
В этой части мы научим газонокосилку отличать скошенную траву от нескошенной с помощью нейросети. А также определять препятствия, такие как бетонные дорожки, что было невозможно только датчиком расстояния в предыдущей части.
Но сначала попробуем определять зеленый цвет травы с помощью OpenCV.
Часть 1. Механика и радиоуправление
Часть 2. Определение высоты травы
Часть 3. Сегментация травы нейросетью
Часть 4. Карта газона на визуальных маркерах
Чтобы ехать по границе нескошенной травы, как это делают люди при ручном кошении, нужно уметь отличать эту границу. В предыдущей части мы для этого использовали датчик расстояния (ультразвуковой и лазерный), чтобы определять высоту травы перед газонокосилкой.
Но такой способ не позволяет распознать возникающие препятствия, если они имеют высоту как трава или ниже. Это могут быть дорожки, посаженные цветы, грядки, лежащие на земле забытые вещи и тому подобное.
Однако трава имеет характерный зеленый цвет, который больше нигде обычно не встречается. Не зря спецэффекты в кино делают на фоне зеленого экрана. Поэтому можно попробовать определить по камере этот зеленый цвет. И это автоматически даст определение всех возможных препятствий, так как они чаще всего отличаются по цвету от травы.
Кроме того, скошенная и нескошенная трава имеют на картинке разную текстуру, поэтому есть шанс различить их с помощью нейросети. Которые как раз хорошо заточены под такие задачи.
Надо сказать, что задача сегментации и визуального определения травы сама по себе очень трудная.
Если отличить визуально бетонные дорожки и участки без травы, например белые камни, интуитивно кажется довольно легко (здесь и далее кадры с видеокамеры, закрепленной на газонокосилке).


То отличить границу скошенной и нескошенной травы на видео уже бывает совсем непросто. Здесь нескошенная явно справа, но где точно проходит граница?

Видео имеет артефакты сжатия и размытия от движения, затрудняющие попиксельный анализ картинки.
Сам газон может иметь неравномерный рост травы и отличаться по составу и виду травинок. Например, вот здесь уже скошенный участок или это высокая трава, которую надо косить? Непонятно...

Встречаются и совсем сложные участки, с которыми непонятно что делать. Как например здесь

Но даже там где в видеопотоке хорошо просматривается граница скошенной травы, определить ее по цветам отдельных пикселей все равно очень сложно


Есть еще одна проблема. В зеленой траве могут встречаться другие цвета. Летом это желтые одуванчики или другие цветы. А потом и белые венчики, когда появляются семена. Что также затрудняет визуальный анализ.

Получение датасета
Для получения датасета, на котором будет обучаться нейросеть, нужно сначала прокосить весь участок вручную с закрепленной на газонокосилке видеокамерой.
К сожалению, при жестком креплении из-за вибраций бензинового двигателя (да и самой косилки при езде по неровностям почвы), записываемая картинка получается примерно такой:
Такое качество изображения абсолютно неприемлемо.
Дело не в колебании направления куда смотрит камера, а в том что отдельные кадры получаются размытые, на которых практически ничего невозможно распознать. Особенно границу между скошенной и нескошенной травой. Вот так выглядят отдельные кадры с камеры при работающем бензиновом моторе:



Нужно делать подвес с виброразвязкой. В простейшем случае это должно быть что-то вроде коробки, внутри которой камера висит растянутой во всех шести направлениях на резинках или пружинках.
К сожалению, другого датасета у меня на данный момент нет, поэтому попробуем поработать хотя бы с таким. Для проверки принципиальной возможности сегментации.
Определение травы с помощью OpenCV
Но сначала попробуем определить зеленую траву в кадре более простым способом с помощью OpenCV. Используя более четкие кадры из начала статьи, снятые при неработающем двигателе.
Если у вас еще не установлен Python, то установите его с сайта https://www.python.org. И установите OpenCV, для чего в командной строке запустите команду
pip install opencv-pythonСуществует классический способ определять на картинке цвета, с учетом что их интенсивность может колебаться в зависимости от освещения, баланса белого камеры и многих других факторов.
Для этого изображение нужно перевести в формат HSV и искать на нем пиксели, попадающие в нужный диапазон цветов в этом формате.
В HSV формате цвет каждого пикселя кодируется не привычными R,G,B компонентами (красный, зеленый, синий). А цветом в диапазоне 0..360, насыщенностью в диапазоне 0..100% и яркостью в диапазоне 0..100%.
Чем выше насыщенность, тем ярче и контрастнее цвет. А чем ниже, тем сильнее цвет стремится к серому.
Чем выше яркость, тем сильнее цвет стремится к белому, а чем ниже, тем ближе к черному.
Номер же самого цвета в диапазоне 0..360 можно определить согласно этой картинке:
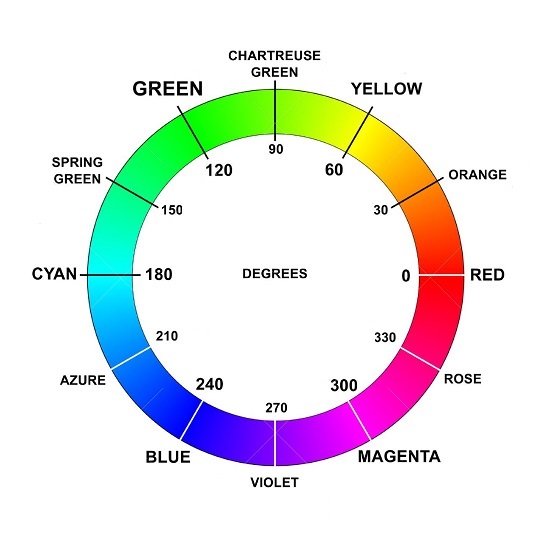
.
В итоге все возможные комбинации зеленого цвета травы попадают примерно в диапазон от [60,20,20] до [180,100,100], где три числа обозначают [цвет, насыщенность, яркость].
С помощью OpenCV это делается очень просто. Скопируйте изображения в папку images и запустите python скрипт из спойлера ниже. Результат будет в папке results. Можно открыть скрипт и подбирать нижнюю и верхнюю границу диапазон цвета в этих строчках
lower = [60,20,20] # нижняя граница: [цвет,насыщенность,яркость]
upper = [180,100,100] # верхняя граница: [цвет,насыщенность,яркость]GrassDetection.py
# Поиск на фотографиях зеленой травы с помощью OpenCV
# диапазон HSV цвета, который искать
# первое число - цвет 0..360 (см. цветовой круг HSV.jpg)
# второе число - насыщенность 0..100%, чем выше, тем чище цвет, а чем ниже, тем ближе к серому
# третье число - яркость, тоже 0..100%
lower = [60,20,20] # нижняя граница: [цвет,насыщенность,яркость]
upper = [180,100,100] # верхняя граница: [цвет,насыщенность,яркость]
images = 'images' # папка с фотографиями
# дальше программа
import os,sys,time
# автозагрузка модулей, если не установлены
try:
import cv2
except:
os.system("pip install opencv-python")
try:
import numpy as np
except:
os.system("pip install numpy")
if not os.path.exists(images):
print(f"\nКаталог {images} не существует, посместите в него фотографии\n")
input()
sys.exit(0)
# создаем папку results
if not os.path.exists("results"):
os.makedirs("results")
# очищаем старые файлы
files = [f for f in os.listdir("results") if f.lower().endswith(".jpg")] # только имена файлов .jpg, без пути!
for f in files:
os.remove("results/"+f)
# читаем все .jpg файлы из папки
files = [f for f in os.listdir(images) if f.lower().endswith(".jpg")]
# переводим цвет HSV [0..360, 0..100%, 0..100%] в opencv формат [0..180, 0..255, 0..255]
lower[0] = lower[0] / 2 # 0..360 -> 0..180
lower[1] = lower[1] * 2.55 # 0..100% -> 0..255
lower[2] = lower[2] * 2.55 # 0..100% -> 0..255
upper[0] = upper[0] / 2
upper[1] = upper[1] * 2.55
upper[2] = upper[2] * 2.55
lower = np.array(lower)
upper = np.array(upper)
t1 = time.time()
count = 0
found = 0
# по всем картинкам...
for filename in files:
try:
im = cv2.imread(images+"/"+filename)
hsv = cv2.cvtColor(im,cv2.COLOR_BGR2HSV) # в формат HSV
# ищем цвет на фотографии, от нижнего до верхнего диапазона
mask = cv2.inRange(hsv, lower, upper) # в маске белый цвет 255 - где попало в диапазон, и 0 - где нет
if np.any(mask): # можно также использовать if 255 in mask: но np.any() почти в два раза быстрее
if found == 0: print("\nНайдено:\n")
found += 1 # счетчик успешно найденных
print(filename) # выводим путь к картинке, где нашли нужное пятно
# полупрозрачное наложение
maskImg = np.zeros(im.shape, im.dtype)
maskImg[:,:] = (0, 255, 0) # цвет накладываемой маски, BGR формат
maskImg = cv2.bitwise_and(maskImg, maskImg, mask=mask)
cv2.addWeighted(maskImg, 0.3, im, 1, 0, im) # 0.3 - степень полупрозрачности
cv2.imwrite(f"results/{filename}", im)
# каждые три секунды покажем сколько процентов осталось
if time.time() - t1 > 3:
t1 = time.time()
print (round(count*100/len(files), 2), "%")
count += 1 # число обработанных файлов
except:
pass
if count == 0:
print(f"\nВ папке {images} нет ни одного .jpg файла\n")
elif found == 0:
print("\nНичего не найдено. Попробуйте изменить HSV диапазон цвета\n")
else:
print("\nКонец работы, результат в папке results\n")
input()
Насколько хорошо такая простая сегментация работает?
На удивление, неплохо. Ниже несколько примеров такого детектирования травы на кадрах с видео

При этом отличающиеся по цвету бетонные дорожки определяются прям хорошо


Так же как щебенка и обычный грунт


Более того, типичные препятствия в виде заборов, стволов деревьев и в том числе ноги человека тоже надежно и очень хорошо определяются (ну, кроме потенциального невезучего человека в зеленых штанах, конечно).


Однако с помощью OpenCV невозможно отличить скошенную траву от нескошенной. Различия между ними, учитывая разное освещение в течении дня, падающие тени и прочие факторы, слишком незначительны, чтобы их можно было обнаружить этим методом.

Обратите также внимание, что желтые одуванчики не попадают в целеный цвет травы. И поэтому будут восприниматься как препятствия в траве:

Однако если уменьшить нижнюю границу до 30, чтобы она захватывала и желтый цвет
lower = [30,20,20] То одуванчики попадают в условную категорию "трава":

Однако обратите внимание, что желтый ящик в левой части снимка тоже закрасился. А значит все желтые объекты на газоне не будут теперь восприниматься как препятствие. Что плохо.
Как итог, OpenCV сегментацию травы вполне можно использовать, если у вас на газоне есть дорожки, темные грядки, участки голого грунта и тому подобное. С этим методом газонокосилка будет ездить только по зеленой траве. Да и просто как защита от брошенных на землю детских игрушек, оставленных ведер, садового инструмента и прочего.
Границу скошенной травы, чтобы ехать вдоль нее, можно определять датчиком расстояния из предыдущей серии. А OpenCV использовать параллельно для безопасности.
Как это реализовать технически?
К точке доступа ESP8266 на газонокосилке может подключаться по Wi-Fi до 4 устройств. Поэтому такую сегментацию можно делать на внешнем устройстве, а потом просто отправлять на ESP8266 команду-флаг, что впереди путь свободен. Что впереди зеленая трава, по которой можно ехать.
Сами же расчеты можно делать несколькими способами:
На бортовом одноплатном компьютере с подключенной камерой, таком как Rasberry PI или NVIDIA Jetson Nano (цена ~100$)
Закрепив на газонокосилке телефон и используя его штатную камеру, а обработку картинки делая на Javascript (есть версия OpenCV под HTML5)
Используя на газонокосилке Wi-Fi камеру (многие экшен камеры умеют отправлять видео по Wi-Fi), а расчеты проводить на ноутбуке рядом. Как вебкамеру можно использовать и обычный телефон, транслируя с него видеопоток на ноутбук с помощью бесплатного приложения IP Webcam
Сегментация травы нейросетью
Но более продвинутым способом определять наличие травы в кадре является использование нейросети.
Потенциально она может определить разницу между скошенной и нескошенной травой. И точно так же успешно будет определять все виды препятствий (все что не является зеленой травой).
Благодаря этому всю работу можно делать полностью по камере, необходимость в датчиках расстояния отпадает.
Разметка датасета
Вытащить кадры из отснятого видео можно с помощью библиотеки FFmpeg и этой команды
ffmpeg -i video.mp4 -vf fps=1 -q:v 1 images/%06d.jpgЭта команда сохранит в папку images по одному кадру с каждой секунды видео, благодаря fps=1. Если у вас видео с частотой 30 к/сек, то нет смысла размечать каждый кадр, используйте только кадры с заметным смещением. Кадры будут сохранены с максимальным качеством, благодаря -q:v 1. Если запускаете эту команду из .bat файла, то вместо images/%06d.jpg указывайте images/%%06d.jpg (с двумя символами %).
С помощью ключей -ss и -t можно указать начало и длительность в секундах участка видео, откуда вырезать кадры
ffmpeg -ss 00:00:00 -i video.mp4 -t 00:00:10 -vf fps=1 -q:v 1 images/%06d.jpgСуществует два основных способа разметки изображения для сегментации: с помощью рисования полигонов или создавая попиксельную маску.
Для разметки полигонами есть неплохая утилита LabelMe. Она скачивается с помощью команды
pip install labelmeА запускается потом в командной строке как
labelmeНо лучше использовать автоматическую попиксельную разметку с помощью замечательной программы PixelAnnotationTool. Скачать ее можно отсюда: https://github.com/abreheret/PixelAnnotationTool/releases
В PixelAnnotationTool достаточно сделать несколько грубых мазков мышью по картинке, а она сама раскрасит ее по классам. М-магия!


Причем это работает и для разметки границы между скошенной и нескошенной травой:


Здесь зеленый цвет - высокая трава, которую надо косить. Желтый - уже скошенная, а красный - препятствия.
Если не совсем правильно сегментировалось (как на примерах выше), то можно добавлять новые штрихи, пока не получится нормально.
Помощь по PixelAnnotationTool
Скопируйте все фотографии в папку images в папке с программой
-
Создайте файл labels.json со списком классов: grass, cut, wall. Можете взять из спойлера ниже или сохранить Tool->Save config file с COCO классами и отредактировать.
labels.json
{ "labels": { "grass": { "categorie": "grass", "color": [ 46, 204, 113 ], "id": 1, "id_categorie": 2, "name": "grass" }, "flat": { "categorie": "cut", "color": [ 255, 191, 0 ], "id": 2, "id_categorie": 2, "name": "cut" }, "wall": { "categorie": "wall", "color": [ 255, 0, 0 ], "id": 3, "id_categorie": 3, "name": "wall" } } } При запуске программы выберите меню Tool->Open config file и загрузите файл labels.json
Откройте папку с фотографиями (сдвиньте размер экрана, если фото не вмещается в окно)
Выбор класса: клавиши 1,2,3
Запуск расчета: Пробел
Каждую картинку сохранять Ctrl+S после рисования
-
Когда все будет готово, запустите в папке с программой скрипт _prepare_dataset.py из спойлера ниже. Он подготовит картинки в нужном формате для нейросети и создаст папку dataset, которую нужно будет скопировать в папку с нейросетью DeepLabV3
_prepare_dataset.py
# coding: utf-8 # Создает задасет для DeeblabV3 folder = 'images' validation = 0.05 # 5% для валидации. случайный, но всегда в одном порядке благодаря seed import os,sys import cv2 import shutil import random from tqdm import tqdm def image_resize(image, width, height, interpolation = cv2.INTER_LINEAR): # изменяет размер с сохранением aspect ratio h, w = image.shape[:2] dw = 0 dh = 0 dscale = 1.0 if h != height or w != width: scale = height / h ww = int(w * scale) if ww > width: d = int((abs(ww - width) / scale) / 2) if d > 0: dw = d dscale = scale image = image[:, d:-d, :] elif ww < width: scale = width / w hh = int(h * scale) d = int((abs(hh - height) / scale) / 2) if d > 0: dh = d dscale = scale image = image[d:-d, :, :] else: dscale = scale image = cv2.resize(image, (width, height), interpolation=interpolation) return image if os.path.exists('dataset'): print("\nFolder dataset already exists! Delete folder first") input() sys.exit(0) files = os.listdir( folder ) # '000001.jpg', '000001_color_mask.png', '000001_mask.png', '000001_watershed_mask.png', #print(files[0:5]) # create folders os.makedirs('dataset/train/Images') os.makedirs('dataset/train/Labels') os.makedirs('dataset/val/Images') os.makedirs('dataset/val/Labels') print('Prepare dataset...\n') count = 0 for file in tqdm(files): if not file.endswith('_mask.png'): f = file[0:-4] # '000001.jpg' -> '000001' mask = folder + '/' + f + '_watershed_mask.png' if os.path.exists(mask): # картинка #shutil.copyfile(folder + '/' + file, 'dataset/train/Images/' + file) # уменьшаем, т.к. рабочее разрешение нейросети 224х224, но при обучении она делает Random Crop 224x224, поэтому реально для аугментации делаем 300х300 image = cv2.imread(folder + '/' + file) image = image_resize(image, 300,300) cv2.imwrite('dataset/train/Images/' + file, image) # маску надо конвертировать из RGB в Grayscale #copyfile(mask, 'dataset/train/Labels/'+f+'.png') image = cv2.imread(mask) h,w = image.shape[0:2] # ВНИМАНИЕ! PixelAnnotationTool по контуру маски делает белую рамку толщиной в 1 пиксель! перекрашиваем его в черный (_background_) cv2.rectangle(image,(0,0),(w-1,h-1),(0,0,0),1) # 