If you use Zabbix to monitor your infrastructure objects but have not previously thought about collecting and storing logs from these objects then this article is for you.

Why collect logs and store them? Who needs it?
Logging or, as they say, recording logs allows you to give answers to questions, what? where? and under what circumstances happened in your IT environment several hours, days, months, even years ago. A constantly appearing error is difficult to localize, even knowing when and under what circumstances it manifests itself, without having logs in hand. In the logs not only generic information about the occurrence of certain errors is written but also more detailed information about the errors that helps to understand the causes of these occurrences.
After you have launched your product and expect results from it, you need to constantly monitor the operation of the product in order to prevent failures before users can see them.
And how to analyze causes of failures of a server whose logs are no longer available (an intruder covering up the traces or any other force majeure circumstances)? - Only centralized storage of logs will help in this case.
If you are a software developer and for debugging you have to “walk” through and look at all the logs on the server then convenient viewing, analysis, filtering and search of logs in the web interface will simplify your actions and you will be able to concentrate more on the task of debugging your code.
Analysis of logs helps to identify conflicts in the configuration of services, to determine the source of occurrence of errors, as well as to detect information security alerts.
Together with monitoring services, logging helps to significantly save engineers' time when investigating certain incidents.
Great variety of solutions for recording logs
The advantages and disadvantages of popular solutions for collecting logs have already been described elsewhere (in russian). Our colleagues analyzed systems such as Splunk, Graylog, and ELK. They revealed good and not so good (of course, for themselves) sides in the presented solutions. To summarize their experience:
ELK turned out to be too cumbersome, resource-intensive, and very difficult to configure on large infrastructures.
Splunk lost users’ trust by simply leaving the Russian market without giving any reason. Splunk partners and customers in Russia had to find new solutions after the expiration of their quite expensive Splunk licenses.
The authors opted for Graylog and in their article give examples of installing and configuring this product.
The article has not described a number of systems such as Humio, Loki, and Monq. But since Humio is a paid SaaS service, and Loki is a very simple log aggregator without parsing, enrichment and other useful features, we will consider only Monq. Monq is a whole set of components for support of IT infrastructure, which includes AIOps, automation, hybrid and umbrella monitoring, but today we are only interested in Monq Collector which is a free tool for collecting and analyzing logs.
Logs plus infrastructure monitoring
One of the features of this tool for working with logs is the ability to process the incoming data stream on the preprocessor using scripts and parsers that you create yourself, in the built-in Lua IDE.
Another distinguishing feature is the product architecture. The product is built upon microservices. And the storage of those very logs is implemented in the columnar analytical DBMS ClickHouse.
The key advantage of ClickHouse is the high speed of execution of SQL read queries (OLAP script), which is provided due to the following distinctive features:
vector computing,
parallelization of operations,
column data storage,
support for approximate calculations,
physical sorting of data by primary key.
But one of the most important features of ClickHouse is a very efficient saving of storage space. The average compression ratio is 1:20 which is a very good number.
If you paid attention to the title of this article you would notice that initially we wanted to tell you what is good about using monq in companies where Zabbix is used as an infrastructure monitoring system.
Firstly, the product for collecting and analyzing logs is provided absolutely free of charge and without any restrictions on traffic and time.
Secondly, the monq Collector includes a built-in connector with Zabbix, which allows you to receive all events from Zabbix triggers and then view them on the same screen with the logs. To receive events from Zabbix and other systems such as Nagios, Prometheus, SCOM, Ntopng, system handlers are provided with the ability to customize the code or write your own handlers.
