
Для частого запуска Spark-приложений, особенно в промышленной эксплуатации, необходимо максимально упростить процесс запуска задач, а также уметь гибко настраивать их конфигурации. В этом может помочь Kubernetes: он позволяет решать задачи изоляции рабочих сред, гибкого управления ресурсами и масштабирования.
Но порог входа в Kubernetes для Data Scientists все еще остается высоким. Мы хотим помочь в работе с непростой технологией, поэтому покажем, как можно быстро развернуть Spark внутри Kubernetes и запустить в нем свое приложение.
Я Александр Волынский, архитектор облачной платформы Mail.ru Cloud Solutions. В этой статье мы вместе:
Запустим кластер Kubernetes и подготовим его для работы со Spark: установим на нем Spark Operator.
Запустим в Spark простое приложение, которое считает число пи. Обычно на этом заканчиваются инструкции в интернете, но мы пойдем дальше и попробуем более интересные вещи.
Обернем приложение в Docker-образ и добавим в него необходимые зависимости. Так вы научитесь добавлять в образ нужные вам библиотеки.
Запустим приложение из этого образа, проверим логи и результаты работы. В процессе вы научитесь основам отладки приложений в Kubernetes.
Установим Spark History Server и перенаправим в него логи приложения, чтобы они были доступны даже после уничтожения пода.
Но прежде чем перейти к практической части, посмотрим, какие преимущества можно получить, если развернуть Spark в Kubernetes.
Если вы предпочитаете видеоинструкцию, можете посмотреть вебинар «Разворачиваем приложение на Apache Spark в Kubernetes. Пошаговый рецепт».
Почему стоит запускать Spark именно в Kubernetes
Все больше специалистов в Data Science и Data Engineering используют контейнеры в ежедневной работе. Это позволяет разделять рабочие среды, упрощает миграцию из On-premise в облако и обратно. Используя Kubernetes и контейнеры, вы приближаетесь к Cloud Native. Перечислим, какие основные преимущества дает запуск Spark внутри Kubernetes:
Изоляция сред. В традиционном развертывании в Hadoop-кластере есть проблема версионности Spark. Если вам необходимо перейти на новую версию Spark, то это добавляет проблем командам администрирования и Data Science. Администраторам нужно организовать бесшовный апгрейд кластера, а дата-инженерам нужно проверить все свои пайплайны и убедиться, что они будут правильно работать в новой версии. Используя Spark в Kubernetes, вы решаете эту проблему. Потому что каждый член команды может создать себе отдельное окружение, которое будет работать в независимом контейнере, упаковать в него Spark-приложение со всем кодом и любыми зависимостями. Можно использовать любую версию Spark, любые зависимости и никому не мешать.
Управление ресурсами. Kubernetes позволяет накладывать ограничения ресурсов на разные приложения и разные типы пайплайнов, например, используя Namespace.
Гибкое масштабирование. Kubernetes в облаке умеет задействовать огромное количество ресурсов на то время, когда они реально используются. Допустим, ваше приложение обычно использует 10 ядер процессора, но иногда для сложной обработки ему нужно 500 или 1000 ядер. В этом случае вам нужно подключить функцию автомасштабирования кластера. Тогда, если ваше приложение запросит 500 ядер, облако их выделит. А когда приложение перестанет генерировать такую нагрузку, ненужные ресурсы автоматически вернутся в облако.
Разделение Storage и Compute-слоев. В Hadoop-кластере каждая нода является и Storage, и Compute. Если для приложения нужно добавить больше ядер, то приходится добавлять новую ноду, которая также добавляет и диски, за которые надо платить. Аналогично, если закончилось место на дисках: CPU хватает, но мы все равно добавляем лишнюю ноду. Облако позволяет разделить Storage и Compute-слои: Kubernetes выступает в роли Compute, а объектное S3-хранилище в роли Storage. Но даже если вы не хотите использовать S3, Kubernetes позволяет реализовать комбинированный сценарий. Вы можете использовать Hadoop-кластер как обычно, но в моменты пиковых нагрузок запускать Spark в Kubernetes, чтобы использовать его ресурсы.
Повышение эффективности использования ресурсов. Если у вас уже есть рабочий кластер Kubernetes, то его можно использовать, чтобы поднять Spark или любое другое приложение. При этом не придется создавать новый кластер.
Способы запуска Spark в Kubernetes
Spark можно запускать в Kubernetes, начиная с версии 2.3, которая вышла в 2018 году.
До недавнего времени это была экспериментальная возможность, но недавно вышла версия Spark 3.1.1, в которой эта возможность доведена до production-ready. Это означает, что Spark полностью готов к запуску в Kubernetes. В вебинаре мы еще использовали версию 3.0.1.
Spark можно запускать в Kubernetes двумя способами:
Spark-submit, это Spark-Native путь. Вы используете spark-submit, задаете, как обычно, все параметры, а в качестве менеджера ресурсов указываете Kubernetes. В этом случае в момент spark-submit внутри Kubernetes создастся под, на котором сначала разместится Driver. Далее этот Driver будет напрямую взаимодействовать с API Kubernetes и создавать Executor по указанным параметрам. При этом Kubernetes не будет знать, что внутри него работает именно Spark, для него это будет просто еще одно приложение.
Kubernetes Operator for Spark, это Kubernetes-Native путь. В этом случае Kubernetes понимает, что внутри него работает Spark. При этом вы получаете более удобный доступ к логам, текущему состоянию Job и статусу приложения. Мы рекомендуем использовать именно этот способ.
Производительность и особенности работы Spark в Kubernetes
Для управления ресурсами и планирования приложений в Spark часто используют Yarn. Долгое время Spark в Kubernetes существенно отставал по скорости и эффективности от Spark в Yarn. Но на текущий момент производительность практически выровнялась. Yarn остается быстрее в среднем на 4–5%.

