На это раз речь пойдет о применении в нашей практике Apache Spark и инструментe, позволяющем создавать ремаркетинговые аудитории.
Именно благодаря этому инструменту, однажды посмотрев лобзик, вы будете видеть его во всех уголках интернета до конца своей жизни.
Здесь мы и набили первые шишки в обращении с Apache Spark.
Архитектура и Spark-код под катом.

Введение
Для понимания целей разъясним терминологию и исходные данные.
Что же такое ремаркетинг? Ответ на этот вопрос вы найдете в вики), а если коротко, то ремаркетинг (он же ретаргетинг) — рекламный механизм, позволяющий вернуть пользователя на сайт рекламодателя для совершения целевого действия.
Для этого нам требуются данные от самого рекламодателя, так называемая first party data, которую мы собираем в автоматическом режиме с сайтов, которые устанавливают у себя наш код — SmartPixel. Это информация о пользователе (user agent), посещённых страницах и совершённых действиях. Затем мы обрабатываем эти данные с помощью Apache Spark и получаем аудитории для показа рекламы.
Решение
Немного истории
Изначально планировалось написание на чистом Hadoop используя MapReduce задачи и у нас это даже получилось. Однако написание такого вида приложения требовало большого количество кода, в котором очень сложно разбираться и отлаживать.
Для примера трёх разных подходов мы приведём код группировки audience_id по visitor_id.
public static class Map extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
String[] split = s.split(" ");
context.write(new Text(split[0]), new Text(split[1]));
}
}
public static class Reduce extends Reducer<Text, Text, Text, ArrayWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
HashSet<Text> set = new HashSet<>();
values.forEach(t -> set.add(t));
ArrayWritable array = new ArrayWritable(Text.class);
array.set(set.toArray(new Text[set.size()]));
context.write(key, array);
}
}
public static class Run {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJarByClass(Run.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(ArrayWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Затем на глаза нам попался Pig. Язык основанный на Pig Latin, который интерпретировал код в MapReduce задачи. Теперь для написания требовалось куда меньше кода, да и с эстетической точки зрения он был куда лучше.
A = LOAD '/data/input' USING PigStorage(' ') AS (visitor_id:chararray, audience_id:chararray);
B = DISTINCT A;
C = GROUP B BY visitor_id;
D = FOREACH C GENERATE group AS visitor_id, B.audience_id AS audience_id;
STORE D INTO '/data/output' USING PigStorage();
Вот только была проблема с сохранением. Приходилось писать свои модули для сохранения, т.к. разработчики большинства баз данных не поддерживали Pig.
Здесь то на помощь пришел Spark.
SparkConf sparkConf = new SparkConf().setAppName("Test");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
jsc.textFile(args[0])
.mapToPair(str -> {
String[] split = str.split(" ");
return new Tuple2<>(split[0], split[1]);
})
.distinct()
.groupByKey()
.saveAsTextFile(args[1]);
Здесь и краткость, и удобство, так же наличие многих OutputFormat, которые позволяют облегчить процесс записи в базы данных. Кроме того в данном инструменте нас интересовала возможность потоковой обработки.
