Довольно давно я хотел сделать свою вытесняющую ОС для микроконтроллера, но не нашел стоящего мануала, или плохо искал, хз. В результате разобрался что к чему, что для этого нужно и решил написать пост об этом, вдруг кому-то пригодится.
Короче говоря, надеюсь это будет полезно, или хотя бы интересно, для людей, ищущих ответы на вопросы на форумах и статьях на Pikabu Хабре, а не в патентах, документации и прочих унылых источниках, где нет вставок с мемами.

Статья ориентирована на людей, уже знакомых с тем, что такое вытесняющая ОС, хотя бы шапочно, поэтому здесь будет описан принцип работы ее составных частей так, чтобы читатель, на основе этой информации, уже смог сделать свою ОС. Простенькую, но свою!)
Итак… Мне очень давно стало интересно, насколько это сложно, круто ли, с какими проблемами придется столкнуться в процессе и какие задачи придется решить.
Вот и решил, пару месяцев назад, сделать свою ОС.
У меня нет цели сделать ОС, дать ей пафосное имя и выложить ее потом, как делают крутые пацаны. Я ее выложу, когда доделаю. А может и нет. А может и не доделаю... Меня скорее интересует - разобраться, как сделать, нежели сделать.
Первой целью была вытесняющая многозадачность, или просто переключение контекста, если хотите. Когда оказалось, что это элементарно, т.к. сделал я это, наверное, за вечер, сразу пошел дальше, добавив типичные сервисы Sleep и семафоры.
Ну а когда оно уже работало, начались проблемы – оказывается, когда ты не делал такого ни разу и не являешься завсегдатым пользователем разных вытесняющих ОС, возникает просто миллион идей как можно реализовать ту или иную фичу, и как оно должно работать, да и вообще, какие фичи еще нужны, а какие нет.
Да, я решил заняться этим, не попользовавшись ничем подобным. Из ОС использовал только кооперативную OSA на PIC24F. Да это очень профессиональный подход. Как говорится – профессионала видно из далека. Спасибо
Хотя..., я же пользуюсь Windows? Да! Она же вытесняющая? Тоже да! К тому же, я очень опытный пользователь! Наверное зря наговариваю на себя...
Определение ОС

Это не учебник по операционным системам, я не даю здесь определение этого термина как однозначно правильное, просто укажу свое определение, чтобы было понятно, от чего я отталкивался и какие задачи хотел решить.
На правах опытного пользователя Google (или Senior Google User, если хотите) – именую результат этой статьи «Embedded Operating System».
Если я не прав – можем позже похоливарить!)
Итак, скажем, что у нас это «Embedded OS», а дальше будем называть просто «ОС» или «операционная система».
Мое определение
Embedded OS – это программная прослойка, позволяющая реализовать псевдо многопоточность, на однопроцессорной системе. То есть – обычном микроконтроллере (да, даже на ардуино, уже предвкушаю этот вопрос :D).
Принцип работы ОС
Исходя из определения – основная задача, которую должна решать наша ОС, это реализация искусственной многопоточности на однопоточном процессоре.
Опустим инициализацию, тогда, в ходе работы, алгоритм искусственной многопоточности будет выглядеть так:
Выполняется задача «1»;
Квант времени задачи заканчивается, и возникает прерывание таймера ОС;
Вызывается ядро ОС;
Сохраняется контекст текущей задачи в стек этой задачи;
Планировщик выбирает следующую задачу;
Контекст следующей задачи восстанавливается из стека новой задачи;
Происходит прыжок в то место задачи «2», на котором она была прервана в последний раз;
Выполняется задача «2»;
Квант времени задачи … ну вы поняли … и … «here we go again».
Переключение потоков изображено на рисунке, который я беспощадно позаимствовал из другой статьи на подобную тему. Прошу меня sorry, не ругайте, но мне лень это просто перерисовывать.
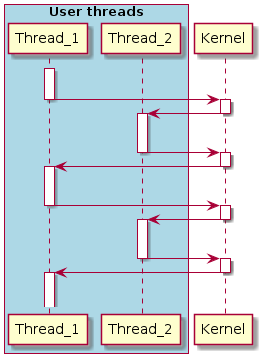
И вот в этом алгоритме уже фигурируют некоторые фичи, которые нужно понять и простить реализовать. Итого нам нужно:
Понять, что такое «Задача»;
Понять, что такое «Квант времени задачи»;
Понять, что такое «Контекст задачи»;
Понять, что такое «Переключение контекста»;
Понять, что такое «Стек задачи»;
Понять, что такое «Планировщик»;
Понять, что такое «Ядро»;
Убедиться, что все точно понятно;
Реализовать все эти приблуды!
Понять, что все было понятно не точно;Переделать все заново.
Термины и определения
Задача
Это просто Си-функция, содержащая бесконечный цикл.
Весь рантайм будет состоять из нескольких таких задач, в которых и будет выполняться код пользователя.
Пример задачи:
void Task1(void)
{
for(;;)
{
/* some important actions */
}
}
Квант времени задачи
Это отрезок времени, который задача гарантированно получает в свое распоряжение на выполнение своих действий, не боясь быть прерванной другими задачами или самой ОС.
Например, если квант времени возьмем как 1мс, тогда временная диаграмма работы ОС будет выглядеть как на рисунке ниже. Условимся, что время выполнения кода ядра, для переключения контекста занимает 50мкс.
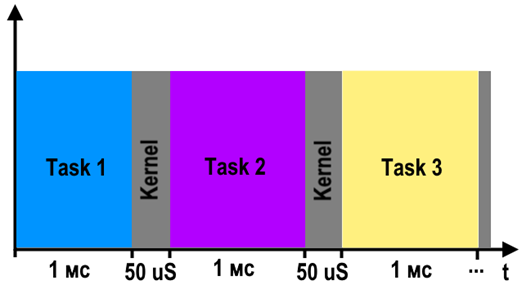
Получается, что это можно использовать в своих целях, например, если нужно выполнить код, который выполняется быстрее, чем квант времени – то можно не париться по поводу синхронизации потоков и успеть выполнить его и так, но это другой вопрос. Мы не должны уйти в лес от основной темы, держу себя в руках!
Алгоритм работы выглядит примерно так:
Настраивается прерывание таймера на 1мс;
Запускается ОС;
Задача 1 работает;
Таймер делает «тик-так» много раз;
Срабатывает прерывание таймера;
ОС переключает контекст на задачу 2 и сбрасывает таймер;
Задача 2 работает;
Таймер делает «тик-так» много раз;
Срабатывает прерывание таймера;
ОС переключает контекст на задачу 2 и сбрасывает таймер;
Aaaand … here we go again …
Уточнение: ОС гарантирует, что если задача получила управление, то ни одна другая задача ей помешать не может, пока квант времени не закончился. Но сама задача может свой квант времени завершить преждевременно, что есть нормальной практикой, и для этого используются сервисы для синхронизации потоков, Sleep, семафоры и т.п. Об этом далее.
Контекст задачи
Здесь все чуть сложнее, если вы не имеете опыта с ассемблером.
Любой процессор выполняет все действия при помощи регистров общего назначения (РОН (нет, это не "пох")). Если вы пишете только на Си, то не совсем понятна разница между глобальными и локальными переменными, и в них тут как раз таки все дело.
Глобальные переменные хранятся в ОЗУ. Это когда вы объявляете переменную вне функций, или в функциях с модификатором «static».
А локальные?
Ну а их как бы и не существует вовсе. Они как бы есть. Но и в то же время – их нет.
Но должны же они где-то храниться?
А вот они, как раз, и хранятся в регистрах общего назначения, но хранятся там только в конкретные моменты.
На самом деле, то, что вы пишете на Си – нужно только для понимания кода, на самом деле в ассемблере все выглядит сильно по-другому.
Например, на Си, функция выглядит так:
uint8_t d;
void Function(void)
{
uint8_t a;
uint8_t b;
uint8_t c;
c = a + b;
PORTB = c;
d = c – a;
}
Объявление переменных a, b и c, на самом деле, вообще не содержат действий, и не скрывают за собой ассемблерных инструкций.
И вот только в строке «c = a + b» начинают работать регистры общего назначения.
А вот переменная «d» – уже хранится в ОЗУ, и поэтому существует всегда.
Как это работает без использования ОС: функция использует РОН для выполнения своего кода, и она уверена, что все РОН принадлежат ей, и она точно сделает все действия и никто ей не сможет помешать!

Ну…, есть еще прерывания. Обработчик прерывания – это такая же функция, которая может тоже вызвать функцию и так далее. И как они используют одни и те же регистры? Если, по сути, могут прервать любую функцию в любой момент, и данные в регистрах будут повреждены.
А все просто.
Во-первых, есть стандарт, описывающий, какие регистры для каких целей и как используются компилятором, например вот: здесь.

Во-вторых, из «во-первых» получаем, что каждая функция, кроме прерываний, может свободно использовать регистры R18-R27, R30, R31, не думая о том, что эти регистры нужны еще кому-то, а вот регистры R2-17, R28, R29 должна в начале работы сохранить, а после работы – вернуть на место.
Вот для этого, компилятор втихаря вначале каждой функции и прерывания вставляет код вида:
push R15
push R16
push R17И в конце функции, перед выходом:
pop R17
pop R16
pop R15Сохраняя регистры в стек, перед началом своей работы, и восстанавливая их обратно, в конце работы, чтобы вернуть все как было.
push/pop – это ассемблерные инструкции для работы со стеком.
Итак...
Получается, что если мы хотим, чтобы задача могла быть «вытеснена» другой задачей, и программа не пошла по пиз сломалась, то, в момент переключения, ОС должна сохранить значения регистров для текущей задачи и перед переключением на следующую задачу – должна восстановить значения регистров в то состояние, в котором они были в последний момент работы следующей задачи.
Это и есть контекст задачи – регистры общего назначения, или, грубо говоря – локальные переменные функции, с точки зрения Си.
Сохраняется контекст в стек соответствующей задачи.
Уточненьице...
Для AVR нужно еще сохранить регистр «SREG», который также каждый раз сохраняется компилятором при входе в каждое прерывание, это уже особенности каждой архитектуры процессоров, пока что это не важно.
Переключение контекста
Это действие, при котором сохраняется контекст последней выполняющейся задачи, выбирается следующая задача, и восстанавливается контекст этой выбранной задачи.
Получается, что код, а точнее псевдокод, для переключения контекста будет выглядеть так:
void ChangeContext(void)
{
SaveRegsIntoStack();
SelectNextTask();
RestoreRegsFromStack();
return;
}SaveRegsIntoStack – это макрос, содержащий ассемблерный код для сохранения всех регистров в стек.
RestoreRegsFromStack – это макрос, содержащий ассемблерный код для выгрузки всех регистров из стека.
В итоге, если расшифровать эти макросы, все будет выглядеть так:
void ChangeContext(void)
{
push R0
push R1
… R2 … R30 …
push R31
push SREG
currentTask = GetNextTask();
pop SREG
pop R31
… R30 … R2 …
pop R1
pop R0
return;
}Стек задачи
Стек – это тип памяти, или способ хранения данных, который используется, в основном, для сохранения адресов возврата при вызове функций и возникновении прерываний.
Также стек, как уже упоминалось чуть выше, используется функциями и прерываниями для временного сохранения регистров общего назначения и их восстановления перед выходом.
Основная проблема использования вытесняющих ОС на «слабых» контроллерах как раз заключается в том, что каждая задача должна иметь свой стек, и даже только для регистров общего назначения он требует немало места, не говоря уже о вызовах функций из задач.
Например, у AVR – всего 32 регистра общего назначения, это значит, что если у вас 4 задачи, то вам необходимо отдать на это (32 * 4) = 128 байт. Учитывая, что, например, в ATmega88 всего 1Кб ОЗУ – это таки потеря потерь.
Вывод: создавать отдельную задачу на каждый светодиод – явно неразумно :D
Получается, что стек – это просто буфер байт, для каждой задачи свой, и каждая задача должна знать границы этого буфера и указатель на текущий байт внутри.
Сам по себе, процессор содержит аппаратный указатель стека, который, в начале работы, сразу после сброса процессора, указывает на конец таблицы ОЗУ и в ходе вызова функций туда сохраняются адреса, а в момент выхода из функций обратно выгружаются.
Без использования вытесняющей ОС, ОЗУ микроконтроллера будет выглядеть так:
Address |
Data |
||
0 |
0x00 |
||
1 |
0x00 |
||
2 |
0x00 |
||
3 |
0x00 |
||
4 |
0x00 |
||
5 |
0x00 |
||
6 |
0x00 |
||
7 |
0x00 |
||
8 |
0x00 |
||
9 |
0x00 |
||
10 |
0x00 |
||
11 |
0x00 |
||
12 |
0x00 |
||
13 |
0x00 |
||
14 |
0x00 |
||
RAMEND -> |
15 |
0x00 |
<-Stack pointer |
С использованием ОС, уже будет выглядеть так:
Address |
Data |
||
0 |
0x00 |
Common |
|
1 |
0x00 |
||
2 |
0x00 |
||
3 |
0x00 |
||
4 |
0x00 |
||
5 |
0x00 |
||
6 |
0x00 |
||
7 |
0x00 |
||
8 |
0x00 |
||
9 |
0x00 |
||
10 |
0x00 |
||
11 |
0x00 |
||
12 |
0x00 |
||
13 |
0x00 |
||
14 |
0x00 |
||
15 |
0x00 |
Task 3 |
|
16 |
0x00 |
||
17 |
0x00 |
||
18 |
0x00 |
||
19 |
0x00 |
||
20 |
0x00 |
||
21 |
0x00 |
||
22 |
0x00 |
<-Stack pointer |
|
23 |
0x00 |
Task 2 |
|
24 |
0x00 |
||
25 |
0x00 |
||
26 |
0x00 |
||
27 |
0x00 |
||
28 |
0x00 |
||
29 |
0x00 |
||
30 |
0x00 |
<-Stack pointer |
|
31 |
0x00 |
Task 1 |
|
32 |
0x00 |
||
33 |
0x00 |
||
34 |
0x00 |
||
35 |
0x00 |
||
36 |
0x00 |
||
37 |
0x00 |
||
38 |
0x00 |
<-Stack pointer |
|
39 |
0x00 |
||
40 |
0x00 |
||
41 |
0x00 |
||
42 |
0x00 |
||
43 |
0x00 |
||
44 |
0x00 |
||
RAMEND -> |
45 |
0x00 |
<-Hardware SP |
Получается, стек задачи можно описать структурой вида:
typedef struct {
uint8_t *buf; // Указатель на буфер
uint8_t *ptr; // Указатель на текущий байт в буфере
} Stack_tПри переключении контекста, аппаратный указатель на стек должен перемещаться на буфер стека задачи.
После сохранения регистров в стек, мы просто должны сохранить значение аппаратного стека в структуру задачи, а после выбора следующей, перед восстановлением регистров из стека, должны присвоить аппаратному указателю значение, сохраненное при предыдущей смене контекста.
Тогда код для переключения контекста уже будет иметь вид:
void ChangeContext(void)
{
/* Сохраняем контекст задачи */
push R0
push R1
… R2 … R30 …
push R31
push SREG
/* Сохраняем текущее состояние аппаратного указателя на стек */
currentTask->stack.ptr = HARDWARE_STACK_POINTER;
/* Выбираем следующую задачу */
currentTask = GetNextTask();
/* Перемещаем аппаратный указатель стека на буфер стека следующей задачи */
HARDWARE_STACK_POINTER = currentTask->stack.ptr;
/* Восстанавливаем контекст задачи */
pop SREG
pop R31
… R30 … R2 …
pop R1
pop R0
return;
}Это практически готовый код для переключения контекста.
Стек ядра и стек прерывания
Стоит еще уточнить, что в идеале ядро и прерывания тоже должны иметь свой стек.
Об этом написано, опять же, в статье, на которую я уже давал ссылку: тут.

