Вводная часть
Что такое перцептивные хэши?
Перцептивное хеширование - это использование алгоритма, который создает фрагмент или отпечаток пальца различных форм мультимедиа. (Источник)
Есть хорошая статья на Habr’е с которой можно ознакомиться здесь.
Для чего можно использовать перцептивные хэши?
Для ускорения поиска записей, как обычные индексы. Этим можно многократно увеличить скорость поиска. Ну что ж, этим и займёмся.
Несколько слов о базе данных видео кадров «VideoColor»
База данных видео кадров «VideoColor» предназначена для быстрого поиска названий видео фильмов, а также позиции кадров в видео. В перспективе её создатели хотят довести количество проиндексированного видео до 1 000 000 файлов.
Структура записей в базе данных «VideoColor»

На картинке видно, что все записи упорядоченны по значению индексного хэша (синие группы). Внутри каждой группы есть подгруппы (выделены зелёным цветом), где записи имеют одинаковое значение перцептивного хэша.
Практическое использование
На приведённом ниже изображении можно видеть, как из таблицы 11x7 выбирается 32 центральных элемента (выделены серым цветом). Их можно использовать для построения перцептивного хэша размером 4 байта. В некоторых случаях этого вполне достаточно. Разумеется, Вы можете использовать и любые другие схемы.
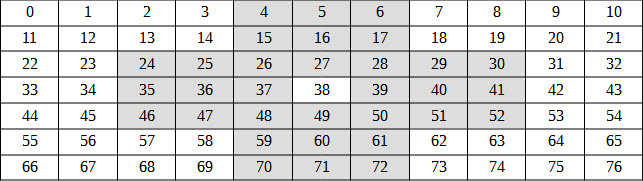
Итак, мы находим средние значения сумм R, G, B в указанных областях, подсчитываем среднее значение для всех выбранных областей S и если оно больше S, то считаем текущий бит равным 1, в противном случае равным 0.
Проблема использования перцептивных хэшей
Существует проблема неоднозначности перцептивных хэшей связанная с тем, что в некоторых точках значения имеют пограничные значения.
Позиции значений
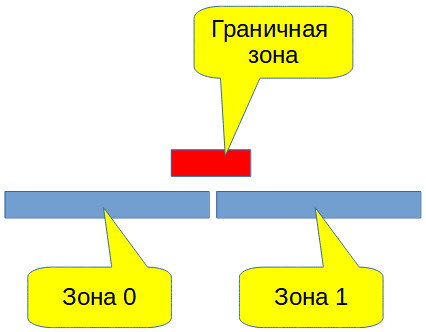
При вычислении хэша нам необходимо привести усреднённое значение либо к 0 либо 1, и здесь возможны неприятности.
Поскольку при перекодировании видео под разное разрешение или битрейт получаемые при просмотре кадры немного отличаются от оригинала, то может случиться следующее. Значение в той или иной точке будут различны для двух схожих изображений. Это приведёт к тому, что значения перцептивных хэшей будут разные. А это, в свою очередь, приведёт к тому, что мы гарантированно не найдём искомый кадр.
Всё пропало!
Генерация массива хэшей
Для решения проблемы связанной с граничными значениями мы поступим следующим образом. Во всех случаях, когда будут встречаться значения в граничной зоне мы будем удваивать хэши, причём в первой группе будут хэши с 0 в данной позиции, а во второй группе будут хэши с 1 в данной позиции. В результате, мы будем осуществлять большее количество поисковых операций, но другого выхода нет. Из минусов — таких удвоений может быть 32. Из плюсов — это не такое уж частое событие и обычно (в среднем) бывает 2-3 удвоения (т. е. 4 или 8 хэшей). Ситуации, когда удвоений становится слишком много, мы можем считать аварийными и в этом случае принудительно ограничивать их количество 6-7.
Использование диапазона хэшей в случае их большого количества
Другой приём позволит нам использовать перцептивные хэши более экономично. Например, мы можем производить поиск не по конкретному значению, а по диапазону значений (min,max). В случае если граница диапазона невелика разница между min и max небольшая, то и размер группы для сравнения с образцом будет небольшой. Тем самым можно полностью избавиться от проблемы с удвоением массива хэшей для младших битов (вполне можно использовать последние 8 бит).
Выводы
Мы использовали перцептивные хэши с целью ускорения поиска кадра в базе данных, а именно для ускорения поиска в группе с заданным индексным хэшем. В тех случаях, когда в группе очень много записей, использование дополнительного поиска с учётом перцептивного хэша существенно ускоряет процесс.