Сегодня, в преддверии старта набора на новый поток курса «Machine Learning», делимся с вами переводом поста из блога PyTorch, в котором рассказывается о работе ИИ для борьбы с вредителями, который анализирует ситуацию по фотографиям феромоновых ловушек в условиях индийской глубинки, где выращивают хлопок, о применении PyTorch Mobile для развертывания моделей прямо на смартфоне в оффлайне, о сжатии моделей и, конечно, немного о том, как работать с аномальными изображениями, которые отправляют индийские фермеры.

Хлопок — одна из основных культур волокон во всем мире, его выращивают в более чем 80 странах. Почти 100 миллионов семей во всем мире занимаются выращиванием хлопка для получения средств к существованию. При таком значении хлопка его особая уязвимость к заражению вредителями вызывает тревогу у многих. Однако заражение вредителями — это одновременно одна из наиболее значимых, но предотвратимых проблем, с которой сталкиваются фермеры, причем 55% всех используемых в Индии пестицидов приходится на разведение хлопка.

Феромоновая ловушка
Wadhwani AI оздавался, чтобы применять ИИ в решении проблем на благо общества. Когда речь идет о борьбе и предотвращении атак на урожай, ловушки для вредителей можно использовать как систему раннего предупреждения, при этом количество захваченных вредителей сообщает о вторжении. Применяя глубокое обучение на изображениях ловушек, AI дает фермерам подробные рекомендации по опрыскиванию с целью упреждающего решения определенных проблем с вредителями.
С помощью PyTorch исследователи ИИ в Wadhwani создали модель, способную точно предсказать местонахождение вредителей в хлопковых культурах. После захвата изображения оно проходит через многозадачную сеть, которая проверяет изображение на валидность. Если это так, то ветка обнаружения указывает на потенциальное местоположение обнаруженных вредителей. Окончательные рекомендации даются, исходя из количества обнаруженных вредителей и установленных энтомологами правил. Весь процесс подробно изложен ниже.

Весь рабочий процесс с решением по мониторингу вредителей
Еще одно преимущество PyTorch — способность использовать выводы в оффлайне. Множество мелких фермерских хозяйств расположено в таких местах, где имеются проблемы с доступом в Интернет. Для удобства пользователей Wadhwani AI может развернуть свои модели с помощью алгоритмов сжатия моделей, уменьшая их размер на 98 %: с 250 до менее чем 5 MB.
Недавно опубликованный в «KDD 2020» доклад нашей команды рассказывает обо всем нашем путешествии, о проблемах, с которыми мы столкнулись, и о том, что мы узнали, пока решали их.

Задействованные в компонентах конвейера инструменты
Наша работа поддерживается целым рядом инструментов, например PyTorch, чтобы разрабатывать и развертывать модели, а также Weights & Biases, чтобы отслеживать эксперименты и передавать их результаты заинтересованным сторонам. Ниже приводится исчерпывающее резюме всех используемых нами инструментов.
Ядро нашего решения — обнаружение объектов. В целом модели обнаружения объектов можно разделить на две категории: двухступенчатые и одноступенчатые детекторы. Двухступенчатые архитектуры, как правило, точнее одноступенчатых, хотя медленнее. Скорость вывода информации имеет первостепенное значение для удобства пользователей, поэтому применяется одноступенчатый подход.
Single Shot MultiBox Detector (SSD) был одним из первых одноступенчатых детекторов, обеспечивший производительность, сравнимую с его двухступенчатыми аналогами, и в то же время высокую скорость. Так как наш набор данных кардинально отличается от стандартных наборов данных обнаружения объектов, мы столкнулись со значительной проблемой. Качество наших изображений ниже потому, что их делают со смартфонов в отдаленных деревнях. Вредители часто склонны группироваться, а это затрудняет определение границ на изображениях. Границы (конечности и крылья) — это в конечном счете ключевые классификаторы, которых нет во входном изображении.

Некоторые проблемы при работе с реальными данными
Используемая для обучения SSD целевая функция называется MultiBox loss. Она состоит из локализующего и классификационного компонентов для учета герметичности ограничивающего поля и точности прогнозируемого класса соответственно. Это то место, где удобно отслеживать различные аспекты функций потерь, чтобы понять, как на них влияют изменения оптимизации, увеличение размера данных, архитектура сети или размер входных данных. Например, на рисунке 4 видно, что в общих потерях (в отношении train/loss) всегда преобладает потеря классификации (train/loss_c), а не потеря локализации (train/loss_l).

Функция SSD Loss на дашборде Weights & Biases
Другой способ наблюдать за эволюцией производительности модели — визуализировать развитие прогнозов с течением времени. Weights & Biases помогает визуализировать прогноз: мы можем отслеживать, как прогнозируемые границы изменяются во времени:

Визуализация эволюции прогнозов границ в Weights & Biases
Развернув модель в полевых условиях, мы обнаружили, что пользователи обычно отправляют фотографии без ловушек. Известно, что модели глубокого обучения плохо работают с аномальными изображениями, часто будучи излишне уверенными в своих ошибочных прогнозах. Для решения этой проблемы — и после использования различных подходов — был обучен отдельный классификатор, чтобы отклонять широкий спектр изображений вне распределения. Далее модель VGGNet обучалась использованию изображений из набора данных COCO в качестве невалидного класса, а также изображений из нашего набора данных вредителей как валидного класса.
Однако во время вывода изображение должно было проходить через две сети, что значительно увеличивало время вывода. Так как и модели проверки изображений, и модели обнаружения объектов использовали одну и ту же базовую сеть VGGNet, на которую приходилась большая часть времени вывода, мы объединили их, добавив новую ветку с последнего слоя базовой сети в SSD для проверки изображений, чтобы у нас была единая модель. Сеть совместно обучалась работе в многозадачной учебной инсталляции, при этом руководители обнаружения и проверки были обучены работе с потерями MultiBox и c кросс-энтропией.
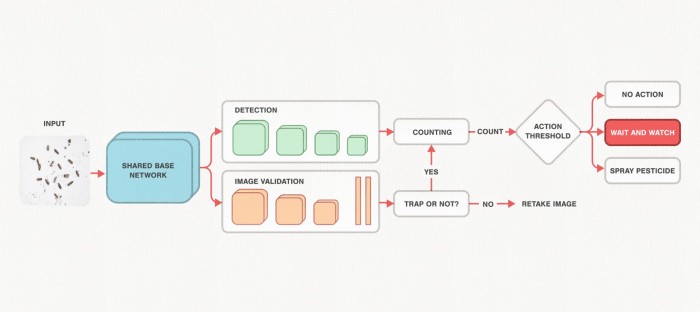
Иллюстрация нашей модели машинного обучения
Наиболее распространенный подход к оценке сетей обнаружения объектов — использование средней точности (Average Precision — AP) для каждого класса. Однако связь между AP и целью этого решения не всегда проста. AP определяется с применением диапазона порогов доверия для каждого класса, тогда как во время развертывания нам необходимо выбрать одну операционную точку. Мы рассматриваем окончательное задание по рекомендации распыления пестицидов как проблему бинарной классификации, когда классы указывают, следует ли распылять пестицид. Следовательно, мы заново определяем ложноположительные и ложноотрицательные факторы ради четкой коммуникации с заинтересованными сторонами, которым, как правило, трудно интерпретировать точность и отзыв, подобные тем, что даны в следующем списке:
Мы поставили перед собой цель достичь менее 5 % MAR и FAR, поскольку и ложноположительные, и ложноотрицательные результаты вредны для фермера. Мы настроили гиперпараметр и выбор оптимального порога доверия для достижения этой общей цели. В частности, мы обнаружили, что график DataFrame в Weights & Biases крайне полезен для понимания прогнозов во время вывода на уровне изображения.
Сравнение реальных данных и прогноза на изображении с использованием графика «dataframe» на Weights & Biases
Этот график помогает визуально сравнивать прогнозируемые и реальные рамки в любом изображении, а также позволяет сортировать, группировать и фильтровать данные в соответствии с нашими требованиями. Например, прогнозы могут сортироваться на основе доверительной оценки, чтобы качественно оценивать входные данные с низким доверием. График «Parameter Importance» в «Weights & Biases» помогает определить самые значительные в отношении потери валидации гиперпараметры.

График важности параметров Weights & Biases показывает корреляцию различных параметров с заданной метрикой
Несмотря на то что основная причина для сжатия модели — развертывание на телефоне, оно также выгодно при развертывании в облаке, поскольку работает значительно быстрее. Мы используем итерационную обрезку (как указано в этой работе) и квантование, чтобы уменьшить размер нашей модели с 265 до 5 MB. В статье представлена такая методика для классификационных сетей.
 .
.
Иллюстрация обрезки сверточных слоев
На рисунке выше показано, как обрезается один фильтр. Давайте рассмотрим два последовательных слоя: L и L+1. Количество входных и выходных каналов для слоя L равно K и N соответственно. Поскольку вывод слоя L — это вход слоя L+1, то количество входных каналов для слоя L+1 также равно N, а количество выходных каналов равно M. Обрезка фильтра по индексу i из слоя L уменьшила бы количество выходных каналов слоя L, а следовательно, и количество входных каналов в слое L+1 на единицу. Таким образом, для обрезки выбранного фильтра также необходимо обновить все слои с помощью слоя L в качестве входных данных. Мы изменим этот метод для работы с многозадачной архитектурой, сокращая 1024 фильтра на каждой итерации обрезки, для 15 итераций. Смотрите этот пост в блоге, чтобы получить более подробный контекст и другие подробности.
Чтобы развернуть модели в производственной среде, мы сначала конвертируем модель PyTorch в модуль TorchScript. TorchScript сериализует модель и делает ее независимой в смысле зависимостей Python. Мы смешиваем сценарии и трассировку для модели, поскольку определенные ее части имеют поток управления, зависимый от данных.
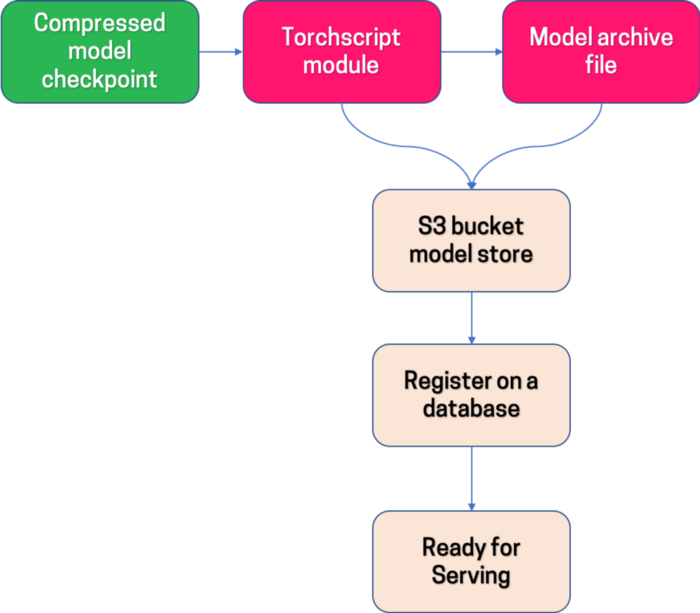
Иллюстрация рабочего процесса подготовки модели PyTorch, готовой к обслуживанию сервером
Мы используем TorchServe, работающий как сервер модели. TorchServe имеет встроенный веб-сервер, который принимает модель, запрос вывода делается через REST API. Это позволяет нам легко настроить модель для пакетных прогнозов. Модуль TorchScript упакован в файл архива модели (.mar), необходимый TorchServe. TorchServe содержит точку входа и рабочий процесс для выполнения запроса вывода. Наконец, модуль TorchScript и файл mar загружаются в корзину s3. Мы создали внутреннюю структуру для ведения реестра и обслуживания моделей сервером. Каждая готовая к производству модель добавляется в реестр моделей вместе со всеми связанными метаданными. Платформа использует получившиеся артефакты для последующего обслуживания модели в экземпляре AWS EC2 с помощью TorchServe.
Чтобы развернуть нашу модель на смартфонах, мы используем PyTorch Mobile. Мы создаем вокруг Pytorch Mobile SDK, извлекающий артефакты из реестра моделей и позволяющий нам эффективно развертывать несколько моделей на устройстве. Приложение может делать выводы без подключения к Интернету. Оно ставит в очередь все данные, необходимые для регистрации, и синхронизирует их обратно с сервером в фоновом режиме, когда мобильный телефон подключен к сети.
Чтобы такие эксперименты можно было повторить, примите во внимание следующее:=
В следующем сезоне наше решение используют более 10 000 фермеров по всей Индии, и мы надеемся, что это побудит больше людей творчески применять ИИ, чтобы решать социальные проблемы.
О Wadhwani AI
Институт искусственного интеллекта Wadhwani AI — это независимый некоммерческий исследовательский институт и глобальный центр, разрабатывающий решения на основе искусственного интеллекта на благо общества. В институте используют возможности современного искусственного интеллекта, чтобы решать глобальных задачи. Миссия Wadhwani AI — разработка и применение инноваций и решений на основе ИИ в широком спектре социальных сфер, включая здравоохранение, сельское хозяйство, образование, инфраструктуру и финансовую доступность.
Искусственный интеллект может решить многие задачи, но задачу экономии на обучении — решить можете только вы. А поможет вам в этом специальный промокод HABR, который даст +10% к скидке, указанной на баннере ниже.

Хлопок — одна из основных культур волокон во всем мире, его выращивают в более чем 80 странах. Почти 100 миллионов семей во всем мире занимаются выращиванием хлопка для получения средств к существованию. При таком значении хлопка его особая уязвимость к заражению вредителями вызывает тревогу у многих. Однако заражение вредителями — это одновременно одна из наиболее значимых, но предотвратимых проблем, с которой сталкиваются фермеры, причем 55% всех используемых в Индии пестицидов приходится на разведение хлопка.
ИИ для мониторинга вредителей
Феромоновая ловушка
Wadhwani AI оздавался, чтобы применять ИИ в решении проблем на благо общества. Когда речь идет о борьбе и предотвращении атак на урожай, ловушки для вредителей можно использовать как систему раннего предупреждения, при этом количество захваченных вредителей сообщает о вторжении. Применяя глубокое обучение на изображениях ловушек, AI дает фермерам подробные рекомендации по опрыскиванию с целью упреждающего решения определенных проблем с вредителями.
С помощью PyTorch исследователи ИИ в Wadhwani создали модель, способную точно предсказать местонахождение вредителей в хлопковых культурах. После захвата изображения оно проходит через многозадачную сеть, которая проверяет изображение на валидность. Если это так, то ветка обнаружения указывает на потенциальное местоположение обнаруженных вредителей. Окончательные рекомендации даются, исходя из количества обнаруженных вредителей и установленных энтомологами правил. Весь процесс подробно изложен ниже.
Весь рабочий процесс с решением по мониторингу вредителей
Еще одно преимущество PyTorch — способность использовать выводы в оффлайне. Множество мелких фермерских хозяйств расположено в таких местах, где имеются проблемы с доступом в Интернет. Для удобства пользователей Wadhwani AI может развернуть свои модели с помощью алгоритмов сжатия моделей, уменьшая их размер на 98 %: с 250 до менее чем 5 MB.
Недавно опубликованный в «KDD 2020» доклад нашей команды рассказывает обо всем нашем путешествии, о проблемах, с которыми мы столкнулись, и о том, что мы узнали, пока решали их.
Построение решения машинного обучения
Задействованные в компонентах конвейера инструменты
Наша работа поддерживается целым рядом инструментов, например PyTorch, чтобы разрабатывать и развертывать модели, а также Weights & Biases, чтобы отслеживать эксперименты и передавать их результаты заинтересованным сторонам. Ниже приводится исчерпывающее резюме всех используемых нами инструментов.
Многозадачная модель
Ядро нашего решения — обнаружение объектов. В целом модели обнаружения объектов можно разделить на две категории: двухступенчатые и одноступенчатые детекторы. Двухступенчатые архитектуры, как правило, точнее одноступенчатых, хотя медленнее. Скорость вывода информации имеет первостепенное значение для удобства пользователей, поэтому применяется одноступенчатый подход.
Single Shot MultiBox Detector (SSD) был одним из первых одноступенчатых детекторов, обеспечивший производительность, сравнимую с его двухступенчатыми аналогами, и в то же время высокую скорость. Так как наш набор данных кардинально отличается от стандартных наборов данных обнаружения объектов, мы столкнулись со значительной проблемой. Качество наших изображений ниже потому, что их делают со смартфонов в отдаленных деревнях. Вредители часто склонны группироваться, а это затрудняет определение границ на изображениях. Границы (конечности и крылья) — это в конечном счете ключевые классификаторы, которых нет во входном изображении.
Некоторые проблемы при работе с реальными данными
Используемая для обучения SSD целевая функция называется MultiBox loss. Она состоит из локализующего и классификационного компонентов для учета герметичности ограничивающего поля и точности прогнозируемого класса соответственно. Это то место, где удобно отслеживать различные аспекты функций потерь, чтобы понять, как на них влияют изменения оптимизации, увеличение размера данных, архитектура сети или размер входных данных. Например, на рисунке 4 видно, что в общих потерях (в отношении train/loss) всегда преобладает потеря классификации (train/loss_c), а не потеря локализации (train/loss_l).
Функция SSD Loss на дашборде Weights & Biases
Другой способ наблюдать за эволюцией производительности модели — визуализировать развитие прогнозов с течением времени. Weights & Biases помогает визуализировать прогноз: мы можем отслеживать, как прогнозируемые границы изменяются во времени:
Визуализация эволюции прогнозов границ в Weights & Biases
Развернув модель в полевых условиях, мы обнаружили, что пользователи обычно отправляют фотографии без ловушек. Известно, что модели глубокого обучения плохо работают с аномальными изображениями, часто будучи излишне уверенными в своих ошибочных прогнозах. Для решения этой проблемы — и после использования различных подходов — был обучен отдельный классификатор, чтобы отклонять широкий спектр изображений вне распределения. Далее модель VGGNet обучалась использованию изображений из набора данных COCO в качестве невалидного класса, а также изображений из нашего набора данных вредителей как валидного класса.
Однако во время вывода изображение должно было проходить через две сети, что значительно увеличивало время вывода. Так как и модели проверки изображений, и модели обнаружения объектов использовали одну и ту же базовую сеть VGGNet, на которую приходилась большая часть времени вывода, мы объединили их, добавив новую ветку с последнего слоя базовой сети в SSD для проверки изображений, чтобы у нас была единая модель. Сеть совместно обучалась работе в многозадачной учебной инсталляции, при этом руководители обнаружения и проверки были обучены работе с потерями MultiBox и c кросс-энтропией.
Иллюстрация нашей модели машинного обучения
Оценка модели
Наиболее распространенный подход к оценке сетей обнаружения объектов — использование средней точности (Average Precision — AP) для каждого класса. Однако связь между AP и целью этого решения не всегда проста. AP определяется с применением диапазона порогов доверия для каждого класса, тогда как во время развертывания нам необходимо выбрать одну операционную точку. Мы рассматриваем окончательное задание по рекомендации распыления пестицидов как проблему бинарной классификации, когда классы указывают, следует ли распылять пестицид. Следовательно, мы заново определяем ложноположительные и ложноотрицательные факторы ради четкой коммуникации с заинтересованными сторонами, которым, как правило, трудно интерпретировать точность и отзыв, подобные тем, что даны в следующем списке:
- Пропущенный сигнал тревоги (MAR): в процентах случаев, когда рекомендация должна была касаться опрыскивания, но система предлагала обратное.
- Скорость ложной тревоги (FAR): в процентах случаев, когда не следует предпринимать никаких действий, но система предложила распыление.
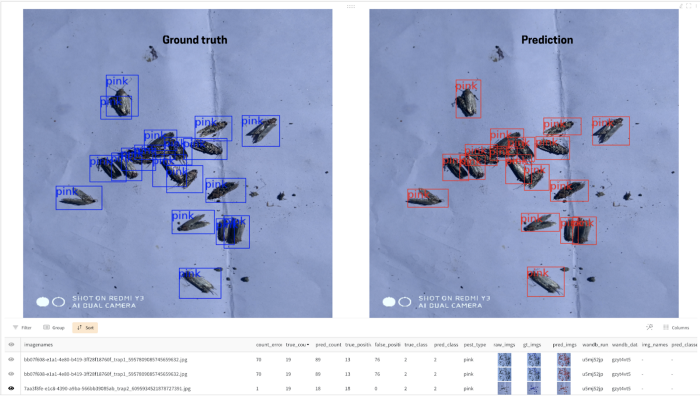
Мы поставили перед собой цель достичь менее 5 % MAR и FAR, поскольку и ложноположительные, и ложноотрицательные результаты вредны для фермера. Мы настроили гиперпараметр и выбор оптимального порога доверия для достижения этой общей цели. В частности, мы обнаружили, что график DataFrame в Weights & Biases крайне полезен для понимания прогнозов во время вывода на уровне изображения.
Сравнение реальных данных и прогноза на изображении с использованием графика «dataframe» на Weights & Biases
Этот график помогает визуально сравнивать прогнозируемые и реальные рамки в любом изображении, а также позволяет сортировать, группировать и фильтровать данные в соответствии с нашими требованиями. Например, прогнозы могут сортироваться на основе доверительной оценки, чтобы качественно оценивать входные данные с низким доверием. График «Parameter Importance» в «Weights & Biases» помогает определить самые значительные в отношении потери валидации гиперпараметры.
График важности параметров Weights & Biases показывает корреляцию различных параметров с заданной метрикой
Сжатие модели
Несмотря на то что основная причина для сжатия модели — развертывание на телефоне, оно также выгодно при развертывании в облаке, поскольку работает значительно быстрее. Мы используем итерационную обрезку (как указано в этой работе) и квантование, чтобы уменьшить размер нашей модели с 265 до 5 MB. В статье представлена такая методика для классификационных сетей.
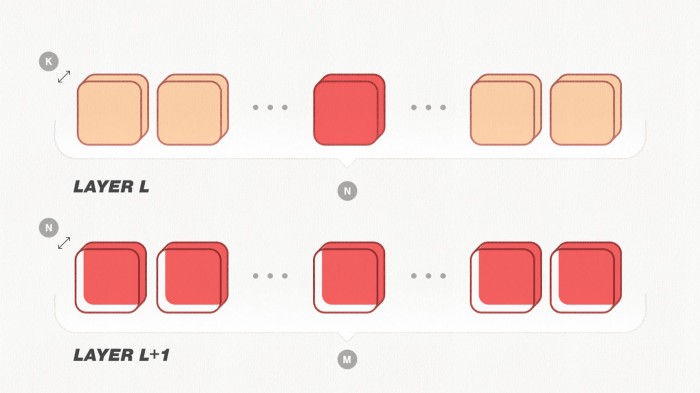
.Иллюстрация обрезки сверточных слоев
На рисунке выше показано, как обрезается один фильтр. Давайте рассмотрим два последовательных слоя: L и L+1. Количество входных и выходных каналов для слоя L равно K и N соответственно. Поскольку вывод слоя L — это вход слоя L+1, то количество входных каналов для слоя L+1 также равно N, а количество выходных каналов равно M. Обрезка фильтра по индексу i из слоя L уменьшила бы количество выходных каналов слоя L, а следовательно, и количество входных каналов в слое L+1 на единицу. Таким образом, для обрезки выбранного фильтра также необходимо обновить все слои с помощью слоя L в качестве входных данных. Мы изменим этот метод для работы с многозадачной архитектурой, сокращая 1024 фильтра на каждой итерации обрезки, для 15 итераций. Смотрите этот пост в блоге, чтобы получить более подробный контекст и другие подробности.
Развертывание модели
Чтобы развернуть модели в производственной среде, мы сначала конвертируем модель PyTorch в модуль TorchScript. TorchScript сериализует модель и делает ее независимой в смысле зависимостей Python. Мы смешиваем сценарии и трассировку для модели, поскольку определенные ее части имеют поток управления, зависимый от данных.
class Model(torch.nn.Module):
def __init__(self, param1, param2):
self.module1 = NeuralNet(param1)
self.module2 = torch.jit.script(FooFunc(param2))
def forward(self, x):
y1 = self.module1(x)
if some_condition:
return self.module2(y1)
else:
return y1
traced_model = torch.jit.trace(Model, torch.randn(1,3,300,300))
Иллюстрация рабочего процесса подготовки модели PyTorch, готовой к обслуживанию сервером
Развертывание в облаке
Мы используем TorchServe, работающий как сервер модели. TorchServe имеет встроенный веб-сервер, который принимает модель, запрос вывода делается через REST API. Это позволяет нам легко настроить модель для пакетных прогнозов. Модуль TorchScript упакован в файл архива модели (.mar), необходимый TorchServe. TorchServe содержит точку входа и рабочий процесс для выполнения запроса вывода. Наконец, модуль TorchScript и файл mar загружаются в корзину s3. Мы создали внутреннюю структуру для ведения реестра и обслуживания моделей сервером. Каждая готовая к производству модель добавляется в реестр моделей вместе со всеми связанными метаданными. Платформа использует получившиеся артефакты для последующего обслуживания модели в экземпляре AWS EC2 с помощью TorchServe.
Развертывание на смартфонах
Чтобы развернуть нашу модель на смартфонах, мы используем PyTorch Mobile. Мы создаем вокруг Pytorch Mobile SDK, извлекающий артефакты из реестра моделей и позволяющий нам эффективно развертывать несколько моделей на устройстве. Приложение может делать выводы без подключения к Интернету. Оно ставит в очередь все данные, необходимые для регистрации, и синхронизирует их обратно с сервером в фоновом режиме, когда мобильный телефон подключен к сети.
Лучшие практики
Чтобы такие эксперименты можно было повторить, примите во внимание следующее:=
- Контейнеризация. Docker широко используется для обеспечения того, чтобы все зависимости, необходимые для репликации эксперимента, были упакованы в единую изолированную среду.
- Управление версиями данных. Поскольку наборы данных продолжают развиваться с течением времени, разделения на наборы тренировки, валидации и тестирования не могут быть статичными. Явно версионируйте данные, чтобы сделать снимки образцов, используемых для обучения любого конкретного эксперимента. На данный момент мы явно сохраняем разбиения в файле версии данных. Мы с нетерпением ждем перехода на артефакты от Weights & Biases.
- Управление версиями эксперимента: мы сохраняем все гиперпараметры для каждого эксперимента в файле конфигурации вместе с идентификатором коммита Git и конкретным начальным значением.
В следующем сезоне наше решение используют более 10 000 фермеров по всей Индии, и мы надеемся, что это побудит больше людей творчески применять ИИ, чтобы решать социальные проблемы.
О Wadhwani AI
Институт искусственного интеллекта Wadhwani AI — это независимый некоммерческий исследовательский институт и глобальный центр, разрабатывающий решения на основе искусственного интеллекта на благо общества. В институте используют возможности современного искусственного интеллекта, чтобы решать глобальных задачи. Миссия Wadhwani AI — разработка и применение инноваций и решений на основе ИИ в широком спектре социальных сфер, включая здравоохранение, сельское хозяйство, образование, инфраструктуру и финансовую доступность.
Искусственный интеллект может решить многие задачи, но задачу экономии на обучении — решить можете только вы. А поможет вам в этом специальный промокод HABR, который даст +10% к скидке, указанной на баннере ниже.
- Курс по Machine Learning
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы

Ajex
А можно вот про это подробнее «Далее модель VGGNet обучалась использованию изображений из набора данных COCO в качестве невалидного класса». Т.е. вы обучали модель использую COCO в качестве того, «как не нужно»?
Я вот сейчас делаю некий проект, тоже на одноступенчатом yolo v4, и имею некоторое кол-во изображений, которые бы хотелось скормить сети как «not valid», дабы исключить ложные срабатывания. Но не могу понять как правильно это сделать. Обучить отдельный класс невалидным изображениям?
diogen4212
зашёл на сайт СОСО и задумался, что из этих изображений могло попасть в ловушки…