OpenSource-проект arataga -- это работающий прототип производительного socks5+http/1.1 прокси-сервера. Реализован arataga на базе Asio, SObjectizer и RESTinio. Об arataga уже рассказывалось несколько месяцев назад именно как о хорошем примере того, как выглядит реальный код на SObjectizer-е. Ведь одно дело повествовать о сильных сторонах SObjectizer-а с иллюстрациями из игрушечных примеров. Совсем другое -- иметь возможность показать почти что продакшен-код.
За время, прошедшее с первой публикации, удалось погонять arataga под более серьезной нагрузкой. Можно сказать, повезло провести первые натурные испытания.
Эти испытания выявили пару узких мест, устранение которых, как мне показалось, можно привести в качестве хороших примеров применения возможностей SObjectizer-а в ситуациях "вот здесь не то, что нам хотелось бы, и это нужно как можно быстрее исправить".
В частности, мы сегодня поговорим о том, что взаимодействие агентов друг с другом только посредством асинхронных сообщений -- это не догма. И что диспетчеры SObjectizer-а влияют на безопасность многопоточного программирования не менее серьезно, чем этот самый обмен сообщениями.
Собственная реализация взаимодействия с DNS
Первым узким местом, которые выявили натурные испытания, стала процедура резолвинга доменных имен.
Отказ от Asio-шного async_resolve
В первой версии arataga ради экономии времени мы не стали делать реализацию взаимодействия с DNS посредством UDP. Вместо этого использовали средства для асинхронного резолвинга, которые доступны в Asio из коробки.
Как я понял, Asio для выполнения async_resolve использует дополнительную рабочую нить, на которой делает обычные синхронные обращения к ОС для преобразования доменного имени в набор IP-адресов. И, если одно такое обращение "притормозит", то будут приостановлены и все последующие обращения к async_resolve. Кроме того, если нам нужно выполнить резолвинг сразу нескольких имен, то параллельно мы этого сделать не можем. Резолвинг будет выполняться последовательно.
В итоге, когда потребовалось обслуживать множество параллельных преобразований доменных имен в IP-адреса Asio-шный async_resolve буквально "вставал колом". Некоторым клиентам результат операции async_resolve приходилось ждать по несколько десятков секунд (максимальные значения, насколько я помню, колебались в районе от 35 до 40 секунд, в зависимости от нагрузки).
Естественно, это никуда не годилось: при наступлении таких тормозов у большинства клиентов просто истекали тайм-ауты и куча соединений тупо отваливалась. Поэтому мы поменяли работу с DNS на свою собственную реализацию.
Работа с DNS на уровне агентов: было и стало
Не думаю, что есть смысл рассказывать о том, как именно было реализовано общение с DNS-серверами посредством UDP-датаграмм, поскольку вся эта работа сосредоточена внутри одного агента a_nameserver_interactor_t и никто деталей этой работы не видит.
Гораздо интереснее рассказывать о том, как резолвинг доменных имен представлен на уровне взаимодействия агентов в arataga.
Первоначальная схема была тривиальной: был некий интерфейсный почтовый ящик (mbox) и два сообщения -- resolve_request_t и resolve_reply_t. За этим почтовым ящиком скрывался единственный агент a_dns_resolver_t, который и отвечал за процедуру резолвинга доменных имен: держал кэш уже обработанных имен, организовывал список ждущих своей очереди доменных имен, дергал async_resolve и обрабатывал результаты резолвинга.

Важный момент, на который хотелось бы обратить внимание -- это то, что само существование dns_resolver было неизвестно другим частям arataga. Механизм резолвинга доменных имен был практически в буквальном смысле "черным ящиком". Просто есть некий mbox, в который нужно отсылать сообщения resolve_request. В каждом resolve_request передается mbox, на который затем прилетает resolve_reply. И это все, что требовалось знать.
Поэтому когда старая реализация резолвинга доменных имен была практически полностью выброшена и заменена новой, то этого внутри arataga никто и не заметил.
Новая же реализация потребовала двух разных агентов вместо одного.
