У бизнес-разработчиков за дедлайнами, сроками, клиентами и большими запусками может складываться впечатление, что инфраструктура выстраивает свой воздушный замок, который далек от того, что происходит в действительности. Захотев это изменить, Алексей Данилов из команды разработки перешел в команду инфраструктуры — последние два года он развивает ее в Яндекс.Вертикали — а это Яндекс.Работа, Яндекс.Недвижимость, auto.ru и Яндекс.Объявления.
Особенность Яндекс.Вертикалей — ребята одновременно и бизнес-юнит Яндекса, и обычная IT-компания. Благодаря первому, у них есть возможность использовать яндексовую инфраструктуру, но, благодаря второму, разработчики смотрят на весь стек и используют то, что им удобно. Алексей сегодня поделится с нами, как это можно сделать более удобно и ближе к пользователям (в его случае — к разработчикам). А также о том, почему на инфраструктуру сейчас надо смотреть как на продукт и какие вызовы это приносит команде, но и что это дает в конечном итоге компании.

Infrastructure
Под инфраструктурой я подразумеваю всё, что окружает бизнесовый код и помогает ему от начала разработки фичи до момента ее доставки. Это и базы данных, и балансировка, и мониторинг, и CI с CD. Сюда же относятся особенности разработки/работы, библиотеки, тестирование, бизнес аналитика, бизнес-специфичные возможности и много чего еще. Это как завод, на котором вместо ручного труда автоматизированы все процессы, и результат мы получаем более быстрый и более качественный.
При этом я рассматриваю инфраструктуру как единую платформу, а не набор разрозненных частей, которые я перечислил выше. И это уместно для компании любого размера. В облаках — Amazon Web Services, Yandex Cloud — автоматизация может строиться, например, на основе terraform. У вас может быть собственное железо или вы его где-то арендуете — и на нем может быть развернут Kubernetes, Nomad, что-то еще. Команда тоже может быть любой — от нескольких человек, которые в основном используют bash или terraform, и до сотен, со своими велосипедами.
И тогда возникает вопрос — как добиться идеальной инфраструктуры Platform as a Service, который мы реализуем для наших пользователей, и вообще — каковы критерии идеальности? Нам не нужно разрабатывать еще один Amazon или Kubernetes — поэтому достаточно небольшой и простой системы, но у нас должна быть возможность ее расширения под наши use cases. Например, если у нас есть какие-то особенные АБ-тесты, особенные условия доставки (например, канареечный релиз ) и особенные правила безопасности — это как раз то, что должна закрывать инфраструктура.
Ее основой, краеугольным камнем будут минимизация/ускорение разработки, упрощение поддержки и простота использования. Остальные требования — понятность, доступность, стабильность и единообразность/распространение практик, а также скрытие низкоуровневых особенностей (чтобы никому не пришлось писать самому конфиг nginx или сложный Kubernetes манифест), техническая поддержка 24*7 и связанность компонентов — конечно, тоже имеют место.
Если выполнить их все, ваша инфраструктура будет не только единой платформой или сервисом, но постепенно будет превращаться в продукт, как это случилось у нас.
Infrastructure/Platform as a product (PaaP)
Сначала мы, конечно, смотрели в сторону сторонних приложений. Например, мы серьезно рассматривали Spinnaker от Netflix. Но он написан на Java, а у нас все пишут на Go, и мы не хотели добавлять еще один язык. Во-вторых, он не поддерживает Nomad и Yandex.Cloud. Следовательно, нам пришлось бы его прилично дорабатывать и интегрировать с нашими внутренними особенностями, что практически равно форку. Поэтому мы стали писать свое.
Изначально мы задумывали Shiva как абстракцию над деплоем (в нашем случае над Nomad) и как multicloud. Но сейчас она уже приросла различными системами и интегрируется со всем, что у нас внутри есть:

Основная ее часть представлена в GitHub в виде карты сервисов. Она изменяется посредством пул-реквестов, конфигурирует балансировку, контролирует деплой и различные пайплайны доставки, SOX, PCI DSS и т.д. То есть это одно описание для полноценной работы:

Архитектура Shiva в упрощенном виде выглядит так:

Сервис постоянно развивается и сейчас он уже частично похож на продуктовый: есть БД, вокруг которой построены различные микро-сервисы, есть небольшие legacy-компоненты (компонент Updater и Shiva смотрят в одну базу) и т.д. То есть с технической точки зрения он развивается как обычный бизнесовый сервис.
UI мы реализовали в Telegram, а впоследствии написали WEB’овский. Telegram-бот — это CLI over Telegram — все команды задаются в формате CLI, но дополнены различными контекстными действиями, кнопками и т.д. Нам нравится этот подход, потому что он кросс-платформенный, его легко обновлять и к нему всегда есть доступ. Можно спокойно обновить или откатить свой сервис в случае проблем. А также очень удобный механизм нотификации, когда вы получаете уведомление о начале процесса деплоя прямо в тележку.
И хоть WEB и получился удобным, все равно часть пользователей остается в Telegram. Потому что UX меняется — в профессию приходит очень много молодых разработчиков. Мы привыкли к WEB, мы привыкли использовать Telegram-боты и вообще общаться в чате. С другой стороны, мы хоть и думаем сделать CLI с такой же функциональностью, но понимаем, что запросов на это не было.
Экономика
Когда встал вопрос об экономике, то первое, о чем мы подумали — модная сейчас юнит-экономика: ее используют при создании стартапа, чтобы понять, насколько он экономически выгоден. К тому же это очень удобный фреймворк:

Но у инфраструктуры нет доходов, тогда как на этой схеме есть и доходы, и расходы. Доход от инфраструктуры равен 0 — это расход компании, — а ROI будет отрицательным: сколько инвестиций не вкладывай, они не отбиваются:
Profit = Revenue - Cost = 0 - X
Есть, конечно, плюшки в виде, например, бесконечного LTV (LifeTime Value) — то есть наши клиенты от нас никогда не уйдут. Но в целом эта метрика нам не подходила, и мы стали думать в сторону velocity (скорость разработки), потому что ее довольно легко преобразовать в деньги. Например, если мы ускорили разработку на час в неделю, то это нетрудно соотнести со средней зарплатой у 500 разработчиков и получить какой-то видимый профит. Вообще инфраструктура — это именно velocity, то есть скорость доставки ценности пользователю. Но у нас это не глобальная метрика, потому что velocity зависит от очень многих факторов. : Если смотреть сверху, то можно выделить:
code — время написания самой логики ;
infrastructure code — время написания инфраструктурного кода (код логов, метрик, алертов и т.д.)
environments — время на настройку переменных окружения, секретов и т.д.;
delivery — время, затраченное на доставку.
На последние три пункта инфраструктура влияет напрямую и может существенно упростить или ускорить их. Для примера рассмотрим механизм проверки новой конфигурации для сервиса. Сначала наша карта сервисов проверялась небольшим скриптом, и далее ее уже должен быть допроверить человек. Но там, где есть работа реального человека, Velocity стремится в 0, а скорость разработки сильно снижается. Поэтому, если у вас деплой или изменение конфигурации (базовые повседневные вещи) завязаны на тикеты или другие инструменты, где есть влияние ожидание работы человека — это те точки роста, которые нужно сразу же автоматизировать.
В нашем случае мы написали GitHub-бота, который с очень большим спектром валидации проверял эту карту и мгновенно отвечал: либо всё хорошо, либо есть какие-то конфликты с другими картами и сервисами:
Следующим нашим пунктом разработки инфраструктуры как продукта стало внедрение user story.
User story
User story — это фундамент любой продуктовой разработки и используется он в любых гибких методологиях идущих от Agile. Это не детальное описание задач — давайте прикрутим здесь кнопку, которая будет делать вот это. User story — это намерение пользователя: какую проблему пользователь решал, как он пытался её решать, почему он её решал, почему она возникла, и, наконец, как мы можем её решить. Разумеется, из user story выводится очень много различных решений. Но сам User story не является им — это основа для решения и инструмент для выявления исходной проблемы.
В бизнесовой разработке user story пишется на повседневном и понятном пользователю языке. Для нас здесь была небольшая ловушка, потому что наши пользователи — разработчики, они очень грамотные и могут принести любую историю — вплоть до того, что надо внести изменения в БД. Поэтому мы должны были обязательно вытягивать основную проблематику — находить инкремент ценной функциональности, реализуемой за короткий срок.
Приведу для примера две наши внутренние истории.
Пример 1. «Залипает обработчик Кафки. Чинится только рестартом сервиса. Фикс в пути. Хочется иметь способ быстро перезапустить контейнеры».
Проблема была понятной и мы предложили сделать команду restart -l prod my_service, в которой указывается слой сервис, чтобы сервис рестартился через телеграм бота.
Пример 2. «При обновлении конфигурации хочется перезапустить сервис без указания версии».
Решением стало: /run -l prod -v 1.0.7 my_service -> /run -l prod my_service.
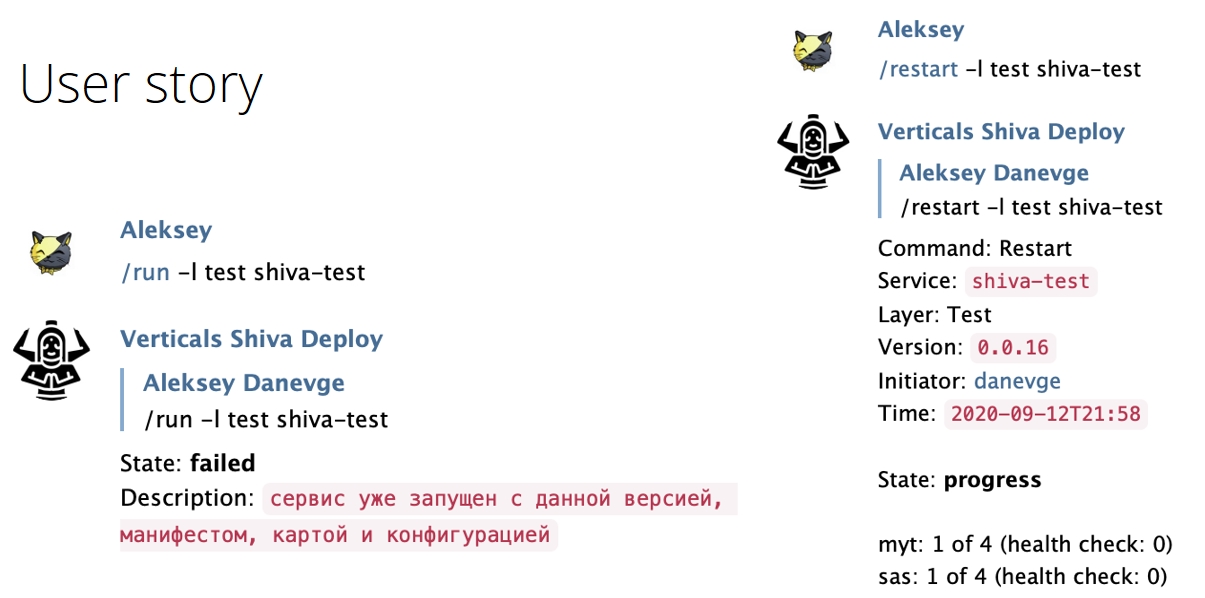
Но изначально это выглядело как одна задача: сделайте нам такую команду для рестарта, после которого сервис притягивает новую конфигурацию. С точки зрения обычной таски это можно было сделать, а с точки зрения user story — нельзя, потому что в первом примере люди видят проблему и периодически рестартят свой сервер, пытаясь найти, что же здесь не так. Если при этом приедет новая конфигурация, это принесет им куда больше проблем, то есть мы можем сделать хуже.
Поэтому первое, что мы сделали — это идемпотентный рестарт, который ничего не подтягивал и при этом гарантировал, что конфигурация будет идентична. А вторым стал run, который можно указать без версии версии и он подтянет новую конфигурацию (новые переменные окружения, новые секреты и обновит остальное окружение). Более того, когда мы в дальнейшем их разделили, то user story с запуском из версии модифицировали и развили так, что run стал гарантировать изменение сервиса. А если ему нечего изменять и нечего подтягивать, то он об этом честно говорил.
То есть разделяя user story, мы можем их по фидбэку развивать дальше. Но даже просто использование user story дает огромный профит, так как мы начинаем слышать пользователя о его проблеме. Но если общаться с пользователями и вместе находить решение — не каждая user story будет реализована, и не каждая — так, как мы придумали.
Customer development (сustdev)
Инструмент сложный в продуктовой разработке, но в случае инфраструктуры он очень прост — потому что мы разрабатываем новый продукт (фичу, решение или какую-то часть нашей системы) не сразу через код, а через пользователя. Можно даже провести ниндзя-сustdev, находясь в переговорке в ожидании какой-нибудь встречи или попивая кофеечек на кофе-поинт. Да и сам процесс не очень сложный:
Выявляем потенциальную проблему (строим гипотезу), формируем идею или решение, но не внедряем ее, а идем к пользователям, чтобы поговорить с ними об их потребностях/болях/проблемах.
Встречаемся с ними, например, на кофе-поинте или на рабочем месте. Можно пообщаться и в Зуме. И в обсуждении можно обнаружить, что проблема пользователям не важна — она не так много времени занимает и не так сильно его напрягает, но зато у него есть более важные проблемы.
Прорабатывая решение вместе, мы получаем либо изначальное успешное решение (если определили проблему верно) или более успешное (поняв из общения, что волнует пользователей) — то есть в выигрыше все.
Например, у нас не было истории деплоев, и мы понимали, что нам она нужна. Мы напридумывали очень много сложных вещей, вплоть до того, чтобы в Telegram с помощью пейджинга показывать список последних 10 сервисов и уже думали, как же их спейджить туда-обратно и т.д. Но пообщавшись с разработчиками, мы поняли, как история начинается у большинства из них: они видят на графиках аномалию — и м нужно посмотреть, не было ли деплоя — не новая ли версия принесла эту аномалию?