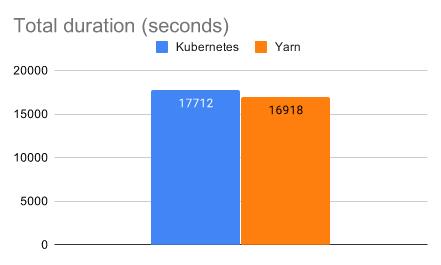
Но здесь нужно отметить, что для тестирования использовались локальные SSD-диски. Производительность Spark в облачном Kubernetes будет ниже из-за того, что мы используем S3 и доступ к данным осуществляется по сети. S3-хранилище позволяет разделить storage и compute слои, а также неограниченно масштабируется под любой объем данных. Но доступ к ним будет медленнее из-за сетевой задержки, тогда как в классическом Hadoop-кластере приложения размещаются рядом с данными, поэтому там минимальные задержки на передачу данных.
Другой момент заключается в том, что Spark в процессе работы активно использует диски для сохранения промежуточного состояния — spill-файлов. Тип используемого диска существенно влияет на производительность. На нашей облачной платформе доступны разные типы дисков: HDD, SSD, High-iOps SSD и сверхбыстрые Low-latency NVMe. Для того чтобы получить максимум от Spark в Kubernetes, стоит использовать самые производительные Low-latency NVMe. Но в любом случае при прочих равных Spark в Kubernetes будет работать медленнее, чем в классическом Hadoop-кластере.
Однако если Hadoop-кластер перегружен, то Kubernetes может обогнать его. Облако позволяет получить огромное количество ресурсов и быстро обработать данные. А загруженный Hadoop-кластер будет долго обрабатывать данные, несмотря на то, что задержка на передачу данных минимальна.
Для увеличения производительности в качестве диска для spill-файлов можно подключить оперативную память. При этом нужно понимать, что если spill-файлы будут слишком большими, то Spark может упасть. Поэтому нужно знать, как работает ваше приложение, какие оно обрабатывает данные и какие совершает операции.
Еще один момент: Kubernetes потребляет часть ресурсов ноды для своих служебных целей. Поэтому если создать ноду, например, с 4 ядрами и 16 Гб оперативной памяти, то Executor не сможет использовать все эти ресурсы. Best practice — выделять для Executor 75–85% от объема ресурсов, либо смотреть по конкретной ситуации.
Еще стоит упомянуть о Dynamic Allocation. В Hadoop он работает за счет того, что там есть External Shuffle Service. Эти промежуточные файлы сохраняются не на самих Executor. А в Kubernetes они сохраняются на Executor, и мы не можем уничтожить те Executor, которые содержат эти shuffle-файлы. То есть в Kubernetes можно активировать Dynamic Allocation, но он будет не такой эффективный, как в Hadoop. Над этим ведется работа, и, возможно, в следующих версиях Spark появится External Shuffle Service, в том числе и для Spark в Kubernetes.
Инструкция по установке и настройке Spark в Kubernetes
Для вебинара мы подготовили репозиторий. Там описаны все шаги, перечислены основные команды и есть все файлы, которые мы будем использовать далее при сборке собственного приложения. Также там есть множество ссылок для дополнительного самостоятельного изучения.
Шаг 1: создаем кластер Kubernetes
Переходим к практической части. Сначала нам необходимо развернуть кластер Kubernetes. Мы будем делать это на нашей облачной платформе Mail.ru Cloud Solutions.
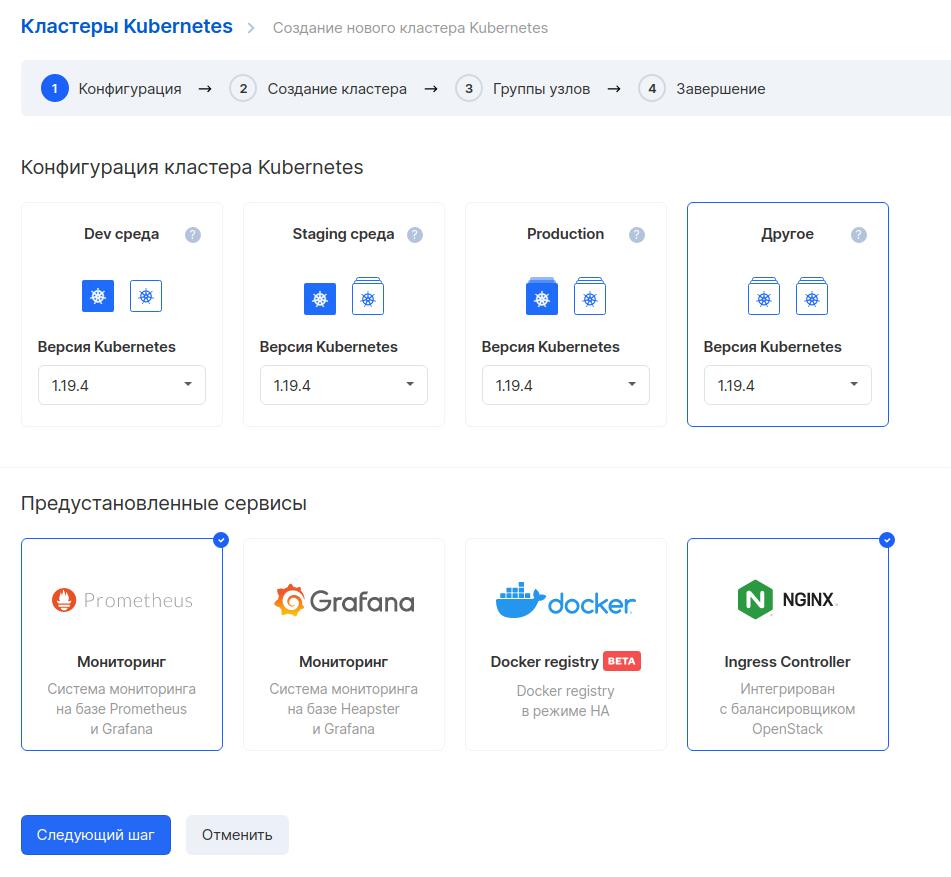
Заходим в панель MCS и создаем кластер Kubernetes. Кластер можно создать в разных конфигурациях, выбираем «Другое», это позволит гибко задать параметры ресурсов. Также выбираем два предустановленных сервиса: мониторинг на базе Prometheus/Grafana и Ingress Controller.
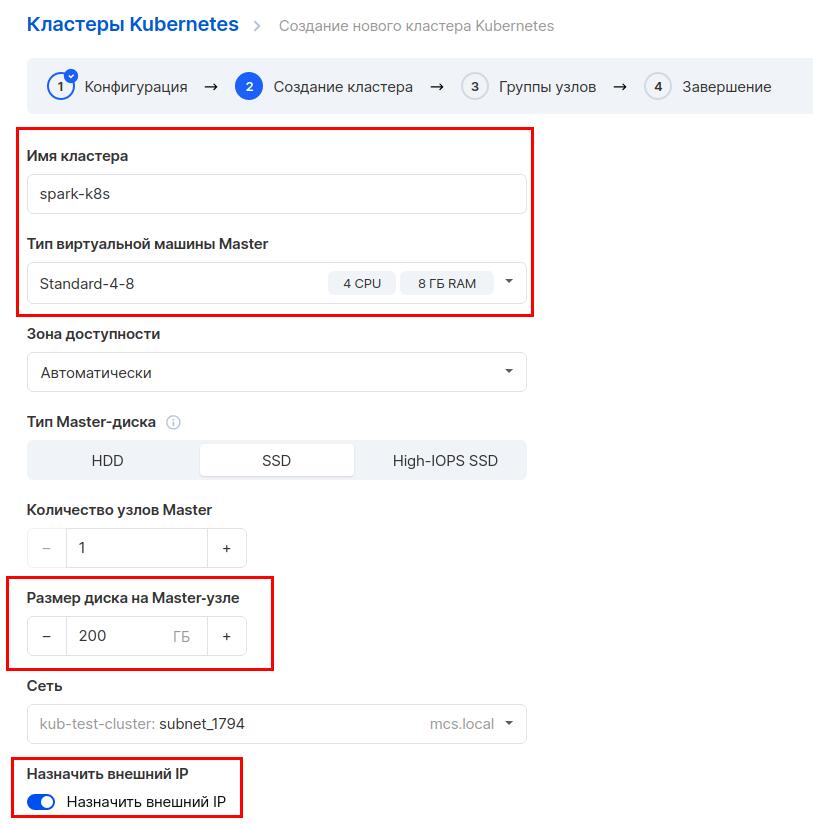