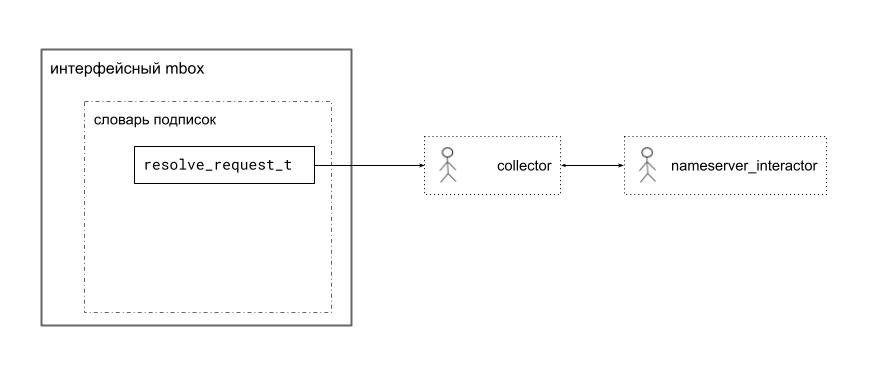
Во-первых, это агент interactor::a_nameserver_interactor_t, который непосредственно общается с DNS-серверами по UDP. Агент nameserver_interactor отвечает за преобразование конкретного запроса на резолвинг в соответствующую UDP-датаграмму и обработку ответов от DNS-серверов.
Во-вторых, это агент lookup_conductor::a_conductor_t, который принимает входящие resolve_request, проверяет наличие результатов в кэше, выстраивает в очередь запросы, для которых нужен резолвинг, и отправляет команды агенту nameserver_interactor.
А вот с conductor все не так просто :)
И самое любопытное здесь то, что на самом деле conductor-ов два.
Первоначально планировалось использовать всего один экземпляр conductor. Который бы обрабатывал и IPv4, и IPv6. По аналогии с тем, как это делал dns_resolver из первых версий arataga: dns_resolver в случае успешного результата получал список IP-адресов, в котором присутствовали и IPv4, и IPv6 адреса. И когда приходил resolve_request_t для получения IPv4 адреса, то dns_resolver выбирал из списка IPv4 адрес. А когда приходил resolve_request для IPv6 адреса, то dns_resolver искал в списке IPv6 адрес (либо же конвертировал в IPv6 один из IPv4 адресов).
Такая схема была принята потому что Asio-шный async_resolver мог вернуть в случае успеха список с двумя типами адресов.
И при рефакторинге взаимодействия с DNS-серверами предполагалось, что таким же образом будет работать и nameserver_interactor.
Но в процессе тестирования nameserver_interactor с реальными DNS-серверами выяснилось, что работает либо запрос ресурсной записи типа A, либо запрос ресурсной записи типа AAAA. Но вот если отослать в одной UDP-датаграмме сразу два запроса (и для A, и для AAAA), то ответ придет только на один из них.
Посему имея на руках почти готовые реализации conductor и nameserver_interactor нужно было что-то оперативно решать. Понятно, что при обращении к nameserver_interactor придется явно указывать тип IP-адреса (IPv4 или IPv6). Но не понятно, как быть с кэшированием результатов и выстраиванием запросов в очереди.
Усложнять conductor и делать в нем отдельные кэши/очереди для разных типов IP-адресов? Вести общий кэш, в котором будут хранится адреса обоих типов и инициировать запрос к nameserver_interactor, если адресов нужного типа в кэше нет?
Тратить дополнительное время на рефакторинг conductor не хотелось, поэтому в модном и молодежном стиле "фигак-фигак и в продакшен" был применен метод грубой силы: вместо одного conductor-а запускается сразу два. Один обслуживает запросы для IPv4, второй -- запросы для IPv6. И оба они подписываются на сообщения resolve_request из интерфейсного mbox-а.
Вопрос был лишь в том, чтобы разрулить поток resolve_request между этими двумя агентами. Нужно был как-то сделать так, чтобы один агент получал только запросы для IPv4, а второй -- только запросы для IPv6.
Сделать это оказалось совсем не сложно. Были применены фильтры доставки для сообщений.
