Как и обещал в предыдущей статье (Что такое Zynq? Краткий обзор), поговорим о передаче данных между процессорным модулем и программируемой логикой. В предыдущей статье упоминалось четыре способа передачи данных, в статье будут рассмотрены два способа, которые нашли большее применение. Подробности под катом. Осторожно, много картинок!
1 Общие сведения
2 Передача данных в режиме PIO
2.1 Аппаратная часть
2.2 Программная часть
2.3 Результаты
3 Передача данных в режиме DMA
3.1 Аппаратная часть
3.2 Программная часть
3.3 Результаты
4 Заключение
5 Используемые источники
В общем случае, передача данных между процессорным модулем и программируемой логикой возможна в двух режимах:
В режиме PIO процессорный модуль работает с программируемой логикой как с набором регистров. Чтобы записать или прочитать определенный объем данных, нужно постоянное участие процессорного модуля. В режиме PIO инициатором всех транзакций является процессорный модуль. Подключение программируемой логики предполагает использование порта GP, где Master это процессорный модуль, Slave – программируемая логика.
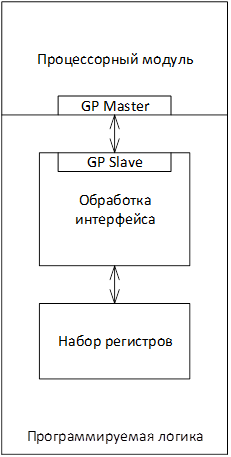
Структура проекта при использовании PIO
Теперь нужно написать приложение, работающее на процессорном модуле, которое будет читать данные из программируемой логики и писать данные в программируемую логику. Необходимо запустить среду разработки Vitis и создать приложение по шаблону Hello World, пример этого показан в предыдущей статье[1].
Адрес созданного ядра для обращения со стороны процессорного модуля можно посмотреть в Vivado. В Flow Navigator => Open Block Design => Вкладка Address Editor. В данном случае адрес равен 0x43C0_0000. По этому адресу расположен регистр, в котором хранится признак, в каком состоянии находятся переключатели. Соответственно, по адресу 0x43C0_0004 расположен регистр, который подключен к светодиодам.
В Vitis откроем файл helloworld.c и заполним:
Где функция Xil_In32 используется для чтения 4х байт данных из программируемой логики, а Xil_Out32 соответственно для записи 4х байт данных в программируемую логику.
Собираем приложение, создаем файл прошивки и заливаем в плату. Описано в предыдущей статье[1].
Запускаем, смотрим в мониторе com-порта:
Все работает корректно.
Таким образом, для доступа в режиме PIO к программируемой логике, необходимо в программируемой логике реализовать один из интерфейсов связи с процессорным модулем, где инициатором является процессорный модуль. Такой интерфейс представлен только портом GP.
Посмотрим, как быстро обрабатываются запросы к программируемой логике через порт GP. Для этого в приложении, работающем на процессорном модуле, добавим подряд несколько записей в регистр в программируемой логике, и измерим время между транзакциями в программируемой логике с помощью вытащенных в отладчик сигналов шины.
Когда шина Axi-Lite работает на частоте 100 МГц, пауза между запросами составляет в среднем 23 такта. Изменим частоту работы шины до 200 МГц. Пауза между запросами становится равной в среднем 33 такта.
Итого, 4 байта данных передаются на частоте 100 МГц 23 такта. Скорость составляет: 32/(23*10нс)= 139 130 434 бит/с ? 135 869 Кбит/с ? 132 Мбит/с ? 16 Мбайт/с.
Итого, 4 байта данных передаются на частоте 200 МГц 33 такта. Скорость составляет 32/(33*5нс)= 193 939 393 бит/с ? 189 393 Кбит/с ? 184 Мбит/с ? 23 Мбайт/с.
Таким образом, можно достичь скорости в 23 Мбайт/с, но при постоянном участии процессорного модуля.
Проект: github.com/Finnetrib/PioTransfer
Передача данных в режиме DMA подразумевает, что процессорный модуль настраивает параметры обмена данными и не участвует непосредственно в обмене. Таким образом, достигается две цели: снижение нагрузки на процессорный модуль и увеличение скорости обработки данных. Платой за это является усложнение аппаратуры.
В Zynq возможно использование нескольких ip-ядер, реализующих функции DMA. В данной статье будет рассмотрено ядро AXI DMA [2].
В AXI DMA есть два канала MM2S и S2MM. Канал MM2S (Memory-mapped to stream) используется для передачи данных из процессорного модуля в программируемую логику. Канал S2MM (Stream to memory-mapped) используется для передачи данных из программируемой логики в процессорный модуль. Каналы работают независимо друг от друга.
AXI DMA подразумевает два варианта использования:
В Direct Register Mode используется один набор регистров, который позволяет передать один буфер из программируемой логики в процессорный модуль и наоборот. Например, для передачи буфера данных из программируемой логики в процессорный модуль, необходимо заполнить поля адреса и размера буфера и запустить DMA. В результате DMA заполнит один буфер в процессорном модуле и остановится.
В Scatter / Gather Mode используется список дескрипторов. DMA обрабатывает буфер, описанный в дескрипторе, и переходит к обработке буфера, описанного в следующем дескрипторе.

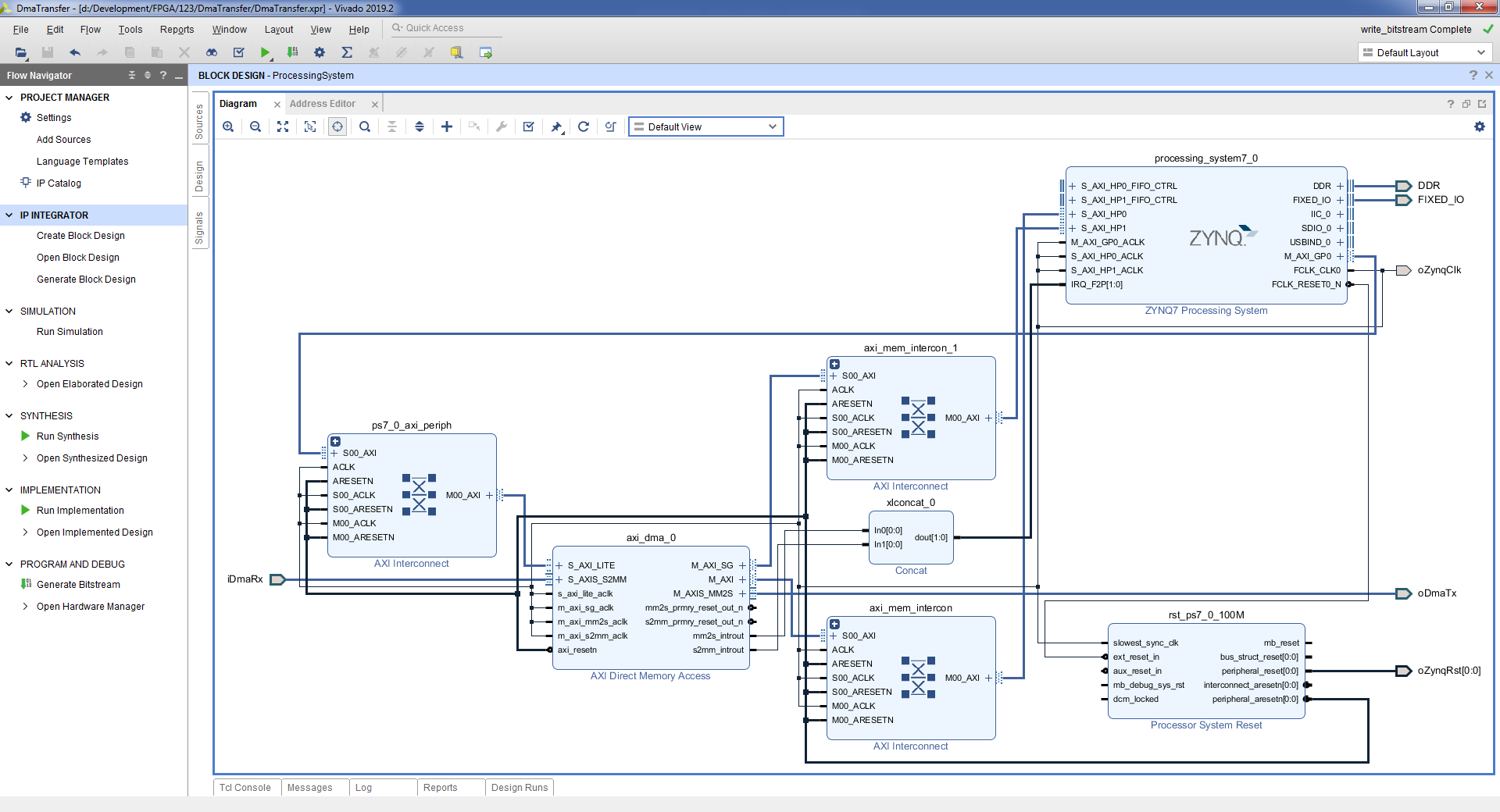
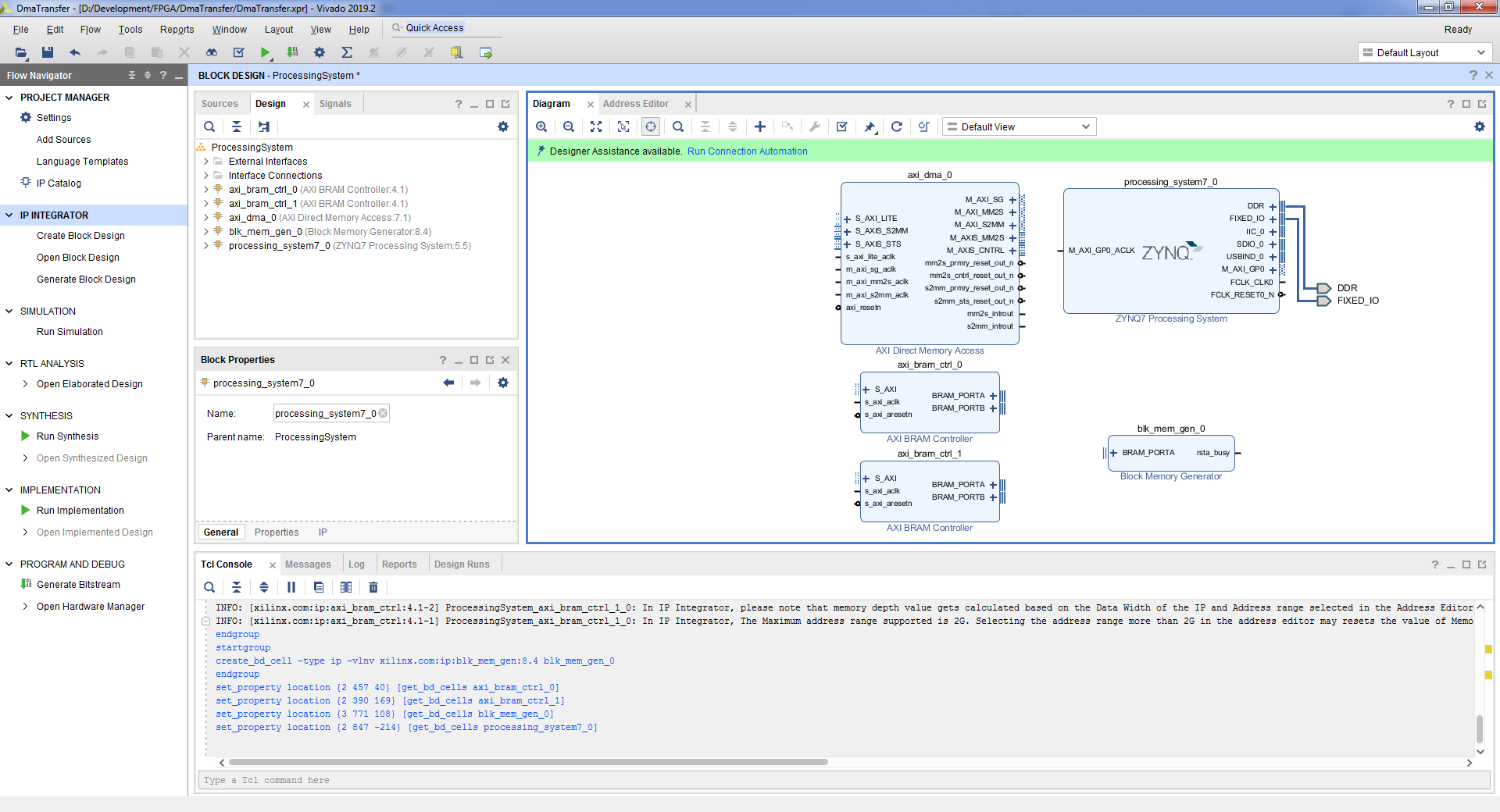
Структура проекта при использовании DMA
Рассмотрим вариант, когда список дескрипторов хранится в программируемой логике. У блока DMA есть порт управления, который подключается к порту GP процессорного модуля. Также имеется порт HP, используемый для обращения к ОЗУ процессорного модуля. Список дескрипторов хранится в памяти дескрипторов. Доступ к памяти дескрипторов возможен как из DMA, так и из процессорного модуля. Процессорный модуль заполняет дескрипторы, DMA вычитывает дескрипторы.
Теперь нужно написать приложение, работающее на процессорном модуле. Необходимо запустить среду разработки Vitis и создать приложение по шаблону Hello World, пример этого показан в предыдущей статье.
Формат дескрипторов для Axi DMA описан в документе на ядро [2]. Дескриптор имеет размер 52 байта, однако, адрес, по которому расположен дескриптор, должен быть выровнен на 64 байта.
Кратко по формату дескриптора:
Адреса в программируемой логике для обращения со стороны процессорного модуля можно посмотреть в Vivado. В Flow Navigator => Open Block Design => Вкладка Address Editor. В данном случае адрес DMA равен 0x4040_0000. Адрес начала области памяти для дескрипторов равен 0x4000_0000.
Собираем приложение, создаем файл прошивки и заливаем в плату. Описано в предыдущей статье[1].