Эта история решилась довольно просто. Мы добавили время деплоя в аннотации на Grafana, и теперь видя какую-то аномалию, можно понять, не было ли деплоя, в том числе деплоя зависимых сервисов. Эта история, кстати, ускорила у нас создание WEB UI.
А потом мы пообщались с тимлидами и выяснили, что они это видят совсем по-другому:
— Developer: «Я вижу по графикам проблемы — нужно проверить, не связано ли это с выкаткой новой версии» (см. график выше).
— Team leads: «Нужна возможность посмотреть кто, что, когда и зачем катил в прод»:
Для тимлидов эту историю со списком, сложными фильтрами, поиском и т.д. мы реализовали намного позже. Потому что, во-первых, наш основной пользователь — это обычный разработчик — тот человек, который каждый день пишет код, делает фичи, раскатывает их, дежурит, заботится о сервисе и т.д. А во-вторых, это был уже этап, когда мы начали выделять и использовать портреты пользователя, а затем — и портреты сервисов.
Портреты пользователей и сервисов
И то, и другое сложно реализуется в продукте, но легко и быстро — в инфраструктуре. Портреты пользователей у нас были довольно простыми:
Разработчики: бэкенд, фронтенд и инфраструктура;
Team leads;
Тестировщики/Автотестировщики;
Аналитики;
Менеджеры, продукты, руководители.
По сути — частичное отражение рабочих позиций :)
А портреты сервисов можно классифицировать по типу, языку или размеру. Первые бывают внутренними (realtime api, back api, async, cron, gateway, и т.д.), DB, внешними, saas и т.д. И они — богатая точка роста, потому что это место отказа каких-то инфраструктурных частей. Это и наша точка роста, которую мы рассматриваем в будущем для себя.
Языки разработки мы рассматриваем нечасто, но иногда приходится смотреть: почему эта история возникает, у кого она возникает, — потому что, например, у java и node.js бывают небольшие различия в работе, и это приходится учитывать.
По размеру портреты сервисов могут быть: function, microservice, service, monolith, distributed monolith и т.д. И если мы, например, понимаем, что проблематика идет из распределенного монолита, то отказываем в этой истории, потому что у нас хорошей практикой считаются мироксервисы и нашим PaaS мы популяризируем и упрощаем жизнь именно с ними..
Вот для примера портрет сервиса БД. С помощью этой карты ставятся бэкапы, происходит доступ к БД на чтение/запись и т.д. Плюс, сам сервис в свои зависимости прочерчивает эту карту, и мы знаем, что это за карта и от чего она зависит — то есть, мы знаем, что сервис А зависит от базы данных В:

Feature request
Но одно дело — найти проблему. Совершенно другое — когда приносят уже готовое решение. Это самая богатая тема, которую можно использовать себе на благо.
Конечно, у нас есть проблемы:
Технически грамотный пользователь может принести уже готовое решение, например: «Сделайте такой API, в БД все сохраните, и на этом хватит».
Личное знакомство — потому что иногда мы отказываем в feature request или говорим, что будем делать по-другому, — и возникает небольшой конфликт.
Но есть и решения:
Превращать в user story — находить проблематику: узнавать, с какой проблемой столкнулся пользователь и как пытался решать;
Смотреть на доработку в контексте портретов — кто к нам пришел, что за сервис, о чем идет речь;
Спорную доработку или ту, в которой мы не уверены, проверять через castdev, потому что все-таки feature request приносит один пользователь и непонятно, насколько это ценный функционал для всех;
Механизм голосований/рейтинга — это самый мощный инструмент. Он не нов, используется во всех хороших продуктовых разработках, например, в терминале Тинькофф-Инвестиции. У них открытые feature request, где люди открыто голосуют — и в итоге в работу идут те, что в топе:
Внутри это также можно легко реализовать, потому что мы работаем в рамках одного issue-трекера. Например, здесь фильтры по нашим feature request:
Из интересного: мы недавно этот вид сделали через наш WEB не таким формальным и увидели, что люди с большей охотой голосуют за идеи — то есть это тоже важно:

Механизм feature request очень удобно использовать как часть синергии с пользователем — и нам не нужно будет сильно прорабатывать такую историю — ведь очень много пользователей проголосовали за нее. Мы можем видеть, кто голосует — и это могут быть разные люди, которые поддерживают разные сервисы. Получается в итоге даже небольшой scoring функциональности — мы точно понимаем и то, что она нужна, и зачем, и насколько это нужно пользователям. Голосование к тому же может заменить множество внутренних исследований — таких, как сustdev.
Roadmap
Хочу отдельно сказать про Roadmap. Это кажется довольно банальной темой, но пообщавшись с разными компаниями, я обнаружил, что у команды инфраструктуры часто не бывает долгосрочного видения. Есть понимание, что они делают через неделю или месяц, но нет понимания, какой должна быть в итоге инфраструктура. И обычно это инфраструктура посредством одной кнопки, когда все описано в GitHub-репозитории и сделана она, например, на CI сборках. Куда стремиться — непонятно.
Ценность даже не в самом плане, а в процессе планирования. Когда мы планируем, мы думаем, что хотим дать пользователям, поэтому roadmap удобно сделать открытым — можно сразу получить фидбэк. Мы можем расставить истории по приоритетам, фидбэк может сказать нам, что большинству намного важнее то, что мы отложили. Так что публичные и регулярно обновляемые планы помогут вам скорректировать roadmap и строить долгосрочный бэклог на его основе.
Кстати, как получать обратную связь?
Тикеты и подписки на них. В нашем случае это самый рабочий инструмент, потому что мы работаем в одной компании, и в одном трекере.
Большие посты – анонсы. Несколько раз в квартал мы делаем большие анонсы, где рассказываем про всю большую функциональность и опять же получаем фидбэк. Иногда мы получаем негативные отзывы, например: «Зачем вы это делаете, если можно взять вот это и то». Тогда мы либо объясняем, либо понимаем, что, может и правда можно реализовать более просто.
У нас есть групповой чатик в Telegram/Slack/Microsoft Teams. В основном мы там собираем обратную связь, хотя он работает как инструмент технической поддержки, а также в нем выкатываем нововведения с небольшими инкрементальными релизами.
Открытые встречи для вопросов/ответов. Мы пока что провели её только один раз, но результат был неплохой.
Еще можно встречаться на демо продуктовой разработки и там отвечать на вопросы. Но мы не проводим демо —сейчас для нас это большая потеря времени.
Еще можно использовать индекс потребительской лояльности NPS (Net Promoter Score). Это простые анкеты: насколько вы удовлетворены нашим сервисом, насколько вам удобно — базовые вопросы для того, чтобы собрать общую статистику лояльности пользователей. Мы не используем NPS, потому что из чата получаем и критику, и позитив, а остальных записываем как нейтральных пользователей.

MVP
После планирования хочу напомнить про инструмент MVP (Minimum Viable Product). Это известный подход, но в инфраструктуре есть нюансы. Мы, как любой бизнесовый продукт, выкатываем «частично недоделанный продукт», где-то не самый удобный, но — минимально рабочий. Потому что мы не можем делать 2-3 месяца какую-то историю, выкатить её, получить средний фидбэк и потом еще месяц переделывать:

Поэтому мы стараемся поддерживать максимально инкрементальные релизы для того, чтобы потихонечку двигаться к тому функционалу, который запланировали в будущем и который, опять же, всем известен. А получая фидбэк, мы успеваем его корректировать:

Например, когда мы резолвили свой первый WEB, его функциональность была далека от функциональности Telegram, да и выглядел он неказисто, если честно. Но впоследствии он развивался, мы получали фидбэк, и в результате даже пошли по другому пути, потому что UXe (пользовательский опыт) отличается от того, что было в Telegram, и от того, что есть в WEB.
WEB сейчас поддерживает тот же самый функционал, но он в той или иной мере реализован в WEB немного по-разному. Плюс, он расширился: в нем есть истории деплоев, работа с картой и манифестом, с переменными окружения и т.д.