1 pixel rectangle image = image_resize(image, 300,300, interpolation=cv2.INTER_NEAREST) # ВНИМАНИЕ! INTER_NEAREST, чтобы пиксели не нарушались в маске h,w = image.shape[0:2] #gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # можно так, но лучше просто брать 1 канал (они там все одинаковые: [3,3,3]) gray = image[:,:,0] # 1 channel cv2.imwrite('dataset/train/Labels/'+f+'.png', gray) ''' # проверим, чтобы не было пикселей больше 3 for i in range(h): for j in range(w): if gray[i][j] > 3: print("File",mask,' pixel', w,'x',h,':', gray[i][j]) sys.exit(0) ''' count += 1 print("Count", count) # создадим файл с классами f = open("dataset/class_names.txt","w+") f.write("_background_\ngrass\ncut\nwall") # ВНИМАНИЕ! первой строкой всегда идет _background_, а потом в каждой строке название класса: grass, cut, wall f.close() print("Created file dataset/class_names.txt") # копируем случайное число файлов в val files = os.listdir( 'dataset/train/Images' ) count = int(len(files) * validation) if count == 0: count = 1 # минимум одну картинку random.seed(123) # инициализация рандома, чтобы всегда выдавал одинаковые числа val = random.sample(files, count) for file in val: shutil.move('dataset/train/Images/'+file, 'dataset/val/Images/'+file) # картинка mask = file[0:-4] + '.png' shutil.move('dataset/train/Labels/'+mask, 'dataset/val/Labels/'+mask) # маска print('Validation:', count, 'files') print('\nDataset created at folder dataset\n\nDone.') input()
Обучение нейросети
Существует множество нейросетей для сегментации. Отличающихся точностью и скоростью работы.
Мы сейчас воспользуемся старенькой DeepLabV3, потому что ее очень просто настраивать. Но существуют более точные и быстрые нейросети, эта уже считается устаревшей.
Скачать DeepLabV3 можно отсюда: https://github.com/jnkl314/DeepLabV3FineTuning
О DeepLabV3
DeepLabV3 работает с изображениями размером 224х224 пикселя (делает RandomCrop(224) при обучении, и CenterCrop(224) при обычной работе). И делает аугментацию в виде горизонтального и вертикального Flip.
Для обучения требует в датасете картинки масок в Grayscale (см. папку sample_dataset), где цвет 0..255 соответствует индексу класса 0..N
После того как вы разметили и подготовили датасет с помощью программы PixelAnnotationTool, включая запуск скрипта _prepare_dataset.py для конвертации датасета в формат, нужный для DeepLabV3 (см. выше инструкцию под спойлером "Помощь по PixelAnnotationTool").
Скопируйте созданную скриптом папку dataset в папку с DeepLabV3.
И запустите обучение (из папки DeepLabV3) с помощью команды
python sources/main_training.py ./dataset ./training_output --num_classes 4 --epochs 100 --batch_size 16 --keep_feature_extractЗдесь отличие от инструкции на сайте только в -num_classes 4, так как нужно указывать число классов на один больше, чем в датасете. У нас три класса: grass,cut и wall, поэтому надо указывать 4.
Каждые 25 эпох будет сохраняться текущая обученная нейросеть в папку training_output. Всего указано 100 эпох (минимальное значение для нормального обучения), но вы можете увеличить до 500, если хотите.
После обучения можно запустить нейросеть на картинках из папке images. Лучше это делать не на тех, на которых обучали, иначе будет необъективно.
Имеющийся в комплекте для этого скрипт неправильно масштабирует изображения при предсказании (уменьшает их на треть зачем-то). Поэтому лучше воспользуйтесь скриптом из спойлера ниже. Можете в нем изменить загружаемую нейросеть из папки training_output, по умолчанию там используется последняя после окончания обучения.
Результат будет в папке results.
_predict.py
import torch
import numpy as np
from torchvision import transforms
import cv2
from PIL import Image
import os
import sources.custom_model as custom_model
num_classes = 4 # число классов + 1, для grass,cut,wall = 4
folder_images = "images" # путь к .jpg картинкам
network = "training_output/best_DeepLabV3_Skydiver.pth" # путь к сохраненной нейросети
def image_resize(image, width, height, interpolation = cv2.INTER_LINEAR):
# изменяет размер с сохранением aspect ratio
h, w = image.shape[:2]
dw = 0
dh = 0
dscale = 1.0
if h != height or w != width:
scale = height / h
ww = int(w * scale)
if ww > width:
d = int((abs(ww - width) / scale) / 2)
if d > 0:
dw = d
dscale = scale
image = image[:, d:-d, :]
elif ww < width:
scale = width / w
hh = int(h * scale)
d = int((abs(hh - height) / scale) / 2)
if d > 0:
dh = d
dscale = scale
image = image[d:-d, :, :]
else:
dscale = scale
image = cv2.resize(image, (width, height), interpolation=interpolation)
return image
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model, input_size = custom_model.initialize_model(num_classes, keep_feature_extract=True, use_pretrained=False)
state_dict = torch.load(network, map_location=device)
model = model.to(device)
model.load_state_dict(state_dict)
model.eval()
transforms_image = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
if not os.path.exists("results"):
os.makedirs("results")
files = [f for f in os.listdir(folder_images) if f.lower().endswith(".jpg")] # только имена файлов .jpg, без пути!
#files = files[0:2]
for fname in files:
image = Image.open(f"{folder_images}/{fname}")
image_np = np.asarray(image) # в формат opencv
# уменьшаем картинки до 224х224, с сохранением aspect ratio, т.к. нейросеть работает с 224х224 (делает center crop 224x224 из любого другого размера)
image_np = image_resize(image_np, 224,224)
image = Image.fromarray(image_np)
image = transforms_image(image)
image = image.unsqueeze(0)
image = image.to(device)
outputs = model(image)["out"]
_, preds = torch.max(outputs, 1)
preds = preds.to("cpu")
preds_np = preds.squeeze(0).cpu().numpy().astype(np.uint8)
print(fname)
# preds_np = cv2.cvtColor(preds_np, cv2.COLOR_GRAY2BGR)
image_np = cv2.cvtColor(image_np, cv2.COLOR_RGB2BGR)
# в preds_np массив из классов 0,1,2..N (т.е. grayscale картинка, где цвет пикселя - индекс класса)
preds_np_color = cv2.applyColorMap(preds_np * 50, cv2.COLORMAP_HSV) # COLORMAP_INFERNO COLORMAP_HOT COLORMAP_HSV color maps: https://docs.opencv.org/master/d3/d50/group__imgproc__colormap.html
# две картинки рядом
#img_res = np.hstack((image_np,preds_np_color))
#cv2.imwrite(f"results/{fname}.png", img_res)
# полупрозрачное наложение
alpha = 0.2
cv2.addWeighted(preds_np_color, alpha, image_np, 1 - alpha,0, image_np)
cv2.imwrite(f"results/{fname}", image_np)
#cv2.imwrite(f"results/{fname}_segmentation.png", preds_np_color)
#cv2.imwrite(f"results/{fname}_image.png", image_np)
Картинки результата в папке results будут с разрешением 224х224 пикселя. Причем боковые края окажутся обрезанными, это нормально. Потому что все камеры снимают широкие картинки, а для нейросети нужны квадратные 224х224. Скрипт подготовки датасета _prepare_dataset.py в PixelAnnotationTool это учитывает и уменьшает изображения с сохранением aspect ratio, чтобы картинка не искажалась.
Результат
От этого ужасного по качеству и размытого от тряски датасета не стоит ожидать высокого качества сегментации. Тем не менее, даже на нем что-то обучилось

Здесь желтым цветом высокая трава, которую надо косить, зеленым уже скошенная, а синим препятствия.
В целом, забор и дорога, а также кусты определяются как препятствия верно. Даже местами верно определяется граница высокой травы, что вообще удивительно при таких размытых исходных картинках (см. в начале статьи примеры кадров с видео при работающем двигателе).
При хороших исходных картинках можно ожидать улучшения качества предсказания как минимум в несколько раз.
Более того, нейросеть DeepLabV3 уже старенькая, сейчас есть намного лучше. За зиму к следующему летнему сезону появятся еще лучше и быстрее.
Узнавать о самых последних и самых качественных нейросетях для сегментации и получать их исходники лучше всего на сайте PapersWithCode, а также поиском на github.com. По фразе "Semantic Segmentation".
Запускать нейросети, как и OpenCV, можно несколькими путями.
На ноутбуке с GPU от NVIDIA, получая картинку с камеры на газонокосилке через Wi-Fi. Или даже софтверно на любом ноутбуке на CPU, так как частоты 1 раз в секунду на маленькой скорости движения должно хватить
На бесплатном серверном GPU Googlу Colab (этот сайт можно открывать в том числе с телефона или с планшета)
Сконвертировать нейросеть в Tensorflow.js и запустить ее в браузере телефона. При этом картинку можно получать со штатной камеры телефона. А сам телефон закрепить на газонокосилке и использовать в качестве камеры. Но из-за того что в телефонах очень слабенькие процессоры, это будет работать только с быстрыми и небольшими нейросетями.
Видео с полевыми испытаниями этого метода не будет, потому что они не проводились. С трясущейся камерой собирать датасет было бесполезно, а сделать виброподвес я в этом сезоне не успел.
Однако сегментация травы нейросетью (да и определение травы с помощью OpenCV) кажется очень перспективным делом. Только ей одной, используя единственную камеру без остальных датчиков, потенциально можно сделать умную и безопасную газонокосилку. Которая будет ездить только по зеленой траве и избегать все возможные виды препятствий. Забытые предметы на земле, находящихся на газоне людей и так далее.
В следующей части мы сделаем то, что больше всего ассоциируется с роботом-газонокосилкой. А именно, автоматическое умное движение по всему газону с помощью определения своих координат на глобальной карте, возвращение на базу, объезжание препятствий произвольной формы с помощью алгоритма поиска пути.