Нынешняя реализация
Процесс в целом выглядит следующим образом:
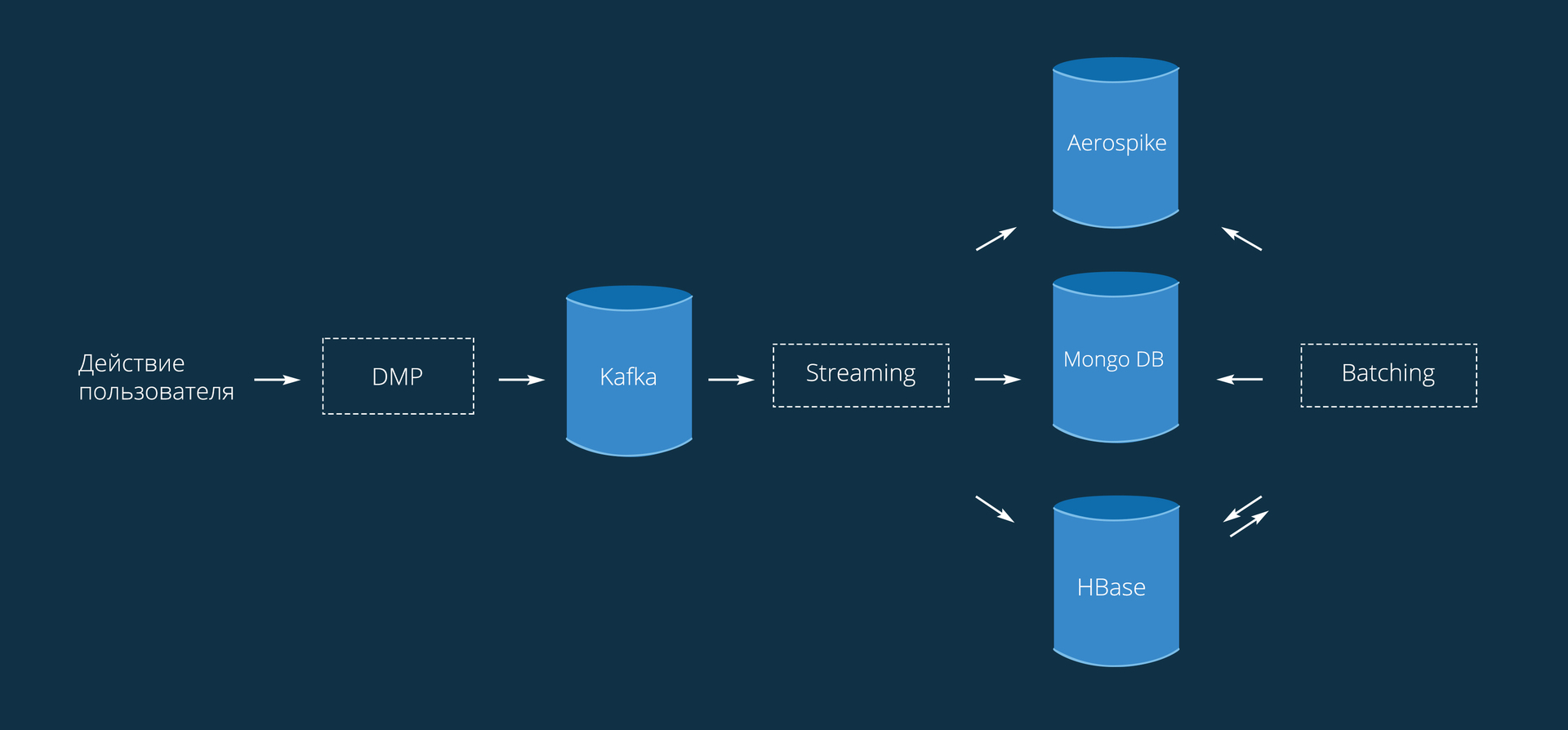
Данные попадают к нам со SmartPixel'ей, установленных на сайтах. Код приводить не будем, он очень простой и аналогичен любой внешней метрике. Отсюда данные приходят в виде { Visitor_Id: Action }. Под Action тут можно понимать любое целевое действие: просмотр страницы/товара, добавление в корзину, покупка или любое кастомное действие, установленное рекламодателем.
Обработка ремаркетинга состоит из 2 основных модулей:
- Потоковая обработка (streaming).
- Пакетная обработка (batching).
Потоковая обработка
Позволяет добавлять пользователей в аудитории в режиме реального времени. Мы используем Spark Streaming с интервалом обработки 10 секунд. Пользователь добавляется в аудиторию почти сразу после совершенного действия (в течение этих самых 10 секунд). Важно отметить, что в потоковом режиме допустимы потери данных в небольших количествах из-за пинга до баз данных или каких-либо других причин.
Главное — это баланс между временем отклика и пропускной способностью. Чем меньше batchInterval, тем быстрее данные обработаются, но много времени будет потрачено на инициализацию соединений и другие накладные расходы, так что за раз обработать можно не так много. С другой стороны, большой интервал позволяет за раз обработать большее количество данных, но тогда больше тратится драгоценного времени с момента действия до добавления в нужную аудиторию.
public class StreamUtil {
private static final Function<JavaPairRDD<String, byte[]>, JavaRDD<Event>> eventTransformFunction =
rdd -> rdd.map(t -> Event.parseFromMsgPack(t._2())).filter(e -> e != null);
public static JavaPairReceiverInputDStream<String, byte[]> createStream(JavaStreamingContext jsc, String groupId, Map<String, Integer> topics) {
HashMap prop = new HashMap() {{
put("zookeeper.connect", BaseUtil.KAFKA_ZK_QUORUM);
put("group.id", groupId);
}};
return KafkaUtils.createStream(jsc, String.class, byte[].class, StringDecoder.class, DefaultDecoder.class, prop, topics, StorageLevel.MEMORY_ONLY_SER());
}
public static JavaDStream<Event> getEventsStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map, int count) {
return getStream(jssc, groupName, map, count, eventTransformFunction);
}
public static <T> JavaDStream<T> getStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map,
Function<JavaPairRDD<String, byte[]>, JavaRDD<T>> transformFunction) {
return createStream(jssc, groupName, map).transform(transformFunction);
}
public static <T> JavaDStream<T> getStream(JavaStreamingContext jssc, String groupName, Map<String, Integer> map, int count,
Function<JavaPairRDD<String, byte[]>, JavaRDD<T>> transformFunction) {
if (count < 2) return getStream(jssc, groupName, map, transformFunction);
ArrayList<JavaDStream<T>> list = new ArrayList<>();
for (int i = 0; i < count; i++) {
list.add(getStream(jssc, groupName, map, transformFunction));
}
return jssc.union(list.get(0), list.subList(1, count));
}
}
Для создания потока сообщений нужно передать контекст, необходимые топики и имя группы получателей (jssc, topics и groupId соответственно). Для каждой группы формируется свой сдвиг очереди сообщений по каждому топику. Также можно создавать несколько получателей для распределения нагрузки между серверами. Все преобразования над данными указываются в transformFunction и выполняются в том же потоке, что и получатели.
public JavaPairRDD<String, Condition> conditions;
private JavaStreamingContext jssc;
private Map<Object, HyperLogLog> hlls;
public JavaStreamingContext create() {
sparkConf.setAppName("UniversalStreamingBuilder");
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConf.set("spark.storage.memoryFraction", "0.125");
jssc = new JavaStreamingContext(sparkConf, batchInterval);
HashMap map = new HashMap();
map.put(topicName, 1); // Kafka topic name and number partitions
JavaDStream<Event> events = StreamUtil.getEventsStream(jssc, groupName, map, numReceivers).repartition(numWorkCores);
updateConditions();
events.foreachRDD(ev -> {
// Compute audiences
JavaPairRDD<String, Object> rawva = conditions.join(ev.keyBy(t -> t.pixelId))
.mapToPair(t -> t._2())
.filter(t -> EventActionUtil.checkEvent(t._2(), t._1().condition))
.mapToPair(t -> new Tuple2<>(t._2().visitorId, t._1().id))
.distinct()
.persist(StorageLevel.MEMORY_ONLY_SER())
.setName("RawVisitorAudience");
// Update HyperLogLog`s
rawva.mapToPair(t -> t.swap()).groupByKey()
.mapToPair(t -> {
HyperLogLog hll = new HyperLogLog();
t._2().forEach(v -> hll.offer(v));
return new Tuple2<>(t._1(), hll);
}).collectAsMap().forEach((k, v) -> hlls.merge(k, v, (h1, h2) -> HyperLogLog.merge(h1, h2)));
// Save to Aerospike and HBase
save(rawva);
return null;
});
return jssc;
}
Здесь, чтобы соединить два (events и conditions) RDD (Resilient Distributed Dataset), используется join по pixel_id. Метод save — фейковый. Это сделано для того, чтобы разгрузить представленный код. На его месте должно находиться несколько преобразований и сохранений.
Запуск
public void run() {
create();
jssc.start();
long millis = TimeUnit.MINUTES.toMillis(CONDITION_UPDATE_PERIOD_MINUTES);
new Timer(true).schedule(new TimerTask() {
@Override
public void run() {
updateConditions();
}
}, millis, millis);
new Timer(false).scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
flushHlls();
}
}, new Date(saveHllsStartTime), TimeUnit.MINUTES.toMillis(HLLS_UPDATE_PERIOD_MINUTES));
jssc.awaitTermination();
}
Вначале создается и запускается контекст. Параллельно этому запускается 2 таймера для обновления условий и сохранения HyperLogLog. Обязательно в конце указывается awaitTermination(), иначе обработка закончится не начавшись.
