Недавно благодаря предсказательной мощи машинного обучения (machine learning, ML) мы обеспечили экономию 1,7 миллионов долларов в год на инфраструктурных тратах, оптимизировав процесс генерации и кэширования превью документов Dropbox. Машинное обучение и раньше применялось в Dropbox для таких хорошо известных функций, как поиск, рекомендации файлов и папок, а также OCR при сканировании документов. Хоть и не все сферы применения ML непосредственно видны пользователю, они всё равно изнутри влияют на развитие бизнеса.
Что такое превью?
Функция Dropbox Previews позволяет пользователям просматривать файл без скачивания контента. В дополнение к превью-миниатюрам Dropbox имеет интерактивную поверхность Previews с возможностью обмена между пользователями и совместной работы, в том числе использования комментарии и тегирования других пользователей.
Наша внутренняя система надёжной генерации превью файлов под названием Riviera занимается генерацией превью для сотен поддерживаемых типов файлов. Этот процесс реализуется созданием цепочки различных преобразований контента, обеспечивающей генерацию ресурсов превью, соответствующих типу файла. Например, Riviera может растеризировать страницу из многостраничного PDF-документа для демонстрации в веб-поверхности Dropbox превью высокого разрешения. Функция превью всего контента поддерживает такие интерактивные возможности, как комментирование и передача другим пользователям. Крупные графические ресурсы в дальнейшем могут преобразовываться в миниатюры изображений, которые демонстрируются пользователю в различных контекстах, в том числе в результатах поиска или в браузере файлов.
В масштабах Dropbox система Riviera обрабатывает ежедневно десятки петабайтов данных. Для ускорения процесса создания превью определённых классов крупных файлов Riviera заранее генерирует и кэширует ресурсы превью (этот процесс мы называем «предварительным прогревом»). Учитывая объём поддерживаемых нами файлов, затраты на процессорные мощности и накопители, связанные с «прогревом», оказываются довольно значительными.
Превью-миниатюры при просмотре файлов. Превью можно увеличивать и с ними можно взаимодействовать как с заменой файла приложения.
Мы увидели перспективу снижения этих затрат при помощи машинного обучения, поскольку часть этого заранее генерируемого контента пользователи никогда не просматривали. Если мы сможем эффективно предсказывать, будет ли использоваться превью, то сэкономим на вычислениях и хранении файлов, проводя «предварительный прогрев» только тех файлов, которые точно будут просмотрены. Мы назвали этот проект Cannes («Канны») в честь знаменитого города на Французской Ривьере, где проводятся предварительные показы фильмов со всего мира.
Баланс в машинном обучении
Существует два аспекта, поиск равновесия в которых повлиял на наши принципы оптимизации превью.
Первая задача заключалась в поиске компромисса между затратами и преимуществами экономии на инфраструктуре при помощи ML. Если выполнять «предварительный прогрев» меньшего количества файлов, то мы сэкономим деньги (а кому это не понравится!), но если отклонить файл ошибочно, то это навредит пользователю. Когда происходит промах кэша, системе Riviera нужно генерировать превью на лету, пока пользователь ждёт отображения результата. Совместно с командой разработчиков Previews мы задали предел снижения удобства для пользователей и использовали этот предел для настройки модели, которая обеспечит приемлемый уровень экономии.
Ещё одним компромиссом был поиск баланса: сложность и производительность модели против интерпретируемости и стоимости введения в эксплуатацию. В целом, в ML существует баланс сложности и интерпретируемости: более сложные модели обычно имеют более точные предсказания, но ценой этого становится снижение интерпретируемости того, почему были сделаны конкретные прогнозы; кроме того, при этом может повыситься сложность ввода в эксплуатацию. В первой версии системы мы решили как можно быстрее создать интерпретируемое ML-решение.
Так как Cannes стало новым ML-приложением, встроенным в существующую систему, выбор в пользу более простой и интерпретируемой модели позволил нам сосредоточиться на реализации работы модели, метрик и отчётности, после чего можно было повышать сложность. Если бы что-то пошло не так или мы обнаружили бы неожиданное поведение в Riviera, то команде ML-разработки было бы проще выполнить отладку и понять, вызваны ли проблемы Cannes, или чем-то ещё. Решение должно быть относительно простым и дешёвым для ввода в эксплуатацию и обслуживания примерно полумиллиарда запросов в день. Уже существующая система просто выполняла «предварительный прогрев» всех файлов с возможностью превью, поэтому любые усовершенствования привели бы к экономии, и чем скорее, тем лучше!
