
Добавь немного WebAssembly, получи выше производительность. Действительно ли это так работает?
Ответ невероятно приятный: все зависит от факторов. От такого количества факторов, чтобы я постараюсь все их здесь перечислить.
Зачем я это делаю? (это можно пропустить)
Мне очень нравится AssemblyScript (говоря по правде: я один из его спонсоров). Это очень молодой язык с небольшой, но страстной командой, которая создала пользовательский компилятор для TypeScript-подобного языка, ориентированного на WebAssembly. Причина, по которой мне нравится AssemblyScript (или сокращенно ASC), заключается в том, что он позволяет среднему веб-разработчику использовать WebAssembly без необходимости изучать потенциально новый язык, такой как C++ или Rust. Важно отметить, что язык похож на машинописный. Не ожидайте, что ваш существующий код TypeScript просто скомпилируется из коробки. Тем не менее, язык намеренно отражает поведение и семантику TypeScript (и, следовательно, JavaScript), что означает, что акт «переноса» TypeScript в AssemblyScript часто носит в основном косметический характер, обычно просто добавляя аннотации типов.
Я всегда задавался вопросом, есть ли что-то полезное в том, чтобы взять кусок JavaScript, превратить его в AssemblyScript и скомпилировать в WebAssembly. Когда мой коллега Ингвар прислал мне фрагмент кода JavaScript для размытия изображений, я подумал, что это будет идеальный пример. Я провел быстрый эксперимент, чтобы увидеть, стоит ли делать более глубокое исследование переноса JavaScript в AssemblyScript. И, о боже, оно того стоило. Эта статья-это более глубокое исследование.
Если вы хотите узнать больше о AssemblyScript, зайдите на сайт, присоединяйтесь к Discord или, если вы хотите, посмотрите вступительное видео AssemblyScript, которое я сделал со своим мужем Джейком на подкасте.
Преимущества WebAssembly
Я думаю, что будет справедливо сказать, что наиболее зрелый вариант использования WebAssembly-это подключение к экосистеме других языков. В Squoosh, например, мы используем библиотеки из экосистемы C/C++ и Rust для обработки изображений. Эти библиотеки не были написаны учитывая веб технологии, но через WebAssembly они все равно могут работать.
WebAssembly, по моему мнению, также сильно ассоциируется с производительностью многих людей. Он был разработан, чтобы быть быстрым, и он скомпилирован, так что он должен быть быстрым, верно? Ну, в течение самого долгого времени я говорил, что WebAssembly и JavaScript имеют одинаковую пиковую производительность, и я все еще стою за этим. При идеальных условиях они оба компилируются в машинный код и в конечном итоге оказываются одинаково быстрыми. Но здесь, очевидно, есть еще один нюанс, и когда условия когда-либо были идеальными в вебе? Я думаю, что было бы лучше, если бы мы подумали о WebAssembly как о способе получить более надежную производительность.
Однако также важно понимать, что WebAssembly в последнее время получает доступ к примитивам производительности (таким как SIMD или потоки shared-memory), которые JavaScript не может использовать, что дает WebAssembly повышенный шанс превзойти JavaScript. Есть также некоторые другие качества WebAssembly, которые могут сделать его более подходящим в конкретных ситуациях, чем JavaScript:
Никакой разминки
Чтобы привести в исполнение V8, Java Script сначала дает код «Ignition» интерпретатору. Ignition оптимизировано для того, чтобы код запускался как можно скорее. Затем «Sparkplug» берет выход с Ignition(печально известный «байт-код») и превращает его в неоптимизированный машинный код, обеспечивая лучшую производительность за счет увеличения объема памяти. Пока ваш код выполняется, V8 внимательно наблюдает за тем, как он собирает данные о формах объектов (думайте о них как о типах). Как только собрано достаточное количество данных, оптимизирующий компилятор V8 «TurboFan» включается и генерирует низкоуровневый машинный код, оптимизированный для этих типов. Это даст еще один значительный прирост скорости.
Если вы хотите узнать больше о точных компромиссах, которые должны делать движки JavaScripts, я могу порекомендовать эту статью Бенедикта и Матиаса.
WebAssembly, с другой стороны, строго типизирован. Его можно сразу же превратить в машинный код. V8 имеет потоковый компилятор Wasm под названием «Liftoff», который, как и Ignition, предназначен для быстрого запуска вашего кода за счет создания потенциально неоптимальной скорости выполнения. Второй Liftoff завершен, TurboFan включается и генерирует оптимизированный машинный код, который будет работать быстрее, чем тот, который произвел Liftoff, но потребуется больше времени для генерации. Большая разница с JavaScript заключается в том, что TurboFan может выполнять свою работу без необходимости сначала наблюдать за вашим Wasm.
Никаких tierdown
Машинный код, который TurboFan генерирует для JavaScript, можно использовать только до тех пор, пока сохраняются предположения о типах. Если TurboFan сгенерировал машинный код для функции f с числом в качестве параметра, а теперь вдруг эта функция f вызывается с объектом, двигатель должен вернуться к Igniotion или Sparkplug. Это называется «deoptimization» (или, сокращенно, «deopt»). Опять же, поскольку WebAssembly строго типизирован, типы не могут изменяться. Не только эти, но и типы, которые поддерживает WebAssembly, предназначены для хорошего сопоставления с машинным кодом. Deopt не может случится с WebAssembly.
Двоичный размер
А теперь немного размывчатой информации. Согласно webassembly.org, «машина стека wasm предназначена для кодирования в двоичном формате, эффективном по размеру и времени загрузки.» И все же WebAssembly в настоящее время печально известна тем, что сильно раздувает двоичный код, по крайней мере, тем, что считается «сильно» в веб разработке. WebAssembly очень хорошо сжимается (через gzip или brotli), что может сократить большую часть раздувания.
Легко забыть, что JavaScript поставляется с большим количеством батареек в комплекте (несмотря на утверждение, что у него нет стандартной библиотеки). Например: Вы можете обрабатывать массивы, объекты, перебирать ключи и значения, разбивать строки, фильтровать, сопоставлять, иметь прототипическое наследование и т. д. Все это встроено в движок JavaScript. WebAssembly не имеет ничего, кроме арифметики. Всякий раз, когда вы используете любую из этих концепций более высокого уровня в языке, который компилируется в WebAssembly, базовый код должен быть скомпилирован в ваш двоичный файл, что является одной из причин больших двоичных файлов WebAssembly. Конечно, эти функции должны быть включены только один раз, поэтому более крупные проекты получат больше пользы от небольшого двоичного представления Wasm, чем от небольших модулей.
Не все эти преимущества одинаково доступны или важны в любом конкретном сценарии. Однако AssemblyScript, как известно, генерирует довольно небольшие двоичные файлы WebAssembly, и мне было любопытно, как он может выдерживать с точки зрения скорости и размера непосредственно сопоставимый с JavaScript.
Перенос на AssemblyScript
Как уже упоминалось, AssemblyScript максимально имитирует семантику TypeScript и API веб-платформы, что означает, что перенос части JS в ASC в основном заключается в добавлении аннотаций типов в код. В качестве первого примера я взял glur, библиотеку JavaScript, которая размывает изображения.
Добавление типов
Встроенные типы ASC отражают типы виртуальной машины WebAssembly. В то время как числовые значения в TypeScript-это просто number(64-битный поплавок IEEE754 в соответствии со спецификацией), AssemblyScript имеет u8, u16, u32, i8, i16, i32, f32 и f64 в качестве своих примитивных типов. Небольшая, но достаточно мощная стандартная библиотека ASC добавляет высокоуровневые структуры данных, такие как string, Array, ArrayBuffer, Uint8Array и т. д. Единственная специфическая для ASC структура данных, которой нет ни в JavaScript, ни в веб-платформе — это StaticArray, о котором я расскажу немного позже.
В качестве примера приведем функцию из библиотеки glur и ее упрощенный аналог AssemblyScript:
function gaussCoef(sigma) {
if (sigma < 0.5)
sigma = 0.5;
var a = Math.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
return new Float32Array([
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
]);
}
function gaussCoef(sigma: f32): Float32Array {
if (sigma < 0.5)
sigma = 0.5;
let a: f32 = Mathf.exp(0.726 * 0.726) / sigma;
/* ... more math ... */
const r = new Float32Array(8);
const v = [
a0, a1, a2, a3,
b1, b2,
left_corner, right_corner
];
for (let i = 0; i < v.length; i++) {
r[i] = v[i];
}
return r;
}Явный цикл в конце для заполнения массива существует из-за текущего замыкания в AssemblyScript: Перегрузка функций пока не поддерживается. В ASC есть только один конструктор для Float32Array, который принимает параметр i32 для длины TypedArray. Обратные вызовы поддерживаются в ASC, но замыкания также не поддерживаются, поэтому я не могу их использовать .forEach() для заполнения значений. Это, конечно, неудобно, но не критично…
Mathf: Возможно, вы заметили Mathf вместо Math. Mathf предназначен специально для 32-битных поплавков, в то время как Math предназначен для 64-битных поплавков. Я мог бы использовать математику и создать привидение, но они всегда немного медленнее из-за повышенных требований к точности. В любом случае, функция gaussCoef не является частью горячего пути, так что это действительно не имеет значения.
Примечание на полях: Обращайте внимание на знаки
Что-то, что заняло у меня смущающе много времени, чтобы понять, так это то, что типы имеют значение. Размытие изображения включает в себя свертку, а это означает целую кучу циклов for, повторяющихся по всем пикселям. Наивно я думал, что, поскольку все пиксельные индексы положительны, счетчики циклов будут такими же, и решил выбрать u32 для этих переменных цикла. Это выльется прекрасным бесконечным циклом, если какой-либо из этих циклов будет повторяться в обратном направлении, как следующий:
let j: u32;
// ... many many lines of code ...
for (j = width - 1; j >= 0; j--) {
// ...
}Кроме того, процесс переноса JS в ASC был довольно механической задачей.
Бенчмаркинг с использованием d8
Теперь, когда у нас есть JS-файл и ASC-файл, мы можем скомпилировать ASC в WebAssembly и запустить небольшой бенчмарк для сравнения производительности скорости запуска.
d-Что?: d8-это минимальная оболочка CLI вокруг V8, предоставляющая тонкий контроль над всеми видами функций движка как для Wasm, так и для JS. Вы можете думать о нем как о Node, но без какой-либо стандартной библиотеки вообще. Просто ванильный ECMAScript. Если вы не скомпилировали V8 локально (что вы можете сделать, следуя руководству по v8.dev), у вас, вероятно, не будет d8. jsvu-это инструмент, который может устанавливать предварительно скомпилированные двоичные файлы для многих движков JavaScript, включая V8.
Однако, поскольку в названии этого раздела есть слово «Бенчмаркинг», я думаю, что здесь важно поставить оговорку: цифры, которые я перечисляю здесь, специфичны для кода, который я написал на выбранном мной языке, запущенном на моей машине (MacBook Air 2020 M1) с использованием бенчмаркингового сценария, который я сделал. Результаты в лучшем случае являются сухими показателями, и было бы неразумно делать из этого количественные выводы об общей производительности AssemblyScript, WebAssembly или JavaScript.
Некоторые могут задаться вопросом, почему я использую d8 вместо того, чтобы запускать его в браузере или даже Node. И Node, и браузер имеют… другие вещи, которые могут или не могут испортить результаты. d8-это самая стерильная среда, которую я могу получить, и как вишенка на торте, она позволяет мне контролировать поведение tier-up. Я могу ограничить выполнение только использованием Ignition, Sparkplug или Liftoff, гарантируя, что эксплуатационные характеристики не изменятся в середине теста.
Методология
Как описано выше, важно «разогреть» JavaScript при бенчмаркинге, давая V8 возможность его оптимизировать. Если вы этого не сделаете, вы вполне можете в конечном итоге измерить смесь характеристик производительности интерпретируемого JS и оптимизированного машинного кода. С этой целью я запускаю программу размытия 5 раз, прежде чем начать измерение, затем делаю 50 временных запусков и игнорирую 5 самых быстрых и медленных запусков, чтобы удалить потенциальные выбросы. Вот что у меня получилось:

С одной стороны, я был рад видеть, что выход Liftoff был быстрее, чем то, что Ignition или Sparkplug могли выжать из JavaScript. В то же время мне не понравилось, что оптимизированный модуль WebAssembly занимает примерно в 3 раза больше времени, чем JavaScript.
Честно говоря, это сценарий Давида против Голиафа: V8-это давний JavaScript-движок с огромной командой инженеров, реализующих оптимизацию и другие умные вещи, в то время как AssemblyScript-относительно молодой проект с небольшой командой вокруг него. Компилятор ASC является однопроходным и переносит все усилия по оптимизации на Binaryen (см. Также: wasm-opt). Это означает, что оптимизация выполняется на уровне байт-кода Wasm VM после того, как большая часть семантики высокого уровня была скомпилирована. V8 имеет здесь явное преимущество. Однако код размытия настолько прост — просто выполняет арифметику со значениями из памяти, — что я действительно ожидал, что он будет пошустрее. Что здесь происходит?
Копнем глубже
Быстро проконсультировавшись с некоторыми ребятами из команды V8 и некоторыми ребятами из команды AssemblyScript (спасибо Дэниелу и Максу!), оказалось, что одним большим отличием здесь являются «проверки границ» — или их отсутствие.
V8 может позволить себе роскошь доступа к исходному коду JavaScript и знания о семантике языка. Он может использовать эту информацию для применения дополнительных оптимизаций. Например: Он может сказать, что вы не просто случайно считываете значения из памяти, но и перебираете ArrayBuffer используя
for… of петли. Какая разница? Ну и с for… of, семантика языка гарантирует, что вы никогда не будете пытаться читать значения вне ArrayBuffer. Вы никогда не закончите тем, что случайно прочитаете байт 11, когда буфер имеет длину всего 10 байт,
или: Вы никогда не выходите за пределы. Это означает, что TurboFan не должен выдавать проверки границ, о которых вы можете думать как о if, удостоверяющих, что вы не обращаетесь к памяти, к которой не должны. Такого рода информация теряется после компиляции в WebAssembly, и поскольку оптимизация ASC происходит только на уровне виртуальной машины WebAssembly, она не обязательно может применять ту же оптимизацию.
К счастью, AssemblyScript предоставляет волшебную аннотацию unchecked (), указывающую на то, что мы берем на себя ответственность за то, чтобы оставаться в границах.
- prev_prev_out_r = prev_src_r * coeff[6];
- line[line_index] = prev_out_r;
+ prev_prev_out_r = prev_src_r * unchecked(coeff[6]);
+ unchecked(line[line_index] = prev_out_r);Но есть и еще кое-что: Типизированные массивы в AssemblyScript (Uint8Array, Float32Array, ...) предлагают тот же API, что и на платформе, а это означает, что они являются просто представлением базового ArrayBuffer. Это хорошо тем, что дизайн API знаком и проверен в боях, но из-за отсутствия высокоуровневой оптимизации это означает, что каждый доступ к полю в типизированном массиве (например, myFloatArray[23]) должен обращаться к памяти дважды: один раз для загрузки указателя на базовый ArrayBuffer этого конкретного массива, а другой-для загрузки значения с правильным смещением. V8, поскольку он может сказать, что вы обращаетесь к типизированному массиву, но никогда к базовому буферу, скорее всего, способен оптимизировать всю структуру данных так, чтобы вы могли читать значения с одним доступом к памяти.
По этой причине AssemblyScript предоставляет StaticArray, который в основном эквивалентен Array, за исключением того, что он не может расти. При фиксированной длине нет необходимости держать объект массива отдельно от памяти, в которой хранятся значения, удаляя эту косвенность.
Я применил обе эти оптимизации к своему «наивному порту» и снова измерил:
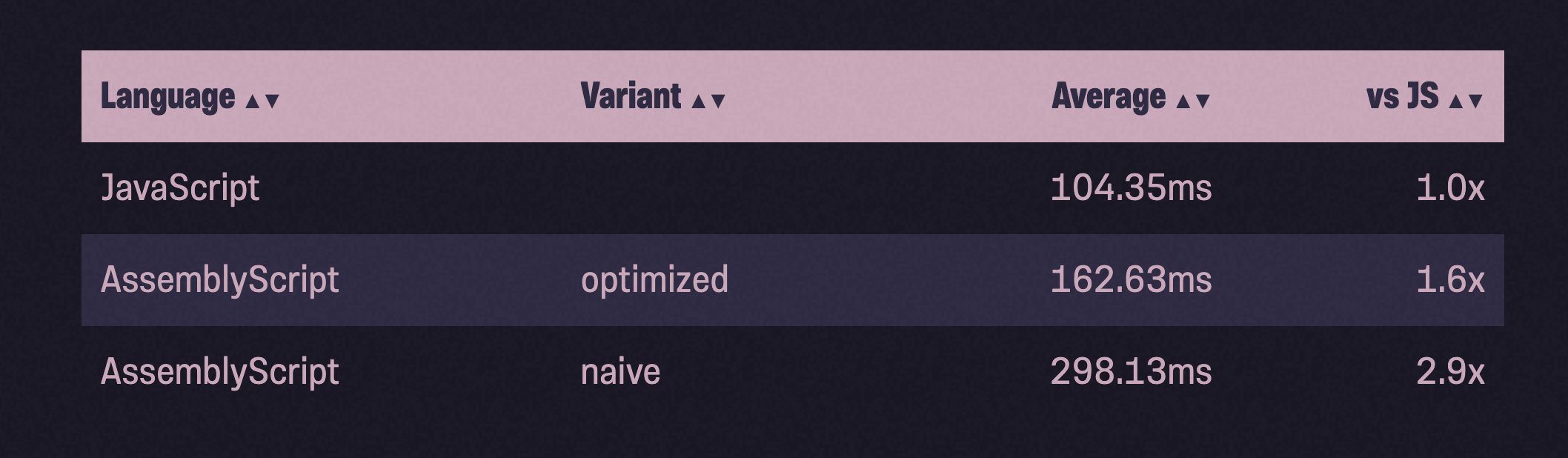
Гораздо лучше! Хотя AssemblyScript все еще медленнее, чем JavaScript, мы значительно приблизились. Это лучшее, что мы можем сделать?
Подлые дефолты
Еще одна вещь, на которую мне указали люди из AssemblyScript, заключается в том, что флаг --optimize эквивалентен-O3s, который агрессивно оптимизирует скорость, но делает компромиссы для уменьшения двоичного размера. -O3 оптимизирует скорость и только скорость. Наличие -O3s по умолчанию хорошо по — двоичный размер имеет значение в веб разработке — но стоит ли оно того? По крайней мере, в этом конкретном примере ответ отрицательный: -O3s в конечном итоге торгует смехотворной суммой ~30 байт за огромный штраф в производительности:

Один единственный флаг оптимизатора делает разницу, как между между днем и ночью, позволяя AssemblyScript обогнать JavaScript (в этом конкретном тестовом примере!). Мы сделали AssemblyScript быстрее, чем JavaScript!
O3: С этого момента я буду использовать только-O3 в этой статье
Сортировка пузырьком
Чтобы получить некоторую уверенность в том, что пример размытия изображения-это не просто случайность, я подумал, что должен попробовать это снова со второй программой. Довольно нетворчески я взял реализацию bubblesort из StackOverflow и провел тот же процесс: Добавление типов. Запустил бенчмарк. Оптимизировал. Запустил бенчмарк. Создание и заполнение массива, подлежащего пузырьковой сортировке, не является частью бенчмарка.
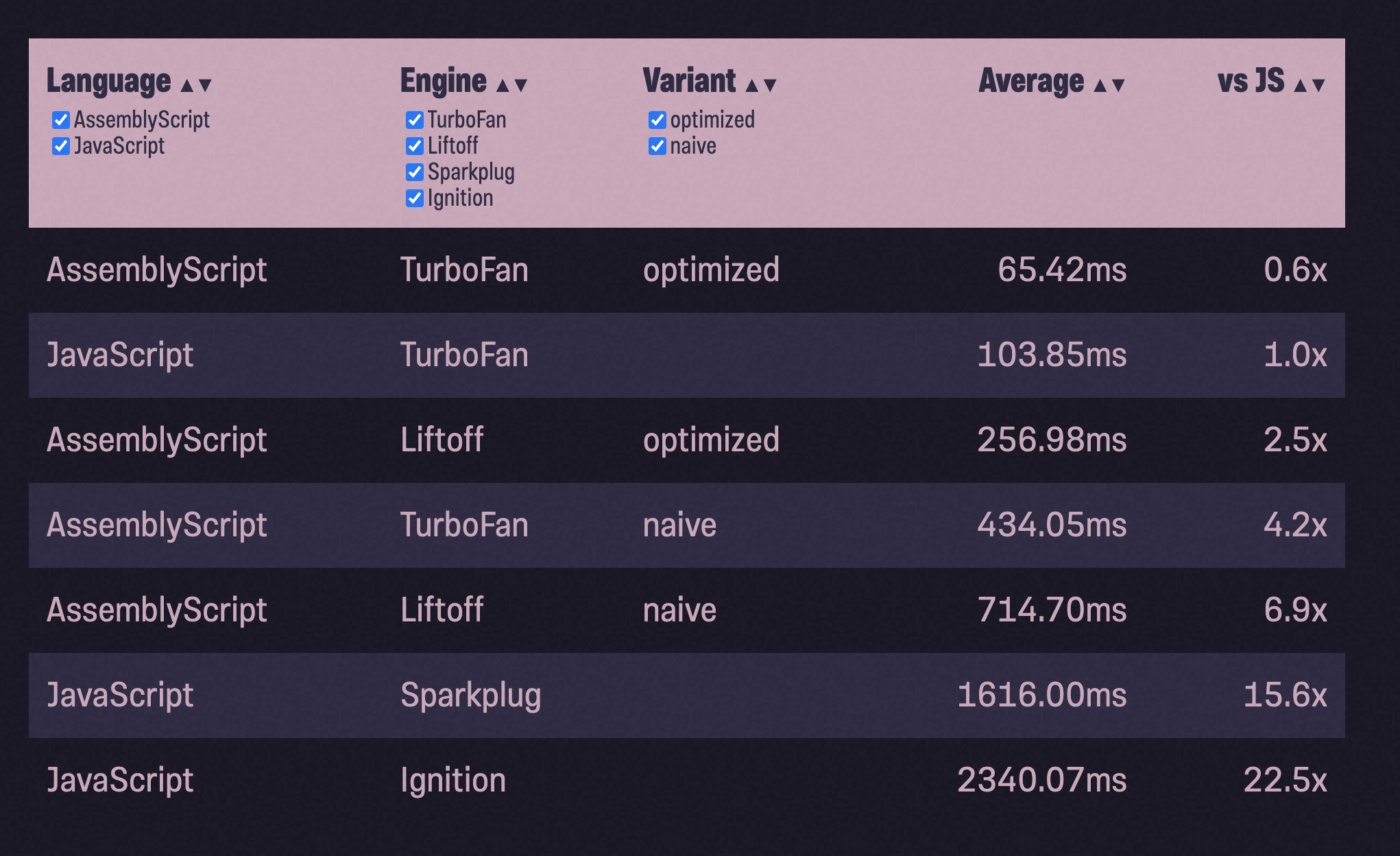
Мы сделали это снова! На этот раз с еще большим расхождением: оптимизированный AssemblyScript почти в два раза быстрее JavaScript. Но сделай одолжение: не переставай читать.