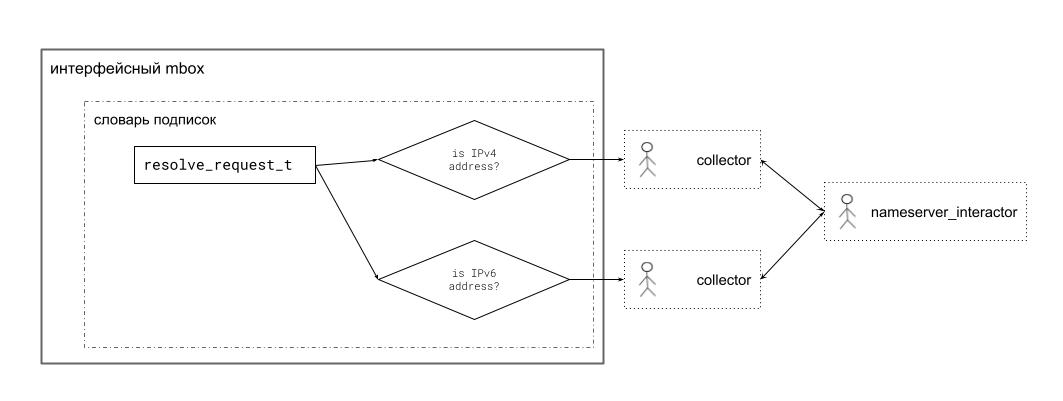
Фильтры доставки -- это предикаты, которые агент может "навесить" на сообщения из конкретного multi-consumer mbox-а. Когда сообщение отсылается в mbox, то mbox обращается к предикату с вопросом "можно ли доставлять конкретно этот экземпляр сообщения до твого владельца?" Если предикат говорит, что можно, то сообщение доставляется. Если нет, то игнорируется.
Благодаря фильтрам доставки агента conductor не пришлось переделывать для того, чтобы запускать его в двух экземплярах. Все, что потребовалось сделать -- это добавить установку фильтра перед подпиской:
void
a_conductor_t::so_define_agent()
{
// We want to receive only requests for our IP-version.
so_set_delivery_filter(
m_incoming_requests_mbox,
[ip_ver = m_ip_version]( const resolve_request_t & req ) {
return ip_ver == req.m_ip_version;
} );
so_subscribe( m_incoming_requests_mbox )
.event( &a_conductor_t::on_resolve );Каков результат этих изменений?
Главный результат -- это возможность параллельного выполнения множества операций резолвинга имен без формирования длинных очередей и долгого ожидания в этих очередях. В итоге по тайм-ауту отваливаются только те запросы, на которые не отвечают сами DNS-сервера. А это на практике происходит очень и очень редко. Так что количество соединений, не получивших обслуживания из-за тайм-аутов DNS, сократилось драматически.
Таймеры для acl_handler-ов
Первые запуски arataga под реальной нагрузкой показали, что потребление ресурсов у arataga не настолько низкое, как хотелось бы. Что и не удивительно, т.к. arataga все еще в стадии прототипа и под высокой нагрузкой тестов было совсем мало, так что узких мест там наверняка множество.
Одно из них оказалось прямо на поверхности, не пришлось даже глубоко копать.
Дело в том, что внутри arataga есть специальное сообщение one_second_timer, которое генерируется раз в секунду и которое используется acl_handler-ами для разных целей: и для контроля тайм-аутов текущих операций, и для пересчета лимитов по подключениям.
Дабы не тратить время при выпуске первой версии arataga была использована самая простая схема: каждый acl_handler просто подписывается на one_second_timer. Что означает, что когда это сообщение возникает, то оно доставляется всем подписчикам.

Т.е., если у нас создано 15K acl_handler-ов, то раз в секунду у них у всех запускается обработчик one_second_timer. Что и увеличивает потребление CPU.
Проблема в том, что далеко не у всех из этих 15K acl_handler-ов в настоящий момент есть необходимость реагировать на one_second_timer. У части acl_handler-ов не будет вообще подключений, которые нужно обслуживать. И доставлять one_second_timer до таких acl_handler-ов нет смысла.
Только вот если агент подписался на сообщение, то сообщение к нему будет доставлено. Даже если сейчас агент в нем и не заинтересован.
Поэтому встал вопрос о том, как сделать так, чтобы на таймер реагировали только те acl_handler-ы, которые в таймере сейчас заинтересованы. И сделать это дешево.
Какие подходы нельзя назвать хорошими?
Фильтры доставки
Можно было бы попробовать задействовать фильтры доставки (о которых речь уже шла выше). Так, фильтр доставки при отсылке сообщения проверял бы наличие принятых подключений у acl_handler-а и, если подключений нет, то запрещал бы доставку сообщения.
Тут сразу несколько проблем.
Во-первых, отсылка сообщения one_second_timer идет с контекста специальной нити таймера, которой управляет сам SObjectizer. И на этой же нити в процессе отсылки сообщения запускаются фильтры доставки. Следовательно, если фильтр доставки хочет обратиться к каким-то потрохам acl_handler-а, то эти потроха должны быть как-то защищены с точки зрения thread-safety. Например, посредством mutex-а. Что отнюдь не бесплатно. И затрудняет реализацию самого acl_handler-а, т.к. внутри агента нужно заботиться о thread-safety, хотя агенты как раз и нужны, чтобы такими вещами не заниматься.
Во-вторых, если у нас много acl_handler-ов, то запуск фильтров доставки для каждого них -- это ведь такая же лишняя работа, как и доставка one_second_timer. Да, это может быть чуть дешевле. Но именно что чуть.
Так что фильтры доставки, наверное, могли бы немного снизить актуальность проблемы, но точно не устранили бы ее.
Подписка/отписка на/от one_second_timer
Если нужно доставлять one_second_timer только до агентов, которые обслуживают принятые подключения, то напрашивается простой и логичный подход: пусть acl_handler при принятии первого подключения создает подписку на one_second_timer, а при потере последнего подключения -- отписывается от one_second_timer.
Это нормальный подход. По крайней мере он идеологически правильный и не ведет к каким-либо проблемам с thread-safety.
Но его нельзя назвать совсем уж дешевым. Ведь подписка на mbox -- это захват нескольких объектов синхронизации (в mbox-е и в агенте-подписчике) + несколько аллокаций памяти на создание объектов-подписок.
А хотелось бы, чтобы работа с one_second_timer была еще дешевле.
Использованный подход
Для того, чтобы еще более снизить расходы на доставку one_second_timer только до тех, кто в этом нуждается, был применен следующий трюк.
Введено понятие timer_provider. Это интерфейс объекта, который должен присутствовать на каждой io_thread в единственном числе. Его задачей является периодический вызов метода on_timer у привязанных к этой же io_thread объектов timer_consumer. Но не у всех timer_consumer, а только у тех, кто заявил о себе timer_provider-у. Т.е., когда у timer_consumer появляется потребность в обработке таймера, он вызывает у timer_provider-а метод activate_consumer, а когда такая потребность исчезает -- вызывает метод deactivate_consumer. Таким образом у timer_provider есть список активных timer_consumer-ов.
За интерфейсом timer_provider скрывается простой агент, который подписывается на one_second_timer. Получив это сообщение timer_provider просто бежит по своему списку активных timer_consumer-ов и вызывает у них on_timer.
timer_consumer-ами являются acl_handler-ы. Когда у acl_handler-а (он же timer_consumer) появляется первое принятое подключение, то acl_handler добавляет себя в список к timer_provider-у. А когда подключений не остается acl_handler вычеркивает себя из списка timer_provider-а.

Фокус в том, что все взаимодействующие в рамках одной io_thread timer_provider и timer_consumer-ы привязанны к одному и тому же диспетчеру. Что гарантирует, что они работают на одной и той же рабочей нити. А значит могут обращаться друг к другу не боясь приключений с thread-safety.
Это отличный пример того, как при работе с SObjectizer-ом отказаться от взаимодействия с агентами только посредством асинхронного взаимодействия и выполнять синхронные вызовы методов агентов, но при этом не иметь проблем с thread-safety. Ведь диспетчеры в SObjectizer-е и были введены как раз для того, чтобы программист мог управлять тем где и как работают его агенты. И, если у программиста есть возможность директивно привязать своих агентов к конкретной нити, то почему бы этим не пользоваться. По крайней мере в условиях, когда хочется выжимать максимум.