Cannes v1
Учтя описанные выше компромиссы, мы намеревались создать для Cannes простую, быструю в обучении и понятную людям модель. Модель v1 была классификатором посредством градиентного бустинга, обученным на таких входных данных, как расширение файла, тип аккаунта Dropbox, в котором хранится файл и последние 30 активности в этом аккаунте. В тесте, проведённом вне работающей системы, мы выяснили, что эта модель может предсказывать превью спустя даже 60 дней после «предварительного прогрева» с точностью >70%. В контрольной системе модель отклоняла примерно 40% запросов «предварительного прогрева», а её производительность находилась в пределах интервала защитного механизма, который мы задали в самом начале. Возникало небольшое количество ложно-отрицательных результатов (файлов, которые по нашим прогнозам не должны были просматриваться, однако просматривались в течение последующих 60 дней), из-за которых возникали дополнительные затраты на генерацию ресурсов превью на лету. Мы использовали метрику «процент отклонённых» минус ложно-отрицательные результаты, получив общую сумму ежегодной экономии в 1,7 миллиона долларов.
Ещё до того, как мы начали исследовать пространство оптимизаций Previews, нам нужно было гарантировать, что потенциальная экономия перевесит стоимость создания решения на основе ML. Нам пришлось выполнить примерную оценку прогнозируемой экономии, которой мы хотели достичь при помощи Cannes. При проектировании и вводе в эксплуатацию ML-систем в крупных распределённых системах нужно смириться с тем, что внесение некоторых изменений в систему постепенно будет влиять на оценки. Из-за того, что первоначальная модель оставалась простой, мы надеялись, что порядок величин влияния на экономию будет стоящим вложенных усилий, даже если со временем придётся вносить незначительные изменения в соседние системы. Анализ обученной модели дал нам более обширное представление о тому, что мы сэкономим в v1, и подтвердил обоснованность вложений в разработку.
Мы провели A/B-тестирование модели на случайной 1-процентной выборке трафика Dropbox при помощи нашей внутренней службы управления доступностью функций Stormcrow. Мы убедились, что точность модели и количество «сэкономленных» «прогревов» соответствовали результатами отдельного анализа, и это было просто отлично! Так как Cannes v1 больше не выполняла «предварительный прогрев» всех возможных файлов, мы ожидали, что частота попаданий в кэш упадёт; во время эксперимента мы наблюдали, что частота попаданий в кэш стала на пару процентных пунктов меньше, чем у контрольной выборки из A/B-теста. Несмотря на это падение, общая задержка отображения превью осталась практически неизменной.
Нас особенно интересовала хвостовая задержка (задержка для запросов выше 90-го перцентиля), потому что промахи кэша, вносившие свой вклад в повышение хвостовой задержки, должны были серьёзнее повлиять на пользователей функции Previews. Нас вдохновило то, что мы не наблюдали ухудшения ни хвостовой задержки превью, ни общей задержки. Тест на работающей системе обеспечил нам уверенность в том, что можно начинать ввод в эксплуатации модели v1 на больший объём трафика Dropbox.
Прогнозирование в реальном времени на больших масштабах
Нам нужно было каким-то образом передавать прогнозы реального времени системе Riviera, чтобы она знала, необходимо ли выполнять «прогрев» файла при движении файлов по пути «предварительного прогрева». Для решения этой проблемы мы превратили Cannes в конвейер прогнозов, получающий относящиеся к файлу сигналы и передающий их в модель, которая прогнозирует вероятность использования будущих превью.
