Disclaimer: в этой статье будет очень много бредовых примеров и сверх очевидных утверждений. Если для вас предельно очевидно, что ... внутри .reduce даёт вам O(n^2), то можно сразу прыгать к разделу "Критика" или просто проигнорировать статью. Если же нет, милости прошу под cut.
Предисловие
Все мы знаем про стандартную конструкцию for (;;) которая чаще всего, в реальном коде, имеет примерно такой вид:
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
// ...
}Далеко не все из нас любят ей пользоваться (только давайте обойдёмся без холиваров на эту тему, статья не об этом), особенно в простых сценариях, т.к. когнитивная нагрузка довольно высока ― очень много малозначительных или даже ненужных деталей. Например в таком вот сценарии:
const result = [];
for (let idx = 0; idx < arr.length; ++ idx) {
const item = arr[idx];
result.push(something(item));
}
return result;Большинство из нас предпочтёт более компактную и наглядную версию:
return arr.map(something);
// или
return arr.map(item => something(item)); note: 2-й вариант избавит вас от потенциальных проблем в будущем, когда something может внезапно обзавестись вторым аргументом. Если он будет числовым, то даже Typescript вас не убережёт от такой ошибки.
Но не будем отвлекаться. О чём собственно речь?
Всё чаще и чаще мы видим в живом коде такие методы как:
.forEach.map.reduceи другие
В общем и в целом они имеют ту же bigO complexity, что и обыкновенные циклы. Т.е. до тех пор, пока речь не заходит об экономии на спичках, программист волен выбирать ту конструкцию, что ему ближе и понятнее.
Однако всё чаще и чаще вы можете видеть в обучающих статьях, в библиотечном коде, в примерах в документации код вида:
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);или даже:
return Object
.entries(object)
.reduce(
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
}),
{}
);Возможно многие из вас зададутся вопросом: а что собственно не так?
Ответ: вычислительная сложность. Вы наблюдаете разницу между O(n) и O(n^2) .
Давайте разбираться. Можно начать с ... -синтаксиса. Как эта штука работает внутри? Ответ: она просто итерирует всю коллекцию (будь то элементы массива или ключи-значения в объекте) с 1-го до последнего элемента. Т.е.:
const bArray = [...aArray, 42]это примерно тоже самое, что и:
const bArray = [];
for (let idx = 0; idx < aArray.length; ++ idx)
bArray.push(aArray[idx]);Как видите, никакой магии. Просто синтаксический сахар. Тоже самое и с объектами. На лицо очевидная сложность O(n).
Но давайте вернёмся к нашему .reduce. Что такое .reduce? Довольно простая штука. Вот упрощённый полифил:
Array.prototype.reduce = function(callback, initialValue) {
let result = initialValue;
for (let idx = 0; idx < this.length; ++ idx)
result = callback(result, this[idx], idx);
return result;
}Наблюдаем всё тот же O(n). Уточню почему - мы пробегаем ровно один раз по каждому элементу массива, которых у нас N.
Что же тогда у нас получается вот здесь:
return source.reduce(
(accumulator, item) => accumulator.concat(...something(item)),
[]
);Чтобы это понять надо, ещё посмотреть, а что такое .concat. В документации вы найдёте, что он возвращает новый массив, который состоит из переданных в него массивов. По сути это поэлементное копирование всех элементов. Т.е. снова O(n).
Так чем же плох вышеприведённый код? Тем что на каждой итерации в .reduce происходит копирование всего массива accumulator. Проведём мысленный эксперимент. Заодно упростим пример (но проигнорируем существование .map, так как с ним такой проблемы не будет):
return source.reduce(
(accumulator, item) => accumulator.concat(something(item)),
[]
);Допустим наш source.length === 3. Тогда получается, что .reduce сделает 3 итерации.
На 1-й итерации наш
accumulatorпуст, поэтому по сути мы просто создаём новый массив из одного элемента.// []на 2-й итерации наш
accumulatorуже содержит один элемент. Мы вынуждены скопировать его в новый массив.// [1]на 3-й итерации уже 2 лишних элемента.
// [1, 2]
Похоже на то, что мы делаем лишнюю работу. Представьте что length === 1000. Тогда на последней итерации мы будем впустую копировать уже 999 элементов. Напоминает алгоритм маляра Шлемиля, не так ли?
Как нетрудно догадаться, чем больше length , тем больше лишней работы выполняет процессор. А это в свою очередь:
замедляет программу
т.к. Javascript однопоточный - препятствует работе пользователя с UI
тратит батарейку ноутбука или телефона на бесполезную работу
греет ваше устройство и заставляет работать кулер
В случае объектов ситуация ещё хуже, т.к. там речь идёт не о быстрых массивах, которые имеют многоуровневые оптимизации, а о dictionaries, с которыми, если кратко, всё сложно.
Но что можно с этим поделать? Много чего. Самое главное - переиспользовать тот же самый массив\объект:
// вместо
(accumulator, item) => accumulator.concat(...something(item))
// вот так
(accumulator, item) => {
accumulator.push(...something(item));
return accumulator; // это ключевая строка
}// вместо
(accumulator, value, key) => ({
...accumulator,
[key]: something(value)
},
// вот так
(accumulator, value, key) => {
accumulator[key] = something(value);
return accumulator;
}Стало чуть менее нагляднее (возможно), но разительно быстрее. Или нет? Давайте разбираться.
Как я уже сказал выше, всё зависит от размера коллекции. Чем больше итераций, тем больше разница. Я провёл пару простых тестов в Chrome и Firefox:
Firefox
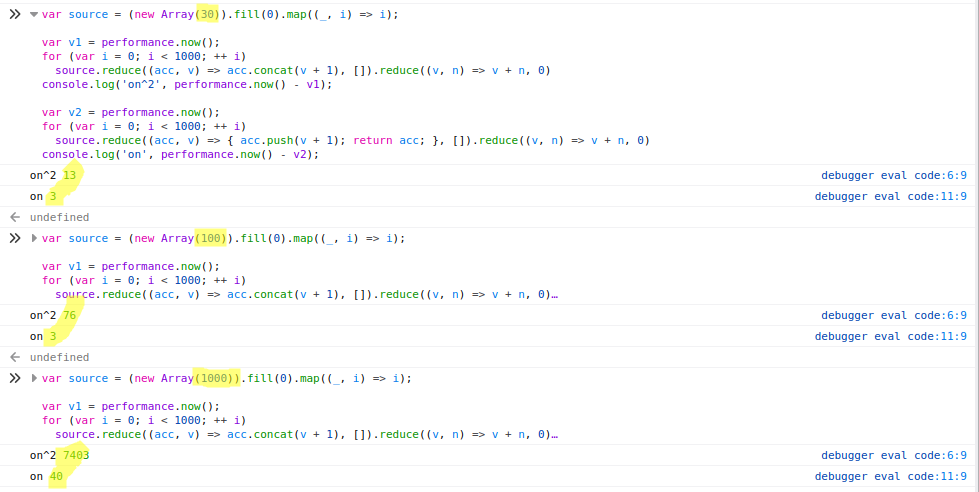
Chrome

При length=30 разница не очень убедительная (13 vs 3). При length=1000 уже становится особенно больно (2600 vs 30).
Критика
Я понимаю, что к этому моменту будет уже много недовольных моими обобщениями. Простите, я попытался написать максимально просто. Но давайте пройдёмся по наиболее популярным аргументам против:
1. При малых N вы не заметите разницу
Что же, это valid point. Если N=3, то разница столь невелика, что едва ли вы хоть когда-нибудь столкнётесь с её последствиями. Правда ваши друзья из мира C++ перестанут с вами здороваться. Особенно в мире Javascript, который как известно скриптовый язык с динамической типизацией, и, поэтому, не предназначен для решения задач, которые требуют настоящей производительности. Что впрочем не мешает ему проникать даже в эти отрасли, вызывая потоки гнева
А что если у нас не 3 элемента, а скажем 30. На моих синтетических "наколеночных" тестах получилась разница в 4 раза. Если этот участок кода выполняется единожды, а не, скажем, в цикле, то вы, скорее всего, точно также не сможете ничего заметить. Ещё бы, ведь речь идёт о долях миллисекунды.
Есть ли тут подводные камни? На самом деле да. Я бы сказал, что тут возможны (как минимум) две проблемы.
Первая проблема: сегодня ваш код исполняется единожды. Завтра вы запускаете его для какого-нибудь большого списка. Скорее всего даже не заглянув внутрь (в больших проектах это может быть очень непросто). В итоге та изначально небольшая разница, может начать играть весомую роль. И моя практика показывает, что
хочешь рассмешить бога, расскажи ему о своих планахмы слишком часто ошибаемся в своих суждениях относительно того, как наш код будет использоваться в будущем.Вторая проблема: у вас ваш код запускается для 30 элементов. Okay. Но среди ваших пользователей есть 5% таких, у которых немного нестандартные потребности. И у них уже почему-то не 30, а 300. Кстати, возможно эти 5% пользователей делают 30% вашей выручки.
Приведу пример. На немецком сайте Ikea (надеюсь они это уже исправили) была проблема: при попытке купить больше 10-12 товаров корзина заказа начинала настолько люто тормозить, что почти любая операция с ней сводилась к 40 секундным задержкам. Т.е. до глупого забавная ситуация: человек хочет купить больше, т.е. отдать компании больше денег, но т.к. где-то внутри сокрыты алгоритмы маляра Шлемиля, он не может этого сделать. Полагаю разработчики ничего об этом не знали. И QA отдел тоже (если он у них есть). Не переоценивайте ваших посетителей, далеко не каждый будет готов ждать по 40 секунд на действие. Признаю, что пример экстремальный. Зато показательный.
Итого: в принципе всё верно. Для большинства ситуаций вы и правда не заметите разницы. Но стоит ли это того, чтобы экономить одну единственную строку? Ведь для того, чтобы избежать этой проблемы, не требуется менять алгоритм, не требуется превращать код в нечитаемый ад. Достаточно просто мутировать итерируемую коллекцию, а не создавать новую.
По сути всё сводится к: каковы мои трудозатраты и каков мой результат. Трудозатраты - одна строка. Результат - гарантия того, что у вас не возникнут "тормоза" на абсолютно ровном месте.
2. Чистые функции в каждый дом
Кто-то может возразить, что пока мы возвращаем в каждой итерации новый массив наша функция чиста, а как только мы начинаем в ней что-нибудь мутировать, мы теряем драгоценную purity. Ребята, любящие FP, у меня для вас замечательная новость: вы можете сколько угодно мутировать в своих чистых функциях state. Они от этого не перестают быть чистыми. И тут в меня полетели камни.
Да, это не шутка (собственно настоящие FP-ы об этом прекрасно знают). Ваша функция должна удовлетворять всего двум критериям, чтобы оставаться чистой:
быть детерминированной
не вызывать side effect-ов
И да, мутация это effect. Но обратите внимание на слово "side". В нём вся соль. Если вы мутируете то, что было целиком и полностью создано внутри вашей функции, то вы не превращаете её в грязную. Условно:
const fn = () => {
let val = 1;
val = 2;
val = 2;
return val;
}Это всё ещё чистая функция. Т.к. val существует только в пределах конкретного вызова метода и он для неё локален. А вот так уже нет:
let val = 1;
const fn = () => {
val = 2;
return val;
}Т.е. не нужно идти ни на какие сделки с совестью (а лучше вообще избегать всякого догматизма), даже если чистота ваших функций вам важнее чистоты вашего тела.
3. Умный компилятор всё оптимизирует
Тут я буду краток: нет, не оптимизирует. Попробуйте написать свой, и довольно быстро поймёте, что нет никакой магии. Да внутри v8 есть разные оптимизации, вроде этой (Fast_ArrayConcat). И да, они не бесполезны. Но не рассчитывайте на магию. Увы, но мы не в Хогвартсе. Математические законы превыше наших фантазий.
По сути для того чтобы избежать O(n^2) в такой ситуации, компилятору необходимо догадаться, что сия коллекция точно никому не нужна и не будет нужна в текущем виде. Как это гарантировать в языке, в котором почти ничего нельзя гарантировать (из-за гибкости и обилия абстракций)?
Причина
Зачем эта статья? От безысходности и отчаяния. Мне кажется основной причиной этой широко распространённой проблемы является React и Redux, с их любовью к иммутабельности. Причём не сами эти библиотеки, а различные материалы к ним (коих тысячи), где встречается этот "паттерн". Если по началу это можно было объяснить тем, что хочется приводить максимально простые примеры, то сейчас это стало mainstream-ом.
Вот например:
PS: coming-out - часто делаю concat внутри reduce ???? в 99% задач вроде не сильно афектит
Или вот:
getDependencies(nodes) {
this.processQueue();
return nodes.reduce(
(acc, node) => acc.concat(Array.from(this.dependencies.get(node) || [])),
[]
);
}I'm pretty surprised that this has any impact, I don't have a good rationale for why but it appears to be dramatically faster to update the array in place.
Складывается ощущение, что этот "паттерн" применяется почти в каждой второй статье про Javascript. Я думаю настало время что-то с этим делать. Люди на собеседованиях не видят никакой проблемы в вызове .includes внутри .filter и подобных штуках. ...-синтаксис по их мнению работает за O(1). А v8 переполнен магией. Люди с 7-ю+ годами боевого опыта делают удивлённые глаза и не понимают, что может пойти не так. Впрочем это уже другая история.
P.S. по вопросам опечаток и стилистических ошибок просьба обращаться в личку.
Комментарии (336)

Drag13
22.11.2021 15:16+7Хороший пост, спасибо. Я бы еще добавил что часто такая проблема возникает в Реакте когда мы рендерим списки из БД потому что
* Мы вызываем этот On2 на каждый рендер
* Рендеры происходят часто
* Списки из базы имееют тенденцию к росту.И вот то что у дева не тормозит (потому что на тестовой базе 10 записей и дев машина сильнее среднестатистической) на проде уже лагает или даже ощутимо вешает юай.

Alexandroppolus
22.11.2021 16:57В Реакте - смотря как реализовано. Допустим, есть массив каких-то объектов, и мы по нему рендерим список. Когда в массиве что-то добавляется или удаляется, то будет перерендер списка, но не будет перерендера каждого элемента (при условии, что не забыли React.memo для элементов). Когда обновляется итем, то в иммутабельном стиле (Редукс и т.д.) тоже будет перерендер списка, а с МобХ уже не будет (если, конечно, элементы списка обернуты в observer и получают итем с наблюдаемыми полями).

eeeMan
23.11.2021 11:26-2не будет перерендера не потому что memo а потому что используешь key правильно

faiwer Автор
23.11.2021 11:27+3На всякий случай уточню — вы же в курсе что правильно выставленный
keyне спасет от re-render-а? Я даже больше скажу, он с ним не связан. Key в React и Vue нужен для сопоставления элементов в списках. Он не используется в целях мемоизацииeeeMan
23.11.2021 12:01я про то, что кей не даст перерендера элементами массива если они не изменились

mayorovp
23.11.2021 12:11А вам говорят про то, что сам массив в любом случае будет рендерится при каждом своём изменении. И этот рендер работает в лучшем случае за O(N), где N — длина массива, а в обсуждаемом случае — за O(N2)
faiwer Автор
23.11.2021 12:11+1Слишком много опечаток в комментарии. Я не понимаю его смысла. Key не даст перерендерить элементы массива если они не изменились? Даст.
eeeMan
23.11.2021 12:12-3нет
faiwer Автор
23.11.2021 12:20Запустите это
import React from "react"; import "./styles.css"; const Inner = () => { console.log('render Inner'); return <div>inner</div>; } export default function App() { const [, setState] = React.useState({}); return (<div> <Inner key="key"/> <button onClick={() => setState({})} > rerender Outer </button> </div>); }eeeMan
23.11.2021 12:24-9щас бы в качестве ключа использовать "key", ты хоть почитай или видео посмотри какие-то про работу реакта) а то прям не совсем слабенько
faiwer Автор
23.11.2021 12:36+10Честно говоря я не очень рекомендую смотреть видео. Я всегда предпочитал первоисточник. В случае React он здесь. Рекомендую прочитать от корки до корки её всю (не эту статью, а всю документацию). Сейчас вы говорите глупости, ввиду полного непонимания предметной области.
faiwer Автор
23.11.2021 12:55+19Я понимаю. И знаете мы бы сэкономили друг другу уйму времени. Потому что я бы не справился с вашим обучением. Одно дело когда человек чего-то не знает. Но совсем другое дело когда человек в своём невежестве воинственнен.

nin-jin
23.11.2021 14:27Что-то я не пойму, почему Inner ререндерится? У него же пропсы не меняются.
Drag13
23.11.2021 14:30+2Функциональные компоненты ре-рендеряться всегда, даже если их пропсы не менялись
nin-jin
23.11.2021 14:38+5Какой зашквар....

А как сделать, чтобы не ререндерились, если пропсы не поменялись? Ну, кроме прикручивания мобх.
Drag13
23.11.2021 14:46+2Reac.memo для функциональных компонентов
React.PureComponent для классовых
UPD под всегда я имел ввиду всегда когда перерендеривается родитель.
Alexandroppolus
23.11.2021 19:38+1Ну, кроме прикручивания мобх.
МобХ в этом плане ничего особого не дает, его декоратор observer дополнительно работает ещё и как React.memo - чтобы не надо было заморачиваться и вешать два декоратора, да и вспоминать какой сначала а какой потом. Зато, в отличии от того же редукса, позволяет экономить ререндеры родительских компонентов, если мутабельно менять что-то в объекте, за некоторыми исключениями.
Alexandroppolus
23.11.2021 12:20Не будет перерендера дома, но будет перерендер виртуального дома. В рамках "оптимизации реакта" обычно говорится о том, как сократить перерендеры vdom
eeeMan
23.11.2021 12:37-1именно это и имел в виду, то что там вызывается функция рендер это уже второстепенное, она в любом случае вызовется, тк мы же изменили массив
faiwer Автор
23.11.2021 12:41В работе React есть две фазы:
renderиcommit.Renderэто построение списка изменений за счёт реконсилирования двухvirtualDomдеревьев. А изменения в настоящемDOMэтоcommit. Так вот ваша "вызывает функция рендер" это как разrender. Вышеописанный memo тоже работает на стадииrender. Аkeyнужен только для сопоставления однородных элементов во время работы алгоритма реконсиляции.eeeMan
23.11.2021 12:57-4как я уже говорил ранее, рендер функция компонента в любом случае вызовется потому что произошло изменение массива (а если ничего не менялось то она и не вызовется), рендер в браузере вызовется только для элемента который изменился, либо в Вашем случае для всех элементов потому что key="key", ещё и ворнинг выдаст из-за одинаковых ключей для всего списка.
faiwer Автор
23.11.2021 13:04+6рендер функция компонента в любом случае вызовется
Не в любом. С самого начала вам сказали про
memo. Вот если обернуть дочерние компонентыmemo(и соблюсти ряд условий), то они не будут пере-render-ены. Кроме тех конкретных instance-ов, элементы которых были изменены.Массив ведь меняется не целиком, а частично. Добавили новый элемент. Изменили существующие. Удалили элемент. Любое из этих изменений вызовет ререндер компонента списка. Но при правильно организованном коде дочерние компоненты лишний раз вызываться не будут.
Вашем случае для всех элементов потому что key="key"
Для каких всех? Я для вас привёл сверх-простой пример где всего один элемент. У него уникальный
key(тот самый которыйkey="key", но вы можете поменять это на любую другую константу). Задача для key — позволить React-у сопоставлять элементы между render-ми.Умоляю, откройте уже документацию. Вы не понимаете о чём вы спорите.

Nikitakun1
23.11.2021 11:49В последнем кейсе в MobX перерендера списка не будет, если массив вручную мутировать, но если у нас такая ситуация, когда на каждый экшн нужно перезапрашивать весь список с бэкенда и перерисовывать, то при присвоении этого нового массива в observable-свойство все перерисуется, верно ведь?
Alexandroppolus
23.11.2021 12:01то при присвоении этого нового массива в observable-свойство все перерисуется, верно ведь?
Само собой. MobX рулит только на точечных мутациях.

zuek
23.11.2021 11:15+3О, кажется, Вы открыли мне глаза на тормоза одного из наших внутренних продуктов, заказанных "на стороне" - пока шла разработка, всё "летало", а как запустили в прод, буквально через полгода начались тормоза... при чём тормоза (по несколько минут на отрисовку) при работе с не особо большими таблицами - буквально по паре тысяч строк, при том, что мой "костыль" на php обрабатывал их за доли секунд. Да, наш "внутренний продукт" был написан на Реакте, в котором я разбираюсь едва ли более, чем никак, собственно, из-за чего я и не смог предложить внятного решения, кроме как резать ежемесячно таблицы...
Напомнило, как лет 20 назад "программист 1С" (на самом деле, не 1С, а RS-Balance, но суть это меняет не сильно), очень удивился, когда его отчёт вместо привычных 15-20 минут стал выполняться за 5-7 секунд, всего лишь после того, как я порекомендовал всю логику унести на серверную сторону, в то время как в изначальном виде, "отчёт" по OLE создавал файл в Excel, выгружал в него "необработанные данные" и уже "на листе Excel" их обрабатывал (группировал, сортировал, и вообще творил всякие вычисления)... по OLE... я не программист, но даже мне это было "странно".

vladkorotnev
03.12.2021 07:54+1OLE/COM-интеропы это та ещё жопа в производительности. Как-то раз писали хреньку для миграции документов из ворда в другой вид ворда (и да, на реакте :-). Обработка в цикле таблицы в строк так 500 через интероп — занимала, чтоб не соврать, ну минут 15. Переделали на генерацию скрипта на VB6, передачу его в ворд, с последующим возвратом склеенного из строк подобия JSON'а — та же самая таблица на 500 строк уже обрабатывалась за 300-400 миллисекунд!


aamonster
22.11.2021 16:01Поддерживаю основную мысль, но ваш пример переиспользования объекта – плохо.
И дело именно в том, что функция не чистая. Не та, которая вызывает reduce, а та, которую вы передаёте в reduce. Та самая коротенькая
(accumulator, item) => {
accumulator.push(...something(item));
return accumulator; // это ключевая строка
}
А проблема на самом деле в использовании reduce там, где должен быть map или filter.faiwer Автор
22.11.2021 16:17+15А проблема на самом деле в использовании reduce там, где должен быть map или filter.
Вы уходите в частности не имеющие отношение к обсуждаемой теме. Тело функции-callback-а, передаваемого в
.reduceможет быть сколь угодно сложным и витееватым. Ключевым (относящимся к теме) является — мутируем ли мы результат, или возвращаем копию+изменение.Причём если с массивом вы в этом тривиальном примере (специально тривиальном, чтобы не морочить голову), можете обойтись
.flatMap-ом. То что вы будете делать с формированием не массива, а объекта? Возвращать[key, value]и писать какой-нибудь мутабельныйzipObject?И дело именно в том, что функция не чистая. Не та, которая вызывает reduce, а та, которую вы передаёте в reduce. Та самая коротенькая
Я знаю. Но nobody cares, ведь так, да? ;-) Догматизм — зло
mayorovp
22.11.2021 22:06+1Может, догматизм и зло, но если нас от всего reduce интересует лишь обход массива — почему, блин, не воспользоваться семантически верным forEach?
faiwer Автор
22.11.2021 22:17+2Можно. А смысл? Те же проблемы, что и у for-of. Можно сразу взять for-of, зачем forEach?
// ^ рвём цепочку const data = {}; for (const [key, value] of Object.entries(obj)) data[key] = something(value); // возобновляем цепочку (если надо)Вариант с reduce позволит не рвать цепочку и не перегружать код (имхо). Но я понимаю, что это вкусовщина. Главное не тащить сюда квадрат.

PsyHaSTe
25.11.2021 01:40Ну на самом деле я согласен, что мутировать хорошо локально, но только когда это явно видно, Ну знаете, `runST` и вот это все. reduce все же рассчитывает на чистую функцию, и если завтра объект аккумулятора начнется как-нибудь хитро кэшироватьяс между разными вызовами редьюсов то можно будет ловить веселые приколы. Видел подобное в плюсовом коде, где значение после мува использовали как «проицинициализированный пустотой объект», а оно так какое-то время было а потом хоп и изменилось.
Вы можете в этой функции мутировать внешний по отношению к редьюсу стейт, это правда. Но вот аргументы редьюса трогать это плохая практика.
В вашем примере если вам не устраивала результирующая производительность стоило воспользоваться флатмапом, который семантически ровно то, что нужно. И рассчитывать, что вот флатмап как раз оптимизирован чтобы не переаллоцировать буфер между итерациями.
В общем, по сути статьи я согласен, но в деталях скрылся дьяволfaiwer Автор
25.11.2021 01:45+3объект аккумулятора начнется как-нибудь хитро кэшироватьяс между разными вызовами редьюсов то можно будет ловить веселые приколы
В пределах одного вызова
reduce? Это как? Если же нет, то не совсем понял проблему, т.к. мы же всегда создаём новый аккумулятор (2-ым аргументом).воспользоваться флатмапом
Я просто не хотел переусложнять пример. Если у вас есть под рукой подходящий пример где точно нужен reduce, но он не отвлекает на себя много внимания, я был бы рад :)
не устраивала результирующая производительность
Категорически не устраивает. Но не в моём коде, а в чужом, который мне приходится запускать у себя. Людей устраивает. А не должна. От этого и бомбит.
PsyHaSTe
25.11.2021 02:01+3В пределах одного вызова reduce? Это как? Если же нет, то не совсем понял проблему, т.к. мы же всегда создаём новый аккумулятор (2-ым аргументом).
Я не придумал в конкретном случае) Но если это дается как общий совет, то такие случаи когда что-то там мемоизировалось и мутировалось у меня бывали, и последствия были плачевные.
С мутабельностью удобно работать когда в сигнатуре видишь
(State m) => ... -> m Number, а без этого знание что формально мы можем представить что всё чистое… Ну мы можем точно так же представить, что любая сишная программа чистая, простоvar x = yэто на самом деле не let а монадический бинд, а все функции написаны в IO. Формально будет верно, по факту никаких гарантий не добавит, и код как был ногострельным так и останется.Я просто не хотел переусложнять пример. Если у вас есть под рукой подходящий пример где точно нужен reduce, но он не отвлекает на себя много внимания, я был бы рад :)
Ну, я в принципе так и подумал, что это упрощение ради примера) Надо подумать — ломать не строить. Если придумаю — напишу. Но как простой ответ можно как раз сказать "редьюс тут плохо подходит по семантики из-за сложности, но вот есть флатмап". По сути это ведь и есть флатмап. Как вариант или взять его из стандартной поставки, или написать свой. Но если писать свой то наверное лучше использовать родной for, а не редьюс. Хотя бы как семантический фактор "здесь происходит нечто что плохо ложится на существующие комбинаторы". По крайней мере у меня такой подход обычно — если пихание мутирующих функций в редьюс выглядит чужеродно, то оно так и есть, и стоит его избегать. У меня по крайней мере такое впечатление.
Категорически не устраивает. Но не в моём коде, а в чужом, который мне приходится запускать у себя. Людей устраивает. А не должна. От этого и бомбит.
Прекрасно понимаю и сочувствую. Сам на ревью на прошлой работе практически настроил автоматический возврат кода на доработку если там есть авейт в цикле. Но они продолжали приходить.
Все что остается — писать подобные образовательные статьи и надеяться на постепенный рост средней квалификациии разработчиков. Не впадая в "а вот в наше время были богатыри — не вы", сейчас качество разработчиков очень выросло. Что ни говори, DDD была овер хайпанутая тема 10-15 лет назад, а ведь по сути там все сводится к "не запускайте ракеты из класса юзера". Чуть позже откровением был SOLID — щас разработчики просто плечами пожимают "ну да, а как ещё разрабатывать, говно ж выйдет".
Понемногу идем. Но да, чтобы процесс шел нужны обучающие материалы вроде этой статьи. За что спасибо
Vilaine
26.11.2021 11:36Сам на ревью на прошлой работе практически настроил автоматический возврат кода на доработку если там есть авейт в цикле.
А как быть, если каждая итерация берёт данные из предыдущей итерации?PsyHaSTe
26.11.2021 11:38Ну тогда очевидно никак. Но в 99% никаких зависимостей нет и код выглядит так:
const orders = []; for (let orderId of orderIds) { orders.push(await getOrder(orderId)); }И тут как бы печально от этого цикла становится
nin-jin
26.11.2021 11:58+1Зато с таким кодом нагрузка на сервер более равномерная.)
PsyHaSTe
26.11.2021 12:09Это правда. Но я считаю что сервер если не справляется с нагрузкой должен сам троттлить запросы клиента, а не клиенты должны писаться с осторожностью. Потому что только сервер знает реальную нагрузку и если его внезапно оптимизируют/переведут на более мощное железо то идти искать все места где его щадят.
Вероятно я отвечаю на сарказм, но раз уж написал то пусть будет
nin-jin
26.11.2021 12:18Троллтить, всмысле возвращать ошибку "вы сделали слишком много запросов в минуту, поэтому мы заблокировали вас на 5 минут и просим решить зубодробительную каптчу"?
Сарказм, конечно, но в любом сарказме есть доля суровой реальности.PsyHaSTe
26.11.2021 12:19Есть разные способы, но в обещм случае да. Потому что гадать на кофейной гуще что вот столько запросов в секунду норм, а больше или меньше уже не норм плохая идея
mayorovp
26.11.2021 13:39Но это получится только если сервер и правда умеет управлять ресурсами, причём его управление ресурсами совпадает с требуемым. А реализовать такое управление ресурсами — куда более сложная задача, нежели ограничить число параллельных исходящих запросов.
Vilaine
26.11.2021 13:17+1Но в 99% никаких зависимостей
Да, но линтер не пропускает этот 1% случаев. =) Хотя в Javascript большинство линтеров поддерживают игнор.PsyHaSTe
26.11.2021 13:25Да, это как раз такой случай, когда иногда это может быть корректно, но почти всегда нет. И да, линтер по идее должен уметь различать случаи когда есть явная зависимость между итерациями
result = await foo(result.Something, somehingElse)Alexandroppolus
26.11.2021 13:38И да, линтер по идее должен уметь различать случаи когда есть явная зависимость между итерациями
result = await foo(result.Something, somehingElse)Зависимость может быть и неявной. Например, на позапрошлой работе, помнится, были запросы на получение рекламы. С требованием "только один запрос в любой момент времени", чтобы не перетерлись изменения в куках.
Но это совсем уж редкие кейсы..
Alexandroppolus
26.11.2021 13:35+2Этот цикл особенно печален тем, что бэк не сделал (или сделал, но фронты не знают) сервис для getOrders(orderIds), чтобы одним запросом.
PsyHaSTe
26.11.2021 15:10+1Это частая история на самом деле. например возьмем гитхаб апи — как получить информацию по репозиториям если у нас есть массив их айдишек?
Или телеграм апи — как получить описание групп если у нас есть список их названий?
faiwer Автор
22.11.2021 16:20+3сама сигнатура reduce заточена под чистую функцию
Забыл отметить, что пока у нас нет настоящих immutable data structures не так важно, как
.reduceзадумывался (в FP мире). Вscalaдля таких вещей у ребят есть специальные древовидные коллекции сO(logN)на операцию. А у нас шиш.faiwer Автор
22.11.2021 16:29+2Кстати в
lodashесть _.transform, который изначально игнорирует возврат из callback-а (точнее поддерживает только ранний выход из итерирования). Лично мне не хватает его в стандартной библиотеке.aamonster
22.11.2021 16:51+4Вот! В _.transform всё сделано так, что сразу понятно, что она ждёт не чистую функцию, а функцию, модифицирующую аккумулятор. Собственно, можно reduce завернуть аналогично.
Дело-то не в догматизме, а в "принципе наименьшего удивления".А так, конечно, тут не хватает линейных типов. Чтобы если вы передали accumulator в качестве аргумента reduce – то всё, дальше по коду ваш accumulator недействителен.
faiwer Автор
22.11.2021 16:57+2Дело-то не в догматизме, а в "принципе наименьшего удивления".
Ну вот если бы речь не шла об
O(n^2)вместоO(n)я бы с вами согласился. Можно было бы говорить про удивление, чистоту кода и т.д… Но увы, на другой чаше весов куда более серьёзный аргумент.И да, было бы классно иметь
transformвArray.prototype.. Тогда сам вопрос бы отпал как таковой.aamonster
22.11.2021 17:04-1Так кто мешает? Array.prototype.transform=function(...)
И не надо говорить про чаши весов. Заверните reduce (или даже цикл) в функцию с понятной сигнатурой и пользуйтесь. Если, конечно, не хватит map/filter.В смысле, я ратую за то, чтобы писать O(n), но понятное O(n) :-)
faiwer Автор
22.11.2021 17:11+7Так кто мешает? Array.prototype.transform=function(...)
За это бьют ногами. История prototypeJS до сих пор всем аукается.
Заверните reduce (или даже цикл) в функцию с понятной сигнатурой и пользуйтесь
Как только завезут
|>первым делом так и сделаю. Текущее же положение вещей в JS community приводит к тому, о чём я написал в статье. Люди блин даже пишут:I'm pretty surprised that this has any impact
Чувак создал PR где заменил
O(n^2)наO(n)и удивлён что это вообще что-то дало. Что характерно, этого ему показалось мало. Ведь "оно должно работать" быстро и он нашёл ещё одну причину. Но вот наO(n)у него глаз не дёрнулся. С его точки зрения, получается, это не проблема (хотя лекарство и помогло). Он полез в кишки v8 и затем целую написал проSymbol.isConcatSpreadable. Дескать в этом проблема (хотя признаю, что в этом тоже есть проблема — "магическая оптимизация" сорвалась).И такой вот софт где народ не думая городит ну вот прямо на пустом месте аховую асимптотику всё больше и больше.
aamonster
22.11.2021 22:50+1Ok, за Array.prototype.... прошу прощения. Но никто не мешает иметь то же самое отдельной функцией. С понятной сигнатурой и сложностью O(n). Для этого даже композиция функций не нужна.
faiwer Автор
22.11.2021 22:55+1Но никто не мешает иметь то же самое отдельной функцией
На самом деле мешает. Сейчас в JS нет удобной возможности не рвать цепочки, т.к. pipe-оператор уже многие годы висит среди незавершённых спецификаций. По сути говоря любой метод, которого нет в chain-е вынуждено заставит вас разворотить всю цепочку трансформаций. Вот с ним такой проблемы уже не будет.
Но мне кажется наш разговор зашёл куда-то не туда. С вашей точки зрения нарушать кем-то придуманную семантику reduce это большой грех. А с моей точки зрения — нет. И то и другое — субъективщина. Поэтому предлагаю на этом и закончить. А то мы скатимся в какой-нибудь холивар про "читаемый\нечитаемый код", "признаки оценки качества кода", "роль семантики в разработке ПО" и пр.
nin-jin
23.11.2021 08:38+6Я тоже любил цепочки. С ними код такой лаконичный. Пока не начал пользоваться отладчиком. А дебажить цепочки - это просто ад. Гораздо удобнее, когда есть отддльная переменная на отдельной строке. Тогда и брейкпоинт можно поставить, и значения на каждом шаге посмотреть, перепрыгнуть шаг-другой, ну и мелкие изменения не приводят к куче правок в коде с разрывами цепочек.
platinum355
23.11.2021 17:01Но вот на
O(n)у него глаз не дёрнулся.А почему у него на 0(n) должен был глаз дёрнуться ? Разве можно собрать зависимости всех нод, не пройдясь по всем нодам ? Удивите)

vkni
23.11.2021 18:00Чувак создал PR где заменил
O(n^2)наO(n)и удивлён что это вообще что-то дало.Это означает, что он явно не понимает, что пишет. Так делать нельзя.
> И такой вот софт где народ не думая городит ну вот прямо на пустом месте аховую асимптотику всё больше и больше.Это просто "кодирование не приходя в сознание". Там может быть много причин - низкая квалификация, повышенные требования по скорости, выгорание, следование хайпам и т.д.
faiwer Автор
23.11.2021 18:12Это просто "кодирование не приходя в сознание". Там может быть много причин — низкая квалификация, повышенные требования по скорости, выгорание, следование хайпам и т.д.
Хотелось бы так думать. Но, как вы сами видите, даже здесь в комментариях более чем достаточно людей, которые вообще не видят в этом никакой проблемы. Причём людей с богатым опытом в разработке.
Пока меня пугает сам тренд на "всё что не убивает меня,
делает меня сильнеене имеет значения", кого-то пугает что ещё есть люди, которые видят в этом проблему :)vkni
23.11.2021 19:21+2Пока меня пугает сам тренд на "всё что не убивает меня,
делает меня сильнеене имеет значения", кого-то пугает что ещё есть люди, которые видят в этом проблему :)Это непосредственное следствие культуры "х*як-х*як и в продакшн", которая непосредственное следствие высококонкурентной среды и коротких горизонтов планирования, которая есть просто рыночная экономика. Поэтому я как-то к этому очень по-философски отношусь - снявши голову, по волосам не плачут.
Я, кстати, понял, что даже в кондовейшем квадратно-гнездовом C можно легко воспроизвести ваш случайный O(N^2), если писать не приходя в сознание:void my_string_transform(char *s) { int i; for( i = 0; i < strlen(s); i++) { .... } }То есть, JavaScript, как язык, и функциональщина, как подход, тут не при чём.

BigBeaver
23.11.2021 20:12Проблема в неопнимании связи между буковками на экране и тем, какая работа компьютера за ними стоит.

AnthonyMikh
24.11.2021 12:55Я, кстати, понял, что даже в кондовейшем квадратно-гнездовом C можно легко воспроизвести ваш случайный O(N^2), если писать не приходя в сознание:
Формально да, но компиляторы уже давно знают про strlen, так что если строка в цикле не изменяется, то компилятор вполне может вынести strlen из цикла. Но да, так писать всё-таки не стоит.

apro
25.11.2021 02:33+3Не всегда кстати C++ компилятор может убрать вызов функции на каждой итерации. Потому что если в итерации вызывается какая-нибудь функция “f” и компилятор знает только ее сигнатуру, но не реализацию, то вполне может быть что данная функция меняет строку через глобальную переменную и поэтому вызов strlen нельзя кэшировать.
Drag13
23.11.2021 18:15-1Справедливости ради, проблема была не в самом методе конкат.
Проблема была в использовании Symbol.isConcatSpreadable где-то в коде, что автоматически замедляло все concat-ы.
Вот статья https://engineering.tines.com/blog/understanding-why-our-build-got-15x-slower-with-webpackfaiwer Автор
23.11.2021 18:21Справедливости ради, проблема была не в самом методе конкат
Не соглашусь. Там просто две проблемы. Одна с
isConcatSpreadable, а другая в.concat in .reduce. Причём ему хватило даже решения второй проблемы. Но чувак дотошный (а почему с wp4 не тормозит?) и он нашёл ещё и 1-ую.Справедливости ради, я думаю, что решение проблемы с
isConcatSpreadableдаст куда больший impact, т.к. affect-ит сразу всю запускаемую кодовую базу.Drag13
23.11.2021 18:27Погодите...
У него действительно было две проблемы, но я не вижу свидетельства того, что в данном случае проблема была именно в concat.
Т.е. осталась ли проблема, в случае если из кодовой базы исчез isConcatSpreadable? Вот это самое интересное и показательное на мой взгляд.
faiwer Автор
23.11.2021 18:31но я не вижу свидетельства того, что в данном случае проблема была именно в concat
Гхм. Всмыыыыысле? Без
concatпроблемы нет. И не важно стоит лиisConcatSpreadableили нет. Это css-in-JS поделие о котором там речь, работает "drammatically faster" если убрать квадрат. Если это не свидетельство, то что же тогда свидетельство?Полностью согласен с mayorovp,
isConcatSpreadableпросто заметал проблему под ковёр.Вот давайте проверку на прочность проведём:
- Не накатываем патч с
O(n). Но накатываем патч сisConcatSpreadable. Проблема решена? Да. Проходит время, N увеличивается. Проблема осталась? Осталась. - Поступаем наоборот. Обе ситуации — всё работает быстро.
Ну а вариант — накатываем оба патча, конечно лучше.
- Не накатываем патч с
Drag13
23.11.2021 18:38Вот давайте проверку на прочность проведём
Вот именно это я и имел ввиду. Только я говорил что в их частном случае конкретная проблема была с isConcatSpreadable, а вы отвечаете о случае общем (и правы в этой части).
Мы говорим с немного разных ракурсов.
mayorovp
23.11.2021 18:22+1Проблема была именно в квадратичном алгоритме, оптимизированный concat лишь позволял её спрятать.
vkni
23.11.2021 19:22Справедливости ради, проблема была не в самом методе конкат.
Проблема в том, что люди не понимают то, что пишут. А метод - это как молоток - инструмент.

Devoter
22.11.2021 16:45-1Вообще, да, хотелось бы иметь интерпретатор для JS, ну или хотя бы компилятор типа TS, который умеет вызовы типа
arr.map(...).filter(...).reduce(...)разворачивать в O(n).faiwer Автор
22.11.2021 16:53Как-то слишком много магии, имхо :) Да и вообще нам бы куда более простых инструментов бы завезли. Например, чтобы не писать:
<Button style={style} onClick={onClick} blabla={blabla} />вместо
<Button { ...{ style, onClick, blabla }} />потому что:
- TS позволяет в этом spread-е передать лишние поля :-(
- TS не оптимизирует 2-ую конструкцию в 1-ую
Если 2-е можно сделать плагином для TS, то вот первое уже нет, т.к. TS не умеет в плагины до type-checking-а :(

youngmysteriouslight
22.11.2021 21:37+9AFAIK, любой интерпретатор JS исполняет
arr.map(x => x + 2).filter(x => x > 0).reduce((a, b) => a + b)за O(n).dustik
23.11.2021 14:22Вот прямо в точку.
Тоже хотел написать, что меня выводит из состояния покоя, что есть "черные ящики оптимизации" в компиляторах.Можно усиленно стараться и писать алгоритмически красиво, но другой разработчик написал редьюс с O(n^2), но компилятор это увидел на втором шаге и под капотом сложил все в оптимальную структуру, а потом это все еще и отсортировал как нужно.
vkni
23.11.2021 04:22А разве это не любой делает?
В GHC есть оптимизация этого под названием stream fusion, которая просто засовывает всё в один цикл вместо нескольких последовательных. Но сложность вычислений вот просто так вроде бы не меняется.
0xd34df00d
23.11.2021 20:59+2Иногда меняется :] Компилятор счастливо оптимизирует
map negate . map negateвid, например, делая из линейной сложности константную.Плюс, у меня были неискусственные случаи, когда квадрат менялся на линейную сложность, но я их сейчас не воспроизведу.

alexxz
23.11.2021 12:53Приведённый вами пример и отрабатывает за O(n). Три (константа) прохода по списку - это O(n). А вот оптимизация вычислений, чтобы это был один проход, а не 3 - это было бы здорово... Можно написать цикл... Ах, ну да, чтобы не писать циклы это всё и придумано.
Devoter
23.11.2021 14:17Да, пожалуй, неверно выразился. Конечно, речь о том, чтоб все это выполнялось за один проход цикла. Собственно, если не ошибаюсь (не силен в ФП), некоторые языки такое позволяют на этапе компиляции. Не отношусь к фанатам подобных конструкций как раз из-за множества проходов, отсутствия break, не говоря уже о том, что сам по себе forEach и любой из его собратьев медленнее обычного for, хотя сейчас уже прикрутили какие-то оптимизации в движках.

LEXA_JA
23.11.2021 15:54+2Это можно сделать за один проход и без ФП, через итераторы. Если не ошибаюсь, то в Rust такие вещи разворачиваются.
В JS это можно сделать через генераторы.function* map(mapper, iterable) { for (const item of iterable) { yield mapper(item); } } function* filter(predicate, iterable) { for (const item of iterable) { if (predicate(item)) { yield item; } } } function reduce(reducer, initial, iterable) { let result = initial; for (const item of iterable) { result = reducer(result, item); } } reduce( (a, b) => a + b, 0, filter( (x) => x > 2, map((x) => x + 1, [1, 2, 3, 4, 5]) ) );

YChebotaev
22.11.2021 16:43+1А потом на ревью прилетит «а че ты так сделал, а не через .../[]?». И доказывай что не занимаешься преждевременной оптимизацией.
Раньше был такой такой чеклист, от авторов Bluebird, в котором были собраны техники оптимизации для оптимизирующего компилятора хрома. Все им пользовались и считали за бест-практайс. На интервью спрашивали. А потом выпустили новый движок и все оптимизации стали не актуальны. Думаю, так же произойдет и с тем о чем вы рассказываете: допилят оптимизации на уровне движка и все ухищрения на уровне кода станут дремучим легаси.
faiwer Автор
22.11.2021 16:49+9И доказывай потом что не занимаешься преждевременной оптимизацией.
Заниматься обучением своих коллег — не грех. Если сильно непробиваемые, можно сменить команду. В конце концов это ваш выбор, с кем вы работаете.
Думаю, так же произойдет и с тем о чем вы рассказываете
Не произойдёт. См. раздел "3. Умный компилятор всё оптимизирует" в статье.
YChebotaev
22.11.2021 18:06-5Заниматься обучением своих коллег — не грех
Я и сам-то не уверен что это не преждевременная оптимизация
Если сильно непробиваемые, можно сменить команду. В конце концов это ваш выбор, с кем вы работаете
Простите, но я не готов отстаивать эту тему настолько, чтобы терять из за нее работу )
Не произойдёт. См. раздел "3. Умный компилятор всё оптимизирует" в статье.
У вас там все очень категорично, не могу на это конструктивно ответить.
Могу только это прокомментировать:Как это гарантировать в языке, в котором почти ничего нельзя гарантировать
А зачем что-то гарантировать? Аргументация построена на введении излишнего и заведомо не выполнимаого ограничения, которого нет в реальности. В JS-е ничего не гарантировано, но связка из трех компиляторов со всем справляется и быстро. Собственно, тут вопрос не принципиального ограничения, а просто пока что у инженеров V8 руки до этого кейса не дошли
faiwer Автор
22.11.2021 18:16+7Я и сам-то не уверен что это не преждевременная оптимизация
Я в статье разобрал ситуацию когда это может быть преждевременной оптимизацией. Когда у вас гарантировано малый N. Там просто разница в производительности не делает погоду.
но я не готов отстаивать эту тему настолько, чтобы терять из за нее работу )
Зачем же доводить до крайностей. Вы видите участок кода, которые является проблемным. Вам задают вопрос — почему так написано. Вы объясняете почему. Предположим с вами не согласны. Вы приводите аргументацию. Вам приводят свою. Если выясняется, что вы не правы, пишете исправляете. Если выясняется, что вы правы, но ваши коллеги не убеждены — работаем над своими soft-skill-ми.
Но изначально писать откровенно плохой код по причине, а вдруг на ревью кто-то подкопается, это очень плохо.
А зачем что-то гарантировать?
Вы понимаете, что единственная серьёзная оптимизация, которая вам тут может быть доступна (нужно вместо
O(n^2)сделатьO(n)) — мутировать коллекцию под капотом. И компилятор не может себе этого позволить не убедившись в том, что коллекция гарантировано никому не доступна кроме итогового адресата у.reduce? И теперь вопрос — как вы собираетесь это проверять?Какие эвристики? Какие контракты? Какие оптимизации? Какие затыки? Можно чуть менее магическим языком, конкретику? ;-)
Я ещё напомню, что речь идёт ДАЖЕ не о TypeScript где у компилятора есть хоть какие-то зацепки.faiwer Автор
22.11.2021 18:31+28А вообще с этими "преждевременными оптимизациями" народ кажется сходит с ума. Одно дело когда нужно перепахать кодовую базу, переписав алгоритм до неузнаваемости. Или скажем когда нужно сильно усложнить архитектуру, дабы добавить что-то, что возможно не пригодится. Или когда экономия происходит там, где от этого почти никакого толку, при наличии настоящих bottle necks.
Например мне запомнился товарищ, который на JAVA backend-е писал все HTML шаблоны в обычных JAVA class method-ах используя string builder и ручное экранирование всего и вся. Он же для всех сетевых взаимодействий использовал web-socket-ы, чтобы избегать лишних заголовков и overhead-а на JSON. Вот это я понимаю preliminary optimizations.
Но когда речь идёт об одной единственной примитивной строке в очевидно опасном месте… Кажется люди стали использовать эту фразу ("преждевременная оптимизация") чтобы ничего никогда никак не оптимизировать, пока к ним Task-а в Jira не прилетит. На мой взгляд, это очень плохо характеризует всю нашу индустрию. Становится понятно, почему многие ассоциируют слово "javascript" исключительно с негативом.
YChebotaev
22.11.2021 20:43Как видите, карма не позволяет мне слишком углубляться в дискуссии, так что отвечу только на одно.
И компилятор не может себе этого позволить не убедившись в том, что коллекция гарантировано никому не доступна кроме итогового адресата
И теперь вопрос — как вы собираетесь это проверять?
Тут я вступаю в тему, в которой мало смыслю, но разве виртуальная машина не ведет подсчет ссылок? Если ссылка всего одна, и она в параметрах reduce, то это значит что объект никому кроме тела этой reduce не доступен.
faiwer Автор
22.11.2021 20:49+4не ведет подсчет ссылок?
Кажется в Swift и Objective C ведёт. А у нас Garbage collector. Для поиска неиспользуемых нод алгоритм пробегает от корня до листьев древа и помечает ноды как достигаемые. А потом пробегает по всем нодам вообще и те, что не помечены, удаляются. Это в общих чертах.
По сути желаемая оптимизация потенциально возможно в функциональных языках со строгой типизацией и мощной системой типов. Ну во всяком случае я думаю что возможно она им доступна. У них там прямо очень много что возможно, по целому ряду причин. Например т.к. там настоящая иммутабельность, что гарантирует то, что никакие изменения не прилетят "сбоку" откуда не ждали. И, мне кажется, компилятору (не в runtime) проще отследить те места, в которых можно точно сказать, что на сий объект больше никто точно не может ссылаться. Но тут надо спросить у самих FP-ов, насколько мои фантазии к ним применимы.

transcengopher
22.11.2021 21:28+10Это же ECMAScript. Поэтому всегда может найтись прибитый сбоку оверрайд
Array.prototype.push, который делает персональные данные массива доступными для неопределённого круга лиц. И даже если так делать давно не принято, сам факт существования такой возможности делает множество видов ссылочных оптимизаций де-факто нерабочими.

fransua
24.11.2021 06:43Я в статье разобрал ситуацию когда это может быть преждевременной оптимизацией. Когда у вас гарантировано малый N. Там просто разница в производительности не делает погоду.
Есть еще вариант - когда рядом еще более тяжелый O(N^2).
Вообще я часто пишу неоптимальный код, осознавая это, и исправляю только если это не ухудшает читаемость. Но очень редко это приходится оптимизировать из-за дальнейших проблем с производительностью. В коде есть места, где каждую структуру нужно выбирать аккуратно, а есть места где "гуляй, рванина", и можно сколь угодно медленно писать.
vkni
23.11.2021 20:29+1Думаю, так же произойдет и с тем о чем вы рассказываете: допилят оптимизации на уровне движка и все ухищрения на уровне кода станут дремучим легаси.
Завязка на оптимизации делает код хрупким, поэтому крайне нежелательна. Для ухода от хрупкости, скажем, в C++ ввели constexpr, в Ocaml ставят явную аннотацию [@tailcall], чтобы даже 40 лет как имеющаяся оптимизация срабатывала или несрабатывала явно.
DarthVictor
22.11.2021 18:12+1Если не нравится лишняя строчка, то вместо
(accumulator, value, key) => { accumulator[key] = something(value); return accumulator; }, {}можно писать
(accumulator, value, key) => accumulator.set(key, something(value)), new Map()

Tiendil
22.11.2021 18:30Потому что
Explicit is better than implicit (c) PEP-20
Не надо создавать и использовать микроскопы в среде, которая проектировалась под молотки.
faiwer Автор
22.11.2021 18:39+3Не совсем понял ваш аргумент. Вы имеете ввиду не надо играть в immutability в языке, в котором для этого ничего нет? И по сути просто не пользоваться
.reduce, т.к. он неявно подразумеваетO(n)? Так вpythonтоже естьreduce.Или вы в целом за
for (;;)конструкции, которые явным образом демонстрируют все действия над коллекцией? Мне как-то пришло на проверку тестовое задание, где человек сделал что-то вроде:// суть задания была написать простейший полифил Array.prototype.map = function(callback) { let result = []; for (let idx = 0; idx < this.length; ++ idx) { result = [...result, callback(this[idx])]; // ^^^^^^^^^ } return result; }Правда такой уникум был только один :)
Tiendil
22.11.2021 18:56+7Я к тому, что нужно блюсти баланс между выразительностью/читабельностью кода, компетенцией людей, которые с ним работают, и возможностями языка по контролю ошибок.
Несоблюдение баланса неизбежно пораждает множество неочевидных проблем. В посте приведён пример неверного использования функциональщины в JS, но это частный случай. Так же можно упороться и в ООП и в других языках.Так в
pythonтоже естьreduceЭто не значит, что его надо использовать везде и всегда :-)
Или вы в целом за
for (;;)В языках, которые не рассчитаны явно на функциональный стиль кода, я за явные циклы. Слишком часто видел как даже (очень) опытные люди косячили из-за того, что не заметили сложность, спрятанную за функцией или методом.
И втихую мечтаю о языке/инструменте, который будет статически анализировать вычислительную сложность и писать варнинги.

TheShock
22.11.2021 20:36+8Вы имеете ввиду не надо играть в immutability в языке, в котором для этого ничего нет? И по сути просто не пользоваться
.reduce, т.к. он неявно подразумеваетO(n)? Так вpythonтоже естьreduce.Да, было бы неплохо поуменьшить использование редьюс, особенно с такими костыльными конструкциями. Лучше использовать более читаемые и подходящие под текущую ситуацию методы вплоть до for'ов.
faiwer Автор
22.11.2021 20:37+2Где-то вдалеке заплакал "redux-программист" :-)

nsinreal
23.11.2021 00:09А при чем тут redux? Нормальные люди давно используют redux-toolkit, где не нужно изгаляться.
faiwer Автор
23.11.2021 00:18+1Рад за них. Я чуть менее
нормальныепрогрессивные продолжают писать...-пирамидки.nsinreal
23.11.2021 18:19+1Под капотом redux-toolkit используется immerjs, который можно подключить в отдельных местах. Оно конечно, делает некоторую деградацию по перфомансу, но это увеличение константны, а не асимптотики.
faiwer Автор
23.11.2021 18:25+2Угу, я знаю. Я где-то 4 года назад написал собственную версию
immerjs, просто потому что кто-то на хабре упомянул саму идею того, что при помощиproxyтакое можно реализовать. А найти готовое решение мне не удалось. Оказалось несложно, но то и дело что-нибудь отваливалось (например так я познакомился со всякими хитрымиSymbol.*, о которых раньше либо не знал, либо забыл. В общем были свои tricky cases.Об immer я узнал из уст одного из интервьюверов. Попросили рассказать что-нибудь интересное, я рассказал про этот solution, а мне в ответ — чувак, ты изобрёл велосипед. Держи
immer("всегда" по-немецки). Было даже немного обидно :-Dnsinreal
23.11.2021 20:58+2Мне было обиднее. Я пытался написать реализацию, довольно схожую, но с дополнительными идеями. В итоге я не смог, а потом вышел immer и у меня очень горело
vkni
23.11.2021 06:21+1Вы имеете ввиду не надо играть в immutability в языке, в котором для этого ничего нет?
Ну в каждом языке есть свои выразительные средства, органичные для него. И если что-то влезает с огромным трудом, то может быть не надо?
Функции высших порядков, кстати, всю жизнь работают в нечистых функциональных языках, вроде ML (SML, OCaml) или Scheme. Просто там как-то привыкли что да, могут появиться от неаккуратного использования примитивов разные странные штуки. Но в целом никаких особенных оптимизаций в том же Ocaml нет - компилятор отрабатывает за 0.5 сек даже большие файлы, всё просто и квадратно-гнездово. Это не GHC.0xd34df00d
23.11.2021 21:01+1ghc дохнет на обмазанном выпендрёжем с типами коде (но там любой компилятор с продвинутой системой типов тормозить будет).
А ещё бывает такое веселье.

dom1n1k
22.11.2021 19:20Меня с самого начала напрягал spread-оператор — вот этой соблазнительной и обманчивой внешней простотой. Сам-то оператор не виноват, но было понятно что многие начнут его совать везде, где можно и нельзя — что и подтвердилось потом на практике.
faiwer Автор
22.11.2021 19:27+6Со spread-оператором выяснилась (на десятках собеседований) интересная ситуация. Почти никто не знает, как он на самом деле работает. Я не шучу. И нет, я не про Symbol в прототипе.
Я предпочитаю на code-interview не заставлять человека писать код, а подсовывать ему кусочки кода и смотреть на реакцию. Так вот — ПОЧТИ ВСЕ думают, что
...spread operator копирует объекты в глубину. Я не шучу. 8 из 10, наверное. Причём кандидаты на senior позицию.И нет, речь не про "ой, что-то я затупил, да, конечно, это работает не так". Мне несложно подсказать. Мне плевать если кандидат не ответил сразу правильно. Важно понять — человек в целом понимает что это и с чем это едят, или нет. А вот прямо делают удивлённое лицо и "ого, а я всегда думал что это полное копирование в глубину". И после всего этого уже я сижу с круглым лицом и думаю. Ну ок, положим ты и правда не знал этого до сего момента. Ну с кем не бывает. Но ведь ты наверняка уже пару сотен раз его использовал в своём коде (или тысяч). Не приходила в голову мысль "о боже я копирую большой объект в глубину, это должно быть охрененно долго"? :-) Видимо нет.

sebres
22.11.2021 21:00+1ПОЧТИ ВСЕ думают, что
...spread operator копирует объекты в глубину.Ну spread operator как бы вообще ничего не копирует (ни в глубину, ни на плоскости), это тупо expand arguments сахар (разворачавающий итерируемое и подменяющий
applyи т.п.), вовсе не обязательно создающий shadow копию или новый список ссылок, если можно просто iterate & yield.Или вы про это вот?
let clone_of_O = { ...O }; let clone_of_A = [ ...A ];Неужели действительно находятся те кто думает, что результат будет "глубже" чем у того же
assignилиslice?!Т. е. понимания что на самом деле делает spread нет в принципе? Мой следующий вопрос был бы, а что в этом примере содержит
b:a = [[1, 2, 3]] b = [a[0], a[0], a[0]] c = [...a, ...a, ...a]И если ответ будет 3 references of
a[0], то что вдруг меняется дляc, когдаaтам просто тупо развернуто.faiwer Автор
22.11.2021 21:09+2Или вы про это вот?
Да, про него.
Неужели действительно находятся те кто думает, что результат будет "глубже" чем у того же assign или slice?!
Да, почти все.

DSL88
22.11.2021 22:41Соглашусь с вами: очень много людей думает, что они так копируют объект. Сколько уже исправлений этого мной написано - не пересчитать.
Я пришёл в js из софта, потому такие ошибки часто бросаются в глаза.
forEach недолюбливаю за невозможность остановки по break. Понятно, что есть every или some, но, как показывает практика, многие с такой конструкцией не знакомы
JordanoBruno
22.11.2021 23:17Вы будете смеяться, но серьезные такие ребятки из AirBnB .forEach вместо for() жестко насаждают через Policy. Причем факт того, что по break не выйти из итерации их никак не смущает.
DSL88
22.11.2021 23:34+1Для этого есть финты в виде every и some...Но все равно это кривость...
Я, когда на сайте реакта читал о хуках и для чего они их сделали, жестко приуныл и уже тогда начать думать куда мылить лыжи из фронтенда: ползти в бакенд или уходить в С++ софт/игры...
JordanoBruno
22.11.2021 23:39-2финты в виде every и some
Break позволяет чутка экономить время, в отличие от предлагаемых Вами финтов.
React пытается развиваться, но это колосс на глиняных ногах, к которому надо еще сверху и сбоку прикрутить десяток модулей, чтоб юзабельно было. Но если не лезть в redux и прочие поделки, то вполне жить можно.
DSL88
22.11.2021 23:44Break позволяет чутка экономить время, в отличие от предлагаемых Вами финтов.
это не я предлагаю, а они.

antonkrechetov
23.11.2021 00:14+2Вы будете смеяться, но серьезные такие ребятки из AirBnB .forEach вместо for() жестко насаждают через Policy. Причем факт того, что по break не выйти из итерации их никак не смущает.
А какое обоснование? в чем плюсы?faiwer Автор
23.11.2021 00:22Скорее всего консистентность кодовой базы. Чтобы каждый не лез кто в лес, кто по дрова выбрали что-то одно. Да и в целом нынче такой тренд, мол
for ;;слишком "сложный". Кажется вswiftот него вообще отказались, оставив толькоfor in ..и итераторную версию.
JordanoBruno
23.11.2021 00:22Вот тут у них написано.
Вкратце:
Why? This enforces our immutable rule. Dealing with pure functions that return values is easier to reason about than side effects.
mayorovp
23.11.2021 02:08+3Только вот фокус в том, что как раз цикл for-of можно использовать для построения той самой pure functions that return values, в то время как forEach уже сам по себе основан на сайд-эффектах.
JordanoBruno
23.11.2021 02:16На самом деле что у for, что у .foreach side-эффектов не так уж и много. Более того, я использую их оба и не вижу какого-либо реального препятствия, почему нужно выбрать один из них. Я лишь привел этот пример, как даже в больших компаниях и весьма опытные товарищи могут легко заблуждаться.

some_x
23.11.2021 12:49В общем "функциональность головного мозга". Мне один такой пациент с похожим обоснованием пытался запретить использовать let и var.
JordanoBruno
23.11.2021 13:22+2var-то правильно, а let видать за компанию? Тоже встречал такого, правда там вопрос решился проще, я был главным и защитил "let" :). Правда оставил товарищу возможность писать с "const", очень уж упертый был, ну а политика по коду у меня весьма мягкая в предпочтениях.

JSmitty
23.11.2021 00:16-1справедливости ради конструкция вида { ... obj } действительно делает поверхностную копию объекта
sebres
23.11.2021 17:31-1справедливости ради конструкция вида { ... obj } действительно делает поверхностную копию объекта
Ну вот первый кандидат на "учить мат-часть"...
Нет, не делает... Она создает новый объект, и передает в него spreaded итератор в виде "списка" object literal аргументов aka key-value pairs...
Т.е. вот эти вот выражения практически эквивалентны в плане нативного исполнения (и последнее не создает никакой копии напрямую):
r = { height: 10, width: 20 }; r = Object.assign({}, r); r = { ...r };Т.е. такой flat clone (без
prototype) просто короткая альтернативаObject.assign(). И его же и вызывает кстати, а не то, что вы себе там придумали...PoC на коленке:
> class Rect { constructor(h, w) { this.height = h; this.width = w; } }; > r = new Rect(10, 20); r Rect {height: 10, width: 20} > r2 = {...r}; r2 { height: 10, width: 20 } > r instanceof Rect true > r2 instanceof Rect falsefaiwer Автор
23.11.2021 17:39+3Вы, кажется, говорите об одних и тех же вещах, но разными словами.
Она создает новый объект, и передает в него spreaded итератор в виде "списка" object literal аргументов aka key-value pairs...
Вы только что описали один из способов сделать shallow object copy. Та самая "поверхностная" (shallow) копия объекта.
Конечно всегда можно погрузиться в детали. Например если переопределить метод-итератор, т.е. написать свой собственный, то туда можно хоть числа Фибоначи воткнуть. Или начать обсуждать нюансы того какие поля будут переданы по-умолчанию, а какие нет.
Но… это уже нюансы. Концептуально поведение объекта по-умолчанию — создать его shallow копию.
sebres
23.11.2021 17:53-1Только человек мне ниже написал, что можно вызвать spread для неитерируемого. Из чего был сделан вывод, что понимания как spread работает в принципе - нет.
JSmitty
23.11.2021 00:23Ну spread operator как бы вообще ничего не копирует (ни в глубину, ни на плоскости), это тупо expand arguments сахар (разворачавающий итерируемое и подменяющий
applyи т.п.)Объект в общем случае (для object spread) не обязан быть итерируемым, чтобы к нему можно было применить object spread. Для использования в контексте списка значений - да, обязан.
sebres
23.11.2021 17:38-1Нет! Обязан (ибо он работает не так как вы себе представляете).
Попробуйте передать туда неитерируемый объект, или переопределите его iterator, чтобы он выкидывал исключение. Я вас уверяю вы его (исключение) обязательно поймаете.
sebres
23.11.2021 18:05+2Посыпаю голову пеплом и выражаю глубочайшие извинения ув. @JSmitty
Только что написал в консоль
{...10}и оно создало мне пустой объект... Хотя я мог бы поклясться, что уже делал такое как-то и оно вылетало с ошибкой. Возможно Object.assign переделали с той поры... или это просто старость.Еще раз прошу прощения если кого ввел в заблуждение.
mayorovp
23.11.2021 18:30+2Потому что
{...obj}и[...seq]— это разные конструкции, и работают они по-разному. Как раз вторая и требует итератор, который можно переопределить и т.п.А первая просто копирует перечислимые собственные свойства объекта, независимо ни от чего. Переопределить тут можно разве что Proxy подсунув.

RAX7
23.11.2021 18:33Вероятно вы перепутали работу spread оператора для объектов и массивов. Для массивов требуется рабочий Symbol.iterator, для объектов - нет (его у них и нет)
({})[Symbol.iterator] // -> undefined ([])[Symbol.iterator] // -> values() { [native code] }sebres
23.11.2021 21:53Я знаю что
[Symbol.iterator]у объектов нет, просто когда (в proposal ES2018 если не ошибаюсь) речь велась про object literals, это определялось как "pass all key:value pairs from an object", что и подтверждает пример вроде:> let o1 = { x: 1, y: 2 }; let o2 = { x: 42, z: 3 }; let o3 = { ...o1, ...o2 }; o3 < {x: 42, y: 2, z: 3}Иначе бы такая merge конструкция не очень работала, по крайней мере с assign такое нельзя (там только два аргумента - target и source)... И я готов был поклясться, что assign не работал для неитерируемых... Что они уже после ES2018 накрутили, чтобы даже скалярный объект воспринимался как валидный, мне не очень понятно (как и для чего это собственно есть нужно и хорошо). Для меня это выглядит как жуткий баг/хак (UB на худой конец), но то такое...
JS, слава богу, не мой язык - я его пользую (вынужден) только поскольку без оного в браузерах никуда (к моему большому сожалению). Во всех же других языках "Object" (aka keyed collections, dictionaries, maps или associative arrays) вполне себе iterable (или как минимум enumerable) и никакого ментального диссонанса при использовании spreading / expanding операторов не возникает, даже если по умолчанию оно за бортом и реализовано с помощью тех же assign-подобных конструкций (чтобы, производительности ради, не разворачивать списки от дефолтных "итераторов" в стек).mayorovp
23.11.2021 22:06просто когда (в proposal ES2018 если не ошибаюсь) речь велась про object literals, это определялось как "pass all key:value pairs from an object"…
…что как раз и означает взятие всех перечислимых собственных свойств объекта. Если что, перечислимость свойств — куда более древнее понятие, нежели Symbol.iterator. Собственно, оно древнее символов.
по крайней мере с assign такое нельзя (там только два аргумента — target и source)
Э-э-э, но ведь у assign можно указать произвольное число аргументов!
Что они уже после ES2018 накрутили, чтобы даже скалярный объект воспринимался как валидный, мне не очень понятно
А почему он, собственно, не должен восприниматься как валидный, если spread operator в контексте литерала объекта изначально создавался для работы со скалярными объектами?
RAX7
24.11.2021 12:44+1даже скалярный объект воспринимался как валидный
У примитивов нет свойств и методов https://javascript.info/primitives-methods , поэтому если сделать "pass all key:value pairs from an object", то получим в результате пустой объект. В этом нет ничего противоречивого, хотя с непривычки может выглядеть странно.
Во всех же других языках "Object" (aka keyed collections, dictionaries, maps или associative arrays) вполне себе iterable
Всё же object и collections, dictionaries, maps разные типы. Оbject является базовым для всех них, но итерабельным эти типы делает наличие специальных методов/свойств реализованных в этих типах.
Возьмем в к примеру C#
object o = new { Name = "John", Age = 21 }; foreach (var item in o) { } // Error CS1579 foreach statement cannot operate on variables // of type 'object' because 'object' does not contain a public instance // or extension definition for 'GetEnumerator'Есть некий объект с анонимным типом, который привели к базовому типу object, но для итерации требуется наличие метода GetEnumerator. Так же и в JavaScript объект - это всего лишь базовый тип, а то, что его используют как словарь/ассоциативный массив так это только потому, что в js изначально не было специальных типов для коллекций.
nin-jin
23.11.2021 09:07По спредам, кстати, можно в статью добавить, что если передача массива в функцию - константная сложность, то передача элементов через спред - это уже линейная, ибо компилятору проходится копировать массив в стек. Соответственно, получаем ещё и риск переполнения стека.

maximzhukov
22.11.2021 19:30+3Сама статья является хорошим напоминаем помнить об алгоритической сложности кода который вы пишите, но ни reduce ни destructuring assignment сами по себе не дают вам O(n^2). Есть тысяча и один способ написать код неэффективно.
faiwer Автор
22.11.2021 19:42по себе не дают вам O(n^2)
Как кстати, такие вещи более точно посчитать? И как записать? Умом то я понимаю, что "чистый квадрат" был бы если бы и на первых итерациях было N операций. Получается что это
O(((1 + N) ^ N) / 2). Но какая-то шибко мудрёная запись. Кажется в пределе получаетсяO((N^2) / 2), что по сути эквивалентноO(N^2)Есть тысяча и один способ написать код неэффективно.
Но больше всего мне "краше" именно этот. Потому что его прямо пропихивают из каждого утюга. По сути это становится стандартом жанра.
upd.
но ни reduce ни destructuring assignment сами по себе не дают вам O(n^2)
Кажется я не сразу вас понял. Я подумал вы про то, что я неправильно BigO посчитал. А вы имели ввиду то, что по отдельности они
O(n)и не страшны? Да, согласен. Нормальные инструменты. Ничего против не имею.maximzhukov
22.11.2021 20:15Да, я именно про то что по отдельности все эти инструменты (ингридиенты) хорошие. Проблемы возникают уже в процессе их совместного применения (рецепте приготовления).
mayorovp
22.11.2021 22:19+2Получается что это O(((1 + N) ^ N) / 2). Но какая-то шибко мудрёная запись.
Наверное, вы
O(((1 + N) * N) / 2)имели в виду, а не возведение в степень и не xor.
Так вот,O(((1 + N) * N) / 2)строго равноO(N ** 2), причём это верно в обе стороны.faiwer Автор
22.11.2021 22:21+1Да, конечно, спасибо. Немного спешил и получилась ерунда, я имел ввиду
* N. Это формула суммы членов арифметической прогрессии.
Medeyko
22.11.2021 23:27+1Возможно, не всем понятно, почему получается эквивалентность, в обе стороны. Попробую на этом же примере и продемонстрировать, почему.
Учитывая, что 1 <= N выполняется для всех натуральных N:

Это в одну сторону. А в другую, учитывая, что 0 <= N выполняется для всех натуральных N:

Т.е. с точностью до константы, как подразумевает О-нотация. (C = 2)
aamonster
22.11.2021 23:02+1O(n) + O(1) == O(n). Большее слагаемое поглощает меньшее.
O(n*2) == O(n). Константный множитель неважен.
Можете теорию почитать, но на практике достаточно этого (и памяти, что все эти O – только при n стремящемся к бесконечности)
faiwer Автор
22.11.2021 23:05Разве я не тоже самое написал? :) (если учесть опечатку с
^вместо*)aamonster
22.11.2021 23:31+3На итог то же самое. Просто коммент создал ощущение какой-то неуверенности в том, как работать с O(...), вот и позволил себе напомнить несложные правила их упрощения. Извиняюсь, если задел.
faiwer Автор
23.11.2021 00:15Да не, что вы. Всё ок. Я признаться вообще не силён в математике, и понимаю всё это примерно на том уровне, что вы и описали. Мысленно возвожу всё в предел и убираю лишние константы. По сути наибольшую сложность представляет определить изначальную формулу.
vkni
23.11.2021 06:34Да там первые 50 страниц Уиттекера Ватсона. Очень просто всё.
aamonster
23.11.2021 16:02Не оверкилл?
А за упоминание книги спасибо, возможно, пора освежить в памяти матан, и она как раз подойдёт.vkni
23.11.2021 17:40Да нет, не оверкилл. Это же проходят все студенты по тех. специальностям. Зато после нормального курса по рядам все эти интервьюшные задачи O(N) вызывают лишь один вопрос - "а проблема-то, собственно, в чём?".
aamonster
23.11.2021 17:47Не, ну так-то для себя лишним не будет, конечно. Я имел в виду – для такой задачки нет "математической" сложности в подсчёте, сложность только в наработке рефлексов типа "а вот тут ещё внутренний цикл вылезает, надо не забыть его учесть".
0xd34df00d
23.11.2021 21:03+1Бывают алгоритмы, где для более точной оценки надо брать всякие интегралы (и там тогда видно, что алгоритм n logn, а не n²). Это уже не так очевидно.
vkni
23.11.2021 23:26Бывают варианты, когда обыкновенные диффуры надо решать (метод, описанный у Кнута в "Конкретной математике" и у Седжвика на Курсере) :-). Но без хорошей базы в виде семестра-двух банального матана (пределы, последовательности, ряды и асимптотики) про сложность алгоритмов лучше вообще не заикаться.
vkni
23.11.2021 23:38+1Диффуров там точно нету.
Я может быть ошибаюсь, и уже не помню, но эта книжка мне показалась именно переусложнённой из-за того, что рассчитана на студентов, не изучавших нормально матан.
vkni
23.11.2021 06:30+2Если вы хотите считать точно, то вам нужно
а) Выделить операции, которые представляют для вас интерес (это может быть доступ по указателю, сложение, деление, вычитание и т.д.). Причём если правильно учитывать архитектуру машины, ответ может быть крайне неочевиден.
б) Выписать кол-во этих операций в зависимости от кол-ва обрабатываемых алгоритмом элементов с нужной вам точностью (как правило - до старшего коэффициента). Как правило, это делается рекурсивной формулой, а дальше с использованием производящих функций переводится в явную.
По второму пункту есть отличный курс профессора Cеджвика - https://www.coursera.org/learn/analytic-combinatorics
Но он требует ТФКП (теория функций комплексной переменной), а именно - теории вычетов + курс по Обыкновенным Дифференциальным Уравнениям.


JordanoBruno
22.11.2021 23:10-7Особенно в мире Javascript, который как известно скриптовый язык с динамической типизацией, и, поэтому, не предназначен для решения задач, которые требуют настоящей производительности.
Настоящей - это какой? Так-то nodejs даже на embedded-системах запускают. А во-вторых, есть вполне себе возможности выполнить родной бинарный код через C/C++/WASM, который очень все быстро посчитает, если надо.
Большинству разработчиков даже особо задумываться не приходится нынче, настолько производительные системы и V8 на текущий момент. Вот раньше было да, на iPhone 3G, если не ошибаюсь, был лимит в 256 Кбайт на страницу, там приходилось аккуратно писать, с учетом перформанса и расхода памяти.
mayorovp
23.11.2021 00:08+4А во-вторых, есть вполне себе возможности выполнить родной бинарный код через C/C++/WASM, который очень все быстро посчитает, если надо.
Но ведь это и называется "не предназначен для решения задач, которые требуют настоящей производительности"
JordanoBruno
23.11.2021 00:28-2Если бы был не предназначен, то не было бы 1100+ модулей, использующих C/C++: https://www.npmjs.com/package/node-gyp?activeTab=dependents
И это только то, что в npm.
faiwer Автор
23.11.2021 00:24WASM
Мой небольшой опыт показывает, что WASM как раз быстро вам не посчитает. У нас получалась 10 кратная разница в сравнении с бинарником.
JordanoBruno
23.11.2021 01:09Вот здесь разница незначительная в сравнении с бинарником, а где-то даже и быстрее. Мне трудно судить по Вашему случаю, так как неясно, на каких алгоритмах тестировали и как реализовано.
faiwer Автор
23.11.2021 01:13Это был алгоритм SHA1 который прогонял через себя сотни тысяч коротки строчек (примерно по 50 символов). Написан на C, скомпилирован через empscripten. Других деталей дать не могу, увы, ибо NDA. Asm.js версия в chrome была равна по скорости WASM.
Полагаю, что очень опытный системный программист смог бы всё отладить и переписать так, чтобы обойти все трудоёмкие для WASM-машины места. Но это не я, я не настоящий сварщик. То что я смог это всё собрать и запустить — уже удача :)

souls_arch
23.11.2021 00:24-3В 1ом пункте сами же все сказали: при малых n разницы никто не видит . И возможные проблемы верно указали. Но основная мощь стримов и лямбд именно в поддерживаемости кода и лучшей читаемости. Понятно, что потом до кода может добраться безголовый джун, но сташие не дадут и заставят переделать. А умный и опытный городить огород на таких конструкциях не станет.
faiwer Автор
23.11.2021 00:29+5Ну дык никто не запрещает вам мутировать аккумулятор в лямбде. И волки сыты, и овцы целы. Разве что внутренний перфекционист может немного негодовать, что идеалы попёрты и семантика искажена. Но лучше бы этот внутренний перфекционист переживал за более насущные проблемы, относящиеся к business value.
А умный и опытный городить огород на таких конструкциях не станет
Повторюсь, этот "паттерн" стал НАСТОЛЬКО популярен, что лезет изо всех щелей. Люди вообще не видят в этом проблемы. И такой код уходит в прод. А потом у людей "react тормозит".
Хотя тормозят они, кажется, сами.
antonkrechetov
23.11.2021 00:28+3Я считаю, корень проблемы — в дизайне стандартной библиотеки. Как раз на такой случай должен быть модифицирующий метод для объединения массивов, который ведет себя, как concat(), но меняет массив и возвращает его же. Да, объединять массивы можно с помощью push() или splice(), но оба этих метода:
1. Не возвращают сам массив, из-за чего их неудобно использовать.
2. Это не самые очевидные функции для объединения массивов. Не уверен, что все помнят, что push() принимает произвольное количество параметров. В то время, как concat() — «сертифицированный» аутентичный способ.
Собственно, все эти npm-пакеты из одной функции тоже намекают, что в библиотеке есть, что улучшать.

emaxx
23.11.2021 00:31Примеры красивые, но есть какие-нибудь данные о том, насколько часто "квадраты" в реальном коде возникают в таких "локальных" ситуациях - т. е. когда весь относящийся к "квадрату" код представляет собой несколько строк кода внутри одной функции?
По ощущениям, очень часто самые тяжёлые квадраты появляются из-за неудачных абстракций - и обнаружить их гораздо сложнее, потому что они "живут" на другом уровне, и для их обнаружения требуется держать в голове детали реализации разных компонентов (а исправление может потребовать редизайна абстракций или, скажем, намеренного их нарушения в конкретном месте).
И тогда может оказаться, что оптимизация работы отдельных .map()/.reduce()/и т. п. - это просто экономия на спичках, потому что настоящее бутылочное горлышко будет в других, менее очевидных местах. В таком случае чрезмерный акцент на этих локальных оптимизациях как не даст ощутимого прироста в производительности, так и, возможно, увеличит вероятность багов из-за менее читаемого кода.
faiwer Автор
23.11.2021 00:40+1Статистики нет. Не уверен что кто-то вообще такие вещи собирает и анализирует. Всем надо фичи в прод доставлять. Но для меня давно очевидно, что, при прочих равных, лучше писать такой код, который гарантировано не вызовет проблем в будущем (на всякий случай повторю — при прочих равных). Ведь в будущем вы просто переиспользуете готовый рабочий, возможно даже протестированный, механизм, не вникая во все его нюансы изнутри (потому что на это нет решительного никакого времени, читать эти тыщи строк кода). Примерно прикините: ну тут нечему тормозить, потому что оно под капотом должно делать А, B & C. А оно на самом деле делает (AA + BB) * C, потому что разработчику этого хватало на его "кошках" в дев-режиме. Что самое печальное, возможно и вам этого хватит. А вот конечный юзер уже взвоет. Его жалоба дойдёт до вас через полгода. Сколько денег за это время упустит бизнес?
И при всём при этом речь идёт об одной строке кода, необходимость которой, очевидно ещё до её написания. Нелепая ведь ситуация. Речь ведь не об "перемудрёной архитектуре" или "сложном алгоритме", который требует кучу времени на реализацию и поддержку. Просто… одна… строка… кода.
Живой пример. Есть такая библиотека для тестирования react-компонент — enzyme. Я использовал её для одного средних размеров проекта. В какой-то момент я понял что мои тесты непозволительно тормозят, там где этого ну категорически быть не должено. Там ведь тупо нечему тормозить. Оказалось ребята из airbnb (кажется) смогли сделать обход дерева в ширину за
O(n^2)(или даже хуже). Я monkey-patch-ул метод простой наколеночной реализацией и всё залетало. С тех пор я опасаюсь пользоваться их npm-пакетами.emaxx
23.11.2021 00:59Я согласен с вами, что красивые примеры в статье таковы, что исправление квадрата в них не усложняет кода. Поэтому да, почему бы и не поправить их. И так же я согласен, что когда создаёшь библиотеку, все применения которой ты заранее не знаешь, то нужно постараться сделать адекватную асимптотику или по крайней мере задокументировать оценки производительности.
Но ведь в реальности обычно по-другому, и нет "белого" или "чёрного". Разработчик работает с километрами кодовой базы, в которой то тут, то там спрятаны квадраты. И какие-то поправить совсем легко, какие-то посложнее, а для каких-то потребуется уже отдельный мини-проект. Копья в code-review будут ломать как раз вокруг этого случая "посложнее", когда ускорение кода возможно путём некоторой потери читабельности или, скажем, расширяемости. Практический толк от каждой из таких оптимизаций будет, скорее всего, мизерным - до тех пор, пока в коде остаются другие квадраты.
faiwer Автор
23.11.2021 01:09+1какие-то посложнее, а для каких-то потребуется уже отдельный мини-проект
Всё так. Но данная статья про один (ну ок два) конкретных use-cases. Ни больше, ни меньше. Я не продвигаю тут идею, что за BigO надо стоять горой и слать всех коллег на три буквы. Всегда и везде есть конкретные обстоятельства, в которые нужно вникать.
Практический толк от каждой из таких оптимизаций будет, скорее всего, мизерным — до тех пор, пока в коде остаются другие квадраты.
Если продолжить эту идею то все наши решения это некий компромис. Всегда есть что-то на одной чаше весов, и что-то на другой. Я не ставил перед собой задачу дать рецепт на все случаи жизни. Я просто прошу перестать людей писать квадраты в очевидных местах, где эти квадраты ну нафиг не нужны и ничего не стоит их убрать. Вы сами заметили, что это не усложняет кода. Вот я именно об этих случаях, а не абстрактно обо всех возможных вообще.
Например я не призываю отказываться от регулярных выражений. Хотя если переписать вручную почти все места их использования в типовом приложении оно только выиграет по производительности. Но сильно проиграет по цене разработки. К тому же вполне вероятно эта победа по скорости никем не будет замечена. Скажем какой смысл писать руками сложный валидатор на имя пользователя, если это можно сделать одной строкой. У меня есть знакомые программисты, которые никогда не пишут регулярок, потому что "они медленные". Я их не понимаю. Каждому инструменту своё применение.
Alexandroppolus
23.11.2021 02:24Регулярки регуляркам рознь. Некоторые работают за линейное время (от длины строки), без возвратов, и вряд ли можно заменить их на код более быстрый; а иные - за экспоненциальное время, если написать по-дурацки. Хотя тут опять же от движка зависит. Сафари меня удивил, он умеет плохие реги разрулить.
aamonster
23.11.2021 16:10Плохие – это какие?
В смысле, это всё ещё регулярные выражения, просто "неудобные" для рекурсивного алгоритма (но нормально обрабатываемые Thompson's construction)? Или нечто с backreferences, что, вообще говоря, не является регулярным выражением, просто впихнуто в их синтаксис?Alexandroppolus
23.11.2021 16:26+1это всё ещё регулярные выражения, просто "неудобные" для рекурсивного алгоритма (но нормально обрабатываемые Thompson's construction)?
Скорее всего они самые.
Вот тут неплохо раскрыто: https://learn.javascript.ru/regexp-catastrophic-backtracking
aamonster
23.11.2021 17:15Ага. Первый случай, да: нет ни единой осмысленной причины им так медленно работать (ну, кроме того, что авторы движка не читали теорию регэкспов). Прямо-таки иллюстрация по теме статьи, только гипертрофированная, вместо жалких квадратов – экспонента.
Alexandroppolus
23.11.2021 19:28Самый прикол в том, что движок с медленными регексами невозбранно используется в V8, и то что за прошедшие годы ничего не поменялось, немного странно.

Fragster
23.11.2021 16:20+5до тех пор, пока в коде остаются другие квадраты.
Странный это был отдел. Лозунг у них был такой: «Познание бесконечности требует бесконечного времени». С этим я не спорил, но они делали из этого неожиданный вывод: «А потому работай не работай - все едино». И в интересах неувеличения энтропии Вселенной они не работали.

mrsantak
23.11.2021 11:21+6Оказалось ребята из airbnb (кажется) смогли сделать обход дерева в ширину за
O(n^2)(или даже хуже).Пфффф, вообще фигня. Мы пару месяцев назад нарвались на багу, из-за которой coursier (он у нас в билд системе используется для выкачивания зависимостей) при билде падал в ООМ. Ему около 50 гигов оперативки стало требоваться для построения репорта в json формате. Как выяснилось там ребята как раз посчитали, что метод
+у списка должен обновлять существующий список, а на деле он создавал новый. Как результат у них алгоритм обхода дерева в глубину начал обходить граф по всем возможным маршрутам в графе. А там уже что-то околоэкспоненциальное вылезает. При этом они там умудрились этот алгоритм еще и по нескольким местам раскопировать в коде.
JordanoBruno
23.11.2021 02:30-4Люди на собеседованиях не видят никакой проблемы в вызове .includes внутри .filter и подобных штуках.
Меня больше пугает, что есть люди, которые видят в этом какие-то проблемы. По-моему весьма глубокому опыту, проблемы с производительностью возникают из-за неверно выбранной архитектуры как софта, так и баз данных. Как показывает практика, один кривоватый запрос или неверная структура базы могут поставить жирнющий такой крест на всех JS-оптимизациях. Или еще хуже - пачка запросов в цикле, иногда скрытых в ORM. Именно это мне приходилось часто исправлять за многими разработчиками, причем некоторые были весьма опытные. И на собеседованиях я спрашиваю, как кандидат умеет оптимизировать софт по производительности, это многое показывает и рассказывает получше любых тестов. А если уж алгоритмы в JS начинают тормозить, то есть отличный вариант - вынести его в микросервис, написанный на чем-то быстром, либо вшить нативный/wasm кусок.
Alexandroppolus
23.11.2021 02:54+8А если уж алгоритмы в JS начинают тормозить, то есть отличный вариант - вынести его в микросервис, написанный на чем-то быстром, либо вшить нативный/wasm кусок.
Сначала поправить асимптотику до оптимальной. А там, глядишь, и не надо будет возиться с нативщиной. Сабж о том, что незачем на ровном месте делать n^2 вместо n.
faiwer Автор
23.11.2021 11:14+1Судя по вашему комментарию вы про nodeJS backend (SQL, ORM, micro-services). Там своя специфика. Вы там не сталкиваетесь с описываемой мною проблемой, потому что на backend стороне никто не играет в immutability. Вот вам и кажется что проблема надуманная.
JordanoBruno
23.11.2021 13:09-4Вы там не сталкиваетесь с описываемой мною проблемой
Я бы так сказал - важность проблемы сильно преувеличена. Намного чаще встречаются на фронте другие ошибки в архитектуре, от которых производительность проседает весьма заметно. Как пример могу привести npm модуль react-dates от той же компании AirBnB. На всякий случай напомню, что это виджет с массой фич по выбору дат, периода дат, отображения календаря и т.д. Там постоянно народ жалуется, что виджет подтормаживает, например, вот. Проблем с производительностью там масса и корни разные, я даже изучал эту проблему внимательно, хороший кейс. Как Вы наверное догадались, проблемы не связаны с теми, которые Вы описали. Не буду раскрывать заранее карты и оставляю Вам возможность изучить реальные причины проблем с производительностью в React-проектах. Может напишете еще одну статью :).
faiwer Автор
23.11.2021 13:30+5Я бы так сказал — важность проблемы сильно преувеличена
Можно пример преувеличений с моей стороны?
от той же компании AirBnB
Похоже это уже не случайность, а закономерность
оставляю Вам возможность изучить реальные причины проблем с производительностью в React-проектах
Пройденный этап? Да я в состоянии написать цикл статьей про архитектурные проблемы React SPA. Но мне лень — это очень большой объём работ.
А теперь главное. О чём статья:
- есть проблема
- может быть критичной, может не быть
- очень широко распространена
- потому что огромный процент обучающих материалов повторяют эту ошибку
- она элементарно избегается ещё на стадии написании кода и не относится к preliminary optimizations
- ей подвержены разработчики самых разных уровней
- её лёгко продемонстрировать, её легко объяснить
Вышестоящего по вашему не достаточно для того чтобы привлечь к этому внимание?
Нет ну так то я могу написать и статью про "Обращение к Javascript сообществу: перестаньте выполнять сетевые запросы последовательно" и многие другие. Это как-то отменяет необходимость конкретно этой статьи?
P.S. мне стыдно за JS сообщество, что приходится объяснять что O(n^2) вместо O(n) это плохо, а когда разница заключается в одной строке, это прямо позорно.
faiwer Автор
23.11.2021 14:01+9JordanoBruno вопрос. Я тут подумал… А если я напишу статью про вредные последствия последовательных сетевых запросов вместо параллельных, вы не напишете что-нибудь вроде:
Меня больше пугает, что есть люди, которые видят в этом какие-то проблемы. Проблема сильно преувеличена. По-моему весьма глубокому опыту, проблемы с производительностью возникают из-за неверно выбранной архитектуры. В реальных SPA я встречал другие более серьёзные проблемы. Да и если у человека низкий сетевой latency, то он и не заметит никаких проблем.
Вы не будет отстаивать позицию, что сразу писать
await Promise.allвместо серииawaitэто предварительная оптимизация, а внимание стоит уделять более серьёзных архитектурным факапам?Или если я напишу статью про "не запрашивайте записи из РСУБД по ID по одной, сделайте это в одном запросе", вы не скажете, что я перегибаю палку, т.к. существуют более серьёзные архитектурные проблемы, и если latency к СУБД меньше 2мс то никто не заметит разницы в производительности? И что вообще есть же кеширование, так что проблема не так ярко выражена, и лучше написать статьи про более серьёзные проблемы.
А если я напишу статью про "умоляю, начните валидировать данные пришедшие с клиента"? Не появятся комментарии про "ну безопасность надо гарантировать на всех слоях приложения, а не только на уровне валидации\санитации\whatever"?
Я просто всё никак не могу взять в толк, откуда такое яростное сопротивление (не только у вас), в очевидно косячном куске частотного кода, который сверх-тривиально фиксится и должен был быть так написан с самого начала.
JordanoBruno
23.11.2021 14:08-1А если я напишу статью..
Так Вы напишите сначала, потом будет видно, как я могу судить по тому, что не сделано? Есть масса случаев, когда те же последовательные запросы выгоднее параллельных. Вы опишите свой конкретный пример, я по критикую, если будет повод. Может Вы толково все распишите и я Вас только похвалю за аргументированность и точность в формулировках.
Я просто всё никак не могу взять в толк, откуда такое яростное сопротивление
Нет никакого яростного сопротивления, о чем Вы? Я лишь к тому, что описанная Вами проблема не критичная для большинства, да и проблемой не является вобщем. Это как красить двери у покосившегося дома.
faiwer Автор
23.11.2021 14:27+10Есть масса случаев, когда те же последовательные запросы выгоднее параллельных
Пример? Сразу даю вводную: браузер, latency=1000ms. Я весь во внимании. Любые примеры про пул-запросов отбрасываю (т.к. там есть параллельные запросы).
Это как красить двери у покосившегося дома.
Спасибо за пример. На нём хорошо видно в чём проблема. Итак, дано:
- покосившийся дом
- некрашеные обшарпанные двери
Правильное решение:
- срочно исправляем проблему с каркасом дома
- красим дверь, покрываем лаком
- При постройке новых домов — нанимаем адекватного архитектора, чтобы дом проблем с каркасом не возникло
- Малярам выдаём более качественную долговечную краску и не забываем про лак
Решение от JordanoBruno (то как я вижу вашу позицию):
- срочно исправляем проблему с каркасом дома
- дверь не красим, т.к. это не проблема. Нет ну правда. Вот покосившийся дом это проблема, да. А дверь… эх, вот дом вспомните, кривой какой был! Ух вот это была проблеееема. Да что вы пристали ко мне с этой дверью? Идите лучше ещё один дом постройте. А я вам потом отзыв оставлю.
JordanoBruno
23.11.2021 14:25-4Можно пример преувеличений с моей стороны?
Пожалуйста:
замедляет программу
Очень не значительно, по сравнению с другими ошибками в архитектуре
т.к. Javascript однопоточный - препятствует работе пользователя с UI
Чтобы препятстовать работе пользователя, это должны быть заметные лаги, то есть 0.2 сек. и более. Это ж какие алгоритмы и объем данных должны ворочаться? Вы так уверены, что большинство с таким сталкивается? Я что-то сомневаюсь.
тратит батарейку ноутбука или телефона на бесполезную работу
греет ваше устройство и заставляет работать кулерКрайне незначительно по сравнению с тремя десятками открытых табов. И уж кулер точно не из-за "reduce" работает.
Но мне лень — это очень большой объём работ.
Никто ж не говорит, что нужно писать сразу про ВСЕ проблемы разработки в React. Выберите самую популярную причину тормозов БОЛЬШИНСТВА проектов React. Я думаю, это будет очень интересно всем разработчикам.
Нет ну так то я могу написать и статью про "Обращение к Javascript сообществу: перестаньте выполнять сетевые запросы последовательно" и многие другие. Это как-то отменяет необходимость конкретно этой статьи?
Не отменяет, Вы можете писать о чем хотите, это ж Хабр.
P.S. мне стыдно за JS сообщество, что приходится объяснять что O(n^2) вместо O(n) это плохо
Это весьма очевидные вещи, но практически никак не влияющие на конечный результат. Именно поэтому большинство разработчиков особо не парится по этому поводу.
Скажем так, когда-то давно я тоже уделял этому время и удивлялся, как это люди допускают такие неэффективные(по-моему мнению) конструкции, ведь можно писать более эффективно. Но потом со временем и опытом понимание пришло - влияние на результат крайне небольшое и большинству заказчиков вообще все равно, будет ли ПО работать в два раза быстрее или два раза медленнее. Потом я побывал на стороне заказчика и понял, что действительно, такие оптимизации особо не влияют на результат. Такая вот правда жизни.
Drag13
23.11.2021 14:32Простите что вмешиваюсь, но
Это ж какие алгоритмы и объем данных должны ворочаться? Вы так уверены, что большинство с таким сталкивается?
Тут не всегда проблема с алгоритмами. Бюджетные модели (особенно телефонов) могут иметь такие проблемы. Вот про это https://habr.com/ru/post/564950/
faiwer Автор
23.11.2021 14:42+2Очень не значительно, по сравнению с другими ошибками в архитектуре
- Значительность зависит от конкретного кейса.
- Наличие ошибок в архитектуре не отменяет существования других ошибок
Выберите самую популярную причину тормозов БОЛЬШИНСТВА проектов React.
Я открыл ваш профиль и не вижу ни одной такой статьи. Что-то не сходится.
но практически никак не влияющие на конечный результат
Неправда. Это зависит от конкретного сценария. Асимптотические ошибки легко приводят к проблемам. Я уже неоднократно с этим сталкивался. Я даже привёл несколько примеров в этой теме. Причём для программиста они могут проявиться весьма неожиданно. Самое худшее — когда это приводит к финансовым потерям (поиск по слову Ikea).
Именно поэтому большинство разработчиков особо не парится по этому поводу.
С моей колокольни это не так: большинство разработчиков НЕ ЗНАЕТ как это работает. Мой опыт проведения собеседований прямое тому свидетельство.
Такая вот правда жизни.
А теперь я опишу как это выглядит с другой стороны: вы перестали воспринимать любые не фатальные проблемы, как проблемы. И кажется совсем (начисто) растеряли навык прогнозирования проблем.
P.S. у меня тоже богатый опыт. И вообще нас тут таких много (это ж хабр). Не стоит писать об этом в каждом 2-м комментарии ;)
JordanoBruno
23.11.2021 15:16-2Я открыл ваш профиль и не вижу ни одной такой статьи. Что-то не сходится.
Ну раз такие аргументы пошли в ход, то я даже не знаю, что ответить. Наверное пойду писать статьи по всем возможным проблемам в разработке ПО ).
faiwer Автор
23.11.2021 15:22+5Ну а что вы хотели? Я написал статью, которая будоражит мой мозг, которую я считаю очень важной для подрастающего поколения JS-разработчиков. Приходите вы с бинарными мышлением ("всё что приложение не убивает не существует") и с аргументами вида "лучше бы вы писали статью про что-нибудь важное" и "меня пугает что кто-то считает это важным". А когда я предположил что подобную критику я встречу, даже если напишу другие статьи (вроде последовательных api-запросов), я получил аргумент "ну ты напиши, а я, сделаю, так уж и быть, доброе дело, почитаю и покритикую". Вам не кажется что кто-то немного дерзит? ;) Кто-то с "глубоким опытом" и комментариями ментора.
Какое-то показное неуважение.
faiwer Автор
23.11.2021 14:51+2Ой, я пропустил кое чего.
Чтобы препятстовать работе пользователя, это должны быть заметные лаги, то есть 0.2 сек. и более
- Я регулярно вижу в консоли warning-и о том что какой-то код не уложился в кадр.
- Асимптотическим проблемам 0.2 сек вообще не рубеж. Проблемы с bigO это зачастую не конкретная строка, а сочетание нескольких методов (к примеру: медленный кусок кода прогоняется в цикле)
- Если это внутри анимации то 0.2 это очень много
Крайне незначительно по сравнению с тремя десятками открытых табов.
Chrome гасит неактивные вкладки, если это возможно. Поэтому десятки открытых табов это больше проблема памяти.
В целом я много раз натыкался на приложения которые соло выедают батарейку за кратчайшие сроки. Асимптотические проблемы, имхо, это один из главных кандидатов на эту роль. Но надо, конечно, разбирать каждый случай по отдельности. FAANG-и считают что это один из наиболее критичных навыков разработчика.
BigBeaver
23.11.2021 14:57+3Вы знаете, если в фоне двигать раздел или ядро компилировать, то эти ваши 0,2 секунды превращаются в 5 иногда. И если оно реально решается добавлением одной строки, то её надо добавить. Я понимаю, что время программистов дорогое и всё такое, но не настолько.
BigBeaver
23.11.2021 13:50+4Но ведь сразу добавить одну простую строку дешевле, чем потом профилировать проект или пытаться спрогнозировать развитие кода в долгосрок.
JordanoBruno
23.11.2021 13:56-3Дело в том, что влияние вышеуказанных методов на производительность весьма невелико и есть масса других, на порядки более влиятельных факторов. Именно поэтому данная проблема не является проблемой у большинства разработчиков. А преждевременная оптимизация - зло, как известно.
BigBeaver
23.11.2021 14:30+4А преждевременная оптимизация — зло, как известно.
Я не специалист по сабжу, но вы можете привести пример потенциальных проблем, вызываемых этой «оптимизацией»? Просто, по мне, она выглядит абсолютно бесплатной.JordanoBruno
23.11.2021 14:47-4Дожили, разработчики уже не знают цитат классиков )).
Как писал в свое время Дональд Кнут:
Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
Данное высказывание настолько известно и популярно, что мало кем оспаривается. Хотя мне больше нравится оно вот в таком виде:
What Hoare and Knuth are really saying is that software engineers should worry about other issues (such as good algorithm design and good implementations of those algorithms) before they worry about micro-optimizations such as how many CPU cycles a particular statement consumes.
BigBeaver
23.11.2021 14:53+3Так я и не оспариваю это утверждение. С чего вы взяли обратное?
Речь скорее о его применимости к сабжу, и вот полная цитата тут как раз скорее против вас, тк ни какого «waste enormous amounts of time thinking about, or worrying» тут нет. Это настолько же является «оптимизацией», насколько ей являются правила типа «всегда оборачивать тело if скобками», «писать default в switch», всегда экранировать строки и тд и тд. Понимаю, что примеры не являются полными аналогиями, но тем не менее.JordanoBruno
23.11.2021 15:09-2Вы немного неверно поняли как Кнутовское высказывание, так и его интерпретацию. Смотрите, вот тут полная его статья, откуда это высказывание, страница(268), почитайте, там весьма интересно:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.103.6084&rep=rep1&type=pdf
Надо понимать, что в 1974-м году программы исполнялись на весьма медленных процессорах и памяти там было с гулькин нос(по нынешним меркам), поэтому тогда скорость программы играла намного более существенную роль, так же как и расход по памяти. Но даже в те времена Кнут рассказывает, почему важно сначала написать программу, а потом уже ее оптимизировать(если потребуется и захочется). Про «всегда оборачивать тело if скобками» я вообще не понял, это не имеет отношения ни к статье, ни к кнутовскому высказыванию, чисто code style rules.
BigBeaver
23.11.2021 15:16+5Не очень ясно, почему вы считаете, что я совсем ничего не читал и ничего не понимаю.
Про «всегда оборачивать тело if скобками» я вообще не понял, это не имеет отношения ни к статье, ни к кнутовскому высказыванию, чисто code style rules.
Это просто пример good practice аналогичный сабжу по трудоемкости. Ну то есть, написать лишнюю строчку из статьи не сильно труднее и не сильно дольше, чем нарисовать пару лишних скобок.а потом уже ее оптимизировать
Я пытаюсь указать вам на то, что конкретное решение изначально обходится дешевле чем не только «оптимизация потом» но даже дешевле, чем создание тикета «попозже глянуть производительность».
Вас послушать, так можно и обход массива по столбцам вместо строк делать — потом оптимизируем, если что.JordanoBruno
23.11.2021 15:36-1Вас послушать, так можно и обход массива по столбцам вместо строк делать — потом оптимизируем, если что.
Эх, а я раньше считал, что у меня получается аргументированно пояснять свою точку зрения. Ну ладно, отвечу словами военного из известного мема: "На этом наши полномочия всё".
faiwer Автор
23.11.2021 15:03+7Дожили, разработчики уже не знают цитат классиков
Да знаем мы её. И да она нам осточертела. Но не потому что плоха, а потому что, по нашему мнению, вы её не правильно трактуете. Вот из вашей же цитаты:
about micro-optimizations such as how many CPU cycles a particular statement consumes
Что такое CPU cycles — это уже нюансы той самой константы, которую вытеснили из bigO. А что у нас тут?
and good implementations of those algorithms
А тут у нас bigO. А почему он тут среди "важных" вещей? А потому что, потенциально это бомба. Это не "small efficiencies".
Может ли описанная в статье проблема изменить bigO нагруженной части приложения? Легко. Просто поместите её туда как кусочек кода в цикле.

ookami_kb
23.11.2021 17:01+9Это просто маятник сильно качнулся в другую сторону. Если в 70-е надо было разработчиков убеждать не тратить много времени на преждевременное вылизывание кода, то теперь приходится их убеждать потратить хоть немного времени, чтобы превратить O(n^2) в O(n).
transcengopher
23.11.2021 15:04+4Замена O(n2) на O(n) — это как раз "good algorithm design".
Даже если на вашей машине разработчика это будет разница между 0.17мс и 0.2мс, то на машине пользователей вместо ваших тестовых десяти элементов легко может быть тысяча, и разница станет куда заметнее. Мой постулат состоит в том, что писать сразу более оптимальный алгоритм стоит куда меньше, чем переписывать готовый код когда он уже начал вызывать проблемы.
Для контекста. Самый большой репорт в моей памяти на данный момент составляет 35 тысяч строк, и каждая строка там тоже не из одного элемента. И нынешнее наше требование — поддерживать по 50 тысяч строк (с запасом чтобы). А по факту просто из-за хорошей гигиены, когда нам пришло обновлённое требование (цифра до этого была около 500), мы всего лишь нагенерировали нужное количество данных и убедились, что всё по-прежнему работает удовлетворительно. Код менять даже не пришлось.JordanoBruno
23.11.2021 15:28-2Мой постулат состоит в том, что писать сразу более оптимальный алгоритм стоит куда меньше, чем переписывать готовый код когда он уже начал вызывать проблемы.
Кнут - дядька опытный, зря не будет телеги прогонять, я бы все же прислушался ).
Мысль его понятна - в сложной программе даже не всегда сразу понятно, где именно тормозит, нужно профайлить или как-то по-другому замерять скорость участков кода. Сложная - это, грубо, человеко-месяцы затрат, а не пример из статьи, где и оптимизировать-то особо нечего.
transcengopher
23.11.2021 16:39+4Мысль его понятна — в сложной программе даже не всегда сразу понятно, где именно тормозит, нужно профайлить или как-то по-другому замерять скорость участков кода.
Одно другому не мешает. Если у вас где-то сложный код и вы там сразу не нашли O(n2), то это простительно, бывает со всеми. Бывает и так, что O(n2) — это вообще лучшая асимптотика из возможных.
Сложная — это, грубо, человеко-месяцы затрат, а не пример из статьи, где и оптимизировать-то особо нечего.
Оптимизация таких мелких примеров, где весь код вообще на одной странице монитора — не попадает в моих глазах под критерии premature optimization. Эти вещи не нужно искать с профайлером, понимаете? Достаточно немного подумать и поменять буквально пару строк кода, всё. У меня такие случаи занимают дополнительно ну максимум минут десять, а success story этого подхода я выше уже приводил в пример.

bbc_69
23.11.2021 17:08+2Не могу не заметить, что Кнут жил в другое время, писал на других языках и пользовался другими инструментами. Не думаю, что современное понимание его слов соответствует тому, что он имел в виду.
Готов поспорить, что он был бы сейчас не стороне тех, кто против скобочек.

movl
24.11.2021 06:43-1На сколько я помню, Кнут стремился чуть ли не к физическим обоснованиям эффективности алгоритмов. По сути, у него делается упор не на абстрактные алгоритмы и языки, а именно на их непосредственное исполнение в физическом мире. Его слова, наверное, можно трактовать как "минимальная форма частного, зачастую не является тем, что вам действительно нужно". Я не думаю, что эта проблема имеет какой-то временной характер. И действительно, если даже брать разбор с этими спреад операторами, то это легко можно оптимизировать во время интерпретации, при условии, конечно, что прототипы базовых классов не менялись, но это уже совсем другая проблема.
bbc_69
25.11.2021 10:03+1На сколько я помню, он говорил о том, что свои силы надо тратить эффективно. Среди примеров неэффективности был момент, когда разработчики правили код, который отвечал за ничего не делание.
Применительно к данной теме: Затраты на то, чтобы писать/не писать скобочки исчезающе малы, фактически отсутствуют. А профит есть и очевидный.
Не думаю, что в данном случае Кнута вообще стоит вспоминать, он писал совсем не о том.
movl
25.11.2021 19:30Да зачастую flatMap решает половину проблем связанных с reduce ...spread, и только сокращает количество скобочек. Сам я, стараюсь как можно реже допускать неявное увеличение асимптотической сложности алгоритмов. Spread оператор, мной воспринимается исключительно как средство выразительности языка. Проблема в том, что всё, так или иначе относящееся к стилю кода, обычно имеет множество субъективных критериев оценки. Не в том смысле, что это какая-то прихоть, а в том, что различные измеряемые критерии, могут быть очень важными для одних, и совершенно ничего не значить для других.
Возможно, я сильно ошибаюсь, но по моим впечатлениям Кнут проводит грань между творческим подходом к решению проблем, и постоянным повторением устаревших однообразных практик. Второй подход, как правило, и приводят к зацикливанию внимания на незначительных мелочах, в условиях перегруженной системы.
http://elib.ict.nsc.ru/jspui/bitstream/ICT/882/3/knuth_1974.pdf
Поэтому, самое эффективное решение, в случае данной проблемы, я вижу, не в том, что бы определить как нужно, и как не нужно писать код в относительно редких случаях. А скорее, в устранении причин, которые нас подводят к составлению подобных правил. Либо в доказательстве того, что единого хорошего решения не существует, но в этом случае придется заменить экстраполяции, уходящие в бесконечность, на практические и ясные методы измерения пользы.
В остальном же, я согласен с автором на 90%. Просто потому что реальные инструменты далеки от идеальных, и сам произвожу подобные "оптимизации" практически на автомате.

crazymax11
23.11.2021 15:03Проблем нет. Ощутимой пользы, в подавляющем большинстве случаев, тоже.
faiwer Автор
23.11.2021 15:10+3А скрытых случаев недостаточно чтобы взять это за правило? Под скрытыми случаями понимаю те самые ситуации где предположения программиста оказались ошибочными (вместо 5 языков или стран в деве на проде подсунили 200, вместо 5 разных товаров, покупатель купил 20, вместо одной записи, потребовалось показать 250, и т.д.)?
Если чему меня опыт и научил, так это в первую очередь тому, что мы все регулярно ошибаемся в своих оценках.
Для того чтобы этой проблемы не было обязательно ждать таску в Jira? Вот эта строка кода стоит того?
crazymax11
23.11.2021 15:21-1потребовалось показать 250
Судя по бенчмаркам, 250 элементов обработаются достаточно быстро.
Для того чтобы этой проблемы не было обязательно ждать таску в Jira? Вот эта строка кода стоит того
Эта строка кода не гарантирует, что проблем не будет. Проблема не в том, что
concatписали, а в том, что проектировали под список из 10-20 элементов. Ну будет вместоconcatчто-то более оптимизированное, а рендер не оптимизировали и UX неудобный т.к. изначально не предполагали больше 10 элементов в списке.faiwer Автор
23.11.2021 15:28+1Судя по бенчмаркам, 250 элементов обработаются достаточно быстро
Повторюсь — это вопрос конкретных условий как и где эти 250 элементов обрабатываются. Вы не натыкались на то что неправильный полифил на
Object.assignуничтожает производительность в старых бразуерах? Я натыкался. В IE8 (или IE7) календарики на форме инициализировались почти минуту. В Chrome такого поведения не было, т.к. полифил не применялся (да и v8 быстрее).Эта строка кода не гарантирует, что проблем не будет.
Давайте я перефразирую ваше же предложение:
Эта строка кода гарантирует, что этой проблемы не будет.
ну как? :)
crazymax11
23.11.2021 15:38-2это вопрос конкретных условий как и где эти 250 элементов обрабатываются.
Согласен, всегда следует оттакливаться от контекста. Есть контексты, где это важная оптимизация, которая ускорит процесс. Но, по моим ощущениям, их очень мало. А в большинстве контекстов неважно,
concatтам будет или неconcatну как? :)
Если честно, я не понял вашу мысль.
faiwer Автор
23.11.2021 15:41+2Если честно, я не понял вашу мысль.
Эта строка гарантирует что именно этой проблемы не будет. А это уже много стоит. Уж точно этой самой строки.
Есть контексты, где это важная оптимизация, которая ускорит процесс
Я вот сейчас понял… Я в принципе не воспринимаю эту штуку как оптимизацию. Это ведь никакая не оптимизация. Это код по-умолчанию.
Вы ведь не пишете:
source .map(something) .slice(5)а пишете:
source .slice(5) .map(something)Является ли 2-ая версия оптимизацией. На мой взгляд нет. Просто первая версия кривая.
crazymax11
23.11.2021 16:18Это ведь никакая не оптимизация
Смотря что понимать под оптимизацией. Но я не знаю определения, по которому код с
pushменее оптимальный, чем код сconcatЭто код по-умолчанию.
Просто первая версия кривая.
Это звучит очень субьективно
faiwer Автор
23.11.2021 16:22+2Это звучит очень субьективно
Если у вас 1-ая версия (где
sliceпослеmap, а не наоборот) может пройти code-review, я рад что не работаю у вас :) На мой взгляд это уже настоящее разгильдяйство.
crazymax11
23.11.2021 16:38+1Если у вас 1-ая версия (где
sliceпослеmap, а не наоборот) может пройти code-reviewДа, такой код может пройти code-review (как и код с
concat), если учитывать контекст применения кода. Например, если нам достаточно, чтобы код корректно работал и выполнялся не дольше минуты.я рад что не работаю у вас :) На мой взгляд это уже настоящее разгильдяйство
Стало еще более субьективно. А как же условия, контексты?
Предлагаю на этом сообщений завершить тред, т.к. от цифр мы пришли к обвинению в непрофессионализме, как в настоящем холиваре :)
faiwer Автор
23.11.2021 16:39+5Предлагаю на этом сообщений завершить тред
Согласен. На мой взгляд это уже за гранью добра и зла. Дальше смысла спорить нет. Мы друг друга не поймём.

Bronx
03.12.2021 07:33+2Это звучит очень субьективно
-- Зубы нужно держать в порядке, чтобы изо рта не воняло и других проблем позже не возникло.
-- Это звучит очень субъективно. Достаточно, чтобы сегодня зубы не качались и жевали, всё остальное -- преждевременная оптимизация.
crazymax11
03.12.2021 08:50Это очень спекулятивная аналогия.
В статье и комментариях есть замеры - reduce + concat на массиве из 1000 элементов отрабатывает около 2мс.
При обработке 1000 элементов, скорее всего, не эта операция окажется узким местом.
Более близкой аналогия была бы, если предположить, что статья предлагает использовать ополаскиватель для рта. Это полезно и с этим никто не спорит, но неиспользование ополаскивателя не является ключевым фактором проблем с зубами.
Bronx
03.12.2021 09:43+4Использование ополаскивателя требует действий сверх базовой гигиены. Использование линейного
reduce+pushилиflatMapвместо квадратичногоreduce+concatне требует ничего, кроме навыков базовой гигиены. Ну просто уже одно только знание, чтоconcatсоздаёт новый массив, аreduceгоняет цикл, и мы одно вставляем в другое, должно вызвать органолептическую реакцию "фу, грязь" и позыв найти нормальный способ.Я понимаю, если кто-то просто не знал/забыл про особенность
concat-- это ок, со всяким бывает. Если же знает, но сознательно выбирает из двух равноценных вариантов более грязный -- и даже настаивает на этом! -- и при этом у него нет серьёзных причин для такого выбора, то это явно проблемы с гигиеной.

Chamie
06.12.2021 20:01-1У кого квадраты с «чистыми» функциями вызывают реакцию «фу, грязь», а у кого мутирование массива push'ем.
Bronx
06.12.2021 20:23Здесь не мутирование абы какого массива, а мутирование внутреннего аккумулятора, специально для этого предназначенного. Чистота сохраняется, внешних эффектов нет, полная детерминированность. Сможете показать, как тут нарушена чистота?
mayorovp
06.12.2021 20:54+1Нарушена чистота внутренней функции, переданной в reduce. С внешней-то понятное дело что всё в порядке.
Bronx
06.12.2021 23:16Это-то понятно, но это именно что внутренняя лямбда, оказывающая эффект исключительно на внутренний аккумулятор, который лежит прямо тут же, рядом. Продолжая аналогию с зубами, у нас нет цели держать зубы чистыми ежесекундно и чистить их после каждого откушенного куска булочки. Это уже будет другая крайность -- обсессивно-компульсивный синдром.
Chamie
07.12.2021 15:09Продолжая аналогию с зубами, у нас нет цели держать зубы чистыми ежесекундно и чистить их после каждого откушенного куска булочки. Это уже будет другая крайность — обсессивно-компульсивный синдром.
Так ведь той же аналогией можно описать и избегание «квадратов» при обходе массива в 5 элементов.
Bronx
08.12.2021 04:46Не всякое избегание — обессивное расстройство. Эдак вы дойдёте до идеи что "гигиена — это тоже ОКР, ритуальное избегание грязи". Нужно же учитывать диапазон последствий. Что отличает здоровую гигиену от обсессивного растройства?
- Гигиена: в худшем случае — бесполезна, в лучшем случае — может сильно помочь.
- Обсессивное расстройство: в лучшем случае — безвредно, а в худшем — может сильно навредить.
Случай в 5 элементов — это то где
reduce+concatещё безвреден, аreduce+pushещё бесполезен. Это то место, где гигиена и ОКР могут показаться неотличимыми, но это не значит, что их можно приравнивать.
Chamie
08.12.2021 17:54Слушайте, ну ваши аргументы же точно так же можно развернуть в обратную сторону: в случае, когда у нас push в маленькой функции, в которой мы можем отследить побочные эффекты — он ещё безвреден, а concat — ещё бесполезен…
Bronx
09.12.2021 04:10А в где worst case у
push? На каких даных он становится вреден? И в чём best case уconcat, когда он становится полезен?

Cerberuser
09.12.2021 05:30+2Если я правильно понял логику Вашего собеседника, речь не о данных, а о коде: чем компактнее и понятнее функция, тем более допустимым в ней может быть использование побочных эффектов, т.к. они все будут на виду. Другой вопрос - зачем вообще использовать в reduce что-то больше пяти-шести строк...
Bronx
09.12.2021 09:03+2Ну в таком разрезе как бы да, если рассматривать независимые оси "код vs данные", то про
pushв маленькой функции можно сказать, что по оси "код" это "лучший случай ", а с ростом кода всё хуже. Но в процессе развития системы шанс случайно и непреднамеренно напороться на большие данные всё же выше, чем шанс случайно и непреднамеренно превратить двустрочник в функцию на пару экранов с кучей эффектов. Код ты сам контролируешь, а данные приходят в reduce извне, сегодня 5 элементов, а завтра 100500. Этот код какой-нибудь джун скопипастит не приходя в сознание, проблема вылезет у него -- а винить он будет того, у кого он код этот взял. Для общей кармы плохо :)
Chamie
09.12.2021 14:52Этот код какой-нибудь джун скопипастит не приходя в сознание, проблема вылезет у него — а винить он будет того, у кого он код этот взял. Для общей кармы плохо :)
Именно! Скопипастит и расширит, не следя за сайд-эффектами. Плюсы иммутабельно-функционального подхода же, в основном, как раз не в повышении производительности, а в упрощении контроля. А джун пусть лучше сначала пишет медленный, но гарантированно рабочий и модульный код, чем быстрый, но требующий вдумчивости в применении.
Bronx
10.12.2021 00:10Скопипастит и расширит
P(скопипастит) > P(скопипастит)*P(расширит|скопипастит)
Ну и если закладываться на "расширит", то ничто ему не мешает до куба расширить :)
не следя за сайд-эффектами
Как уже говорилось, сайд-эффектов тут нет. Есть эффекты, изолированные внутри чистой функции, т.е. очищенные.
Chamie
10.12.2021 02:37Ну и если закладываться на «расширит», то ничто ему не мешает до куба расширить :)
Да просто передаст в качестве второго параметра не пустой массив, а какой-нибудь существующий.Как уже говорилось, сайд-эффектов тут нет. Есть эффекты, изолированные внутри чистой функции, т.е. очищенные.
Давайте определимся: где «тут»? Функция, в которой этот reduce используется? Функция-редьюсер? Метод reduce?
Главная функция у нас будет чистая только если мы за этим проследим (этакий unsafe-код) это и есть «следя за сайд-эффектами» (что они не просачиваются наружу), функция-редьюсер у нас точно не чистая, а метод reduce так и вообще просто вызывает её в цикле, никак не ограничивая её в мутировании см. тот же пример выше с передачей существующего массива в качестве стартового значения «аккумулятора» (мне о нём больше нравится думать как об объекте межитерационного обмена).
Bronx
10.12.2021 05:02Давайте определимся: где «тут»?
Функция
(items) => items.reduce( (acc, item) => {...}, [])— является чистой что с
concat, что сpushвместо....Да просто передаст в качестве второго параметра не пустой массив, а какой-нибудь существующий.
Легко:
(items, init) => items.reduce( (acc, item) => { acc.push(item); return acc; }, [...init])— сложность кода такая же, эффективность на месте, никаких эффектов наружу не просачивается.
Хотя не очень понятно зачем — если мы переиспользуем аккумулятор для межитерационного обмена, то ожидаем, что в нём будет накапливаться результат прогона нескольких редьюсеров, и нам важно конечное значение аккумулятора, а не промежуточные.
BigBeaver
23.11.2021 15:10+3О чем и речь. Но при нулевых затратах даже «меньшинство» случаев означает огромную пользу для человечества, тк даже «меньшинство» это, как правило, очень много (в штуках), если мы говорим о вебе — при миллионе пользователей (запросов?) в день даже 1% это много.

Keyten
23.11.2021 05:34+13Кстати, знаете, как сделать вот этот код...
for (let idx = 0; idx < arr.length; ++ idx) { const item = arr[idx]; result.push(something(item)); }...читаемее в три раза?
Вот так:
for (let i = 0; i < arr.length; i++) { const item = arr[i]; result.push(something(item)); }

Zoolander
23.11.2021 09:27-4Согласен, описанные в статье практики могут выстрелить в ногу. Но они выстрелят в некоторых случаях. В большинстве остальных случаев читабельность важнее, так как огромное количество времени кодеров уходит на чтение и разбор чужого кода.
Поэтому стандартизированные общие практики в итоге позволяют экономить больше ресурсов, так как большинство кодеров в фронтенде не сталкивается с проблемой высоконагруженных систем.
Впрочем, тем, кто пишет серверный код - уже стоит призадуматься. Да, в серверном коде я бы не стал так яростно использовать цепочечные методы. На бэкенде и доли миллисекунды в итоге довольно быстро превращаются в большие выигрыши или большие потери.faiwer Автор
23.11.2021 11:19+6В большинстве остальных случаев читабельность важнее, так как огромное количество времени кодеров уходит на чтение и разбор чужого кода.
И насколько у нас упала "читабельность"? Код стал непонятным? :) Really?
JordanoBruno
23.11.2021 14:31В большинстве остальных случаев читабельность важнее, так как огромное количество времени кодеров уходит на чтение и разбор чужого кода.
Поддержу тут.
большинство кодеров в фронтенде не сталкивается с проблемой высоконагруженных систем
И тут тоже. В основном надо писать быстро, так как сроки поджимают.
тем, кто пишет серверный код - уже стоит призадуматься
Там все перекроют потери если лишний раз сходишь в базу. Лучше там пооптимизировать.

adam4leos
27.11.2021 07:05Я бы не откидывал фронтенд так просто. Вот, пару лет назад писал большую статью об огромной полезности знаний алгоритмов и структур данных во фронтенде на dou, с примерами применения.
crazymax11
23.11.2021 09:59Сделал бенч на jsbench.me и выглядит, что чтобы не уложится в 16 мс, нужно пару сотен элементов в массиве.
Это я не к тому, что использовать
concatвreduce- хорошая практика. Но из статьи выглядит, будто бы уже при 30 элементах в массиве будет проседать перформанс, однако это не так. Граница, когда все становится плохо, находится дальше и там, возможно,concatбудет не самой большой проблемой
Finesse
23.11.2021 10:20+3Пара сотен это не так много, как кажется. В 16 милисекунд нужно уложить не только обработку данных, но и модификацию DOM-дерева, и ещё оставить браузеру время на обработку изменений DOM-дерева, отрисовку интерфейса и обработку событий. На 5-летних устройствах всё это будет происходить раза в 2 медленнее. По-хорошему, обработка данных должна занимать не больше 1мс на железе разработчика.
faiwer Автор
23.11.2021 11:24+1Я так понимаю вы сделали следующие допущения:
- код запускается не в цикле (или циклах)
- код запускается всего один раз
- это единственный код который вообще запускается
В целом да. 30^2 операций не так много, чтобы соло создать performance bottleneck :) На моих примерах разница с линейной версией была всего в 4 раза.
crazymax11
23.11.2021 11:36Я повторил бенч из скриншотов из Firefox и Chrome. Там где сравниваются 2600 vs 30
faiwer Автор
23.11.2021 11:40Там по 3 примера: 1000, 100, 30. Ну просто для наглядности различий между
O(n)иO(n^2). 2600:30 это не количество элементов, это количество миллисекунд. И такая большая разница была как раз при 1000 элементах. При 30 всего 16:3. Что полностью соответствует теории — чем выше N, тем больше дистанция. Чем ниже N, тем меньше дистанция.crazymax11
23.11.2021 11:52-1Мне, при беглом прочтении статьи, показалось, что обработка 1000 элементов через
concatзанимает 2 секунды , а черезpush- 30 мс.Но там делается 1000 прогонов по 1000 элементов и потом замеряется общее время. Получается,
concatна 1000 элементов в среднем выполнялся за 2мс. Это, конечно, много и повлияет на рендер, но не прям драмматично.Если нам нужно эти 1000 элементов еще и отрендерить, то полезнее будет заняться оптимизацией рендера, а не заменой
concatfaiwer Автор
23.11.2021 12:01+5Это, конечно, много и повлияет на рендер, но не прям драмматично.
Да, всё зависит от обстоятельств. К примеру я не так давно долго ковырялся с MapBox картами. Мне нужно было "на лету" генерировать текстуры картинок, которые нужно показывать на карте. Возможных картинок до 170.
Первая рабочая версия была слишком долгой. На одну картинку (генерацию её blob-а) уходило 20ms. Пришла в голову идея переиспользовать существующий canvas между картинками (затирать часть областей и рисовать поверх). Удалось сократить с 20ms на 0.2ms.
Казалось бы — успех, ура. Но всё равно меньше 2ms на картинку не получалось достичь, т.к. даже готовую картинку mapbox съедает не меньше чем за 2ms. Просто тупо копирует ImageData побайтово целых 2ms. В случае картинки для retina в 4-6 раз медленнее.
А картинок до 170. Тут не то что в кадр не уложиться… тут вообще беда-беда. Стало очевидно что надо это дело дробить на чанки. Взял
requestAnimationFrame. Работает. Теперь общее время работы не условных 400-900ms а 11 секунд. Это никуда не годится. Но такова плата за асинхронность. Любые мои попытки как-то разбить вычисления на чанки приводили к тому что ломался JIT и всё замедлялось в разы (пусть и отзывчиво).К чему это всё я? К 2мс.
то полезнее будет заняться оптимизацией рендера, а не заменой concat
Безусловно, в первую очередь надо браться за bottleneck. А касательно
concatих не убирать надо. Их просто не надо писать. Всё просто. Не нужно с самого начала писать бредовый код.
faiwer Автор
23.11.2021 12:09Если нам нужно эти 1000 элементов еще и отрендерить
Кстати не факт, что нужно рендерить. Не все данные нужны для отображения.
Пример. Писал приложение для ручного формирования расписаний. Там были достаточно большие данные (почти все данные школы), чтобы ни в коем случае, нельзя было забивать на bigO, но выводилось их весьма ограниченное количество. Все проблемы с performance были на стороне объекто-дробилок (всякие фильтрации, вычисление подходящих окон для размещения урока, валидация и пр. и пр.). Вся эта объекто-вакханалия перевычислялась на лету при малейших изменениях.
Для примера стоило начать drag-n-drop-ать условный "Математика 2А класс Савельева Е.В." с панели "неразмеченных уроков" на "текущая проекция расписания" как нужно было за <16ms пересчитать все допустимые ячейки. Где-то у 2А уже урок, где-то нельзя, так как нормативы нагрузки перевыполнятся, где-то у учителя другой урок, где-то кабинет занят физиком, ну и т.д… Естественно это всё ещё и реактивное (иначе бы я вечность это писал).
Любые попытки написать это игнорируя квадратичную сложность на ровном месте просто уничтожили бы проект.

PoetLuchnik
23.11.2021 12:13+3Немного рановато для таких статей. Вот через пару лет когда наступит Производительный Кризис и цена эффективного кода будет выше чем цена быстрописного, тогда и пригодятся этот и подобные тексты.
Порой у меня создается ощущение что программирование это не про здравый смысл, а про моду и стиль. Используются популярные решения, а не эффективные. (надеюсь кто то скажет мне что я не прав)

debagger
23.11.2021 17:22Тут еще проблема в том, что при сдаче проекта редко кто пробует тестировать на рабочих объемах данных. А на тестовых всё работает, фичи не падают, анимации плавные и в целом замечаний нет.
debagger
23.11.2021 17:18+1У меня был случай лет 15 назад, когда на вопрос к разработчику, почему так тормозят расчеты в программе (Delphi + MSSQL) был ответ - это не мои проблемы, томозит - купите сервер помощнее. Пришлось самому лезть разбираться (пока он был в отпуске), в итоге тормоза пропали после добавления пары хинтов в SQL-запрос. Когда ему показал, как я решил проблему, в ответ было - ну давай везде эти хинты навешаем.
К слову - человек к тому времени уже лет 5 занимался исключительно клепанием CRUD-двухзвенок на этой связке, а я только начал тогда изучать работу с БД.
К чему я это рассказываю - ничего не поменялось за эти годы. Если человек не видит потенциальной проблемы в том, что список покупок в корзине обновляется 40 секунд, или что документ по уникальному реквизиту в системе документооборота ищется 5 минут, и если за такое ему не бьют линейкой по пальцам, а послушно докупают более мощные серверы и терпят убытки из-за потерянных покупателей - ничего не поменяется. Если повезет, придет другой разработчик, который парится за производительность и вычистит из кода квадраты, кубы и прочие экспоненты, но это должно еще повезти.
MFilonen2
23.11.2021 20:57+4Удивлён, что это вызвало такую большую дискуссию. Всегда был уверен, что переход от N к N2 – ну никак не незначительная потеря производительности. И классики говорили все же про оптимизации, изменяющие константу возле big O.
А уж если ради того, чтобы убрать одну строку кода на такое идут – что ж, теперь я понимаю, почему так много плохих сайтов в Интернете.Alexandroppolus
23.11.2021 21:34+5Самое смешное, что всякие алгоритмические мегамозги придумывают хитрейшие алгоритмы на 100500 строк, ради того чтобы выкинуть из bigO лишний ln N, и никто не утверждает, что они заняты фигнёй. А тут по сути на халяву разница на целый N, причем как в скорости, так и во вспомогательной памяти.
isergey87
23.11.2021 22:00+10Удивляет как здравый смысл (не делать ненужных действий) многие называют преждевременной оптимизацией.
В следующий раз когда пойдете в магазин возьмите тележку. Когда захотите положить туда товар - вернитесь возьмите новую тележку, положите туда товар. Когда снова понадобится положить товар - опять вернитесь и возьмите новую тележку, переложите все товары в новую тележку и добавьте новый товар. И так повторяйте каждый раз с новым товаром. Интересно использование одной тележки вы будете называть оптимизацией или просто здравым смыслом?
P.S. А потом выйдет GC из подсобки и будет очень рад числу ненужных тележек, оставленных по всему магазину.
interhin
24.11.2021 11:22Тоже считаю что всё что описано в статье, просто здравый смысл и это очевидно любому кто пишет код. Когда ты понимаешь что объем данных будет небольшой можно пренебречь ради читаемости.
0x450x6c
24.11.2021 11:13Справедливости ради, в случае массива, можно использовать flatMap:
Плюс я намеренно не стал сильно углубляться в объекты, сказав, что там всё сложно. Потому что в зависимости от реализации, любая операция с объектом может затребовать
O(logN)действий (если он скажем сделан при помощиbinary search tree). В общем и целом — объекты не массивы, они и сложнее и тяжелее.nin-jin
24.11.2021 12:49В тайпскрипте есть ReadonlyMap.
faiwer Автор
24.11.2021 12:53Я же не про типы. Я про оптимизированную структуру данных, с которой можно работать иммутабельно, без больших пенальти по производительности.
nin-jin
24.11.2021 12:57Так объекты тут ничем не отличаются. Даже медленнее работают из-за жонглирования скрытыми классами.
faiwer Автор
24.11.2021 12:58Да, я знаю. Я не имел ввиду того, что
Mapхуже чем{}. Наверное слишком косноязычно написал. Просто пожаловался на отсутствие желаемого. Но нас ждут#{}и#[]с ними будет поинтереснее.Nikitakun1
24.11.2021 13:25А вы же тут с самого начала обсуждаете пересоздание объектов? Не доступ по ключу? Доступ по ключу и у
{}, и уMapвсегда же будетO(1)?faiwer Автор
24.11.2021 13:34Я видимо с утра сильно непонятно пишу. Sorry. Я ни в коем случае не имел ввиду что
Mapимеет другие bigO, нежели{}. Выбор междуmapи{}это больше вопрос семантики и привычки. Я предпочитаюmap, т.к. никакие прототипы уже не играют никакой роли и явный вызов.get,.set,.hasпозволяет с первого взгляда понять, мы имеем дело со словарём. В то время какobj[key] =оставляет много возможных вариантов, и требуется больше вникать в код. Плюс, если объект не был создан как-нибудь такObject.create(null), то не стоит забывать про уже существующие свойства из прототипа объекта, который в случаеMapне будет. Плюс nin-jin правильно написал про hidden-classes. Но в случаеMapу нас меньше сахара. В общемMapvs{}это тема для отдельного занудного топика.и у Map всегда же будет O(1)?
Я бы не стал ручаться за все движки. Можно реализовать и за
logN. Плюс обратите внимание на "всегда". Если взять операцию записи (не чтения), то она будетO(1)только амортизированно. Т.е. в какой-то момент там будут всеO(n), т.к. под капотом система будет вынуждена пересоздать весь hashmap, но уже большего размера
0x450x6c
24.11.2021 13:31+1Всё как обычно: это зависит от обстоятельств. На моей практике было очень много примеров когда в массиве были сотни и тысячи полей. Просто словарик. Сейчас для таких целей завезли
Map, и я предпочитаю использовать его. НоImmutableMapу нас нет :)Всё так, только количество таких словарей мало, большинство объектов имеют мало полей.
Как вариант, для объектов вместо reduce можно использовать map + Object.fromEntries.
---
Немного переделал ваш тест, чтобы тестировать на объекты.
На firefox, ожидаемо занимает много времени: https://i.imgur.com/FUljbwl.png
Но интересно, что chrome смог это оптимизировать: https://i.imgur.com/IlA84PE.pngfaiwer Автор
24.11.2021 13:37Как вариант, для объектов вместо reduce можно использовать map + Object.fromEntries
Да, можно. Страшненько получается правда, поэтому не совсем понятно зачем. ИМХО читаемость куда ниже.
Alexandroppolus
24.11.2021 14:01+1Страшненько получается правда, поэтому не совсем понятно зачем
Когда мы поштучно добавляем новые поля в {}, меняются скрытые классы для него. Object.fromEntries, реализованный нативно, теоретически мог бы избежать этой проблемы. Хотя не знаю, как дело обстоит сейчас и что быстрее. Оно там внутри постоянно меняется.
0x450x6c
24.11.2021 14:14+1Этот вариант может быть предпочтительнее, для тех кто хочет обходиться иммутабельними структурами.
Я не против мутировать accumulator, но например eslint пока не сможет везде запретить мутации кроме accumulator'a, поэтому приходиться либо запретить везде либо разрешить.
Если вы решили запретить мутабельные структуры, то такой вариант (Object.fromEntries) вам подходить, во всех остальных случаях мутация accumulator'а предпочтительнее.
---
Читаемость можно улучшить с помощью вспомогательных функций, например:pipe( source, array.map(n => [n, n]), dict.fromEntries, );
Либо в будущем так:source |> %.map(n => [n, n]) |> Object.fromEntries(%)

Lynn
24.11.2021 17:16+2В случае объекта, там обычно не бывает тысячи полей.
Недавно на ruSO был вопрос как обойти ограничение браузера на (кажется) 48 миллионов(!) полей в объекте… O_o
{kind=link}
Smoquin
24.11.2021 11:16Может ли кто-либо, пожалуйста, привести пример неудачного includes внутри .filter? И пример оптимизации. Не уверен, что понял. Заранее благодарю!
faiwer Автор
24.11.2021 11:19-
.includesпробегает по всему массиву, поэтому тамO(n) -
.filterтоже пробегает по всему массиву, поэтому тамO(n) - итого если одно вызывается в другом, то вы получаете
O(n^2)илиO(n * m)(если это разные массивы)
В простых случаях, когда N и M крошечные, можно пренебречь (ну или нельзя, решайте сами). В остальных стоит задуматься — можно ли это дело исправить? В целом да и довольно просто. Надо просто один из массивов преобразовать в, скажем,
new Set. А потом уже использовать вместоarr2.includes(arr1val)аarr2set.has(arr1val). Разница на этой операции будетO(n)vsO(1)(либоO(logN)еслиSetсделан через binary search tree).На преобразование тоже уйдёт память и время. По времени
O(n)в случае hashmap, иO(n logN)в случае tree. Но эта операция не выполняется внутри.filterпоэтому погоды уже не делает.Ещё раз уточню. Если ваши
NиMравны, скажем, четырём, то сидеть колупать код резона нет :)Alexandroppolus
24.11.2021 11:42На преобразование тоже уйдёт время и память.
O(n logN)в случае tree.Откуда там logN? Дерево занимает O(n) памяти
upd: а, это время
faiwer Автор
24.11.2021 11:43Я про время, не про память. Сорри что запутал. Поправил комментарий (переставил слова)
tvictor
30.11.2021 21:38Подскажите, что лучше использовать в данной ситуации? Есть массив строк и поле для ввода. По мере ввода пользователя нужно фильтровать этот массив строк - в выборку должны попадать лишь те, что содержат введённую строку.
Когда массив строк не очень велик, вариант arr.filter(str => str.includes(value)) работает без тормозов, да. Когда нужно было это сделать на большом массиве строк (если правильно помню, 5000 строк), то использовал arr.filter(str => str.match(value)). На Includes были заметны тормоза, на match - летало.faiwer Автор
30.11.2021 21:49Есть много алгоритмов поиска подстроки в строке. Суть сводится к тому, что "в лоб" эту задачу быстро не решить. Но если изначально подготовить оптимальную структуру данных, перегнать в неё исходные данные, то потом по ним можно искать быстрее. Какой конкретно подойдёт лучше я не знаю, потому что ни разу не сталкивался с такой задачей. Точнее с самой задачей сталкивался, но всегда были крошечные объёмы, где код можно было писать ногами. Вот тут есть описания и сам список.
Ещё добавлю, что в рамках такой задачи не помешает предварительно:
- trim-ать строки
- str.normalize — нормализовывать
- приводить к одному case-у (например lower)
Ещё можно дробить поисковый запрос на слова и искать отдельно по каждому слову. Частенько это лучше покрывает желания пользователя, чем просто поиск в лоб.
tvictor
01.12.2021 08:25Спасибо за ответ. Тоже каждый раз это были маленькие объёмы. Лишь один раз на тестовом задании был набор из 5000 строк. Даже не строк, а объектов с несколькими строками внутри, по которым надо было искать. Как писал выше, там меня match выручил.
Про trim знаю, да. Пойду почитаю про другие способы )
Alexandroppolus
30.11.2021 22:07+3Как вариант, сохранять и переиспользовать предыдущие выборки. Наиболее типовой сценарий здесь - когда в текстовом поле набивается слово, и с каждой новой буквой делается поиск. И, допустим, имея на руках выборку для "abc", которая существенно меньше исходного полного набора слов, из неё очень быстро сделаем выборку для "abcd", ничего не потеряв. В общем, для некоторой введённой строки S ищем среди предыдущих запросов запрос для наиболее длинной подстроки S, и выбираем из него.
Ну а если бы поиск делался не по вхождению, а по началу строки, то там можно с помощью префиксного дерева без проблем окучивать сотни тыщ строк
Bronx
03.12.2021 08:26+1Заодно можно не торопиться делать поисковый запрос с первой же введённой буквы, а подождать, скажем, двух-трёх, чтобы первая же выборка оказалась достаточно маленькой. Плюс, имеет смысл ограничить поиск лишь первыми N вхождениями, юзер всё равно не будет просматривать все 10000.
Chamie
06.12.2021 20:04+2…а потом наткнуться на то, что группу «The Who» в поиске не найти, потому что он выкидывает артикли, личные местоимения и слова меньше 4 символов.

wataru
30.11.2021 22:17+1Если строки должны начинаться со ввода, то отличный вариант — построить бор из фильтруемых строк, при вводе пользователя спускаться по этому бору и потом при поиске обходить бор с этой вершины и выводить все строки в этом поддереве.
Если запрос пользователя должен входить как подстрока, то можно разбить все строки на 3-граммы (3 подряд идущих символа), для каждого набора построить список из всех строк, которые его содержат (отсортированные по id). Потом при запросе эти списки мерджить и искать только в этих строках.
Еще, я не знаю, что там у String.includes под капотом, но может ручная реализация какого-нибудь KMP будет быстрее.
Самый быстрый и сложный в реализации метод будет таким: построить суффиксные деревья для всех строк, потом объединить их в одно дерево. Потом в каждой вершине сохранить Set всех строк, кончающихся в поддереве. Чтобы быстро строить и не занимать очень много памяти, надо каждый Set хранить в виде персистентного бинарного сбалансированного дерева. Тогда построить это счастье можно за O(L log n) и памяти оно столько же занимать будет. Тут L — суммарная длина всех строк, n — их количество. Зато время поиска будет O(1) на каждый введенный символ и вывод всех строк будет за O(k), где k — длина ответа. Быстрее вообще никак. Но этот метод будет проигрывать совсем наивным на маленьких размерах из-за оверхеда и по настоящему засияет только при больших наборах данных. Но бонусом тут можно дерево предпостроить на сервере и выдать сразу его на клиент.
Но никакие эти структуры, естественно, не встроены никуда, а на js наверно даже не реализованы нигде ни разу.
nin-jin
30.11.2021 22:42Из простых решений можно чуть доработать ваше: соединяем все строки через перевод строки, после чего через match натравливаем на неё регулярку. Например:
'foo bar\nbar\nfoo'.match( /^.*bar.*$/migu ) // ['foo bar', 'bar']
mayorovp
30.11.2021 22:53+1Предположу, что вы делали не просто match по строке, а по заранее подготовленному регулярному выражению. В таком случае ничего удивительного нет — ведь includes тоже делает подготовку, пусть и более простую — зато каждый раз.
Из более оптимальных способов тут можно разве что заранее сокращенное суффиксное дерево построить для всего массива строк, это заставит поиск "летать", но вы замаетесь его строить.
-

alexskakun
24.11.2021 19:07Синтаксис
{ ...acc, newProp: value }настолько привлекателен, что порой действительно забываешь, что он может сильно повлиять на производительность.Уже точно не помню где, давно было, читал, что добавление/удаление свойств существующему объекту достаточно тяжёлые операции. Для себя сделал "правило" стараться не расширять объекты вот так:
obj[property] = value, где это может повлиять на производительность. В контексте статьи, решение для себя нашёл такое:const newObject = Object.fromEntries(source.reduce((acc, item, i) => { acc.push([i, item]); return acc; }, []));Если количество элементов
sourceравно количеству свойств уnewObject, то можно вообще избавиться от `push()`, а записывать вaccпо индексу:const newObject = Object.fromEntries(source.reduce((acc, item, i) => { acc[i] = [i, item]; return acc; }, new Array(source.length)));Но разница уже совсем не принципиальная. В хроме при n = 10 000 всего несколько миллисекунд.
faiwer Автор
24.11.2021 19:13Если количество элементов source равно количеству свойств у newObject
Просто замените
.reduceна.map.Для себя сделал "правило" стараться не расширять объекты вот так:
obj[property] = valueЧестно говоря я рекомендую вам провести замеры. Есть немалая вероятность что экономии нет, или она крошечная. Вы исходите из того, что
Object.fromEntriesочень мощно оптимизирован. Может быть оно так и есть. А может быть и нет. А ещё может быть что потери на игры с ненужным массивом перебивают любую выгоду от финта ушами сObject.fromEntries. В общем я рекомендую вначале прогнать простые тесты на нужных вам платформах. А то может быть вы зря мучаетесь :)Ну и стоит отметить, что асимптотической разницы там быть не должно. И если речь не про высоконагруженный участок кода какой-нибудь числодробилки то едва ли игра стоит свеч.
alexskakun
25.11.2021 14:09Просто замените
.reduceна.map.Действительно, что-то я увлёкся редьюсом)
Честно говоря я рекомендую вам провести замеры.
Я проверил.
Object.fromEntries()работает намного быстрее, чем{ ...acc, props val }, но обычное добавление свойства всё же быстрее. Если оценивать сложность то она одинаковая: O(n) (простое добавление) против O(2n) (Object.fromEntries), а вот в абсолютном времени простое добавление свойства побыстрее.faiwer Автор
25.11.2021 14:24На всякий случай уточню
O(n)это ровно тоже самое чтоO(100500 * N). Т.е.O(n) === O(2n). То о чём вы говорите (2) это константа. Время, которое тратится на отдельно взятую операцию. У разных алгоритмов она, разумеется, разная. Поэтому когда мы говорим обbigOмы в первую очередь говорим о больших объёмах данных, т.к. чем больше данные, тем меньше влияния константы при разныхbigO. Даже если у одного алгоритма константа в 20 раз выше, чем у другого, если тот другой имеетbigO(n!), а первыйO(n), то роль этих "в 20 раз" уже не важна на объёмах. 20х алгоритм будет настолько ультимативно быстрее, что ...В отдельно взятых ситуациях берут в рассчёт уже и константы. И прочие обстоятельства. К примеру есть много вариаций binary search tree. У большинства из них (или всех, не знаю) одни и те же
bigO. Но разница в константе (и прочих нюансах непокрытыхbigO) заставляет применять разные деревья. Понятное дело это касается нагруженных участков кода.alexskakun
25.11.2021 15:06Да, я именно это я и написал. Возможно, не совсем точно выразил мысль. С точки зрения оценки сложности алгоритма O(n) = O(2n).
Vilaine
27.11.2021 04:44-1Иммутабельность обычно требует некоторых жертв (копирования), но это не касается самих коллекций. Если это не Haskell с его изощренными оптимизациями связанных списков или finger trees, то для всех коллекций следует избегать immutability. Если речь о гарантированно малых величинах, то скорее всего это малые величины являются частью домена и поэтому должны быть инкапсулированы в какое-нибудь (иммутабельное или нет) перечисление. Например, список допустимых статусов. Если они не являются частью ограниченного домена, то они и гарантированно малыми не являются.
Это, правда, по опыту backend. Смею предположить, что оператор "..." может быть попросту неудачен и не должен быть добавлен в язык именно потому, что он в 99% случаев ведёт к O(N) вместо O(1), что неизбежно приведёт к O(N^x) системах с бОльшей цикломатической сложностью, которую вовсе не всегда можно удержать в голове. Или, как минимум, к лишнему множителю o(xN). По-моему, ЯП не должен проектироваться с таким подходом, когда сахар замедляет программу в типичном случае без убер-оптимизатора, пусть якобы немного в этом типичном случае.mayorovp
27.11.2021 11:16На самом деле, оператор "..." вполне удачен, потому что у него есть куча применений когда без него совсем плохо.
Например, вызов функции с передачей произвольного числа аргументов:
fn(foo, bar, ...baz)без этого оператора выглядел бы так:fn.apply(null, [foo, bar].concat(baz)). И да, у нормальных функций никогда не бывает слишком много аргументов.Vilaine
28.11.2021 04:15-1Например, вызов функции с передачей произвольного числа аргументов: fn(foo, bar, ...baz)
Пример так себе, потому что в этом случае можно обойтисьfn(foo, bar, baz), объявив функцию соответствующим образом. Заодно ничего никуда копироваться не будет. Я думаю, функции с произвольным числом аргументов — это не пример отличного дизайна. Оператор для неудачного дизайна — не лучшая идея.
Про кучу применений я как раз не в курсе. Чисто логически я вижу, что этот оператор поощряет неудачный дизайн кода, когда можно или нужно использовать другие пути — при разработке и развитии ЯП хотелось бы таких решений избегать.mayorovp
28.11.2021 10:01Если это декоратор — то надо работать с тем что есть. И с чего вы вообще взяли, что у функции переменное число аргументов?
Vilaine
28.11.2021 18:23-1Если это декоратор — то надо работать с тем что есть.
Не совсем понимаю, но специальный оператор для работы «с тем что есть» — такое себе.И с чего вы вообще взяли, что у функции переменное число аргументов?
А зачем ещё код вродеfn(foo, bar, ...baz)? Если функция имеет фиксированные аргументы, и в массиве эти аргументы, то это даже ещё хуже. Аргументы к функциям должны быть явными, а не разворачиваться из массива, потому что в массиве может быть что угодно.transcengopher
30.11.2021 22:53А зачем ещё код вроде fn(foo, bar, ...baz)?
Например, для каррирования и прочих функций высокого порядка.
rewlad-dev
28.11.2021 03:35Я прекрасно понимаю алгоритмичесую сложность, но мутировать в что-то лишний раз, тем более в reduce, не буду:
Это плохой пример другим. Товарищи решат, что так можно везде, и начнут, например, удалять элементы из массива по которому проходят. А потом товарищи перейдут на бакенд, который многопоточный. И про "memory model" не прочитают. Оптимизировать безопасный код проще, чем вылавливать плохо повтояемые баги.
Итак, у меня 1000 элементов, для которых описанная оптимизация имеет значение. А они точно нужны на клиенте? Может, в качестве первой оптимизации, их не присылать, а взять только те 20, которые пользователь видит.
Ну хорошо, в этот раз у меня канвас на UHD и элементов правда нужно много. А использовать библиотеку с дополнительными структурами данных не разрешили. Я ведь могу написать свой минимальный "util.js", в котором внутри всё будет в стиле "for(;;)" и "let", а снаружи чисто.
Есть линтеры, которые заставляют помечать небозопасные конструкции. Возможно есть/будет и для js такой инструмент. И я стараюсь писать код так, чтобы легко интегрировать его в будущем.
faiwer Автор
28.11.2021 13:21Смешались в кучу люди кони… И не-JS backend с многопоточностю, и мутация итерируемых коллекций, и канвас. Ух. Но я и не настаиваю на
.reduce. Если согласно вашим правилам, принятым в команде, мутации в.reduceэто большой грех, то:- используйте вместо него
.flatMap, там где это возможно - не используйте
.reduce, там где получаетсяO(n^2)на пустом месте. Есть множество способов сделать тоже самое, без него
Главное не ставьте аргументы из п1. выше чем bigO. Над нами уже весь IT мир потешается.
- используйте вместо него
Druj
«Достаточно умный компилятор это оптимизирует»© — неизвестный FP адепт.
faiwer Автор
В целом, статически типизированным чистым FP языкам доступны очень хитрые оптимизации.
Но ничего. Вот завезут к нам immutable data structures (где-то лежал черновик спецификации), заживём
vkni
Как правило, на статически типизированных чистых FP языках, не пишут "не приходя в сознание". В смысле, там, конечно, есть "неявная" мемоизация, и т.д., но
1. Можно посмотреть промежуточный код, включая ассемблер.
2. Обычно люди, всё-таки, представляют последствия того, что оптимизация не сработала.
Ну и явная мемоизация в Clean, кмк, лучше, чем неявная в Haskell.
0xd34df00d
То, что есть в хаскеле — это не неявная мемоизация, а ленивая стратегия вычислений. Функцию
fac n = if n > 0 then n * fac (n - 1) else 1никто мемоизировать не будет.А вот хороша или нет лень по умолчанию — отдельный вопрос.
csl
Как только убежусь, что она плоха - отключу лень (конечно, если только в стратегии был боттлнек).
0xd34df00d
Ну, если честно, я в требовательном к производительности коде давно отключаю лень по умолчанию (и начинаю файл с
{-# LANGUAGE Strict #-}).vkni
Ну вы же знаете про динамическое программирование на Хаскеле.
0xd34df00d
Я и узел там завязывать умею, но не могу назвать это неявной мемоизацией.
vkni
Я конкретно про вот это - https://jelv.is/blog/Lazy-Dynamic-Programming/
В Клине же есть явное описание того, что мемоизуется, а что - перевычисляется:
https://clean.cs.ru.nl/download/html_report/CleanRep.2.2_12.htm#_5.2_Defining_Graphs
PsyHaSTe
Как говорил один мой знакомый
Так что мб ленивость по дефолту это и не так уж плохо
transcengopher
Если это про понятность, то мне, честно говоря, первая версия более понятна, чем вторая — а я даже не на функциональных языках пишу, а на Java 8+ (ну ещё на ECMA 6, но это мелочи).
mayorovp
Вот именно, первая версия гораздо понятнее. Но она требует ленивых вычислений во избежание переполнения стека.
Alexandroppolus
а оптимизации хвостовой рекурсии там разве не предусмотрено?
mayorovp
Так она хвостовая только во втором примере.