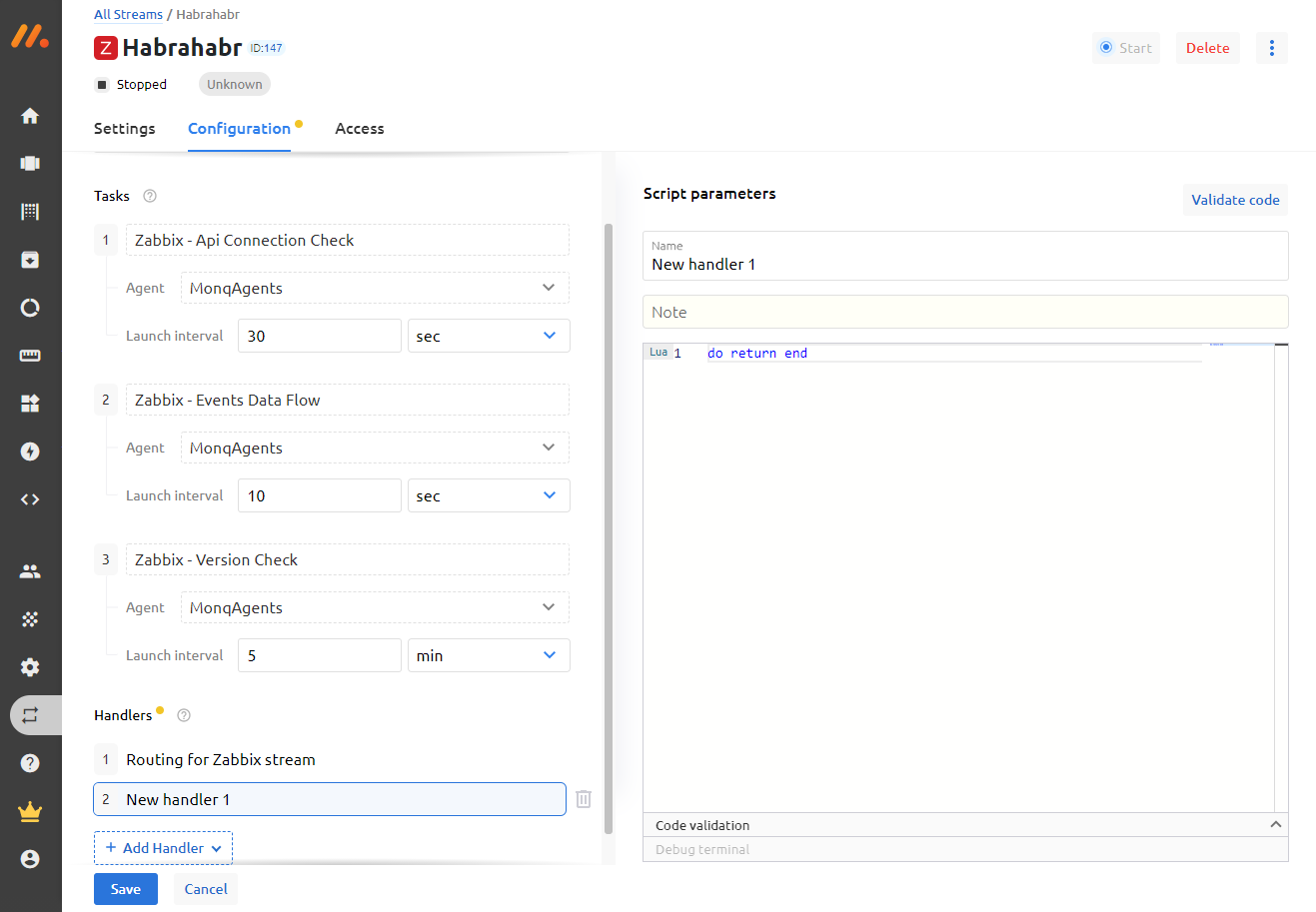
For example, you can convert the date format to your liking:
function is_array(t)
local i = 0
for _ in pairs(t) do
i = i + 1
if t[i] == nil then return false end
end
return true
end
function convert_date_time(date_string)
local pattern = "(%d+)%-(%d+)%-(%d+)(%a)(%d+)%:(%d+)%:([%d%.]+)([Z%p])(%d*)%:?(%d*)";
local xyear, xmonth, xday, xdelimit, xhour, xminute, xseconds, xoffset, xoffsethour, xoffsetmin
xyear, xmonth, xday, xdelimit, xhour, xminute, xseconds, xoffset, xoffsethour, xoffsetmin = string.match(date_string,pattern)
return string.format("%s-%s-%s%s%s:%s:%s%s", xyear, xmonth, xday, xdelimit, xhour, xminute, string.sub(xseconds, 1, 8), xoffset)
end
function alerts_parse(result_alerts, source_json)
for key, alert in pairs(source_json.alerts) do
alert["startsAt"]=convert_date_time(alert["startsAt"])
alert["endsAt"]=convert_date_time(alert["endsAt"])
result_alerts[#result_alerts+1]=alert
end
end
local sources_json = json.decode(source)
result_alerts = {};
if (is_array(sources_json)) then
for key, source_json in pairs(sources_json) do
alerts_parse(result_alerts, source_json)
end
else
alerts_parse(result_alerts, sources_json)
end
next_step(json.encode(result_alerts))
Thirdly, if you install the trial version or the paid add-on monq AIOps, then a number of native features connecting Zabbix and monq would appear that allow you to:
bind Zabbix nodes and triggers to resource-service model in monq,
automatically create in monq correlation rules (synthetic triggers) with preset filters and rules for events coming from Zabbix,
work with low level discovery (LLD) in Zabbix.
