В предыдущей статье я рассказывал, как мы в #CloudMTS строим облачные сервисы для разработчиков ИИ. В частности, я коснулся эволюции нашего GPU SuperCloud в MLOps Platform. И если последний сервис сейчас находится в режиме бета-тестирования, то GPU SuperCloud активно используют наши клиенты.
Сегодня я хочу поделиться с вами опытом компании VisionLabs, которая применяет наш IaaS на GPU для решения задач компьютерного зрения. Под катом — интересные подробности о работе сервиса на реальном кейсе Computer Vision-компании.

VisionLabs создают продукты на базе компьютерного зрения и машинного обучения для финансовых и транспортных компаний, ретейлеров и международных технологических корпораций. Ее ключевой продукт — платформа компьютерного зрения и видеоаналитики LUNA, а также линейка устройств на базе собственных технологий (Luna Ace, Luna Pos, Luna Thermo и др.). С помощью Luna Platform клиенты VisionLabs решают задачи детектирования лиц, их сравнения и определения дополнительных атрибутов, таких как пол, возраст, эмоции и ключевые точки на изображениях с людьми.
Делается все это с помощью обученных нейросетей. Несмотря на расхожее мнение, современные алгоритмы распознавания лиц на базе очень глубоких нейронных сетей справляются с этой задачей гораздо лучше человека.
Для эксперимента VisionLabs нужно было быстро получить требуемый объем вычислительных мощностей, поэтому компания изначально рассматривала облачные сервисы c GPU. Было и еще одно требование: возможность запуска собственных Docker-контейнеров. Часть провайдеров отказывали клиенту из-за невозможности поддержать нестандартную архитектуру или запрашивали длительный процесс подготовки к такому запуску.
Наш GPU SuperCloud команда тестировала на ряду с другими сервисами. В его пользу сыграли следующие факторы:
Кстати, стоит подробнее остановится на последнем пункте. Сейчас на рынке есть сервисы, которые предлагают более гибкие модели оплаты. Но VisionLabs изначально планировали запустить один, но продолжительный по времени (около 2-3 месяцев) процесс. При таком сценарии использования GPU SuperCloud с помесячной тарификацией оказался выгоднее решений с pay-as-you-go.
Для запуска эксперимента была выбрана конфигурация вычислительного сервера с 4-мя картами Tesla V100.
Наш GPU SuperCloud — тот же IaaS, толькона максималках на графических ускорителях, поэтому работать с ним так же просто, как и с обычным облаком. В процессе обучения модели у команды VisionLabs сложностей с сервисом не возникло, а для решения каких-то специфичных вопросов всегда можно было обратиться к техподдержке. Но, к чести специалистов заказчика, даже помощь техподдержки ему не потребовалась. Единственный вопрос по адресам размещения SSD решился за считанные минуты двумя сообщениями.
Для обучения клиент использовал стандартный для отрасли фреймворк PyTorch — он уже был установлен в контейнере заказчика вместе со всеми зависимостями, нужными библиотеками и дополнениями.
Каждая эпоха обучения длилась около 4-х суток: модель меньшего масштаба обучалась на ресурсах заказчика, однако была существенно ограничена внутренними мощностями. Исходя из многомесячного планирования и изучения работы алгоритмов инженеры VisionLabs смогли спрогнозировать достаточный объем вычислительных мощностей и приступили к поиску провайдера. На #CloudMTS выбор остановился в том числе благодаря наличию двухнедельного пробного периода, гибкости и сбалансированному соотношению цена/качество. Здесь вы можете нас упрекнуть: «как говорится, сам себя не похвалишь…», однако вы всегда можете сравнить актуальные цены на рынке. :)
Во время пробного периода заказчик загрузил к нам свой демо-контейнер со стандартным для компании набором инструментов обучения и произвел несколько тестовых запусков. По итогам изучения логов выяснилось, что проблем нет и можно перенести к нам «боевую» систему.
С вычислительными ресурсами GPU SuperCloud можно работать напрямую через терминал с подключением по SSH. Это позволяет быстро разворачивать собственные Docker-контейнеры, удобно обмениваться данными с сервером и запускать инструменты мониторинга активных процессов.
Компания VisionLabs предоставила скриншот конфигурационного файла для создания Docker-контейнера, образ которого загружался в сервис GPU SuperCloud.

Предоставлено VisionLabs
Гипотеза подтвердилась: архитектуры-трансформеры оказались действительно перспективны в задачах распознавания лиц.
Обратите внимание на графики ошибки предсказания целевой задачи обучения для базовой модели и масштабированной модели, полученной с помощью GPU SuperCloud. Из этого графика видно, что масштабированная архитектура имела заметно меньшую ошибку по целевой задаче.


Рисунок 2. Графики ошибки по целевой задаче обучения базовой модели трансформера и масштабированного варианта, полученного с помощью сервиса GPU SuperCloud. Предоставлено VisionLabs.
В качестве примера результатов на независимом тесте в таблице ниже приведены результаты на ковариционном тесте верификации лиц базы IJB-C [1] для базовой архитектуры (Base transformer) и масштабированной (Scaled transformer), полученной в результате обучения на сервисе GPU SuperCloud.
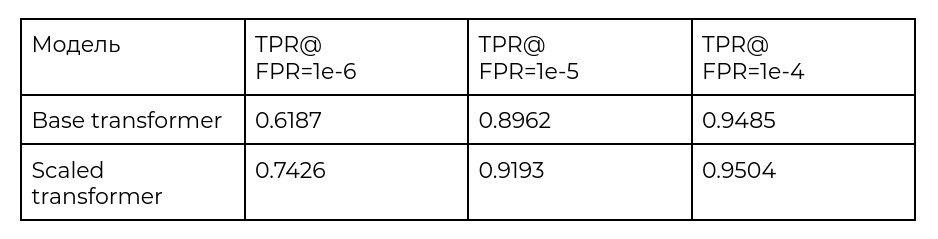
Таблица 1. Сравнение результатов точности верификации ковариационного теста IJB-C для базовой модели (Base transformer) и масштабированной модели (Scaled transformer), обученной с использованием сервиса GPU SuperCloud. Предоставлено VisionLabs
[1]. Nada, Hajime, et al. «Pushing the limits of unconstrained face detection: a challenge dataset and baseline results.» 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, 2018.
Для задач в сфере машинного обучения и ИИ у нас есть и другие инструменты — MLOps Platform и суперкомпьютер GROM, в создании которых GPU SuperCloud сыграл далеко не последнюю роль (мы уже рассказывали их историю ранее в блоге).
Предназначение GROM'а — решение ресурсоёмких задач в сфере ML и AI. Специальный программный стек High Performance Computing (HPC) помогает использовать весь потенциал вычислительного кластера. Для максимальной скорости обмена данными все узлы суперкомпьютера связаны высокоскоростной сетью Infiniband. «Сердце» GROM'а — карты NVIDIA DGX A100, общий объём видеопамяти на каждом узле — 320 Гб. Пиковая производительность достигает 2,26 петафлопс.
Вычислительный кластер GROM оснащен системой хранения данных NetApp на базе технологии NVMe. Она обеспечивает сверхскоростной доступ узлов к различным данным и за счёт этого максимально ускоряет процесс машинного обучения. Можно запускать задачи как на отдельных узлах, так и на всех 20.
Сегодня суперкомпьютер GROM используется для решения внутренних задач: на нем разрабатываются проекты в сфере распознавания/синтеза речи и изображений, строятся различные предиктивные модели и многое другое. В будущем мы планируем открыть доступ к мощностям GROM'а внешним заказчикам.

Сегодня я хочу поделиться с вами опытом компании VisionLabs, которая применяет наш IaaS на GPU для решения задач компьютерного зрения. Под катом — интересные подробности о работе сервиса на реальном кейсе Computer Vision-компании.
Чем занимаются в VisionLabs
VisionLabs создают продукты на базе компьютерного зрения и машинного обучения для финансовых и транспортных компаний, ретейлеров и международных технологических корпораций. Ее ключевой продукт — платформа компьютерного зрения и видеоаналитики LUNA, а также линейка устройств на базе собственных технологий (Luna Ace, Luna Pos, Luna Thermo и др.). С помощью Luna Platform клиенты VisionLabs решают задачи детектирования лиц, их сравнения и определения дополнительных атрибутов, таких как пол, возраст, эмоции и ключевые точки на изображениях с людьми.
Делается все это с помощью обученных нейросетей. Несмотря на расхожее мнение, современные алгоритмы распознавания лиц на базе очень глубоких нейронных сетей справляются с этой задачей гораздо лучше человека.
