
Пинать такую коробку следует с особой осторожностью
В целом я просто хотел сказать, что если вы смотрите all-flash массив на замену тирингового с ценой за гигабайт чуть пониже, надёжный и от топового вендора — продолжайте читать. Минимальный американский street price, заявленный вендором, начинается с 19 тысяч долларов. Но понятно, что на проектах, где нужно такое железо, всегда находится скидка, программа или спецпредложение, которые могут уменьшить цену спецификации, порой значительно. Заглядывайте внутрь, чтобы понять, почему SSD может быть дешевле тирингового массива, в частности, для VDI.
Началась история этой железки с того, что в HP давно подозревали, что после примерно 2012 года всё больше и больше серверных мощностей будет требовать быстрых СХД. Поэтому они купили контору 3PAR, клепающую неплохие мидрейнджевые системы хранения, взяли напильник — и понеслось. Что получилось — сейчас покажу.
Архитектура
Когда ко мне в руки впервые попал HP 3PAR 7400, я отнёсся к нему скептически, как к младшему брату в семье Full Flash массивов. Но два дня, проведённых с массивом, сильно изменили моё мнение.
HP 3PAR 7400 расширяется до 4 контроллеров, может нести 240 SSD дисков, вмещает 96 Gb оперативной памяти в каждую контроллерную пару и просто очень красив. Железная часть массива мало отличается от привычных mid-rande массивов, но ПО приятно удивило своей архитектурой. Оно больше похоже на ПО high-end массивов, чем на то, к чему я привык в массивах среднего уровня.
Факты следующие:
Массив можно расширить до 4 контроллеров, то есть уровень отказоустойчивости HP 3PAR (при правильной конфигурации) сильно превосходит таковой большинства массивов среднего уровня.
Потом кэш. В большинстве mid-range массивов контроллерная пара имеет кэш, разделённый на чтение и запись. Кэш на запись зеркалируется между контроллерами, но только в качестве защиты, а головы используют свою память раздельно. Если СХД хочет получить заметную часть рынка, ей нужно научиться динамически изменять размеры памяти, выделенные для чтения и записи. HP 3PAR пошёл дальше. Инженеры сделали Cache-Centric массив с общей памятью для всех контроллеров. В результате команда из 4 контроллеров в HP 3PAR работает значительно лучше, чем 4 малосвязанных контроллера в большинстве mid-range СХД.
Дедупликация. Никто не любит делать одну и ту же работу дважды. С этим маркетинговым заявлением многие массивы ринулись на рынок, предлагая решения с дедупликацией. Если разобраться, то большинство этих массивов делают дедупликацию в постпроцессе. Записывают данные на диск, а потом, когда появится свободное время, считывают эти данные и пытаются дедуплицировать. Таким образом, работа сделана не дважды, а четырежды. В плюсе — некоторый выигрыш по месту при малом проценте записи. В остальных случаях — не применимо. 3PAR делает дедупликацию на лету, не записывая промежуточные данные. Таким образом, на хорошо дедуплицируемых наборах данных получается выигрыш в скорости работы массива (на диски нужно писать меньше данных, какая-то часть отсеивается как уже записанная), и место экономится.
Ещё система не пишет пустые (нулевые) блоки. Они отсеиваются на уровне ASIC-ов.
Среди нас есть левши и правши. Точно так же и с массивами. Есть массивы Active\Passive (это однорукие), есть Active\Active ALUA (это те самые среднестатистические левши и правши), а есть честные Active\Active. HP 3PAR именно такой. Контроллеры массива равноправны, никаких проблем с переездами лунов и неактивными путями.

Контроллер массива
Обновлять массивы лучше в онлайне. Среднестатистический массив при обновлении перезагружает контроллеры по одному, а значит, хост в какие-то моменты времени теряет половину путей. Обычно проходит без проблем, но иногда какой-нибудь хост может затупить и не восстановить пути вовремя. Обновление следующего контроллера положит вторую половину путей. Приложения такого обращения простить не могут и валятся с глухим стуком, порождая алерты в системах мониторинга и седые волосы на головах админов. В 3PAR постарались учесть проблемы простых людей и от них нас избавить. В случае обновления или поломки контроллера его WWN-ы временно переедут на соседний контроллер. В результате пути не теряются, приклад не падает, а я буду спать спокойнее (и больше).
