Кому будет интересно?
Реактор сегодня - это стильно, модно, молодежно. Почему многие из нас практикуют реактивное программирование? Мало кто может ответить однозначно на этот вопрос. Хорошо - если Вы понимаете свой выигрыш, плохо - если реактор навязан организацией как данность. Большинство аргументов "ЗА" - это использование микросервисной архитектуры, которая в свою очередь обязывает микросервисы часто и много коммуницировать между собой. Для коммуникации в большинстве случаев выбирают HTTP взаимодействие. Для HTTP нужен легковесный веб-сервер, а что первое приходит на ум? Tomcat. Тут появляются проблемы с лимитом на максимальное количество сессий, при превышении которого веб-сервер начинает реджектить запросы (хотя лимита этого не так уж и легко достичь). Здесь на подмогу приходит реактор, который подобными лимитами не ограничен, и, например, Netty в качестве веб-сервера, который работает с реактивностью из коробки. Раз есть реактивный веб-сервер, нужен реактивный веб-клиент (Spring WebClient или Reactive Feign), а раз клиент реактивный, то вся эта жуть просачивается в бизнес логику, Mono и Flux становятся Вашими лучшими друзьями (хотя по началу есть только ненависть :))
Среди бизнес задач, очень часто встречаются серьезные процедуры, которые обрабатывают большие массивы данных, и нам приходится применять реактор и для них. Тут начинаются сюрпризы, если реактор не уметь готовить, можно и проблем схлопотать очень много. Превышение лимита файловых дескрипторов на сервере, OutOfMemory из-за неконтролируемой скорости работы неблокирующего кода и многое многое другое, о чем мы сегодня поговорим. Мы с коллегами испытали очень много трудностей из-за проблем с пониманием как держать реактор под контролем, но всё что нас не убивает - делает нас умнее!
Блокирующий и неблокирующий код
Вы ничего не поймете дальше, если не будете понимать разницу между блокирующим и неблокирующим кодом. Поэтому, остановимся и внимательно разберемся в чем разница. Вы уже знаете, блокирующий код реактору - враг, неблокирующий - бро. Проблема лишь в том, что в настоящий момент времени, не все взаимодействия имеют неблокирующие аналоги.
Лидер здесь - HTTP взаимодействие, вариантов масса, выбирай любой. Я предпочитаю Reactive Feign от Playtika, в комбинации со Spring Boot + WebFlux + Eureka мы получаем очень годную сборку для микросервисной архитектуры.
Давайте по-простому: НЕблокирующий код, это обычно всё, в названии чего есть reactive, а блокирующий - все оставшееся :) Hibernate + PostgreSQL - блокирующий, отправить почту через JavaMail - блокирующий, скинуть сообщение в очередь IBMMQ - блокирующий. Но есть, например, реактивный драйвер для MongoDB - неблокирующий. Отличительной особенностью блокирующего кода, является то, что глубоко внутри произойдет вызов метода, который заставит Ваш поток ждать (Thread.sleep() / Socket.read() и многие подобные), что для реактора - как нож в спину. Что же делать? Большинство бизнес логики завязано на базу данных, без нее никуда. На самом деле достаточно знать и уметь делать 2 вещи:
Необходимо понимать где блокирующий код. В этом может помочь проект BlockHound или его аналоги (тут тема для отдельной статьи)
Исполнение блокирующего кода необходимо переключать на пулы, готовые его выполнять, например:
Schedulers.boundedElastic(). Делается это при помощи операторовpublishOn&subscribeOn
Разгоняемся сами
Перед тем, как продолжить, необходимо немного размяться!
Уровень 1
@Test
fun testLevel1() {
val result = Mono.just("")
.map { "123" }
.block()
assertEquals("123", result)
}Начнем с простого, такой код обычно пишут начинающие reactor программисты. Как начать цепочку? Mono.just и ты на коне :) Оператор map трансформирует пустую строку в "123" и оператор block делает subscribe.
Обращаю особенное внимание на оператор
block, не поддавайтесь соблазну использовать его в Вашем коде, исключение составляют тесты, где это очень удобно. При вызовеblockвнутри метода ВашегоRestController, Вы сразу получите исключение в рантайме.
Уровень 2
fun nonBlockingMethod1sec(data: String)
= data.toMono().delayElement(Duration.ofMillis(1000))
@Test
fun testLevel2() {
val result = nonBlockingMethod1sec("Hello world")
.flatMap { nonBlockingMethod1sec(it) }
.block()
assertEquals("Hello world", result)
}Усложняем наш код, добавляем неблокирующий метод nonBlockingMethod1sec, все что он делает - ожидает одну секунду. Все что делает данный код - дважды, по очереди, запускает неблокирующий метод.
Уровень 3
fun collectTasks() = (0..99)
@Test
fun testLevel3() {
val result = nonBlockingMethod1sec("Hello world")
.flatMap { businessContext ->
collectTasks()
.toFlux()
.map {
businessContext + it
}
.collectList()
}
.block()!!
assertEquals(collectTasks().toList().size, result.size)
}Начинаем добавлять самое интересное - Flux! У нас появляется метод collectTasks, который собирает массив из сотни чисел, и далее мы делаем из него Flux - это будет наш список задач. К каждой задаче мы применяем трансформацию через оператор map. Оператор collectList собирает все результаты в итоговый список для дальнейшего использования.
Здесь наш код начинает превращаться в рабочий паттерн, который можно использовать для массового выполнения задач. Сначала мы собираем некий "бизнес контекст", который мы используем в дальнейшем для выполнения задач.
Уровень 4
fun collectTasks() = (0..100)
@Test
fun testLevel4() {
val result = nonBlockingMethod1sec("Hello world")
.flatMap { businessContext ->
collectTasks().toFlux()
.flatMap {
Mono.deferContextual { reactiveContext ->
val hash = businessContext + it + reactiveContext["requestId"]
hash.toMono()
}
}.collectList()
}
.contextWrite { it.put("requestId", UUID.randomUUID().toString()) }
.block()!!
assertEquals(collectTasks().toList().size, result.size)
}Добавляем немного плюшек. Появилась запись данных (15) в реактивный контекст, а также чтение (10) из него. Мы почти у цели. Постепенно переходим к итоговому варианту
Уровень 5
fun collectTasks() = (0..1000)
fun doSomethingNonBlocking(data: String)
= data.toMono().delayElement(Duration.ofMillis(1000))
fun doSomethingBlocking(data: String): String {
Thread.sleep(1000); return data
}
val pool = Schedulers.newBoundedElastic(10, Int.MAX_VALUE, "test-pool")
private val logger = getLogger()
@Test
fun testLevel5() {
val counter = AtomicInteger(0)
val result = nonBlockingMethod1sec("Hello world")
.flatMap { _ ->
collectTasks().toFlux()
.parallel()
.runOn(pool)
.flatMap {
Mono.deferContextual { _ ->
doSomethingNonBlocking(it.toString())
.doOnRequest { logger.info("Added task in pool ${counter.incrementAndGet()}") }
.doOnNext { logger.info("Non blocking code finished ${counter.get()}") }
.map { doSomethingBlocking(it) }
.doOnNext { logger.info("Removed task from pool ${counter.decrementAndGet()}") }
}
}.sequential()
.collectList()
}
.block()!!
assertEquals(collectTasks().toList().size, result.size)
}Вот мы и добрались до итогового варианта! Часть с реактивным контекстом была опущена для более наглядной демонстрации того, зачем мы здесь собрались. У нас появились два новых метода: doSomethingNonBlocking (3) & doSomethingBlocking (6) - один с неблокирующим ожиданием в секунду, второй с блокирующим. Мы создали пул потоков для обработки задач (10), добавили счетчик активных задач в реакторе (15). У нас появился оператор parallel (19) и обратный ему sequential (29). Задачи мы назначили на свежесозданный пул (20). Для понимания, что же происходит внутри, добавили логирование внутри операторов doOnRequest (вызывается перед исполнением метода), doOnNext (вызывается после исполнения метода). Основная задумка - на примере, определить сколько задач одновременно выполняется в реакторе и за какое время цепочка завершит свою работу.
Такой "паттерн", мы с коллегами очень часто применяем для выполнения сложных задач, таких как отправка отчетов или массовая обработка транзакций. Первым делом собирается бизнес контекст - это некая структура, содержащая в себе информацию, полученную в результате вызовов других микросервисов. Бизнес контекст необходим нам для выполнения самих задач, и собирается он заранее, чтобы не тратить время в процессе обработки. Далее мы собираем список задач, превращаем их во Flux и скармливаем реактору на параллельную обработку.
И вот здесь начинается самое интересное. Попробуйте ответить на несколько вопросов. Как Вы считаете, сколько времени будет выполнятся данная цепочка? В ней 100 задач, в каждой задаче неблокирующее ожидание в 1 секунду, блокирующее ожидание в 1 секунду, и у нас в наличии пул из 10 потоков? (Вполне годная задачка на собеседование senior reactor developer :))
Правильный ответ
Около 12 секунд. Рассуждаем от блокирующего :) Блокирующее ожидание никуда не деть, и тут имеем 100 блокирующих секунд на 10 потоков, итого 10 секунд. Неблокирующее ожидание заметно нам лишь в первый раз, далее оно незаметно запускается в передышках между блокирующим. Не забываем про одну секунду сбора "бизнес контекста" перед запуском задач.
А теперь уберем строку (26) .map { doSomethingBlocking(it) } . Освободим наш реактор от блокирующего кода, интересно, сколько теперь времени займет выполнение цепочки?
Правильный ответ
2 секунды! 1 на сбор "бизнес контекста" и 1 на выполнение всех задач. Реактор запустит 100 задач одновременно. Но ведь у нас пул из 10 потоков? Как так? Первый разрыв шаблона.
Мы идем до конца и увеличиваем количество задач в методе collectTasks() до ... 1000? а может быть сразу до 15000? Как долго реактор будет выполнять столько задач?
Правильный ответ
2 секунды! 1 на сбор "бизнес контекста" и 1 на выполнение всех задач. Реактор запустит ВСЕ задачи одновременно. Второй разрыв шаблона. Где предел?
А это вообще легально?
Как же так и как это контролировать? Почему это опасно? Что если внутри параллельной обработки Вы решите вызвать другой микросервис? Если у вас 30000 задач, и по завершению каждой, Вам нужно отправлять запрос соседнему микросервису, Вы с удивлением можете обнаружить, что реактор непременно постарается выполнить все вызовы одновременно (Вы ведь используете реактивный web-client или реактивный feign, верно?) Открытие такого большого количества сокетов повлечет за собой превышение лимита открытых файловых дескрипторов в системе, что как минимум создаст проблемы с невозможностью создания новых сокетов в системе и помешает другим сервисам, а как максимум повалит Вам на сервере SSH и Вы потеряете доступ к серверу. Сомневаюсь, что в этот момент, программист будет кричать "зато смотри как быстро работает".
Разрыв шаблона. Thread Pool & Reactor
Основная проблема начинающего реактор программиста - это образ мышления, если есть медленный процесс - добавь X потоков, будет быстрее в X раз, а если слишком быстро - сократи количество потоков. Как всё просто было раньше? :) С реактором это не работает.
Классический thread pool - двери. Больше дверей - больше пропускная способность, все работает быстрее.

Теперь встречайте reactor! Вы видите двери? Нет никаких дверей

Реактор это большой мешок с подарками, или воздушная труба, задачи в которую валятся и летают там пока не выполнятся. А кто эти люди в желтом? Это наши epoll реактивные потоки, которые ни в коем случае нельзя нагружать блокирующими задачами. Можно провести аналогию с прорабами или инженерами. Они здесь, чтобы управлять процессом, а не чтобы выполнять тяжелую работу. Займите одного инженера тяжелой задачей, и когда к нему придет следующий рабочий с вопросом "что делать дальше?", он не сможет ответить, потому что был занят. Вот так и появляются таймауты в реактивном коде. Казалось бы микросервис стоит без нагрузки, выполняет какие-то задачки, а один из 500 запросов к нему падает с тайм-аутом, и непонятно почему. Велика вероятность что инженер был занят блокирующей задачей! Заботьтесь о своих инженерах и поручайте тяжелую работу специально обученным рабочим, например, Schedulers.boundedElastic().
Как контролировать эту "трубу", в которую валится всё без контроля? Вот мы и подошли к кульминации
Конфигурируем реактор!
В своей дефолтной конфигурации, параллельная обработка в реакторе зависит от количества ядер процессора сервера, на котором запускается код, поэтому, к своему удивлению, Вы получите разные результаты, проверяя работу реактора в тесте на локальной машине с 4-8 ядрами и production сервере с 32 ядрами.
Парад настроек открывает parallel с его аргументом parallelism
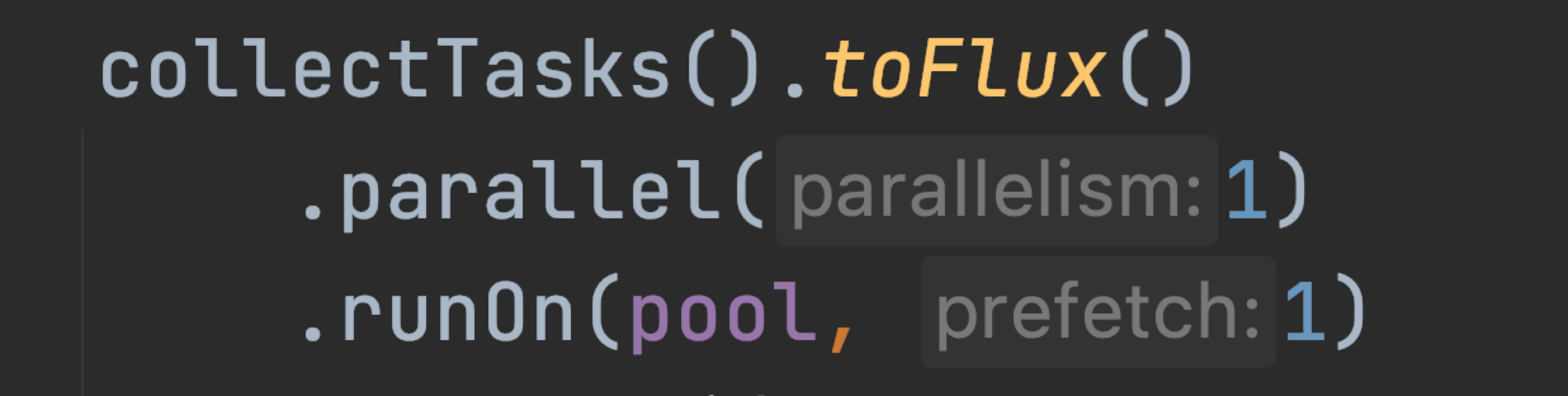
Меняя parallelism, мы можем регулировать количество запускаемых rails (это местное понятие реактора, которое похоже на корутины, но по сути является количеством одновременно выполняемых неблокирующих задач). Prefetch мы рассмотрим более подробно в следующем разделе.
Но одного parallelism недостаточно, реактор все еще будет нагребать задач как не в себя.
Мало кто обращал внимание что у оператора flatMap (только того что запускается на Flux) есть перегрузки с интересными аргументами, а именно maxConcurrency

maxConcurrency очень важен, по дефолту значение стоит Integer.MAX_VALUE (определяет сколько неблокирующих задач может выполняться одновременно на одной рельсе. Понимаете теперь откуда аппетит у реактора?
Также, не стоит забывать, что если цепочка будет запущена несколько раз (вызов одного http метода контроллера несколько раз), то все помножится! Никакой пул не спасет.
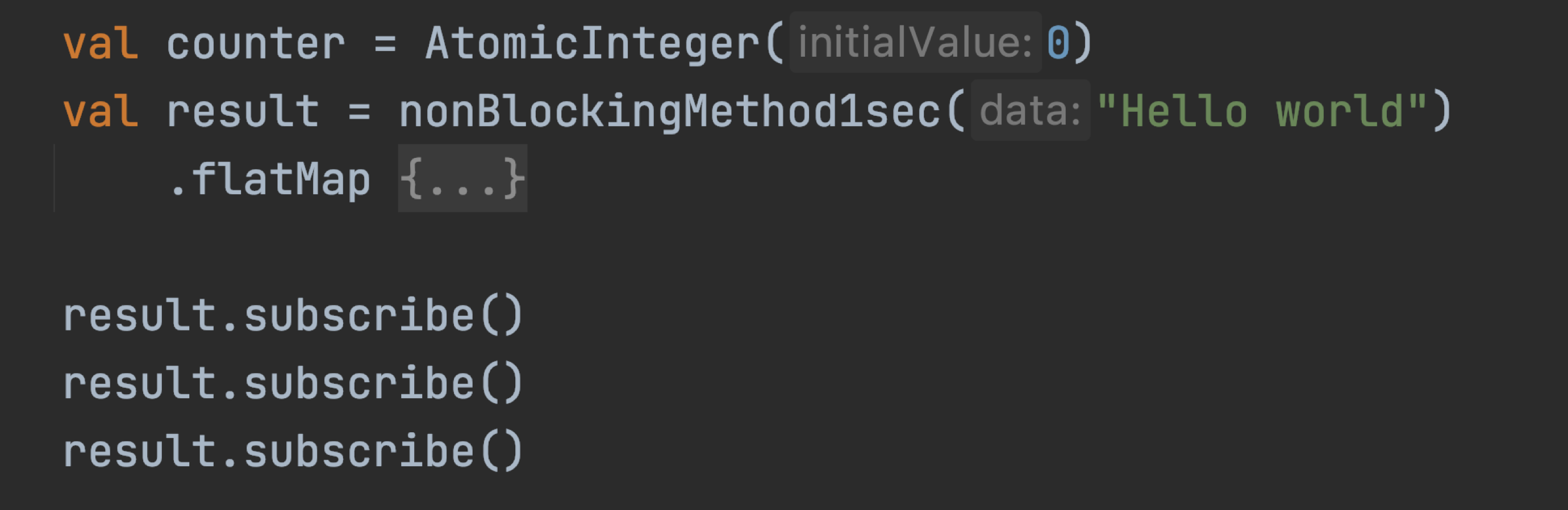
Количество запусков цепочки напрямую влияет на количество одновременно выполняемых задач.
Подведем небольшой итог:
parallel (parallelism)
flatMap (maxConcurrency)
Количество запусков цепочки
Эти три параметра являются множителями, для расчета количества одновременных задач.
По дефолту это Кол-во ядер * Integer.MAX_VALUE * Количество запусков цепочки
Напротив же, запустив данный код для 5 задач длительностью в секунду мы получим цепочку работающую 5 секунд. Теперь всё под контролем!
val result = nonBlockingMethod1sec("Hello world")
.flatMap { _ ->
collectTasks().toFlux()
.parallel(1)
.runOn(pool, 1)
.flatMap({
Mono.deferContextual { _ ->
doSomethingNonBlocking(it.toString())
}
}, false, 1, 1)
.sequential()
.collectList()
}
.block()!!Стоп, или не всё?
Thread Pool
Зачем же нужен пул потоков в реакторе? Думайте о нем как о двигателе для Вашего автомобиля. Чем пул мощнее - тем блокирующие задачи будут разбираться быстрее, а если потоков мало, то и блокирующие задачи задержатся у вас надолго! А куда же мы без блокирующих вызовов? На количество одновременно выполняемых задач в реакторе он не влияет, вот это поворот :)
Надеюсь, Вы не пробовали использовать Schedulers.parallel() для исполнения Вашего блокирующего кода? =) Несмотря на свое подходящее название
(ну называется он parallel, значит и нужен для параллельной обработки)использовать этот пул можно только для неблокирующего кода, в доке указано что он живет с одним воркером, и содержит в себе только особенные, реактивные потоки.
Распределение задач по рельсам
Не коснулись мы еще одной важной темы. Обычно, мы пытаемся закончить обработку большого массива данных в кратчайший срок, с чем нам определенно поможет изложенный выше материал, но это еще не все. В тестах мы часто используем синтетические данные, которые генерируем одинаковыми порциями, исключая погрешности production среды. Задачи обычно выполняются разное время и это создает проблемы с равномерным распределением задач.
Зеленые прямоугольники это наши задачи, которые распределяются в реакторе по алгоритму round-robin, что в случае с синтетическими данными дает красивую картинку.
.
54 блокирующих задачи (каждая по 1сек),? round-robin распределение по 6 рельсам")
Но запуская код в production среде, мы можем встретиться с долгим запросом в базу, сетевыми задержками, плохим настроением микросервиса да и чего только не бывает.

54 блокирующих задачи (каждая по 1сек кроме 2ух),? round-robin распределение по 6 рельсам")
Оператор collectList() вернет нам результат только после завершения последней задачи, и как мы видим, наш пул будет простаивать пока 1 поток трудится разгребая очередь накопившихся задач. Это создает неприятные задержки, когда Вы знаете что можно быстрее, но быстрее не происходит.
Бороться с этим можно несколькими способами
concatMapвместоflatMap(посмотрите в профилировщик на ваш пул, передумаете)правильно планировать задачи, чтобы исключить аномалии (почти невозможно)
дробить каждую задачу на много мелких, и также запускать их в параллельную обработку чтобы нивелировать проблемы с распределением (вполне рабочий вариант)
prefetch(наш выбор!)
Параметр prefetch у flatMap & runOn позволяет определить, сколько задач будет взято на одну рельсу на старте, а затем при достижении некоторого порога выполнения задач, реквесты будут повторяться с этим количеством. Значение по умолчанию - 256. Сменив значение на 1, можно заставить реактор использовать механизм "work stealing", при котором, рельсы и потоки, которые освободились, будут забирать задачи себе на выполнение и картина получится гораздо более приятная.

54 блокирующих задачи (каждая по 1сек кроме 2ух),? round-robin распределение по 6 рельсам
Prefetch !")
На этом у меня всё. Будет интересно прочесть Ваши замечания и комментарии, на 100% истину не претендую, но все результаты подкреплены практическими примерами, на Spring Boot + Project Reactor 3.4. Всем спасибо!






raamid
К картинке с реактором так и напрашивается подпись (извините не сдержался):
— Вот туда я лопатку уронил!