Распределение
Некоторые из вас, возможно, заметили, что в обоих этих примерах очень мало или вообще нет распределений. V8 заботится обо всем управлении памятью (и сборке мусора) в JavaScript для вас, и я не буду притворяться, что много знаю об этом. С другой стороны, в WebAssembly вы получаете кусок линейной памяти, и вам нужно решить, как ее использовать (или, скорее, это делает язык). Насколько эти рейтинги меняются, если мы интенсивно используем динамическую память?
Чтобы измерить это, я решил протестировать реализацию двоичного древа. Бенчмарк заполняет двоичное древо 1 миллионом случайных чисел (любезно предоставленных Math.random()) и pop() возвращает их обратно, проверяя, что числа находятся в порядке возрастания. Процесс остался таким же, как и выше: сделать naive порт JS-кода в ASC, запустить бенчмарк, оптимизировать, снова бенчмарк:
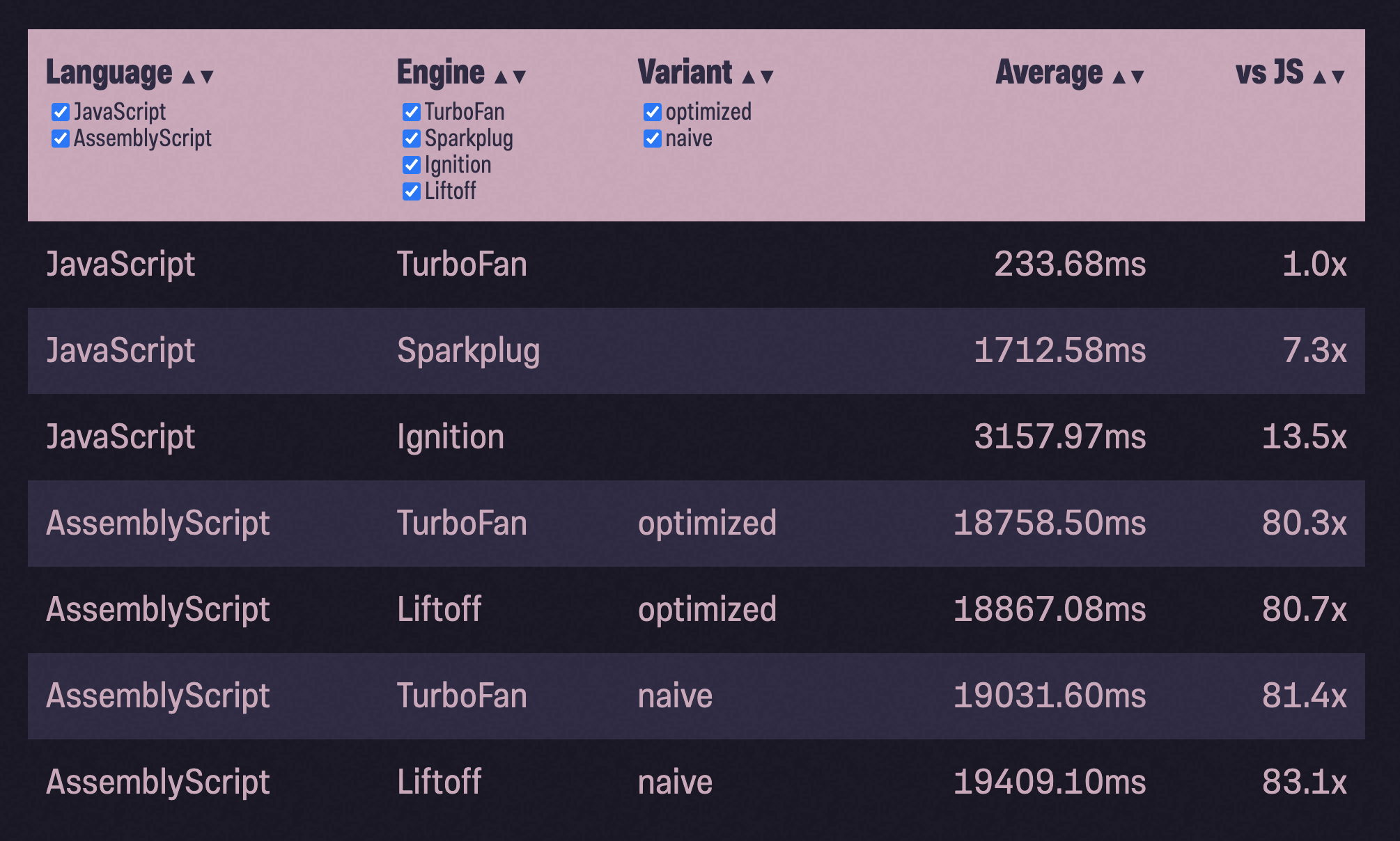
в 80 раз медленнее, чем JavaScript?! Даже медленнее, чем Ignition?
Конечно, здесь что-то еще идет не так.
Время выполнения
Все данные, которые мы создаем в AssemblyScript, должны храниться в памяти. Чтобы убедиться, что мы не перезаписываем ничего другого, что уже находится в памяти, существует управление памятью. Поскольку AssemblyScript стремится обеспечить знакомую среду, зеркально отражающую поведение JavaScript, он добавляет полностью управляемый сборщик мусора в ваш модуль WebAssembly, так что вам не нужно беспокоиться о том, когда выделять и когда освобождать память.
По умолчанию AssemblyScript поставляется с двухуровневым распределителем памяти Segregated Fit и инкрементным сборщиком мусора Tri-Color Mark & Sweep (ITCMS). На самом деле для этой статьи не имеет значения, какой распределитель и сборщик мусора они используют, мне просто показалось интересным, что вы можете ознакомится с ними.
Эта среда выполнения по умолчанию, называемая инкрементной, на удивление мала, добавляя в ваш модуль всего около 2 КБ gzip'd WebAssembly. AssemblyScript также предлагает альтернативные среды выполнения, а именно minimal и stub, которые можно выбрать с помощью — runtime. flag minimal использует тот же распределитель, но более легкий GC, который не запускается автоматически, а должен быть вызван вручную. Это может быть полезно для высокопроизводительных случаев использования, таких как игры, где вы хотите контролировать, когда GC приостановит вашу программу. заглушка чрезвычайно мала (~400B gzip'd) и быстра, так как это всего лишь bump allocator.
Мой прекрасный удар по памяти: bump allocator чрезвычайно быстры, но не имеют возможности освободить память. Хотя это звучит глупо, это может быть чрезвычайно полезно для одноцелевых модулей, где вместо освобождения памяти вы удаляете весь экземпляр WebAssembly и вместо этого создаете новый. Если вам интересно, я действительно написал bump allocator в своей статье Compiling C to WebAssembly without Emscripten.
Насколько быстрее это делает наш эксперимент с бинарной кучей? Весьма существенно!

И minimal, и stub значительно приближают нас к производительности JavaScripts. Но почему эти двое намного быстрее? Как уже упоминалось выше, minimal и incremental используют один и тот же распределитель, так что это не может быть так. У обоих также есть сборщик мусора, но minimal не запускает его, если явно не вызывается (а мы его не вызываем). Это означает, что отличительное качество заключается в том, что incremental сборка мусора выполняется, а minimal и stab. Я не понимаю, почему сборщик мусора должен иметь такое большое значение, учитывая, что он должен отслеживать один массив.
Рост
После выполнения некоторого профилирования с помощью d8 на сборке с отладочными символами (--debug) оказывается, что много времени тратится на системную библиотеку libsystem_platform.dylib, которая содержит примитивы уровня ОС для потоковой обработки и управления памятью. Вызовы в эту библиотеку выполняются из __new и __renew, которые, в свою очередь, вызываются из Array#push:
[Bottom up (heavy) profile]:
ticks parent name
18670 96.1% /usr/lib/system/libsystem_platform.dylib
13530 72.5% Function: *~lib/rt/itcms/__renew
13530 100.0% Function: *~lib/array/ensureSize
13530 100.0% Function: *~lib/array/Array#push
13530 100.0% Function: *binaryheap_optimized/BinaryHeap#push
13530 100.0% Function: *binaryheap_optimized/push
5119 27.4% Function: *~lib/rt/itcms/__new
5119 100.0% Function: *~lib/rt/itcms/__renew
5119 100.0% Function: *~lib/array/ensureSize
5119 100.0% Function: *~lib/array/Array#push
5119 100.0% Function: *binaryheap_optimized/BinaryHeap#pushЯвно видно, что здесь у нас проблема с распределением. Но JavaScript каким-то образом умудряется сделать постоянно растущий массив быстрым, так почему не может AssemblyScript? К счастью, стандартная библиотека AssemblyScript довольно мала и доступна, так что давайте взглянем на эту зловещую функцию push () класса Array :
export class Array<T> {
// ...
push(value: T): i32 {
var length = this.length_;
var newLength = length + 1;
ensureSize(changetype<usize>(this), newLength, alignof<T>());
// ...
return newLength;
}
// ...
}Функция push() правильно определяет, что новая длина массива равна текущей длине плюс 1, а затем вызывает функцию ensureSize (), чтобы убедиться, что в базовом буфере достаточно места (»емкости») для роста до этой длины.
function ensureSize(array: usize, minSize: usize, alignLog2: u32): void {
// ...
if (minSize > <usize>oldCapacity >>> alignLog2) {
// ...
let newCapacity = minSize << alignLog2;
let newData = __renew(oldData, newCapacity);
// ...