Размещение данных. Обычно СХД нарезаются фиксированными RAID-группами. Недостатки такого подхода следующие:
- Луны располагаются только на одной RAID-группе.
- При поломке диска в ребилде задействована одна RAID-группа. Медленно и не надёжно.
- Нужен выделенный HotSpare диск. Понятное дело, что место нужно зарезервировать в любом случае, но диск-то простаивает. Хотелось бы его использовать, особенно если это SSD в FULL FLASH массиве.
- На одном наборе дисков могут лежать луны только с одинаковым уровнем защиты.
Здесь решение такое: все диски нарезаются на маленькие кусочки, из которых можно делать луны. Для каждого луна можно выбрать уровень защиты и количество кусочков, для которых будет считаться парити. На одном диске могут лежать луны с разным уровнем защиты, а каждый лун размазан по всем дискам. Получается:
- Каждый лун равномерно распределяется по дискам СХД.
- При поломке диска в ребилде задействованы все диски массива.
- Не нужен выделенный HotSpare диск.
- На одних и тех же дисках легко размещаются данные с разным уровнем защиты.
Ну и как вам функционал? По цене — mid-range. Сравните функционал с тем, что стоит в ваших серверных.
Теоретическая часть на этом закончена, пора переходить к тестированию. Хочу заметить, что тестирование производительности не претендует на «полный отчёт по производительности массива». Для этого нужна неделя и несколько вариантов конфигурации. Здесь собраны несколько базовых тестов, дающих общее понимание возможностей СХД. В тестовой железке всего 12 дисков.

Наш экземпляр
Для оценки производительности СХД с большим количеством дисков придётся использовать логику и калькулятор. Я же тестировал три вида нагрузки. Графики ниже. Слева — луны без дедупликации, справа — такие же луны с дедупликацией. Данные, которые я писал на диск, совершенно случайны и абсолютно не дедуплицируются — мне было интересно посмотреть на «оверхед» дедупликации.
Тест 1. 100% чтение, 100% Random, блоки 4k
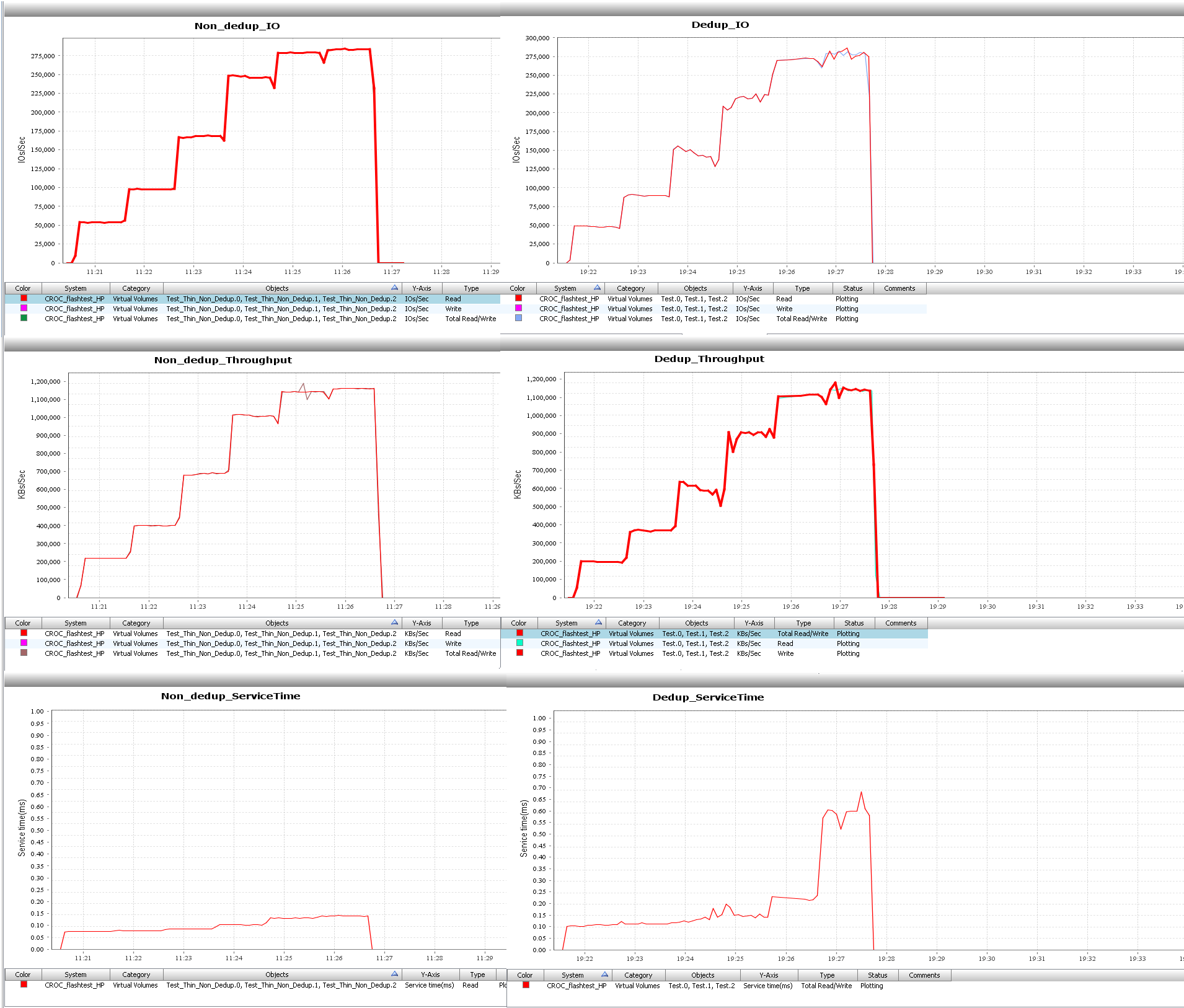
На 12 SSD дисках массив делает около 300 000 IO с временем отклика меньше секунды. К сожалению, время отклика на лунах с дедупликацией начинает «заваливаться» после 250 000 IO, но результат все равно меньше миллисекунды.
Тест 2. 70% чтение, 30% запись, 100% Random, блоки 4k
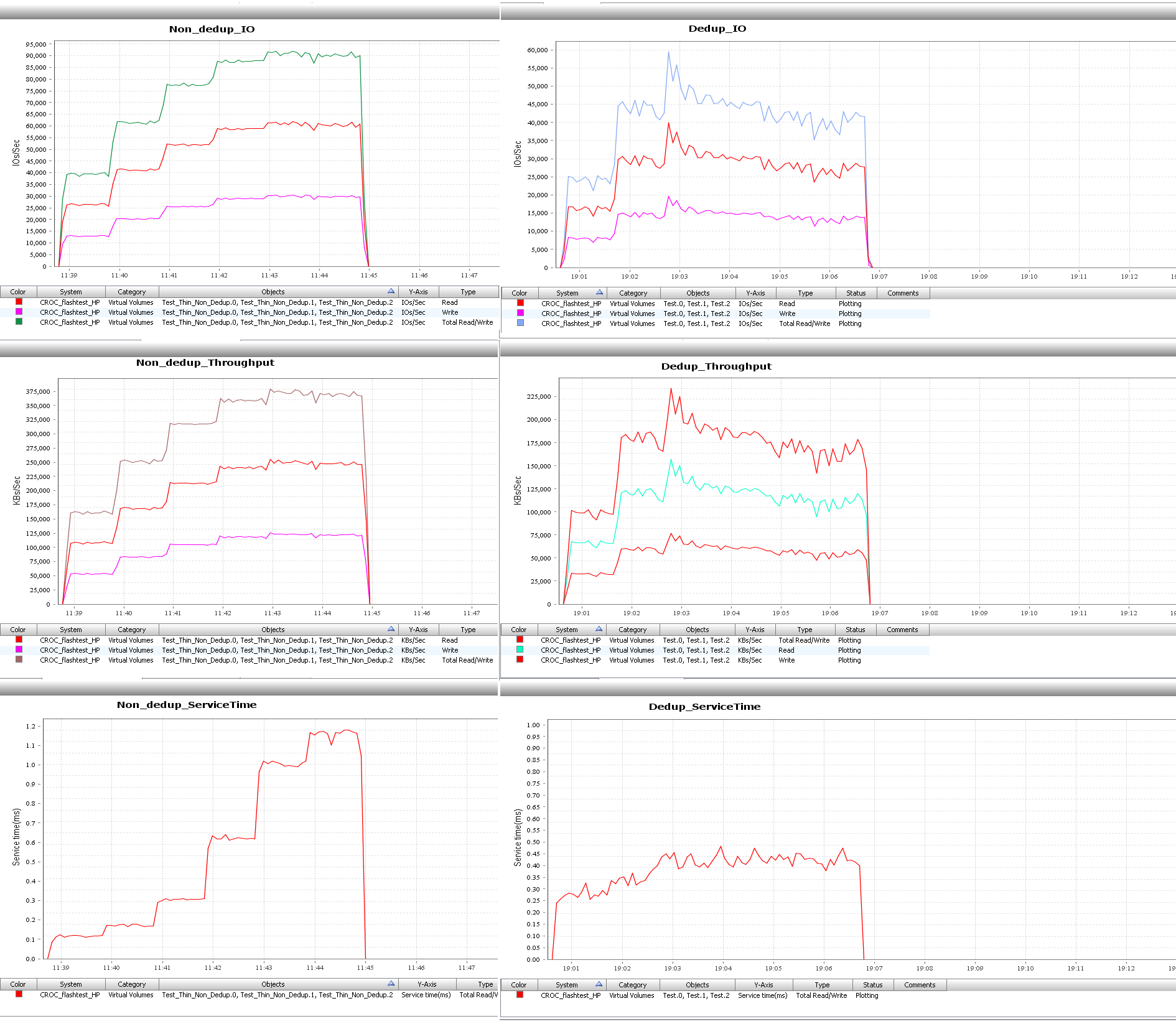
Из графиков видно, что луны с дедупликацией заметно сдали в производительности на смешанной нагрузке. Но 90 000 IO на недедуплицированном луне с откликом меньше 1 мс в СХД с 12 дисками — хороший для midrange СХД результат. Для лунов с дедупликацией на этой конфигурации 45 000 — потолок, хотя время отклика нормальное.
Тест 3. 100% запись, 100% Random, блоки 4k
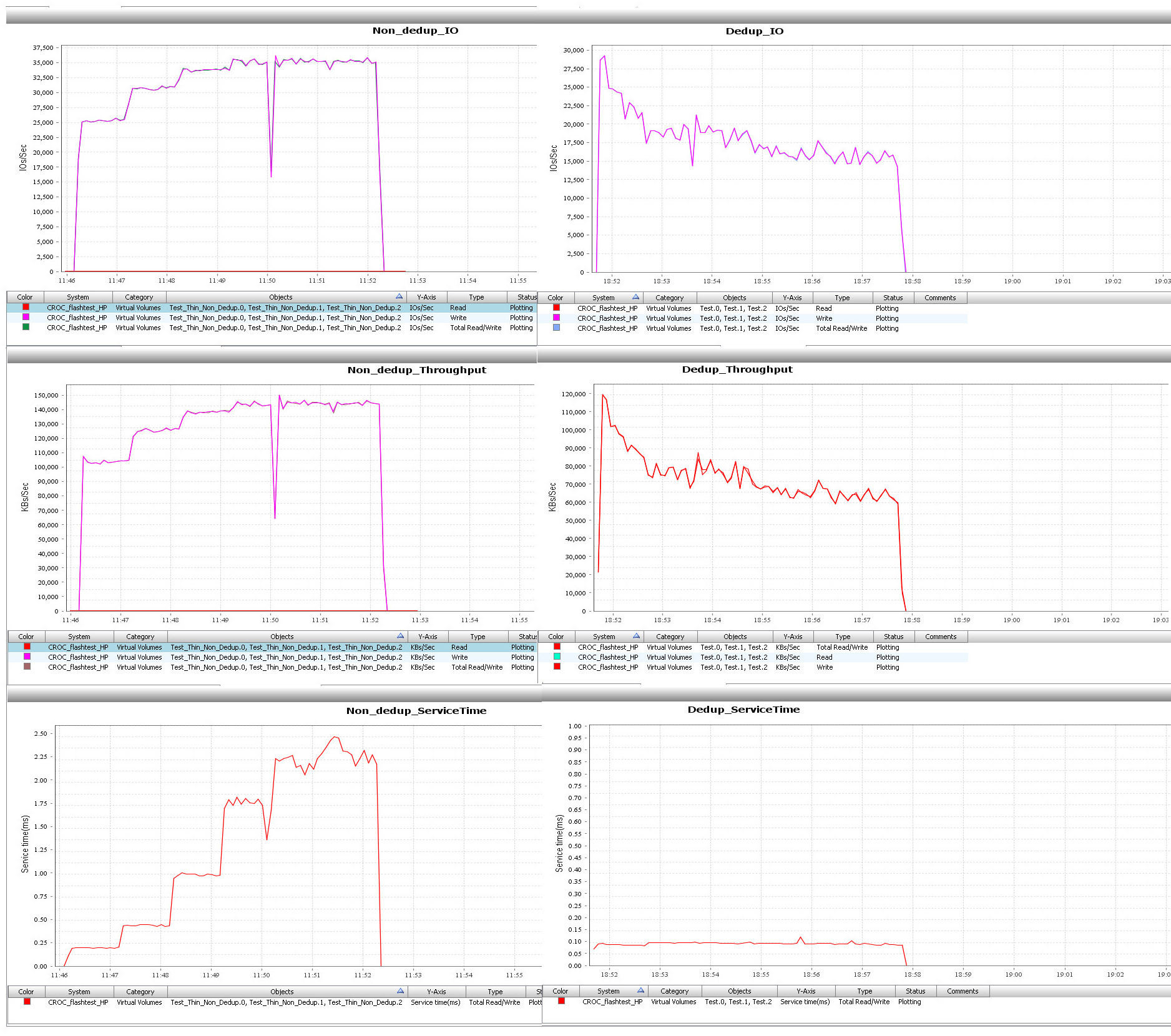
Вполне достойно для 100% случайной записи. Время отклика, конечно, немного завышено, но это легко решается добавлением дисков.
Тест 4. Классический тест с выдёргиванием диска на смешанной нагрузке
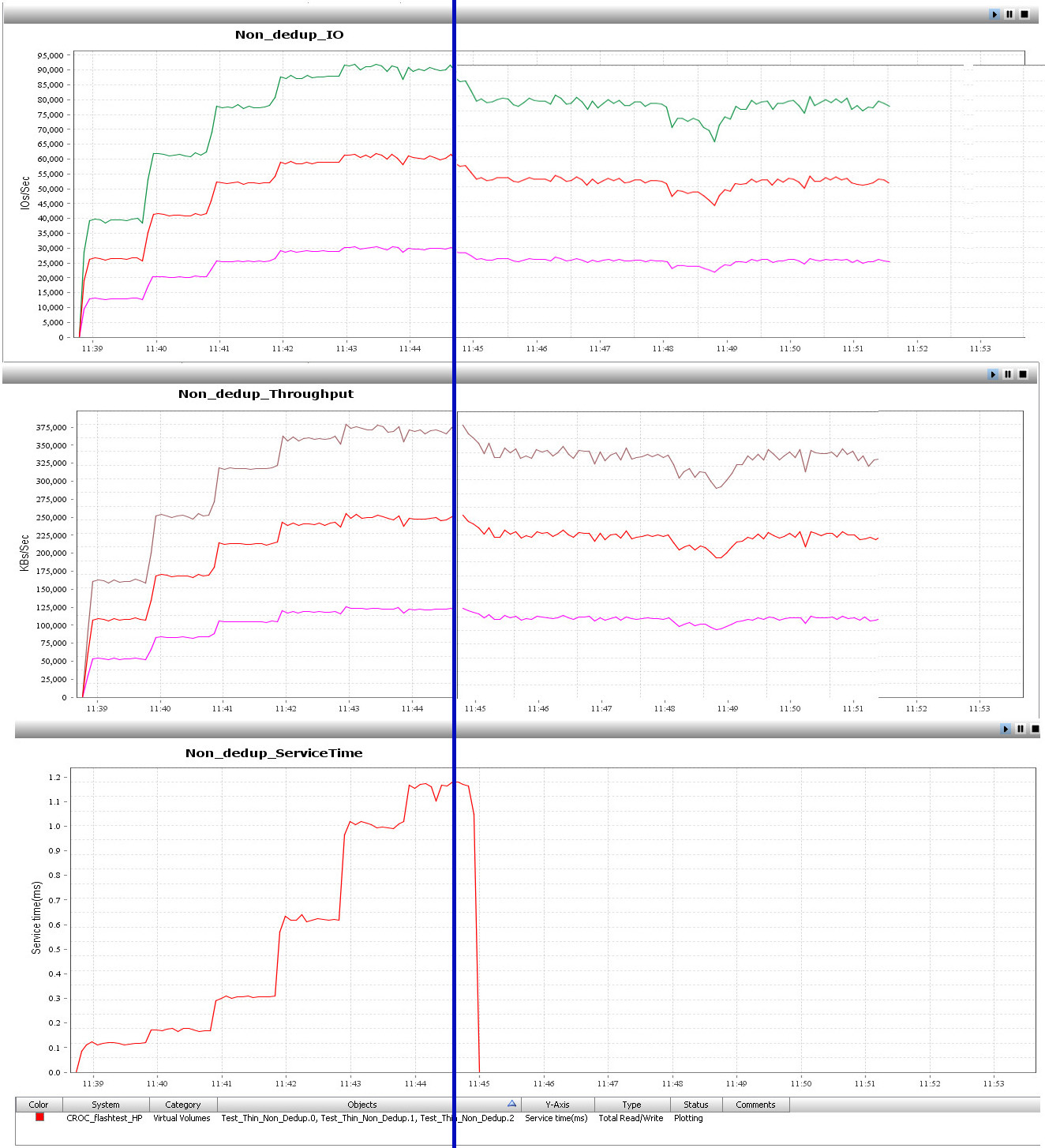
Видно, что производительность массива несколько упала, но так как в ребилде задействованы все диски одновременно, резкого падения производительности не случилось.
Самое важное
Массив станет отличной all-flash заменой тиринговому «старичку» для использования в смешанной или виртуальной среде. All-flash массив обычно дороже тирингового решения, но если учесть in-line дедупликацию, то всё может оказаться не таким очевидным. При коэффициенте дедупликации — 2, Flash массивы начинают становиться дешевле «тиринговых». Но нужно считать под конкретный кейс.
Оборудование ввозится в Россию через дистрибьютора. В среднем даже сейчас от размещения заказа до поставки проходит 8 недель. Счета за конфигураторы выставляются в долларах, при необходимости мы можем перевести спецификацию в рубли для договора. Кстати, данное оборудование можно заказать по программе Flexible Capacity Service.
Что вообще надо знать про это железо?
Максимально в массив можно забить 240 SSD дисков. Интерфейс — FC, 8 Гб/с, 8 портов, можно добавить ещё 16 портов FC или 10 GbE iSCSI. Минимум два контроллера, максимум 4 контроллера. RAID 1, RAID 5 и RAID 6. Кэш 64 ГБ на контроллерную пару.