Overkill
Важно понимать, когда продуктовый подход становится слишком сложным. Бизнесовые команды становятся настолько большими, что состоят из множества людей с разной направленностью и спецификой. Есть product owner, цель и задачи которого — выстраивать roadmap и определять, какие из историй делаются. Есть product менеджер, UX-специалисты, разработчики, тестировщики и т.д. Когда большие истории разбиваются только по user story и пытаются делать с добавлением какой-то пользовательской ценности. Всё это очень круто, но сейчас для нашей команды это — overkill. Как в принципе, и A/B-тестирование.
Поэтому нужно четко определять, что мы используем, а что — нет. Для небольших команд инфраструктуры, как наша, есть лайфхаки, которые помогают иметь результат не хуже:
Стараться понять: «Зачем?» То есть не «Разработчик хочет 500 Тб БД», а: «Разработчику нужно сохранять информацию о машинках (которую мы никогда не сохраняли) — тогда мы сможем работать вместе над одной проблемой пользователя»
Добавить в команду «продуктового» разработчика, потому что DevOps расширяется, кода мы пишем сейчас больше, и нужен разработчик, который пропитан этой атмосферой.
Добавить в команду фронтендера, понимающего в той или иной мере в интерфейсах. Да, это не профессиональный дизайнер, но для инфраструктуры этого достаточно.
Обязательно нужен механизм голосования за идеи для того, чтобы упростить scoring задач.
Собирать roadmap и сделать его открытым.
Периодически собирать аналитику — не сложные и большие графики, — но чтобы плюс-минус понимать, что происходит у пользователей.
Нужно много автотестов , так как я все еще не представляю вакансии тестировщика в команде инфраструктуры, как и дизайнера — по крайней мере в 2021 году.
И основной пойнт — больше синергии с пользователями. Потому что хорошую инфраструктуру ограниченной командой с ограниченными ресурсами можно делать только в синергии с пользователями — вытаскивая самые ценные истории.
Итог
В заключении рекомендую книгу «Психбольница в руках пациентов» Алана Купера — я ее прочитал очень давно и с огромным удовольствием, она меня вдохновила. Сейчас настало время, когда ее стоит рекомендовать не только product owner, продуктовым разработчикам, дизайнерам, но и команде инфраструктуры. Там очень много полезных примеров, в которых можно найти себя.
Подытоживая:
Разговаривайте со своими пользователями, находите проблематику — надо искать проблемы, а не решения.
Относитесь к внутренней инфраструктуре как к единой платформе, как к единому PaaS.
Разрабатывайте PaaS как полноценный внутренний продукт.
Используйте проверенные простые продуктовые подходы, но только те, которые окажутся простыми. Если тот или иной подход (тот же сustdev или портреты пользователей) кажется сложным, возможно, сейчас их не стоит использовать.
Повышайте ценность PaaS (скорость/расходы разработки/поддержки).
Создавайте современные интерфейсы.
Примите, что современная команда инфраструктуры приближается к продуктовой. Её уже официально называют командой DevOps‘еров. Эта мифологическая команда приближается к продуктовой по своим требованиям и тому, как она должна работать. Следование новым веяниям и использование современных подходов поможет создавать действительно удобную инфраструктуру
А любые сложности можно обойти в синергии с пользователем. Если вы создадите коммуникации и инструменты для этого, вы получите максимум фидбэка, а значит — максимум информации, как инфраструктура может сделать компанию эффективней. Пишите, я готов к обсуждению.
Профессиональная конференция DevOpsConf 2021 пройдёт 31 мая и 1 июня этого года в Москве, в отеле Radisson Slavyanskaya. Расписание уже сформировано. На сайте вы можете познакомиться с программой и спикерами.
Как всегда, будут реальные кейсы компаний, сложные инженерные аспекты цифровой трансформации, многообразие технологий и подходов: наглядно, просто, с конкретными рекомендациями. Билеты здесь.
До встречи в оффлайне!
Maslukhin
Блин, спасибо. Надо пересчитать психбольницу