто вносятся изменения в инфраструктуру. Кто-то, например, виртуалки каждый день добавляет, а кто-то раз в год — цена при этом в первом приближении будет одинаковая.
Часто у заказчика задача выглядит как «Вот администрируйте нам теперь всё». А что всё-то? Поставщику услуг (то есть нам) непонятен объём, всё перезакладывается по трудозатратам. Если мы перезаложимся, вы переплатите. Если вдруг ценник вырастет по ходу контракта — будут конфликты. Если же вдруг что-то случится, и мы возьмём контракт дешевле, чем он стоит в реальности, то постараемся отказаться, и в итоге придётся ещё раз искать исполнителя.
Иногда бывает, что заказчик вообще не знает свою инфраструктуру (например, после слияния-поглощения или скоропостижного ухода прошлого админа). Да и просто если это филиал, и туда долго не заглядывали. В таком случае нужно делать аудит в самом начале. Аудит, конечно, сам по себе стоит денег, но очень экономит деньги на последующем контракте. Да и результаты аудита можно показывать в конкурсе, если хочется сравнить поставщиков по цене за единицу услуги. Мы ведь как считаем: есть цена работы (ремонта, выезда), есть понимание, сколько и каких устройств. Дальше смотрим: на такую-то единицу будет столько-то отказов в месяц, столько-то времени потратим на это. Ну или берём систему резервного копирования. Здесь кому-то достаточно настроить один раз и только проверять, чтобы все бэкапы прошли. А кто-то бесконечно меняет политики, добавляет, убирает, снова добавляет. Мы админим с 90-х и по всему копим статистику, поэтому предсказываем довольно точно. А когда «есть столько серверов непонятной набивки, сколько-то виртуалок, непонятные ОС и что-то ещё там, надо админить, парень уволился» — гарантированно получаются негуманные ценники. Тем более что к нам часто встают со старым оборудованием, на которое поддержки производителя давно нет.
Дальше надо разбить контракт на регулярные работы и редкие. Дело вот в чём: если это какие-то постоянные работы с фиксированной длительностью — выделяем в отдельный блок и прописываем регулярность. Для редких задач — формируем список систем-решений, по которым нужны компетенции (даже если нужны будут раз в год). Исполнитель подготовит спецов. И не будет включать это в основной прайс. Просто пропишет ставки на такие работы.
Мой любимый пример — это когда заказчик решил, что в администрирование входит полная миграция сервисов, на которых работал сайт, в другой ЦОД на расстоянии 1000 км вместе с серверами. Типа, берите сервера и всё с ними вместе взятое (сеть, хранилки, данные на них…) и везите, мы же платим за их администрирование. Но это, скорее, из ряда вон. Обычно мы такие вещи выделяем в отдельные проекты и прорабатываем детально миграцию.
Время реакции
Я регулярно вижу заказчиков, которые прописывают время реакции неправильно или вообще не прописывают. Здесь лучше всё зафиксировать, чтобы ожидания совпадали с реальностью. Суперважно на критичное оборудование писать жёсткие SLA: у нас обычно это время реакции 15 минут, замена — четыре часа. Только вот если так сделать для всего железа в ЦОДе — ценник снова получится негуманный. Бывают и более сложные контракты. У нас есть производства, где средний ценник выше обычного, но при этом мы подписываемся под тем, что платим по несколько миллионов рублей за час простоя. Потому что на эти узлы завязан производственный цикл. Не заметил наш дежурный, что память переполняется на сервере или задержался в дороге с запчастью — можно по итогам года ещё и заказчику остаться должным.
Обычно производство, когда хочет разовые работы (по мере отказов), старается прописать SLA 15 минут, не понимая, что за этим стоит. Чтобы отправить инженера с таким допуском, нужно, чтобы он весь год дежурил, а на Новый год ещё и не пил (или пил строго по шахматке с коллегами). А это стоит денег — и совсем не как разовая услуга.
Был контракт, когда нужно было удерживать 99 % аптайма, и платили за это со штрафами за выход из показателя. Мы посмотрели инфраструктуру, решили, что она в принципе не потянет, и надо всё переделать. В контракт не вошли, но знаем тех, кто решил, что прокатит. Не прокатило.
Отчётность
Третьи любимые грабли — заказчик не устанавливает формат отчётности. Разработайте формат отчётности, который вы хотите видеть. И укажите в контракте её периодичность. Если у вас все задачи выполняются по ставкам, то лучше, чтобы исполнитель перед началом работ оповещал о предварительной оценке длительности работ.
