Андрей Гаврилов работает в компании EPAM software инженером и занимается data-инженерными задачами. Пишет на Python, работает с Big Data и изучает Data Science — потому что невозможно заниматься Big Data на Python, не касаясь при этом Data Science.
И однажды он захотел выяснить, насколько модуль Spark, связанный с machine learning — рабочий. Имеет ли смысл его применять, когда мы мигрируем какое-то решение — например, Scikit-learn — на Spark. На конференции Russian Python Week 2020 он рассказал о своем эксперименте, а сегодня — самая суть для вас.
Обозначим задачу: есть пайплайн, написанный с привычными для Data Scientist фреймворками типа Scikit-learn. Это нужно перенести в кластер Spark’а. Посмотрим, в чем тут может быть проблема.

Давайте посмотрим, как работает Spark Application. Когда мы сабмитим его в кластер, то появляется драйвер, который отвечает за основную логику изменений с данными. В этом контейнере работает наш Python’овский код, который делится на две части. Это сам код, который содержит Python’овскую логику (вызовы библиотек, преобразования, логирование и т.д.). И команды, которые отправлены в executor’ы Spark’а, чтобы они выкачивали, процессировали данные и т.д.
Проблема в том, что если какая-то библиотека (например, Scikit-learn или Keras) не знает, что она работает в кластере, и не подозревает, что работает распределенно, то она будет работать только на том драйвере, который выделен для Python’овского кода. То есть данные, которые были прочитаны Spark’ом на executor’е, она попробует закачать полностью на драйвер, и только на этой одной машине попытается обучить DS модель. Это выглядит как огромный bottleneck, и это довольно грустно.

Именно эту проблему я и захотел решить — объяснить модели, что она должна работать распределенно, брать данные с executor’ов и там же на executor’ах их процессить, а не тянуть все на драйвер. В Spark для этого даже есть специальный модуль, реализующий распределенно привычные нам алгоритмы машинного обучения. Это и позволит отправить вычисления с драйвера на executor’ы — туда, где в памяти лежат выкачанные данные.
Я провел небольшое исследование, чтобы посмотреть, сможем ли мы это сделать и насколько при этом просядет перформанс (как по времени выполнения так и по качеству результата). В PySpark ML уже имплементированы типовые сценарии использования. Я выбрал классификацию, чтобы реализовать ее двумя путями. Первый — с помощью Scikit-learn и всех привычных штук, а второй — с использованием Spark ML.

В качестве dataset взял Large Movie Review Dataset, где собраны отзывы о фильмах и классифицировал каждый отзыв по бинарности — позитивный или негативный. Базовый пайплайн выглядел так: есть текст, мы его токинизируем, выделяем стоп-слова, приводим в нормальную форму, накидываем TF-IDF и применяем NaiveBayes-классификатор.
Base Line
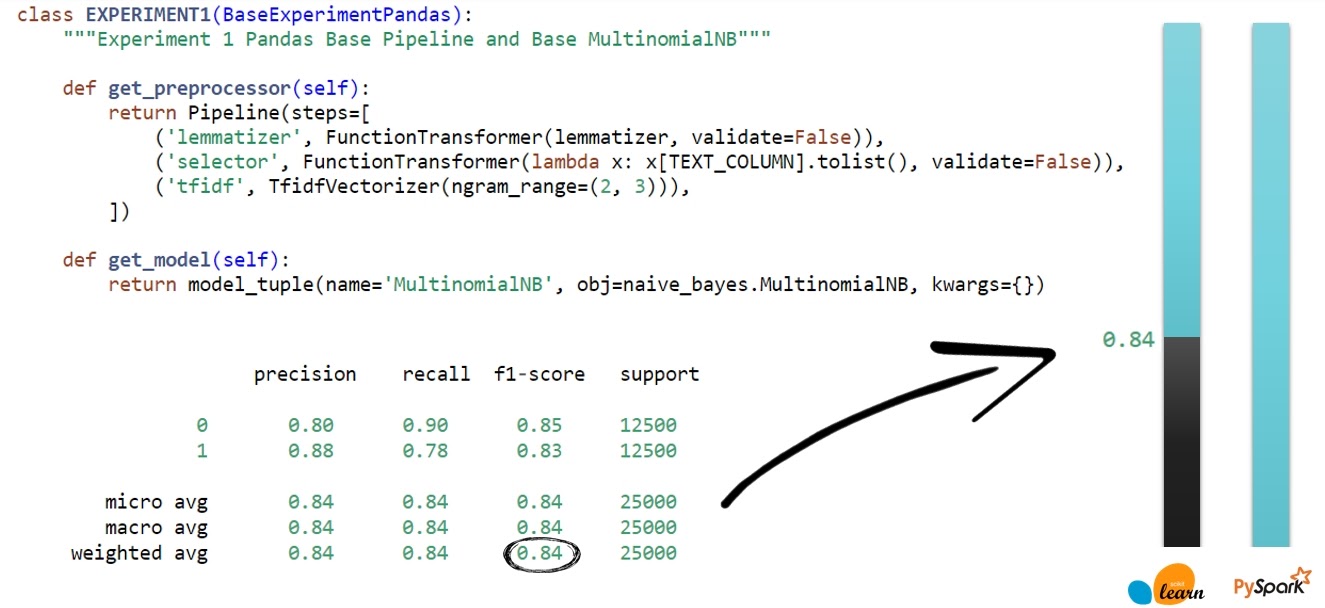
Сначала я сделал это с помощью Scikit-learn и создал небольшой пайплайн, где на шаге лемматизации у меня удаляются и стоп-слова. После чего подготовил к TF-IDF и сделал TF-IDF преобразование. Пока все самое базовое, гипер-параметры не тюнил. После применения NaiveBayes-классификатора в classification_report стало видно, что точность классификации f1-score — 84%.
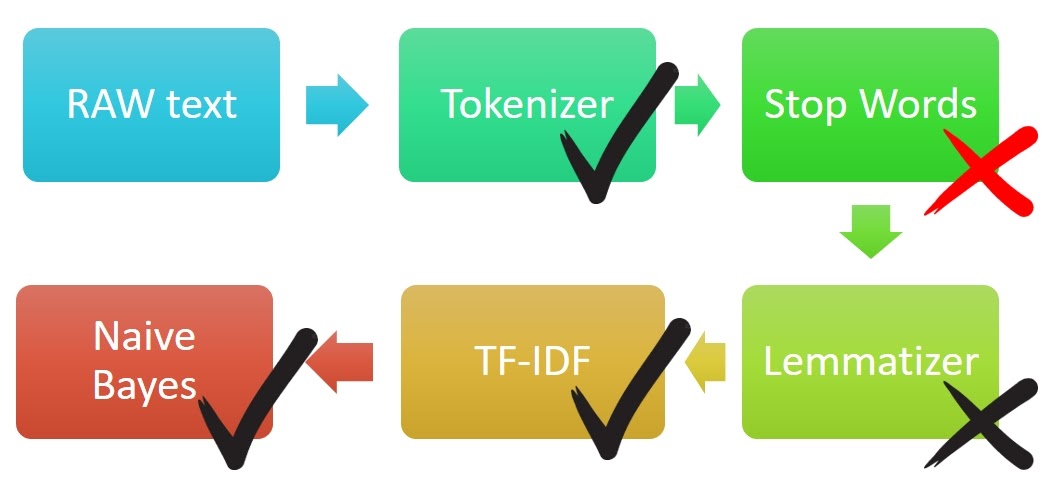
При миграции на Spark сначала пришлось проверить, есть ли в Spark ML все необходимые компоненты. Сможем ли мы заменить все части пайплайна на распределенные аналоги? Есть токинизатор – круто. Есть штука, которая удаляет стоп-слова — здорово, хотя потом я выясню, что работают они не очень хорошо. Так что пока я не буду их использовать. Нет лемматизации, но ОК, попробуем без нее. Есть TF-IDF, но он разбит на несколько компонентов, и вообще работает из коробки не так, как Scikit-learn, а с нюансами. И есть классификатор.
Итак, я добавил токинизатор, шаг с ngram (потому что в Base Line для Scikit-learn мы использовали ngram, а не чистый текст) и TF-IDF. Также я использовал именно BS классификатор, который тоже есть в PySpark ML. Смотрим, что получилось:

Качество 82% — это чуть хуже, чем у Scikit-learn, но для Base Line в принципе норм.
Оптимизация
Для оптимизации я потюнил гипер-параметры TF-IDF в имплементации Scikit-learn. Видим, что качество улучшилось до 86%.

Когда я пробовал другие классификаторы, выиграл SVM — качество классификации выросло до 89%. Если обратиться к решениям на Kaggle, то можно увидеть, что качество выше 90% достигалось серьезными нейронками, а не классическими методами. Так что мои 89% вполне приемлемо для рассматриваемого dataset.

Я вернулся к PySpark и проверил, как в его случае поведет себя SVM. Видно, что после замены модели получаем тоже прирост качества, хоть и не такой большой, как это было в предыдущем эксперименте.
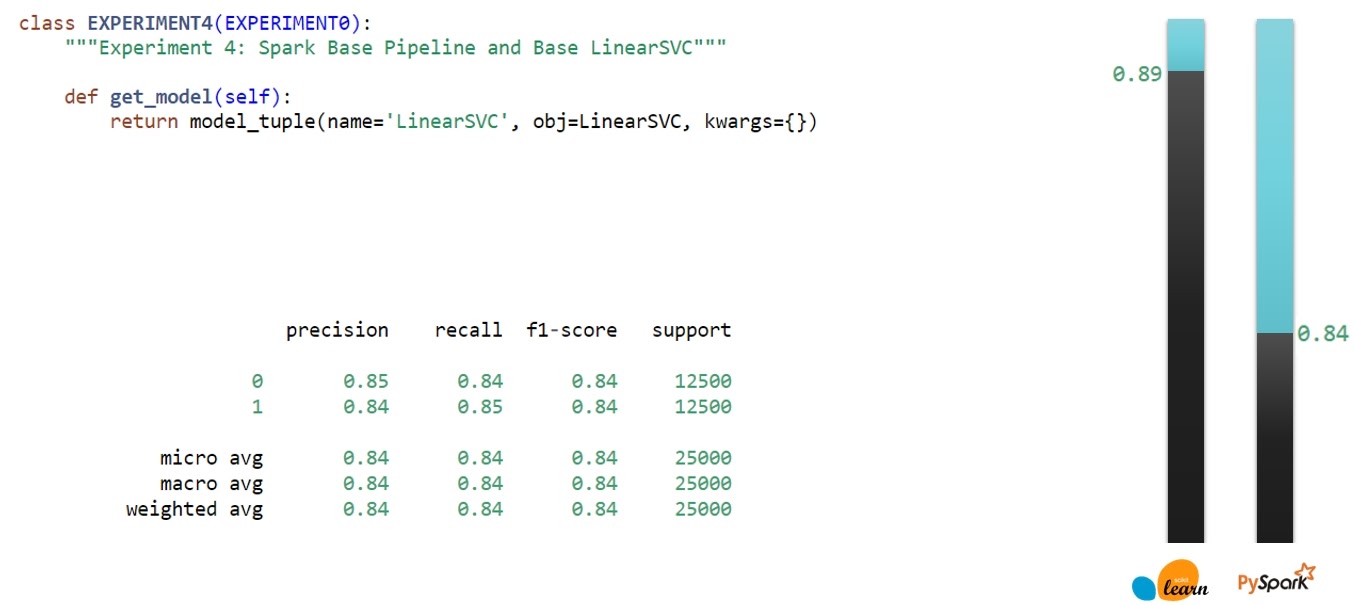
Но — у нас все еще не оптимальные гипер-параметры.
В Scikit-learn есть TF-IDF реализация, которая предлагает нам как параметр указать, сколько NGram будем использовать для формирования блока с текстом.
NGram — это комбинации слов. NGram уровня 2 будет словосочетанием из двух слов и т.д.
В процессе исследования я выяснил, что для данной задачи оптимальной будет комбинация просто слов и NGram второго порядка.
Но в Spark ML нет такого TF-IDF из коробки, чтобы использовать NGram в качестве опций. Зато есть инструмент, который позволяет посчитать NGram различных порядков для конкретного текстового dataset. Я посчитал каждый отдельно и сконкатенировал их. При сравнении победили те же Ngram 1 и 2 порядка. Качество классификации повысилось до 88%, а это всего на 1% меньше, чем у классификации Scikit-learn.

Далее. Я столкнулся с тем, что классификация в кластере работает 25 минут при нескольких секундах в случае sklearn — то есть надо думать, в чем проблема. В первую очередь я репартиционировал данные, которые мы читаем. Потому что из неразделенного формата мы будем читать весь dataset в одну партицию. И никогда в жизни не дождемся конца таких параллельных вычислений. оэтому я принудительно репартиционировал данные на 10 партиций, чтобы добиться параллельности.
Также для селекта только двух нужных мне колонок можно использовать умные форматы, например, parquet. Тогда информация о необходимых колонках будет прокинута оптимизатором Spark SQL на уровень parquet. Лишний трафик по сети не будет гоняться, следовательно, и чтение будет происходить быстрее.
Без кэша Spark будет часто перечитывать одни и те же dataset’ы. И, возможно, даже на каждой итерации модели. Поэтому нужно еще кэшировать данные на разных этапах — так мы можем их переиспользовать без повторного прочтения и вычисления необходимых трансформаций.

После таких нехитрых модификаций время выполнения с 25 минут уменьшилось до 1,5 минут.
Сравнительная таблица, как уменьшилось время препроцессинга и время выполнения модели с оптимизациями и без них:

Видно, что препроцессинг ускорился ненамного, а время работы модели уменьшилось на порядок. Это как раз связано со способами кэширования и грамотного использования Spark.
Стоп слова
Итак, у нас есть неплохая скорость и качество модели. Но что там со стоп словами? В Spark ML есть модуль посвященный удалению стоп слов: StopWordsRemover. При его использовании очень сильно проседает качество — и в случае NaiveBayes классификатора, и при использовании SVM.

Непонятно, почему это происходит, и это очень подозрительно. Возможно, Spark’овский StopWordsRemover удаляет слишком много слов, и среди них есть важные, поэтому качество модели падает. Либо здесь виноваты модели, которые просто хуже работают после того, как мы удалили много контекста.
Немного наблюдений
Далее я чуть более детально расскажу про некоторые странности, с которыми встретился.
TF-IDF в Spark
TF-IDF — это табличное представление текста в виде токенов. В качестве строк — документы, в качестве столбцов — уникальные слова, которые встречаются в этих документах, а на пересечении — некоторые взвешенные метрики.

Когда мы запускаем TF-IDF из Scikit-learn, то он строит такое представление буквально для всего корпуса текста. В качестве строк выступают все документы, которые ему были переданы (все строки в DataFrame), а количество столбцов определяется динамически количеством уникальных слов в анализируемом тексте.
В Spark’овском TF-IDF нужно заранее указать, сколько столбцов будет, и неважно, сколько в нем слов. Что вызывает вопросы. Почему именно столько? И если выбрать меньшее количество, то какие тогда документы (токены) попадут в итоговую репрезентацию? Это спорно и странно. Но все равно я проверил, как размерность влияет на качество итоговой классификации.
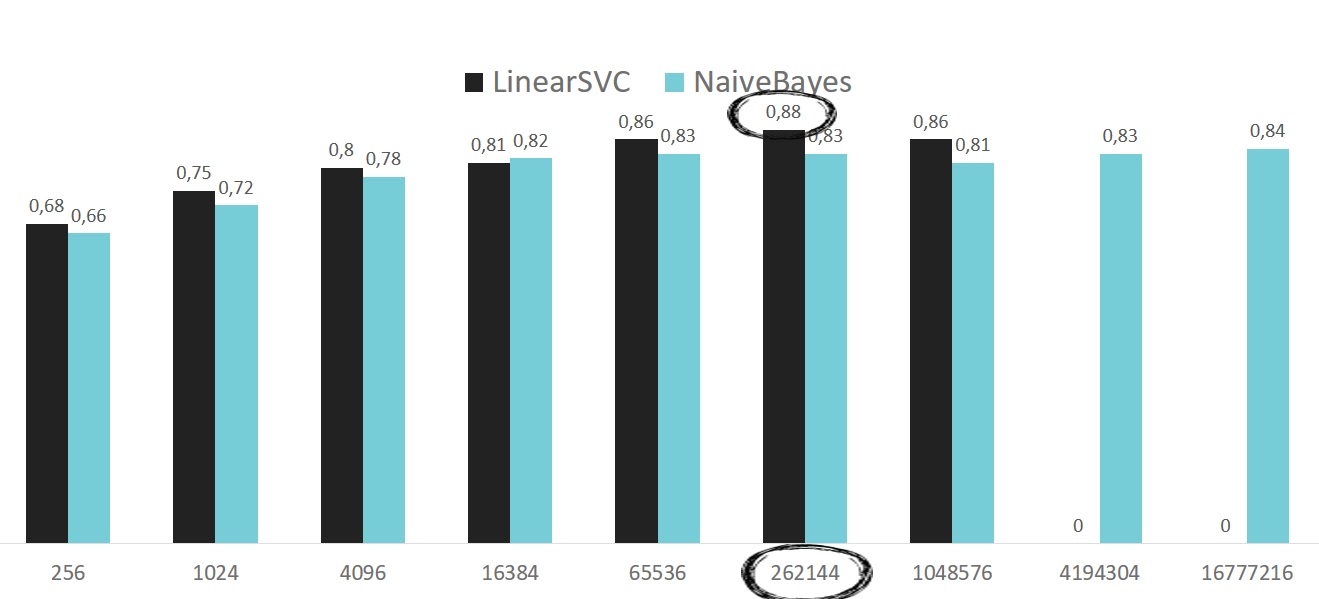
Видим, что лучший параметр для данного разложения — это 262 144. В случае SVM это одновременно и максимальное качество классификации классификатора, и дефолтное значение. Это видно в исходном коде этого алгоритма. Это странно, но я не смог найти объяснения, почему оно выбрано дефолтным — этого просто нет в документации. Но у меня оно получилось оптимальным.
Если запускать SVM локально при большом количестве фичей, он падает по памяти.

А если запускать на кластере, то он работает 9,5 часов, что неприемлемо для dataset, который анализируется за пару минут. Хотя эта проблема не новая. Алексей Зиновьев рассказывал про такие проблемы в Spark’овском SVM: что он реализован достаточно плохо и работает долго при большом количестве фичей.
NaiveBayes в Spark
NaiveBayes — не самый оптимальный классификатор для данной задачи, но в процессе я нашел необычную закономерность, связанную со сглаживанием. Дело в том, что если мы получаем на вход документ, в котором есть новые токены, не прошедшие обучение, то вероятность для них попасть в какой-либо документ, равна нулю. И тогда ломается вся структура — перемножение вероятностей, одна из которых нулевая, обнуляет все, и качество классификации сильно падает.

Идея сглаживания состоит в том, что мы часть вероятностей забираем из других компонент и передаем той, у которой вероятность 0. То есть забираем часть информации у важных компонент, отдавая ее неважным, но в маленьких дозах. Тогда мы не ломаем всю систему целиком.
Но проблема в том, что чем больше мы увеличиваем параметр, тем больше забираем полезной информации у полезных токенов и отдаем бесполезным. Мы зашумляем данные и качество классификации должно падать.
В случае Scikit-learn это подтвердилось. А вот со Spark’овским NaiveBayes классификатором все произошло ровно наоборот. Моя первая мысль была, что у них просто инвертирован параметр — передается его обратная величина (единица, разделенная на этот параметр сглаживания). Но если посмотреть в документацию, по всем формулам нужно передавать именно сам параметр. Его возрастание должно привести к тем же проблемам, что и в Scikit-learn, но нет.

Я долго анализировал, почему так происходит. Возможно, это связано как раз со стоп-словами — в моем эксперименте нет их удаления (в случае Spark). Из-за этого мусорные слова вылезли наверх и благодаря сглаживанию мы как раз отдали больше внимания важным словам? А не мусорным, то есть более важные компоненты смогли вырасти повыше и внести свой вклад — и качество классификации улучшилось.
Но это объяснение притянуто за уши. Поэтому такая модель не готова для использования в production — она работает не очень стабильно, и непонятно, как она себя поведет на новых данных.
Гибрид
Напоследок я решил заменить в Spark’овском пайплайне препроцессинг, завернув в UDF способ удаления стоп-слов и лемматизацию, сделав таким образом гибридный пайплайн. Он будет читать данные Spark’ом, препроцессить их привычными нам тулами из SkLearn, а все дальнейшие шаги (TF IDF и модель) будут снова из Spark’а.
Но и тут была загвостка — для удаления стоп-слов используется фреймворк NLTK, который выкачивает словари один раз — перед тем, как начать работать. Когда мы работаем на одной машине (Jupyter-ноутбуке или локально), проблем никаких нет. Но когда мы начинаем работать на кластере, ито мы хотим использовать NLTK на executor’ах, а не на драйвере, чтобы не тянуть все данные на него, начинаются проблемы.
В этом случает NLTK должен запуститься на executor’ах. Однако на executor’е он, разумеется, не выкачал свои словари. Код написан таким образом, что если NLTK видит, что словари не выкачаны, то пытается их скачать. Но на executor’ах у процесса недостаточно прав для того, чтобы закачать словарь в то место, где выполняется код.
Наверное, есть разумные способы решения этой проблемы. В NLTK можно указать путь, куда можно скачивать, и, наверное, в executor’е есть папка, на которую у нас есть права. Но когда я с этой проблемой столкнулся, была ночь, и я ничего умнее не придумал, чем просто пройтись по executor’ам и вручную закачать нужный словарь. Это сработало.
Теперь можно сравнить качество работы NaiveBayes-классификатора в случае чисто Spark’овского пайплайна, Scikit-learn пайплайна и гибридного, который должен по идее некоторые проблемы Spark’овского решить.

К нашему удивлению гибридный пайплайн повел себя как Spark’овский. Его качество растет с увеличением параметра сглаживания. Значит, дело не в удалении стоп-слов и не в нормализации, а скорее всего — в TF-IDF трансформации. Непонятно, какие слова TF-IDF использует и какие слова в итоге фигурируют в качестве фичей, почему оно ограничено. Даже правильное удаление стоп-слов и приведение их к нормальной форме все равно не позволяет построить такое TF-IDF представление, которое бы устроила нас в рамках текущей задачи.
Итог
Это те исследования, которые я хотел показать. Контрибьютить Spark ML достаточно больно. Spark MLlib использовать не стоит, потому что он медленный, практически вообще не работает. А со Spark ML в принципе можно поиграть, он в каком-то виде работает, но насколько стабильно — делайте выводы сами.
На рынке решений очень много и каждое имеет право на существование. Их просто нужно пробовать. Я рассказал про один такой тест, а на самом деле у нас сейчас в production работают много решений, которые мы сначала проверяли подобным образом. Общего решения из коробки — нет. А мой эксперимент, возможно, кому-то сэкономит время и из этой цепочки проб и ошибок вы исключите Spark ML.
Профессиональная конференция для Python-разработчиков пройдет 27 и 28 сентября в Москве. Про AI/ML и визуализацию данных будет 5 докладов. Вы сможете узнать про навыки в сфере и о документировании. Услышать о JupyterHub и автоматизации процесса. Получить опыт в работе с Data Science и МЛ-сервисами под нагрузкой. Билеты здесь. Все доклады — тут.