Далее выбираем конфигурацию кластера. Задаем имя кластера и тип виртуальной машины: 4 ядра и 8 Гб оперативной памяти. Можно выбрать и меньше, но для надежности рекомендуем такие значения. Выберем диск размером 200 Гб. Также отметим опцию «Назначить внешний IP», чтобы можно было управлять кластером через интернет.
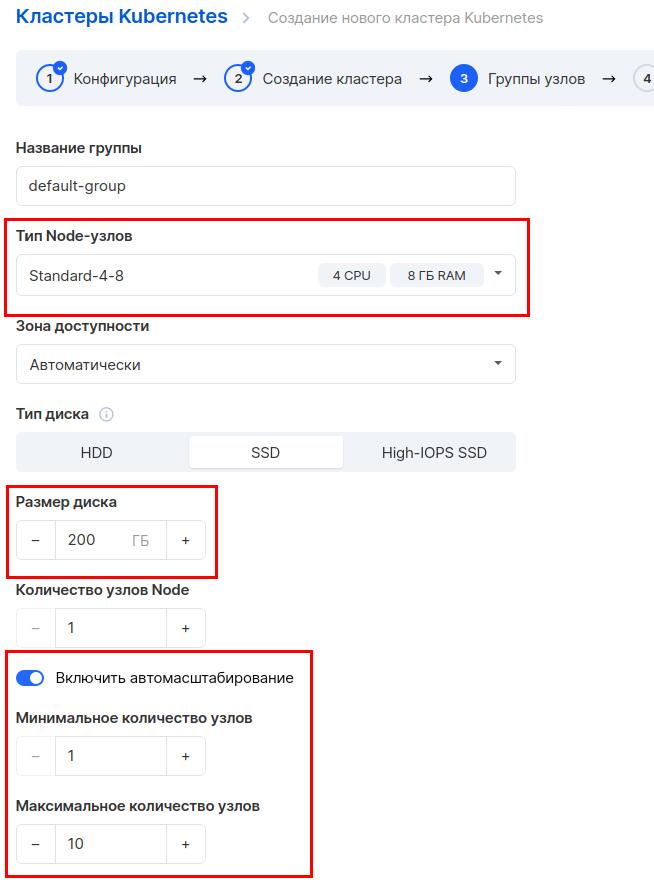
На следующем шаге указываем параметры для группы узлов. Также выберем 4 ядра и 8 Гб оперативной памяти, размер диска 200 Гб. Включим автомасштабирование, укажем максимальное количество узлов — 10. Это нужно, чтобы при возрастании нагрузки облако автоматически добавило к кластеру ноды, а после спада нагрузки автоматически их забрало.
Если у вас возникнут сложности, вот полная инструкция по созданию кластера Kubernetes.
Шаг 2: скачиваем Spark
Все дальнейшие действия мы будем проводить в виртуальной машине с ОС Ubuntu. Мы не будем подробно описывать процесс создания и подготовки ВМ. Вот что вам нужно будет подготовить:
Импортируйте конфигурационный файл, который вы получили после создания кластера.
Также вы можете развернуть все это на своей машине.
Теперь нам необходимо скачать Spark. Переходим на официальный сайт, выбираем версию 3.0.1 и сборку под Hadoop 3.2. Нажимаем на ссылку Download Spark.
Примечание: мы проверяли работоспособность именно на версии 3.0.1, а сейчас уже доступны 3.0.2 и 3.1.1. Мы их не проверяли, но думаем, что проблем с ними быть не должно.
Далее распаковываем скачанный архив:
tar -xvzf spark-3.0.1-bin-hadoop3.2.tgzОткроем файл ~/.profile на редактирование и добавим в него несколько переменных:
export SPARK_HOME=~/spark-3.0.1-bin-hadoop3.2
alias spark-shell=”$SPARK_HOME/bin/spark-shellЭтим мы задаем переменную SPARK_HOME, для того чтобы быстро получить доступ к директории со Spark. Также создаем alias для запуска Spark Shell. У меня еще задана переменная KUBECONFIG, для того чтобы kubectl мог работать с кластером Kubernetes.
Чтобы не перелогиниваться, применим файл явно:
source ~/.profileШаг 3: устанавливаем Spark Operator
Для установки Spark Operator мы воспользуемся Helm. Сначала добавим репозиторий:
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operatorДалее установим Spark Operator:
helm install my-release spark-operator/spark-operator --namespace spark-operator --create-namespace --set sparkJobNamespace=default --set webhook.enable=trueМы добавили параметр --set webhook.enable=true для того, чтобы Spark Operator мог изменять поды, монтировать к ним секреты, ConfigMap и так далее.
Далее нам нужно создать service account role и role binding:
#create service account, role and rolebinding for spark
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: spark-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["*"]
- apiGroups: [""]
resources: ["services"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-role-binding
namespace: default
subjects:
- kind: ServiceAccount
name: spark
namespace: default
roleRef:
kind: Role
name: spark-role
apiGroup: rbac.authorization.k8s.io
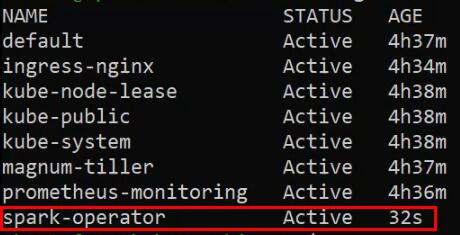
EOFПроверяем Namespaces:
kubectl get nsВидим, что появился Namespace spark-operator:
Теперь запустим демо-приложение, которое считает число ?. Для этого мы возьмем репозиторий от Google, где уже есть это приложение:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator spark-operatorЧтобы запустить приложение, применим YAML-файл:
kubectl apply -f spark-operator/examples/spark-pi.yamlПроверим, что под создается:
kubectl get podsМы видим, что под создается и находится в статусе ContainerCreating:

Теперь посмотрим логи этого пода:
kubectl logs spark-pi-driver | grep 3.1Мы видим, что приложение отработало и посчитало число ?:

Также через Kubernetes мы можем получить список всех Spark-приложений. Это возможно потому, что мы использовали Spark Operator. Kubernetes знает о том, что в нем работает новый тип ресурсов — spark applications.
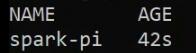
Итак, получим список всех Spark-приложений:
kubectl get sparkapplications.sparkoperator.k8s.ioВ нашем случае это только одно приложение:
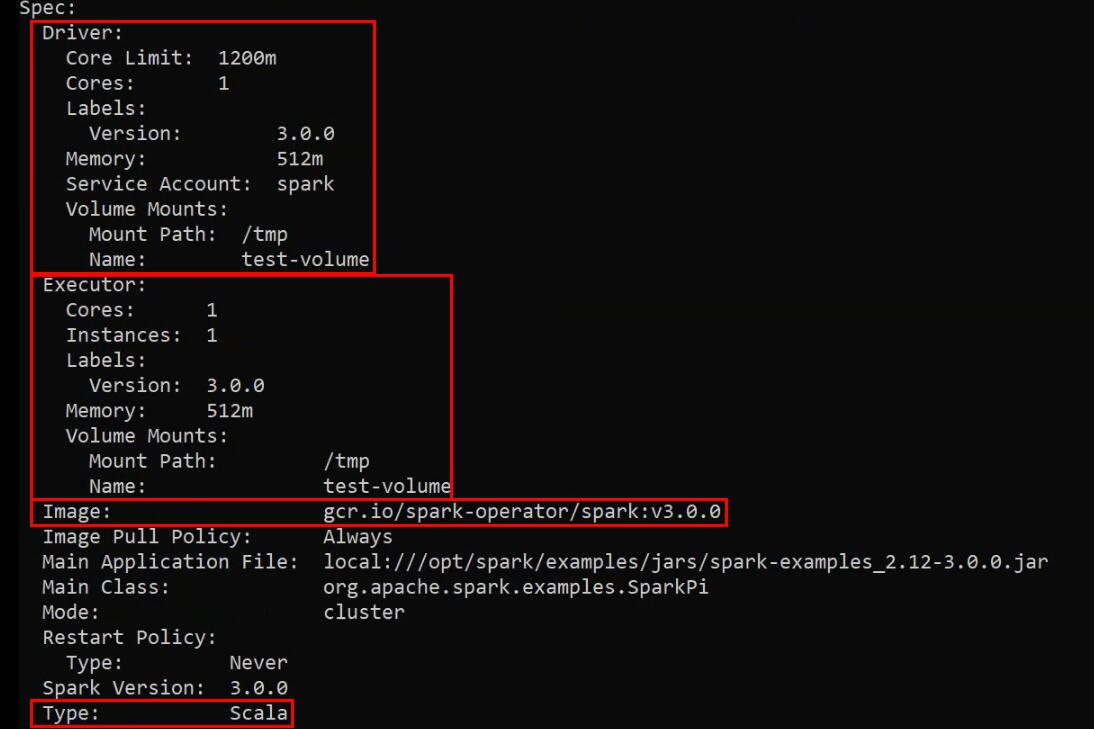
Теперь посмотрим различную информацию по этому приложению. Это опять же возможно благодаря Spark Operator:
kubectl describe sparkapplications.sparkoperator.k8s.io spark-piТут мы видим запрошенные ресурсы для Driver и Executor. Также видим образ, который использовался для запуска демо-приложения. И также видим, что мы запускаем приложение типа Scala (еще поддерживаются Python и R):
Ниже видим, какие стадии проходило приложение:

Шаг 4: собираем Docker-образ, запускаем свое приложение
Далее мы будем собирать Docker-образ с собственным приложением. Для этого мы подготовили репозиторий, клонируем его:
git clone https://github.com/stockblog/webinar_spark_k8s/ webinar_spark_k8sТеперь нам нужно перенести из этого репозитория папкуcustom_jobs в директорию $SPARK_HOME:
mv webinar_spark_k8s/custom_jobs/ $SPARK_HOMEЭто нужно, чтобы для сборки образа мы могли использовать утилиту docker-image-tool, которая поставляется вместе со Spark. Она устроена так, что внутрь Docker-context помещает только те файлы и папки, которые находятся внутри $SPARK_HOME. Одно из предназначений этой утилиты — минимизировать размер образа. Но также вы можете собрать собрать образ без нее, просто используя Docker.
Далее мы рассмотрим два простых приложения. Первое читает данные из бакета — выводит 10 первых строк датасета для ознакомления, а второе копирует датасет в другой бакет. Для этого нам понадобятся credentials для доступа к бакету, а также пути к ним. Если у вас еще нет S3-хранилища, вы можете создать его на платформе Mail.ru Cloud Solutions.
Сначала создадим Secret, в нем будут храниться credentials. Вместо PLACE_YOUR_S3_CRED_HERE подставьте ваши данные:
kubectl create secret generic s3-secret
--from-literal=S3_ACCESS_KEY='PLACE_YOUR_S3_CRED_HERE'
--from-literal=S3_SECRET_KEY='PLACE_YOUR_S3_CRED_HERE'Теперь создадим ConfigMap, в котором хранятся пути до бакетов. Вместо S3_PATH и S3_WRITE_PATH подставьте ваши данные:
kubectl create configmap s3path-config
--from-literal=S3_PATH='s3a://s3-demo/evo_train_new.csv'
--from-literal=S3_WRITE_PATH='s3a://s3-demo/write/evo_train_csv/'Теперь познакомимся с содержанием Python-файлов, которые мы будем помещать внутрь приложения. Переходим в папку custom_jobs и открываем файл s3read.py:
cd $SPARK_HOME/custom_jobs
nano s3read.pyМы видим, что приложение читает данные из бакета и выводит первые 10 строк. Для доступа к бакету мы используем переменные, которые указали ранее: S3_ACCESS_KEY, S3_SECRET_KEY и S3_PATH:
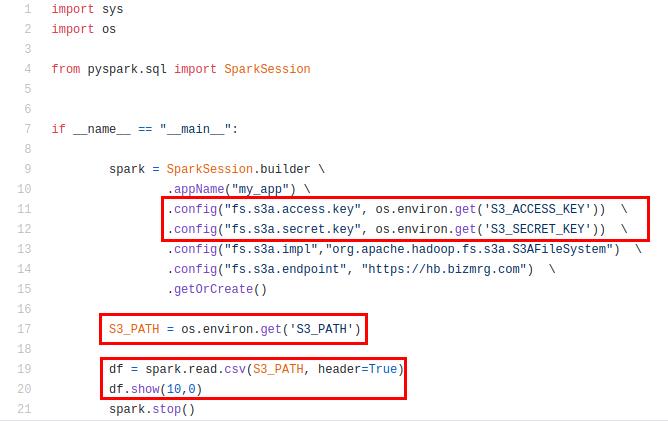
Второе приложение — s3read_write.py. Оно также выводит первые 10 строк из одного бакета и записывает датасет в другой. Для этого используется еще одна переменная S3_WRITE_PATH, в которой хранится путь до второго бакета.
Теперь познакомимся с содержимым docker-файла, который мы будем использовать для сборки:
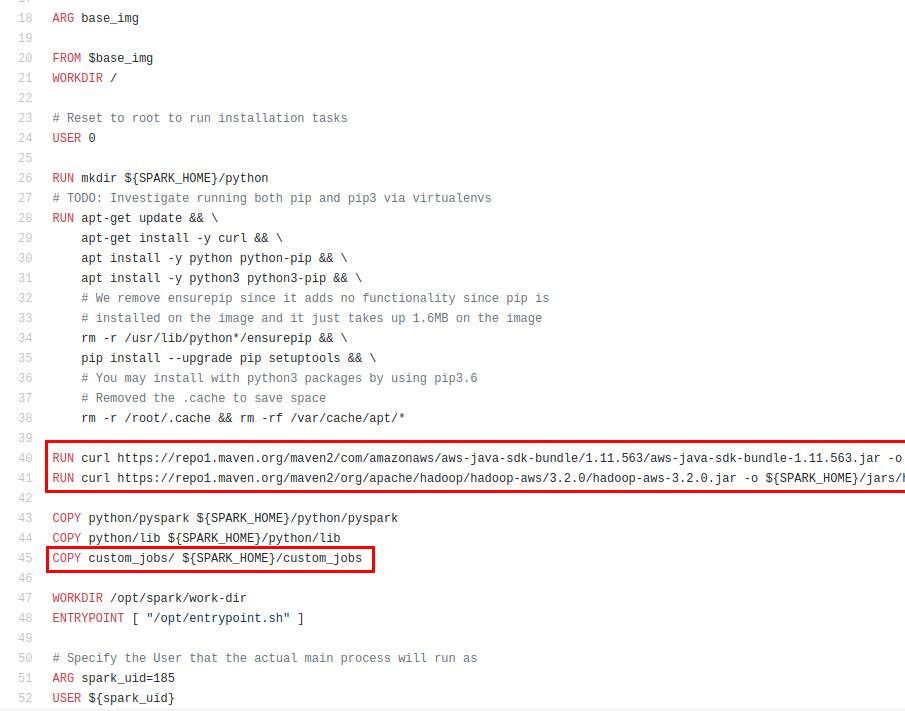
Он собран на основе официального Docker-файла, который идет в комплекте со Spark. Мы добавили в него JAR-файлы для доступа к S3, без них не получится подключиться к объектному хранилищу. Также мы копируем папку custom_jobs внутрь SPARK_HOME, для того чтобы код приложения попал внутрь Docker-образа.
Теперь будем собирать образ. Мы используем docker-image-tool — инструмент, о котором говорили выше. Мы указали тег webinar_spark_k8s и Docker-файл:
sudo /$SPARK_HOME/bin/docker-image-tool.sh -r $YOUR_DOCKER_REPO -t webinar_spark_k8s -p ~/webinar_spark_k8s/yamls_configs/Dockerfile buildВидим, что образ успешно собрался:

Далее мы опубликуем образ в DockerHub. Для начала зададим переменную DOCKER_REPO, в которой хранится имя репозитория. Вы можете использовать публичный или приватный репозиторий. Вот инструкция, как залогиниться в приватный репозиторий. Мы будем использовать наш публичный репозиторий mcscloud:
export DOCKER_REPO=mcscloudТеперь отправим образ в репозиторий:
sudo /$SPARK_HOME/bin/docker-image-tool.sh -r $DOCKER_REPO -t webinar_spark_k8s -p ~/webinar_spark_k8s/yamls_configs/Dockerfile pushТеперь, когда мы запушили образ в репозиторий, мы будем использовать его, чтобы развернуть в Spark. Такой подход позволяет нам запускать Spark Jobs стандартным для Kubernetes способом — декларативным. Это означает, что мы декларативно описываем состояние Job, а Kubernetes уже сам будет приводить ее к желаемому состоянию. Это возможно благодаря тому, что мы используем Kubernetes Operator.
Перейдем в директорию yaml_configs и посмотрим на содержимое файла s3read_write_with_secret_cfgmap.yaml. На основе этого файла вы сможете создавать свои:
cd webinar_spark_k8s/yaml_configs
nano s3read_write_with_secret_cfgmap.yaml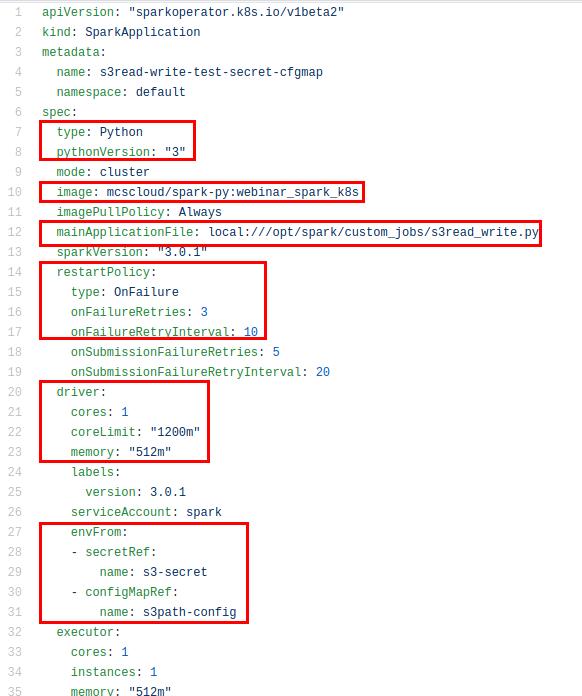
В этом файле видно, что мы используем Python третьей версии. Мы используем образ, который только что запушили в репозиторий. Наше приложение s3read_write.py находится внутри этого образа в папке custom_jobs. Далее мы задаем restart policy: если приложение упадет, оно будет перезапущено три раза с интервалом в 10 секунд.
Также мы задаем требования по ресурсам, отдельно для Driver и Executor. Для доступа к S3 мы указываем названия credentials и ConfigMap, в которых у нас хранятся данные для доступа к хранилищу: s3-secret и s3path-config. Они также задаются отдельно для Driver и Executor.
Есть более простой способ указать эти переменные. Рассмотрим файл s3read_example_one.yaml:
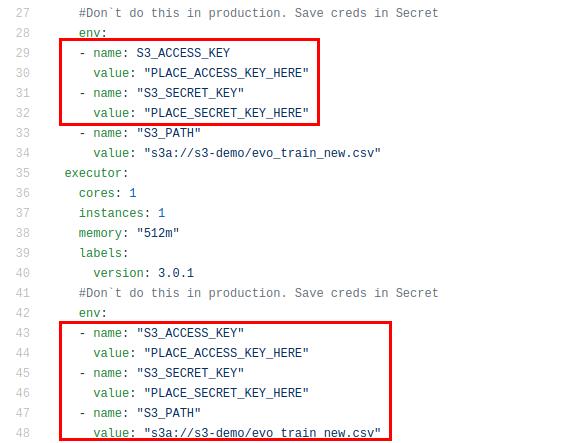
Здесь все то же самое, но переменные окружения объявлены явно внутри YAML-файла. Мы не рекомендуем так делать в продуктовых средах, но на этапе тестирования или проверки MVP можно попробовать.
Теперь запустим приложение, применив YAML-файл:
kubectl apply -f ~/webinar_spark_k8s/yamls_configs/s3read_write_with_secret_cfgmap.yamlПриложение создалось:

Теперь посмотрим список подов в Kubernetes:
kubectl get podsВидим, что сейчас создается контейнер с приложением:

Теперь снова проверим список Spark-приложений:
kubectl get sparkapplications.sparkoperator.k8s.ioВидим, что приложение только что запустилось, 13 секунд назад:

Опять посмотрим список подов:
kubectl get podsВидим, что Driver уже работает, сейчас создается Executor:

Если через некоторое время еще раз проверить список подов, мы увидим, что контейнер уже создался и приложение находится в статусе Running, значит, оно работает:

Мы можем выполнить команду kubectl get events и увидеть все события, которые связаны с приложением: как оно стартовало, нет ли ошибок, когда добавлялись поды и так далее. Вы можете посмотреть это сами, мы не будем приводить скриншот.
Через некоторое время снова проверяем поды:
kubectl get podsТеперь все поды в состоянии Completed, значит, приложение закончило работу:

Посмотрим логи:
kubectl logs s3read-write-test-driverВидим, что приложение отработало успешно. Оно вывело в лог первые 10 строчек из бакета:
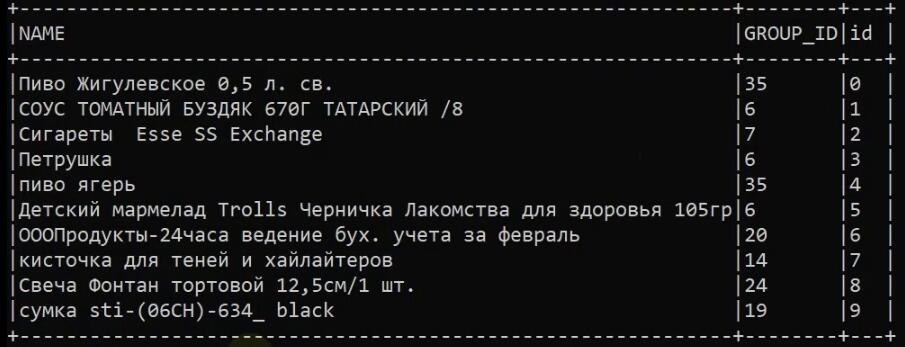
Теперь проверим, что оно записало этот датасет в другой бакет. Напомним, что в ConfigMap мы указали название нашего бакета — s3-demo — и папку, куда нужно складывать файлы, — write/evo_train_csv. Заходим в бакет и убеждаемся, что файлы создались:
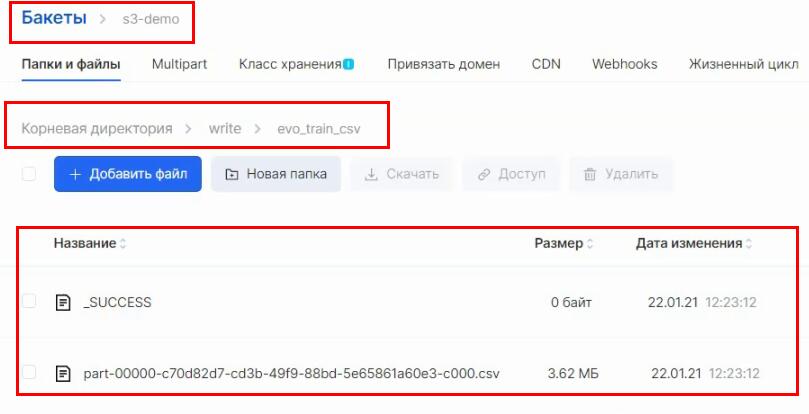
Итог: наше кастомное Spark-приложение запустилось и работает в Kubernetes.
Шаг 5: устанавливаем Spark History Server
С нашим приложением есть одна сложность. Если под, на котором оно работает, будет уничтожен, все логи также пропадут. Поэтому мы будем перенаправлять логи в отдельный S3-бакет, а для просмотра будем использовать Spark History Server, который мы также развернем в Kubernetes.
Чтобы разделить приложение и History Server, мы создадим в Kubernetes отдельный Namespace, это как бы виртуальный кластер внутри Kubernetes. Namespace позволяет разделять объекты, ресурсы, доступы и так далее.
Создаем Namespace:
kubectl create ns spark-history-serverПроверим, что он создался командой kubectl get ns:
Для того, чтобы Spark History Server мог читать логи из S3, нам нужно снова создать Secret с нашими данными для доступа к объектному хранилищу. Мы уже создавали такой Secret ранее, но так как History Server находится в другом Namespace, он не сможет получить к нему доступ.
Создаем новый Secret, указываем только что созданный Namespace. Вместо PLACE_YOUR_S3_CRED_HERE укажите свои данные:
kubectl create secret generic s3-secret
--from-literal=S3_ACCESS_KEY='PLACE_YOUR_S3_CRED_HERE'
--from-literal=S3_SECRET_KEY='PLACE_YOUR_S3_CRED_HERE' -n spark-history-serverПроверим, что Secret создан с помощью kubectl get secrets -n spark-history-server:

Теперь перейдем непосредственно к установке Spark History Server. Для этого мы снова воспользуемся Helm. Добавим репозиторий:
helm repo add stable https://charts.helm.sh/stableЧтобы установить Spark History Server, сначала нужно изменить нужные нам настройки. Для этого мы воспользуемся файлом values-hs.yaml. Переходим в папку с файлом и открываем его на редактирование:
cd webinar_spark_k8s/yamls_configs/
nano values-hs.yamlМы прокомментируем настройки, чтобы вы знали, что вам нужно будет поправить. Во-первых, активируем S3. Далее указываем бакет и директорию с логами. Далее указываем название Secret, в котором хранятся credentials. Далее указываем тип сервиса — LoadBalancer. Это значит, что History Server будет доступен по внешнему IP:
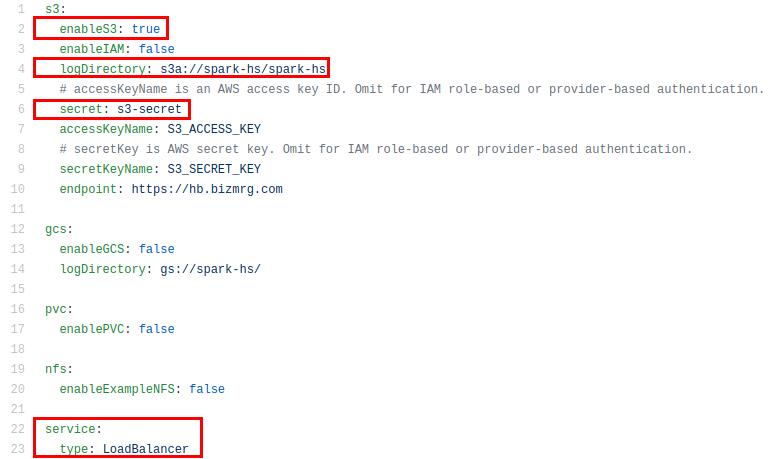
Еще один важный момент. В этом файле сейчас не указан способ авторизации, поэтому на сервер сможет зайти любой, если узнает его адрес. В продуктиве мы так делать не рекомендуем, но для тестирования можно пока оставить так.
Теперь мы применяем этот файл:
helm install -f ~/webinar_spark_k8s/yamls_configs/values-hs.yaml my-spark-history-server stable/spark-history-server --namespace spark-history-serverТеперь нам нужно узнать, по какому IP-адресу доступен History Server. Для этого выполняем команду:
kubectl get service -n spark-history-serverВидим, что Cluster-IP уже выделен, а внешнего адреса еще нет. Облако генерирует его:

Подождем несколько минут и повторим команду. Теперь мы видим IP-адрес и порт, на который нужно зайти:

Переходим в History Server, в нашем случае по адресу http://87.239.106.171:18080. Мы видим, что он работает, но в нем пока нет логов:

Чтобы они появились, нам нужно немного изменить наше приложение. Мы сделаем так, чтобы оно писало логи в определенный S3-бакет. Для этого мы создали файл s3_hs_server_test.yaml.
Он практически идентичен нашему предыдущему YAML-файлу за тем исключением, что мы добавили секцию sparkConf и в ней указываем, куда нужно писать логи. Опять же, для упрощения мы прописываем наши credentials в явном виде, но в продуктивном использовании так делать не рекомендуется:
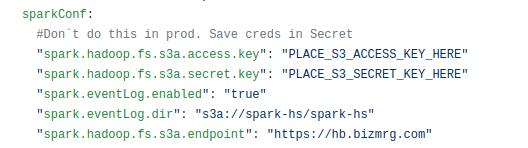
Теперь применим этот файл:
kubectl apply -f ~/webinar_spark_k8s/yamls_configs/s3_hs_server_test.yamlПосмотрим на состояние подов:
kubectl get podsВидим, что приложение в процессе работы:

Ждем некоторое время, проверяем поды снова. Видим, что запустился и Executor:

Ждем некоторое время и проверяем логи:
kubectl logs s3read-write-hs-server-test-driverВидим, что приложение отработало и вывело 10 первых строк из бакета:
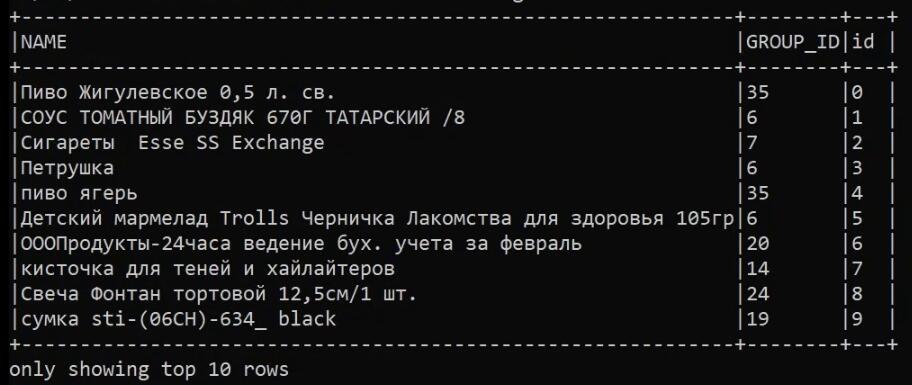
Переходим в History Server. Видим, что появилась запись о выполненном приложении:
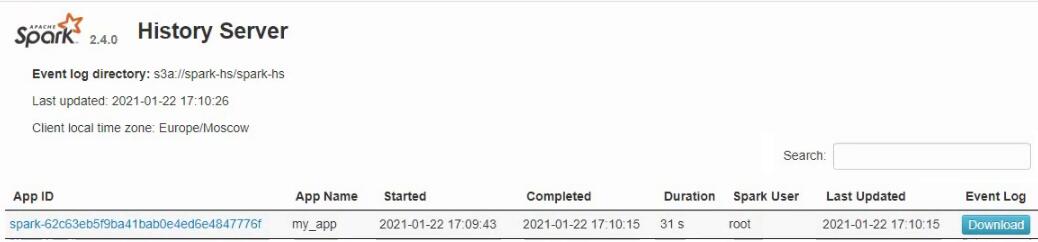
Мы можем нажать на ссылку в столбце App ID и посмотреть все логи:
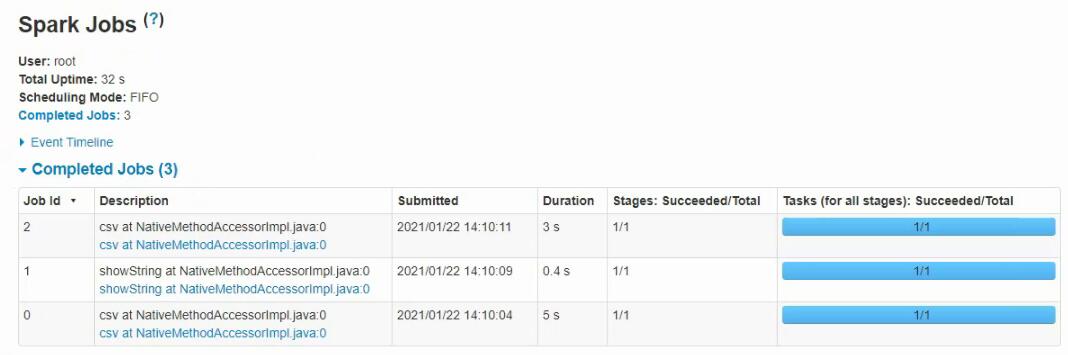
Тут мы можем получить всю информацию о работе приложения для полноценной отладки.
Результат
Spark в Kubernetes позволяет изолировать рабочие среды, управлять ограничениями приложений и получить гибкую масштабируемую систему. В этой статье мы установили Spark в Kubernetes, обернули свое приложение в Docker-образ и запустили его Native-способом для Kubernetes.
Новым пользователям платформы мы дарим 3000 бонусов после полной верификации аккаунта. Вы сможете повторить сценарий из статьи или попробовать другие наши сервисы.
Что еще почитать по теме: