
К старту флагманского курса по Data Science делимся сокращённым переводом из блога RealPython о трюках с Pandas, материал начинается с конфигурирования запуска библиотеки и заканчиваются примерами работы с операторами и их приоритетом. Затрагивается тема экономии памяти, сжатие фреймов, интроспекция GroupBy через итерацию и другие темы. Подробности, как всегда, под катом.
1. Параметры запуска интерпретатора
Возможно, вы сталкивались с богатыми опциями и настройками системы Pandas. Установка настраиваемых параметров Pandas при запуске интерпретатора значительно снижает производительность, особенно при работе в среде сценариев. Можно воспользоваться pd.set_option() для настройки по своему усмотрению с помощью Python или в файле запуска IPython. Параметры используют точечную нотацию: pd.set_option ('display.max_colwidth', 25), которая хорошо подходит для вложенного словаря параметров:
Код
import pandas as pd
def start():
options = {
'display': {
'max_columns': None,
'max_colwidth': 25,
'expand_frame_repr': False, # Don't wrap to multiple pages
'max_rows': 14,
'max_seq_items': 50, # Max length of printed sequence
'precision': 4,
'show_dimensions': False
},
'mode': {
'chained_assignment': None # Controls SettingWithCopyWarning
}
}
for category, option in options.items():
for op, value in option.items():
pd.set_option(f'{category}.{op}', value) # Python 3.6+
if __name__ == '__main__':
start()
del start # Clean up namespace in the interpreterЗапустив сеанс интерпретатора, вы увидите, что сценарий запуска выполнен и Pandas автоматически импортируется с вашим набором опций:
Код и вывод
>>> pd.__name__
'pandas'
>>> pd.get_option('display.max_rows')
14Воспользуемся данными abalone в репозитории машинного обучения UCI, чтобы продемонстрировать заданное в файле запуска форматирование. Сократим данные до 14 строк с точностью до 4 цифр для чисел с плавающей точкой:
Код и вывод
url = ('https://archive.ics.uci.edu/ml/'
... 'machine-learning-databases/abalone/abalone.data')
>>> cols = ['sex', 'length', 'diam', 'height', 'weight', 'rings']
>>> abalone = pd.read_csv(url, usecols=[0, 1, 2, 3, 4, 8], names=cols)
>>> abalone
sex length diam height weight rings
0 M 0.455 0.365 0.095 0.5140 15
1 M 0.350 0.265 0.090 0.2255 7
2 F 0.530 0.420 0.135 0.6770 9
3 M 0.440 0.365 0.125 0.5160 10
4 I 0.330 0.255 0.080 0.2050 7
5 I 0.425 0.300 0.095 0.3515 8
6 F 0.530 0.415 0.150 0.7775 20
# ...
4170 M 0.550 0.430 0.130 0.8395 10
4171 M 0.560 0.430 0.155 0.8675 8
4172 F 0.565 0.450 0.165 0.8870 11
4173 M 0.590 0.440 0.135 0.9660 10
4174 M 0.600 0.475 0.205 1.1760 9
4175 F 0.625 0.485 0.150 1.0945 10
4176 M 0.710 0.555 0.195 1.9485 12Позже вы увидите этот набор данных и в других примерах.
2. Игрушечные cтруктуры данных с помощью модуля тестирования Pandas
Модуль
pandas.util.testingбыл удалён в Pandas 1.0. Публичный API для тестирования изpandas.testingтеперь ограниченassert_extension_array_equal(),assert_frame_equal(),assert_series_equal()иassert_index_equal(). Автор признаёт, что узнал вкус своего лекарства за то, что полагался на недокументированные части библиотеки Pandas.
