Перевод статьи подготовлен в преддверии старта курса "Deep Learning. Basic".
Предлагаем также всем желающим посмотреть запись вебинара «Knowledge distillation: нейросети обучают нейросети».

В конце 2018 года исследователи из FAIR опубликовали статью «Переосмысление предобучения в ImageNet», которая впоследствии была представлена на ICCV2019. В статье представлены некоторые очень интересные выводы относительно предобучения. Я тогда не стал посвящать этому событию отдельный пост, но мы долго обсуждали его в нашем слаке (KaggleNoobs). Исследователи из Google Research and Brain team предложили расширенную версию той же концепции. Их новая публикация затрагивает не только тему предобучения (pre-training), она также исследует самообучение (self-training), сравнивая его с предобучением и обучением без учителя (self-supervised learning) на тех же наборах задач.
Введение
Прежде чем мы углубимся в детали, представленные в публикации, давайте сделаем один шаг назад и обсудим сначала несколько понятий. Предобучение — очень распространенная практика в различных областях, таких как компьютерное зрение, NLP и генерация речи. Когда речь заходит о компьютерном зрении, мы ожидаем, что модель, предварительно обученная на одном наборе данных, поможет другой модели. Например, предобучение ImageNet с учителем является широко используемым методом инициализации для моделей обнаружения и сегментации объектов. Трансферное обучение (transfer learning) и точная настройка (fine-tuning) — два распространенных метода для реализации этой затеи.
С другой стороны, самообучение пытается улучшить эффективность модели за счет включения прогнозов для модели на неразмеченных данных для получения дополнительной информации, которая может быть использована во время обучения. Например, использование ImageNet для улучшения модели обнаружения объектов COCO. Сначала модель обучается на наборе данных COCO. Затем она используется для создания псевдо-меток для ImageNet (мы отбрасываем исходные метки ImageNet). Затем псевдо-размеченные данные ImageNet и размеченные данные COCO объединяются для обучения новой модели.
Обучение без учителя — еще один популярный метод предобучения. Обучение с самоконтролем направлено не только на изучение высокоуровневых признаков. Мы хотим, чтобы наша модель обучалась более качественным, более надежным универсальным представлениям, которые работают с более широким спектром задач и наборов данных.
Что ж, хватит болтовни! Мудреные определения в сторону, ведь вы до сих пор не понимаете, о чем конкретно эта статья? Или мы собрались здесь, чтобы определения почитать?
Мотивация
Мы используем эти методы уже достаточно давно. Авторы заинтересованы в том, чтобы найти ответы на следующие вопросы:
Насколько может помочь предобучение? Когда предобучение не приносит пользы?
Можем ли мы использовать самообучение вместо предобучения и получить аналогичные или лучшие результаты по сравнению с предобучением и обучением без учителя?
Если самообучение превосходит предобучение (если предположить, что это так), то насколько оно лучше, чем предобучение?
В каких случаях самообучение лучше предобучения?
Насколько самообучение гибкое и масштабируемое?
Сетап
Наборы данных и модели
Обнаружение объектов: авторы использовали набор данных COCO (118K изображений) для обнаружения объектов с применением обучения с учителем. ImageNet (1,2М изображений) и OpenImages (1,7М ??изображений) использовались в качестве немаркированных наборов данных. Были использован детектор RetinaNet с EfficientNet-B7 в качестве базовой сети (backbone). Разрешение изображений было до 640 x 640, слои пирамиды от P3-P7 и использовались 9 якорей на пиксель.
Семантическая сегментация: для обучения с учителем использовался набор для обучения сегментации PASCAL VOC 2012 (1,5K изображений). Для самообучения авторы использовали аугментированный набор данных PASCAL (9K изображений), COCO (240K размеченных, а также неразмеченных изображений) и ImageNet (1,2M изображений). Использовалась модель NAS-FPN с EfficientNet-B7 и EfficientNet-L2 в качестве базовых сетей.
Дополнительные сведения, такие как размер пакета, скорость обучения и т. д., смотрите в разделе 3.2 в публикации.
Аугментация данных
Во всех экспериментах как для обнаружения, так и для сегментации использовались четыре различных метода аугментации для увеличения эффективности. Эти четыре метода, в порядке возрастания их сложности, таковы:
Augment-S1: это стандартная Flip and Crop (переворот и кадрирование) аугментация. Стандартный метод flip and crop состоит из горизонтальных переворотов изображения и флуктуаций масштаба (scale jittering). Операция флуктации также может быть случайной, так же как то как мы изменяем размер изображения до (0.8, 1.2) от размера исходного изображения, а затем обрезаем его.
Augment-S2: состоит из AutoAugment и переворотов и кадрирований.
Augment-S3: включает сильную флуктуацию масштаба, AutoAugment, перевороты и кадрирование. Флуктуация масштаба увеличен до (0.5, 2.0).
Augment-S4: комбинация RandAugment, переворотов и кадрирования и сильной флуктуацией масштаба. Флуктуация масштаба такая же, как и в Augment-S2/S3.

Предварительное обучение
Для изучения эффективности предобучения использовались предварительно обученные контрольные точки (checkpoints) ImageNet. EfficientNet-B7 — архитектура, используемая для оценки. Для этой модели использовались две разные контрольные точки. Они обозначаются как:
ImageNet: контрольная точка EfficientNet-B7, обученная с помощью AutoAugment, которая достигает 84,5% top-1 точности в ImageNet.
ImageNet++: контрольная точка EfficientNet-B7, обученная с помощью метода Noisy Student, который использует дополнительные 300 млн неразмеченных изображений и обеспечивает 86,9% top-1 точности.
Обучение из случайной инициализации обозначается как Rand Init.
Самообучение
Реализация самообучения основана на алгоритме Noisy Student и состоит из трех этапов:
Модель-учитель обучается на размеченных данных, например, на наборе данных COCO.
Затем модель-учитель используется для создания псевдометок для неразмеченных данных, например ImageNet.
Модель-ученик обучается оптимизировать потери на человеческой разметке и псевдо-метках одновременно.
Ради бога, можем ли мы уже взглянуть на хоть какие-нибудь эксперименты?
Эксперименты
Влияние увеличения и размера размеченного набора данных на предобучение
Авторы использовали ImageNet для предварительного обучения с учителем и варьировали размер размеченного набора данных COCO для изучения эффекта предобучения. Разнился не только размер размеченных данных, но и аугментации разной силы для обучения RetinaNet с EfficientNet-B7 в качестве базовой сети. Авторы наблюдали следующие факты:
Предобучение ухудшает эффективность, когда используется более сильная аугментация данных: авторы заметили, что, когда они используют стандартную аугментацию, Augment-S1, как она описана выше, предобучение помогает. Но по мере увеличения силы аугментации, предобучение помогает все меньше и меньше. Даже больше, они заметили, что при использовании сильнейшей аугментации (Augment-S3) предварительная тренировка на самом деле сильно ухудшает эффективность.
Чем больше размеченных данных, тем меньше польза предварительного обучения: это не открытие. Все мы знаем, что предварительное обучение помогает, когда у нас мало данных. Но если у нас достаточно размеченных данных, то обучение с нуля не будет результировать в плохой эффективности. Авторы пришли к такому же выводу, и этот вывод согласуется с публикацией FAIR.
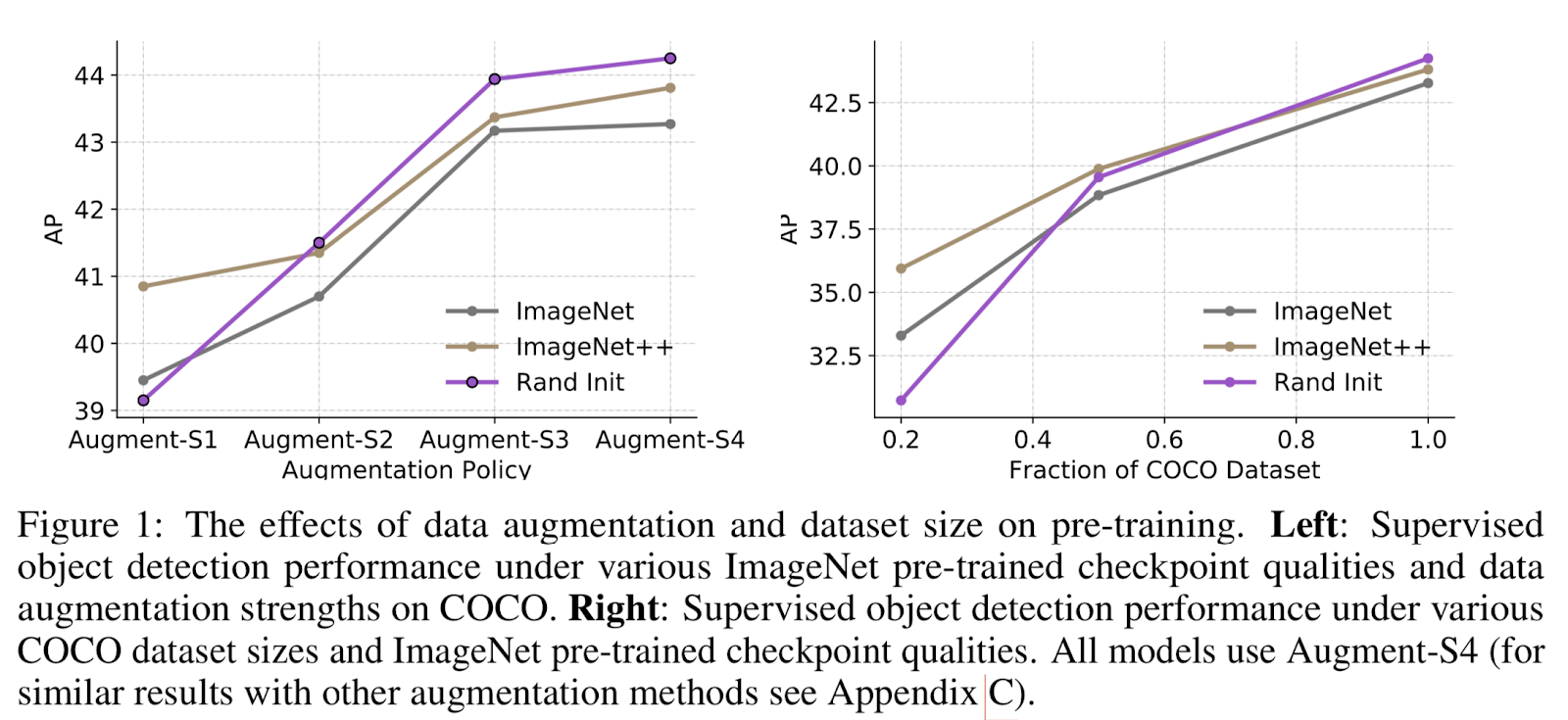
Связь между более сильной аугментацией и снижением эффективности — довольно интересная находка. Как вы думаете, почему так происходит?
Мое мнение: большинство моделей, обученных в ImageNet, не используют такие сильные аугментации. Когда вы добавляете тяжелые аугментации, модель может не устаканиться должным образом. Модели даже могут иногда немного переобучаться под определенные аугментации, хотя это требует более тщательного и детального изучения.
Влияние увеличения и размера размеченного набора данных на самообучение
Теперь, когда мы увидели влияние предварительного обучения, пришло время проверить результаты с той же задачей (в данном случае обнаружение объекта COCO) с той же моделью (RetinaNet детектор с базой EfficientNet-B7), но на этот раз с самообучением. Авторы использовали для самообучения набор данных ImageNet (метки для ImageNet в этом случае отбрасываются). Авторы отметили следующее:
Самообучение хорошо помогает в режимах с большим объемом данных/сильной аугментацией, даже когда скорее предобучение мешает: авторы обнаружили, что при добавлении самообучения к случайно инициализированной модели, при использовании тяжелой аугментации, это не только повышает исходные результаты, но также превосходят результаты, достигаемые с предобучением. Вот результаты:

2. Самообучение хорошо работает на разных размерах наборов данных и дополняет предобучение. Авторы обнаружили еще один интересный аспект самообучения, который дополняет предобучение. Проще говоря, использование самообучения со случайно инициализированной или предобученной моделью всегда повышает эффективность, и прирост эффективности остается неизменным для разных режимов данных.