Стек ядра
Стек ядра у нас будет. В коде ядра могут вызываться функции, планировщика, например, адреса возвратов не должны попадать в стек задач, т.к. это неэстетично, и при создании задачи, пользователь не должен думать «сколько же еще байт нужно докинуть, чтобы все работало».
Этот стек будет содержать только адреса возврата, выделять место для регистров общего назначения нам не нужно, а значит, в нем должно быть место только для адресов возврата. Если ядро имеет цепочку вложенных вызовов из трех функций, то это 3 адреса, если мы говорим об AVR, то это 6 байт. Вообще фигня…
Как это выглядит в коде – представлено ниже. Уже знакомая функция изменения контекста:
void ChangeContext(void)
{
/* Сохраняем контекст задачи */
push R0
push R1
… R2 … R30 …
push R31
push SREG
/* Сохраняем текущее состояние аппаратного указателя на стек */
currentTask->stack.ptr = HARDWARE_STACK_POINTER;
/* Перемещаем аппаратный указатель стека на буфер стека ядра */
HARDWARE_STACK_POINTER = kernelStack.ptr;
/* Выбираем следующую задачу */
currentTask = GetNextTask();
/* Сохраняем аппаратный указатель стека */
/* На самом деле это не обязательно, т.к. мы вернулись из функции, */
/* и указатель вернулся в исходное состояние до вызова функции. */
/* Но это для понимания и предсказуемости кода */
kernelStack.ptr = HARDWARE_STACK_POINTER;
/* Перемещаем аппаратный указатель стека на буфер стека следующей задачи */
HARDWARE_STACK_POINTER = currentTask->stack.ptr;
/* Восстанавливаем контекст задачи */
pop SREG
pop R31
… R30 … R2 …
pop R1
pop R0
return;
}Стек прерываний
Стека прерывания у нас не будет. Почему? Я уже почти дописал статью, и вспомнил, что я его не сделал, да, там всего пара макросов, но я не хочу быстро их добавлять, не протестировав нормально, и прикрепить этот проект к статье. Это как-то неправильно. Пусть, лучше, его не будет. Но я его опишу. Это уже что-то
В дальнейшем, может быть, вернусь к этой статье и исправлю этот недостаток, когда и ОС допилю.
Для прерываний можно без зазрения совести использовать тот же буфер стека, что и для ядра, т.к. они оба используются в прерываниях, и кто первый встал – того и стек!
Если мы добавим стек прерываний, то пользователь ОС просто должен в каждое свое прерывание добавить строку для перемещения стека в начало обработчика прерывания и для восстановления в конце.
Тогда любое прерывание будет выглядеть как-то так:
ISR(SOME_IMPORTANT_INTERRUPT)
{
/* Здесь могут быть скрытые PUSH, которые добавит компилятор */
/* Сохраняем значение аппаратного указателя стека текущей задачи */
currentTask->stack.ptr = HARDWARE_STACK_POINTER;
/* Перемещаем аппаратный указатель стека на буфер стека ядра/прерывания */
HARDWARE_STACK_POINTER = kernelStack.ptr;
/* Что-то делаем, пользовательский код */
/* …………………… */
/* …………………… */
/* Восстанавливаем аппаратный указатель стека на буфер стека текущей задачи */
HARDWARE_STACK_POINTER = currentTask->stack.ptr;
/* Здесь могут быть скрытые POP, которые добавит компилятор */
return;
}Понятно, что это должно быть скрыто в макросы, но пока что для наглядности и для понимания принципа, как это должно работать.
Планировщик
Это отдельная история, которая будет реализована примитивно, т.к. это отдельная тема, но суть планировщика не меняется – это просто Си функция, которая должна вернуть нам указатель на следующую задачу.
В нашей ОС не будет алгоритмов планирования, планировщик будет примитивным.
А сделаем мы это не из-за лени, как вы могли подумать, а исключительно ради благородных целей. А именно, чтобы планировщик выполнял то, ради чего он вообще нужен, мы же не изверги, чтобы создавать что-либо, и не давать ему правильно выполнять свои обязанности…
Я работал однокристальщиком в одной небольшой фирме, где меня заставляли поддерживать 1С, так что я знаю, что он чувствует, когда занимается не тем, для чего был рожден
Это я не таю злобу на 1С, я просто не был рожден чтобы работать XD
Планировщик должен выполнять две функции:
Определить, какая задача будет выполняться следующей;
Минимизировать простой процессора.
Т.к. мы не забываем, что делаем ОС на AVR, то лучшей оптимизацией для минимизации простоя процессора является – отказ от сложных алгоритмов планирования. Тем более, что объем ОЗУ так и говорит, что несколько задач – это прям максимум!
А тупой перебор массива из 2, 4 или даже 10 (десять задач, карл) элементов – это гораздо быстрее, чем какой-то, даже самый примитивный алгоритм планирования.
Я не буду заливать про односвязный список, чтобы не перегружать, т.к. это просто оптимизация планировщика. А оптимизация – это не про сейчас, это «future simple»
Код планировщика я тупо скопировал реальный, который у меня был на данным момент. На самом у меня было много вариантов, и с одно- и с двусвязным списком, но пока что решил вернуться на изначальный, т.к. для меня он проще на этапе отладки и более предсказуемый.
Реальный код здесь вставлять я не хотел, т.к. псевдокод понятнее. Но не смог написать "рабочий" псевдокод и забил, скинув настоящий)
static Task_t *GetNextTask (void)
{
static uint8_t currentTaskIndex = 0;
bool taskAvailable;
uint8_t i;
if(Kernel_currentTask->status == TASK_STATUS_RUN)
{
Kernel_currentTask->status = TASK_STATUS_READY;
}
i = CONFIG_USER_TASKS_NUMBER;
while(i--)
{
Kernel_currentTask = &Kernel_tasksList[currentTaskIndex];
taskAvailable = false;
if(Kernel_currentTask->status == TASK_STATUS_READY)
{
taskAvailable = true;
}
currentTaskIndex++;
if(currentTaskIndex >= CONFIG_USER_TASKS_NUMBER)
{
currentTaskIndex = 0;
}
if(taskAvailable)
{
break;
}
}
if(!taskAvailable)
{
Kernel_currentTask = &taskIdle;
}
Kernel_currentTask->status = TASK_STATUS_RUN;
return Kernel_currentTask;
}Ядро
Ядро ОС – это часть ОС, которая и занимается переключением контекста.
Казалось бы, важнейшая часть ОС, че так мало написал?! А? А? А? А?
Ну а я отвечу – ядро содержит фичи, которые мы уже рассмотрели чуть выше.
Вот, как бы и все…
Инициализация и запуск
Вот тут сейчас и будут основные прЕколы, которые не давали мне спать спокойно.
В ходе работы получается классный конечный автомат. Аппаратный стек работает сам по себе. Он же на то и «аппаратный». Задачи переключаются.
А вот, как оказалось, запустить этот «конечный автомат» – та еще дилемма.
На самом деле идей было полно. Все они разные. Но каждая из них имеет заметный такой недостаток. Я, до сих пор, и не знаю какой вариант действительно самый крутой. Сейчас выбрал последний, т.к. он наиболее оптимальный по объему кода и быстродействию.
Дилемма
Вот есть у нас, например, три задачи.
У каждой уже есть свой стек, каждая – как на подбор, хоть «косынку» запускай!
Но, ядро ОС вызывается в прерывании. А как работает вызов функций и прерываний? Правильно, при вызове функции в стек сохраняется адрес последней инструкции плюс единичка.
И вот произошло первое прерывание, мы попали в обработчик прерывания:
Из него мы вызываем обработчик ядра ОС «Kernel()»;
Сохраняем регистры в стек;
Выбираем следующую задачу;
Указатель стека перемещаем на буфер стека задачи;
И возвращаемся из функции «Kernel()».
А куда возвращаемся?
Адрес возврата в прерывание находится не в стеке этой задачи, т.к. аппаратный указатель стека (Hardware SP) и карта ОЗУ после первого прерывания будет выглядеть так:
Address |
Data |
||
0 |
0x00 |
Common |
|
1 |
0x00 |
||
2 |
0x00 |
||
3 |
0x00 |
||
4 |
0x00 |
||
5 |
0x00 |
||
6 |
0x00 |
||
7 |
0x00 |
||
8 |
0x00 |
||
9 |
0x00 |
||
10 |
0x00 |
||
11 |
0x00 |
||
12 |
0x00 |
||
13 |
0x00 |
||
14 |
0x00 |
||
15 |
0x00 |
Task 3 |
|
16 |
0x00 |
||
17 |
0x00 |
||
18 |
0x00 |
||
19 |
0x00 |
||
20 |
0x00 |
||
21 |
0x00 |
||
22 |
0x00 |
<-Stack pointer |
|
23 |
0x00 |
Task 2 |
|
24 |
0x00 |
||
25 |
0x00 |
||
26 |
0x00 |
||
27 |
0x00 |
||
28 |
0x00 |
||
29 |
0x00 |
||
30 |
0x00 |
<-Stack pointer |
|
31 |
0x00 |
Task 1 |
|
32 |
0x00 |
||
33 |
0x00 |
||
34 |
0x00 |
||
35 |
0x00 |
||
36 |
0x00 |
||
37 |
0x00 |
||
38 |
0x00 |
<-Stack pointer |
|
39 |
0x00 |
||
40 |
0x00 |
||
41 |
0x00 |
<-Hardware SP |
|
42 |
0xCC |
||
43 |
0xDD |
||
44 |
0xAA |
||
RAMEND -> |
45 |
0xBB |
0xCCDD – адрес возврата в прерывание;
0xAABB – адрес возврата в main() из прерывания.
Видно, что адреса возврата попали в исходный стек, который не имеет отношения ни к одной из задач. Если мы теперь переключили указатель стека на буфер стека задачи при смене контекста, то после выхода из функции «Kernel()» мы не вернемся в обработчик прерывания, и из него потом не вернемся в задачу, т.к, если сейчас выбрана «Задача 1», то указатель стека будет указывать на ячейку «38», а там явно нет адреса возврата, там либо мусор, либо нули.
Очевидно, что в стек каждой задачи необходимо вручную подставить:
Адрес возврата в тело функции соответствующей задачи (это просто адрес функции);
Адрес возврата в обработчик прерывания.
Первое нужно обязательно, т.к. в ходе работы туда потом попадет адрес возврата не в начало функции, а в определенное ее место, где задача была приостановлена. И этот адрес будет подставлен на тапе создания задачи, т.к. мы его уже знаем, это адрес функции тела задачи.
А вот второе – далее посмотрим… В этом и проблема!
Решение 1
Первое, что я придумал и реализовал было так.
В «ChangeContext()» есть флаг «static bool firstEntry = true;», который указывает на то, что это первый вход в функцию «ChangeContext()» после сброса процессора.
Если это первый вход – значит мы берем из ОЗУ, по указателю на стек, адрес возврата в прерывание, и можем его подставить в стек каждой задачи.
Этот флаг потом сбрасываем в «false».
И при повторных входах этот код не выполняется.
Получается, что все задачи получают в свой стек адрес возврата, если это первое прерывание ОС.
Все работает, но здесь мы имеем код, который нужен только один раз за время жизни всей программы, а выполняем мы его в самой требовательной по быстродействию секции, в самом ядре, и выполняем каждый раз. Конечно, проверка одного флага – это несколько тактов, но все же – это не круто!
Мы же крутые? Конечно крутые!
Идем дальше!
Решение 2
Адреса обработчиков всех прерываний хранятся в памяти программы, а именно в самом ее начале, начиная с нулевого адреса.
Как получить адреса обработчиков прерываний из памяти программы
Итак, как получить адрес обработчика прерывания из памяти программы.
Открыв HEX файл, ну или проект в режиме отладки, находим, что в памяти программы есть такие буквы:
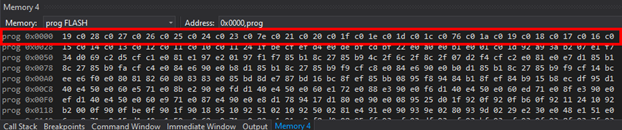
Красным выделены вектора прерываний. Далее я привожу кривой, но все же наглядный рисунок, совмещенный с даташитом.