В модуле Pandas testing скрыт ряд удобных функций для быстрого построения квазиреалистичных Series и фреймов данных:
Код и вывод
>>> import pandas.util.testing as tm
>>> tm.N, tm.K = 15, 3 # Module-level default rows/columns
>>> import numpy as np
>>> np.random.seed(444)
>>> tm.makeTimeDataFrame(freq='M').head()
A B C
2000-01-31 0.3574 -0.8804 0.2669
2000-02-29 0.3775 0.1526 -0.4803
2000-03-31 1.3823 0.2503 0.3008
2000-04-30 1.1755 0.0785 -0.1791
2000-05-31 -0.9393 -0.9039 1.1837
>>> tm.makeDataFrame().head()
A B C
nTLGGTiRHF -0.6228 0.6459 0.1251
WPBRn9jtsR -0.3187 -0.8091 1.1501
7B3wWfvuDA -1.9872 -1.0795 0.2987
yJ0BTjehH1 0.8802 0.7403 -1.2154
0luaYUYvy1 -0.9320 1.2912 -0.2907Их около 30, полный список можно увидеть, вызвав dir() на объекте модуля. Вот несколько вариантов:
Код и вывод
>>> [i for i in dir(tm) if i.startswith('make')]
['makeBoolIndex',
'makeCategoricalIndex',
'makeCustomDataframe',
'makeCustomIndex',
# ...,
'makeTimeSeries',
'makeTimedeltaIndex',
'makeUIntIndex',
'makeUnicodeIndex']Они полезны для бенчмаркинга, тестирования утверждений и экспериментов с не очень хорошо знакомыми методами Pandas.
3. Используйте преимущества методов доступа
Возможно, вы слышали о термине акcессор, который чем-то напоминает геттер (хотя геттеры и сеттеры используются в Python нечасто). В нашей статье будем называть аксессором свойство, которое служит интерфейсом для дополнительных методов. В Series [на момент написания оригинальной статьи] их три, сегодня их 4:
Код и вывод
>>> pd.Series._accessors
{'cat', 'dt', 'sparse', 'str'}Да, приведённое выше определение многозначно, поэтому до обсуждения внутреннего устройства посмотрим на примеры.
.cat— для категориальных данных;.str— для строковых (объектных) данных;.dt— для данных, подобных времени.
Начнём с .str: представьте, что у вас есть необработанные данные о городе/области/индексе в виде одного поля в Series Pandas. Строковые методы Pandas векторизованы, то есть работают со всем массивом без явного цикла for:
Код и вывод
>>> addr = pd.Series([
... 'Washington, D.C. 20003',
... 'Brooklyn, NY 11211-1755',
... 'Omaha, NE 68154',
... 'Pittsburgh, PA 15211'
... ])
>>> addr.str.upper()
0 WASHINGTON, D.C. 20003
1 BROOKLYN, NY 11211-1755
2 OMAHA, NE 68154
3 PITTSBURGH, PA 15211
dtype: object
>>> addr.str.count(r'\d') # 5 or 9-digit zip?
0 5
1 9
2 5
3 5
dtype: int64Для примера сложнее предположим, что вы хотите разделить три компонента city/state/ZIP аккуратно на поля фрейма данных. Вы можете передать регулярное выражение в .str.extract(), чтобы «извлечь» части каждой ячейки в Series. В .str.extract(), .str — это аксессор, а .str.extract() — метод аксессора:
Код и вывод
>>> regex = (r'(?P<city>[A-Za-z ]+), ' # One or more letters
... r'(?P<state>[A-Z]{2}) ' # 2 capital letters
... r'(?P<zip>\d{5}(?:-\d{4})?)') # Optional 4-digit extension
...
>>> addr.str.replace('.', '').str.extract(regex)
city state zip
0 Washington DC 20003
1 Brooklyn NY 11211-1755
2 Omaha NE 68154
3 Pittsburgh PA 15211Код иллюстрирует цепочку методов, где .str.extract (regex) вызывается на результате addr.str.replace ('.', ''), который очищает использование точек, чтобы получить красивую двухсимвольную аббревиатуру штата. Полезно немного знать о том, как работают эти методы-аксессоры, чтобы понимать, почему нужно использовать их, а не что-то вроде addr.apply (re.findall, …). Каждый аксессор — это класс Python:
.strотображается наStringMethods..dtотображается наCombinedDatetimelikeProperties..cat— наCategoricalAccessor.
Эти отдельные классы затем «прикрепляются» к Series с помощью CachedAccessor. Именно когда классы обёрнуты в CachedAccessor, происходит магия.
CachedAccessor вдохновлён конструкцией «кэшированного свойства»: свойство вычисляется только один раз для каждого экземпляра, а затем заменяется обычным атрибутом. Это происходит путём перегрузки метода .__get__(), который является частью протокола дескриптора Python.
Если вы хотите прочитать больше о работе дескрипторов, смотрите Descriptor HOWTO и этот пост о дизайне кэшированных свойств. В Python 3 также появился
functools.lru_cache(), предлагающий аналогичную функциональность. Паттерн можно найти повсюду, например в пакетеaiohttp.