Особенности
- Железка очень классная. 3PAR хорош для смешанных и виртуальных сред, отлично подходит для всех хорошо дуплицируемых данных (всякого рода виртуализация, VDI). Можно использовать и как универсальную СХД. Работать будет, как автомат Калашникова, но цена за гигабайт в full Flash конфигурации будет несколько выше, чем у тиринговых массивов.
- Есть и некоторые особенности. Если писать на хранилище много информации в течение долгого времени, производительность падает. На мой взгляд, это связано с используемой в дисках технологией FLASH памяти CMLC, позволяющей существенно выиграть в цене диска. Создаётся впечатление, что массив в определённые моменты искусственно ограничивает скорость записи, чтобы избежать преждевременного износа дисков, но документального подтверждения этому факту нет.
- На борту бесплатная (у других вендоров эта опция часто идёт за дополнительные деньги) дедупликация, но не надейтесь сильно дедуплицировать ей базы данных. Она затачивалась под виртуальные среды. Блок дедупликации — 16 килобайт.
- Вендор пишет цену за гигабайт 1,5 доллара. В нашем тесте она получилась выше, но всё равно очень вкусной.
Вот ссылка на описание разных технологических фишек массива.
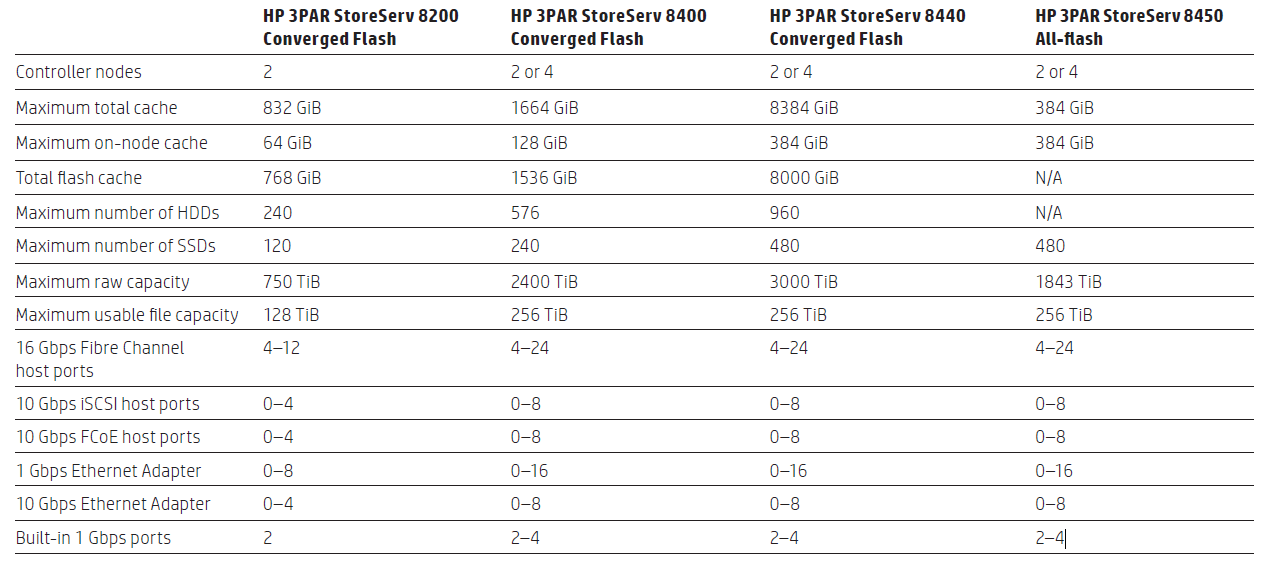
Отличия моделей линейки
На этом тестирование завершено. На вопросы готов ответить, пишите в комментариях или прямо в почту rpokruchin@croc.ru.