Защита от повисших указателей
Сейчас timer_provider и timer_consumer хранят указатели друг на друга. Но, при этом агенты, реализующие данные интерфейсы, принадлежат разным кооперациям. Т.е. уничтожаться они могут в разном порядке.
Когда у acl_handler-а (т.е. у timer_consumer-а) вызывается so_evt_finish (это последнее событие для агента перед дерегистрацией), то acl_handler вычеркивает себя из списка timer_provider-а. Так что у timer_provider-а не может остаться повисших указателей на timer_consumer-ы (в теории, по крайней мере).
Но что с самим указателем на timer_provider? Как сделать так, чтобы он оставался валидным до тех пор, пока жив хотя бы один acl_handler?
Очень просто: кооперация с агентом timer_provider выступает в качестве родительской для всех коопераций с acl_handler-aми. В этом случае SObjectizer гарантирует, что родительская кооперация не будет уничтожена пока есть хотя бы одна живая дочерняя кооперация. Т.е. указатель на timer_provider внутри timer_consumer-ов будет оставаться валидным.
Каков результат этих изменений?
В зависимости от конфигурации, количества ACL внутри arataga и входящей нагрузки расход CPU на тестовых прогонах снизился от 1.5 до 4-х раз.
Заключение
Для нас arataga получился интересным полигоном для еще одних натурных испытаний SObjectizer и RESTinio. Да еще и с возможностью открыто показать как выглядит реальный код на SObjectizer-е.
Надеюсь, что читателям, которые следят за SObjectizer, было интересно. Если есть какие-то вопросы или непонятные моменты, то я с удовольствием отвечу на них в комментариях.
В завершение хочу сказать вот что: не смотря на то, что пока у нас нет ресурсов на дальнейшее развитие своего OpenSource, тем не менее проекты не заброшены. Если кто-то находит ошибки, мы их исправляем. Если у кого-то возникают вопросы, то стараемся помочь. Иногда даже выпускаем обновления с мелкими улучшениями.
Так что, если у кого-то есть сомнения о том, брать или не брать SObjectizer/RESTinio/json-dto в работу, то отбросьте их и попробуйте. В случае сложностей или проблем смело обращайтесь к нам, без помощи не оставим.
SokoloffA
Про таймеры для acl_handler-ов, как я понял проблема в том, что все хэндлеры срабатывали в одно время. Мне пришло в голову другое решение, что-то вроде шардирования. Генерировать сообщение one_second_timer не раз в секунду, а, скажем 10 раз, и передавать соответствующее число от 0 до 9. А хэндлеры при подписке случайно генерят число (1-9) и ставят соответствующий фильтр. В результате хэндлеры запускаются не все разом, а группами.
eao197 Автор
В одно время генерировались заявки на запуск хэндлеров. Далее уже хэндлеры на каждой io_threads запускались последовательно.
Соответственно, накладные расходы складываются из двух составляющих:
Если использовать предложенный вами метод, то от пункта №1 вообще не избавляемся (более того, он становится даже более дорогим, т.к. придется запускать еще и фильтры доставки). Пункт №2 так же никуда не уходит, просто он начинает складываться из нескольких составляющих (по количеству шард).
Вашу идею можно было бы развить следующим образом: завести не один mbox для one_second_timer, а N. И заставлять acl_handler-ов подписываться на один из них (случайным образом или посредством какого-то распределения). Для каждого из этих N mbox-ов запускается свой экземпляр one_second_timer. Тогда при наступлении очередного таймерного события единовременная отсылка для каждого из этих N mbox-ов занимала бы гораздо меньше времени.
Как развитие этой идеи можно было бы сделать свой кастомный mbox, который бы сам шардировал подписки. И когда таймер отдает этому mbox-у очередной one_second_timer, то сам mbox отдает one_second_timer сперва первой шарде, затем второй, затем третьей и т.д. Основой для шардирования могли бы стать идентификаторы рабочих нитей, с которых выполняется подписка.
Однако, ключевой момент в том, что если у нас из 15K acl_handler-ов в таймере сейчас заинтересованы только 5K, то оставшиеся 10K вообще никак нельзя трогать.