Сегодня рассмотрю архитектурный паттерн CQRS и его возможное место в вашей архитектуре. Также осуществим его реализацию на языке golang.
Проблематика
В некоторых проектах Каруны мы стремимся к микросервисной архитектуре. У этой концепции много плюсов, но она создаёт некоторые трудности. Одну из таких трудностей и метод её преодоления я хочу рассмотреть в данной статье.
Для простоты возьмём универсальный пример в виде приложения интернет-магазина. Предположим, он имеет микросервисную архитектуру и следует доменной модели. Одной из главных частей нашего приложения является функционал, связанный с заказами пользователей и с товарами в этих заказах. В нашей архитектуре есть два соответствующих сервиса: order и goods. Сервис order отвечает за создание, обновление, удаление и чтение сущностей заказа (order), а сервис goods реализует тот же CRUD с товарами заказа. Наши клиенты (мобильные приложения, браузерное приложение, и т.д.) взаимодействуют с этими сервисами, и для удобства у нас реализован паттерн объединение API. Т.е разработан сервис, выполняющий роль API-композитора, работающий с данными наших сервис-провайдеров order и goods. Общую архитектуру можно представить следующим образом:

Что касается API-композитора, то его роль может выполнять веб-приложение, API-шлюз или отдельный сервис. Но выбор варианта в нашем случае выходит за рамки темы данной статьи.
Вроде бы всё неплохо: есть одна точка входа в приложение, логика разнесена по доменным областям. Но что делать в случае, когда API-композитору нужно выполнить нетривиальные выборки и объединять большие наборы данных?
Бизнес просит, чтобы были реализованы сложные фильтры и пагинация. Например, нужно выбрать заказы, в которых количество товаров больше заданного N. В этом случае нам нужно делать полную выборку из сервиса goods, и на композитор будет ложиться задача объединения и фильтровки большого количества данных. Это неэффективно и задействует большое количество памяти. Как раз в этом случае на помощь приходит шаблон CQRS, который и решает проблему.
Проектирование
Суть шаблона CQRS (command query responsibility segregation — разделение ответственности командных запросов) заключается в разделении модулей и данных на две отдельные части: команды и запросы. Командные модули реализуют операции: create, update, delete. Модуль запросов реализует получение данных (get). Помимо улучшенного разделения ответственностей, преимущество данного шаблона заключается в том, что сервисы могут хранить данные в таком виде, в каком это удобно для более эффективных запросов. В нашем случае сервисы order, goods будут выполнять только команды, а новый сервис order-history возьмёт на себя ответственность в реализации запросов. Посмотрим, как меняется архитектура с внедрением шаблона CQRS:
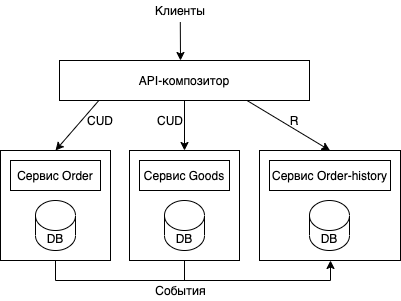
Теперь сервисы order и goods отвечают только за изменение соответствующих им сущностей: заказов и товаров. Все эти изменения, помимо записи в базы данных сервисов, публикуются в виде событий. Новый сервис order-history отвечает только за запросы на чтение данных. Он подписывается на события из order, goods и заполняет/изменяет свою базу данных.
Реализация
Попробуем реализовать с помощью следующего стэка: golang как язык сервисов, postgresql для баз данных и kafka для обмена сообщениями между сервисами.
Создадим локальное рабочее окружение, а именно — сервисы order, goods, order-history, БД для каждого сервиса и брокер kafka:
docker-compose.yml
version: '3.9'
services:
order:
build:
dockerfile: .docker/app.Dockerfile
context: ./
args:
SERVICE_NAME: order
environment:
- HTTP_BIND=8080
- POSTGRES_DB=orders
- POSTGRES_USER=orders_user
- POSTGRES_PASSWORD=orders_password
- HOST_DB=db-order
- PORT_DB=5432
- KAFKA_ADDR=kafka:9092
- ORDER_CREATED_TOPIC=order_created_v1
depends_on:
- db-order
- kafka
volumes:
- ./order:/app/order:delegated
- ./.docker/entrypoint.sh:/entrypoint.sh:ro
entrypoint: /entrypoint.sh
ports:
- "8080:8080"
networks:
- cqrs
db-order:
image: postgres:14
environment:
- POSTGRES_DB=orders
- POSTGRES_USER=orders_user
- POSTGRES_PASSWORD=orders_password
ports:
- "5441:5432"
volumes:
- data:/var/lib/postgresql
networks:
- cqrs
goods:
build:
dockerfile: .docker/app.Dockerfile
context: ./
args:
SERVICE_NAME: goods
environment:
- HTTP_BIND=8081
- POSTGRES_DB=goods
- POSTGRES_USER=goods_user
- POSTGRES_PASSWORD=goods_password
- HOST_DB=db-goods
- PORT_DB=5432
- KAFKA_ADDR=kafka:9092
- GOODS_CREATED_TOPIC=goods_created_v1
volumes:
- ./goods:/app/goods:delegated
- ./.docker/entrypoint.sh:/entrypoint.sh:ro
entrypoint: /entrypoint.sh
depends_on:
- db-goods
- kafka
ports:
- "8081:8081"
networks:
- cqrs
db-goods:
image: postgres:14
environment:
- POSTGRES_DB=goods
- POSTGRES_USER=goods_user
- POSTGRES_PASSWORD=goods_password
ports:
- "5442:5432"
volumes:
- data:/var/lib/postgresql
networks:
- cqrs
order-history:
build:
dockerfile: .docker/app.Dockerfile
context: ./
args:
SERVICE_NAME: order-history
environment:
- HTTP_BIND=8082
- POSTGRES_DB=orders_history
- POSTGRES_USER=orders_history_user
- POSTGRES_PASSWORD=orders_history_password
- HOST_DB=db-order-history
- PORT_DB=5432
- KAFKA_ADDR=kafka:9092
- GOODS_CREATED_TOPIC=goods_created_v1
- ORDER_CREATED_TOPIC=order_created_v1
depends_on:
- db-order-history
- kafka
volumes:
- ./order-history:/app/order-history:delegated
- ./.docker/entrypoint.sh:/entrypoint.sh:ro
entrypoint: /entrypoint.sh
ports:
- "8082:8082"
networks:
- cqrs
db-order-history:
image: postgres:14
environment:
- POSTGRES_DB=orders_history
- POSTGRES_USER=orders_history_user
- POSTGRES_PASSWORD=orders_history_password
ports:
- "5443:5432"
volumes:
- data:/var/lib/postgresql
networks:
- cqrs
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- '2181:2181'
networks:
- cqrs
kafka:
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- '9092:9092'
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CREATE_TOPICS: order_created_v1:1:1,goods_created_v1:1:1
networks:
- cqrs
volumes:
data:
networks:
cqrs:
Сервис order будет сохранять заказы в таблицу:
CREATE TABLE orders (
id BIGSERIAL PRIMARY KEY,
user_id BIGINT NOT NULL,
created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL
);И реализовывать эндпоинт для создания заказа:
func NewServer(db *pgxpool.Pool, kafkaProducer sarama.SyncProducer) Server {
s := Server{}
s.kafkaProducer = kafkaProducer
s.db = db
s.router = mux.NewRouter()
s.router.HandleFunc("/v1/order", s.CreateOrderV1).Methods(http.MethodPost)
return s
}Который обрабатывает создание заказа, сохраняет его в БД и шлет событие в топик order_created_v1:
обработчик CreateOrderV1
func (s Server) CreateOrderV1(w http.ResponseWriter, r *http.Request) {
err := r.ParseForm()
if err != nil {
log.Error().Err(err).Msg("Data hasn't been parsed.")
w.WriteHeader(http.StatusBadRequest)
return
}
userID := r.Form.Get("userId")
order := model.Order{}
err = s.db.QueryRow(context.Background(), `INSERT INTO orders (user_id, created_at) VALUES ($1, NOW()) RETURNING id, user_id, created_at`, userID).Scan(&order.ID, &order.UserID, &order.CreatedAt)
if err != nil {
log.Error().Err(err).Msg("Order hasn't been created.")
w.WriteHeader(http.StatusInternalServerError)
return
}
msg := model.CreatedOrderMsg{Data: order}
msgStr, err := json.Marshal(msg)
if err != nil {
log.Error().Err(err).Msg("Message hasn't been marshaled.")
w.WriteHeader(http.StatusInternalServerError)
return
}
producerMsg := &sarama.ProducerMessage{Topic: os.Getenv("ORDER_CREATED_TOPIC"), Value: sarama.StringEncoder(msgStr)}
_, _, err = s.kafkaProducer.SendMessage(producerMsg)
if err != nil {
log.Error().Err(err).Msg("Message hasn't been sent.")
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusCreated)
}Сервис goods реализуется аналогично. Таблица для хранения товаров заказов:
CREATE TABLE goods (
id BIGSERIAL PRIMARY KEY,
order_id BIGINT NOT NULL,
created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL
);Эндпоинт для создания товара в заказе:
s.router.HandleFunc("/v1/goods", s.CreateGoodsV1).Methods(http.MethodPost)И обработчик для создания товара в заказе и отсылки события в топик goods_created_v1:
обработчик CreateGoodsV1
func (s Server) CreateGoodsV1(w http.ResponseWriter, r *http.Request) {
err := r.ParseForm()
if err != nil {
log.Error().Err(err).Msg("Data hasn't been parsed.")
w.WriteHeader(http.StatusBadRequest)
return
}
orderID := r.Form.Get("orderId")
goods := model.Goods{}
err = s.db.QueryRow(context.Background(), `INSERT INTO goods (order_id, created_at) VALUES ($1, NOW()) RETURNING id, order_id, created_at`, orderID).Scan(&goods.ID, &goods.OrderID, &goods.CreatedAt)
if err != nil {
log.Error().Err(err).Msg("Goods hasn't been created.")
w.WriteHeader(http.StatusInternalServerError)
return
}
msg := model.CreatedGoodsMsg{Data: goods}
msgStr, err := json.Marshal(msg)
if err != nil {
log.Error().Err(err).Msg("Message hasn't been marshaled.")
w.WriteHeader(http.StatusInternalServerError)
return
}
producerMsg := &sarama.ProducerMessage{Topic: os.Getenv("GOODS_CREATED_TOPIC"), Value: sarama.StringEncoder(msgStr)}
_, _, err = s.kafkaProducer.SendMessage(producerMsg)
if err != nil {
log.Error().Err(err).Msg("Message hasn't been sent.")
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusCreated)
}БД сервиса order-history имеет следующую структуру:
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL
);
CREATE TABLE goods (
id BIGSERIAL PRIMARY KEY,
order_id BIGINT NOT NULL,
created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL,
FOREIGN KEY (order_id) REFERENCES orders (id)
);Сервис слушает события order_created_v1 и goods_created_v1 и записывает данные в свою БД:
обработка события order_created_v1
...
type OrderCreatedEvent struct {
Data struct {
ID int64 `json:"id"`
UserID int64 `json:"user_id"`
CreatedAt time.Time `json:"created_at"`
} `json:"data"`
}
func (oh OrderHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
oce := OrderCreatedEvent{}
err := json.Unmarshal(msg.Value, &oce)
if err != nil {
log.Error().Err(err).Msg("Event hasn't been handled.")
session.MarkMessage(msg, "")
continue
}
_, err = oh.db.Exec(context.Background(), `INSERT INTO orders (id, user_id, created_at) VALUES ($1, $2, $3)`, oce.Data.ID, oce.Data.UserID, oce.Data.CreatedAt)
if err != nil {
log.Error().Err(err).Msg("Event hasn't been inserted.")
}
session.MarkMessage(msg, "")
}
return nil
}
...обработка события goods_created_v1
...
type GoodsCreatedEvent struct {
Data struct {
ID int64 `json:"id"`
OrderID int64 `json:"order_id"`
CreatedAt time.Time `json:"created_at"`
} `json:"data"`
}
func (gh GoodsHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for msg := range claim.Messages() {
gce := GoodsCreatedEvent{}
err := json.Unmarshal(msg.Value, &gce)
if err != nil {
log.Error().Err(err).Msg("Event hasn't been handled.")
session.MarkMessage(msg, "")
continue
}
_, err = gh.db.Exec(context.Background(), `INSERT INTO goods (id, order_id, created_at) VALUES ($1, $2, $3)`, gce.Data.ID, gce.Data.OrderID, gce.Data.CreatedAt)
if err != nil {
log.Error().Err(err).Msg("Event hasn't been inserted.")