Запускаем, смотрим в мониторе com-порта:
Таким образом, для обмена данными между процессорным модулем и программируемой логикой, в программируемой логике необходимо реализовать один из интерфейсов связи с процессорным модулем, где инициатором является программируемая логика. Такие интерфейсы представлены портами GP, HP, ACP. В предыдущей статье [1] они все были рассмотрены.
Посчитаем скорость передачи данных: (256 раз * 102400 байт) / (271 * 100 мкс) ? 967 321 033 байт/с ? 944 649 Кбайт/с ? 922 Мбайт/с.
Битовая скорость 7 738 568 264 бит/с.
Теоретическая скорость составляет 32 бита * 250 МГц = 8 000 000 000 бит/с.
Также, существует возможность хранить дескрипторы не в памяти программируемой логики, а в оперативной памяти, подключенной к процессорному модулю. В таком случае порт M_AXI_SG подключается к порту HP Zynq.
Рассмотрим первый вариант, когда для доступа DMA к данными и к дескрипторам в оперативной памяти процессорного модуля используются разные порты HP. Модифицируем прошивку в программируемой логике, чтобы получилась следующая схема:
Доступ к данными и дескрипторами через разные порты
Исходный код приложения приводить не будем. Отличия лишь в том, что дескрипторы не нужно копировать в память программируемой логики. Однако, необходимо учесть условие, чтобы адрес каждого дескриптора был выровнен на 64 байта.
После запуска приложения, в мониторе com-порта увидим, что время выполнения копирования буфера данных не поменялось, также 271 * 100 мкс.
Рассмотрим второй вариант, когда для доступа к DMA и к дескрипторам в оперативной памяти процессорного модуля используется один и тот же порт. Модифицируем прошивку в программируемой логике, чтобы получилась следующая схема:

Доступ к данными и дескрипторами через один и тот же порт
Исходный код приложения не поменялся относительно предыдущего варианта.
После запуска приложения, в мониторе com-порта увидим новое время выполнения операции копирования буфера: 398 * 100 мкс.
В результате, скорость обработки составит: (256 раз * 102400 байт) / (398 * 100 мкс) ? 658 653 266 байт/с ? 643 216 Кбайт/с ? 628 Мбайт/с.
Битовая скорость 5 269 226 128 бит/с.
Проект: github.com/Finnetrib/DmaTransfer
В этой статье мы рассмотрели два реализации обмена данными между процессорным модулем и программируемой логикой. Режим PIO прост в реализации и позволяет получить скорость до 23 Мбайт/с, режим DMA несколько посложнее, но и скорость выше — до 628 Мбайт/с.
Содержание
1 Общие сведения
2 Передача данных в режиме PIO
2.1 Аппаратная часть
2.2 Программная часть
2.3 Результаты
3 Передача данных в режиме DMA
3.1 Аппаратная часть
3.2 Программная часть
3.3 Результаты
4 Заключение
5 Используемые источники
1 Общие сведения
В общем случае, передача данных между процессорным модулем и программируемой логикой возможна в двух режимах:
- PIO, используется порт GP.
- DMA, используется порт HP.
2 Передача данных в режиме PIO
В режиме PIO процессорный модуль работает с программируемой логикой как с набором регистров. Чтобы записать или прочитать определенный объем данных, нужно постоянное участие процессорного модуля. В режиме PIO инициатором всех транзакций является процессорный модуль. Подключение программируемой логики предполагает использование порта GP, где Master это процессорный модуль, Slave – программируемая логика.
Структура проекта при использовании PIO
2.1 Аппаратная часть
- Создаем проект для Zybo в Vivado, тип микросхемы xc7z010clg400-1.
- Создаем block design. Во Flow Navigator => Create Block Design => имя «ProcessingSystem» => OK.
- Используя кнопку «+» на поле или сочетания клавиш Ctrl + I добавим процессорное ядро.
- Подключим необходимые выводы, нажав кнопку «Run Block Automation» => OK.
- Импортируем настройки процессорного модуля. Для этого выполним двойной клик на Zynq7 Processing System => Import XPS Setting => Укажем путь к файлу => OK => OK.
- Создаем периферийное ядро, которое будет реализовывать доступ к регистрам в программируемой логике. Tools => Create and Package New IP => Next => Create a new AXI4 peripheral => Next => Задаем имя ядра, например «PIO_registers» и указываем путь к каталогу для сохранения => Next => В этом окне можно выбрать количество регистров (4 хватит), тип интерфейса, в данном случае это Lite => Next => Add IP to the repository => Finish.
- После этих действий, созданное ядро появится в списке доступных для работы в IP каталоге. Можно его увидеть, если выбрать в Flow Navigator => IP Catalog.

- Добавим созданное ядро на рабочую область. Ctrl + I => PIO_registers.
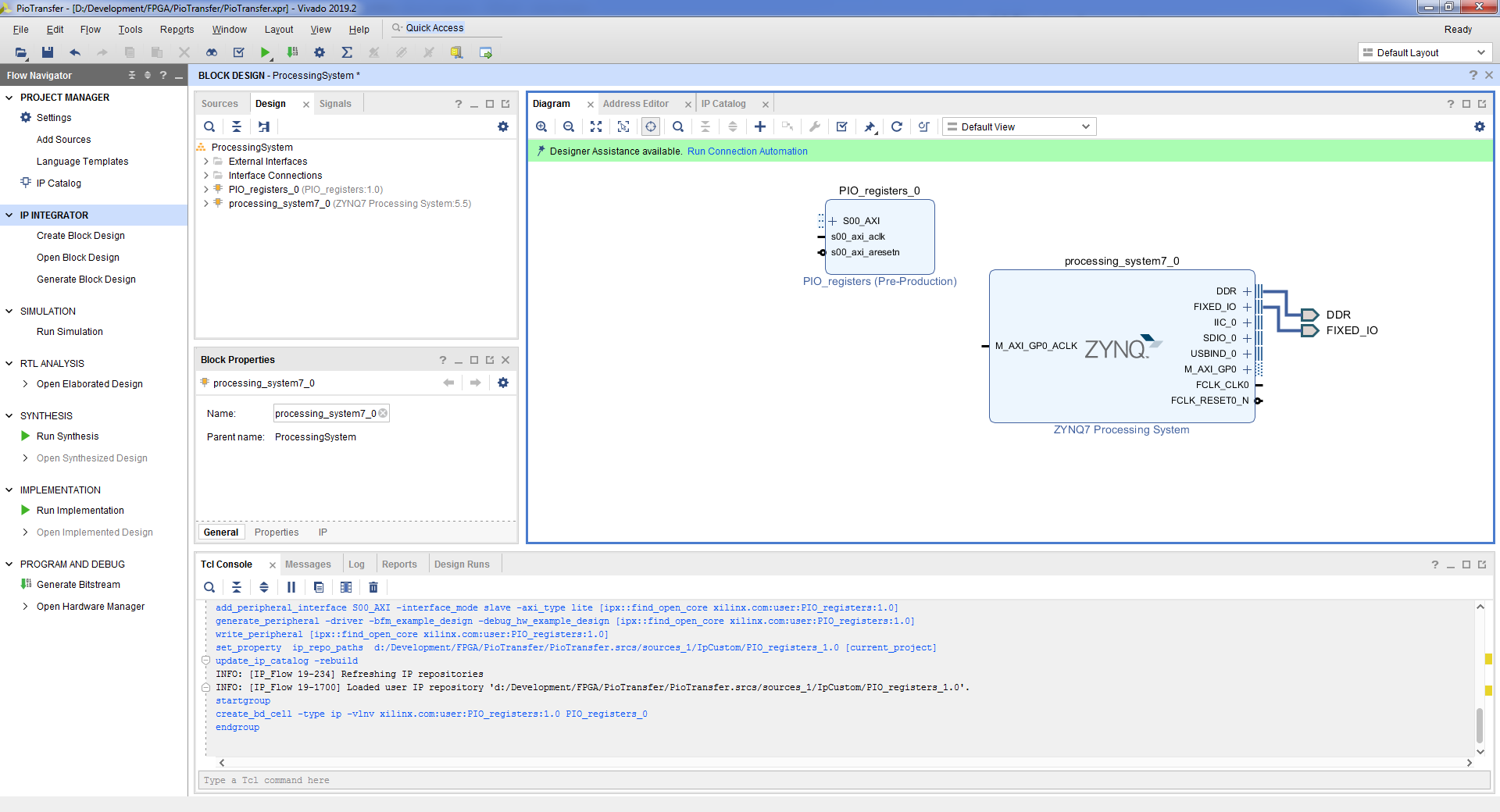
- Отредактируем созданное ядро, добавив в него работу с перемычками и светодиодами. Для этого на блоке PIO_registers правой кнопкой мыши => Edit in IP Packager => OK. Откроется новое окно Vivado с созданным ядром.
- В файле PIO_registers_v1_0.vhd добавим входные и выходные порты и подключим их к внутреннему модулю:
iSwitches : in std_logic_vector( 3 downto 0); oLeds : out std_logic_vector( 3 downto 0); ... iSwitches => iSwitches, oLeds => oLeds,
- В файле PIO_registers_v1_0_S_AXI.vhd добавим входные и выходные порты:
iSwitches : in std_logic_vector( 3 downto 0); oLeds : out std_logic_vector( 3 downto 0);
- Опишем обработку входов и выходов:
signal SwitchesReg : std_logic_vector(31 downto 0); ... process (SwitchesReg, slv_reg1, slv_reg2, slv_reg3, axi_araddr, S_AXI_ARESETN, slv_reg_rden) variable loc_addr :std_logic_vector(OPT_MEM_ADDR_BITS downto 0); begin -- Address decoding for reading registers loc_addr := axi_araddr(ADDR_LSB + OPT_MEM_ADDR_BITS downto ADDR_LSB); case loc_addr is when b"00" => reg_data_out <= SwitchesReg; when b"01" => reg_data_out <= slv_reg1; when b"10" => reg_data_out <= slv_reg2; when b"11" => reg_data_out <= slv_reg3; when others => reg_data_out <= (others => '0'); end case; end process; process (S_AXI_ACLK) begin if (rising_edge(S_AXI_ACLK)) then if (S_AXI_ARESETN = '0') then SwitchesReg <= (others => '0'); else SwitchesReg( 3 downto 0) <= iSwitches; end if; end if; end process; process (S_AXI_ACLK) begin if (rising_edge(S_AXI_ACLK)) then if (S_AXI_ARESETN = '0') then oLeds <= (others => '0'); else oLeds <= slv_reg1( 3 downto 0); end if; end if; end process;
- Сохраняем vhd файлы, открываем вкладку Package IP – PIO_registers. Обновим ядро с учетом изменённых файлов. Вкладка Compatibility меняем Life Cycle на Production. Вкладка File Groups => Merge changes from File Group Wizard. Вкладка Customization Parameters => Merge changes from Customization Parameters Wizard. Вкладка Review and Package => Re-Package IP => Yes. Vivado с созданным ядром закроется.
- В окне Block Design выбираем Report IP Status, в появившимся внизу окне выбираем Upgrade Selected => OK => Skip => OK.
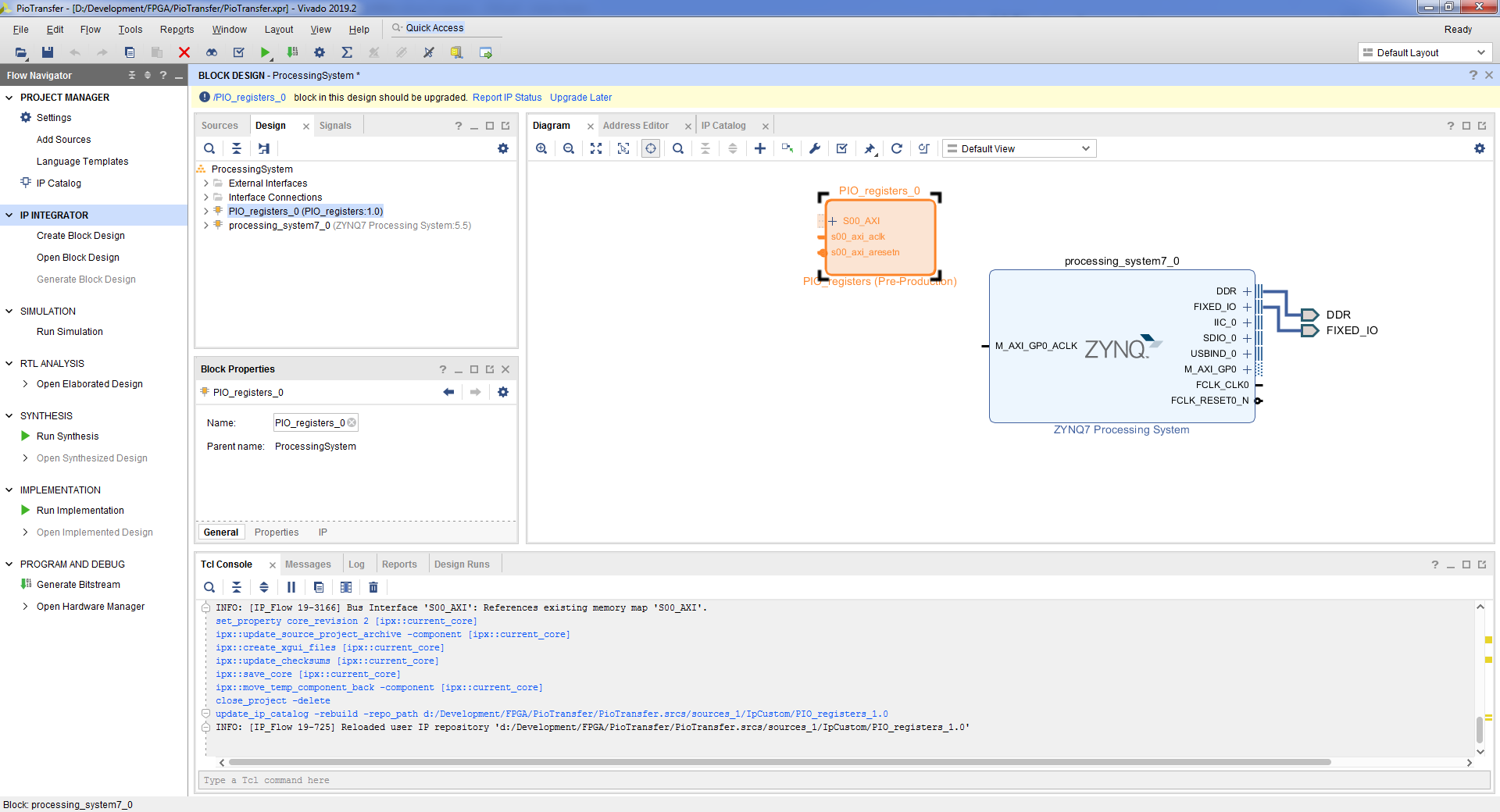
- Подключим созданное ядро к процессору. Для этого нажимаем Run Connection Automation => OK.