Комментарии (17)

rstepanov
22.09.2015 11:07+2Именно такой массив мы искали пару лет назад, у HP ничего похожего на тот момент не было и сейл нам упорно рассказывал, что оно нам не нужно. В итоге купили Хуавей, так как IBM было слишком дорого…


ximik13
22.09.2015 14:40+1Прошу прощения за оффтопик, но не сдержался :).
А отвертка на «главной» фото — это случайно не Westward? Уж больно похожа.
Если так, то не комильфо это — крутить такой отверткой HP 3Par :). Такие отвертки EMC2 поставляет в комплекте с DataDomain.RPOkruchin
23.09.2015 10:00+1Это хорошая отвертка. Я пользуюсь ей уже пару лет, и она нормально работает с любыми массивами. К счастью, HP не предъявляет требований к модели отвертки.

amarao
22.09.2015 19:22«время отклика меньше секунды». Наверное, вы хотели сказать «милисекунды»? Потому что если это официальное «а у нас SSD на IO запрос отвечают быстрее секунды», то…


AlexanderCam
23.09.2015 15:10-1«На борту бесплатная (у других вендоров эта опция часто идёт за дополнительные деньги) дедупликация» — NetApp уже лет 10 дает это for free :)
«Луны располагаются только на одной RAID-группе» — Так уже даже EMC не делает.
«В результате команда из 4 контроллеров в HP 3PAR работает значительно лучше, чем 4 малосвязанных контроллера в большинстве mid-range СХД.» — если использовать 4 контроллера, то будет 8 путей, что может вызвать проблему когерентности кэша. Нужно почитать, что на эту тему пишет сам вендор в connectivity guide (например EMC не рекомендует такой конфиг для VPLEX).
«Response time 0.1 ms» — это для SSD очень мало, даже для «True Flash» это очень мало, даже с половиной выключенных ячеек памяти на «True Flash» можно добиться около 0.25ms, а 0.1ms — это какой-то кэш.
P.S. и пора уже перестать воспринимать массив через призму IOPS'ов т.к. в большой инфраструктуре массив так же должен хорошо интегрироваться с этой инфраструктурой, т.к. IOPS'ы должны быть управляемыми.
P.P.S. реклама не удалась, КРОКу не зачет.

navion
01.10.2015 18:15Аналог DDP и дедупликация поддерживаются на обычных нефлешевых/тиринговых версиях 3Par?
Если нет, то почему? Ведь это всё фичи контроллера, а тип дисков особой роли играть не должен — в крайнем случае может понадобиться кэш из нескольких SSD.
ximik13
Мне кажется логичнее предположить, что дело все же в процессе «garbage collection» и эффекте «Write Cliff» для SSD, чем в каком-то искусственном ограничении записи.
Про это ваши коллеги-конкуренты вот в этой статье более-менее подробно писали.
RPOkruchin
Если проблема в GC, то массив должен терять производительность при случайной записи маленькими блоками быстрее, чем при последовательной записи большими блоками в один поток. В СХД, которую я тестировал, по моим ощущениям это не так. Производительность падает после определенного объема записанной информации, вне зависимости от типа записи. Для того, чтобы наверняка ответить на этот вопрос, нужен доступ к документации, которую не показывают партнерам.
Искусственное ограничение может иметь смысл, так как flash, который использует вендор, поддерживает малое количество перезаписи.
ximik13
Искусственное ограничение такого рода не имеет смысла. Если заказчик хочет записывать большое количество данных на массив, то ему ни что не помешает. Медленно или быстро, но данные будут записаны.
Найдете и почитаете описание эффекта Write Cliff для SSD решений, в том числе на англоязычных ресурсах. Основные симптомы как раз совпадают с описанными вами. Если на SSD или на all flash array идет большой поток записи и в итоге данными заполняется большой % дискового пространства, то GC (особенно когда в штатном режиме он запускается по расписанию) просто не успевает отчищать нужное количество блоков от «устаревших» данных. В результате GC продолжает работать в фоне, а вот операции записи сильно проседают. Писать то некуда, помеченные к перезаписи блоки есть, но они еще не очищены от старых данных. Это и называют эффектом Write Cliff.