}
session.MarkMessage(msg, "")
}
return nil
}
...Сервис будет реализовывать эндпоинт получения данных:
s.router.HandleFunc("/v1/order-history", s.GetOrderHistoryV1).Methods(http.MethodGet)И сама реализация метода:
обработчик GetOrderHistoryV1
func (s Server) GetOrderHistoryV1(w http.ResponseWriter, r *http.Request) {
err := r.ParseForm()
if err != nil {
log.Error().Err(err).Msg("Data hasn't been parsed.")
w.WriteHeader(http.StatusBadRequest)
return
}
threshold := r.Form.Get("threshold")
offset := r.Form.Get("offset")
limit := r.Form.Get("limit")
rows, err := s.db.Query(context.Background(), `SELECT orders.id, orders.user_id, orders.created_at FROM orders
INNER JOIN goods ON goods.order_id = orders.id
GROUP BY orders.id
HAVING COUNT(goods.id) > $1
LIMIT $2 OFFSET $3`, threshold, limit, offset)
if err != nil {
log.Error().Err(err).Msg("Goods haven't been got.")
w.WriteHeader(http.StatusInternalServerError)
return
}
defer rows.Close()
data := make([]model.Order, 0)
for rows.Next() {
o := model.Order{}
sErr := rows.Scan(&o.ID, &o.UserID, &o.CreatedAt)
if sErr != nil {
log.Error().Err(err).Msg("Reading error.")
w.WriteHeader(http.StatusInternalServerError)
return
}
data = append(data, o)
}
ordersRsp := model.OrdersResponse{Data: data}
response, err := json.Marshal(ordersRsp)
if err != nil {
log.Error().Err(err).Msg("Response hasn't been marshaled.")
w.WriteHeader(http.StatusInternalServerError)
return
}
w.Write(response)
}Теперь мы без лишних накладных расходов можем выполнить запрос на получение заказов, в которых количество товаров больше 1.
curl 'http://localhost:8082/v1/order-history?limit=2&threshold=1&offset=0'
Таким образом, мы получаем данные без сложной обработки, вся логика получения данных и обработки реализована в сервисе order-history.
Для простоты мы реализовали только создание сущностей и чтение их в сервисе order-history. Реализация обновления данных может усложнить логику сервисов, т.к нужно поддерживать конкурентное обновление данных и как-то обрабатывать повторяющиеся события.
Полный листинг реализации данного функционала вы можете найти на моем github.
Заключение
Реализация шаблона CQRS позволяет эффективно разделить логику приложения: эффективно реализуются запросы и улучшить общее разделение ответственности
В модуле запросов можно использовать другие СУБД помимо PostgreSQL — в том числе и аналитические. Например, clickhouse или vertica. Также можно использовать NoSQL хранилища типа MongoDB или DynamoDB.
Несмотря на преимущества, CQRS влечёт за собой усложнение архитектуры (администрирование и обслуживание БД). Может появиться рассинхронизация между представлениями для БД команд и запросов. За этим тоже необходимо следить.
Модуль представлений сложен в обслуживании: проблемы конкурентного обновления данных и повторяющихся событий.
CQRS хорошо совместим с event sourcing.
Комментарии (8)

no_future
26.10.2021 23:32+1Имхо. CQRS как идея попахивает фанатизмом, мне больше нравится угол зрения «сложные запросы требуют специализированных СУБД».
Есть микросервисы-владельцы мастер-данных по товарам и заказам — отлично, значит, они знают обо всех изменениях товаров и заказов и могут паблишить эту информацию для всех желающих. Например, для микросервиса аналитических запросов по товарам-заказам.
Конечно, в нагрузку мы получаем дублирование данных в системе и риск их рассинхронизации, но это совсем другая история.

AlexSpaizNet
28.10.2021 15:20CQRS отличный паттерн. Особенно в связке с NoSQL базами. Позволяет создавать кайнд оф матириалайзд вьюз, просто на апликативной уровне а не на уровне базы (оракл, майкрософт). Как результат, позволяет не только строить независимые сервисы, но и быстрые и оптимизированные, потому что структура данных в базе заточена под определенные запросы.
