
В этой статье хочу поделиться нашим опытом работы с обновлениями RabbitMQ Live. Здесь вы узнаете некоторые подробности о нашей архитектуре и вариантах ее использования. Давайте начнем с самого простого... Зачем нам нужен RabbitMQ в бизнесе?

Наша архитектура
Мы являемся компанией медицинского страхования, и наш бизнес зависит от множества различных сторонних сервисов для анализа рисков, обработки претензионных документов, начисления ежемесячных платежей и т.д. Все эти процессы требуют определенного времени на обработку, поэтому, чтобы наши сервисы работали быстро и автономно друг от друга, мы используем асинхронную обработку задач, которые могут выполняться в фоновом режиме. Такой подход ускоряет ответы и позволяет осуществлять дополнительные сопутствующие функции, т.е. отправку электронной почты, создание полисов, подтверждение верификации т.д.

Каждый раз, когда клиент обращается к API с каким-либо намерением, делая запрос, это намерение может создавать последующие задачи. Эти задачи не нужно обрабатывать синхронно, а именно, не требуется обрабатывать их сразу же во время обработки первоначального запроса. Вместо этого мы помещаем сообщение об этом намерении в очередь, где оно может быть асинхронно получено другим процессом и обработано независимо от первоначального запроса.
Проблема
Но с большими возможностями приходит и большая ответственность. Обработка сообщений очень важна и критична для нашего бизнеса. Срок действия некоторых сообщений может истечь без использования или в случае несоответствия аргументов ограничениям очереди. Теоретически, этого не должно происходить или может произойти в очень редких случаях. Но поскольку нам приходится работать с данными клиентов, то терять важные сообщения нельзя. Чтобы сохранить неиспользованные сообщения в брокере и не возвращать их в исходную очередь, воспользуемся функцией dead-letter.
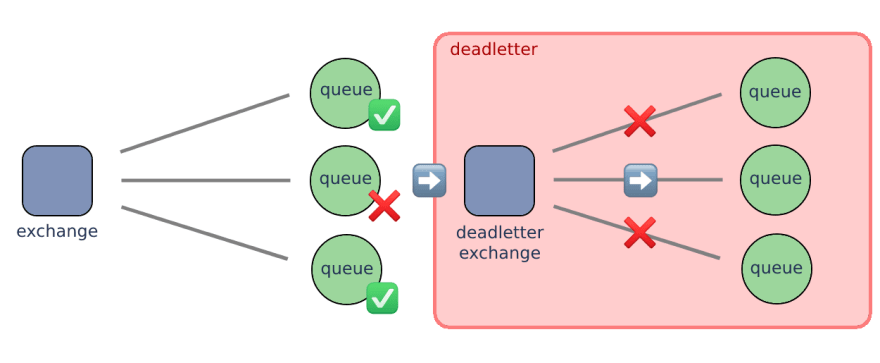
Сообщения публикуются в обменнике (exchange) и могут быть отправлены в несколько очередей в зависимости от ключа маршрутизации. Как видно из изображения выше, мы использовали ту же схему dead-letter, что и для оригинальных очередей, поэтому "мертвые" (dead) сообщения могут оказаться в неверных dead-letter очередях . Это не очень критично, если вы собираете "мертвые" сообщения вручную (учитывая, что они редки), но, тем не менее, все равно странно обнаружить их в неподходящем месте.
Чтобы решить эту проблему, необходимо добавить новый аргумент в свойства очередей, это x-dead-letter-routing-key, и он должен быть уникальным. В качестве уникального значения для ключа маршрутизации можно использовать само имя очереди. Эта идея на шаг приблизила нашу команду к удачному решению: нам больше не нужен dead-letter обменник. Для упрощения можно использовать безымянный обменник по умолчанию "" с dead-letter очередью в качестве ключа маршрутизации, и он будет перенаправлять сообщение непосредственно в нужную очередь.

К сожалению, сделать все не так просто, как об этом пишут или говорят. Чтобы сохранить согласованность и стабильность работы брокера сообщений, RabbitMQ не позволяет изменять аргументы уже существующих очередей.
Подготовка к развертыванию
Итак, RabbitMQ не позволяет изменять аргументы очередей во время рантайма, поэтому единственный возможный способ сделать это — удалить очереди и создать их заново с обновленными аргументами. Но этого нельзя делать в продакшне, так как мы можем потерять некоторые сообщения, когда они уже будут удалены, а новых еще не существует. Чтобы решить данную проблему, нам нужно ввести временные очереди для обработки таких сообщений, в то время как старые очереди удаляются. Для простой системы это осуществимо с помощью 4 релизов:
Создайте временные очереди, но пока не обрабатывайте сообщения из них.
Переключитесь на новые очереди и удалите старые. На этом шаге у нас уже есть правильно настроенные очереди, но имена у них другие. Чтобы вернуться к старым именам, нам нужно снова проделать те же шаги.
Создайте новые очереди со старыми именами, но с обновленными аргументами. Пока не пользуйтесь сообщениями из них.
Переключитесь на новые очереди с обновленными аргументами.

4 релиза, совсем не мало, верно? Это требует не только много мелкой работы, но и внимания, чтобы каждый раз убедиться, что все прошло правильно. Как мы можем их уменьшить?
Самое простое, что мы можем сделать, это договориться о переименовании очередей. Это сократит количество релизов в 2 раза, так как нам не нужно будет переименовывать их обратно. Это вполне приемлемо для нас, и даже больше, поскольку мы улучшили процесс обработки сообщений. Но это уже совсем другая история.
Что еще можно сделать? Включение потребителей и обработки сообщений в новых очередях сразу же сократит количество релизов до одного, но мы должны признать риск дублирования сообщений, когда новые очереди уже созданы, а старые еще обрабатываются.
Но я не учел один момент. У нас есть сине-зеленый процесс развертывания (blue-green deployment process), это когда существует несколько инстансов одной и той же вещи. Во время деплоя, вы берете один из них, обновляете, затем устанавливаете его, затем - другой, чтобы обновить. Это гарантирует, что процесс не прерывается, всегда что-то есть. В нашем случае это означает, что там всегда есть пользователь.

Таким образом, сообщения определенно могут быть продублированы, если они будут задеплоены в рабочее время. Деплой занимает несколько минут, а это значит, что и старая, и новая очереди будут активны в течение нескольких минут.
Самое время проанализировать и решить, безопасно ли развертывать приложение ночью (и действительно ли мы хотим это делать), когда поток сообщений невелик, или стоит имплементировать сторонний сервис, например Redis, чтобы проверить, было ли сообщение старой или новой версии уже обработано каким-то пользователем, .
Релиз
Самый простой способ проверить нагрузку на наш брокер сообщений — это посмотреть количество журналов по дням недели и времени. Поскольку мы являемся узконаправленной компанией, работающей только в Германии, у нас очень низкая нагрузка на сообщения с позднего вечера до раннего утра.

Это не такая большая нагрузка, какая возможна, поэтому вероятен риск того, что некоторые сообщения могут быть продублированы, но даже если это произойдет, их количество будет крайне мало, и мы сможем разобраться с ними вручную. Таким образом экономятся ресурсы и время, которые потребовались бы для двух релизов.
После попытки выпустить релиз после полуночи мы обнаружили, что не можем сделать это ночью. Некоторые из наших сторонних сервисов недоступны, поэтому контейнер просто не может быть загружен. Один раз попробовать стоило, теперь это известно наверняка. Ночь — чтобы спать.
Но все же можно сделать это поздно вечером или рано утром. Нужно только обратить внимание на загрузку RabbitMQ.
Поздно вечером:

Рано утром:

Было решено нажать кнопку релиза рано утром. На этот раз все прошло хорошо, и дубликатов не было.
Это был непростой способ решения проблемы, но оно того стоило. Благодаря этому мы узнали много интересного о процессах обработки и развертывания сообщений. Теперь все работает еще лучше, чем раньше, с правильными настройками очередей и разделенной обработкой сообщений.
Резюме
RabbitMQ не позволяет переименовывать очереди или изменять аргументы очереди;
чтобы изменить что-то в очереди, вы должны удалить ее и создать заново;
для безопасного повторного создания нужно использовать временные очереди;
стабильная система может работать под несколькими инстансами, поэтому помните о дублировании сообщений между старыми и новыми очередями;
если ваш бизнес привязан к одному часовому поясу и не имеет высокой нагрузки в ночное время, то допускается наличие дублированных сообщений вместо избыточного инжиниринга потребителей.
Материал подготовлен в рамках курса «Highload Architect».
Всех желающих приглашаем на бесплатное demo-занятие «Паттерны декомпозиции системы на микросервисы». На занятии мы познакомимся с паттернами декомпозиции системы на микросервисы. Рассмотрим технические и бизнесовые подходы к декомпозиции.
>> РЕГИСТРАЦИЯ