И оно же, в увеличенном виде, красным выделил нужные нам данные, для нужного вектора прерывания. Мне нужно было прерывание «TIMER0 COMPA».
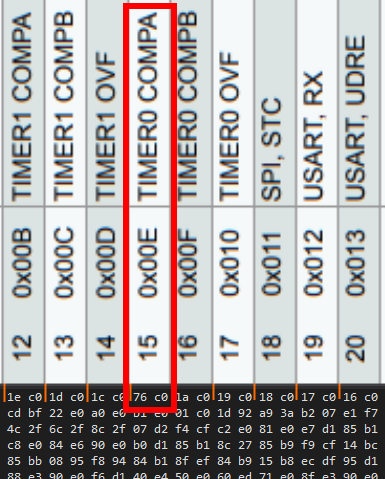
Видим данные «0x76C0». Т.к. это Big-endian, на самом деле там «0xC076».
Шо такое 0xC076?
А вот вспомнив, что вначале всех программ на ASM (когда писал на ASM, да, я крутой) я писал:
RJMP 0x0000 ; Reset
RJMP 0x0001 ; INT0
RJMP 0x0002 ; INT1
...Понимаем, шо это такое есть на самом деле! Точнее, я надеюсь, что я понимаю…
В даташите «AVR Assembler Instruction Set Manual» находим инструкцию RJMP, и видим ее формат:

Где 0b1100 => 0xC
И подтверждаем, что «0xC0» вначале – это инструкция RJMP, отбросив которую получим относительный адрес обработчика прерывания.
Далее получаем фактический адрес в памяти:
Где «15» – это порядковый номер нашего прерывания в таблице векторов прерываний.
В отладке у меня действительно, обработчик прерывания располагался по адресу 0x85.
То есть, в момент инициализации мы можем прочитать адрес оттуда, и во время инициализации каждой задачи сразу подставлять этот адрес в стек этой задачи.
Процессорное время в ядре мы не теряем, т.к. это выполняется только один раз на этапе инициализации.
Уже круто!
Но только это строки кода, которые содержат код для конкретной архитектуры, и конкретно под этот микроконтроллер. И берет адрес конкретного прерывания. А если нам нужен будет Timer2 вместо Timer0? Та вы шо? Это нам шо, городить дефайны, в которых потом можно ногу сломать? И так для каждого микроконтроллера и для каждого прерывания?
Так ну не, это, конечно круто! Но это перебор крутости!
Решение 3
Я держал это решение в голове с самого начала, но принимать его на вооружение ну капец как не хотел.
Оно избавляет нас от недостатков как первого, так и второго способов.
Но приносит свой недостаток. Та бл…
В прерывании мы не вызываем «ChangeContext()» как функцию, а при помощи ассемблера «прыгаем» в эту функцию. Тогда мы оказываемся внутри функции, но при этом, в стек не сохраняется адрес возврата, а значит, вернувшись из функции «ChangeContext()», из стека будет взят сразу адрес возврата в задачу.
Одни плюсы!
Сейчас этот вариант мне, конечно, нравится, т.к. он самый быстрый, и экономит 2 байта на лишний адрес возврата, да и не нужно городить дефайны в config-файле и лишний код.
Но только теперь теряется предсказуемость. Когда мы вызываем функцию – ожидается, что мы из нее вернемся, а мы – не возвращаемся. Работает как часы, но не эстетично.
Оператор «goto» тоже работает как часы, но от него отказались по этой же причине. И не зря, хотя в некоторых ситуациях он наоборот делает код более понятным.
Получается, со скрипом принимаем это решение и тогда код запуска ОС будет выглядеть как в листинге ниже. Это опять псевдокод. Код «OS_Init» и «OS_CreateTask» опустим, т.к. это банально инициализация внутренних переменных.
int main(void)
{
cli();
Timer1A_Init();
OS_Init();
OS_CreateTask(Task1, stackBufTask1, sizeof(stackBufTask1));
OS_CreateTask(Task2, stackBufTask2, sizeof(stackBufTask2));
sei();
OS_Start();
}
void OS_Start (void)
{
currentTask = &tasksList[0];
StackPointer_SetAddress(currentTask->stackPointer);
/* Ща буит ассемблер */
RJMP ChangeContext
/* Ассемблера не буит */
}
void ChangeContext(void)
{
/* Код написан сильно выше */
}Голые функции

Гугл не хочет сохранять мой запрос «naked functions», наверное, думает, что я ищу порно, поэтому вот еще один мем, который напрашивается сам по себе:

Важное замечание, сохранение и восстановление контекста, сохранением и выгрузкой данных из стека, должны быть первой и последней инструкциями при смене контекста.
А т.к. компилятор, как упоминалось сильно выше, сам добавляет инструкции push/pop в каждую функцию и прерывание, чтобы сохранить регистры, которые считает нужными, то нам необходимо это как-то отключить, иначе ничего не поедет. Стек просто сломается, или в регистрах будут не те данные.
По умолчанию, любое прерывание и любую функцию компилятор преобразует вот в такое:
/* Прерывание таймера TIMER0 COMPA */
ISR(TIMER0_COMPA_vect)
{
push R16
push R17
/* User code */
pop R17
pop R16
}
/* Обработчик ядра нашей ОС */
void Kernel(void)
{
push R16
push R17
/* User code */
pop R17
pop R16
}Даже сохранение пары регистров все ломают. Даже одного. Даже на пол битика!
Для решения этой проблемы у функций могут быть атрибуты.
Одним из таких атрибутов является «naked», который говорит компилятору, что он не должен в эту функцию добавлять prolog (инструкции «push») и epilog (инструкции «pop» и возврата «ret» или «reti», если речь о прерывании).
Поэтому прерывание таймера, в котором мы вызываем ядро ОС, и само ядро ОС должны быть «naked» функциями.
Если кто не знает, все эти атрибуты описаны в документации на соответствующий компилятор.
В этом примере я использую стандартный компилятор WinAVR, если не ошибаюсь, который идет вместе с Atmel Studio (ну, или как там сейчас модно говорить – Microchip Studio).
В коде прототипы обработчика прерывания и функции «ChangeContext()» будут иметь вид:
/* Прерывание таймера TIMER0 COMPA */
ISR(TIMER0_COMPA_vect, ISR_NAKED)
{
}
/* Обработчик ядра нашей ОС */
void ChangeContext(void) __attribute__ ((naked));Сервисы ОС
Операционная система должна обеспечивать синхронизацию потоков. Для примера будут реализованы только сервисы «Sleep» и семафоры.
Важным замечанием будет, что мы до сих пор не упоминали задачу «Idle».
Сейчас самое время, т.к. она нужна как раз для этих сервисов.
Задача "Idle"
Если у нас есть несколько задач и все они вызвали сервис «Sleep», и спят ближайшие 1000 мс, что-то же должно выполняться, но только не код самих задач.
Вот здесь нам и нужен Idle-task. Это такая же задача, как и пользовательские, просто она выполняется всегда, когда другие задачи чего-то ждут.
По крайней мере я ее реализовал как обычную задачу, т.к. так проще, но есть мысли и о других способах, но это другая история.
Тело этой задачи должно содержать проверку на наличие актуальных задач, и если они есть – инициировать смену контекста.
static void IdleTask(void)
{
uint8_t i;
for(;;)
{
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
Kernel_DisableInterrupts();
if(Kernel_tasksList[i].status == TASK_STATUS_READY)
{
Kernel_Isr();
}
Kernel_EnableInterrupts();
}
}
}Sleep
Этот сервис должен позволить задаче передать управление операционной системе, и вернуть управление не ранее чем через указанное кол-во времени.
Тут почти как в ардуинах этих ваших, только во время «delay()» мы занимаемся чем-то полезным.
Логика сервиса проста как цикл «while»:
Изменяем статус задачи из «RUN» в «SLEEP»;
Сохраняем значение таймера, при котором планировщик изменит статус этой задачи из «SLEEP» в «READY»;
Вызываем ядро ОС «Kernel()»;
Ядро передает управление другой задаче;
И все…
Код сервиса выглядит примерно так:
void Service_Sleep(uint16_t cycles)
{
Kernel_DisableInterrupts();
currentTask->status = TASK_STATUS_SLEEP;
currentTask->timer = cycles;
ChangeContext();
Kernel_EnableInterrupts();
}Семафоры
Этот сервис должен позволить задаче передать управление операционной системе, и вернуть, как только указанный семафор будет кем-то установлен. Например, другой задачей или прерыванием.
Это почти как ничего не делать, только ничего не делать с пользой.

С семафорами чуть сложнее, чем с «Sleep», т.к. здесь появляются опять разные идеи как это все реализовать. Я сделал самый простой способ, где перебирал массив семафоров, но позже чуть оптимизировал.
Теперь задача содержит указатель на семафор, который ждет.
В общем, код, опять, не оптимальный, зато понятный и предсказуемый.
Для упрощения, в этом примере, установка семафора «Service_SetSemaphore()» запускает все задачи, которые ждут конкретный семафор, чтобы не перегружать пример.
void Service_WaitSemaphore(uint8_t semaphoreId)
{
Kernel_DisableInterrupts();
if(semaphoreId < CONFIG_SEMAPHORES_NUMBER)
{
if(currentTask->semaphorePtr == &semaphores[semaphoreId])
{
*currentTask->semaphorePtr = false;
}
else
{
currentTask->status = TASK_STATUS_SLEEP;
currentTask->semaphorePtr = &semaphores[semaphoreId];
ChangeContext();
}
}
Kernel_EnableInterrupts();
}
void Service_SetSemaphore(uint8_t semaphoreId)
{
uint8_t i;
if(semaphoreId < CONFIG_SEMAPHORES_NUMBER)
{
semaphores[semaphoreId] = true;
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
if(tasksList[i].semaphorePtr == &semaphores[semaphoreId])
{
*tasksList[i].semaphorePtr = false;
tasksList[i].semaphorePtr = NULL;
tasksList[i].status = TASK_STATUS_READY;
}
}
}
}Пишем ОС, т.к. мы уже умные
Если мы уже все поняли – можно это все реализовать!
Писать это мы сейчас будем на ATmega88.
Файловая структура
Создаем структуру проекта, она будет выглядеть так:

Далее будем идти снизу вверх, реализуя фичи с самого низкого уровня абстракции до самого высокого.
os/kernel/config/cpu.h
В этом файле у нас будут дефайны для аппаратных фич микроконтроллера, а точнее, регистры.
Я не нашел в стандартной библиотеке "avr/io.h" адрес STACK_POINTER, поэтому пришлось взять его из даташита (0x005D) и задефайнить самостоятельно.
CPU_KERNEL_TIMER_REGISTER – регистр таймера, прерывание которого мы используем в качестве таймера ОС.
Cpu_KernelTimerClear() – должен очищать значение счетчика таймера. Он используется в ядре перед восстановлением контекста и прыжка в следующую задачу, чтобы минимизировать потери процессорного времени на выполнения кода ядра ОС. Как-никак 40 мкс…
cpu.h
#ifndef CPU_H_
#define CPU_H_
#include <avr/io.h>
/* Hardware stack interface config */
#define CPU_STACK_POINTER_REGISTER_ADDRESS 0x005D
/* Timer for 'kernel ISR' interface config */
#define CPU_KERNEL_TIMER_REGISTER TCNT0
#define Cpu_KernelTimerClear() (CPU_KERNEL_TIMER_REGISTER = 0x00)
#endif /* CPU_H_ */os/kernel/config/stack_cfg.h
В этом файле должна быть расположена конфигурация стека. Размер места для регистров общего назначения и т.п., а также интерфейс для работы со стеком, т.к. нам нужно будет «вручную» перемещать аппаратный указатель на стек и сохранять его значение.
STACK_SPACE_FOR_GENERAL_PURPOSE_REGISTERS – кол-во байт для хранения регистров общего назначения в стеке.
STACK_SPACE_FOR_STATUS_REGISTER – кол-во байт для хранения регистра статуса. Это регистр «SREG» у AVR.
STACK_SPACE_FOR_RETURN_TO_TASK_ROUTINE – кол-во байт для хранения адреса возврата в задачу. Этот адрес используется для возврата в задачу из ядра ОС. Это либо начало задачи, либо точка, на которой задача была прервана в прошлый раз.
STACK_SPACE_FOR_COMMON_USE – это объем данных в стеке, который занят только регистрами.
STACK_MINIMUM_EXPECTED_SIZE_FOR_TASK – это минимальный требуемый размер стека для задачи в принципе.
StackPointer_GetAddress() – этот макрос должен возвращать байт, расположенный по указателю на аппаратный указатель стека.
StackPointer_SetAddress(__addr__) – этот макрос должен устанавливать аппаратный указатель на стек на указанный адрес.
stack_cfg.h
#ifndef STACK_CFG_H_
#define STACK_CFG_H_
#include "cpu.h"
#define STACK_SPACE_FOR_GENERAL_PURPOSE_REGISTERS 32
#define STACK_SPACE_FOR_STATUS_REGISTER 1
#define STACK_SPACE_FOR_RETURN_TO_TASK_ROUTINE 2
#define STACK_SPACE_FOR_COMMON_USE (STACK_SPACE_FOR_GENERAL_PURPOSE_REGISTERS + STACK_SPACE_FOR_STATUS_REGISTER)
#define STACK_MINIMUM_EXPECTED_SIZE_FOR_TASK (STACK_SPACE_FOR_COMMON_USE + STACK_SPACE_FOR_RETURN_TO_TASK_ROUTINE)
#define STACK_POINTER_REGISTER (*((uint16_t *)CPU_STACK_POINTER_REGISTER_ADDRESS))
#define StackPointer_GetAddress() ((uint8_t *)STACK_POINTER_REGISTER)
#define StackPointer_SetAddress(__addr__) (STACK_POINTER_REGISTER = (uint16_t)(__addr__))
#endif /* STACK_CFG_H_ */os/kernel/core/…
Модуль «stack» содержит только структуру стека и функции для работы с ним. Там ничего интересного:
stack.h
stack.h
#ifndef STACK_H_
#define STACK_H_
#include <stdint.h>
#include <stddef.h>
typedef struct {
uint8_t *stackPointer;
uint8_t *stackBegin;
uint8_t *stackEnd;
} Stack_t;
void Stack_Init(Stack_t *stack, uint8_t *stackBuf, size_t stackSize);
void Stack_PushByte(Stack_t *stack, uint8_t byte);
#endif /* STACK_H_ */stack.c
stack.c
#include <stdint.h>
#include <stddef.h>
#include "stack.h"
void Stack_Init(Stack_t *stack, uint8_t *stackBuf, size_t stackSize)
{
uint8_t *stackBegin;
uint8_t *stackEnd;
stackBegin = (stackBuf + stackSize - 1);
stackEnd = stackBuf;
stack->stackPointer = stackBegin;
stack->stackBegin = stackBegin;
stack->stackEnd = stackEnd;
}
void Stack_PushByte(Stack_t *stack, uint8_t byte)
{
*stack->stackPointer = byte;
stack->stackPointer--;
}С модулем «task» аналогично, только мы уже объединяем некоторые структуры, в т.ч. и «stack», и получаем «задачу».
task.h
task.h
#ifndef TASK_H_
#define TASK_H_
#include <stdint.h>
#include <stdbool.h>
#include "stack.h"
typedef enum {
TASK_STATUS_INIT=0,
TASK_STATUS_SLEEP_TIMER,
TASK_STATUS_SLEEP_SEMAPHORE,
TASK_STATUS_READY,
TASK_STATUS_RUN
} TaskStatus_e;
typedef union {
struct {
unsigned stackOverflow :1;
unsigned unused :7;
} bits;
uint8_t byte;
} TaskErrorFlags_t;
typedef struct {
bool firstEntry;
TaskStatus_e status;
TaskErrorFlags_t errorFlags;
bool *semaphorePtr;
void (*function)(void);
Stack_t stack;
uint16_t timer;
} Task_t;
bool Task_Setup(Task_t *taskPointer, void *taskFunction, uint8_t *stackBuf, size_t stackSize);
#endif /* TASK_H_ */task.c
task.c
#include <stdint.h>
#include <stdbool.h>
#include <stddef.h>
#include "../config/stack_cfg.h"
#include "stack.h"
#include "task.h"
bool Task_Setup(Task_t *taskPointer, void *taskFunction, uint8_t *stackBuf, size_t stackSize)
{
bool result = false;
bool taskSlotAvailable;
uint16_t word;
uint8_t byteHigh;
uint8_t byteLow;
if((taskPointer == NULL) || (taskFunction == NULL) || (stackBuf == NULL) || (stackSize < STACK_MINIMUM_EXPECTED_SIZE_FOR_TASK))
{
result = false;
}
else
{
taskSlotAvailable = ((void *)taskPointer->function == NULL) ? true : false;
if(taskSlotAvailable)
{
taskPointer->firstEntry = true;
taskPointer->status = TASK_STATUS_READY;
taskPointer->errorFlags.byte = 0x00;
taskPointer->semaphorePtr = NULL;
taskPointer->function = taskFunction;
taskPointer->timer = 0;
/* Init task stack */
Stack_Init(&taskPointer->stack, stackBuf, stackSize);
/* Set return address to the task body */
word = (uint16_t)(taskPointer->function);
byteHigh = (uint8_t)(word >> 8);
byteLow = (uint8_t)(word & 0x00FF);
Stack_PushByte(&taskPointer->stack, byteLow);
Stack_PushByte(&taskPointer->stack, byteHigh);
/* */
result = true;
}
}
return result;
}Далее уже рассмотрим модуль «kernel». Там есть на что обратить внимание, хотя, не так уж и много.
kernel.h
Здесь есть макросы «Kernel_SaveTaskContext()» и «Kernel_RestoreTaskContext()», для сохранения и восстановления контекста задачи соответственно. Есть два варианта макросов – один сделан через список push/pop, второй через цикл на ассемблере. Первый вариант – заметно быстрее, второй – заметно компактнее. Экономим 84 байта, что для AVR таки заметно, но выполняется этот код на 35 мкс дольше, что тоже заметно, но я не думаю, что кто-то планирует делать на AVR систему реального времени – так что это быстродействие тоже не смертельно, и имеет место быть.
Также, к большому сожалению, многие переменные объявлены как extern, для использования отдельного модуля «services». Если перенести все сервисы в модуль «kernel» – можно будет убрать модификатор «extern», но я так не хочу.
kernel.h
#ifndef KERNEL_H_
#define KERNEL_H_
#include <stdint.h>
#include <stdbool.h>
#include "task.h"
#include "../../config.h"
#if(CONFIG_KERNEL_USE_COMPACT_PUSH_POP)
/***************************************/
#define Kernel_SaveTaskContext() \
asm volatile( \
";------------------\r\n" \
" push r31 \r\n" \
" push r30 \r\n" \
" push r29 \r\n" \
" push r28 \r\n" \
";------------------\r\n" \
" in r28,__SREG__ \r\n" \
" push r28 \r\n" \
";------------------\r\n" \
" ldi r29,(32-4) \r\n" \
" ldi ZL,(32-4) \r\n" \
" ldi ZH,0 \r\n" \
";------------------\r\n" \
"loop_push: \r\n" \
" ld r28,-Z \r\n" \
" push r28 \r\n" \
" dec r29 \r\n" \
" brne loop_push \r\n" \
";------------------\r\n");
/***************************************/
#define Kernel_RestoreTaskContext() \
asm volatile( \
";----------------------\r\n" \
" ldi r29,(32-4) \r\n" \
" ldi ZL,0 \r\n" \
" ldi ZH,0 \r\n" \
"loop_pop: \r\n" \
" pop r28 \r\n" \
" st Z+,r28 \r\n" \
" dec r29 \r\n" \
" brne loop_pop \r\n" \
";----------------------\r\n" \
" pop r28 \r\n" \
" out __SREG__,r28 \r\n" \
";----------------------\r\n" \
" pop r28 \r\n" \
" pop r29 \r\n" \
" pop r30 \r\n" \
" pop r31 \r\n" \
";----------------------\r\n");
#else
/***************************************/
#define Kernel_SaveTaskContext() \
asm volatile( \
"push r31 \r\n" \
"push r30 \r\n" \
"push r29 \r\n" \
"push r28 \r\n" \
"push r27 \r\n" \
"push r26 \r\n" \
"push r25 \r\n" \
"push r24 \r\n" \
"push r23 \r\n" \
"push r22 \r\n" \
"push r21 \r\n" \
"push r20 \r\n" \
"push r19 \r\n" \
"push r18 \r\n" \
"push r17 \r\n" \
"push r16 \r\n" \
"push r15 \r\n" \
"push r14 \r\n" \
"push r13 \r\n" \
"push r12 \r\n" \
"push r11 \r\n" \
"push r10 \r\n" \
"push r9 \r\n" \
"push r8 \r\n" \
"push r7 \r\n" \
"push r6 \r\n" \
"push r5 \r\n" \
"push r4 \r\n" \
"push r3 \r\n" \
"push r2 \r\n" \
"push r1 \r\n" \
"push r0 \r\n" \
"in r16,__SREG__\r\n" \
"push r16 \r\n");
/***************************************/
#define Kernel_RestoreTaskContext() \
asm volatile( \
"pop r16 \r\n" \
"out __SREG__,r16\r\n" \
"pop r0 \r\n" \
"pop r1 \r\n" \
"pop r2 \r\n" \
"pop r3 \r\n" \
"pop r4 \r\n" \
"pop r5 \r\n" \
"pop r6 \r\n" \
"pop r7 \r\n" \
"pop r8 \r\n" \
"pop r9 \r\n" \
"pop r10 \r\n" \
"pop r11 \r\n" \
"pop r12 \r\n" \
"pop r13 \r\n" \
"pop r14 \r\n" \
"pop r15 \r\n" \
"pop r16 \r\n" \
"pop r17 \r\n" \
"pop r18 \r\n" \
"pop r19 \r\n" \
"pop r20 \r\n" \
"pop r21 \r\n" \
"pop r22 \r\n" \
"pop r23 \r\n" \
"pop r24 \r\n" \
"pop r25 \r\n" \
"pop r26 \r\n" \
"pop r27 \r\n" \
"pop r28 \r\n" \
"pop r29 \r\n" \
"pop r30 \r\n" \
"pop r31 \r\n");
#endif
#define Kernel_Nop() asm volatile("nop")
#define Kernel_JumpToIsr() asm volatile("rjmp Kernel_Isr")
#define Kernel_DisableInterrupts() asm volatile("cli")
#define Kernel_EnableInterrupts() asm volatile("sei")
#define Kernel_ReturnFromIsr() asm volatile("reti")
extern uint16_t Kernel_timer;
extern Task_t *Kernel_currentTask;
extern Task_t Kernel_tasksList[CONFIG_USER_TASKS_NUMBER];
extern bool Kernel_semaphores[CONFIG_SEMAPHORES_NUMBER];
void Kernel_Init(void);
void Kernel_Start(void);
void Kernel_Isr(void) __attribute__ ((naked));
#endif /* KERNEL_H_ */kernel.c
Здесь видно, что обработчик ядра не сильно изменился, в сравнении с нашим псевдокодом выше, все инструкции на месте, ну и, сюрприз-сюрприз, на самом деле она называется по-другому! О нет!
ErrorCheck_StackOverflowed() – макрос, для определения переполнения стека задачи. Далее в планировщике можно увидеть ловушку с бесконечным циклом. Но, на самом деле, эта проверка определяет переполнение стека, если мы вошли в ядро с переполнением, а вот если он в задаче переполнился, а потом вернулся обратно – ну никак. Это отдельная тема, есть пара идей, как это проверять, но это лютые глупости без аппаратных ловушек… Например – проверять содержимое ОЗУ каждый раз на порчу, при помощи контрольных сумм, или вроде того, но это медленно, шо капец… Так что здесь глупостей таких пока что не делаем. Возможно, потом
Хочу обратить внимание на функцию «TimersRoutine()». В нашем примере кода сервиса «Sleep» немного более примитивная реализация таймера, и там каждая задача имеет свой счетчик, на самом деле в моей реализации это не так. Видно, что каждая задача содержит константу, с которой сравнивается общий таймер ядра «Kernel_timer». И только он один инкрементируется, что оптимальнее.
kernelInterruptTimer – также интересный момент. Эта переменная хранит значение аппаратного таймера, прерывание которого мы используем для ОС. В функции планировщика «Scheduler()» мы проверяем его на вопрос – «аппаратный таймер дошел до своего предела и мы в обработчике ядра из-за прерывания, или из-за ручной смены контекста вызовом сервиса?». И только потом инкрементируется таймер сервиса «Sleep». Без этой фичи – вызовы сервисов для смены контекста дают сильную погрешность таймера «Sleep».
kernel.c
#include <stdint.h>
#include <stddef.h>
#include <stdbool.h>
#include <string.h>
#include "../config/cpu.h"
#include "../config/stack_cfg.h"
#include "stack.h"
#include "kernel.h"
#define ErrorCheck_StackOverflowed() \
(((Kernel_currentTask->stack.stackPointer + 1) < Kernel_currentTask->stack.stackEnd) \
|| (Kernel_currentTask->stack.stackPointer > Kernel_currentTask->stack.stackBegin))
Task_t *Kernel_currentTask;
Task_t Kernel_tasksList[CONFIG_USER_TASKS_NUMBER];
bool Kernel_semaphores[CONFIG_SEMAPHORES_NUMBER];
uint16_t Kernel_timer;
static void Scheduler(void);
static void IdleTask(void);
static void TimersRoutine(void);
static void SelectNextTask(void);
static Task_t taskIdle;
static uint8_t taskIdleStackBuf[CONFIG_IDLE_TASK_STACK_SIZE];
static Stack_t kernelStack;
static uint8_t kernelStackBuf[CONFIG_KERNEL_STACK_SIZE];
void Kernel_Init(void)
{
/* Clear variables */
Kernel_timer = 0;
memset(Kernel_tasksList, 0, sizeof(Kernel_tasksList));
memset(Kernel_semaphores, 0, sizeof(Kernel_tasksList));
/* Initialize variables */
Task_Setup(&taskIdle, IdleTask, taskIdleStackBuf, sizeof(taskIdleStackBuf));
Stack_Init(&kernelStack, kernelStackBuf, sizeof(kernelStackBuf));
}
void Kernel_Start(void)
{
Kernel_currentTask = &taskIdle;
Kernel_currentTask->firstEntry = false;
StackPointer_SetAddress(Kernel_currentTask->stack.stackPointer);
Kernel_JumpToIsr();
}
void Kernel_Isr(void)
{
/* Save task context to the stack buffer */
Kernel_SaveTaskContext();
/* Save current state of the hardware stack pointer to the current task structure */
Kernel_currentTask->stack.stackPointer = StackPointer_GetAddress();
/* Set stack pointer to the kernel stack buffer */
StackPointer_SetAddress(kernelStack.stackPointer);
/* Process scheduler logic */
Scheduler();
/* Save current state of the hardware stack pointer tor the kernel stack structure */
kernelStack.stackPointer = StackPointer_GetAddress();
/* Move stack pointer to the stack buffer of the next task */
StackPointer_SetAddress(Kernel_currentTask->stack.stackPointer);
Cpu_KernelTimerClear();
/* If it's first entry to Kernel ISR from this task -> then do nothing */
if(Kernel_currentTask->firstEntry)
{
Kernel_currentTask->firstEntry = false;
}
/* else -> restore task context from stack */
else
{
Kernel_RestoreTaskContext();
}
/* Return from 'naked' function that is also interrupt routine */
Kernel_ReturnFromIsr();
}
static void Scheduler(void)
{
static uint8_t kernelInterruptTimer = 0;
/* Traps */
if(ErrorCheck_StackOverflowed())
{
for(;;)
{
Kernel_Nop();
}
}
kernelInterruptTimer += CPU_KERNEL_TIMER_REGISTER;
if(kernelInterruptTimer >= CONFIG_KERNEL_ISR_TIMER_COMPARATOR_VALUE)
{
kernelInterruptTimer = 0;
TimersRoutine();
}
SelectNextTask();
}
static void IdleTask(void)
{
uint8_t i;
for(;;)
{
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
Kernel_DisableInterrupts();
if(Kernel_tasksList[i].status == TASK_STATUS_READY)
{
Kernel_Isr();
}
Kernel_EnableInterrupts();
}
}
}
static void TimersRoutine(void)
{
uint8_t i;
Kernel_timer++;
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
if(Kernel_tasksList[i].status == TASK_STATUS_SLEEP_TIMER)
{
if(Kernel_tasksList[i].timer == Kernel_timer)
{
Kernel_tasksList[i].status = TASK_STATUS_READY;
}
}
}
}
static void SelectNextTask(void)
{
static uint8_t currentTaskIndex = 0;
bool taskAvailable;
uint8_t i;
if(Kernel_currentTask->status == TASK_STATUS_RUN)
{
Kernel_currentTask->status = TASK_STATUS_READY;
}
i = CONFIG_USER_TASKS_NUMBER;
while(i--)
{
Kernel_currentTask = &Kernel_tasksList[currentTaskIndex];
taskAvailable = false;
if(Kernel_currentTask->status == TASK_STATUS_READY)
{
taskAvailable = true;
}
currentTaskIndex++;
if(currentTaskIndex >= CONFIG_USER_TASKS_NUMBER)
{
currentTaskIndex = 0;
}
if(taskAvailable)
{
break;
}
}
if(!taskAvailable)
{
Kernel_currentTask = &taskIdle;
}
Kernel_currentTask->status = TASK_STATUS_RUN;
}os/services/…
service.h
Ну тут скукотень, конечно же…
service.h
#ifndef SERVICES_H_
#define SERVICES_H_
#include <stdint.h>
#include <stddef.h>
#include <stdbool.h>
void Service_InitKernel(void);
void Service_Sleep(uint16_t cycles);
void Service_WaitSemaphore(uint8_t semaphoreId);
void Service_SetSemaphore(uint8_t semaphoreId, bool broadcast, bool changeContext);
bool Service_CreateUserTask(void *taskFunction, uint8_t *stackBuf, size_t stackSize);
#endif /* SERVICES_H_ */service.c
А вот тут кое-что есть. Но лучше бы была скукотень, я не хочу описывать, я заеб устал…
Окей…
Service_Sleep() – здесь как раз таки видно тот прикол с таймером. Мы рассчитываем будущее значение «Kernel_timer» с учетом переполнения, когда пройдет указанное кол-во тактов операционной системы. И сохраняем это значение в таймер задачи.
Service_SetSemaphore() – сервис установки семафора, и у него есть аргументы «broadcast» и «changeContext». Если первый == «true», значит одновременно «поедут» все задачи, которые ждут данный семафор. Второй аргумент, если «true», инициирует смену контекста. Например, полезно, если вы устанавливаете семафор в другой задаче, а не в прерывании.
Установка семафора при аргументе «broadcast == false» возможно отработает не так как нужно, т.к. у меня сейчас не реализована очередь семафоров, и семафор будет все время забирать первая задача в списке задач. Назовем это не «Лень», а «Errata».
У «Atmel», кстати, тоже Errata есть, а чем я хуже?
service.c
#include <stdint.h>
#include <stddef.h>
#include <stdbool.h>
#include "../config.h"
#include "../kernel/core/task.h"
#include "../kernel/core/kernel.h"
/*
* Initializes kernel
*/
void Service_InitKernel(void)
{
Kernel_Init();
}
/*
* Sleep service.
* Immediately changes the context.
* Arguments:
* cycles - number of OS timer ticks, after which task will be continued.
*/
void Service_Sleep(uint16_t cycles)
{
Kernel_DisableInterrupts();
Kernel_currentTask->status = TASK_STATUS_SLEEP_TIMER;
if((UINT16_MAX - Kernel_timer) < cycles)
{
cycles -= (UINT16_MAX - Kernel_timer);
Kernel_currentTask->timer = cycles;
}
else
{
Kernel_currentTask->timer = (Kernel_timer + cycles);
}
Kernel_Isr();
Kernel_EnableInterrupts();
}
/*
* Transfers task to the sleep state to wait for the binary semaphore.
* - If the semaphore is already set -> semaphore will be cleared and function returns to the current task.
* - If the semaphore isn't set yet -> it changes the context.
*/
void Service_WaitSemaphore(uint8_t semaphoreId)
{
Kernel_DisableInterrupts();
if(semaphoreId < CONFIG_SEMAPHORES_NUMBER)
{
if(Kernel_currentTask->semaphorePtr == &Kernel_semaphores[semaphoreId])
{
*Kernel_currentTask->semaphorePtr = false;
}
else
{
Kernel_currentTask->status = TASK_STATUS_SLEEP_SEMAPHORE;
Kernel_currentTask->semaphorePtr = &Kernel_semaphores[semaphoreId];
Kernel_Isr();
}
}
Kernel_EnableInterrupts();
}
/*
* Sets the semaphore by ID.
* Arguments:
* semaphoreId - Semaphore ID;
* broadcast - allows you continue tasks synchronic, if all of them waits current semaphore:
* If 'true', then status of all tasks which waits this semaphore will be changed to the 'ready',
* If 'false', then first task which waits this semaphore will be changed to the 'ready'.
* changeContext - context will be changed immediately.
*/
void Service_SetSemaphore(uint8_t semaphoreId, bool broadcast, bool changeContext)
{
uint8_t i;
if(semaphoreId < CONFIG_SEMAPHORES_NUMBER)
{
Kernel_semaphores[semaphoreId] = true;
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
if(Kernel_tasksList[i].semaphorePtr == &Kernel_semaphores[semaphoreId])
{
*Kernel_tasksList[i].semaphorePtr = false;
Kernel_tasksList[i].semaphorePtr = NULL;
Kernel_tasksList[i].status = TASK_STATUS_READY;
if(!broadcast)
{
break;
}
}
}
if(changeContext)
{
Kernel_DisableInterrupts();
Kernel_currentTask->status = TASK_STATUS_READY;
Kernel_Isr();
Kernel_EnableInterrupts();
}
}
}
/*
* Creates user task in the scheduler queue.
*/
bool Service_CreateUserTask(void *taskFunction, uint8_t *stackBuf, size_t stackSize)
{
bool result;
uint8_t i;
result = false;
for(i = 0; i < CONFIG_USER_TASKS_NUMBER; i++)
{
result = Task_Setup(&Kernel_tasksList[i], taskFunction, stackBuf, stackSize);
if(result)
{
break;
}
}
return result;
}os/config.h
Самое унылое.
Но все же.
Конфигурация ОС.
Интересного нет ничего, кроме оговорочки, что есть константа «CONFIG_KERNEL_ISR_TIMER_COMPARATOR_VALUE», которая должна хранить значение компаратора для таймера, который мы используем для ОС.
Это не круто, но, иначе никак, т.к. это число нам нужно для компенсации частых вызовов смены контекста вручную из задач (помните, было выше?).
config.h
#ifndef CONFIG_H_
#define CONFIG_H_
#include <stdint.h>
#include "kernel/config/stack_cfg.h"
#define CONFIG_KERNEL_USE_COMPACT_PUSH_POP 0
#define CONFIG_USER_TASKS_NUMBER 5
#define CONFIG_SEMAPHORES_NUMBER 10
#define CONFIG_KERNEL_ISR_TIMER_COMPARATOR_VALUE 125
/* Idle task stack must have extra space for return address when it's call 'Kernel_Isr()' from own body */
#define CONFIG_IDLE_TASK_STACK_SIZE (STACK_MINIMUM_EXPECTED_SIZE_FOR_TASK + 2)
/* Kernel stack must have space only for function, that can be called in 'Kernel_Isr()' */
/* Please, change it only if you change 'Kernel_Isr' routine!!! */
#define CONFIG_KERNEL_STACK_SIZE 16
#endif /* CONFIG_H_ */os/os.h
Ну и наконец-то… Дождались…
Этот файл нужно подключить в ваш «main()», ну или откуда вы там ОС вызывать собираетесь.
И этот файл содержит интерфейсы для работы с ОС.
os.h
#ifndef OS_H_
#define OS_H_
#include "kernel/core/kernel.h"
#include "services/services.h"
#define OS_Init() Service_InitKernel()
#define OS_Start() Kernel_Start()
#define OS_Isr() Kernel_JumpToIsr()
#define OS_Sleep(__cycles__) Service_Sleep((__cycles__))
#define OS_SemaphoreWait(__id__) Service_WaitSemaphore((__id__))
#define OS_SemaphoreSet(__id__) Service_SetSemaphore((__id__), false, false)
#define OS_SemaphoreSetImmidiately(__id__) Service_SetSemaphore((__id__), false, true)
#define OS_SemaphoreSetBroadcast(__id__) Service_SetSemaphore((__id__), true, false)
#define OS_SemaphoreSetBroadcastImmidiately(__id__) Service_SetSemaphore((__id__), true, true)
#define OS_CreateTask(__func__, __stack_buf__, __stack_size__) Service_CreateUserTask((__func__), (__stack_buf__), (__stack_size__))
#endif /* OS_H_ */Результат работы
Далее скриншоты примера работы нашей ОС.
Квант времени задачи 1 мс, используем 4 задачи вызывая в каждой сервис «Sleep» на 100 мс.
Код «main()» ниже. Идентификаторы некоторых макросов и функций могут отличаться от примеров с псевдокодом. Простите, если найдете что-то отличающееся
Код "main()", для примера, как это сделано:
main.c
#include <stdint.h>
#include <stdbool.h>
#include <stddef.h>
#include <avr/io.h>
#include <avr/interrupt.h>
#include "os/os.h"
#define TIMER_KERNEL_PERIOD_debug 1
#define TIMER_KERNEL_PERIOD_1ms 2
#define TIMER_KERNEL_PERIOD_8ms 3
#define TIMER_KERNEL_PERIOD TIMER_KERNEL_PERIOD_1ms
void Gpio_Init(void);
void Timer1A_Init(void);
void Timer2A_Init(void);
uint8_t stackBufTask1[64];
uint8_t stackBufTask2[64];
uint8_t stackBufTask3[64];
uint8_t stackBufTask4[64];
void Task1(void);
void Task2(void);
void Task3(void);
void Task4(void);
int main(void)
{
cli();
Gpio_Init();
Timer1A_Init();
OS_Init();
OS_CreateTask(Task1, stackBufTask1, sizeof(stackBufTask1));
OS_CreateTask(Task2, stackBufTask2, sizeof(stackBufTask2));
OS_CreateTask(Task3, stackBufTask3, sizeof(stackBufTask3));
OS_CreateTask(Task4, stackBufTask4, sizeof(stackBufTask4));
sei();
OS_Start();
}
void Gpio_Init(void)
{
DDRB |= 0xFF;
PORTB = 0x00;
}
void Timer1A_Init(void)
{
TCCR0A = 0x00; /* Normal mode, PWM pin OC0A/OC0B disconnected */
TIMSK0 |= (1<<OCIE0A); /* Enable OVF A interrupt */
#if(TIMER_KERNEL_PERIOD == TIMER_KERNEL_PERIOD_debug)
TCCR0B = (1<<CS00); /* Freq/1 */
OCR0A = 50; /* 50 ticks */
#elif(TIMER_KERNEL_PERIOD == TIMER_KERNEL_PERIOD_1ms)
TCCR0B = (1<<CS01)|(1<<CS00); /* Freq/64 */
OCR0A = 125; /* 1 ms */
#elif(TIMER_KERNEL_PERIOD == TIMER_KERNEL_PERIOD_8ms)
TCCR0B = (1<<CS02); /* Freq/256 */
OCR0A = 250; /* 8 ms */
#else
#error "Wrong kernel timer period specified!"
#endif
TCNT0 = 0x00; /* */
TIFR0 = 0xFF; /* ISR flags resets by writing '0xFF' */
}
void Timer2A_Init(void)
{
TCCR2A = 0x00; /* Normal mode, PWM pin OC0A/OC0B disconnected */
TIMSK2 |= (1<<OCIE2A); /* Enable OVF A interrupt */
TCCR2B = (1<<CS22); /* Freq/64 */
OCR2A = 25; /* 200 uS */
TCNT2 = 0x00; /* */
TIFR2 = 0xFF; /* ISR flags resets by writing '0xFF' */
}
void Task1(void)
{
for(;;)
{
OS_Sleep(100);
PORTB ^= 1;
}
}
void Task2(void)
{
for(;;)
{
OS_Sleep(100);
PORTB ^= 2;
}
}
void Task3(void)
{
for(;;)
{
OS_Sleep(100);
PORTB ^= 4;
}
}
void Task4(void)
{
for(;;)
{
OS_Sleep(100);
PORTB ^= 8;
}
}
ISR(TIMER0_COMPA_vect, ISR_NAKED)
{
OS_Isr();
}Скриншоты
Схема в протеусе для ардуинщиков 99-го левела:
Осцилоскопия
Вот так все работает. Видно, что есть 4 синхронизированных меандра.

Но, если присмотреться, видно смещение на 40 мкс между задачами. Как раз весь код ядра с планировщиком и сервисом «Sleep» выполняется около 40 мкс, что проверено в отладке.

Ссылки
GitHub я себе еще не завел, поэтому залил проект на свой гугл-диск: здесь
Ссылка на статью, на которую я уже ссылался пару раз: тут
Ссылка на статью, на которую я не ссылался, но читал, хоть и давно: здесь
Соглашение AVR-GCC для использования регистров компилятором: тут
Комментарии (45)

AVI-crak
31.07.2021 21:13-3Памяти всего 1 килобайт, переключаем, вытесняем, обрабатываем... А работать когда?
GitHub это полезно и бесплатно. Но начинать нужно с домашней системы контроля версий.

A3IPIB Автор
31.07.2021 21:21+2Памяти всего 1 килобайт, переключаем, вытесняем, обрабатываем... А работать когда?
Я не понял в чем суть замечания.
Работаем во время кванта времени, который длится 1 мс, если хотите - меняете период прерывания таймера, и задаёте свой квант времени, вот и работаете. До 100 мкс ядро, 1000 мкс рантайм (можете задать 10 мс, тогда рантайм будет 10 000 мкс).
Памяти всего 1 килобайт
Каждая задача требует 35 байт для стека, значит, если у нас целых четыре задачи, то:


Целых 884 байта остается!
Даже если каждый таск будет вызывать 4 вложенных функции, это еще плюс 32 байта.
Ну тогда будет 852 байта.
Этого недостаточно для чего?
По-моему для всего за глаза...
Целью для меня была именно статья, а не проект. Если буду выкладывать эту ОС как релиз - заведу гит.

lamerok
01.08.2021 10:09Для такого мелкого контроллера лучше сделать вытесняющую ОС с run to completion задачами, в таком случае, не нужен будет отдельный стек для задач, и вообще не надо будет заморачиваться с сохранением контекста задач, все автоматом будет делаться компилятором, ну и конечно переключение контекста будет в разы быстрее.
Еще вопрос, а зачем для микронтроллера не ОСРВ вытесняющая операционка? Ну т.е основное преимущество ОС для микронтроллеров, это как раз возможность по событию быстро переключиться на высоко-приоритную задачу, чтобы обеспечить "мгновенную реакцию", т.е послал я из прерывания по таймеру событие задаче измерение, тут же ее вызвал. Не совсем уловил этот момент у вас. У вас получается как в Винде, пока 1мс не пройдет, никакой реакции, верно я понял?
A3IPIB Автор
01.08.2021 12:06лучше сделать вытесняющую ОС с run to completion
Согласен, это лучше, если бы у меня была цель сделать что-то максимально оптимальное для AVR. А здесь же была цель именно сделать настоящую вытесняющую ОС. Не важно под какую архитектуру. AVR я выбрал, т.к.:
Их, с аппаратной точки зрения, я знаю лучше других архитектур, а значит я буду сконцентрирован только на ОС, а не изучении архитектуры;
Хотел сделать максимально простую вытесняющую ОС, которая поедет даже на AVR, т.к. если делать сразу под ARM - многие моменты по поводу оптимизации могут ускользнуть, т.к. там ресурсов хоть жеппой жуй. Такой себе челендж для меня;
Опять же, я уже отвечал на другие комментарии, цель этой ОС, в первую очередь - обучение.
Первым требованием к моей ОС была возможность вызывать в задачах тупые задержки "while", т.к. делать это в кооперативных ОС нельзя, и в "run to completion", если я правильно понимаю что это, тоже нельзя.
Ожидать что-то через сервисы ОС не всегда удобно. Как опытный пользователь кооперативной RTOS - я просто уже за*бался что-то ждать без "while", если нет требований к быстродействию.
Без "while" код начинает выглядеть ненаглядно, и не далеко уходит от использования конечного автомата в "main()" без использования ОС в принципе.
Ну и конечно же сделать вытесняющую ОС общего назначения мне банально было интереснее.
Можно сказать - мечта детства, сделать свой мини-компьютер на AVR, подключить дисплей, внешнюю память и т.п. Вот для этого мне и нужна была вытесняющая ОС общего назначения. Конечно, это не эффективно, если сравнивать с Ryzen 2600 и материнкой на X570. Но это просто домашний проект, ничего важного для посторонних людей. Это просто для души)
а зачем для микронтроллера не ОСРВ вытесняющая операционка?
А я в статье не написал что она "не ОСРВ". Правда и не написал, что она "ОСРВ"...
Потому что побоялся холиваров;
Я не смог найти четкого определения ОСРВ, чтобы мог уверенно ее так назвать.
После долгих поисков информации, я пришел к выводу, что ОСРВ - это просто ОС, для которой разработчик просто указывает время реакции ОС на изменения. То есть, время переключения контекста после установки семафора, например.
Вот когда доделаю - измерю время реакции, и, наверное, назову ее ОСРВ)))
У вас получается как в Винде, пока 1мс не пройдет, никакой реакции, верно я понял?
Нет, если задача должна чего-то дождаться, она может начать ждать семафор, я их реализовал. Тогда она перестает выполняться. И потом планировщик возобновит ее если кто-то установит этот семафор.
lamerok
01.08.2021 14:16Нет, если задача должна чего-то дождаться, она может начать ждать семафор, я их реализовал. Тогда она перестает выполняться. И потом планировщик возобновит ее если кто-то установит этот семафор.
Я имею ввиду, вот к примеру, пришло внешнее прерывание от АЦП и нужно тут же посчитать что-то. Понятно, что в прерывании считать не надо, иначе заблокируем все, надо передать событие задаче. Обычно так и делается, прерывание просто генерит событие, тут же вызывается планировщик и запускается нужная задача для обработки события, а как это у вас будет происходить? Насколько я понял, пока не пройдет квант времени, ничего не произойдёт. Т.е. придется эту 1 мс ждать в худшем случае, верно?
run to completion", если я правильно понимаю что это, тоже нельзя.
В run to completion они(задержки) не нужны :). Задача вызывается только тогда, когда она нужна. Это кстати еще хорошо с точки зрения потребления, и не надо каждый раз 1мс долбить таймер в 90% в пустую. Но придется задействовать много таймеров, ну либо также можно сделать на одном таймере, но тогда долбежка тоже будет.
A3IPIB Автор
01.08.2021 14:50В run to completion они(задержки) не нужны :). Задача вызывается только тогда, когда она нужна.
Это получается таблица событий. Это не то, что мне нужно.
Я имею ввиду, вот к примеру, пришло внешнее прерывание от АЦП и нужно тут же посчитать что-то. Понятно, что в прерывании считать не надо, иначе заблокируем все, надо передать событие задаче. Обычно так и делается, прерывание просто генерит событие, тут же вызывается планировщик и запускается нужная задача для обработки события, а как это у вас будет происходить?
Если задача 1 ждет семафор, а задача 2 выполняется, то пока квант времени задачи 2 не закончится - задача 1 не получит управление, даже если семафор установлен.
Смена контекста из прерывания еще не реализована. Но она будет.

sami777
01.08.2021 00:35+1Вообще то локальные переменные обычно хранятся на стеке. и уже оттуда помещаются в регистры, по мере необходимости их использования. В конце концов локальных переменных то же может быть много ( ну кто знает, сколько вы их объявите внутри функции, хоть 50 штук) Где на них столько регистров наберешься???? По моему по договору (для армов) первые три регистра используются для хранения локальных, а вот все остальное (будь те любезны) на стек.
A3IPIB Автор
01.08.2021 01:59+1локальные переменные обычно хранятся на стеке. и уже оттуда помещаются в регистры
Локальные переменные не хранятся в стеке просто так. Либо я не понял что имеется ввиду)
Да, они могут попасть в стек в ходе выполнения функции, например, если нужно что-то сохранить, и выполнить другие манипуляции и этими же регистрами, но это зависит от компилятора.
И это хорошее замечание, которого я не учел, спасибо!
Как будет время - я разберусь с этим и обновлю статью, т.к. это может стать причиной переполнения стека и об этом нужно знать.

ironsnake
03.08.2021 14:09В регистры вы можете поместить столько локальных переменных, сколько у вас регистров. Все остальные будут храниться на стеке и при необходимости перемещаться в регистр. Когда происходит выход из функции, SP выставляется в адрес, на котором он был в начале функции.
sami777
01.08.2021 00:49-2Под "naked" функцией возможно имело смысл поискать по ключевому слову "inline" функция? Как помню для старых 8 битных avr все функции по умолчанию инлайнились компилятором.
A3IPIB Автор
01.08.2021 02:11+1Под "naked" функцией возможно имело смысл поискать по ключевому слову "inline" функция?
Я не уловил смысл. Где поискать и зачем?
Как помню для старых 8 битных avr все функции по умолчанию инлайнились компилятором
"naked" точно убирает prolog и epilog, т.к. этот атрибут именно для этого и нужен.
А вот "inline" - я не уверен что все компиляторы делают все одинаково с ним, так что его я для этих целей использовать не рекомендую.
Только что проверил в этом же проекте - компилятор мне ничего не заинлайнил. Ему вообще все пофигу. Либо моя 8-битная avr-ка недостаточно старая)
все функции по умолчанию инлайнились
Ну очевидно, что инлайнить функции, которые вызываются несколько раз, он точно не должен. Прям вот права иметь не должен.
Разве что речь о старых AVR, в которых не было стека, но я о таких не слышал)
sami777
01.08.2021 08:37-3INLINE
Нет, не все. Где то надо перед объявлением функции явно указывать ключевое слово "inline". А для наиболее простых мк (частный пример 8 бит авр, в авр студио), по умолчанию инлайнил функции, которые допускали возможность прямого выполнения в коде, как вы выразились без "пролога и эпилога".
ghosts_in_a_box
02.08.2021 13:20+2inline именно про встраивание функции в тело другой функции и ключевым словом является только в С++, оно не имеет никакого отношения к удалению пролога и эпилога. Тут нужен именно naked.
С некоторыми оговорками, ближайший аналог из Си это #define. Встроенную функцию можно лучше оптимизировать и нет никаких накладных расходов на вызов (т.к. по-факту не происходит ни вызова ни возврата из встроенной функции), но бинарник от этого может довольно значительно распухнуть, т.к. функция будет поставлена во все места, где она вызывается.
sami777
02.08.2021 20:38Спорить не буду. Пишу на "Си". Если перед Си функцией объявляю ключевое слово "inline" GCC не ругается. Будет использоваться стек компилятором в этом случае, не проверял. Но предполагаю, что для уменьшения накладных расходов, большинство функций можно сделать встроенными в тело главной функции.
predator86
02.08.2021 23:31Но предполагаю, что для уменьшения накладных расходов, большинство функций можно сделать встроенными в тело главной функции.
Какие именно накладные расходы Вы имеете в виду?ghosts_in_a_box
03.08.2021 00:22Расходы на вызов, возврат, перекладывание данных в нужные регистры, через которые передаются параметры в функцию, прочие манипуляции, описанные в ABI.
Но все эти накладные расходы не важны, когда прошивка не помещается в МК, не зря inline на -Os не включается, и вообще компилятор сам решает, встраивать функцию или нет. Заставить его можно через forceinline, только скорее всего это плохая идея.
И для того, что описано в стаье inline не подходит, т.к. он именно встраивает функцию по месту вызова, и если встраивание не удалось (например, куда встраивать обработчик прерывания?), то пролог и эпилог никуда не денутся.
Diamus
01.08.2021 00:57И тут возникает вопрос: а зачем? Вы уж извините, но в данном контроллере каждый байт на счету, как в памяти так и во флеше. Отладка Операционной Системы и тестирование на данном микроконтроллере у Вас займет столько времени, что Вы никогда не окупите проект даже если будете работать за свой счет 95 % времени. А почему пишу - мой КБ (конструкторское бюро) мне выдал PIC16 для 30К $ девайса. Все было сделано на ассемблере за 2 года, плюс 1 год потрачено на новую функциональность из-за нехватки памяти. А потом на новом 32 bit контроллере с 256 Flash и 256 RAM я сделал похожее устройство (правда, прототип) без всех ограничений (а они были, уж поверьте) за 3 месяца удаленно. И тут дело не только в опыте.
И Ваш проект звучит - мне скучно и нечем заняться, но не рекомендуйте его пожалуйта :) Нужна OS for Embedded - ThreadX лежат исходники например, Linux тоже не закрыт.Никак не хочу оскорбить - просто Ваша статья может ввести в заблуждение
A3IPIB Автор
01.08.2021 01:51+3И тут возникает вопрос: а зачем?
Чтобы разобраться!
Это удивительно, и может показаться не очевидным, но разбираться, делая с нуля, шаг за шагом - полезнее, и в некотором смысле проще, чем разбирать код уже готовой ОС. Т.к. там:
Много ненужных фич, которые будут отвлекать;
Много оптимизаций, которые могут запутать;
Не понятная структура для того, кто еще не делал такого ни разу. Вот и я, не делал такого ни разу, поэтому решил сделать свое, чтобы разобраться.
Я так понимаю, вы сторонник идеи "зачем делать свое, если все сделано до нас".
Вот мне как раз таки становится грустно из-за этой идеи...
Т.к. из-за этого - мало кто знает что и как работает, и способны только бездумно копировать. И конечно же плодить статьи по ардуино, из разряда:
"Подключаете библиотеку, копируете мой код - и у ваш веб-сервер и дата центр готов."
Круто, конечно, оно работает, но мне от этого грустно(
И Ваш проект звучит - мне скучно и нечем заняться
Скучно и нечем заняться - это запускать Скайрим на тесте на беременность, что, кстати, уже было.
"разобраться, как это сделать" != "нечем заняться"
А если я портирую проект на PIC24 или ARM - что-то изменится? Вашу претензию удовлетворю, т.к. там памяти больше. А что еще хорошего будет?
У моего проекта было три цели:
Разобраться, как сделать вытесняющую ОС;
Сделать вытесняющую ОС для AVR;
Определить, насколько это целесообразно, использовать вытесняющую ОС на AVR, т.к. их действительно мало, но они есть.
Так вот:
Первый пункт выполнен;
Второй пункт выполнен, хоть, она еще и не доделана;
Третий пункт выполнен, считаю, что это весьма целесообразно.
Если вы считаете, что вытесняющая ОС для AVR - абсурд, то не сталкивались с моими задачами, например, когда тебе нужно сделать типовое устройство для коммутации нагрузки и т.д. В таких проектах не требуется много памяти, а вот многопоточность - ну капец как упростит код.
И я в статье нигде не писал, что создаю конкурента FreeRTOS, ThreadX, или буду ее рекомендовать для Automotive-разработчиков или Илону Маску. А как раз таки, указал, что это ради обучения и примера. Я ни в коем случае не рекламирую свой проект, я его приложил как доказательство, что все работает, и чтобы те, кому интересно, могли поиграться, если не нашли всех ответов в статье.
А по поводу:
мой КБ (конструкторское бюро) мне выдал PIC16 для 30К $ девайса. Все было сделано на ассемблере за 2 года, плюс 1 год потрачено на новую функциональность из-за нехватки памяти.
И я не понял, у чему это было упомянуто, но, думаю, ваше КБ делает что-то не так, если приняло такое решение.
Diamus
01.08.2021 09:01Суть моего поста была в том, чтобы не усложнять код без необходимости. Вы не забывайте про тех, кто будет платить за разработку ОС, кто будет тестировать и кто прийдет после Вас. Но Вы абсолютно правы в том, что я Вашего проекта не знаю и оценить целесообразность использования ОС не могу - просто я столько видел проектов, для людям хотелось поэксперементировать с чем-то новым - и простой проект превращался в неподдерживаемого монстра.
Свой проект почему я упомянул - это как не нужно делать - тогда я был молодой и не мог оценить проект, да и железо было готово - но если бы тогда сразу взяли новый микроконтроллер - время разработки уменьшилось бы. А сейчас в том проекте 5 байт свободной оперативной памяти - и никакой функциональности не добавишь без полного редизайна.
ОС вносит очень большой overhead.
Я не пишу под Ardino или Rasberry, чтобы с гордостью рассказывать, какой я Embedded разработчик - просто в моих проектах микросекунды играют роль.
Например если глянуть, как генерируется код для портов в нынешних IDE, то чтобы pin перещелкнуть - это одна команда без OC - и страница кода если требуется поддержка OC.
lamerok
01.08.2021 10:27Ну иногда требуется
А вообще, проект, проекту рознь. Иногда возьмешь микроконтроллер побольше и начинаешь шашкой махать, а потом оказывается, что выбранный контроллер на 50 центов дороже, того, в который ты мог влезть. И ты теряешь 50 000 долларов в год из за этого.
Насчет ОС для такого мелкого микроконтроллера, я там выше написал, можно было бы run to completion сделать, проще, меньше, быстрее.
Но в общем с ОС разрабатывать софт приятнее.

select26
01.08.2021 10:02-1OS – это программная прослойка,
Вот простите меня пожалуйста. Вы же сами посмеиваетесь над своим поспешным подходом. Но любой человек (да и не человек тоже), который собирается писать ОС, должен сначала понимать что это такое.
Есть фундаментальный труд, на котором выросли писатели ВСЕХ современных ОС: "Операционные системы" Э. Таненбаума. После прочтения этой книги в голове будет порядок и работать будет проще. Заодно можно узнать о существовании целого ряда готовых RTOS для MK.A3IPIB Автор
01.08.2021 12:26+1OS – это программная прослойка, позволяющая реализовать псевдо многопоточность
Да, именно прослойка. Прослойка между аппаратным обеспечением микроконтроллера и кодом, выполняющимся в рантайме. Прослойка, которая позволяет объединить эти две части и реализовать псевдо многопоточность. Все верно. Если мое определение отличается от данного в вашем фундаментальном труде - это не значит что я не понимаю что это и как работает.
Вот простите меня пожалуйста. Вы же сами посмеиваетесь над своим поспешным подходом. Но любой человек (да и не человек тоже), который собирается писать ОС, должен сначала понимать что это такое.
Я думаю, было бы полезнее, если бы была конкретная претензия ко мне, что я сделал не так. Вместо того, чтобы цепляться за мое определение, лучше укажите на то, где я допустил ошибку в проекте, что реализовал не так. Я буду рад если будет такое замечание.
сначала понимать что это такое
Я так понимаю, мое определение повлекло за собой ошибки в реализации. Если это так - укажите какие именно. Иначе - вы подтверждаете что не повлекло, и тогда я не понимаю вашу претензию.
Если я прочту этот фундаментальный труд, и изменю слова в определении - что-то изменится?
Если два человека знают как работает что-либо, и они объясняют это своими словами - в этом нет ничего плохого.
Заодно можно узнать о существовании целого ряда готовых RTOS для MK.
Я знаю ряд готовых RTOS для МК. Это не отвернуло меня от создания своей.
Опять же "зачем делать то, что уже сделано до нас?" - затем же, зачем учиться играть на муз инструменте и писать свою музыку.

COKPOWEHEU
01.08.2021 11:29Тоже делал подобную штуку в свое время. Правда, дошел только до переключения задач, поскольку не смог придумать как продемонстрировать его работу неспециалисту. В частности как одна задача будет запускать другую, как они будут работать с памятью и т.д. Просто архитектура AVR для этого не очень-то предназначена: и всей оперативки мало, и инструкций косвенного доступа не хватает. Так что полноценную ОС на ней не написать.
А вот на ARM было бы интереснее. Там и работа относительно базового адреса имеется, и даже выполнение из оперативки, так что задачи можно вообще на лету подгружать.A3IPIB Автор
01.08.2021 12:36полноценную ОС на ней не написать
Для начала нужно определиться что такое полноценная ОС, чтобы понимать до каких требований нужно дотянуться, собственно это и есть ТЗ. Конечно, если брать FreeRTOS как полноценную, то она просто не влезет, т.к. занимает килобайты. Но там много фич, от которых можно отказаться.
и инструкций косвенного доступа не хватает
Ну так регистровые пары XYZ есть, по памяти ходить можем, мне хватает)
А вообще на AVR невозможно сделать полноценную ОС только из-за того, что нет ничего для проверки переполнения стека. Ни прерываний, ни ловушек.
на ARM было бы интереснее
Как раз таки на AVR интереснее, т.к. там ничего нет. Хотя, у каждого свои интересы...
Сделал бы ОС для ARM - вместо вопросов "а зачем тебе ОС на AVR?" были бы "а зачем тебе такая слабая ОС на ARM"?
COKPOWEHEU
02.08.2021 10:09+1Для начала нужно определиться что такое полноценная ОС
Ну, моя цель была навелосипедить ОС, аналогичную десктопным, то есть чтобы и процессы на лету запускать, и подгружать откуда-то, и разграничение доступа обеспечить. И потом похвастаться «компьютером» на контроллере.Ну так регистровые пары XYZ есть
Вроде команда ldd r, Y+2 не везде поддерживается, а без нее любой доступ к локальным переменным превращается в издевательство над адресным регистром.А вообще на AVR невозможно сделать полноценную ОС только из-за того, что нет ничего для проверки переполнения стека.
Лучше сказать более общо — нет механизма защиты памяти.Как раз таки на AVR интереснее, т.к. там ничего нет.
Некоторые аппаратные вещи все-таки необходимы. Ну, скажем, без прерываний не реализовать планировщик. Без выполнения кода из ОЗУ не реализовать по-человечески загрузку с внешнего носителя.Сделал бы ОС для ARM — вместо вопросов «а зачем тебе ОС на AVR?» были бы «а зачем тебе такая слабая ОС на ARM»?
Пф-ф-ф, тем, кто не понимает зачем вообще нужно велосипедостроение, вряд ли можно это объяснить.

Indemsys
01.08.2021 12:26Своя ось может быть чревата серьезными последствиями.
Если вы как разработчик поступательно будете осваивать все более сложные и перспективные платформы, то от своей оси придется отказаться.
Но отказаться будет трудно, жалко же потраченных сил.
Это приведет к фрустрации и конфликтам с заказчиками.Какая ни была бы ось она требует поддержки. Например при ее модификациях нужно всегда думать об обратной совместимости, нужно делать порты, нужно также создавать и апгрейдить документацию, нужно делать переходные слои для чужого API сервисов реального времени и т.д. и т.п.
В сети масса исходников заточенных под mbed, uCOS-II , Azure RTOS, Zephyr RTOS, MQX ...
Своя ось исключает их из вашего круга интересов. Вернее вы будете их рассматривать только для того чтобы объяснить себе почему они вам не подходят. Это психологическая ловушка.
На самом деле любая из перечисленных может быть запущена на Cortex-M0. Любая из них справиться с тем же что и собственная. У них разница только в глубине и охвате поддержки.
Вот эту глубину и охват и следует изучать. В каких-то из них гораздо подробнее описано как на самом деле работают RTOS и переключатели контекста, в каких-то гораздо больше примеров применения, в каких-то гораздо точнее приведены тайминги и реальный цифры быстродействия, какие-то снабжены уникальными функциями трассировки системных вызовов и контролем переполнения стека и т.д.
И вот вместо изучения всего этого богатства вы пилите свою ось.A3IPIB Автор
01.08.2021 13:15+1Своя ось может быть чревата серьезными последствиями. Если вы как разработчик поступательно будете осваивать все более сложные и перспективные платформы, то от своей оси придется отказаться. Но отказаться будет трудно, жалко же потраченных сил.
Я нигде не писал, что я буду использовать ее в своей работе. Это домашний проект для изучения темы. Не более.
И вот вместо изучения всего этого богатства вы пилите свою ось.
И вот вместо того, чтобы писать на пайтоне, люди пишут на Си.
Я пилю свою ось, т.к. это моя профессия, и в то же время хобби.
Да и все известные сейчас ОС начинались с таких шагов. Разве нет?

abondarev
01.08.2021 13:14+1Согласен с тезисом о том что эффективным путем освоения архитектуры ОС является разработка ОС. Но с другой стороны можно взять готовую ОС например тот же Minix, и модифицируя ее понять как она работает. Кроме того вы смешиваете конкретный микроконтроллер и архитектуру ОС. Вот у нас есть статья про планировщик https://habr.com/ru/company/embox/blog/219431/ да там есть некоторая привязка к нашему проекту, но сделано это только для того чтобы любой смог сразу воспроизвести все примеры описанные в статье. А привязываться к конкретной архитетуре при изучении принципов планирования, это не очень хорошо. Это отдельная тема вот например по поводу особенностей для ARM Cortex-m https://habr.com/ru/company/embox/blog/330236/
A3IPIB Автор
01.08.2021 13:26Но с другой стороны можно взять готовую ОС например тот же Minix, и модифицируя ее понять как она работает.
Можно, но когда изучаешь что-то, разбирая уже готовое - ты можешь упустить многие нюансы, приняв мысли другого автора за чистую монету, даже не подумав "а почему именно так". А когда "переживешь" этот момент - будешь глубже это все понимать.
Кроме того вы смешиваете конкретный микроконтроллер и архитектуру ОС.
Как раз AVR не имеет ничего такого в своей архитектуре, чтобы ОС получилась исключительно для AVR. В них есть только стек и таймер, что есть во всех микроконтроллерах без исключения. А вот если писать сразу на ARM, то там и отдельный таймер для ОС есть, и аппаратные приблуды для стека, и т.д. Что и наложит свой отпечаток на ОС.
Портировать эту ОС на любую архитектуру - без проблем, а вот ОС для ARM обратно - уже будут проблемы.
Единственное влияние архитектуры, которое я здесь зацепил, это сохранение регистра "SREG" в контекст задачи. Содержимое контекста в принципе будет разным для каждой архитектуры. Банально количество регистров общего назначения будет отличаться.
А привязываться к конкретной архитетуре при изучении принципов планирования, это не очень хорошо.
Про планировщик это была скорее шутка, если привязка планировщика к архитектуре это: "не делать алгоритм планирования", то это не похоже на привязку XD
abondarev
01.08.2021 13:49разбирая уже готовое - ты можешь упустить многие нюансы, приняв мысли другого автора за чистую монету, даже не подумав "а почему именно так". А когда "переживешь" этот момент - будешь глубже это все понимать.
Не нужно конечно принимать за чистую монету, нужно мыслить критически. Если вы приходите к тем же выводам что и многие до вас, то все в порядке, если нет, то вполне возможно вы что то упустили, или вы увидели другой путь или не стыковки. Собственно так и происходит развитие.
Если же писать самому, то можно за чистую монету принять как раз свои фантазииили частный случай работы и упустить много важных деталей.А вот если писать сразу на ARM
Ни в коем случае не предлагал писать под ARM или другую архитектуру. Посмотрите первую ссылку, там ни слово о регистрах. А у вас naked аттрибут не работает, ассемблер, а давайте первый раз выйдем из прерывания и так далее.
A3IPIB Автор
01.08.2021 14:55А у вас naked аттрибут не работает, ассемблер, а давайте первый раз выйдем из прерывания и так далее.
Я здесь не уловил мысль...
Что значит "у вас naked не работает"?
"Ассемблер" - а как переключить контекст без ассемблера?
"а давайте первый раз выйдем из прерывания и так далее" - можно подробнее, чтобы я понял, как ответить на вопрос?
abondarev
01.08.2021 15:04Не обязательно отвечать на вопросы. Я лишь высказал мнение, что у вас в статье смешаны архитектурные с точки зрения ПО части и архитектурные для CPU части. Например, у вас описано что первое переключение контекста отличается от последующих, но ведь чтобы этого избежать достаточно добавить понятие инициализация контекста.
А в целом хорошая работа, продолжайте!
A3IPIB Автор
01.08.2021 16:31Не обязательно отвечать на вопросы.
Не обязательно, но желательно, чтобы расставить все точки. Если есть в комментариях замечания, вопросы и т.п. Или я вижу, что меня поняли не так, как я это планировал - я лучше отвечу.
первое переключение контекста отличается от последующих, но ведь чтобы этого избежать достаточно добавить понятие инициализация контекста
Согласен, не подумал вынести это в отдельный термин. Может позже исправлю.
Но в варианте, который я принял в итоге (решение 3) это и не требуется.
abondarev
01.08.2021 16:58У Вас написано что Решение 3, одни плюсы, ну разве что не эстетично. На самом деле, объясните себе как вызвать перепланирование не из прерывания? Ну например поток в sleep ушел или ждет чего то?
Я уж не говорю, о том что функция contex_switch вообще то возвращается в тоже место, но только при возврате в этот же поток.
Я еще раз повторюсь Вы проделали хорошую работу и я не пытаюсь ее критиковать. Я просто обращаю внимание, что когда вы учитесь сразу на собственной ОС, вы сильно сужаете проблематику и не видете очень многих действительно важных моментов. И я предложил только начать с базовой теории в отрыве от конкретной задачи и процессора. Возможно сейчас с полученным опытом прочтение Таненбаума принисет очень хороший результат :)

Roman_Cherkasov
01.08.2021 13:15+2Искренне не понимаю людей которые пишут - своя ОС отстой, есть куча готовых. Автор же написал, что пишет свою ос в обучающих целях. Чтобы самому научиться, даже не кого-то научить и тем более не использовать в проде.
Indemsys
01.08.2021 13:40-2Ну так можно же учиться про себя тихо и не пиариться.
А раз пиариться, то добро пожаловать в мир конкуренции.
Для себя ли или не для себя, но когда почувствуете холодок бесполезности своего труда, то будет некомфортно. Тут конкуренция в плюс, поскольку может вовремя дать сигнал остановиться.
Еще один минус самописаной оси - самобытная терминология.
Эт тож сильный барьер в приобщения к лучшим практикам.
К примеру что это - "текущая задача"? Есть термин "активная задача", но она может быть вовсе не текущей в смысле исполняемой в данный момент.Да и речь не идет о том что автору выбрать, а о том как автору эффективней учиться.
И всего лишь.A3IPIB Автор
01.08.2021 14:46+1Ну так можно же учиться про себя тихо и не пиариться.
При чем здесь пиар?
В самом начале статьи написано, для чего я ее опубликовал.
Я был бы рад увидеть такую статью, когда сам начал, но не нашел, и написал ее сам, чтобы такие как я могли ее прочитать.
Indemsys
01.08.2021 15:38Как правильный и быстрый путь для начинающих я бы советовал переписать или отрефакторить уже готовую ось и лучше не одну.
A3IPIB Автор
01.08.2021 16:43+1Только разрабатывая все с нуля можно ощутить весь спектр приятных ощущений от вопросов, которые ты должен решить. И этот путь позволит глубже разобраться.
Рефакторинг чужой ОС даст только ответ на вопрос "как это работает".
А между "знаю как работает" и "могу это сделать" огромная пропасть.
Ark_V
А как она поработает если вы ее из процессора в стек выгрузили?
Должно ж быть "я восстанавливаю контекст" и уже восстановленный запустить в работу, не?
"последняя", "следующая" - это понятно, а зачем тут "текущая" непонятно. Более понятно восстановление контекста выбранной не предыдущем этапе т.е. "следующей задачи", а не понятно откуда взявшейся (явно не проговоренной) "текущей".
A3IPIB Автор
Та я уже уставший был когда публиковал, и картинку на скорую руку сделал, тольк опотом сообразил)
Отредактировать не мог, пока статью не опубликовали. Вот, опубликовали - сейчас и исправлю)
И спойлеры подправлю, т.к. в них нет названий...
Последнюю мы вытеснили, выбираем следующую, и она становится текущей)
Все понятно)