
Эффективное использование машинного обучения — сложная задача. Вам нужны данные. Вам нужен надёжный конвейер, поддерживающий потоки данных. И больше всего вам нужна высококачественная разметка. Поэтому чаще всего первая итерация моих проектов вообще не использует машинное обучение.
Что? Начинать без машинного обучения?
Об этом говорю не только я.
Догадайтесь, какое правило является первым в 43 правилах машинного обучения Google?
Правило №1: не бойтесь запускать продукт без машинного обучения.
Машинное обучение — это здорово, но для него требуются данные. Теоретически, можно взять данные из другой задачи и подстроить модель под новый продукт, но она, скорее всего, не справится с базовыми эвристиками. Если вы предполагаете, что машинное обучение придаст вам рост на 100%, то эвристика даст вам 50%.
Множество практиков машинного обучения, с которыми я проводил интервью в рамках проекта Applying ML, в ответ на этот вопрос тоже дают похожие ответы: «Представьте, что вам дали новую незнакомую задачу, которую нужно решить при помощи машинного обучения. Как вы подойдёте к её решению?»
«Для начала я приложу серьёзные усилия к тому, чтобы проверить, можно ли решить её без машинного обучения. Я всегда стремлюсь пробовать менее гламурные, простые вещи, прежде чем переходить к более сложным решениям». — Вики Бойкис, инженер ML в Tumblr
«Я думаю, что сначала важно выполнить задачу без ML. Решить задачу вручную или при помощи эвристик. Это заставит вас глубоко освоить задачу и данные, что является самым важным первым шагом. Более того, стоит получить точку отсчёта без ML, чтобы честно сравнивать показатели». — Хамел Хуссейн, ведущий инженер ML в Github
«Сначала попробуйте решить задачу без машинного обучения. Этот совет дают все, потому что он хорош. Можно написать несколько правил или эвристик if/else, чтобы принимать простые решения и действовать на их основе». — Адам Лаиакано, ведущий инженер платформы ML в Spotify
Тогда с чего начинать?
Вне зависимости от того, используете ли вы простые правила или глубокое обучение, всегда помогает достаточный уровень понимания данных. Поэтому возьмите выборку данных, чтобы собрать статистику и визуализировать её! (Примечание: в основном это относится к табличным данным. По другим данным, как то изображения, текст, звук и т.д., собирать статистику может быть сложнее.)
Простые корреляции помогают в выявлении связей между каждым признаком и целевой переменной. Затем можно выбрать подмножество признаков с самыми сильными связями, чтобы их визуализировать. Это не только помогает с пониманием данных и нашей задачи (а значит, и с более эффективным использованием машинного обучения), но и позволяет лучше освоить контекст предметной области бизнеса. Однако стоит заметить, что корреляции и собранная статистика могут вводить в заблуждения — иногда оказывается, что переменные, имеющие сильные связи, обладают нулевой корреляцией (подробнее об этом ниже).
Точечные диаграммы — любимый инструмент для визуализации числовых значений. Отложите признак на оси X, а целевую переменную — на оси Y, и взаимосвязь проявится сама. В показанном ниже примере температура имеет нулевую корреляцию с продажами мороженого. Однако мы видим чёткую связь на точечной диаграмме — с повышением температуры люди покупают больше мороженого, но выше определённой температуры становится слишком жарко и они просто не выходят из дома.