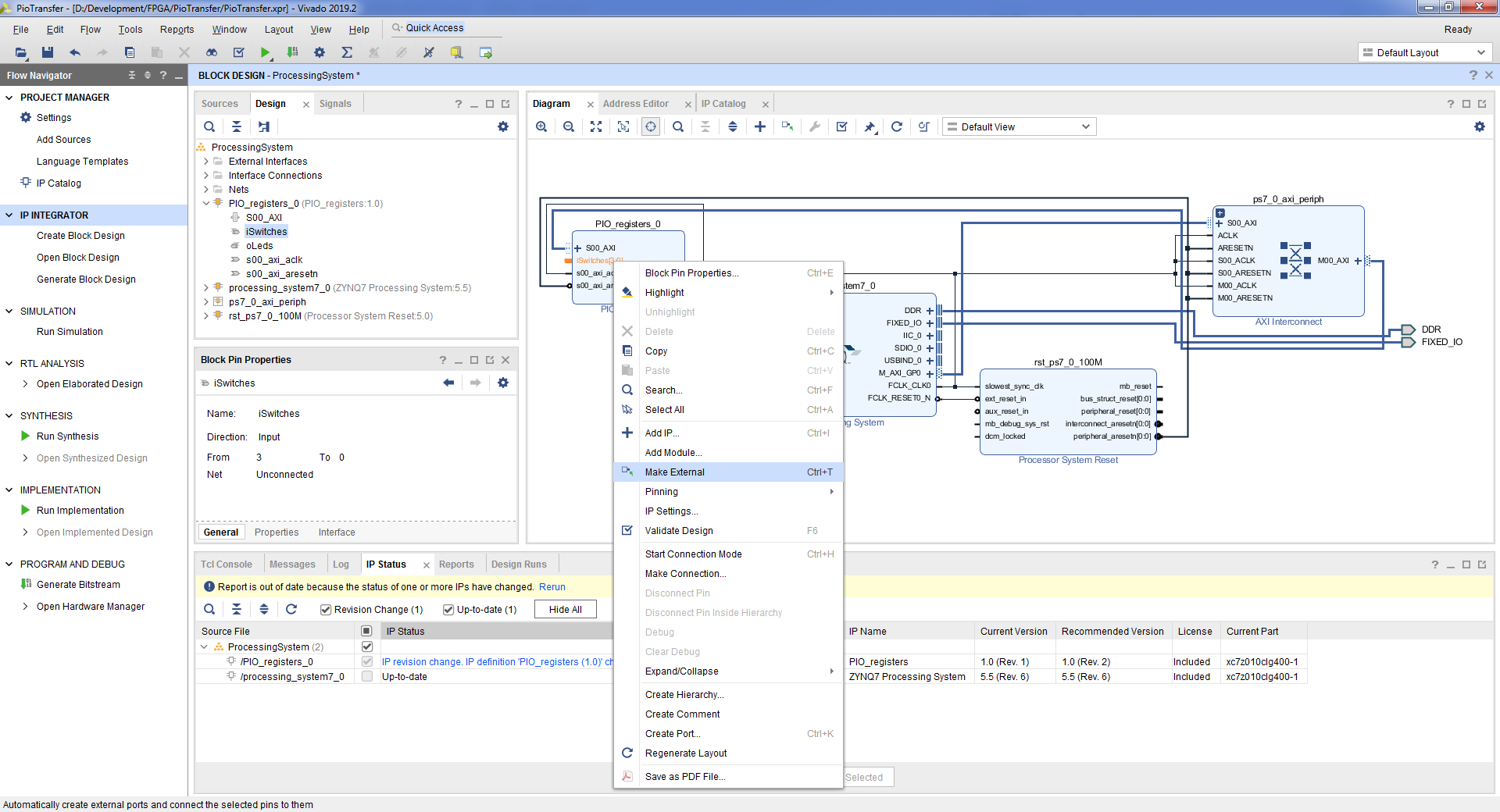
- Подключим порты созданного ядра к портам block design’a. Для этого выделяем порт, нажимаем правую кнопку => Make External.
- Переименуем полученные порты для удобства подключения iSwitches_0 => iSwitches. oLeds_0 => oLeds.
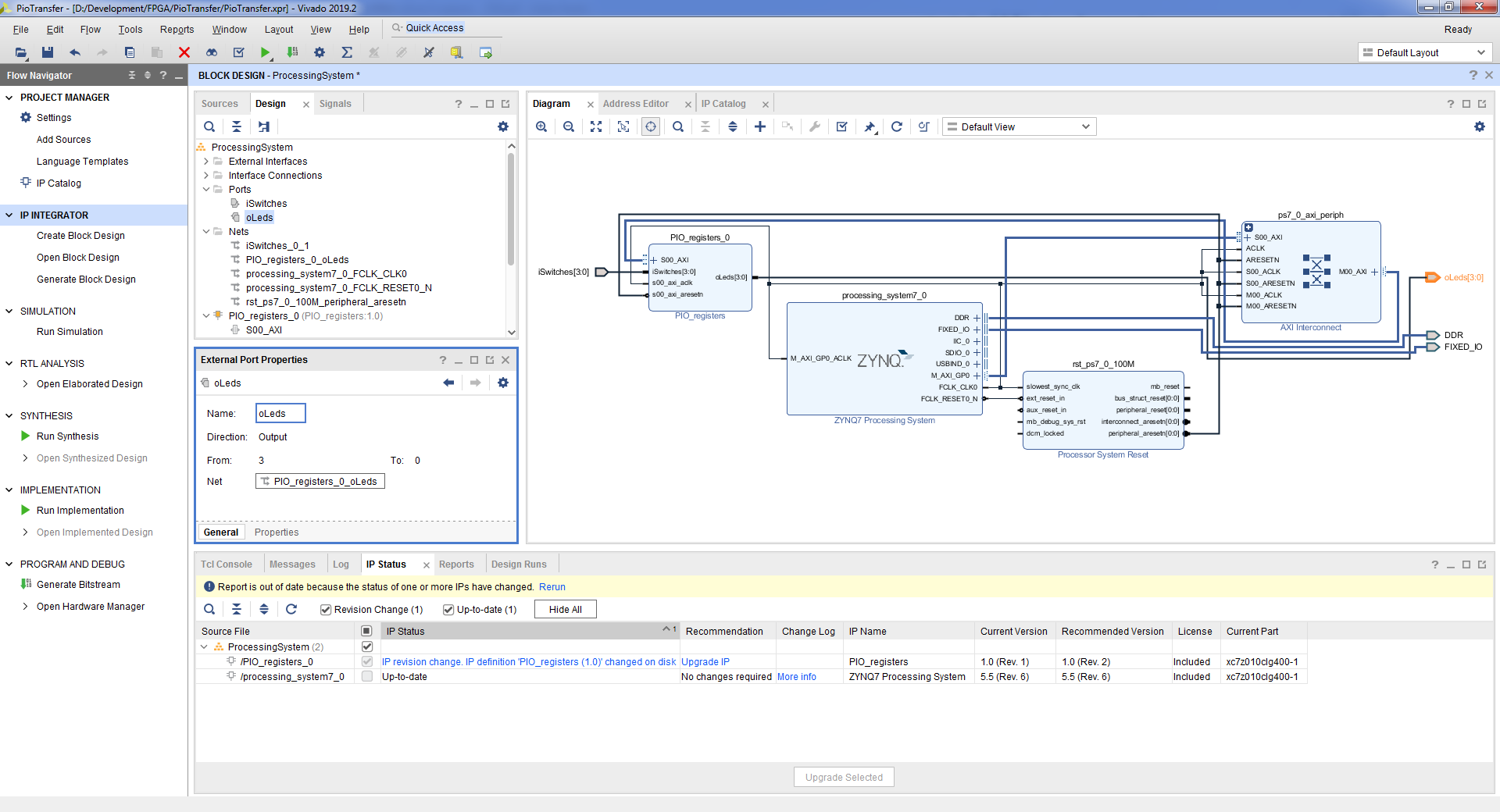
- Проверим полученный дизайн => Tools => Validate Design => Ok.
- File => Save Block Design.
- Переключаемся из режима работы с block design в режим работы с проектом, нажав во Flow Navigator => Project Manager.
- Смотрим, как описаны порты у полученного block design’a. Для этого выбраем файл ProcessingSystem.bd, правой кнопкой => View Instantiation Template.

- Создаем vhd файл top-уровня и подключаем в нем полученный block design. File => Add Sources => Add or create design sources => Next => Create File => вводим имя файла и указываем путь до каталога => OK => Finish => OK => Yes.
- Заполняем файл:
entity PioTransfer is port ( DDR_addr : inout std_logic_vector(14 downto 0 ); DDR_ba : inout std_logic_vector( 2 downto 0 ); DDR_cas_n : inout std_logic; DDR_ck_n : inout std_logic; DDR_ck_p : inout std_logic; DDR_cke : inout std_logic; DDR_cs_n : inout std_logic; DDR_dm : inout std_logic_vector( 3 downto 0 ); DDR_dq : inout std_logic_vector(31 downto 0 ); DDR_dqs_n : inout std_logic_vector( 3 downto 0 ); DDR_dqs_p : inout std_logic_vector( 3 downto 0 ); DDR_odt : inout std_logic; DDR_ras_n : inout std_logic; DDR_reset_n : inout std_logic; DDR_we_n : inout std_logic; FIXED_IO_ddr_vrn : inout std_logic; FIXED_IO_ddr_vrp : inout std_logic; FIXED_IO_mio : inout std_logic_vector( 53 downto 0 ); FIXED_IO_ps_clk : inout std_logic; FIXED_IO_ps_porb : inout std_logic; FIXED_IO_ps_srstb : inout std_logic; -- Control iSwitches : in std_logic_vector( 3 downto 0 ); oLeds : out std_logic_vector( 3 downto 0 ) ); end PioTransfer; architecture Behavioral of PioTransfer is begin PS : entity WORK.ProcessingSystem port map ( DDR_addr => DDR_addr, DDR_ba => DDR_ba, DDR_cas_n => DDR_cas_n, DDR_ck_n => DDR_ck_n, DDR_ck_p => DDR_ck_p, DDR_cke => DDR_cke, DDR_cs_n => DDR_cs_n, DDR_dm => DDR_dm, DDR_dq => DDR_dq, DDR_dqs_n => DDR_dqs_n, DDR_dqs_p => DDR_dqs_p, DDR_odt => DDR_odt, DDR_ras_n => DDR_ras_n, DDR_reset_n => DDR_reset_n, DDR_we_n => DDR_we_n, FIXED_IO_ddr_vrn => FIXED_IO_ddr_vrn, FIXED_IO_ddr_vrp => FIXED_IO_ddr_vrp, FIXED_IO_mio => FIXED_IO_mio, FIXED_IO_ps_clk => FIXED_IO_ps_clk, FIXED_IO_ps_porb => FIXED_IO_ps_porb, FIXED_IO_ps_srstb => FIXED_IO_ps_srstb, -- Control iSwitches => iSwitches, oLeds => oLeds ); end Behavioral;
- Добавляем используемые входы и выходы в файл пользовательских ограничений. File => Add sources => Add or create constrains => Next => Create File => вводим имя файла и указываем путь до каталога => OK => Finish.
- Заполняем файл согласно принципиальной схеме:
#Switches set_property PACKAGE_PIN G15 [get_ports {iSwitches[0]}] set_property PACKAGE_PIN P15 [get_ports {iSwitches[1]}] set_property PACKAGE_PIN W13 [get_ports {iSwitches[2]}] set_property PACKAGE_PIN T16 [get_ports {iSwitches[3]}] set_property IOSTANDARD LVCMOS33 [get_ports {iSwitches[*]}] #LEDs #IO_L23P_T3_35 set_property PACKAGE_PIN M14 [get_ports {oLeds[0]}] set_property PACKAGE_PIN M15 [get_ports {oLeds[1]}] set_property PACKAGE_PIN G14 [get_ports {oLeds[2]}] set_property PACKAGE_PIN D18 [get_ports {oLeds[3]}] set_property IOSTANDARD LVCMOS33 [get_ports {oLeds[*]}]
- Соберем проект. Для этого во Flow Navigator => Generate Bitstream => OK. Появившиеся окно, что создание прошивки успешно завершено, закрываем.
- Экспортируем полученные файлы для разработки приложения на процессорном модуле. Для этого выбираем File => Export => Export Hardware => вводим имя файла и указываем путь до каталога => OK. Получаем на выходе файл .xsa
2.2 Программная часть
Теперь нужно написать приложение, работающее на процессорном модуле, которое будет читать данные из программируемой логики и писать данные в программируемую логику. Необходимо запустить среду разработки Vitis и создать приложение по шаблону Hello World, пример этого показан в предыдущей статье[1].
Адрес созданного ядра для обращения со стороны процессорного модуля можно посмотреть в Vivado. В Flow Navigator => Open Block Design => Вкладка Address Editor. В данном случае адрес равен 0x43C0_0000. По этому адресу расположен регистр, в котором хранится признак, в каком состоянии находятся переключатели. Соответственно, по адресу 0x43C0_0004 расположен регистр, который подключен к светодиодам.
В Vitis откроем файл helloworld.c и заполним:
int main()
{
init_platform();
u32 Status = 0x00;
u32 Command = 0x00;
xil_printf("Hello World\n\r");
while (1)
{
Status = Xil_In32(0x43C00000);
xil_printf("Status %x\n\r", Status);
if (Status == 0x01 || Status == 0x02 || Status == 0x04 || Status == 0x08)
{
Command = 0x01;
}
else if (Status == 0x03 || Status == 0x5 || Status == 0x06 || Status == 0x9 || Status == 0xA || Status == 0x0C)
{
Command = 0x03;
}
else if (Status == 0x7 || Status == 0x0B || Status == 0x0D || Status == 0x0E)
{
Command = 0x7;
}
else if (Status == 0x0F)
{
Command = 0x0F;
}
else
{
Command = 0x00;
}
xil_printf("Command %x\n\r", Command);
Xil_Out32(0x43C00004, Command);
usleep(1000000);
}
cleanup_platform();
return 0;
} Где функция Xil_In32 используется для чтения 4х байт данных из программируемой логики, а Xil_Out32 соответственно для записи 4х байт данных в программируемую логику.
2.3 Результаты
Собираем приложение, создаем файл прошивки и заливаем в плату. Описано в предыдущей статье[1].
Запускаем, смотрим в мониторе com-порта:
Xilinx First Stage Boot Loader
Release 2019.2 Dec 9 2020-15:16:52
Silicon Version 3.1
Boot mode is QSPI
SUCCESSFUL_HANDOFF
FSBL Status = 0x1
Hello World
Status 0
Command 0
Status 8
Command 1
Status C
Command 3
Status D
Command 7
Status F
Command F
Все работает корректно.
Таким образом, для доступа в режиме PIO к программируемой логике, необходимо в программируемой логике реализовать один из интерфейсов связи с процессорным модулем, где инициатором является процессорный модуль. Такой интерфейс представлен только портом GP.
Посмотрим, как быстро обрабатываются запросы к программируемой логике через порт GP. Для этого в приложении, работающем на процессорном модуле, добавим подряд несколько записей в регистр в программируемой логике, и измерим время между транзакциями в программируемой логике с помощью вытащенных в отладчик сигналов шины.
Когда шина Axi-Lite работает на частоте 100 МГц, пауза между запросами составляет в среднем 23 такта. Изменим частоту работы шины до 200 МГц. Пауза между запросами становится равной в среднем 33 такта.
Итого, 4 байта данных передаются на частоте 100 МГц 23 такта. Скорость составляет: 32/(23*10нс)= 139 130 434 бит/с ? 135 869 Кбит/с ? 132 Мбит/с ? 16 Мбайт/с.
Итого, 4 байта данных передаются на частоте 200 МГц 33 такта. Скорость составляет 32/(33*5нс)= 193 939 393 бит/с ? 189 393 Кбит/с ? 184 Мбит/с ? 23 Мбайт/с.
Таким образом, можно достичь скорости в 23 Мбайт/с, но при постоянном участии процессорного модуля.
Проект: github.com/Finnetrib/PioTransfer
3 Передача данных в режиме DMA
Передача данных в режиме DMA подразумевает, что процессорный модуль настраивает параметры обмена данными и не участвует непосредственно в обмене. Таким образом, достигается две цели: снижение нагрузки на процессорный модуль и увеличение скорости обработки данных. Платой за это является усложнение аппаратуры.
В Zynq возможно использование нескольких ip-ядер, реализующих функции DMA. В данной статье будет рассмотрено ядро AXI DMA [2].
В AXI DMA есть два канала MM2S и S2MM. Канал MM2S (Memory-mapped to stream) используется для передачи данных из процессорного модуля в программируемую логику. Канал S2MM (Stream to memory-mapped) используется для передачи данных из программируемой логики в процессорный модуль. Каналы работают независимо друг от друга.
AXI DMA подразумевает два варианта использования:
- Direct Register Mode
- Scatter / Gather Mode
В Direct Register Mode используется один набор регистров, который позволяет передать один буфер из программируемой логики в процессорный модуль и наоборот. Например, для передачи буфера данных из программируемой логики в процессорный модуль, необходимо заполнить поля адреса и размера буфера и запустить DMA. В результате DMA заполнит один буфер в процессорном модуле и остановится.
В Scatter / Gather Mode используется список дескрипторов. DMA обрабатывает буфер, описанный в дескрипторе, и переходит к обработке буфера, описанного в следующем дескрипторе.
3.1 Аппаратная часть
Структура проекта при использовании DMA
Рассмотрим вариант, когда список дескрипторов хранится в программируемой логике. У блока DMA есть порт управления, который подключается к порту GP процессорного модуля. Также имеется порт HP, используемый для обращения к ОЗУ процессорного модуля. Список дескрипторов хранится в памяти дескрипторов. Доступ к памяти дескрипторов возможен как из DMA, так и из процессорного модуля. Процессорный модуль заполняет дескрипторы, DMA вычитывает дескрипторы.
- Создаем block design. Во Flow Navigator => Create Block Design => имя «ProcessingSystem» => OK.
- Используя кнопку «+» на поле или сочетания клавиш Ctrl + I добавим процессорное ядро.
- Подключим необходимые выводы, нажав кнопку «Run Block Automation» => OK.
- Импортируем настройки процессорного модуля. Для этого выполним двойной клик на Zynq7 Processing System => Import XPS Setting => Укажем путь к файлу => OK => OK
- Добавим на поле одно ядро AXI Direct Memory Access, два ядра AXI BRAM Controller, одно ядро Block Memory Generator.
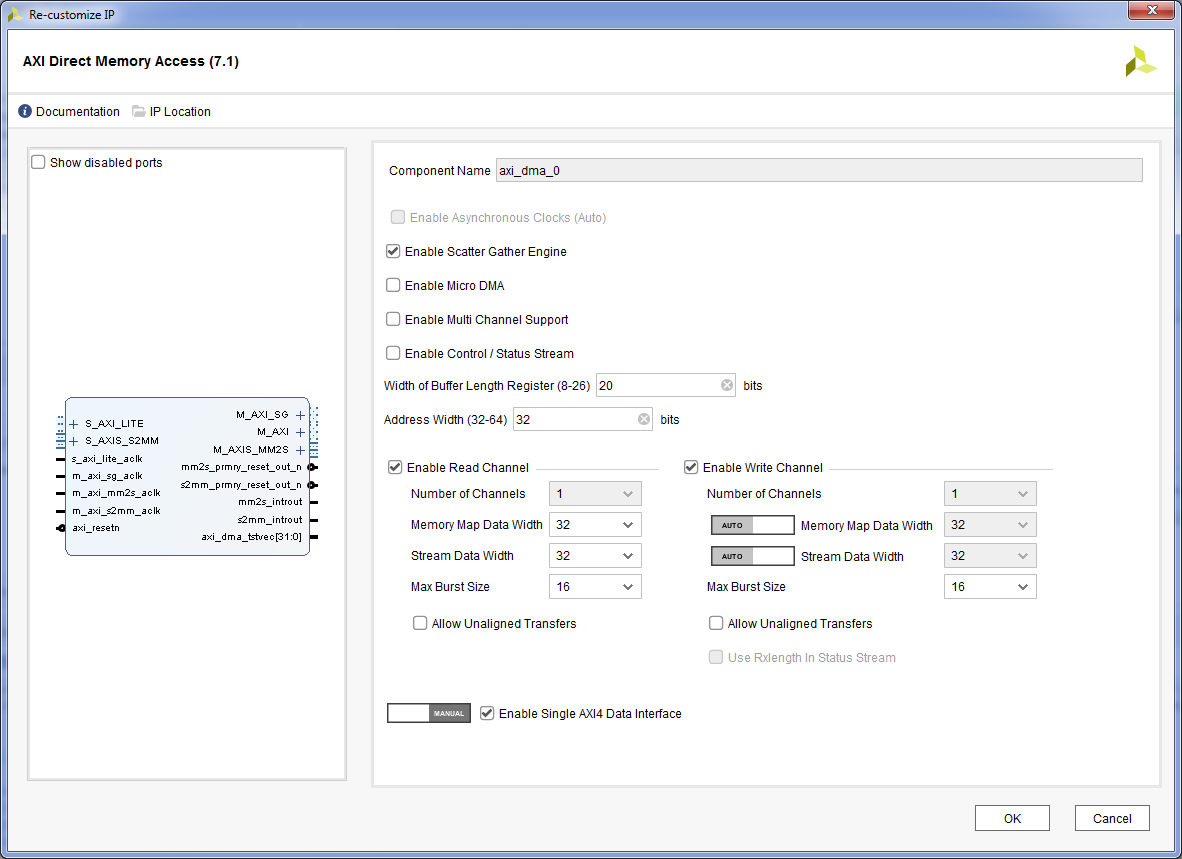
- Двойной клик на ядре AXI Direct Memory Access, настроим ядро. Галка «Enable Scatter Gather Engine» включит режим работы по списком дескрипторов, оставляем. Галка «Enable Control / Status Stream» используется для работы совместно с ядром AXI Ethernet, снимаем. Поле «With of Buffer Length Register» задает количество разрядов, используемых при обработке размера буфера. Запишем в поле число 20, что даст максимальный размер буфера в 2^20 = 1 048 576 байт. Поле «Address With» задает разрядность адреса. Значения в 32 будет достаточно. Галки «Enable Read Channel» и «Enable Write Channel» позволяют включить каждый из каналов независимо друг от друга. Переключатель «Enable Single AXI4 Data interface» позволяет сократить количество линий связи на диаграмме, поэтому включим его. Нажимаем «OK» после настройки.
- Двойной клик на ядре AXI BRAM Controller. В поле «Number of BRAM Interfaces» выбираем значение 1. Нажимаем «OK» после настройки.
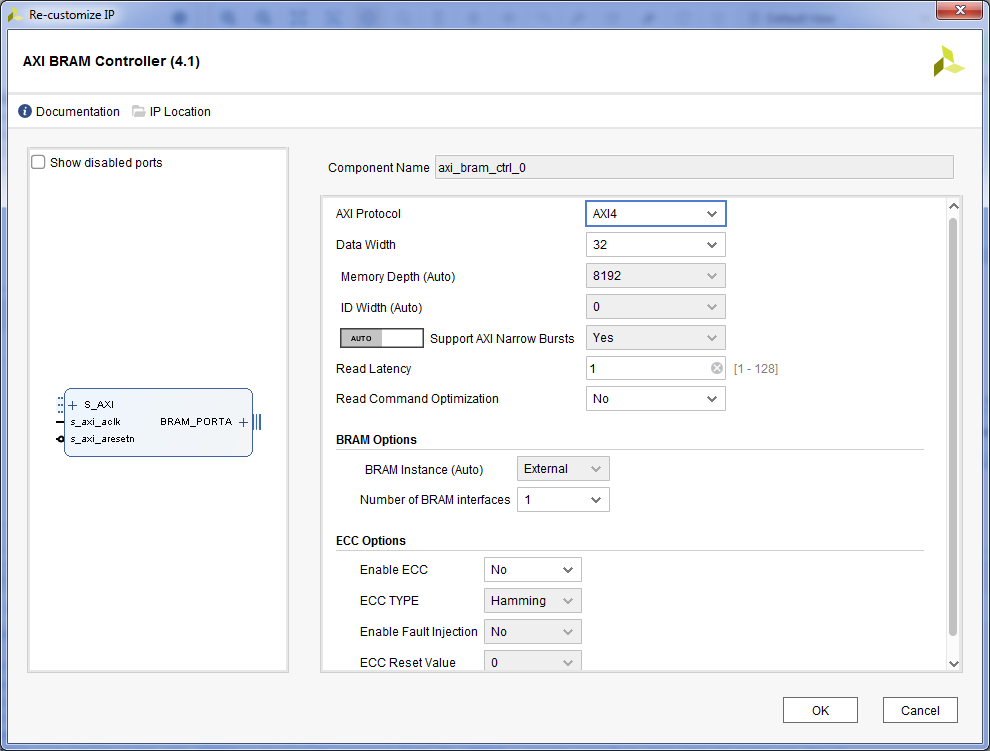
- Повторяем для второго ядра AXI BRAM Controller.
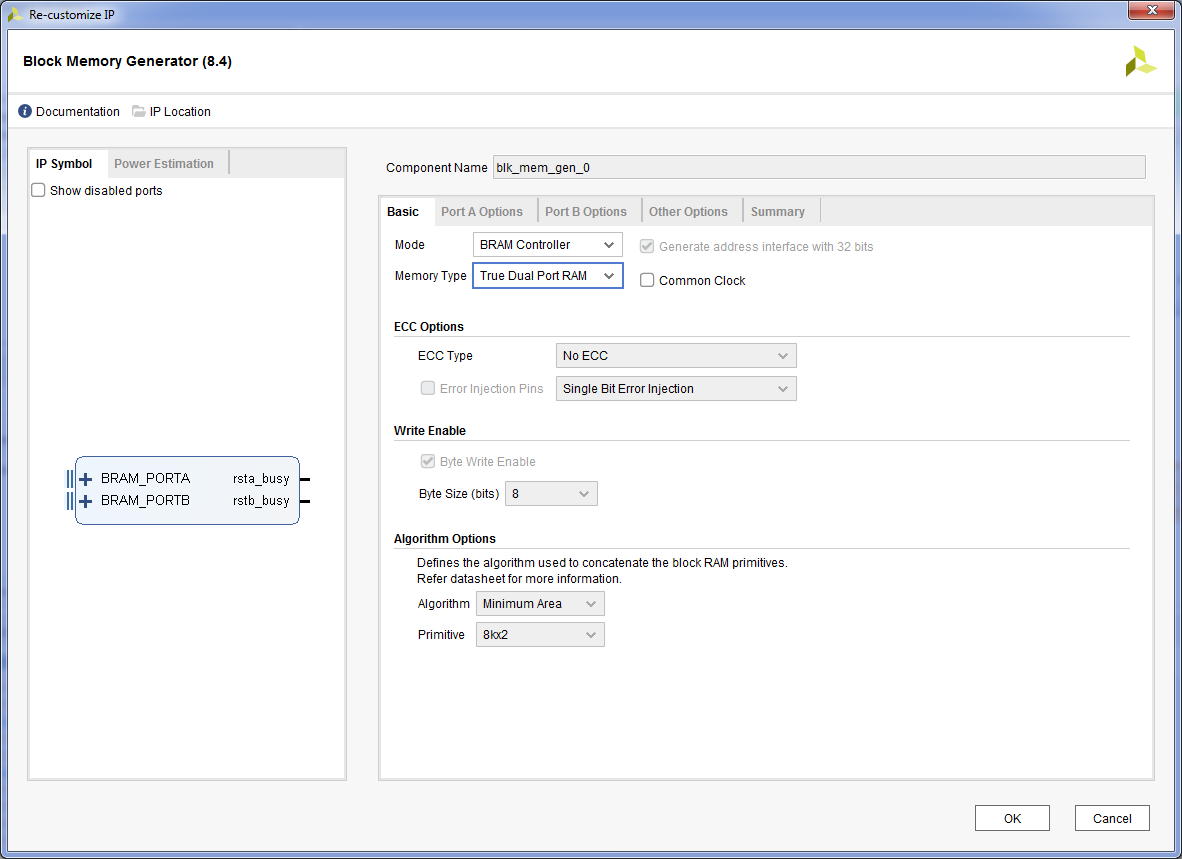
- Двойной клик на ядре Block Memory Generator. В поле «Memory Type» выбираем «True Dual Port RAM». Нажимаем «OK» после настройки.
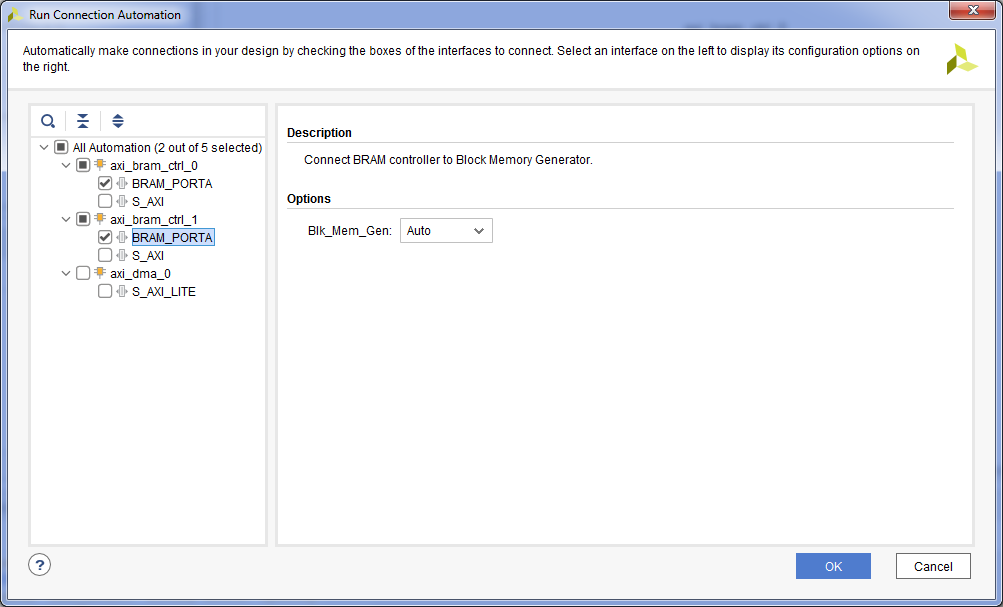
- Подключим полученный блок памяти к контроллерам памяти. Для этого нажимаем «Run Connection Automation» => Галку на axi_bram_ctrl_0 BRAM_PORTA => Галку на axi_bram_ctrl_1 BRAM_PORTA => OK.
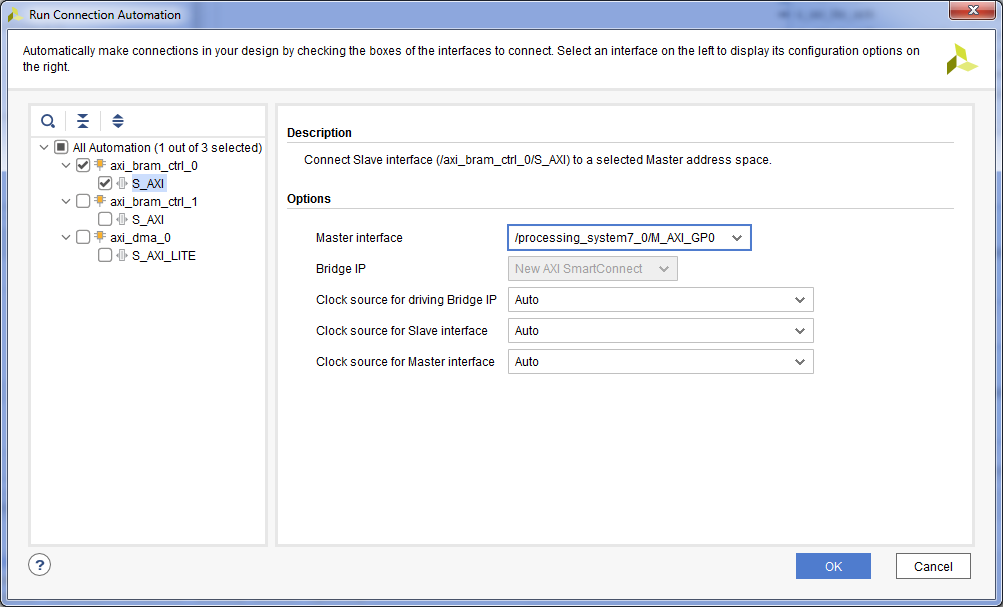
- Подключим нулевой контроллер памяти к процессорному модулю. Для этого нажимаем «Run Connection Automation» => Галку на axi_bram_ctrl_0 S_AXI => Выбрать Master Interface /processing_system7_0/M_AXI_GP0 => OK. Таким образом, процессорный модуль получит доступ к памяти дескрипторов.
- Подключим первый контроллер памяти к ядру DMA. Для этого нажимаем «Run Connection Automation» => Галку на axi_bram_ctrl_1 S_AXI => Выбрать Master Interface /axi_dma_0/M_AXI_SG => OK. Таким образом, DMA контроллер также получит доступ к памяти дескрипторов.
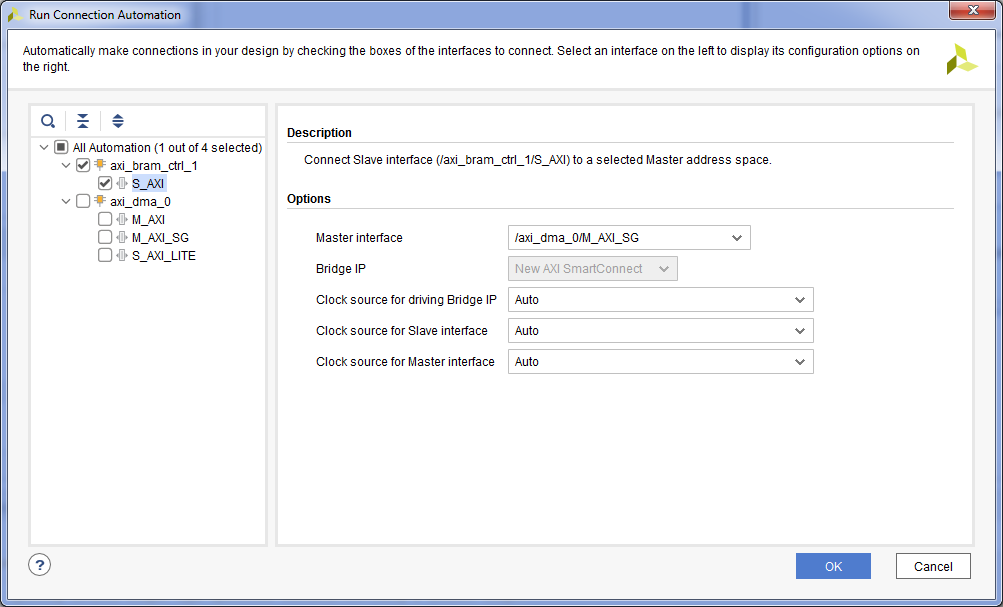
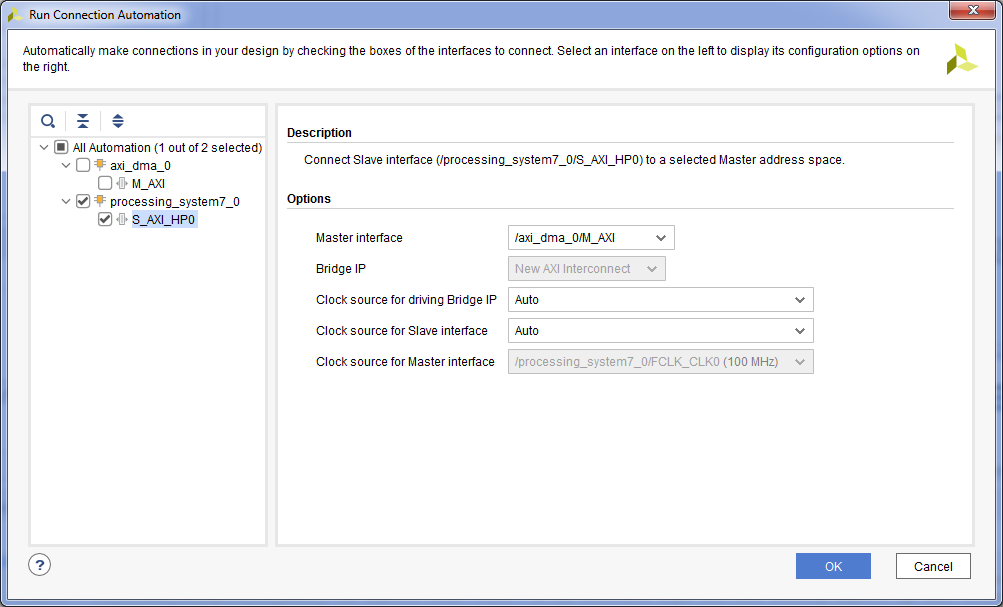
- Подключим управление DMA к процессорному модулю. Для этого нажимаем «Run Connection Automation» => Галку на axi_dma_0 S_AXI_LITE => OK.
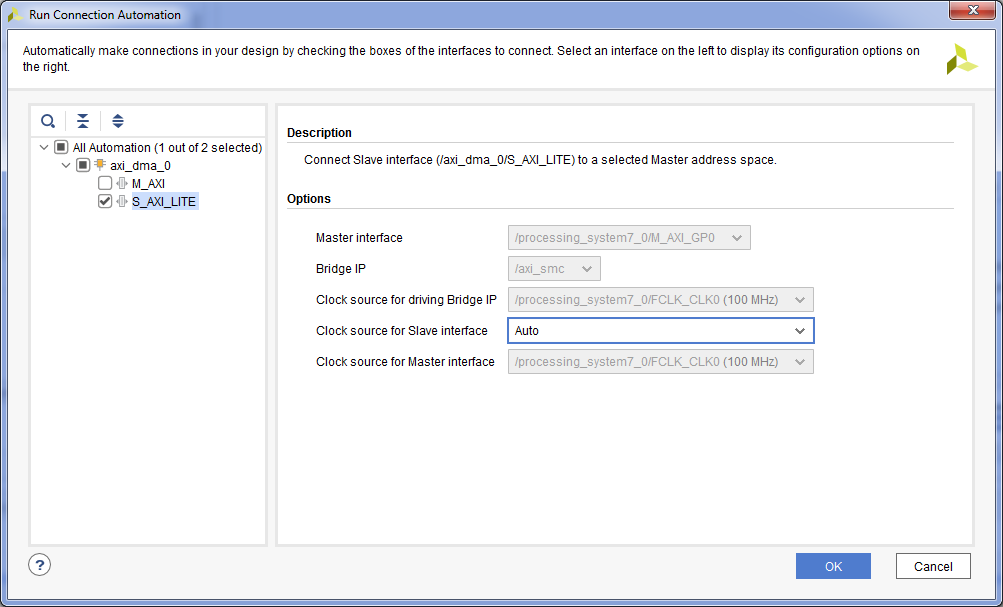
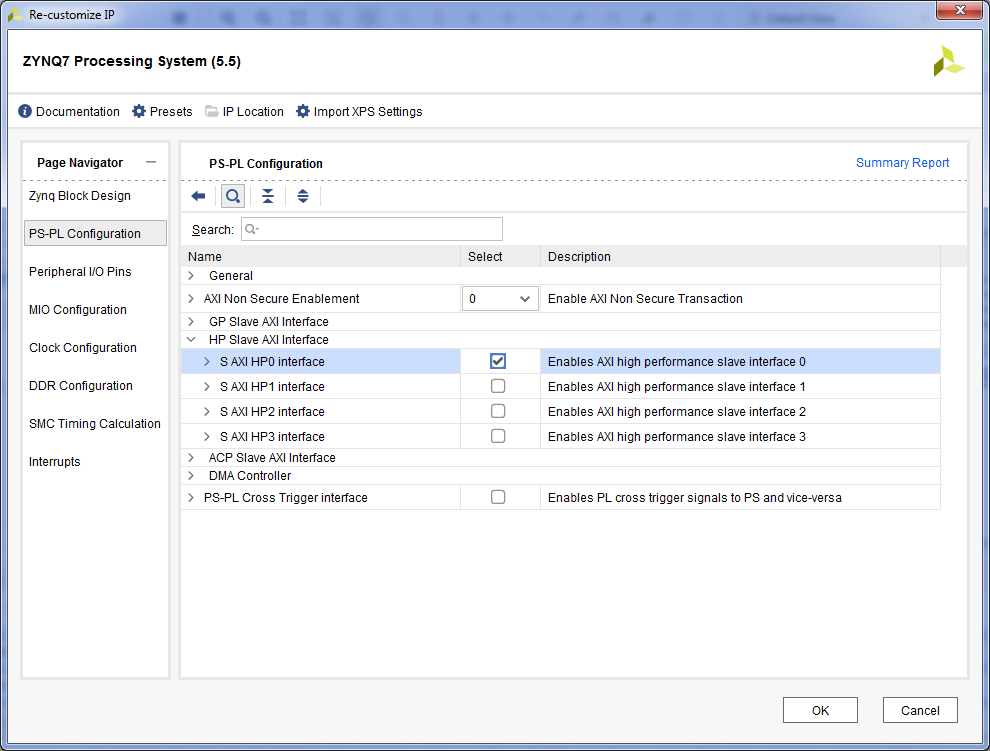
- Включим в процессорном модуле порт для доступа к оперативной памяти процессорного модуля – HP и прерывания из программируемой логики. Для этого двойной клик на ядре Zynq7 Processing System => Вкладка PS-PL Configuration => Развернем HP Slave AXI Interface => Галку на S AXI HP0 Interface.
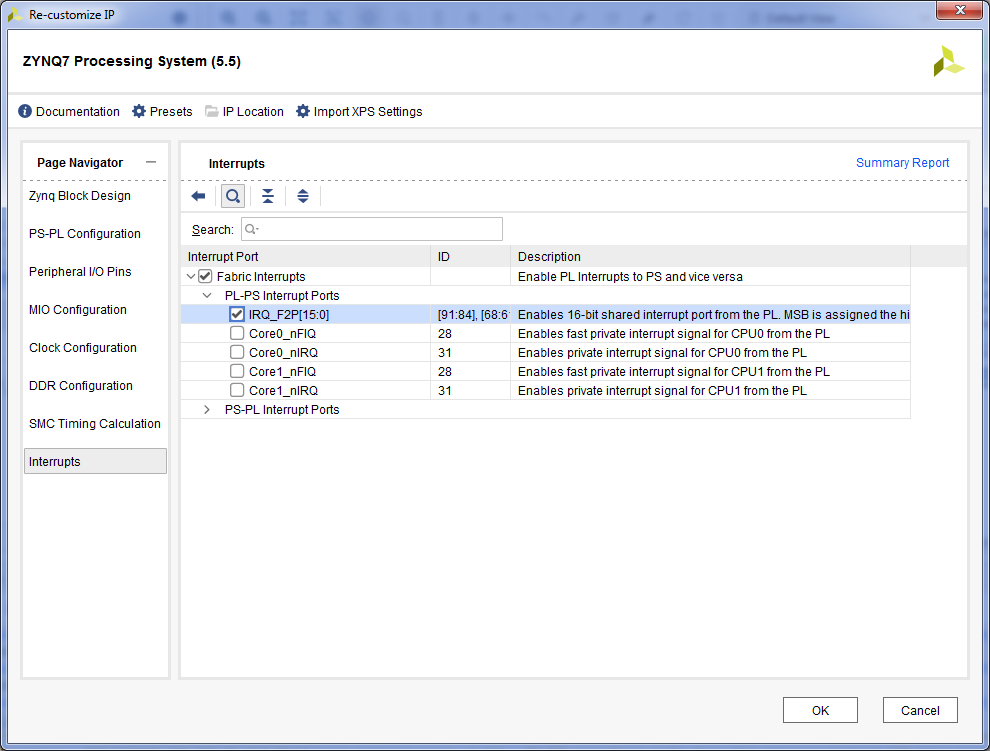
Вкладка Interrupts => Развернем Fabric Interrupts => Развернуть PL-PS Interrupts Ports => Галку на Fabric Interrupts => Галку на IRQ_F2P => OK.
- Подключим DMA к порту для доступа к оперативной памяти. Для этого нажимаем «Run Connection Automation» => Галку на processing_system7_0 S_AXI_HP0 => Выбираем Master Interface /axi_dma_0/M_AXI => OK.
- Подключим прерывания от DMA к процессорному модулю. Для этого добавим на поле блок Concat через кнопку + или сочетание клавиш Ctrl + I.
- Наведем курсор на вывод mm2s_introut DMA, курсор примет форму карандаша. Кликаем на вывод mm2s_introut и не отпуская кнопку мыши тянем линию к входу In0 блока Concat. Доводим до блока, после появления зеленой галочки, отпускаем.
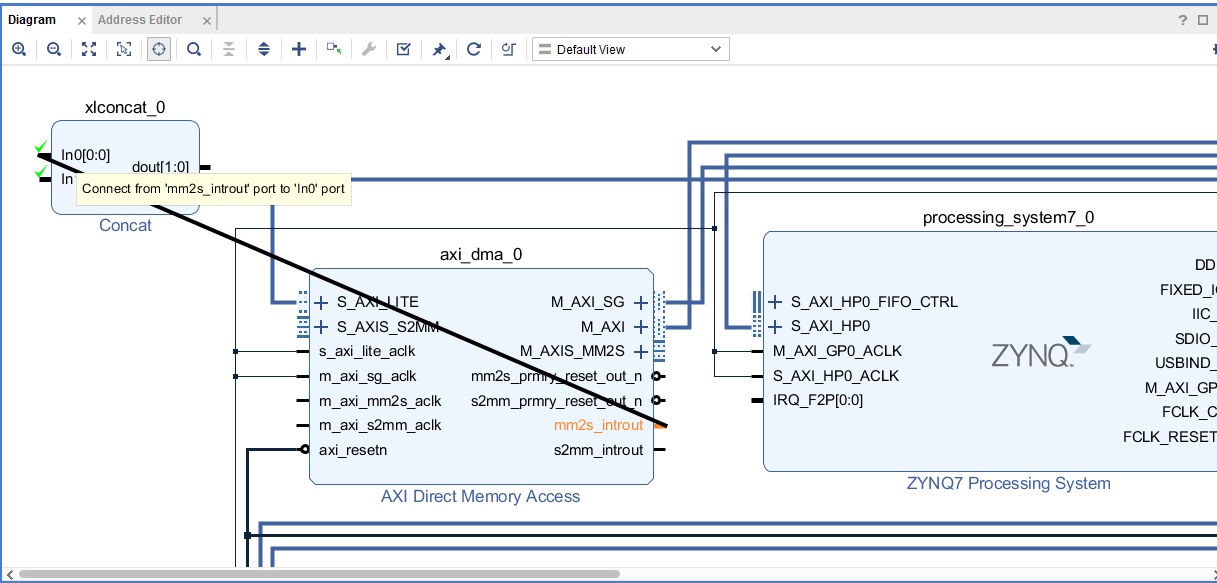
- Повторяем также для вывода s2mm_introut, который подключим к входу In1 блока Concat.
- Выход dout блока Concat таким же образом подключим к входу IRQ_F2P ядра Zynq7 Processing System.
- DMA подключено. Теперь необходимо подключить вход и выход DMA для данных. Так как обработка данных планируется за пределами Block Design, вытащим наружу тактовый сигнал и сигнал сброса. Для этого правый клик на свободном месте поля и выбираем Create Port или сочетание клавиш Ctrl + K. Заполняем имя порта, направление и тип => OK.
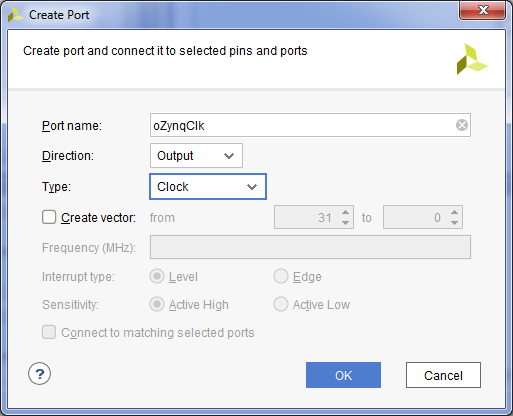
- Наведем курсор мыши на созданный порт и после появления карандаша подключим порт к выводу FCLK_CLK0 ядра Zynq7 Processing System.
- Подключим сигнал сброса. Для этого выделяем вывод peripheral_reset ядра Processor System Reset => правой кнопкой мыши => Make External.
- Клик на полученный порт, зададим новое имя порта и укажем, на каком тактовом сигнале необходимо обрабатывать данный сигнал.
- Подключим вход данных DMA. Для этого выделим порт S_AXIS_S2MM блока AXI Direct Memory Access => правой кнопкой мыши => Make External.
- Клик на полученный порт, зададим новое имя порта и укажем, на каком тактовом сигнале необходимо обрабатывать данный сигнал.
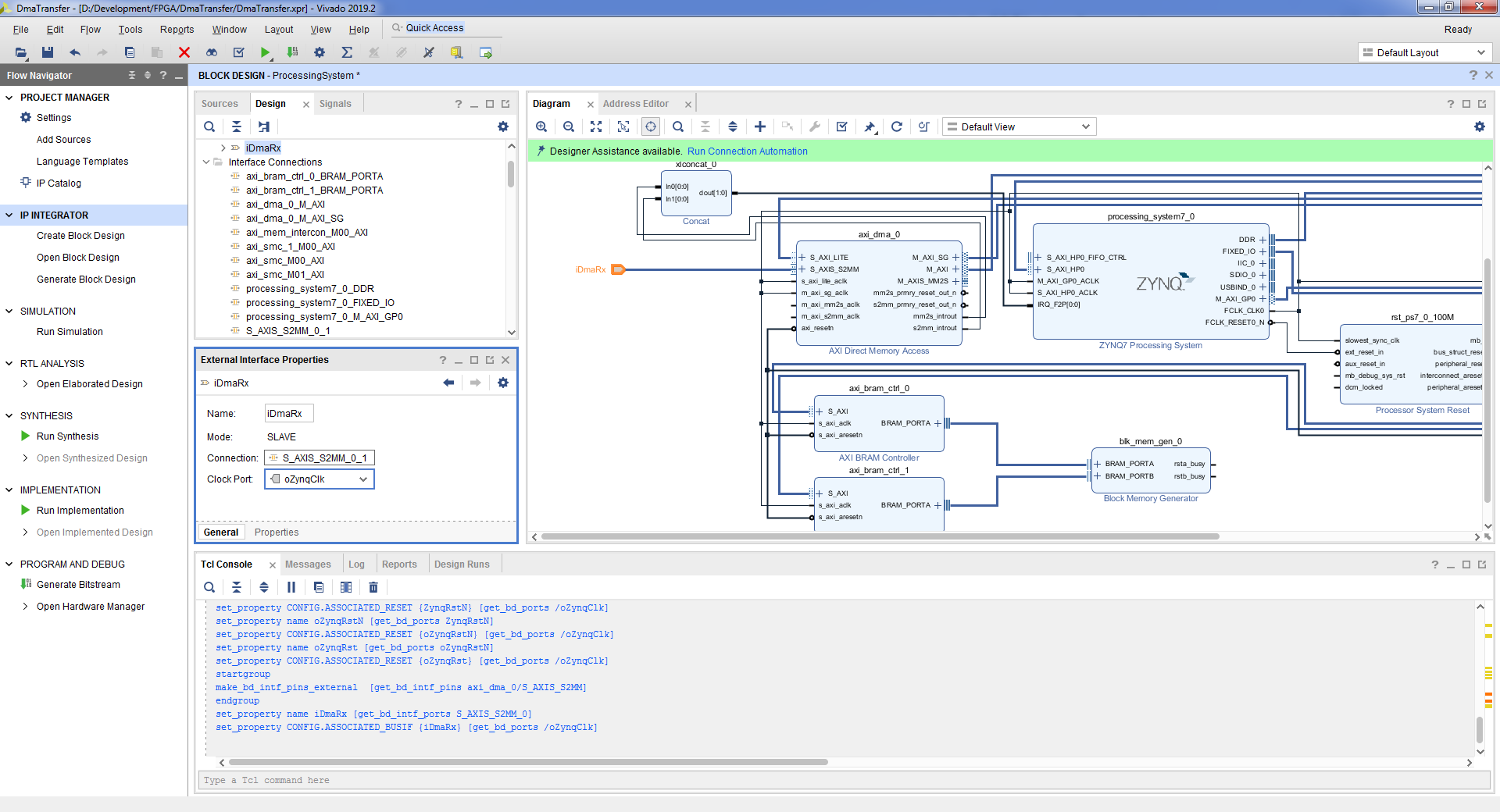
- Подключим выход данных DMA. Для этого выделим порт M_AXIS_MM2S блока AXI Direct Memory Access => правой кнопкой мыши => Make External.
- Клик на полученный порт, зададим новое имя порта и укажем, на каком тактовом сигнале необходимо обрабатывать данный сигнал.

- Подключим входы тактового сигнала для портов S_AXIS_S2MM и M_AXIS_MM2S у блока AXI Direct Memory Access. Для этого нажимаем «Run Connection Automation» => Галку на m_axi_mm2s_aclk и m_axi_s2mm_aclk => OK
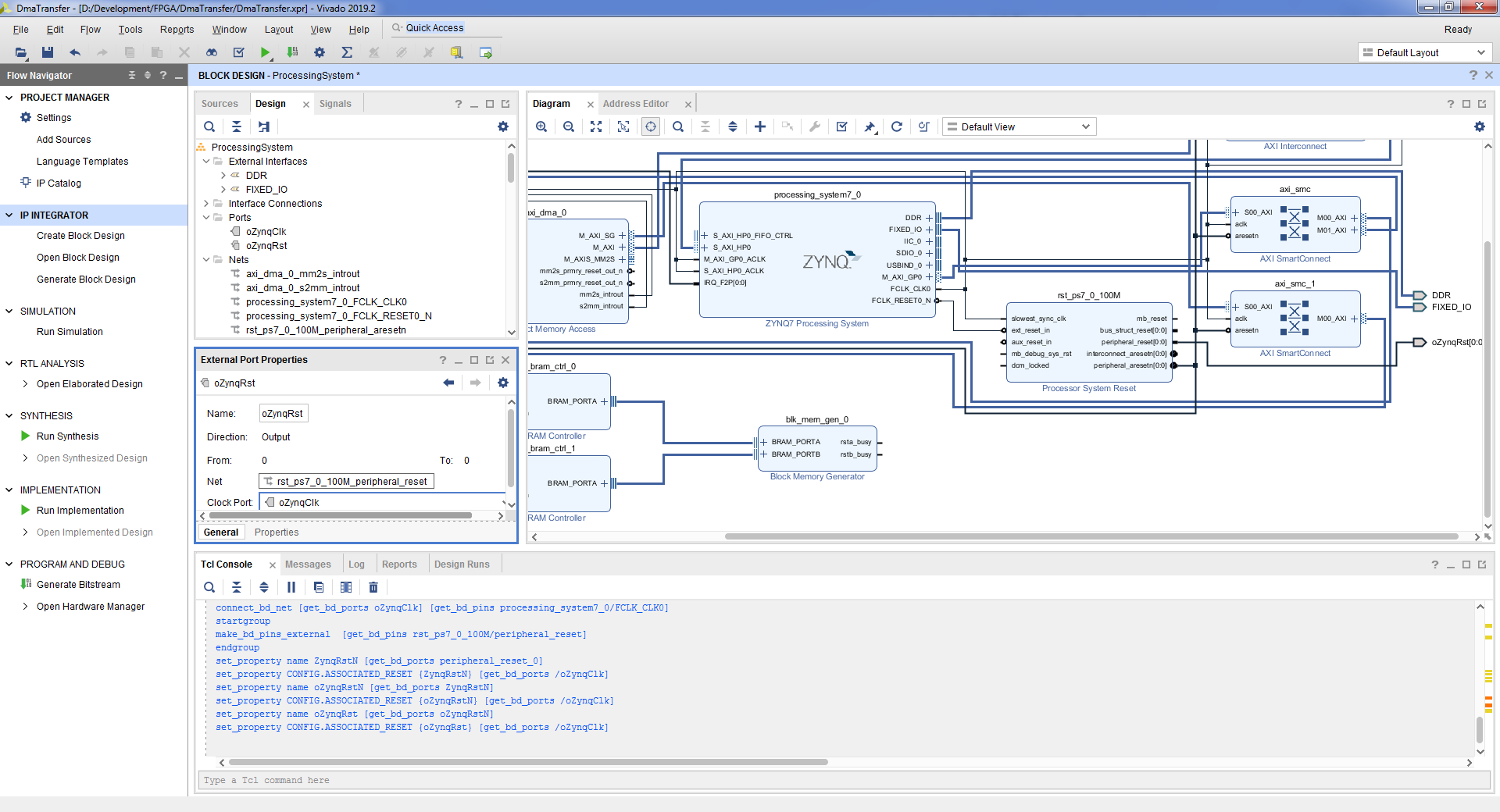
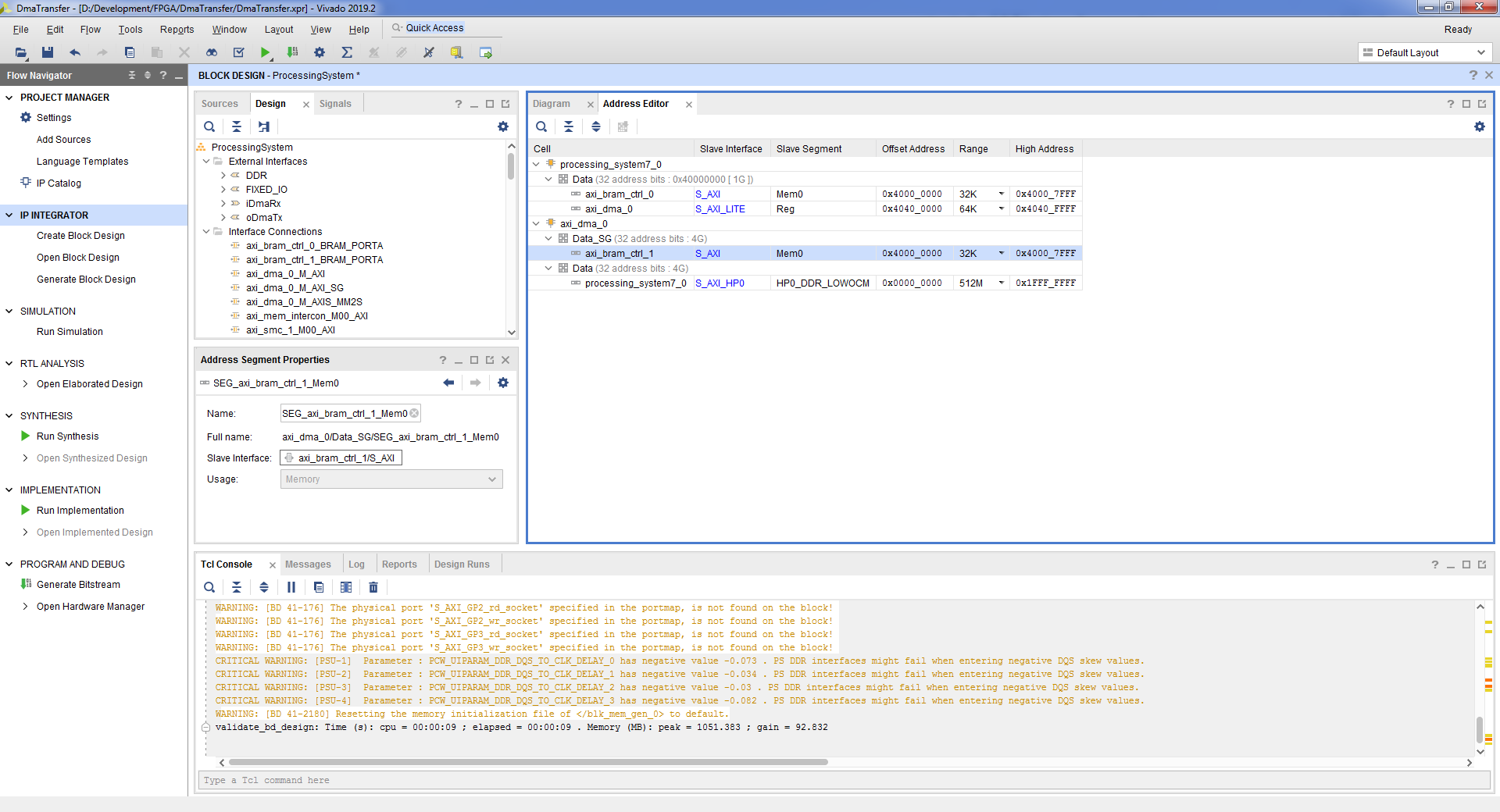
- Теперь необходимо изменить адресное пространство так, чтобы при обращении к блоку памяти от процессорного модуля и от блока DMA адреса были одинаковы. Заодно и увеличим размер памяти для хранения дескрипторов. Вкладка Address Editor => processing_system7_0 / Data / axi_bram_ctrl_0 => Offset Address 0x4000_0000 => Range 32K. Далее axi_dma_0 / Data_SG / axi_bram_ctrl_1 => Offset Address 0x4000_0000 => Range 32K.
- Tools => Validate Design => OK. Полученная схема:
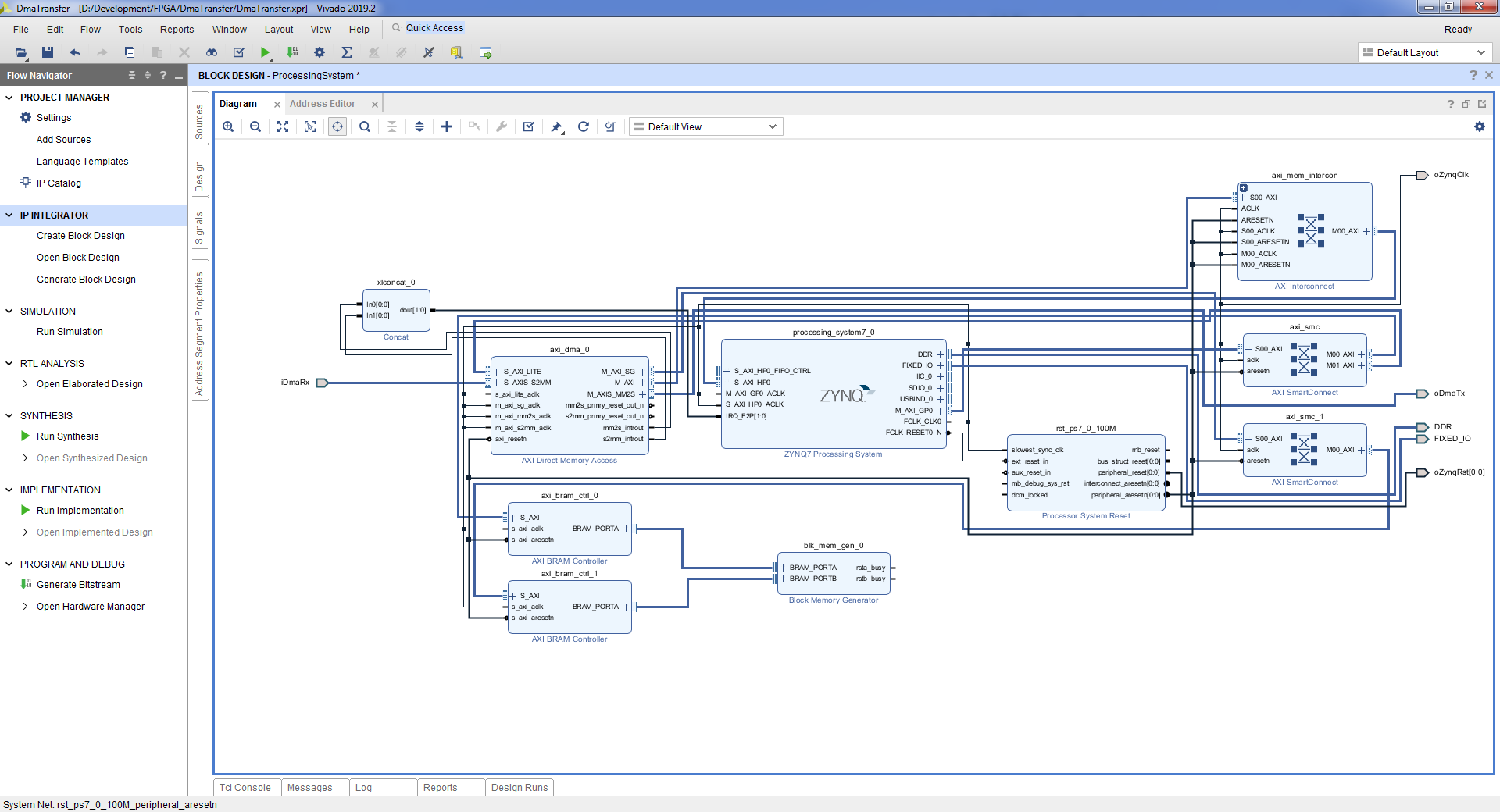
- File => Save Block Design.
- Переключаемся из режима работы с block design в режим работы с проектом, нажав во Flow Navigator => Project Manager.
- Смотрим, как описаны порты у полученного block design’a. Для этого выбираем файл ProcessingSystem.bd, правой кнопкой => View Instantiation Template.
- Создаем vhd файл top-уровня и подключаем в нем полученный block design. File => Add Sources => Add or create design sources => Next => Create File => вводим имя файла и указываем путь до каталога => OK => Finish => OK => Yes.

- Заполняем файл:
entity DmaTransfer is port ( DDR_addr : inout std_logic_vector(14 downto 0); DDR_ba : inout std_logic_vector( 2 downto 0); DDR_cas_n : inout std_logic; DDR_ck_n : inout std_logic; DDR_ck_p : inout std_logic; DDR_cke : inout std_logic; DDR_cs_n : inout std_logic; DDR_dm : inout std_logic_vector( 3 downto 0); DDR_dq : inout std_logic_vector(31 downto 0); DDR_dqs_n : inout std_logic_vector( 3 downto 0); DDR_dqs_p : inout std_logic_vector( 3 downto 0); DDR_odt : inout std_logic; DDR_ras_n : inout std_logic; DDR_reset_n : inout std_logic; DDR_we_n : inout std_logic; FIXED_IO_ddr_vrn : inout std_logic; FIXED_IO_ddr_vrp : inout std_logic; FIXED_IO_mio : inout std_logic_vector(53 downto 0); FIXED_IO_ps_clk : inout std_logic; FIXED_IO_ps_porb : inout std_logic; FIXED_IO_ps_srstb : inout std_logic ); end DmaTransfer; architecture Behavioral of DmaTransfer is signal RxData : std_logic_vector(31 downto 0); signal RxKeep : std_logic_vector( 3 downto 0); signal RxLast : std_logic; signal RxValid : std_logic; signal RxReady : std_logic; signal TxData : std_logic_vector(31 downto 0); signal TxKeep : std_logic_vector( 3 downto 0); signal TxLast : std_logic; signal TxValid : std_logic; signal TxReady : std_logic; signal clk : std_logic; signal rst : std_logic; signal FifoDataW : std_logic_vector(36 downto 0); signal FifoWrite : std_logic; signal FifoRead : std_logic; signal FifoDataR : std_logic_vector(36 downto 0); signal FifoEmpty : std_logic; signal FifoFull : std_logic; begin PS : entity WORK.ProcessingSystem port map ( DDR_addr => DDR_addr, DDR_ba => DDR_ba, DDR_cas_n => DDR_cas_n, DDR_ck_n => DDR_ck_n, DDR_ck_p => DDR_ck_p, DDR_cke => DDR_cke, DDR_cs_n => DDR_cs_n, DDR_dm => DDR_dm, DDR_dq => DDR_dq, DDR_dqs_n => DDR_dqs_n, DDR_dqs_p => DDR_dqs_p, DDR_odt => DDR_odt, DDR_ras_n => DDR_ras_n, DDR_reset_n => DDR_reset_n, DDR_we_n => DDR_we_n, FIXED_IO_ddr_vrn => FIXED_IO_ddr_vrn, FIXED_IO_ddr_vrp => FIXED_IO_ddr_vrp, FIXED_IO_mio => FIXED_IO_mio, FIXED_IO_ps_clk => FIXED_IO_ps_clk, FIXED_IO_ps_porb => FIXED_IO_ps_porb, FIXED_IO_ps_srstb => FIXED_IO_ps_srstb, -- Dma Channel iDmaRx_tdata => RxData, iDmaRx_tkeep => RxKeep, iDmaRx_tlast => RxLast, iDmaRx_tready => RxReady, iDmaRx_tvalid => RxValid, oDmaTx_tdata => TxData, oDmaTx_tkeep => TxKeep, oDmaTx_tlast => TxLast, oDmaTx_tready => TxReady, oDmaTx_tvalid => TxValid, -- System oZynqClk => clk, oZynqRst(0) => rst ); FifoDataW(31 downto 0) <= not TxData; FifoDataW(35 downto 32) <= TxKeep; FifoDataW( 36) <= TxLast; FifoWrite <= TxValid and not FifoFull; TxReady <= not FifoFull; EchFifo : entity WORK.SyncFifoBram37x1024 port map ( clk => clk, srst => rst, din => FifoDataW, wr_en => FifoWrite, rd_en => FifoRead, dout => FifoDataR, full => open, empty => FifoEmpty, prog_full => FifoFull ); RxData <= FifoDataR(31 downto 0); RxKeep <= FifoDataR(35 downto 32); RxLast <= FifoDataR(36); RxValid <= not FifoEmpty; FifoRead <= RxReady; end Behavioral; - Соберем проект. Для этого во Flow Navigator => Generate Bitstream => OK. Появившиеся окно, что создание прошивки успешно завершено, закрываем.
- Экспортируем полученные файлы для разработки приложения на процессоре. Для этого выбираем File => Export => Export Hardware => вводим имя файла и указываем путь до каталога => OK. Получаем на выходе файл .xsa

3.2 Программная часть
Теперь нужно написать приложение, работающее на процессорном модуле. Необходимо запустить среду разработки Vitis и создать приложение по шаблону Hello World, пример этого показан в предыдущей статье.
Формат дескрипторов для Axi DMA описан в документе на ядро [2]. Дескриптор имеет размер 52 байта, однако, адрес, по которому расположен дескриптор, должен быть выровнен на 64 байта.
Кратко по формату дескриптора:
- NXTDESC — адрес следующего дескриптора;
- NXTDESC_MSB — старшие 32 бита адреса следующего дескриптора;
- BUFFER_ADDRESS — адрес буфера;
- BUFFER_ADDRESS_MSB — старшие 32 бита адреса буфера;
- RESERVED — не используется;
- RESERVED — не используется;
- CONTROL — задает размер буфера, признаки начала и конца пакета;
- STATUS — показывает, сколько байт принято/передано, обработан/не обработан;
- APP0 — используется для работы с каналом «Control/Status Stream»;
- APP1 — используется для работы с каналом «Control/Status Stream»;
- APP2 — используется для работы с каналом «Control/Status Stream»;
- APP3 — используется для работы с каналом «Control/Status Stream»;
- APP4 — используется для работы с каналом «Control/Status Stream».
Адреса в программируемой логике для обращения со стороны процессорного модуля можно посмотреть в Vivado. В Flow Navigator => Open Block Design => Вкладка Address Editor. В данном случае адрес DMA равен 0x4040_0000. Адрес начала области памяти для дескрипторов равен 0x4000_0000.
- В Vitis откроем файл helloworld.c и подключим следующие библиотеки
#include <xil_io.h> #include "sleep.h" #include "xil_cache.h" #include "xil_mem.h" - Каждый дескриптор должен начинаться с адреса, кратного 64 байтам. Следовательно, в 32Кбайта поместятся 32 768 / 64 = 512 дескрипторов. По 256 на прием и 256 на передачу.
#define DESC_COUNT 256 ... /** Descriptors for receive */ struct SGDesc RxDesc[DESC_COUNT]; /** Descriptors for transmit */ struct SGDesc TxDesc[DESC_COUNT]; - Выключим работу кэша, чтобы не думать, когда его сбросить.
/** Flush Cache */ Xil_DCacheFlush(); /** Disable Cache */ Xil_DCacheDisable();
- Заполним буферы, которые будут передаваться в программируемую логику.
for (u16 desc = 0; desc < DESC_COUNT; desc++) { for (u32 i = 0; i < BUFFER_SIZE; i++) { TxBuffer[desc][i] = desc + i; } } - Заполним список дескрипторов для передачи.
for (u16 i = 0; i < DESC_COUNT; i++) { TxDesc[i].NXTDESC = &TxDesc[i]; TxDesc[i].NXTDESC_MSB = 0x0; TxDesc[i].BUFFER_ADDRESS = &TxBuffer[i][0]; TxDesc[i].BUFFER_ADDRESS_MSB = 0x0; TxDesc[i].RESERVED0 = 0x0; TxDesc[i].RESERVED1 = 0x0; TxDesc[i].CONTROL = 0xC000000 + sizeof(TxBuffer[i]); TxDesc[i].STATUS = 0x0; TxDesc[i].APP0 = 0x0; TxDesc[i].APP1 = 0x0; TxDesc[i].APP2 = 0x0; TxDesc[i].APP3 = 0x0; TxDesc[i].APP4 = 0x0; } - Скопируем дескрипторы передачи в память дескрипторов, которая расположена в программируемой логике.
DescAddr = 0x40000000; for (u16 i = 0; i < DESC_COUNT; i++) { Xil_MemCpy(DescAddr, &TxDesc[i], sizeof(TxDesc[i])); DescAddr += 0x40; } - Запишем указатель на следующий элемент в списке дескрипторов.
/** Write pointer to next pointer */ DescAddr = 0x40000000; for (u16 i = 0; i < DESC_COUNT - 1; i++) { Xil_Out32(DescAddr, DescAddr + 0x40); DescAddr += 0x40; } /** Write pointer for last descriptor */ Xil_Out32(DescAddr, DescAddr); - Повторим для списка дескрипторов приема.
/** Fill descriptor to receive */ for (u16 i = 0; i < DESC_COUNT; i++) { RxDesc[i].NXTDESC = &RxDesc[i]; RxDesc[i].NXTDESC_MSB = 0x0; RxDesc[i].BUFFER_ADDRESS = &RxBuffer[i][0]; RxDesc[i].BUFFER_ADDRESS_MSB = 0x0; RxDesc[i].RESERVED0 = 0x0; RxDesc[i].RESERVED1 = 0x0; RxDesc[i].CONTROL = sizeof(RxBuffer[i]); RxDesc[i].STATUS = 0x0; RxDesc[i].APP0 = 0x0; RxDesc[i].APP1 = 0x0; RxDesc[i].APP2 = 0x0; RxDesc[i].APP3 = 0x0; RxDesc[i].APP4 = 0x0; } /** Copy receive descriptor for memory of descriptors */ DescAddr = 0x40000000 + 0x4000; for (u16 i = 0; i < DESC_COUNT; i++) { Xil_MemCpy(DescAddr, &RxDesc[i], sizeof(RxDesc[i])); DescAddr += 0x40; } /** Write pointer to next pointer */ DescAddr = 0x40000000 + 0x4000; for (u16 i = 0; i < DESC_COUNT - 1; i++) { Xil_Out32(DescAddr, DescAddr + 0x40); DescAddr += 0x40; } /** Write pointer for last descriptor */ Xil_Out32(DescAddr, DescAddr); - Запустим DMA на передачу. DMA начинает обрабатывать данные после записи в регистр значения хвоста списка дескрипторов.
/** Reset DMA and setup */ /** MM2S */ Xil_Out32(0x40400000, 0x0001dfe6); Xil_Out32(0x40400000, 0x0001dfe2); /** S2MM */ Xil_Out32(0x40400030, 0x0001dfe6); Xil_Out32(0x40400030, 0x0001dfe2); /** PL => PS */ Xil_Out32(0x4040003c, 0x00000000); Xil_Out32(0x40400038, 0x40004000); Xil_Out32(0x40400030, 0x0001dfe3); Xil_Out32(0x40400044, 0x00000000); Xil_Out32(0x40400040, 0x40007FC0); /** PS => PL */ Xil_Out32(0x4040000C, 0x00000000); Xil_Out32(0x40400008, 0x40000000); Xil_Out32(0x40400000, 0x0001dfe3); Xil_Out32(0x40400014, 0x00000000); Xil_Out32(0x40400010, 0x40003FC0); - Подождем, пока будет обработан последний дескриптор на приеме и посчитаем время обработки. Конечно, можно использовать прерывания, но для тестовой задачи это излишне.
/** Wait ready in last descriptor */ while (1) { status = Xil_In32(0x40003FDC); if ((status & 0x80000000) == 0x80000000) { break; } else { countWait++; usleep(100); } } xil_printf("Time %x \n\r", countWait);
3.3 Результаты
Собираем приложение, создаем файл прошивки и заливаем в плату. Описано в предыдущей статье[1].
Запускаем, смотрим в мониторе com-порта:
Xilinx First Stage Boot Loader
Release 2019.2 Dec 16 2020-15:11:44
Silicon Version 3.1
Boot mode is QSPI
SUCCESSFUL_HANDOFF
FSBL Status = 0x1
Hello World
Time 10F
Таким образом, для обмена данными между процессорным модулем и программируемой логикой, в программируемой логике необходимо реализовать один из интерфейсов связи с процессорным модулем, где инициатором является программируемая логика. Такие интерфейсы представлены портами GP, HP, ACP. В предыдущей статье [1] они все были рассмотрены.
Посчитаем скорость передачи данных: (256 раз * 102400 байт) / (271 * 100 мкс) ? 967 321 033 байт/с ? 944 649 Кбайт/с ? 922 Мбайт/с.
Битовая скорость 7 738 568 264 бит/с.
Теоретическая скорость составляет 32 бита * 250 МГц = 8 000 000 000 бит/с.
Также, существует возможность хранить дескрипторы не в памяти программируемой логики, а в оперативной памяти, подключенной к процессорному модулю. В таком случае порт M_AXI_SG подключается к порту HP Zynq.
Рассмотрим первый вариант, когда для доступа DMA к данными и к дескрипторам в оперативной памяти процессорного модуля используются разные порты HP. Модифицируем прошивку в программируемой логике, чтобы получилась следующая схема:
Доступ к данными и дескрипторами через разные порты
Исходный код приложения приводить не будем. Отличия лишь в том, что дескрипторы не нужно копировать в память программируемой логики. Однако, необходимо учесть условие, чтобы адрес каждого дескриптора был выровнен на 64 байта.
После запуска приложения, в мониторе com-порта увидим, что время выполнения копирования буфера данных не поменялось, также 271 * 100 мкс.
Рассмотрим второй вариант, когда для доступа к DMA и к дескрипторам в оперативной памяти процессорного модуля используется один и тот же порт. Модифицируем прошивку в программируемой логике, чтобы получилась следующая схема:
Доступ к данными и дескрипторами через один и тот же порт
Исходный код приложения не поменялся относительно предыдущего варианта.
После запуска приложения, в мониторе com-порта увидим новое время выполнения операции копирования буфера: 398 * 100 мкс.
В результате, скорость обработки составит: (256 раз * 102400 байт) / (398 * 100 мкс) ? 658 653 266 байт/с ? 643 216 Кбайт/с ? 628 Мбайт/с.
Битовая скорость 5 269 226 128 бит/с.
Проект: github.com/Finnetrib/DmaTransfer
4 Заключение
В этой статье мы рассмотрели два реализации обмена данными между процессорным модулем и программируемой логикой. Режим PIO прост в реализации и позволяет получить скорость до 23 Мбайт/с, режим DMA несколько посложнее, но и скорость выше — до 628 Мбайт/с.
altulinov
Вспоминая свой опыт с прошлого места работы, где был задействован в разработке на FPGA, в том числе и с платформой ZYNQ: зачем такие скорости обмена между ЦП и ПЛИС?
ЦП хорош тем, что уже реализованы базовые интерфейсы (UART, Ethernet, USB), можно быстро накидать программу управления логикой в ПЛИС части.
Данные-то в ЦП зачем гонять? Там где нужна была максимальная скорость между управляемой железкой с кучей данных и каким-то интерфейсом, писалась обертка для ПЛИС. А обертку уже контролировал проц.
Единственное, где помню, что нужна была работа через проц с DMA, это работа с памятью DDR… Но и опять же участие процессора сводилось к настройке регистров в разных контроллерах.
Fenja Автор
Например, в программируемой логике реализован какой-то алгоритм обработки данных, который обрабатывает наиболее часто встречающиеся случаи. Если пришли данные, которые нуждаются в особой обработке (редкий случай) то их проще обработать на процессорном модуле. Чем быстрее они туда попадут, тем быстрее обработаются. Когда есть запас по скорости это всегда хорошо.
И в случае с работой с DDR. Можно организовать обмен данными (в случае большого объема) между разными каналами в программируемой логике через DDR, подключенную к процессорному модулю. Дескрипторы удобнее на процессорном модуле заполнять, а в обмене он непосредственно не участвует.
Brak0del
Так может в вашем конкретном случае и вовсе без проца можно обойтись, глядишь, ещё и денег сэкономите на железе?
Фишка Zynq и прочих подобных SoC с ПЛИС на борту в том, что на проц можно накатить ОС, линукс какой-нибудь, а логику ПЛИС использовать как акселератор тяжёлых вычислений и дёргать драйверами. При этом с одной стороны у вас будет очень сложный софт в проце, а с другой возможность делать наиболее тяжёлые операции на ПЛИС в реалтайме.
Сейчас не очень слежу за Zynq, но судя по статьям Xilinx, они очень интересуются 5G и Zynq туда хорошо вписывается. Также наблюдаю её у тех, кто обрабатывает видео с камер наблюдения в реальном времени (crowd control) и кто делает примочки для авто (всякие ADAS). Раньше у Xilinx был журнал Xcell, например в номерах 88 и 93 можно глянуть некоторые реальные кейсы, где, почему и как она использовалась.
proton17
Вот Вам кейс из реальной жизни. Zynq US+, на ЦП крутится линух с ftp и несколько SSD на SATA, а на PL многоканальный контроллер оптического интерфейса а ля FC. Вот тут DMA и прочая дичь очень кстати.
AquariusStar
Всё зависит от задач. У меня несколько раз были такие задачи, которые прямо требовали участия процессора с программой. Конечно, можно реализовать конечный автомат для реализации алгоритма. Но это выльется в незабываемое приключение с багами и поиска случаев, когда они работают не в той фазе или случайно перепутал сигнальные линии. А если ещё управляете с компьютера, одновременно гоняя данные туда-сюда (могут участвовать высокоскоростные приёмопередатчики), то бывает ещё веселее.
kulikser
У нас например одна из задач отрисовывать графики, полученные путем обработки данных с АЦП разными алгоритмами в реальном времени. FPGA данные через DMA в драйвер отправляет, драйвер через mmap в userspace, оттуда сервер через вебсокеты на фронтенд. Кнопочку нажал и в web-интерфейсе получил по 7 графиков для каждого из 4-5 каналов на несколько тысяч точек.