Это к вопросу «А почему у вас тут два часа, а не полтора?» — это вечный спор. Мы решаем его так: перед ремонтом даём заказчику оценку с погрешностью плюс-минус 10 % в стороны. Крупные задачи выносим в проекты с планом работ и сроками этапов.
Понятно, что нужен контроль с обеих сторон, что происходит с затратами времени: мы пускаем заказчика в свои системы и фанатично нарезаем отчёты, чтобы не было никаких сюрпризов. Потому что мы заинтересованы в продлении на год, два, три и пять. И знаем, что если ощущения полного контроля и предсказуемости нет, продления контракта тоже не будет.
Ещё полезно прописывать регулярные встречи. Первый месяц каждую неделю, чтобы отстроить процесс, потом реже, чтобы поставщик делился с вами рекомендациями, что он видит. Дальше раз в месяц, минимум — раз в квартал. У нас есть заказчик, который уходит от своего аутсорсера через месяц, а тот даже не в курсе. Потому что диалога нет. Заказчика не слушают и делают всё как пять лет назад. То есть без учёта его новых требований бизнеса. Заказчик было пытался донести, но потом плюнул, начал искать нового контрагента.
Документация
Грабли номер четыре — это практическое отсутствие документации на объекте. Да, я знаю, что никто не любит вносить изменения в документацию по инфраструктуре. Если не прописать это в договоре, то там что-то сделал, здесь что-то переделал, а сказать забыл — обычная ситуация. Альтернатива — взять кого-то, кто будет за вас поддерживать её в актуальном состоянии (что-то поменял, отразил). Будет просто менять исполнителей или передавать сопровождение обратно внутренним специалистам.
Мы сотни раз приходили туда, где из документов — только DRP примерно 2011 года. И пользоваться им нельзя. На моей памяти как минимум два случая, когда у таких заказчиков вставало производство. Помогали разобраться в чём дело, оказалось — DRP не сработал, потому что поменялись IP.
Не забудьте забрать выгрузку в конце периода
Продвинутые аутсорсеры ведут CMDB: проинсталлировали новое оборудование, внесли в базу. Всё поддерживается в актуальном состоянии. Если своей CMDB-базы нет, то у сервисных организаций она всегда есть. Ну так вот, если речь не о вашей — попросите в неё доступ. И обязательно добавьте в контракт пункт — чтобы накопленные данные потом передали вам в момент расторжения договора. У нас есть заказчик, который радовался, что за него следят где какая гарантия, где какая лицензия. Но когда договор закончился, пришлось самому срочно всё инвентаризировать. Это была первая наша услуга вместе с аудитом — прошлый контрагент ну никак не хотел делиться данными.
Не бойтесь включать высокие штрафы в договор
Нормальный исполнитель хорошо к ним относится. Готовность под них подписаться — показатель того, что поставщик уверен в соблюдении SLA. Единственный момент — если передаёте прямо контроль за снижением производительности и фиксируете процент доступности, сделайте, например, месяц на переходный период, когда штрафы не действуют. Месяц нужен, чтобы вникнуть в ИТ-инфраструктуру, актуализировать документацию, получить все доступы и после этого уже гарантировать доступность. Если кто-то подписывается без этого — ваша инфраструктура первый месяц под угрозой.
Ещё, кстати, нужно прямо на живой инфраструктуре замерить то, что вы считаете нормальным уровнем производительности. Потом будет с чем сравнивать и предъявлять исполнителю, что производительность снизилась. Иначе не докажете.
Сразу подключайте к процессу проработки ИБ-специалиста
Это настолько важно, что часто определяет проект вообще. Давайте ещё раз: сразу подключайте к процессу проработки ИБ-специалиста. Если вы вдруг это не сделали, ждите беды. Чаще всего админят удалённо, поэтому поставщику нужно понимать какие требования будут. Например, есть клиенты, для которых критично видеонаблюдение за выделенным рабочим местом, с которого идёт подключение. У банков ещё серьезнее — там есть прям ГОСТы и требования ЦБ. Лучший способ составить ТЗ, которое резко повысит ценник, — прямо в нём сослаться на внутренний регламент и не предоставить его.
У нас был случай, как-то три месяца не могли подписать договор, ИТ-директор вешался. Безопасник хотел реализации ГОСТа, мы хотели, чтобы он показал, как он сейчас реализован (подозревая, что никак), и предлагали прислать вариант. Он не присылал. В итоге написали, что «если в течение трёх дней от вас не поступят комментарии к предложенному тексту технического задания, то мы его считаем согласованным», и поставили в копию руководителя компании. ИБ прислали одну фразу: «Установка обновлений и патчей, устраняющих критические уязвимости ИБ, должна производиться не позже 48 часов». И всё. Можно сказать, пронесло.
Вообще, тема ИБ жирная и скользкая. Безопасники живут в своём мире. Всё классно и здорово, инфраструктурщики между собой договорились, контрагенты реализуют. И тут приходишь ты в компанию, а тебе: вот идите в первый отдел договариваться. А там сажают на табуретку и задают вопросы, потому что до них никто не довёл, что что-то происходит.
А, да, и не забывайте отмечать, что админы должны иметь доступ на объект. А то сложно менять запчасти в сервере удалённо. У нас были на одном из проектов ожидания по пять-шесть часов из-за того, что нужно было, чтобы глобальная команда компании (ИТ-глава в Индии) апрувила заявки на физический доступ инженера.
Сервис деск важен
Если хотите видеть заявки онлайн, не поленитесь прописать возможность интеграции системы Service Desk вашей и исполнителя или необходимость web-портала. Так вы сможете прозрачно контролировать исполнение. Многим заказчикам, работающим через почту, приходит только отбивка «Ваш тикет очень важен для нас, и скоро мы им займёмся». И всё, дальше чёрный ящик. А если кейс критичный, все хотят видеть приоритет, хотят видеть, кто работает, микростатусы. Некоторые просили каждые десять минут звонить. Теперь у нас есть выделенный человек, который стоит рядом с инженером, не мешает ему решать задачу, но при этом информирует заказчика о статусе по критичным кейсам, когда всё встало, ничего не работает и все нервничают.
Ещё очень классно было в одном банке, где регламент реакции на инциденты описывался во внутреннем стандарте. Нам, к счастью, его дали. Там было 300 страниц, написанных в далёком 2005 году и обновлённых в 2018 поверх набором костылей. В общем, среди всего прочего логичного, там была процедура реакции на инциденты с собиранием чата из важных людей исключительно в Скайпе. Ночью нужно всех заинтересованных созвать и туда отписывать. А Скайп не так что бы очень живой. Пришлось его заново ставить.
Сертификаты должны быть не в компании, а у спецов вашего проекта
Простой совет: убедитесь в профессионализме исполнителя, это сертификаты и опыт работы в компании.
Совет посложнее: убедитесь, что именно эти люди будут на вашем проекте. Есть компании, которые прям пишут в ТЗ кого можно подключать к работам, а кого нет. Стажёры не подходят под работу с критичными системами. Можете так и прописать: «Тестирование спецов силами наших специалистов». Я вот видела, как на железку приехал человек с пачкой инструкций. Говорит: «Меня на Юду нашли за 5 тысяч рублей».
Бывает, дали список классный, выиграли, приходят парни на установочное совещание — а там другие люди, которые не участвовали, нет пары нужных компетенций. Знаю, что на рынке были кейсы, когда три раза меняли команды. В финансах процедура простая: есть списки, кто может прикасаться к инфраструктуре. Не допускают никого просто так, только по белому списку.
Напоследок
Выпишите все требования свои, типы работ, типы заявок и сделайте форму в XLS с невозможностью редактирования полей. Потому что очень часто поставщики стараются вписать что-то своё, и дальше невозможно сравнивать. Знаю, совет простой, но редко кто этим пользуется. А потом тратится гора времени, чтобы разобраться, кто чего наобещал и кто выгоднее по цене.
Пример проекта
У нас на поддержке есть компания розничной торговли с магазинами во всех регионах России (за год увеличивается на 13 % по количеству магазинов). Инфраструктура состоит из 1400 позиций разных производителей, на её базе работают критичный для бизнеса функционал. На ИТ ложится огромное число задач по развитию. Там даже поддержка инфраструктуры уже настолько большая, что ИТ-департамент один не справляется. Оборудования много, надо как-то управлять его жизненным циклом. В общем, они пять лет используют аутсорсинг для рутинных задач. Мы с ними два года. В задачах:
- Мониторинг вычислительной инфраструктуры и среды виртуализации в режиме 24 x 7.
- Информирование ответственных о проблемах по результатам мониторинга, для критичных кейсов в течение 15 минут.
- Заведение заявок на замену запчастей у производителей, замена, информирование о восстановлении работы.
- Контроль за выходом обновлений, анализ их критичности для ИБ/стабильности работы и регулярная установка.
- Управление перечнем 1400 единиц оборудования во внутренней CMDB.
- Инсталляция нового оборудования по запросу, внесение данных в CMDB.
У нас команда: первая линия отвечает за мониторинг и заведение заявок у вендоров, вторая за работы на местах, третья — смежные области (когда прикладной софт не работает, и непонятно, где проблема). Есть выделенный технический менеджер, он контролирует и координирует всех техспецов; отдельно ответственный за CMDB; отдельно сервис-менеджер — на нём общая координация проекта.
Относительно контракта. Сразу скажу, что в нём зафиксирован SLA на все работы, а также штрафы за их невыполнение. Есть возможность ежеквартального пересмотра списка поддерживаемого оборудования с лёгким пересчётом стоимости, так как есть прайс-лист на каждую единицу. Ещё мы проводим с заказчиком регулярные встречи, где обсуждаем результаты работы и планы на будущее.
На выходе — экономия 5500 часов за год для заказчика, которые собственные сотрудники потратили на проекты по развитию. 99,9 % выполнения SLA (было два нарушения в первый месяц по срокам оповещения, скорректировали за счёт регулярной обратной связи). На 30 % снизилось число оповещений от системы мониторинга, спасибо оптимальной настройке. CIO на вопрос о том, как мы работаем, ответил: «Мы о вас не слышим». Он-то понимает, как это важно.
Шаблон ТЗ вот. Там 16 страниц адской бюрократии, которая сбережёт всем сторонам нервы и много сотен часов работы, если один раз прочитать и обсудить до подписания.

amarao
А как вы решаете проблему отказов софта? Вот, например, была лет 10 назад история у vmware, что 29 февраля лицензия сказала, что она не лицензия и выключила все виртуалки. Вам говорят "включай", а софт говорит "нифига". Чей это даунтайм?
NSlyadneva Автор
Если нарушение работоспособности связано с багами у самого производителя, то наш счетчик на время восстановления работы приостанавливается на время решения проблемы со стороны производителя. Да и часто заказчики разграничивают вендорский сервис и администрирование. Но мы параллельно работаем над обходным решением, которое позволит восстановить самый критичный сервис. Виртуалка встала, предложим и поможем развернуть на физическом.
amarao
А как вы определяете, что это баги производителя, а не кривые руки персонала? И как вы это доказываете заказчику? (Если вендор признал, то просто, но до этого момента?)
paranoya_prod
Если Vmware это сделала у всех, то виноват вендор, если это единичный случай, то проводится расследование с документированием всех шагов. Потом этот документ показывается заказчику.
NSlyadneva Автор
Если все встало, то после восстановления работы разбираемся в причинах (смотрим на момент, когда появились ошибки, кто какие действия до и после совершал и т.д.). Целое расследование со всех сторон проводим. Сейчас невозможно скрыть кривые руки персонала.
anonymous
Вы проводите расследование ИТ-инцидента в компании, у которой нет специалиста провести это расследование, и в которой вы — заинтересованная сторона (т.к. иначе штафы). Кажется результат такого расследования предсказуем.
NSlyadneva Автор
Расследование заключается в первую очередь в сборе и анализе всех фактов и взаимосвязей, которые подтверждаются техническими данными (логами, отчётами и т.д.) с обоснованием произошедшего инцидента. Скрыть что-то существенное или переиначить факты в этом плане не так просто. Поэтому всегда даем максимально подробный отчет и пруфы, чтобы снять такие вопросы сразу.
anonymous
Прежде всего, я не сомневаюсь в существовании честных и неподкупных людей. Но с юридической точки зрения, заинтересованная сторона, проводящая расследование — это примерно как подкупленный судья (заинтересованный в получении выгоды/заинтересованный в сокрытии преступлений коллег т.д.), ведущий разбирательство.
У вас нет независимого аудита? Часто ли бывали случаи, что клиенты жаловались на расследование? Проводились ли расследования с независимыми аудиторами, каковы их результаты? На своем примере скажу, я бы не доверял расследованиям собственной деятельности любой компании, потому что у неё выгода в другом.
apcsb
Я так понимаю, «расследование» ведется с позиции презумпции виновности — не смог отмазаться, что вендор виноват — попал.
А насчёт
Это типичная ошибка жадного аутсорсера (ну, или когда руководитель делает аутсорсинг ради бонуса, а не результата), и честно говоря, они после этого сами себе буратины — квалифицировааного контроллёра (или трёх, для избыточности и кворума) нужно оставлять.
anonymous
Да, это как правило прописывается в договоре, нарушил sla восстановления = штраф. А потом уже доказывай, что виновен вендор/провайдер, любая третья сторона, даже уборщица со шваброй.