Зачем потребовался облачный сервис на GPU
В последнее время в компьютерном зрении набирают популярность так называемые архитектуры-трансформеры, пришедшие еще из области задач обработки естественного языка. Они стали демонстрировать очень хорошие результаты и в компьютерном зрении. До настоящего времени для решения задач компьютерного зрения были наиболее популярны нейронные сети с использованием операций свертки для вычисления активаций внутри сети. Эти операции обладали свойством локальности — признаки вычислялись на основании некоторой локальной окрестности. Это затрудняло учет взаимодействия признаков между удаленными областями изображений, который мог бы помочь повысить точность. Архитектура трансформеров позволяет выполнять учет этих взаимодействий за счет использования механизма self-attention, правда, требуя значительных вычислительных затрат. На рисунке 1 схематически представлено сравнение работы операции свертки и механизма self-attention на примере обработки одноканального изображения. При выполнении операции свертки в каждой точке входного изображения берутся соседние значения в виде локального окна и умножаются на значения фильтра свертки, которые являются обучаемыми параметрами. Сумма полученных значений сохраняется в соответствующую координату результата свертки — как и входное изображение, это двумерный массив данных. Принцип использования окрестностей вокруг пикселей и скользящего фильтра свертки, параметры которого не зависят от расположения окрестности, обеспечивают локальность вычисления признаков и эквивариантность к сдвигу объектов на изображении.
В механизме работы трансформеров используется другой принцип — каждый пиксель входного изображения мы агрегируем со всеми остальными пикселями изображения. Все веса агрегации оставшихся пикселей для каждого обрабатываемого пикселя входного изображения уникальны и вычисляются на ходу с учетом значений пикселей и их координат в пространстве. Это позволяет внести учет взаимодействий между дальними пикселями, не увеличивая в такой значительной степени количество параметров нейронной сети, как это бы потребовалось для фильтров свертки очень больших размеров, чтобы они учитывали взаимодействия отдаленных пикселей.
Рисунок 1. Принцип работы операции свертки и механизма self-attention. Предоставлено VisionLabs.
Как показывает опыт других исследователей, в ряде задач они работают не хуже сверточных сетей (более того, VisionLabs удалось достичь превосходства над ними в задачах распознавания лиц), но лучше смогут реализовать потенциал большого количества данных, накопленных клиентом за годы работы.
В случае с такими архитектурами в наибольшей степени важен следующий принцип: чем больше обучающих данных поступит в систему, тем эффективнее каждая единица информации сможет реализовать свой потенциал. Архитектуры с наибольшим числом параметров лучше реализуют потенциал роста количества данных для обучения. Соответственно, для обучения требуется значительное количество памяти (в ней в процессе обучения сохраняются параметры модели) и мощные видеопроцессоры. Чем больше данных поступает на вход, тем более мощное оборудование требуется для расчетов.
— Сергей Миляев, главный исследователь VisionLabs

Мы решили провести эксперимент с архитектурами-трансформерами, но наши собственные ресурсы для полноценного тестирования гипотезы о масштабировании архитектур трансформеров не подходили. Например, некоторые модели просто не влезали по памяти. Поэтому было принято решение искать внешнего провайдера с облаком на базе GPU Nvidia.
— Сергей Миляев, главный исследователь VisionLabs
Для эксперимента VisionLabs нужно было быстро получить требуемый объем вычислительных мощностей, поэтому компания изначально рассматривала облачные сервисы c GPU. Было и еще одно требование: возможность запуска собственных Docker-контейнеров. Часть провайдеров отказывали клиенту из-за невозможности поддержать нестандартную архитектуру или запрашивали длительный процесс подготовки к такому запуску.
Наш GPU SuperCloud команда тестировала на ряду с другими сервисами. В его пользу сыграли следующие факторы:
- с его помощью можно быстро развернуть вычисления для задач различного масштаба;
- позволяет оперативно загрузить контейнеры;
- условия тарификации подходят для долгих процессов обучения;
- можно гибко формировать сроки аренды.
Кстати, стоит подробнее остановится на последнем пункте. Сейчас на рынке есть сервисы, которые предлагают более гибкие модели оплаты. Но VisionLabs изначально планировали запустить один, но продолжительный по времени (около 2-3 месяцев) процесс. При таком сценарии использования GPU SuperCloud с помесячной тарификацией оказался выгоднее решений с pay-as-you-go.
Для запуска эксперимента была выбрана конфигурация вычислительного сервера с 4-мя картами Tesla V100.
Как проходил эксперимент
Наш GPU SuperCloud — тот же IaaS, только
Перед нами стояла задача «скормить» компьютеру колоссальное количество изображений людей (десятки миллионов картинок!), обработать их и на выходе получить модель, способную распознавать на разных кадрах одних и тех же людей вне зависимости от их выражения лица, позы и положения головы.
— Сергей Миляев, главный исследователь VisionLabs
Для обучения клиент использовал стандартный для отрасли фреймворк PyTorch — он уже был установлен в контейнере заказчика вместе со всеми зависимостями, нужными библиотеками и дополнениями.
Каждая эпоха обучения длилась около 4-х суток: модель меньшего масштаба обучалась на ресурсах заказчика, однако была существенно ограничена внутренними мощностями. Исходя из многомесячного планирования и изучения работы алгоритмов инженеры VisionLabs смогли спрогнозировать достаточный объем вычислительных мощностей и приступили к поиску провайдера. На #CloudMTS выбор остановился в том числе благодаря наличию двухнедельного пробного периода, гибкости и сбалансированному соотношению цена/качество. Здесь вы можете нас упрекнуть: «как говорится, сам себя не похвалишь…», однако вы всегда можете сравнить актуальные цены на рынке. :)
Во время пробного периода заказчик загрузил к нам свой демо-контейнер со стандартным для компании набором инструментов обучения и произвел несколько тестовых запусков. По итогам изучения логов выяснилось, что проблем нет и можно перенести к нам «боевую» систему.
С вычислительными ресурсами GPU SuperCloud можно работать напрямую через терминал с подключением по SSH. Это позволяет быстро разворачивать собственные Docker-контейнеры, удобно обмениваться данными с сервером и запускать инструменты мониторинга активных процессов.
Компания VisionLabs предоставила скриншот конфигурационного файла для создания Docker-контейнера, образ которого загружался в сервис GPU SuperCloud.
- строка 1 — базовый образ,
- строка 11 — путь к спискам дополнительных библиотек для установки с использованием менеджера pip,
- строка 13 — запуск обучения с необходимыми параметрами внутри скрипта.
Предоставлено VisionLabs
Что получилось
Гипотеза подтвердилась: архитектуры-трансформеры оказались действительно перспективны в задачах распознавания лиц.
Обратите внимание на графики ошибки предсказания целевой задачи обучения для базовой модели и масштабированной модели, полученной с помощью GPU SuperCloud. Из этого графика видно, что масштабированная архитектура имела заметно меньшую ошибку по целевой задаче.
Рисунок 2. Графики ошибки по целевой задаче обучения базовой модели трансформера и масштабированного варианта, полученного с помощью сервиса GPU SuperCloud. Предоставлено VisionLabs.
Полученная в ходе обучения на сервисе GPU SuperCloud модель позволила сократить ошибки распознавания лиц в самых сложных сценариях. В некоторых случаях ошибку удалось сократить на 15% по сравнению c базовой моделью трансформеров, обученной на серверах VisionLabs.
— Сергей Миляев, главный исследователь VisionLabs
В качестве примера результатов на независимом тесте в таблице ниже приведены результаты на ковариционном тесте верификации лиц базы IJB-C [1] для базовой архитектуры (Base transformer) и масштабированной (Scaled transformer), полученной в результате обучения на сервисе GPU SuperCloud.
Таблица 1. Сравнение результатов точности верификации ковариационного теста IJB-C для базовой модели (Base transformer) и масштабированной модели (Scaled transformer), обученной с использованием сервиса GPU SuperCloud. Предоставлено VisionLabs
[1]. Nada, Hajime, et al. «Pushing the limits of unconstrained face detection: a challenge dataset and baseline results.» 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, 2018.
GROM: продолжаем путь в ИИ
Для задач в сфере машинного обучения и ИИ у нас есть и другие инструменты — MLOps Platform и суперкомпьютер GROM, в создании которых GPU SuperCloud сыграл далеко не последнюю роль (мы уже рассказывали их историю ранее в блоге).
Предназначение GROM'а — решение ресурсоёмких задач в сфере ML и AI. Специальный программный стек High Performance Computing (HPC) помогает использовать весь потенциал вычислительного кластера. Для максимальной скорости обмена данными все узлы суперкомпьютера связаны высокоскоростной сетью Infiniband. «Сердце» GROM'а — карты NVIDIA DGX A100, общий объём видеопамяти на каждом узле — 320 Гб. Пиковая производительность достигает 2,26 петафлопс.
Вычислительный кластер GROM оснащен системой хранения данных NetApp на базе технологии NVMe. Она обеспечивает сверхскоростной доступ узлов к различным данным и за счёт этого максимально ускоряет процесс машинного обучения. Можно запускать задачи как на отдельных узлах, так и на всех 20.
Сегодня суперкомпьютер GROM используется для решения внутренних задач: на нем разрабатываются проекты в сфере распознавания/синтеза речи и изображений, строятся различные предиктивные модели и многое другое. В будущем мы планируем открыть доступ к мощностям GROM'а внешним заказчикам.