}
}ensureSize(), в свою очередь, проверяет, меньше ли емкость нового minSize, и если да, то выделяет новый буфер размера minSize с помощью __renew, что влечет за собой копирование всех данных из старого буфера в новый. По этой причине наш бенчмарк, где мы помещаем миллион значений одно за другим в массив, в конечном итоге вызывает много работы по распределению и создает много мусора.
В других языках, таких как Rust’s std::vec или Go slices, новый буфер имеет двойную емкость старого буфера, что амортизирует работу распределения с течением времени. Я работаю над тем, чтобы исправить это в ASC, но в то же время мы можем создать наш собственный CustomArray, который имеет желаемое поведение. О чудо, мы сделали все быстрее!

При этом изменение incremental происходит так же быстро, как stub и minimal, но ни один из них не такой быстрый, как JavaScript в этом тестовом примере. Вероятно, есть и другие оптимизации, которые я мог бы сделать, но мы уже довольно глубоко увязли в сорняках, и это не должно быть статьей о том, как оптимизировать AssemblyScript.
Есть также много простых оптимизаций, которые я хотел бы, чтобы компилятор AssemblyScript сделал для меня. С этой целью они работают над IR под названием «AIR». Будет ли решение из коробки делать вещи быстрее без необходимости вручную оптимизировать каждый доступ к массиву? Весьма вероятно. Будет ли это быстрее, чем JavaScript? Трудно сказать. Но мне было интересно, чего могут достичь более «зрелые» языки с «очень умными» цепочками инструментов компилятора.
Rust & C++
Я переписал код на Rust, стараясь быть как можно более идиоматическим, и скомпилировал его в WebAssembly. Хотя он был быстрее, чем naive порт для AssemblyScript, он был медленнее, чем наш оптимизированный AssemblyScript с CustomArray. Поэтому мне пришлось сделать то же самое, что и в AssemblyScript: избегая связанных проверок, оставлять некоторые unsafe здесь и там. При такой оптимизации модуль WebAssembly Rust работает быстрее, чем наш оптимизированный AssemblyScript, но все же не быстрее JavaScript.
Я использовал тот же подход с C++, используя Emscripten для компиляции его в WebAssembly. К моему удивлению, моя первая попытка оказалась столь же шустрой, как и JavaScript.

Lrn2code: Версии, помеченные как «idiomatic», все еще очень сильно вдохновлены оригинальным JS-кодом. Я попытался использовать свои знания идиом целевого языка, но в конце концов это все равно порт. Я уверен, что реализация с нуля кем-то с большим опытом работы на этих языках будет выглядеть по-другому.
Я совершенно уверен, что Rust и C++ можно было бы сделать еще быстрее, но у меня нет достаточно глубоких знаний ни того, ни другого языка, чтобы выжать эти последние пару оптимизаций.
Размеры файлов Gzip'd
Стоит отметить, что размер файла является сильной стороной AssemblyScript. Сравнивая размеры файлов gzip'd, мы получаем:

Вывод
Я хочу быть предельно ясным: любой обобщенный, количественный вывод из этой статьи был бы неразумным. Например, Rust не в 1,2 раза медленнее JavaScript. Эти цифры очень специфичны для кода, который я написал, оптимизаций, которые я применил, и машины, которую я использовал. Тем не менее, я думаю, что есть некоторые общие рекомендации, которые мы можем извлечь, чтобы помочь вам принимать более обоснованные решения в будущем:
- Компилятор Liftoff V8 будет генерировать код из WebAssembly, который работает значительно быстрее, чем то, что Ignition или SparkPlug могут предоставить для JavaScript. Если вам нужна производительность без какого-либо времени прогрева, WebAssembly-это ваш инструмент выбора.
- V8 действительно хорош в выполнении JavaScript. Хотя WebAssembly может работать быстрее, чем JavaScript, вполне вероятно, что для этого вам придется вручную оптимизировать свой код. Я мог бы увидеть этот сдвиг баланса, как только появится широко распространенная поддержка SIMD и потоков и большой опыт разработчиков в их использовании.
- Компиляторы могут сделать много работы за вас, более зрелые компиляторы, скорее всего, лучше оптимизируют ваш код.
- Модули AssemblyScript, как правило, намного меньше, чем другие модули WebAssembly, созданные другими языками. В этом исследовании AssemblyScript был не меньше, чем исходный JavaScript, но это вполне могло быть иначе для больших модулей.
Если вы не доверяете мне (а вы не должны!) и хотите покопаться в тестовом коде самостоятельно, взгляните на суть.
Наши серверы можно использовать для разработки с WebAssembly.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