Synthetic triggers allow you to handle any event that goes into the monq monitoring system. It is possible to create triggers from templates or customize them from scratch using scripts written in the Lua language in the IDE editor built into the web interface.
Using the Zabbix connector in monq, you can import the entire infrastructure and build a resource-service model of your whole information system. This is convenient when you need to quickly localize the problem and find the cause of the incident.
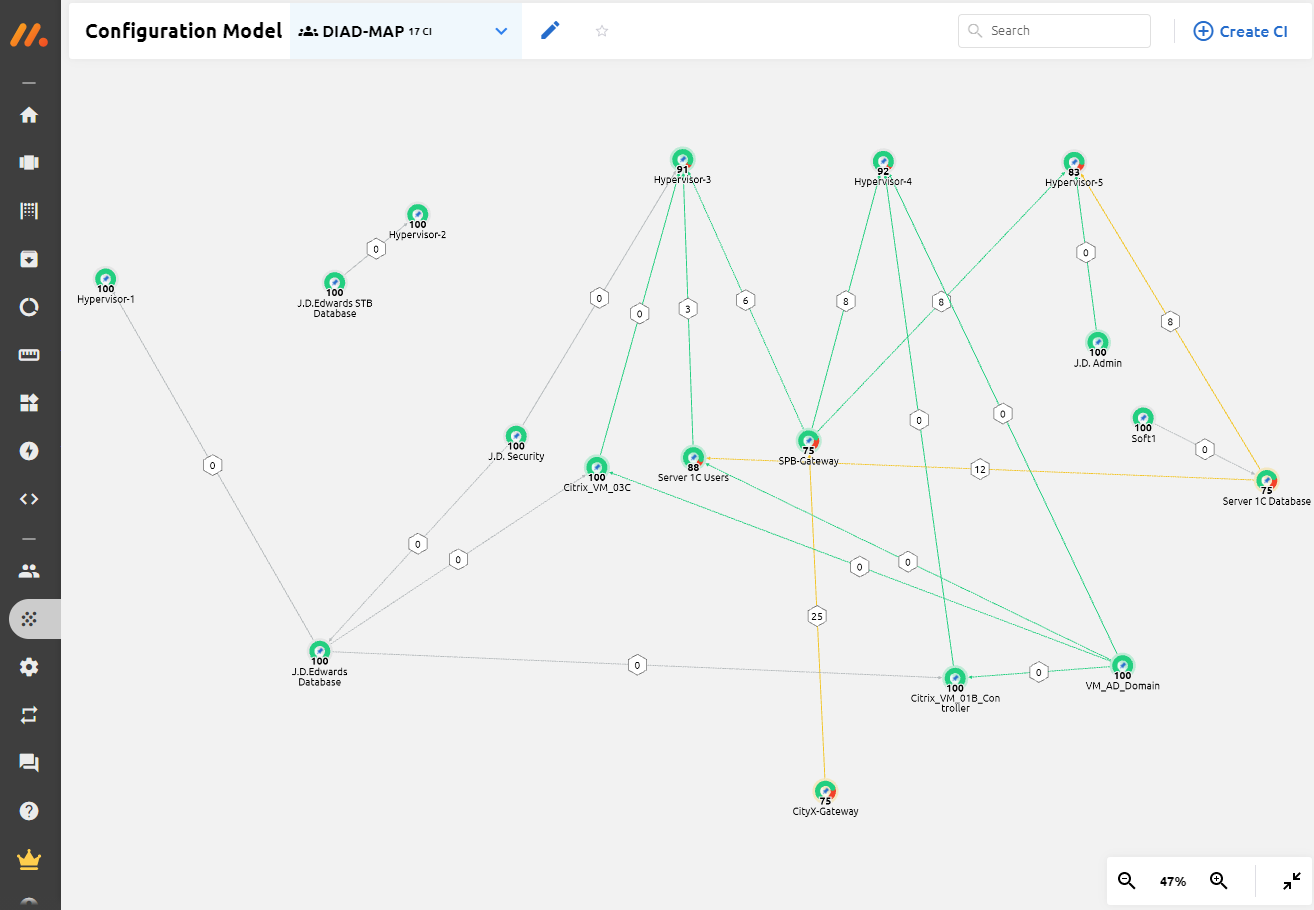
The question is brewing, is it possible to differentiate access to logs to certain categories of persons? For example, so that information security logs are available only to sysadmins? The answer is yes, it’s possible.
To do this monq Collector has a very flexible role model for workgroups built in. System users can simultaneously have different roles in different workgroups. When connecting a data stream one can allow read or write access to certain roles and assign those roles to users.
How does this help in collecting logs?
Let's try to describe a small fictional use case. We have a cluster running Kubernetes. There are several rented virtual machines. All nodes are monitored using Zabbix. And there is an authorization service which is very important for us since several corporate services work through it.
Zabbix periodically reports that the authorization service is unavailable, then it is available again in a minute or two. We want to find the reason for the drop in service and not flinch from every alert sound from the phone.
Zabbix is an excellent monitoring tool but it is not enough for investigating incidents. Errors can often be found in the logs. And for this we will collect and analyze logs with the monq Collector.
So, in order:
1. We configure collection of logs from the nginx-ingress controller which is located in the cluster running Kubernetes. In this case, we will transfer logs to the collector using the fluent-bit utility. Here are the listings of configuration files:
[INPUT]
Name tail
Tag nginx-ingress.*
Path /var/log/containers/nginx*.log
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 10MB
Skip_Long_Lines On
Refresh_Interval 10
Let's prepare parsers for nginx to convert raw data to JSON:
[PARSER]
Name nginx
Format regex
Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
....
[PARSER]
Name nginx-upstream
Format regex
Regex ^(?<remote>.*) \- \[(?<realip>.*)\] \- (?<user>.*) \[(?<time>[^\]]*)\] "(?:(?<method>\S+[^\"])(?: +(?<path>[^\"]*?)(?: +(?<protocol>\S*))?)?)?" (?<code>[^
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name nginx-error
Format regex
Regex ^(?<time>\d{4}\/\d{2}\/\d{2} \d{2}:\d{2}:\d{2}) \[(?<log_level>\w+)\] (?<pid>\d+).(?<tid>\d+): (?<message>.*), client: (?<client>.*), server: (?<server>.*)
Time_Key time
Time_Format %Y/%m/%d %H:%M:%S
2. We also send logs to the collector using fluent-bit (monk collector will have its own extractor in August, I will write about it later)
[OUTPUT]
Name http
Host monq.example.ru
Match *
URI /api/public/cl/v1/stream-data
Header x-smon-stream-key 06697f2c-2d23-45eb-b067-aeb49ff7591d
Header Content-Type application/x-ndjson
Format json_lines
Json_date_key @timestamp
Json_date_format iso8601
allow_duplicated_headers false
3. Infrastructure objects are monitored in Zabbix with parallel streaming of logs in monq.
4. Some time passes and an event from Zabbix comes to monq stating that the authentication service is not available.
5. Why? What happened? We open the monq primary events screen, and there is already a flurry of events from nginx-ingress-controller:
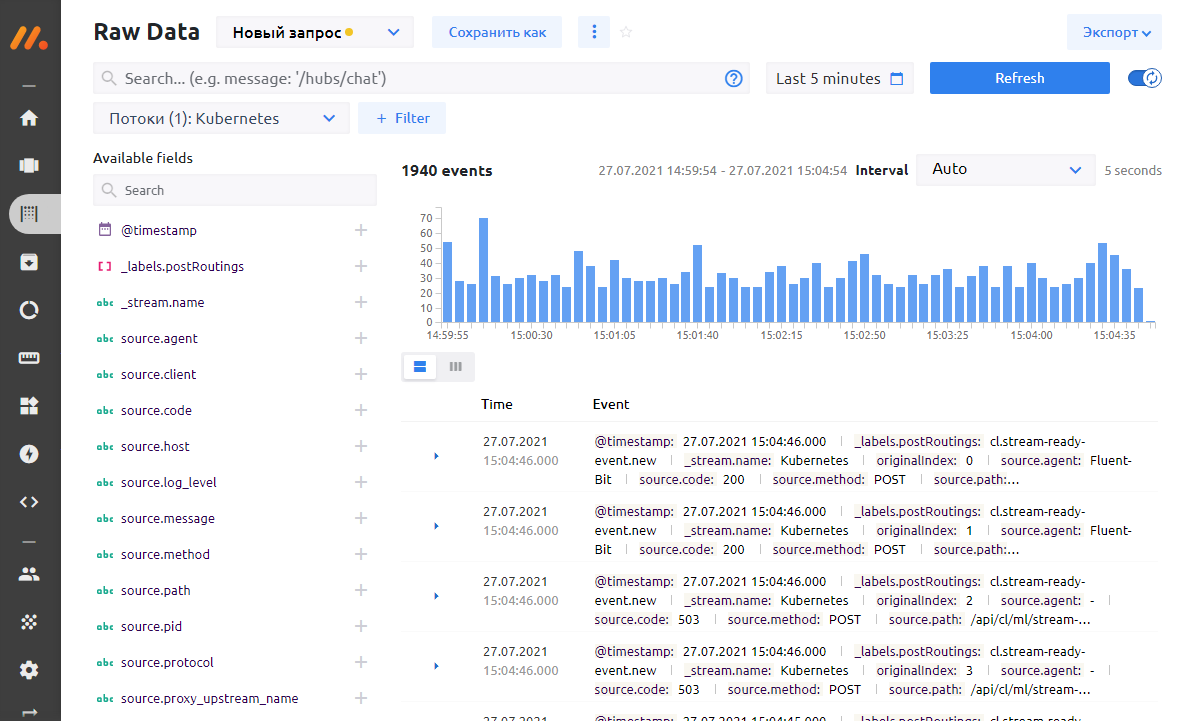
6. Using the analytical tools of the primary screen, we find out that we have a 503 error - in 30 minutes there are already 598 records with this errors, or 31.31% of the total number of logs from the nginx-ingress controller:
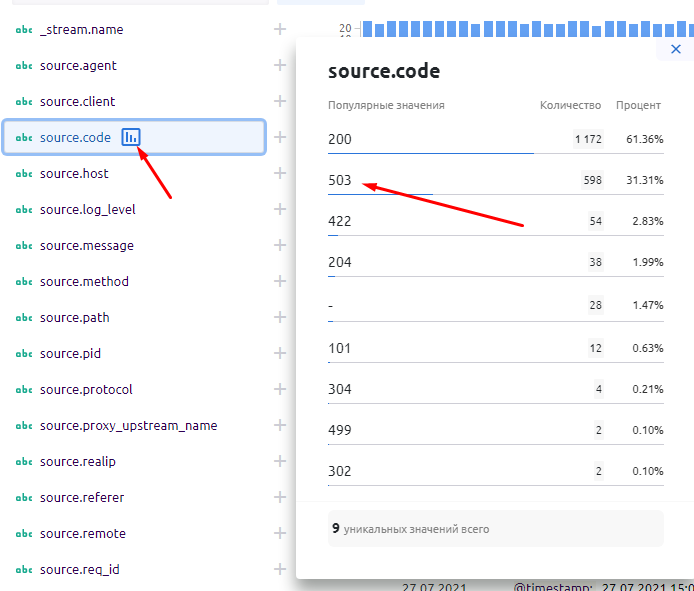
7. From the same window we can filter events by clicking on the error value and selecting “add to filter”. As a result, “the source.code = 503” parameter will be added to the filter panel. Excessive log data will be removed from the screen.
8. We turn to the analysis of structured logs and see at which URL the error is returned, understand which microservice is failing and quickly solve the problem by recreating the container:

9. For the future, we start collecting logs from this container in monq, and next time we know much more information about the problem that can be passed on to developers to fix the code.
The use case that I gave above is more of a demonstration of general principles. In life, things are often not so obvious. Here’s an example from our practice.
Year 2019. We were developing a system in which there are 50+ containers. In each release, our release master spent a lot of time figuring out why inter-microservice connections could break. Moving between microservices and logs, each time typing kubectl get log, in one window, the same thing in the second window, then in the third. And you also needed to tail the web server logs. Then you had to remember what was in the first window, etc. Also the team was growing, did you have to give everyone access via ssh to the server? No, you opted for an aggregator.
We set up sending logs to ELK, collected everything that was needed, and then something happened. In ELK, each event source uses its own index and this is very inconvenient. The team kept growing, outsourcers appeared, we realized that we need to differentiate the rights of working groups. The number of logs began to grow strongly, some sort of clustering of the database by its own means began to be needed, without the use of a tambourine, a highload was needed. In ELK, for all these functions you have to pay. Instead we decided to switch to the monq Collector for collecting logs.
Year 2021. A regular release, everything rolled out, Kuber launched containers, Zabbix sends alarms that authorization does not work. We go to the monq Collector screen, parse the fields, and see where the problem is. We see from the logs that the problem started at a certain time, after the rollout of a particular container. The problem was solved quickly and easily, and this is on a volume of more than 200 GB of logs per day with more than 30 people working with the storage system.