Вводная часть
Проблема скорости поиска
Прежде чем перейти к основной теме имеет смысл взглянуть на проблему со стороны.
Сколько кадров содержит среднестатистический видео фильм?
Сколько фильмов должно быть в базе данных, чтобы пользователи начали пользоваться данным сервисом?
Попробуем ответить на эти вопросы.
150 000 кадров — содержит среднестатистический фильм.
1 000 000 видео — столько должна содержать современная база данных, чтобы быть востребованной.
В нашей базе данных должно быть порядка 150 миллиардов кадров. Это очень много! Как осуществить поиск за доли секунды по такой огромной таблице?
Поисковый алгоритм «VideoColor»
Технология поиска «VideoColor» заключается в том, что каждый кадр в видео рассматривается как отдельное изображение по которому может вестись поиск. Индексируемое, а затем и искомое изображение, делится на табличные области и в каждой из её ячеек находятся усреднённые значения компонент красного, зелёного и синего цветов. По ним, в дальнейшем, можно производить сравнение для нахождения искомого кадра.

Решение проблемы
Использование хэшей для ускорения поиска
Для решения вышеописанной проблемы есть решение и оно заключается в использовании хэшей. Хэш — это некоторое число, которое получается путём применения хэш-функции к исходным данным. Использование хэшей даст нам возможность ускорить поиск нашего кадра в огромном массиве информации.
В качестве исходных данных можно использовать усреднённые значения RGB определённых областей заданного изображения. А сам хэш можно сделать 32-битовым беззнаковым целым числом.
Проблема неоднозначности хэшей
Позиции значений
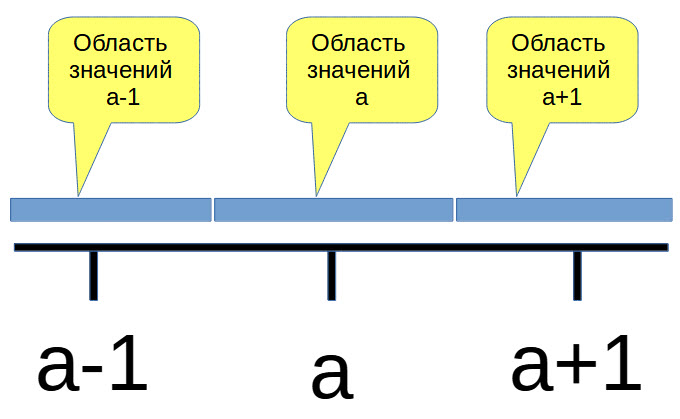
При вычислении хэшей нам необходимо привести усреднённое значение к целому числу, а вот здесь возможны неприятности.
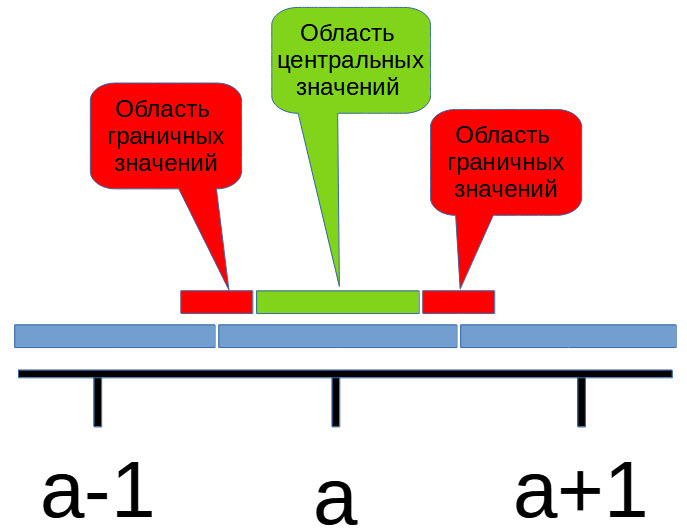
Поскольку при перекодировании видео под разное разрешение или битрейт получаемые при просмотре кадры немного отличаются от оригинала, то может случиться следующее. Хэш от исходного изображения, возможно, будет отличаться от хэша перекодированного изображения. Это связано с тем, что усреднённые значения в пограничных областях могут изменяться в большую или меньшую стороны (пусть даже на небольшую величину) и мы можем получить вместо a значение a+1.
Кроме того, при захвате или экспорте кадра из видео в формат JPEG или другой формат (с потерями) происходит дополнительное изменение исходного кадра.
В результате мы получаем неоднозначность хэшей от различных версий кадров одного и того же видео. Это серьёзная проблема!
Использование массива хэшей
Удваивание хэшей
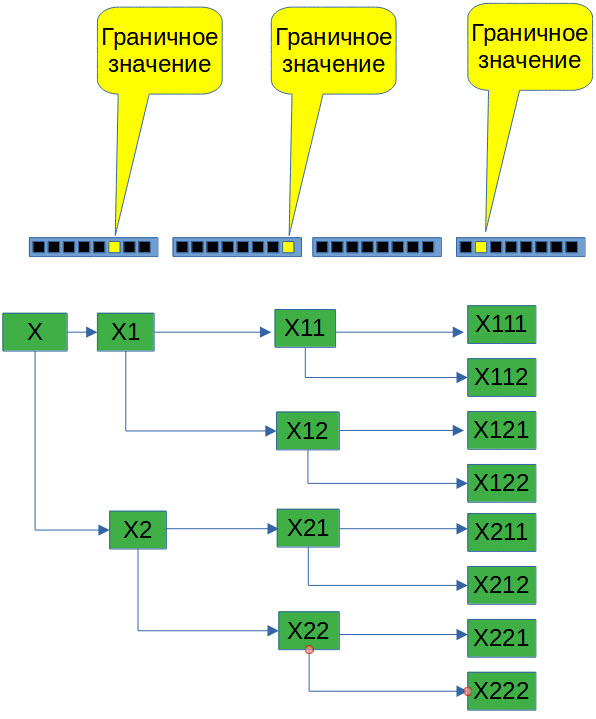
Для решения проблемы неоднозначности хэшей можно применить следующий подход. Если проанализировать входные значения, то можно увидеть, что они занимают либо центральные (близкие к центру) позиции или граничные позиции. В этом случае можно сделать предположение, что мы получили вилку значений и от одного значения хэша мы переходим к двум значениям и т. д. На каждом таком пограничном случае мы удваиваем количество хэшей, причём каждому присваиваем определённое значение вероятности.
Да, мы усложняем алгоритм поиска и многократно увеличиваем время поиска. Скользкий путь, но, попробуем пойти по нему дальше.
Вероятности хэшей
Если бы у всех значений из массива хэшей были бы равные вероятности, то нам пришлось бы в процессе поиска осуществлять поиск по всем хэшам. Если хэши имеют разную вероятность, то мы можем в первую очередь осуществлять поиск по более вероятным. И в случае нахождения кадра с минимальными отклонениями в узловых точках имеем право считать, что поиск успешен, а оставшиеся хэши просто игнорировать. Тем самым существенно ускоряем процесс поиска.
Проблема неравномерного распределения хэшей по адресному пространству
Как устроен индексный хэш?
Если каждой записи в таблице присвоить добавить новое поле - хэш, то можно его использовать как индекс для поиска. К сожалению, это потребует дополнительных затрат на индексацию и мы поступим по-другому. Создадим индексный файл, каждая ячейка которого будет содержать ссылку на запись в таблице с данными. А сами данные упорядочим таким образом чтобы внутри одной группы были записи с одинаковым индексным хэшем, причём эти группы упорядочены по значению хэша.
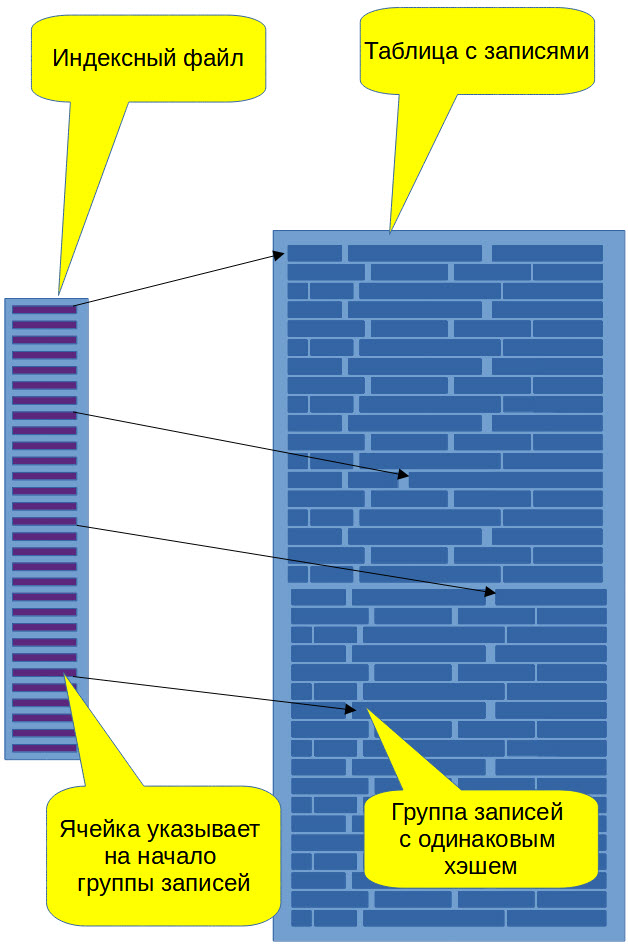
В этом случае, когда нам понадобится найти данные с заданным значением хэша (индекса), мы просто читаем поле с этим индексом из индексного файла (а также последующее поле, чтобы узнать количество записей с этим значением индекса). А затем, имея номер нулевой записи группы в таблице с записями читаем необходимые записи из таблицы записей.
Распределение по частоте индексного хэша
В идеале, если распределение записей более менее равномерное, мы получим, что для 150 миллиардов записей в каждой индексной ячейке будет приблизительно
150 000 000 000 / 4 000 000 000 = 38 записей.
Однако, в реальности дела обстоят не так радужно. Если построить гистограмму распределения, то она будет выглядеть приблизительно так.

Пики соответствуют наиболее частым значениям. Это, например, может быть значение (R=0, G=0, B=0) и оно по частоте может достигать 3-5% от общего количества кадров. В этом случае необходимо использовать другие механизмы ускорения поиска внутри группы, например, перцептивные хэши.
Выводы
Для ускорения поиска кадров в базе данных отлично подходят индексные хэши. С их помощью можно многократно ускорить процесс поиска. Хотя проблема неоднозначности хэшей вынуждает нас осуществлять поиск не по одному, а по целой группе хэшей, тем не менее «игра стоит свеч».
Ссылки по теме
Комментарии (4)

sim2q
14.11.2021 18:42Мы такое в бытность начала p2p для mp3 пробовали придумать. Когда даже альбом лишний было было вытащить накладно. Тоже - база фреймов. Но закончилось всё на уровне
накурились-помечталимозгового штурма и будучи дилетантами упёрлись, что каждый блок фрейм будет начинать с рандомного места. Сейчас бы наверное можно попробовать привязываться к BPM (для электронной музыки с битом).
Для торрентов кстати тоже актуально, но вроде уже решили в новой версии - отдельным хэшем для каждого файла.
ps извиняюсь, что сумбурно - последствия тех времён)
amarao
Мне кажется, у вас плохая хеш-функция. Хорошая хеш-функция на всём массиве данных должна давать более равномерное распределение.
Имея на руках такую базу, можно вполне серьёзно коммитнуться в поиск хорошей хэш-функции для изображения.
Алсо, 32-битное число - плохо. Это всего 4 миллиарда вариантов, а у вас одних кадров 150 миллиардов. Берите u64 или u128 как основу.
Из базовых эвристик: я бы сделал отдельный if если картинка очень чёрная (там вечно титры ползут), т.е. если общая яркость кадра меньше какой-то величины, то используется другая функция (которая, например, пытается найти опорные точки в качестве источника для генерации значения).
Возможно, если видео кропнуть на 20% и пережать в разрешение 8x8, то после сжатия чем-то типа mjpeg, получившееся будет само по себе неплохим хешем.
aapsoftware Автор
Спасибо за развёрнутый комментарий!
По-поводу хэш функции: тут, не столько она плоха, сколько сами данные. Здесь я должен извиниться и сказать, что в данной публикации не описал механизм получения исходных данных для вычисления хэша, а они получаются путём загрубления значений R,G,B.
R'=R/8; G'=G/8; B'=B/8;
Иначе флуктуации значений (от пережатых версий видео или JPEG компрессии скриншотов) будут зашкаливать.
Самое большое количество кадров приходится на значения R=G=B=0. Потом R=G=B=255, ну и дальше - градации серого.
Что касается 32 битного целого, то тут ситуация такова. То, что кадров больше, чем значений хэша - в этом нет ничего плохого. Просто когда мы ищем наш кадр, мы анализируем группу с этим значением хэша. Если их там несколько десятков, то мы их быстро проанализируем. Даже если несколько сотен, то на SSD всё летает. Проблема, когда их тысячи и больше. А в выше упомянутых ячейках R'=G'=B'=0 их в той базе может быть несколько миллиардов, что уже очень плохо. Но, плюс U32 в том, что база указателей имеет фиксированный размер в 32 ГБ и она по первому же fseek'у и read'у даёт нам место, где читать данные уже в файле с записями и сколько их читать! Для U64 файл указателей будет нереально большой. Кроме того, это потребует много аппаратных и вычислительных ресурсов при перестроении данных (если мы добавим информацию о новых видео).
Всё же поиск в отдельных случаях требует дополнительного ускорения и я для этого использую перцептивные хэши (об этом в следующей публикации). Как я их использую? Внутри группы с конкретным индексным хэшем данные сортируются по перцептивному хэшу. Получается двойное механизм индексации. Это реально помогает, хотя там есть некоторые нюансы. И, несмотря на это, для некоторых значений R'=G'=B'=0 и некоторых других внутри данной группы могут быть очень длинные подгруппы с одинаковым значением перцептивного хэша. Вот такие цепочки я отбрасываю.
Что касается последнего Вашего замечания, то я его не понял. Хэш я вычисляю для каждого кадра, а mjpeg используется для видео (т.е. множества кадров).
amarao
Я понял. У вас проблема не с коллизиями, наоборот, вам важно key space для хеш-таблицы. Кстати, попробуйте положить данные в clickhouse, он ОЧЕНЬ хорошо умеет хера ... обабатывать большие объёмы данных.
насчёт mjpeg: mjpeg это такой 'jpeg для фильмов', т.е. он не учитывает предыдущие/последующие кадры. Грубо говоря, что я предлагал: пережать видео в микроскопический формат, так, чтобы каждый кадр занимал 128 бит, и использовать его как хеш для оригинального кадра.
Впрочем, ваш concern про количество возможных seek'ов понятен.