Второй аксессор, .dt, предназначен для данных о времени. Технически он принадлежит к DatetimeIndex Pandas, и если его вызывать для Series, то сначала он преобразуется в DatetimeIndex:
Код и вывод
>>> daterng = pd.Series(pd.date_range('2017', periods=9, freq='Q'))
>>> daterng
0 2017-03-31
1 2017-06-30
2 2017-09-30
3 2017-12-31
4 2018-03-31
5 2018-06-30
6 2018-09-30
7 2018-12-31
8 2019-03-31
dtype: datetime64[ns]
>>> daterng.dt.day_name()
0 Friday
1 Friday
2 Saturday
3 Sunday
4 Saturday
5 Saturday
6 Sunday
7 Monday
8 Sunday
dtype: object
>>> # Second-half of year only
>>> daterng[daterng.dt.quarter > 2]
2 2017-09-30
3 2017-12-31
6 2018-09-30
7 2018-12-31
dtype: datetime64[ns]
>>> daterng[daterng.dt.is_year_end]
3 2017-12-31
7 2018-12-31
dtype: datetime64[ns]Третий аксессор, .cat, — только для категориальных данных, которые вы вскоре увидите в отдельном разделе.
4. Создание индекса времени даты из столбцов компонентов
Если говорить о данных, подобных времени, как в daterng, можно создать Pandas DatetimeIndex из нескольких компонентных столбцов, вместе эти столбцы образуют дату или время:
Код и вывод
>>> from itertools import product
>>> datecols = ['year', 'month', 'day']
>>> df = pd.DataFrame(list(product([2017, 2016], [1, 2], [1, 2, 3])),
... columns=datecols)
>>> df['data'] = np.random.randn(len(df))
>>> df
year month day data
0 2017 1 1 -0.0767
1 2017 1 2 -1.2798
2 2017 1 3 0.4032
3 2017 2 1 1.2377
4 2017 2 2 -0.2060
5 2017 2 3 0.6187
6 2016 1 1 2.3786
7 2016 1 2 -0.4730
8 2016 1 3 -2.1505
9 2016 2 1 -0.6340
10 2016 2 2 0.7964
11 2016 2 3 0.0005
>>> df.index = pd.to_datetime(df[datecols])
>>> df.head()
year month day data
2017-01-01 2017 1 1 -0.0767
2017-01-02 2017 1 2 -1.2798
2017-01-03 2017 1 3 0.4032
2017-02-01 2017 2 1 1.2377
2017-02-02 2017 2 2 -0.2060Наконец, вы можете отказаться от старых отдельных столбцов и преобразовать их в Series:
Код и вывод
>>> df = df.drop(datecols, axis=1).squeeze()
>>> df.head()
2017-01-01 -0.0767
2017-01-02 -1.2798
2017-01-03 0.4032
2017-02-01 1.2377
2017-02-02 -0.2060
Name: data, dtype: float64
>>> df.index.dtype_str
'datetime64[ns]Интуитивно суть передачи фрейма данных в том, что DataFrame похож на словарь Python, где имена столбцов — это ключи, а отдельные столбцы (Series) — значения словаря. Поэтому pd.to_datetime (df[datecols].to_dict (orient='list')) здесь также будет работать.
Это — зеркало конструкции datetime.datetime в Python, где вы передаёте аргументы с ключевыми словами, например datetime.datetime(year=2000, month=1, day=15, hour=10).
5. Использование категориальных данных для экономии времени и места
Одна из мощных возможностей Pandas — её объект типа данных (dtype) Categorical. Даже если вы не всегда работаете с гигабайтами данных в оперативной памяти, вы наверняка сталкивались со случаями, когда простые операции над большим DataFrame зависают более чем на несколько секунд.
dtype Pandas object — часто отличный кандидат для преобразования в категориальные данные. (object — это контейнер для str, разнородных типов данных или «других» типов.) Строки занимают значительное место в памяти:
Код и вывод
>>> colors = pd.Series([
... 'periwinkle',
... 'mint green',
... 'burnt orange',
... 'periwinkle',
... 'burnt orange',
... 'rose',
... 'rose',
... 'mint green',
... 'rose',
... 'navy'
... ])
...