Погодите-ка секундочку! Когда используется ImageNet++ init, выигрыш невелик по сравнению с выигрышем в Rand init и ImageNet init. Есть какая-то конкретная причина?
Да, ImageNet++ init получается из контрольной точки, для которой использовались дополнительные 300M неразмеченных изображений.
Предварительное обучение с учителем против самообучения
Мы увидели, что предобучение ImageNet с учителем снижает эффективность в режиме с максимальным объемом данных и в режиме сильной аугментации данных. Но как насчет предобучения без учителя? Основная цель самостоятельного обучения, предобучения без меток, — это создание универсальных представлений, которые можно перенести на более широкий круг задач и наборов данных.
Минуточку! Дайте я угадаю. Поскольку при обучении без учителя используются более качественные представления, оно должно быть, по крайней мере, на уровне самообучения, если не лучше.
Не хочется вас разочаровывать, но ответ — НЕТ. Чтобы исследовать эффекты обучения без учителя, авторы использовали полный набор данных COCO и сильнейшие аугментации. Цель состояла в том, чтобы сравнить случайную инициализацию с моделью, предварительно обученной с помощью современного алгоритма с обучения без учителя. Контрольная точка для SimCLR в этом эксперименте использовалась до того, как она была тонко настроена (fine-tuned) в ImageNet. Поскольку SimCLR использует только ResNet50, основа детектора RetinaNet была заменена на ResNet50. Вот результаты:
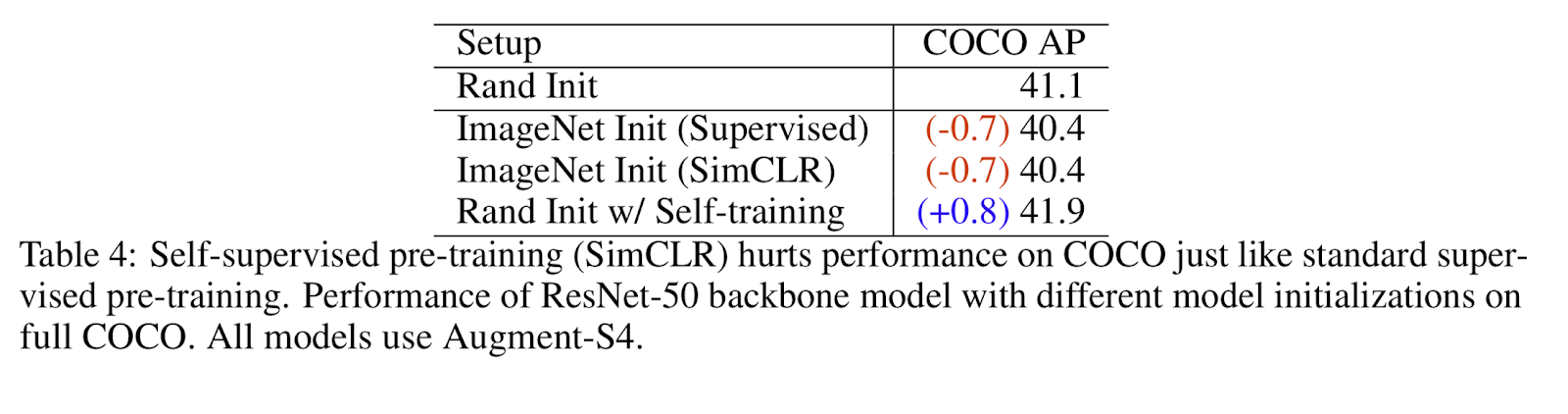
Даже в этом случае мы наблюдаем, что предобучение без учителя снижает эффективность, а самообучение же повышает ее.
Что мы узнали?
Предобучение и универсальные представления признаков
Мы увидели, что предварительное обучение (как контролируемое, так и самостоятельное) не всегда приводит к повышению эффективности. Более того, оно всегда уступает самообучению. Почему так происходит? Почему предобучение ImageNet не так хорошо для обнаружения объектов COCO? Почему представления, полученные с помощью предобучения без учителя, не помогли повысить эффективность?
На мой взгляд, у большинства исследователей в области компьютерного зрения уже есть эта интуитивная догадка, на которую снова указывают авторы: предобучение не осознает интересующую задачу и может не смочь адаптироваться.
Подумайте об ImageNet, это задача классификации, которая намного проще, чем задача обнаружения объектов. Узнает ли предварительно обученная сеть для задачи классификации всю информацию, необходимую для решения задач локализации? Вот моя любимая формулировка: разные задачи требуют разного уровня детализации, даже если задачи являются подмножеством друг друга.
Совместное обучение
Как указали авторы, одна из сильных сторон парадигмы самообучения состоит в том, что оно совместно обучает цели с учителем и цели самообучения, тем самым устраняя несоответствие между ними. Мы всегда можем утверждать, что вместо того, чтобы искать какой-либо другой метод устранения несоответствия различий между задачами, почему мы не можем обучаться вместе, например, совместно обучая ImageNet и COCO?
Авторы использовали тот же сетап, что и при самообучении для этого эксперимента, и обнаружили, что предобучение ImageNet дает улучшение +2,6AP, но использование случайной инициализации и совместного обучения дает больший выигрыш +2,9AP. Более того, предобучение, совместная тренировка и самообучение — все могут работать вместе. Используя тот же источник данных ImageNet, предобучение ImageNet получает улучшение +2,6AP, предобучение + совместное обучение дает +0,7AP, а комбинация предобучения + совместного обучение + самообучение дает улучшение +3,3AP.

Важность согласования задач
Как мы видели выше, согласование задач важно для повышения производительности. В этой статье сообщалось о схожих выводах о том, что предобучение на Open Images снижает эффективность COCO, несмотря на то, что оба они помечены ограничивающими рамками. Это означает, что мы не только хотим, чтобы задача была такой же, но и чтобы аннотации были одинаковыми, чтобы предварительное обучение было действительно полезным. Авторы отметили еще две интересные вещи:
Предварительное обучение ImageNet, даже с дополнительными человеческими метками, работает хуже, чем самообучение.
При сильной аугментации данных (Augment-S4) обучение с помощью PASCAL (наборы данных для обучения + аугментация) на самом деле снижает точность. Между тем, псевдометки, созданные путем самообучения на одном и том же наборе данных, повышают точность.

Масштабируемость, универсальность и гибкость самообучения
Из всех экспериментов, проведенных авторами, мы можем сделать вывод, что:
Что касается гибкости, самообучение хорошо работает в любой конфигурации: режим с низким объемом данных, режим с высоким объемом данных, слабая аугментация данных и сильная аугментация данных.
Самообучение не зависит от архитектуры или набора данных. Он хорошо работает с различными архитектурами, такими как ResNets, EfficientNets, SpineNet и т. д., а также с различными наборами данных, такими как ImageNet, COCO, PASCAL и т. д.
В общем, самообучение хорошо работает, когда предобучение терпит неудачу, но также и когда предобучение обучение тоже работает хорошо.
Что касается масштабируемости, самообучение показывает себя хорошо, поскольку у нас больше размеченных данных и лучшие модели.
Это хорошо. Некоторые из перечисленных здесь пунктов вызывают множество вопросов о том, как все мы использовали предварительное обучение. Но все, что имеет плюсы, имеет и минусы. Вы, должно быть, скрываете какой-то важный момент?
Ограничения самообучения
Хотя у самообучение есть свои преимущества, у него также есть несколько ограничений.
Самостоятельное обучение требует больше вычислительных ресурсов, чем точная настройка на предварительно обученной модели.
Ускорение от предобучения варьируется от 1,3x до 8x, в зависимости от качества предобученной модели, силы аугментации данных и размера набора данных.
Самообучение не является полной заменой трансферного обучения и тонкой настройки. Оба эти метода также будут активно использоваться в будущем.
Заключение
На мой взгляд, эта статья поднимает множество фундаментальных вопросов, касающихся предобучения, совместного обучения, понимания задач и универсальных представлений. Решение этих вопросов гораздо важнее, чем построение моделей с миллиардами параметров. Работа над подобными проблемами может помочь нам лучше понять решения, принимаемые глубокими нейронными сетями.
Узнать подробнее о курсе "Deep Learning. Basic"
Смотреть запись вебинара «Knowledge distillation: нейросети обучают нейросети»