Пакетная обработка
Раз в день перестраивает все аудитории, что решает проблемы устаревших и утерянных данных. Есть у ремаркетинга одна неприятная особенность для пользователя — навязчивость рекламы. Здесь вступает lookback window. Для каждого пользователя сохраняется дата его добавления в аудиторию, таким образом мы можем контролировать актуальность информации для пользователя.
Занимает 1.5-2 часа — все зависит от нагрузки на сеть. Причем большая часть времени это сохранение по базам: загрузка, обработка и запись в Aerospike 75 минут(выполняется в одном pipeline), остальное время — сохранение в HBase и Mongo (35 минут).
JavaRDD<Tuple3<Object, String, Long>> av = HbaseUtil.getEventsHbaseScanRdd(jsc, hbaseConf, new Scan())
.mapPartitions(it -> {
ArrayList<Tuple3<Object, String, Long>> list = new ArrayList<>();
it.forEachRemaining(e -> {
String pixelId = e.pixelId;
String vid = e.visitorId;
long dt = e.date.getTime();
List<Condition> cond = conditions.get(pixelId);
if (cond != null) {
cond.stream()
.filter(condition -> e.date.getTime() > beginTime - TimeUnit.DAYS.toMillis(condition.daysInterval)
&& EventActionUtil.checkEvent(e, condition.condition))
.forEach(condition -> list.add(new Tuple3<>(condition.id, vid, dt)));
}
});
return list;
}).persist(StorageLevel.DISK_ONLY()).setName("RawVisitorAudience");
Здесь почти то же, что и в потоковой обработке, но не используется join. Вместо него используется проверка event по списку condition с таким же pixel_id. Как оказалось, такая конструкция требует меньше памяти и выполняется быстрее.
Сохранение в базы
Сохранение из Kafka в HBase изначально было зашито в потоковый сервис, но из-за возможных сбоев и отказов было решено вынести его в отдельное приложение. Для реализации отказоустойчивости использовался Kafka Reliable Receiver, который позволяет не терять данные. Использует Checkpoint для сохранения метаинформации и текущих данных.
Количество записей в HBase на текущий момент около 400 миллионов. Все события хранятся в базе 180 дней и удаляются по TTL.
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable", "true");
jssc.checkpoint(checkpointDir);
Теперь вместо
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, batchInterval);
используем
JavaStreamingContext jssc = JavaStreamingContext.getOrCreate(checkpointDir, new ВашРеализованыйКласс());
Сохранение в Aerospike происходит при помощи самописного OutputFormat и Lua-скрипта. Для использования асинхронного клиента пришлось дописать два класса к официальному коннектору (форк).
public class UpdateListOutputFormat extends com.aerospike.hadoop.mapreduce.AerospikeOutputFormat<String, Bin> {
private static final Log LOG = LogFactory.getLog(UpdateListOutputFormat.class);
public static class LuaUdfRecordWriter extends AsyncRecordWriter<String, Bin> {
public LuaUdfRecordWriter(Configuration cfg, Progressable progressable) {
super(cfg, progressable);
}
@Override
public void writeAerospike(String key, Bin bin, AsyncClient client, WritePolicy policy, String ns, String sn) throws IOException {
try {
policy.sendKey = true;
Key k = new Key(ns, sn, key);
Value name = Value.get(bin.name);
Value value = bin.value;
Value[] args = new Value[]{name, value, Value.get(System.currentTimeMillis() / 1000)};
String packName = AeroUtil.getPackage(cfg);
String funcName = AeroUtil.getFunction(cfg);
// Execute lua script
client.execute(policy, null, k, packName, funcName, args);
} catch (Exception e) {
LOG.error("Wrong put operation: \n" + e);
}
}
}
@Override
public RecordWriter<String, Bin> getAerospikeRecordWriter(Configuration entries, Progressable progressable) {
return new LuaUdfRecordWriter(entries, progressable);
}
}
Асинхронно выполняет функцию из указанного пакета.