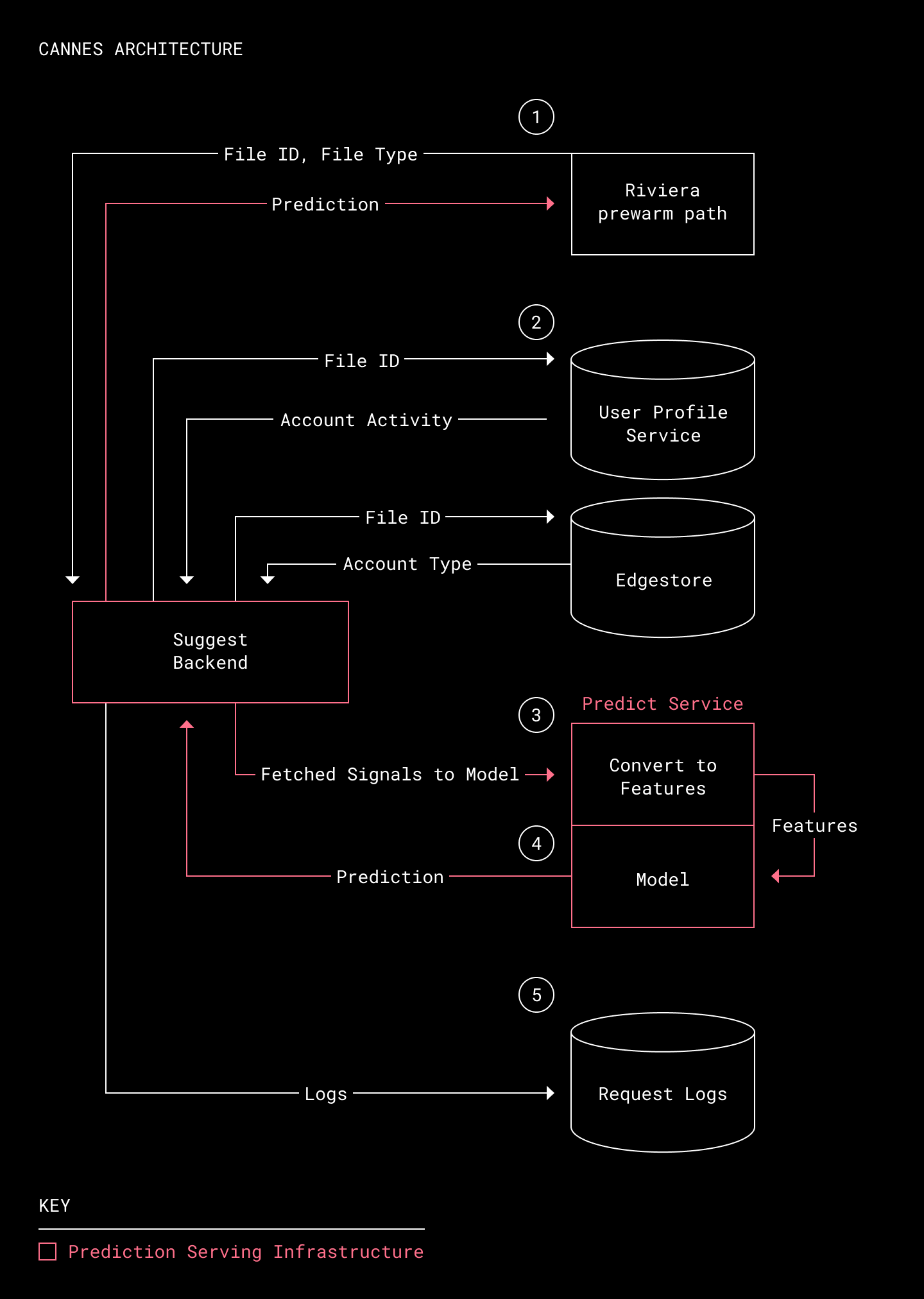
Архитектура Cannes
- Получаем от пути «предварительного прогрева» Riviera идентификатор файла. Riviera собирает идентификаторы всех файлов, для которых возможен «предварительный прогрев». (Riviera может выполнять превью примерно 98% файлов, хранящихся в Dropbox. Существует небольшое количество файлов, которые относятся к неподдерживаемым типам или не могут создать превью по какой-то другой причине.) Riviera отправляет запрос на прогноз с идентификатором файла и его типом.
- Получение сигналов реального времени. Для сбора самых последних сигналов для файла в момент предсказания мы использовали внутренний сервис под названием Suggest Backend. Этот сервис валидирует запрос на предсказание, а затем запрашивает соответствующие сигналы, относящиеся к этому файлу. Сигналы хранятся или в Edgestore (основной системе хранения метаданных Dropbox), или в User Profile Service (массиве данных RocksDB, выполняющем агрегацию сигналов активности Dropbox).
- Кодируем сигналы в вектор признаков. Собранные сигналы передаются в Predict Service, кодирующий сырые сигналы в вектор признаков, который содержит всю важную информацию файла, а затем отправляет этот вектор модели для оценки.
- Генерируем прогноз. Модель использует вектор признаков для возврата прогнозируемой вероятности того, что превью файла будет использоваться. Это прогноз затем отправляется обратно Riviera, которая «прогревает» файлы, у которых есть вероятность просмотра превью в течение 60 дней в будущем.
- Журналируем информацию о запросе. Suggest Backend журналирует вектор признаков, результаты прогноза и статистику запроса — всю критически важную информацию для контроля снижения производительности и проблем с задержками.
Дополнительный фактор
Снижение задержки прогнозирования важно, потому что описанный выше конвейер находится на критичном пути для функции «предварительного прогрева» Riviera. Например, при использовании системы для работы с 25% трафика мы наблюдали пограничные случаи, опускавшие уровень доступность Suggest Backend ниже наших внутренних SLA. Дальнейшее профилирование показало, что в этих случаях происходил таймаут на этапе 3. Мы усовершенствовали этап кодирования признаков и добавили в путь прогнозирования еще несколько других оптимизаций, снижающих хвостовую задержку для таких пограничных случаев.
Оптимизируем ML
Во время и после процесса ввода в эксплуатацию нашим приоритетом была устойчивость и гарантии того, что система не повлияет негативно на пользователей на поверхности Previews. Критически важными компонентами процесса ввода в эксплуатацию ML являются тщательный мониторинг и многоуровневая система предупреждений.
Метрики Cannes v1
Инфраструктурные метрики: у систем общего пользования есть собственные SLA, касающиеся аптайма и доступности. Для мониторинга и отправки предупреждений в реальном времени мы используем готовые инструменты наподобие Grafana. Есть следующие метрики:
- Доступность Suggest Backend и Predict Service
- Актуальность данных User Profile Service (или массива данных действий)
Метрики превью: мы выделили ключевые метрики производительности превью,
а именно распределение задержек превью. Мы оставили контрольные 3% для сравнения метрик превью с Cannes и без неё, защищаясь от дрейфа модели или непредусмотренных изменений систем, способных снизить производительность модели. Кроме того, Grafana является популярным решением и для контроля метрик на уровне приложений. Применяются следующие метрики:
- Распределение задержек превью (сравнение Cannes и контрольной группы без Cannes); особое внимание уделяется задержкам выше p90
- Частота попадания в кэш (сравнение Cannes и контрольной группы без Cannes): общее количество попаданий в кэш/общее количество запросов на превью контента
Метрики производительности модели: у нас есть метрики модели для Cannes v1, которые использует команда ML-разработчиков. Мы создали собственный конвейер для вычисления этих метрик. Нас интересуют следующие метрики:
- Матрица неточностей; особое внимание уделяется изменениям в частоте ложно-отрицательных результатов
- Площадь под кривой ошибок: одновременно с непосредственным контролем статистики матрицы неточностей вычисляется AUROC с целью сравнения производительности с будущими моделями.
Представленные выше метрики производительности вычисляются ежечасно и сохраняются в Hive. Мы используем Superset для визуализации важных метрик и создания дэшборда изменения производительности Cannes по времени. Предупреждения Superset, создаваемые на основе таблиц метрик, позволяют нам узнать об изменении поведения лежащей в основе системы модели ещё до того, как оно повлияет на пользователей.
Однако самих по себе мониторинга и предупреждений недостаточно для обеспечения здоровья системы; необходимо создание чёткой иерархии владения и процессов передачи на более высокие уровни. Например, мы задокументировали выше по потоку определённые зависимости ML-систем, способные повлиять на результаты модели. Также мы создали перечень задач для дежурных инженеров с подробными пошаговыми инструкциями, позволяющими определить, возникла ли проблема внутри Cannes или в другой части системы, а также путь передачи на более высокие уровни, если причиной являлась модель ML.
Современное состояние и дальнейшие исследования
Cannes теперь используется почти для всего трафика Dropbox. В результате этого мы заменили приблизительно 1,7 миллиона долларов ежегодных затрат на «предварительный прогрев» 9 тысячами в год на инфраструктуру ML (в основном эти траты вызваны повышением объёма трафика к Suggest Backend и Predict Service).
В следующей версии проекта можно исследовать множество захватывающих областей. Теперь, когда остальная часть системы Cannes выведена в продакшен, мы можем поэкспериментировать с более сложными типами моделей. Также можно разработать более точную функцию затрат для модели на основании более подробных данных об издержках и масштабах использования. Ещё один способ применения Previews, который мы обсуждали — использование ML для более подробных предсказательных решений для каждого файла, чем просто «прогрев нужен/не нужен». Возможно, нам удастся обнаружить потенциал дальнейшей экономии благодаря более творческому использованию предсказательного «прогрева».
Мы надеемся обобщить выводы и инструменты, созданные для Cannes, на другие инфраструктурные проекты Dropbox. Применение машинного обучения в оптимизации инфраструктуры — интересная область для вложения сил и средств.
На правах рекламы
Закажите и сразу работайте! Создание VDS любой конфигурации в течение минуты, в том числе серверов для хранения большого объёма данных до 4000 ГБ. Эпичненько :)