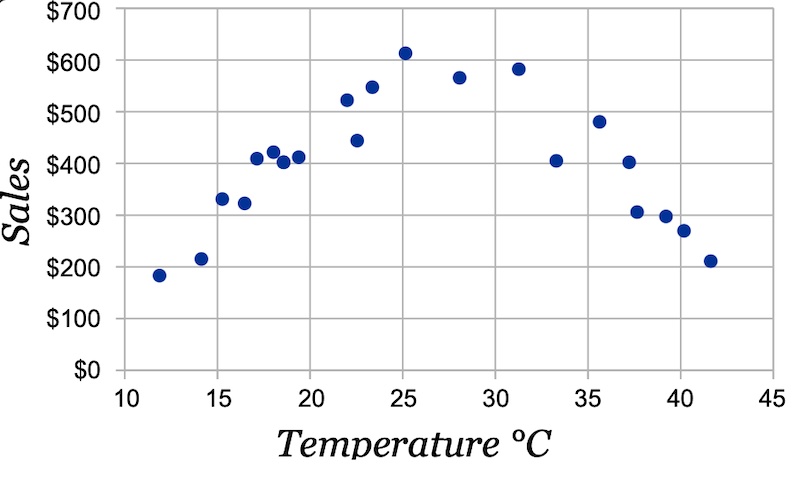
Точечная диаграмма непостоянной связи между температурой и продажами мороженого (источник)
Я выяснил, что если какая-то из переменных является категорийной, то хорошо подходят диаграммы типа «ящик с усами». Допустим, вы пытаетесь спрогнозировать срок жизни собаки — насколько важен её размер для этого параметра?
Ящик с усами срока жизни разных размеров пород собак (источник)
Имея понимание данных, мы можем начать решение задачи при помощи эвристик. Вот несколько примеров использования эвристик для решения часто встречающихся задач (вы удивитесь, насколько сложно их решить):
- Рекомендации: рекомендовать элементы с самыми лучшими показателями из предыдущего периода; также они могут быть сегментированы на категории (например, жанры или бренды). Если у вас есть поведение покупателя, то вы можете вычислить агрегированную статистику по совместному взаимодействию, чтобы вычислить схожесть элементов для рекомендаций i2i (см. здесь Swing Algorithm компании Alibaba).
- Классификация продуктов: правила на основе регулярных выражений для названий продуктов. Вот пример из классификатора продуктов Walmart (раздел 4.5): если название продукта содержит «ring», «wedding band», «diamond.», "*bridal", и т.д., то отнести его к категории колец.
- Выявление спама в обзорах: правила, основанные на количестве обзоров с одного IP, время публикации обзора (например, странная публикация в 3 часа ночи), схожесть (например, дистанция редактирования) между текущим обзором и другими обзорами, опубликованными в тот же день.
Многие люди также ответили на этот твит, предложив использовать в качестве точки отсчёта без машинного обучения регулярные выражения, межквартильный диапазон для выявления выбросов, скользящую среднюю для прогнозирования, создание словарей для сопоставления адресов, и т.д.
Действительно ли работают эти эвристики? Да! Меня часто поражает, насколько они эффективны, учитывая минимальные усилия, необходимые для их реализации. Вот пример того, как один простой список исключений позволил остановить скаммеров.
«Много лет назад у нас был похожий опыт. После блокирования скаммеры быстро создавали новые веб-сайты и ускальзывали от моделей, но продолжали использовать одни и те же изображения с одинаковыми именами файлов. Попались!». Джек Хэнлон (@JHanlon)
А вот ещё один пример, в котором регулярные выражения оказались лучше глубокого обучения.
«Меня за это так много критиковали. В одном проекте, над которым я работал, выполнялось сравнение строк, но заказчик был разочарован тем, что я не использовал нейросети, и нанял для этого кого-то другого. Угадайте, какой способ оказался точнее и дешевле?», — Митч Хейл (@bwahacker)
Да, вы можете сказать, что эти люди, обучавшие модели машинного обучения, не понимали, что они делают. Возможно. Тем не менее, смысл в том, что понимание данных и простые эвристики запросто могут проявить себя лучше, чем
model.fit(), и потратить на них придётся в два раза меньше времени.Эти эвристики также помогают с бутстреппингом разметки (weak supervision). Если вы начинаете с нуля и у вас нет разметки, weak supervision позволяет быстро и эффективно получить множество меток, хоть и низкого качества. Эти эвристики можно формализовать как функции разметки для генерирования меток. Другими примерами weak supervision являются использование баз знаний и заранее обученных моделей. Подробнее о weak supervision в Google и Apple можно прочитать здесь.
Когда же нужно использовать машинное обучение?
После того, как у вас появится точка отсчёта без ML с достаточно хорошими показателями, и объём усилий по поддержке и совершенствованию этой точки отсчёта перевешивает объём усилий по созданию и развёртыванию системы на основе ML. Сложно конкретно указать, когда это случается, но когда становится невозможно изменять ваши 195 созданных вручную правил без того, чтобы что-то не сломалось, то стоит задуматься о машинном обучении. Вот правило №3 из Правил ML компании Google.
Правило №3: выбирайте машинное обучение вместо сложной эвристики.
Простая эвристика может позволить выпустить продукт. Сложную эвристику невозможно поддерживать. После того, как у вас накопились данные и появилось базовое понимание того, что вы пытаетесь достичь, переходите к машинному обучению… и вы обнаружите, что модель машинного обучения проще обновлять и поддерживать.
Наличие надёжных конвейеров обработки данных и высококачественной разметки данных тоже дают понять, что вы готовы к машинному обучению. Но прежде чем это произойдёт, имеющиеся у вас данные могут быть недостаточно хороши для машинного обучения. Допустим, вам нужно снизить уровень мошенничества на вашей платформе, но вы даже не знаете, как выглядит мошенническое поведение, не говоря уже об отсутствии меток.
Или у вас могут быть данные, но в настолько плохом состоянии, что их невозможно использовать. Например, есть данные о категориях продуктов, которые можно использовать для обучения классификатора продукции. Однако продавцы намеренно ошибочно классифицируют продукты, чтобы обмануть систему (например, чтобы была установлена меньшая комиссия на определённые категории или чтобы проще обеспечить ранжирование в категориях с малым количеством товаров).
Часто для получения «золотого стандарта» набора данных с высококачественными метками требуется разметка вручную. При его наличии обучение и валидация работ по машинному обучению становятся намного проще.
Но что если мне нужно использовать ML ради самого ML?
Хм, тогда вы находитесь в сложном положении. Как обеспечить равновесие между решением задачи (удовлетворением требований заказчика) и тратой кучи времени и усилий просто ради самого ML? У меня нет ответа на этот вопрос, но я процитирую гениальный совет Брэндона Рорера.
«Совет по стратегии работы с ML
Когда у вас есть задача, создайте два решения — байесовский трансформер с глубоким обучением, работающий в многооблачном (multicloud) Kubernetes и SQL-запрос, построенный на основе стека чрезвычайно упрощающих допущений. Одно решение запишите в своё резюме, второе используйте в продакшене. И все будут довольны». — Брэндон Рорер (@_brohrer_)
Комментарии (11)

S_A
05.11.2021 16:14Вот я лично даже и близко не Алфабет или даже Вымпелком. Хотя правила относительно этого вопроса у меня тоже есть:
Ценны не модели, а в первую очередь связанные данные.
Ценны не модели, а их прогнозы.
Ошибки делает и обычный софт. Цена ошибки может быть сопоставима.
Нельзя заставлять людей гадать почему алгоритм поступил так. Объясняй принцип и рассказывай в каких случаях модель может ошибаться (и как).
ML неплохо моделирует явления замкнутых систем. ML часто может заменять решения одного человека. Иногда - множества, но с большей неопределенностью. Не стоит пытаться пробовать ML, когда нельзя оценить распределение предсказываемого или оно меняется без "физической связи".
Вообще, я не очень понял, в чем мысль. Что можно не пользоваться ML? Да не пользуйтесь, как-будто кто-то заставляет.
ML, собственно, это и есть извлечение эвристик из данных, и их последующая эксплуатация. Просто в зависимости от алгоритма, эвристик, различным образом сформулированных.
Так что все это, особенно для оператора, выглядит как пчелы против меда.

QtRoS
05.11.2021 16:43+7Да не пользуйтесь, как-будто кто-то заставляет
Кажется, Вы не до конца понимаете, какое сейчас происходит давление на бизнес а-ля "Если не примените ИИ, то конкуренты вас выдавят". Причем это какой-то абстрактный ИИ, серебряная пуля. А вот прикладное машинное обучение не все умеют готовить. Вот и получается, что даже адептам ML, вроде автора оригинальной статьи, приходится распространять идею начинать проекты без ML. Это помогает бизнесу не строить иллюзий о фантастических эффектах, рассматривать ИИ как инструмент решения точечных задач.
P.S. Есть штучные компании, у которых именно бизнес построен на ИИ. Я не о них.
P.S.S. Очень трудно сформулировать видение о положении дел в одном комментарии, хоть статью пиши.
S_A
05.11.2021 16:48-1"Если не примените ИИ, то конкуренты вас выдавят"
А может это просто здравая мысль? То есть всякое давление просто из-за хайпа, а хайп просто из-за магического вау-эффекта на неискушенных?
Я про то что ML выставлять карго-культом - тоже хайпожорство.
S_A
05.11.2021 18:15А вот конкретно видением я и сам могу поделиться, без всяких статей. Два типа ML-внедренцев,
Слышали звон (в том числе от консультантов каких), хотят, считают сначала экономический эффект, потом пытаются реализовать. Это часто индустриальный крупняк, который как инвестиционный проект рассматривает в том числе и ML.
"Доморощенный" (в хорошем смысле) ML. inhouse team, никаких подрядчиков.
Соотношение я бы сказал 50/50,. с вариациями на тему. Но все понимают ценность, пусть даже хоть и первые не в курсе, в чем механика эффекта, пытаясь извлечь его на бумаге и в пресс-релизах, кормя попутно неумеек интеграторов, которые бустят что в руки попадётся.
Развеивать мифы о русском ML, бессмысленном и беспощадно, стоило бы в таком ключе. А не сакральными откровенными со ссылками на гугл.

Dzhimsher
07.11.2021 12:06-1Мысль поста в том, что надо применять инструмент под задачу.
Для этого надо сначала разобраться в задаче, а не пытаться для 2 + 2 использовать квантовый компьютер )
S_A
08.11.2021 04:53Да, спасибо. До этого что "инструмент под задачу" никто не догадался помыслить.
Ведь все только и делают, что сетки заряжают, никто уже и код не пишет.
Dzhimsher
08.11.2021 11:06Как бы смешно это ни было, но именно так часто и происходит. Заказчики зачастую хотят увидеть использование не рационального инструмента для задачи, а именно сам факт использование инструмента
S_A
08.11.2021 16:14Конечно, ведь рациональными зачастую бывают только программисты, ведь часто только они знают решение задачи.
Я там выше по поводу карго-культа высказался уже. На третий вираж уже лень заходить.
Одно только добавлю - задач на данных, которые решаются без машинного обучения с теми же метриками, значительно меньше. Разница как между континуальными и счетными множествами. Формул, как комбинаций символов, счетное число, а функций - пусть из того же C[0, 1] - континуально.
Это также означает что с ростом поступающих данных (без оверфита) ML-модели будут работать с определённым качеством, а эвристики точно хуже.
Но это волнует только исследователей. И еще тех, у кого данных много. Например как у какого-нибудь сотового оператора.
Dzhimsher
08.11.2021 16:53Проблема не в рациональности. А в осведомленности. И большинство заказчиков банально не понимают, что им надо.
И цель таких статей не "общение с себе подобными", а просвещение заказчиков. И выиграют от этого все. В том числе исполнители

Ok_Lenar
07.11.2021 10:33+1При большом количестве данных и требуемом большом количестве решений используйте AI.
При большом количестве данных и требующихся конкретных из них выводов используйте статистический анализ.
При недостаточном количестве данных и требующихся из них выводах используйте аналитику.
Это будет рационально с любых точек зрения.
monane
) Вы зачем смеетесь? Ну дали детям микроскоп ну ударили они им по столу, ну тяж0лый дааа/