>>> import sys
>>> colors.apply(sys.getsizeof)
0 59
1 59
2 61
3 59
4 61
5 53
6 53
7 59
8 53
9 53
dtype: int64Я вызвал
sys.getsizeof(), чтобы показать память, занимаемую каждым отдельным значением в Series. Помните, что это объекты Python, у них есть издержки ресурсов. (sys.getsizeof ('')вернёт 49 байт). Есть методcolors.memory_usage(), который суммирует использование памяти и полагается на атрибут.nbytesбазового массива NumPy. Не увязните в этих деталях: важно относительное использование памяти, возникающее в результате преобразования типов, об этом ниже.
А что если бы мы могли взять перечисленные выше уникальные цвета и отобразить каждый из них в занимающее меньше места целое число? Наивная реализация:
Код и вывод
>>> mapper = {v: k for k, v in enumerate(colors.unique())}
>>> mapper
{'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
>>> as_int = colors.map(mapper)
>>> as_int
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int64
>>> as_int.apply(sys.getsizeof)
0 24
1 28
2 28
3 24
4 28
5 28
6 28
7 28
8 28
9 28
dtype: int64Другой способ сделать то же самое в Pandas — pd.factorize (colors) :
Код и вывод
>>> pd.factorize(colors)[0]
array([0, 1, 2, 0, 2, 3, 3, 1, 3, 4])Так или иначе объект кодируется как перечислимый тип (категориальная переменная).
Вы сразу заметите, что использование памяти сократилось почти вдвое по сравнению с использованием полных строк с dtype object. Ранее в разделе об аксессорах я упоминал категориальный асцессор .cat. Приведённый выше пример с mapper — грубая иллюстрация того, что происходит внутри dtype Categorical в Pandas:
«Использование памяти
Categoricalпропорционально количеству категорий плюс длина данных. Напротив,objectdtype — это константа, умноженная на длину данных» (Источник).
В colors выше есть соотношение двух значений на каждое уникальное значение, то есть на категорию:
Код и вывод
>>> len(colors) / colors.nunique()
2.0Экономия памяти от преобразования в Categorical хороша, но невелика:
Код и вывод
>>> # Not a huge space-saver to encode as Categorical
>>> colors.memory_usage(index=False, deep=True)
650
>>> colors.astype('category').memory_usage(index=False, deep=True)
495Но, если у вас будет, например, много демографических данных, где мало уникальных значений, объём требуемой памяти уменьшится в 10 раз:
Код и вывод
>>> manycolors = colors.repeat(10)
>>> len(manycolors) / manycolors.nunique() # Much greater than 2.0x
20.0
>>> manycolors.memory_usage(index=False, deep=True)
6500
>>> manycolors.astype('category').memory_usage(index=False, deep=True)
585Кроме того, повышается эффективность вычислений: для категориальных Series строковые операции [выполняются над атрибутом .cat.categories, а не над каждым исходным элементом Series. Другими словами, операция выполняется один раз для каждой уникальной категории, а результаты отображаются обратно на значения. Категориальные данные имеют аксессор .cat — окно в атрибуты и методы манипулирования категориями:
Код и вывод
>>> ccolors = colors.astype('category')
>>> ccolors.cat.categories
Index(['burnt orange', 'mint green', 'navy', 'periwinkle', 'rose'], dtype='object')Можно воспроизвести что-то похожее на пример выше, который делался вручную:
Код и вывод
>>> ccolors.cat.codes
0 3
1 1
2 0
3 3
4 0
5 4
6 4
7 1
8 4
9 2
dtype: int8Всё, что вам нужно сделать, чтобы в точности повторить предыдущий ручной вывод, — это изменить порядок кодов:
Код и вывод
>>> ccolors.cat.reorder_categories(mapper).cat.codes
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int8Обратите внимание, что dtype — это int8 NumPy, 8-битное знаковое целое, которое может принимать значения от −127 до 128. Для представления значения в памяти требуется только один байт. 64-битные знаковые int были бы излишеством с точки зрения потребления памяти. Грубый пример привёл к данным int64 по умолчанию, тогда как Pandas достаточно умна, чтобы привести категориальные данные к минимально возможному числовому dtype.