В качестве примера представлена функция добавления в список новых значений.
local split = function(str)
local tbl = list()
local start, fin = string.find(str, ",[^,]+$")
list.append(tbl, string.sub(str, 1, start - 1))
list.append(tbl, string.sub(str, start + 1, fin))
return tbl
end
local save_record = function(rec, name, mp)
local res = list()
for k,v in map.pairs(mp) do
list.append(res, k..","..v)
end
rec[name] = res
if aerospike:exists(rec) then
return aerospike:update(rec)
else
return aerospike:create(rec)
end
end
function put_in_list_first_ts(rec, name, value, timestamp)
local lst = rec[name]
local mp = map()
if value ~= nil then
if list.size(value) > 0 then
for i in list.iterator(value) do
mp[i] = timestamp end
end
end
if lst ~= nil then
if list.size(lst) > 0 then
for i in list.iterator(lst) do
local sp = split(i)
mp[sp[1]] = sp[2] end
end
end
return save_record(rec, name, mp)
end
Этот скрипт добавляет в список аудиторий новые записи вида «audience_id,timestamp». Если запись существует, то timestamp остается прежним.
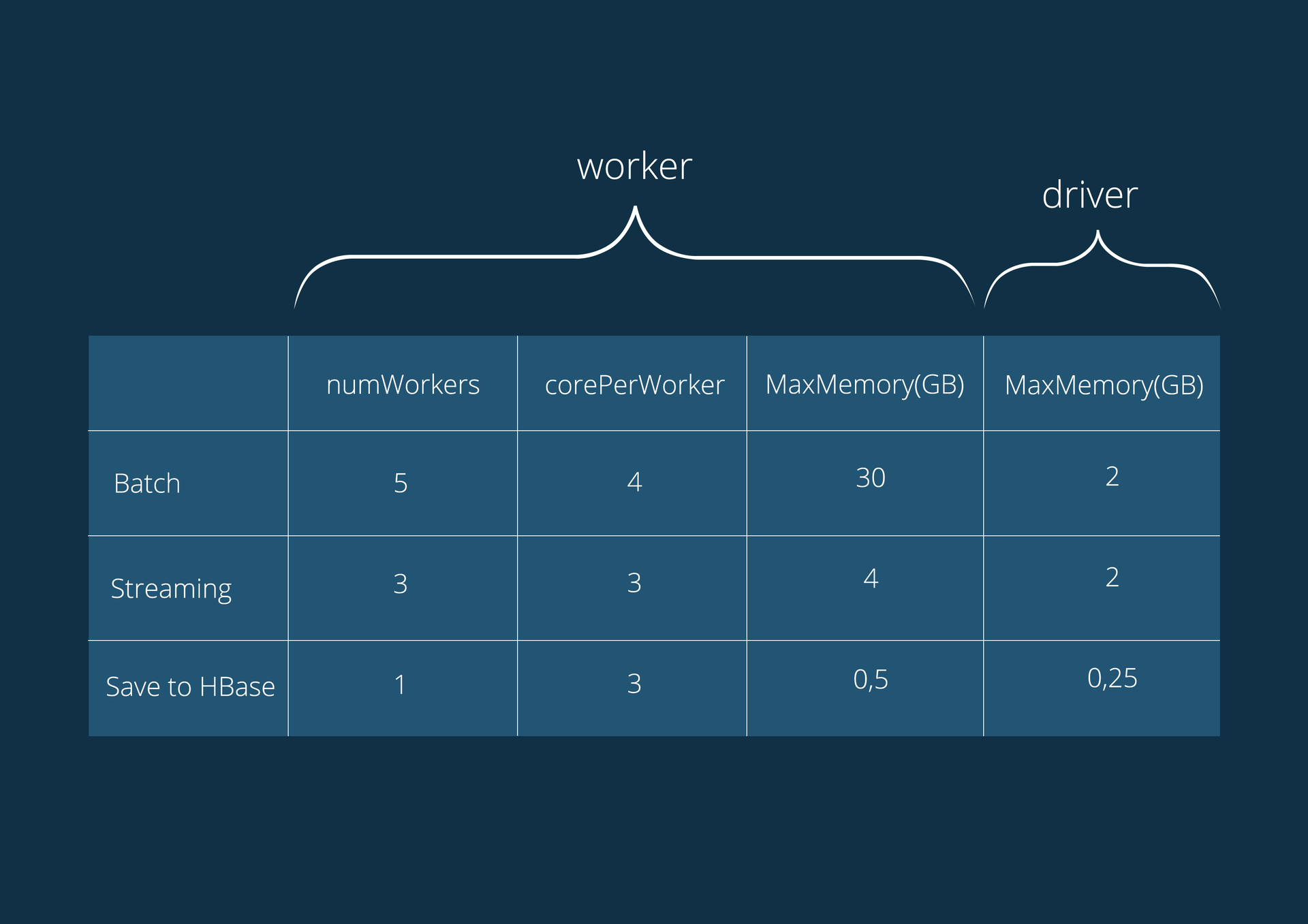
Характеристики серверов, на которых работают приложения:
Intel Xeon E5-1650 6-cores 3.50 GHz (HT), 64GB DDR3 1600;
Операционная система CentOS 6;
Версия CDH 5.4.0.
Конфигурация приложений:
В заключении
На пути к данной реализации мы опробовали несколько вариантов (С#, Hadoop MapReduce и Spark) и получили инструмент, который одинаково хорошо справляется как с задачами потоковой обработки, так и пересчётов огромных массивов данных. За счёт частичного внедрения лямбда архитектуры, повысилось переиспользование кода. Время полной перестройки аудиторных каналов, снизилось с десятка часов, до десятка минут. А горизонтальная масштабируемость стала как никогда простой.
Попробовать наши технологии вы всегда можете на нашей платформе Hybrid.
P.S.
Особая благодарность выражается DanilaPerepechin за неоценимую помощь в написании статьи.
Комментарии (30)

kirichenko
04.09.2015 13:05-2За счёт частичного внедрения лямбда архитектуры, повысилось переиспользование кода.
Интересно, каким образом.
Вообще, спарк — какой-то обрезок, пригодный вот для таких SQL-like обработок. Чуть что сложнее — лучше даже не связываться с ним. Одно только остутствие доступа из воркера к конфигурации чего стоит (она ж несереализуема, вплоть до 1.4.0).
FrostNova
04.09.2015 13:15+1Интересно, каким образом
Потоковый и пакетный обработчики используют одну и туже логику обработки событий.
Позвольте спросить: зачем Вам доступ к конфигу из воркера? Можно в драйвере конфиг посмотреть и уже через драйвер воркеры могут получить интересующий Вас параметр.kirichenko
04.09.2015 17:53А если у меня этих параметров штук 20, к примеру? И Воркеры — объекты классов, определённых где-то в другом месте.
FrostNova
04.09.2015 18:08+1На счет количества параметров — не вижу никакой проблемы. А для объектов классов для подключаемых библиотек Вы правы — ошибки не избежать. Но кто вам мешает использовать ту самую (1.4.0 и выше) версию?
kirichenko
04.09.2015 20:51Скорее всего я неправ, что «наезжаю» на спарк, просто не моё это — сердцу родней старый добрый mr, хотя, дни его сочтены. Скала и вся эта функциональщна всё портит.
kirichenko
04.09.2015 18:08А причём тут «лямбда архитектура»? Без неё никак не получалось использовать не только ту же логику но и тот же самый код?
FrostNova
04.09.2015 19:22Смысл «лямбда архитектуры» лежит во фразе: «большие и быстрые» данные. Потоковая обработка данных отвечает за «быстрые», пакетная за «большие», а переиспользование кода я считаю частью «лямбда архитектуры», так как в обоих случаях обрабатываются одинаковые данные.
Возможно я неправильно понимаю смысл «лямбда архитектуры» и хотел бы Ваш комментарий по этому поводу.kirichenko
04.09.2015 20:45Я просто к тому, что то же самое можно получить и без неё. Я, честно говоря, далёк от всех этих функциональных штучек.
dcheklov
04.09.2015 13:16+1Spark далеко не обрезок, и, наоборот, по сравнению с классическим MR предоставляет абсолютный контроль над обработкой данных. Напишите пример задачи обработки, чтобы понять, где Spark будет лажать
kirichenko
04.09.2015 18:03Спарк всего лишь оптимизирует граф выполнения и позволяет кешировать промежуточные результаты в памяти. Контроля над обработкой данных так столько же, сколько в классическим MR, если не меньше. По крайней мере, в классическим MR многие вещи более логичны и очевидны, в то время как в спарке они реализуется как хаки, с использованием особенностей тех или иных функций (setup/cleanup, двойная сортировка и т.п.).
Пример задачи где спарк будет лажать я уже привёл, банально передать конфигурацию в воркеры. Ну и да, тот случай, когда промежуточных данных больше, чем оперативной памяти.

alexkrash
04.09.2015 15:00Наверное, здесь произошла «типичная подмена понятий». Вы имели в виду из executor'а (исполнителя юзерских лямбд)? А какого рода конфигурация нужна? Для своих нужд я вполне обхожусь broadcast'ами, или сериализуемым своим классом с настройками.
kirichenko
04.09.2015 17:43Нет, я говорю о воркерах, и о более сложных обработках. Когда эти обработки — не «юзерские лямбды» и не замыкания, а экземпляры классов, имплементирующих хотя бы VoidFunction. Как броадкастить то, что не сериализуется? Зачем педалить свой класс, когда есть конфиг спарка, из контекста можно получить конфиг хадупа и т.п.?
alexkrash
04.09.2015 15:06У Вас в драйвере по таймеру запускается updateConditions(), который модифицирует rdd.
1.) Насколько я понимаю, размер этой коллекции должен быть мал, т.к. она должна быть послана через broadcast на всех executor'ов — это так? Если нет — расскажите, пожалуйста.
2.) У меня в приложении есть такая же необходимость — со временем обновлять некий конфиг, и доставлять его на executor'ов. Но, согласно документации, чтобы применилось синхронно на всех executor'ах, это должен быть либо ручной broadcast, либо неявный — через сериализатор лямбд. Недокументировано то, что при обновлении в драйвере, изменения разъедутся по executor'ам. Насколько стабильно/синхронно у Вас применяются эти изменения? Или в Вашем случае допустимо несинхронное применение изменений, и Вы о нем знаете?FrostNova
04.09.2015 15:33+11) Да, действительно, размер этой коллекции достаточно мал.
2) Для нашего потокового обработчика некритична небольшая разница в синхронизации. В любом случае пакетный обработчик перестроит все аудитории под текущее состояние условий. На счет стабильности: на драйвере иногда можно встретить OutOfMemoryError. Происходит это из-за того, что при использовании persist() или cache() на драйвере накапливается информация, которая совсем не хочет очищаться автоматически (точные причины почему это происходит мне, увы, не известны). Проблема решилась добавлением System.gc() в конце updateConditions().
FrostNova
04.09.2015 15:31Промахнулся с ответом: habrahabr.ru/company/targetix/blog/266009/#comment_8560397

Stas911
04.09.2015 17:45А почему не Cassandra? Ее рассматривали?
dcheklov
04.09.2015 17:53+1Если Cassandra вместо Spark, то смысла не вижу, тк основное требование у нас — это гибкость обработки и возможность использовать обычный язык программирования. Что бы там не предлагала Кэсси — мы всегда будем зависеть о ее ограничений. Если заметили, мы в реалтайме еще собираем HyperLogLog каждого аудиторного сегмента.
Из баз данных, которые из коробки предлагают все, что нам нужно было в этой задаче — VoltDB. Но я не могу ручаться за то, что с ней не было бы каких-то косяков и ограничений.Stas911
04.09.2015 18:04Кассандра вместо HBase, а Spark умеет с данными в ней работать через DataStax-овский коннектор.
dcheklov
04.09.2015 18:08+1Тут скорее ответ выглядит так: у кого какой опыт с той или иной базой. Чтобы потестить базу в High Load проектах, нужно с этой базой в реальных условиях пожить 3-5 месяцев, чтобы узнать все плюсы и минусы. Так что HBase выбрали исходя из предыдущего опыта, а Cassandra испытывалась только на локальном компе)

robert_ayrapetyan
04.09.2015 20:42Есть ли у вас статы и репорты (dims/metrics) — с часовой\дневной\месячной и т.п. гранулярностью? Если да — где вы все это добро храните?
FrostNova
05.09.2015 11:54+1Мы используем HyperLogLog для сохранения статистики по аудиториям. Потоковый обработчик каждые 10 минут обновляет состояние аудиторий за текущий час. Пакетный обработчик сохраняет статистику за весь период. В итоге комбинируя статистику за весь период и часовую можно получить информацию по аудиториям с точностью до 10 минут. Все HyperLogLog храним в MongoDB. Остальные метрики (количество обработанных данных, время работы и т.п.) отправляются на хранение в Graphite.

DIegoR
05.09.2015 19:43Интересно измеряли ли вы эффективность вашей рекламы в зависимости от задержки обработки/показа. Очевидно, что при нулевой задержке она будет неэффективна, так как человек еще находтся на целевой странице. На бесконечности тоже нулевая эффективность. Значит где-то есть максимум хоть один. Так вот где он, через 20 секунд, 20 минут, 20 часов или 20 дней?
Ну и конечно вопрос, зачем мне показывать лобзик, который я уже купил? Но это похоже вопрос риторический :-)DanilaPerepechin
06.09.2015 00:09+2На самом деле оба вопроса риторические, но на оба я и отвечу =)
Для рекламных кампаний разных направленностей существуют различные точки эффективности. Когда то это долгосрочный интерес, когда то краткосрочный. Соответственно и пользователь с разными типами интересов по разному реагирует на рекламу.
Приведу один пример человек готовится к путешествию и бронирует себе отель, покупает билеты и прочее. Так вот в этом случае среднее время поиска человека 17 дней, в течении которых происходит 6 сессий поиска. Человек в среднем посещает 18 сайтов и делает 7 кликов по рекламе. Соответственно в других типах интересов, другие цифры. Мы ответственно подходим к исследованию основных шаблонов для различных типов интересов, и уже имеем достаточно информации чтобы обеспечить потребности большинства наших клиентов.
А на второй вопрос ответ проще. С сайтов устанавливающих наш код приходит информация о состоянии пользователя, на какой стадии необходимого действия он остановился. Если целевое действие продать, а пользователь остановился лишь на добавлении товара в корзину, мы используем один тип ремаркетинговых действий, если пользователь остановился на оформлении заказа — другой. А если вы уже купили лобзик и целевой действие совершено, мы вас оставляем в покое. Может только иногда будем показывать рекламу лобзика, чтобы вы были удовлетворенны покупкой ещё больше ( шутка =) )
0x0FFF
Приятно, что и российские компании постепенно приходят к идее использования современных open-source инструментов и архитектур, отказываясь от тех же исторических WebLogic + Oracle DB в подобных системах
Небольшой вопрос касательно архитектуры: у вас используются Aerospike, MongoDB и HBase, все они в той или иной мере key-value store. Можете пояснить, в чем идея такого разбиения и какие принципиальные кейсы вынесены на Aerospike и MongoDB, с которыми не справился бы HBase?
dcheklov
Aerospike — хранит уже готовые профили пользователей, например таблица visitor_id; audiences[]. Когда в DSP приходит RTB-запрос, то используется именно Aerospike. Здесь пока ни одна другая база не показывала такие результаты быстродействия, низкий latency, и низкую загрузку процессора.
Mongo — хороша для кодеров, когда нужно сохранить объект в базу. Здесь Mongo со своей документ-ориентированной архитектурой вне конкуренции. Нагрузки практически не держит. В общем эта база только под специфические задачи осталась.
HBase — у нас пришла на смену Mongo, но пока не везде смогла вытеснить ее из-за ограничений. HBase интегрирован в кластер Hadoop и ее реально можно настроить на высокую отказоустойчивость и быстродействие. Также очень важна рандомная запись/чтение, что Mongo ну совсем никак не настроить
FrostNova Кстати а, что здесь Mongo делает, мы вроде ее уже выпилили?
FrostNova
В MongoDB хранятся аудиторные условия. Учитывая то, что они могут быть представлены фактически любой структурой — MongoDB как нельзя кстати.
dcheklov
Вы в статье упустили важную часть, как раз про описание аудиторий, а также про модель данных (Event). В общем вся суть для чего мы вообще эту архитектуру задумали) Получилось очень сильно про Spark, но мало — какую задачу решает.
0x0FFF
Хорошая архитектура. Я бы сделал почти так же
FrostNova
Исторически так сложилось, что MongoDB мы использовали во многих проектах. Постепенно мы уходим от ее использования, но все же для хранения сложной структуры данных она пока что незаменима. Что касается Aerospike, то тут все просто — для RTB нужен быстрый отклик с учетом обращения к DB и обработки.