Используем во многих местах, и пока довольны. Read сервисы получаются маленькими, оптимизированными, с предиктэбл перформансом, легко поддерживаемые и тестируемые.
Особенный профит в местах где количество запросов на чтение превосходит количество запросов на запись. Разделение ворклоада позволяет базе на запись не тормозить потому что с нее никто не читает и не нужно выделать ресурсы на чтение.
physics7
Патерн любопытный, но не совсем улавливаю смысл разделения сервисов с дополнительными базами. Это выглядит так - хочу избавиться от геморроя при помощи наждачки (извините за такое сравнение). Предположим, у меня крутятся REST сервисы (порядка 20 на данный момент) в среде кубрернетис кластера. Каждый из сервисов требует определенные ресурсы для своего контейнера, в котором он запускается. В рамках патерна CQRS мне необходимо разделить все сервисы на сервисы только чтения и на сервисы "изменения" данных, то есть увеличивается количество требуемых ресурсов в кластере уже для 40 сервисов плюс сервисы для синхронизации баз данных, да и, возможно, для самих БД.
На данном этапе мы решаем проблему "больших" объемов - пагинацией, то есть обработки данных порциями, при чем такая порционность приводит к возможности распараллеливания процесса.
Я ни в коем случае не критикую этот паттерн, просто хочу лучше понять когда его лучше использовать...
slava-a Автор
Паттерны должны решать проблемы, а не создавать их. Возможно, у Вас простая бизнес-логика приложения и паттерн действительно не применим, а только усложнит все.
А смысл его в повышении эффективности запросов на SELECT. Например, если какая-то бизнес логика с множественными JOIN'ами, группировками, агрегациями, то сервис агрегатор может невероятно усложниться и начать не справляться с таким по ресурсам.
Что касается параллельности: опять же, результат запроса с одного сервиса может использоваться для запроса в другой сервис. Тут уже нужно как-то убирать параллельность и получаем усложнение сервиса.
physics7
Спасибо за ответ. На мой взгляд этот паттерн применим в случае множественности источников создания (изменения) данных - например, датчики каких-либо данных, а вот для наблюдателя (анализатора) достаточно только чтение...
Вы правы, у нас нет настолько сложной логики в запросах...
Deosis
Паттерн вообще никак не связан с дроблением сервисов. Можно его реализовать и на одном сервисе.
Основная идея в том, что запросы только возвращают данные, а команды только меняют их.
boblgum
все ниже сказанное сугубо имхо
как я понимаю и преподношу CQRS это в первую очередь "смысловое" разделение бизнеса, его логики и соответственно исполнения. все основывается на том, что относительно "одни и те же данные" в разных контекстах, оказывается, совсем не обязательно "совместимы".
например, в разных контекстах условного онлайн-магазина данные пользователя магазином могут быть совершенно разными. для формирования заказа нужен адрес доставки, а для бухгалтерии эта информация совершенно неинтересна.
повышенная эффективность запросов данных это только второстепенный аспект. в первую очередь достигается чистота и порядок в данных нужных для реализации бизнеса в определенном контексте.
по отношению к REST данный паттерн также имеет преимущество в том, что он более соответствует реальности. так как коммуникация осуществляется путем конкретно определенных команд и запросов. каждая команда или запрос соответсвует определенному бизнес-кейсу. а вот REST относительно далек от бизнеса пытаясь "переписать" процессы с помощью жестко ограниченного набора глаголов.
ради забавы. попробуйте "понятно" описать в REST такой процесс как "расторжение договора" со всеми (ну, хотя бы несколько) истекающими из этого последствиями
onets
CQRS - разделение контекстов на чтение и запись. БД кстати на первых порах может быть тоже одна. Позже могут появится вьюхи/денормализация, которые будут отражены только в контексте на чтение. А еще позже можно выделить отдельную базу на отдельном сервере для построения отчетов например.
Оба эти контекста можно использовать и внутри одного сервиса. А можно и наплодить сервисов, как автор данной статьи.
Но что на самом деле в статье не рассмотрено, так это действительно сложная логика. И вот там начинается веселье. Лично у меня складывается мнение, что CQRS без «надстроек» подходит только, чтобы обернуть в запросы и команды select/insert/update/delete.