Большинство атрибутов .cat связаны с просмотром и манипулированием самими базовыми категориями:
Код и вывод
>>> [i for i in dir(ccolors.cat) if not i.startswith('_')]
['add_categories',
'as_ordered',
'as_unordered',
'categories',
'codes',
'ordered',
'remove_categories',
'remove_unused_categories',
'rename_categories',
'reorder_categories',
'set_categories']6. Интроспекция объектов Groupby через итерацию
При вызове df.groupby ('x') результирующие объекты Pandas groupby могут быть немного непрозрачными. Этот объект инстанцируется лениво и сам по себе не имеет никакого осмысленного представления. Продемонстрируем это на наборе данных abalone из первого примера:
Код и вывод
>>> abalone['ring_quartile'] = pd.qcut(abalone.rings, q=4, labels=range(1, 5))
>>> grouped = abalone.groupby('ring_quartile')
>>> grouped
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x11c1169b0>Хорошо, теперь у вас есть объект groupby, но что это за штука и как её увидеть? Прежде чем вызвать что-то вроде grouped.apply (func), вы можете воспользоваться тем, что объекты groupby можно итерировать:
Код
>>> help(grouped.__iter__)
Groupby iterator
Returns
-------
Generator yielding sequence of (name, subsetted object)
for each groupНечто, получаемое grouped.__iter__(), представляет собой кортеж (name, subsetted object), где name — это значение столбца группировки, а subsetted object — это DataFrame — подмножество исходного DataFrame на основе любого указанного вами условия группировки, то есть данные разбиваются по группам:
Код и вывод
>>> for idx, frame in grouped:
... print(f'Ring quartile: {idx}')
... print('-' * 16)
... print(frame.nlargest(3, 'weight'), end='\n\n')
...
Ring quartile: 1
----------------
sex length diam height weight rings ring_quartile
2619 M 0.690 0.540 0.185 1.7100 8 1
1044 M 0.690 0.525 0.175 1.7005 8 1
1026 M 0.645 0.520 0.175 1.5610 8 1
Ring quartile: 2
----------------
sex length diam height weight rings ring_quartile
2811 M 0.725 0.57 0.190 2.3305 9 2
1426 F 0.745 0.57 0.215 2.2500 9 2
1821 F 0.720 0.55 0.195 2.0730 9 2
Ring quartile: 3
----------------
sex length diam height weight rings ring_quartile
1209 F 0.780 0.63 0.215 2.657 11 3
1051 F 0.735 0.60 0.220 2.555 11 3
3715 M 0.780 0.60 0.210 2.548 11 3
Ring quartile: 4
----------------
sex length diam height weight rings ring_quartile
891 M 0.730 0.595 0.23 2.8255 17 4
1763 M 0.775 0.630 0.25 2.7795 12 4
165 M 0.725 0.570 0.19 2.5500 14 4Соответственно объект groupby также имеет .groups и групповой геттер — .get_group():
Код и вывод
>>> grouped.groups.keys()
dict_keys([1, 2, 3, 4])
>>> grouped.get_group(2).head()
sex length diam height weight rings ring_quartile
2 F 0.530 0.420 0.135 0.6770 9 2
8 M 0.475 0.370 0.125 0.5095 9 2
19 M 0.450 0.320 0.100 0.3810 9 2
23 F 0.550 0.415 0.135 0.7635 9 2
39 M 0.355 0.290 0.090 0.3275 9 2Независимо от того, какие вычисления вы выполняете над grouped, будь то отдельный метод Pandas или пользовательская функция, каждый из этих «подфреймов» передаётся один за другим как аргумент вызываемой функции. Именно отсюда происходит термин «split-apply-combine»: разбить данные по группам, выполнить расчёт для каждой группы и объединить их в некую агрегированную форму. Если вам трудно представить, как именно будут выглядеть группы, просто итерации и печать нескольких из них могут быть очень полезны.
7. Используйте этот трюк с отображением для бининга
Представьте: есть Series и соответствующая «таблица сопоставления», где каждое значение принадлежит к многочленной группе или вообще не принадлежит ни одной группе:
Код и вывод
>>> countries = pd.Series([
... 'United States',
... 'Canada',
... 'Mexico',
... 'Belgium',
... 'United Kingdom',
... 'Thailand'
... ])
...
>>> groups = {
... 'North America': ('United States', 'Canada', 'Mexico', 'Greenland'),
... 'Europe': ('France', 'Germany', 'United Kingdom', 'Belgium')
... }Другими словами, вам нужно сопоставить countries со следующим результатом:
Текст
0 North America
1 North America
2 North America
3 Europe
4 Europe
5 other
dtype: objectЗдесь нужна функция, похожая на функцию Pandas pd.cut(), но для группировки на основе категориальной принадлежности. Для имитации можно воспользоваться pd.Series.map(), который вы уже видели:
Код
from typing import Any
def membership_map(s: pd.Series, groups: dict,
fillvalue: Any=-1) -> pd.Series:
# Reverse & expand the dictionary key-value pairs
groups = {x: k for k, v in groups.items() for x in v}
return s.map(groups).fillna(fillvalue)Код значительно быстрее, чем вложенный цикл Python по группам для каждой страны:
Код и вывод
>>> membership_map(countries, groups, fillvalue='other')
0 North America
1 North America
2 North America
3 Europe
4 Europe
5 other
dtype: objectРазберёмся, что происходит. Это отличный момент, чтобы войти в область видимости функции с помощью отладчика Python, pdb, чтобы проверить, какие переменные локальны относительно функции.
Задача — сопоставить каждую группу в groups целому числу. Однако Series.map() не распознаёт 'ab' — ему нужна разбитая версия, где каждый символ из каждой группы отображён на целое число. Это делается охватом словаря:
Код и вывод
>>> groups = dict(enumerate(('ab', 'cd', 'xyz')))
>>> {x: k for k, v in groups.items() for x in v}
{'a': 0, 'b': 0, 'c': 1, 'd': 1, 'x': 2, 'y': 2, 'z': 2}Этот словарь может передаваться в s.map() для сопоставления или «перевода» его значений в соответствующие индексы групп.
8. Загрузка данных из буфера обмена
Часто возникает ситуация, когда нужно передать данные из такого места, как Excel или Sublime Text, в структуру данных Pandas. В идеале сделать это хочется, не проходя промежуточный этап сохранения данных в файл и последующего чтения файла в Pandas. Вы можете загрузить DataFrames из буфера обмена компьютера с помощью pd.read_clipboard(). Его аргументы в виде ключевых слов передаются в pd.read_table().
Это позволяет копировать структурированный текст непосредственно в DataFrame или Series. В Excel данные будут выглядеть примерно так:
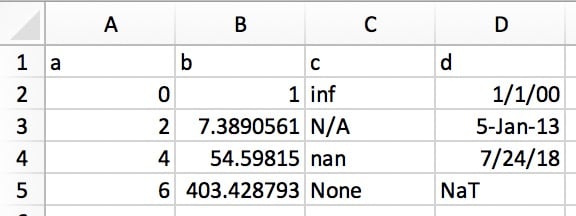
Его текстовое представление может выглядеть так:
Код и вывод
a b c d
0 1 inf 1/1/00
2 7.389056099 N/A 5-Jan-13
4 54.59815003 nan 7/24/18
6 403.4287935 None NaTПросто выделите и скопируйте текст выше и вызовите pd.read_clipboard():
Код и вывод
>>> df = pd.read_clipboard(na_values=[None], parse_dates=['d'])
>>> df
a b c d
0 0 1.0000 inf 2000-01-01
1 2 7.3891 NaN 2013-01-05
2 4 54.5982 NaN 2018-07-24
3 6 403.4288 NaN NaT
>>> df.dtypes
a int64
b float64
c float64
d datetime64[ns]
dtype: object9. Запись объектов Pandas в сжатый формат
Этот короткий пример завершает список. Начиная с версии Pandas 0.21.0 вы можете записывать объекты Pandas непосредственно для сжатия gzip, bz2, zip или xz, а не хранить несжатый файл в памяти и преобразовывать его. Вот пример, использующий данные abalone из первого трюка:
abalone.to_json('df.json.gz', orient='records',
lines=True, compression='gzip')Коэффициент разницы в размерах равен 11,6:
>>> import os.path
>>> abalone.to_json('df.json', orient='records', lines=True)
>>> os.path.getsize('df.json') / os.path.getsize('df.json.gz')
11.603035760226396Data Science — это не только статистика, но и написание кода, который с учётом работы с большими данными должен быть эффективным. В этом одна из причин высокой зарплаты специалиста в науке о данных, стать которым мы можем помочь вам на нашем курсе. Также вы можете узнать, как начать карьеру аналитика или инженера данных, начать с нуля или прокачаться в других направлениях, например, в Fullstack-разработке на Python:

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также: