
Helm — один из самых популярных пакетных менеджеров для Kubernetes, так что познакомиться с ним поближе стоит всем, кто сталкивается с задачами деплоя приложений. Эта статья завершает мое краткое, но достаточно полное введение в Helm.
Если вы вдруг пропустили первую часть, ее можно прочитать здесь. Во второй мы продолжим разбираться со списком типичных задач, возникающих в процессе деплоя: от инфраструктурных измненений до управления релизным циклом и расширения функциональности Helm.
На всякий случай напомню, что фрагменты кода здесь даны в виде картинок, чтобы выделить на них важные строки. Но для вашего удобства я собрал все примеры из текста в этом репозитории.
Итак, поехали дальше. Мы остановились на цифре 3.
3. Управление блоками кода по условию
Для инфраструктурных изменений в основном используется управление блоками кода по условию.
Пример 1: Допустим, для окружений разработки мы хотим использовать БД в Kubernetes, а для продуктивных окружений используем выделенные сервера:

Код из секции if вставится в релиз, если окружения не production и loadtest.
Пример 2: Более сложное условие:

Если выставлено значение app.storage.persistance, используем volumeClaimTemplate, если нет — делаем emptydir.
Пример 3: В условиях можно использовать функции Go templates:

Здесь review* окружения ограничиваются по ресурсам.
Впрочем, подобные конструкции можно оптимизировать при помощи функции toYaml. Мы можем описать в values.yaml несколько секций, соответствующих секции resources.

А потом вставить их в код при помощи toYaml:

Ниже приведен тот же пример с выбором значений по окружению.

4. Модульная разработка
Поскольку современное приложение — сложная многокомпонентная система, Helm-чарты могут очень сильно разрастаться. Вот пример такого исторически сложившегося чарта.

Здесь мы видим сразу много всего. Вот только некоторые из составляющих приложения: API, несколько воркеров, периодические задачи, инфраструктурные компоненты в виде базы данных и очередей, а также в виде описания ингресса, плюс периодические задачи резервного копирования. А теперь представьте, что у нас несколько окружений, в которых нужно развернуть совершенно разный набор компонентов:
В окружения тестирования нам нужен полный набор инфраструктурных компонентов, прогон миграций, нам необходимо прогнать задачу с тестами, но не нужны cronjob резервного копирования PostgreSQL и компонент с метриками.
В dev-окружении нам нужны инфраструктурные компоненты в кластерном варианте — там придется иногда запускать задачу сброса и восстановления БД с последней резервной копии — но не стоит задача резервного копирования.
В продуктивных окружениях не нужно развёртывание БД, ни в коем случае нельзя запускать задачу восстановления БД с резервной копии и тесты, но актуально задача резервного копирования.
Представляете, какую логику нужно встроить в шаблоны и как легко в ней запутаться? На этот счет был сформулирован разумный принцип:

Для реализации этого принципа мы можем использовать механизм модульной разработки (subcharts). Мы можем выделить типовые компоненты в отдельные чарты и подключать их в основной чарт как subcharts. Для их размещения в структуре чарта предусмотрена папка charts:

Чтобы подключить subchart, мы должны описать его в секции dependencies в файле Chart.yaml:
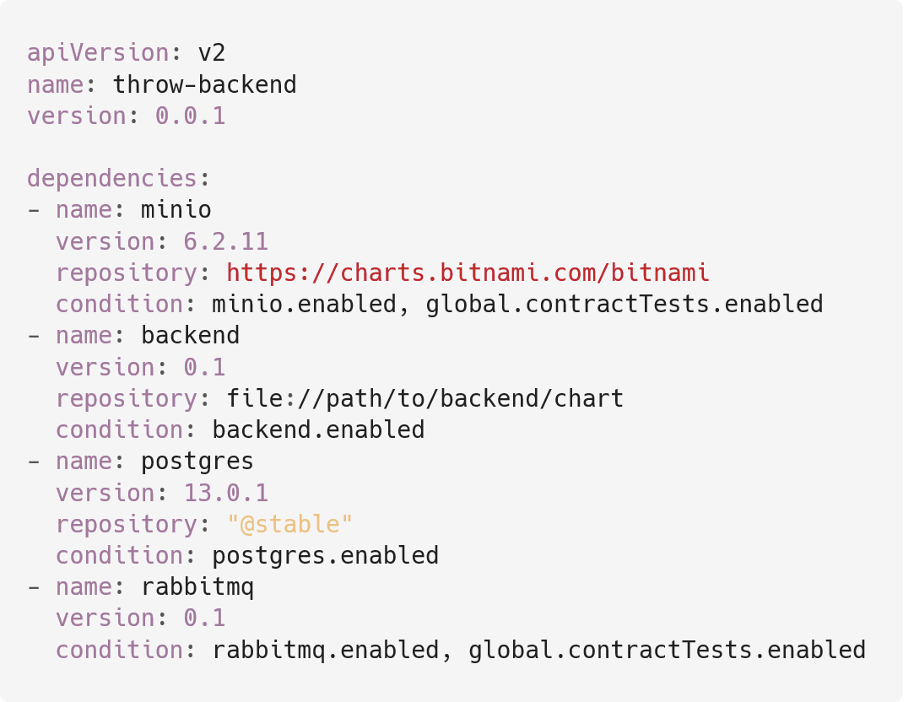
Стандартные функции Helm позволяют подключать subchart из:
Сетевых репозиториев чартов.
Чартов, находящихся на файловой системе.
Подключенных к системе сетевых репозиториев чартов.
Папок, расположенных в папке charts.
При этом, если используются subcharts из сетевых репозиториев чартов, перед деплоем чарта нужно вызвать команду
helm dependency update
Она скачает архивы с чартами из сетевых репозиториев в папку charts.
Следующий важный момент в использовании subcharts — условия их включения или, точнее, выключения (потому что подключенные subcharts активны по умолчанию).
Эти условия могут быть двух видов: conditions или tags.

В conditions можно описать несколько произвольных ключей из values через запятую.
В секции tags можно описать список из нескольких значений, объявленных в секции tags в values. Любой из них, будучи выставлен в false, приведет к тому, что связанный subchart не будет включен при рендере релиза:

Естественно, все values мы можем переопределять при вызове Helm при помощи ключей --set и --values:
helm upgrade --install -n ${CI_NAMESPACE} ${RELEASENAME} .infra/helm \
--set "backend.enabled=true" \
--set "minio.enabled=true" \
--set "postgres.enabled=true" \
--set "rabbitmq.enabled=true" \
--set "tags.migrations=false"Т. о. мы можем собирать релизы из сабчартов как из кубиков Lego, гибко переиспользуя код.
Следующий важный момент при использовании сабчартов — работа с values. И здесь есть несколько возможностей:

Прежде всего, вы можете определить в parent chart значения на ключе global (Строки 1—7). Эти значения будут доступны всем subcharts. Здесь нужно быть внимательнее с названиями ключей, поскольку ненароком можно что-то переопределить и получить непредсказуемое поведение.
Следующая возможность — переопределить переменные непосредственно сабчарта. Для этого нужно добавить в values parent chart префикс, равный имени сабчарта, и описать нужные ключи (строки 9, 13 и 17).
И последняя важная возможность при подключении subcharts — работа с named templates. Здесь есть две возможности:
Named templates из parent chart доступны во всех сабчартах. При этом нужно также быть внимательнее с названиями, поскольку есть возможность ненароком что-то переопределить.

2. Другая возможность — library charts, которые появились в версии Helm 3. Если в Chart.yaml в сабчарте выставлен тип library, то все named templates из него будут доступны parent chart и всем сабчартам.

При этом я бы хотел заострить внимание на следующем моменте. Давайте вернемся к примеру antiAffinity из секции с примерами named templates:

В рамках одного чарта этот define почти бесполезен. Т. е. он раскидает поды всех deployments, в которые будет подключен, по разным нодам без группировки по деплойменту. Обычно это не то, что нам нужно. Но если мы унесём его в library chart и будем подключать в сабчарты из него, то за счет использования стандартного значения .Chart.Name, он встроится в их код и будет работать как надо.
5. Работа с внешними репозиториями
Думаю, на работе с внешними репозиториями стоит остановиться подробнее. Рассмотрим ее на примере artifactshub.io:
При помощи поиска найдем репозитории для Prometheus. Внутри имеются инструкции по его подключению.

Выполним их:

Здесь мы подключили репозиторий при помощи helm repo add и присвоили ему имя prometheus-community.
Затем при помощи команды helm repo update мы скачали актуальный список чартов, которые содержатся в репозитории (механизм аналогичен apt update).
Затем при помощи helm search repo нашли нужный нам chart. На этом шаге можно увидеть описание чарта, версию чарта и приложения.
Затем при помощи helm fetch можно скачать архив чарта, распаковать, заглянуть внутрь, убедиться, что нас всё усваивает, и затем установить его из сетевого репозитория. Или, возможно, поправить и установить из локальной папки.
6. Трекинг выката
При выкате релиза мы хотим как можно раньше узнать, если что-то пойдет не так. Не от системы мониторинга, которая сообщит нам, что всё сломалось. И не от благодарных пользователей в случае, если такой системы у нас вдруг вовсе нет, а сразу по окончании деплоя. В Helm для этого существует ключ --wait:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--wait \
--timeout 600s \
--debugЗдесь есть несколько нюансов.
Прежде всего, это таймауты. Часто выкат релиза может занимать значительное время, поскольку он может включать в себя долгие maintenance процедуры (например, накат миграций), долгую инициализацию приложений (со множествои init-контейнеров и прогревом кэшей), Kubernetes deployment policies, которые очень медленно по одному заменяют поды приложения, и т. д. По умолчанию Helm ждет выката релиза пять минут, после чего считает его не удавшимся. Если ваш релиз выкатывается дольше, увеличьте время ожидания выката при помощи ключа wait.
Следующий нюанс: по умолчанию во время ожидания выката релиза Helm ничего не пишет — непонятно, чего он ждёт и не подвис ли вообще. Если указать ключ --debug, Helm будет держать вас в курсе:

Но при этом он также выведет отрендеренные yamls релиза: если у вас при выкате передаётся секретная информация, вы можете её таким образом скомпрометировать. Так что будьте с этим осторожны.
Еще один тонкий момент связан с Kubernetes deployment policy. По умолчанию Helm считает успешным выкат релиза, когда выкатилось минимальное количество подов, заданных в deployment policy.
Допустим у нас deployment replicas = 1.

Первая из приведённых ниже стратегий не допускает нулевого количества подов при деплое, вторая допускает.

В первом случае Helm проследит, чтобы новый под корректно стартовал и заработал, во втором удовлетворится тем, что Kubernetes API корректно принял патч нового релиза. При этом pod новой версии может не запуститься по множеству причин.
6.1. Откат выката
Говоря о релизном цикле, нужно разобраться и с возможностью отката релиза. Чаще всего Helm обернут CI-системой, и для отката релиза нужно просто перезапустить пайплайн выката нужной версии. Но поскольку, как я описывал выше, Helm сохраняет историю релизов в release backend, есть возможность откатить релиз и при помощи команды вида:
helm rollback -n ci-namespace ci-release [REVISION]Если Helm умеет версионировать релизы и следить за корректностью выката релиза, вполне логично появление возможности откатить релиз, если что-то пошло не так. Этот режим включается при помощи ключа –atomic:
helm upgrade --install -n ci-namespace ci-release path/to/chart \
--atomic7. Установка очередности запуска подов
Основная задача Kubernetes — запустить группу контейнеров на группе серверов и следить за их работоспособностью. Из коробки он имеет достаточно ограниченный набор средств для управления конкретно очередностью запуска. Между тем это достаточно часто требуется в рамках релизного цикла для разного рода регламентных работ. Например, сброс и прогрев кэшей, создание очередей, запуск тестов после выката или классический пример — миграции базы данных.
Обычно нужно, чтобы миграции запустились перед выкатом релиза, потому что новый код запросто может падать, не найдя каких-то нужных вещей в БД.
Можно сделать прогон миграций одновременно с выкатом релиза. При этом пока миграции не накатятся (а этот процесс часто бывает долгим), новые поды могут падать. Согласно базовому поведению, Kubernetes при падении пода каждый раз всё больше увеличивает время перед новой попыткой его запустить. При этом определённое время выката релиза может превратиться в непредсказуемое.
Некоторые делают прогон миграций при помощи init-контейнеров. Эта практика, на мой взгляд, тоже плохая. Миграции, конечно, должны быть построены декларативно, так чтобы был возможен их многократный запуск. Но если у вас, например, 20 реплик конкретного приложения, и они перекатываются, согласно Kubernetes deployment policy, по 5 подов за раз, причем каждый будет запускать миграции перед выкатом — что будет с базой, предсказать сложно.
Многие встраивают запуск миграций в CI-пайплайн, но и этот вариант лучшей практикой не назовешь — он делает пайплайны хрупкими. Допустим, у нас на каждую feature-ветку создаётся review-окружение для разработчика, при этом БД также создаётся в Kubernetes. Если миграции будут встроены в pipeline до выката релиза, то для нового окружения они не смогут выкатиться, поскольку БД ещё не будет существовать. Если же мы поместим их после выката релиза, не сможет выкатиться релиз, потому что код приложения будет падать на пустой базе.
Эту задачу может взять на себя Helm, поскольку он находится именно в той части релизного цикла, откуда это делать проще всего.
Для этого в Helm существуют так называемые lifecycle hooks. Их суть заключается в том, чтобы при наступлении одного из перечисленных ниже событий, Helm может создавать или удалять объекты Kubernetes:
pre-install Executes after templates are rendered, but before any resources are created in Kubernetes
post-install Executes after all resources are loaded into Kubernetes
pre-delete Executes on a deletion request before any resources are deleted from Kubernetes
post-delete Executes on a deletion request after all of the release's resources have been deleted
pre-upgrade Executes on an upgrade request after templates are rendered, but before any resources are updated
post-upgrade Executes on a rollback request after templates are rendered, but before any resources are rolled back
pre-rollback Executes on a rollback request after templates are rendered, but before any resources are rolled back
post-rollback Executes on a rollback request after all resources have been modified
test Executes when the Helm test subcommand is invoked ( view test docs)
Чтобы использовать Helm hooks, мы добавляем соответствующие аннотации в описание объекта. Вот пример job с миграциями:

В Строке 7 описаны условия создания этой job: после установки релиза или перед его апгрейдом.
В Строке 8 описан вес хука. Т. е. мы можем делать несколько maintenance-шагов с заданной очерёдностью. Например, при создании нового окружения можно сперва восстановить базу из резервной копии, а потом прогнать по ней миграции.
В Строке 8 описано необязательное условие удаления объекта. Иногда бывает нужно почистить за собой.
Для желающих копнуть глубже, есть подходящая страница документации.
8. Отладка Helm чартов
Для отладки в Helm существуют несколько возможностей.
8.1. lint
Прежде всего, это Helm lint. И он бесполезен.

Может быть, в будущем его доработают, но сейчас он может только предупредить, что вы забыли добавить в свой чарт иконку.
8.2. template и debug
При помощи ключа template мы можем отрендерить релиз и посмотреть, какие yaml он гененирует (это можно использовать для просмотра результата работы чарта или в inhouse инструментах).

Здесь есть несколько тонких моментов.
Прежде всего, при запуске Helm c ключом template нужно передать ему все остальные ключи --set и --values, с которыми будет выкатываться релиз, чтобы добиться повторяемости рендера релиза.
Если была допущена ошибка в синтаксисе yaml, будет выдана ошибка с указанием строки в сгенерированном yaml (которая может отличаться от строки в template). Но если добавить ключ --debug, Helm выведет неправильный yaml — можно будет посмотреть, что пошло не так.
8.3. dry run
При помощи ключа --dry-run можно имитировать деплой чарта в Kubernetes (helm install / helm upgrade --dry-run) и отловить какие-то специфичные ошибки, которые могут возникнуть в процессе (например, отсутствие нужного crd или правка иммутабельного поля).

8.4. Документация
Думаю, не стоит лишний раз убеждать вас в том, насколько важна документация. Особенно если проект разрабатывается командой специалистов. Для управления документацией в Helm есть несколько механизмов.
NOTES.txt — информация о релизе.

Информация, содержащаяся в NOTES.txt, будет выведена из папки templates при успешном завершении выката релиза. При этом мы можем использовать все механизмы шаблонизации Helm.

Для чего это может быть нужно? Например, чтобы уведомить разработчиков об адресе окружения и имени namespace, в который произошел выкат.

Это особенно полезно, если вы используете динамические окружения для тестирования изменений.
8.5. Комментарии
Коментарии в Helm могут быть двух типов:

Отличие их состоит в том, что YAML comments включаются в финальный рендер релиза, а Template Comments - нет. Поэтому нужно быть внимательнее с YAML comments, - теоретически ими можно что-то сломать.
9. Управление релизным циклом
Основные моменты релизного цикла (выкат, откат, выкат с откатом) мы обсудили. Давайте добьём это вопрос окончательно.
Просмотр установленных релизов осуществляется с помощью команды
helm list -n namespace
Как видите, на вход команды нужно подать имя Kubernetes namespace, поскольку Helm-релизы namespace-специфичные.
Посмотреть YAML последней версии релиза можно при помощи команды
helm get manifest -n namespace release-name
Хочу заметить, что это именно текст релиза. Если YAML объектов, связанных с релизом, изменялся вручную или при помощи каких-то других механизмов, они будут отличаться.

Удалить релиз можно при помощи команды
helm -n namespace delete release-name
При этом удалятся все объекты Kubernetes, которые Helm посчитает порожденными релизом. Это хороший способ почистить за собой. Однако стоит помнить, что некоторые объекты он может не тронуть. Например, если у вас statefulset с persistentClaimTemplate, то Helm сочтет порожденные им persistentVolume и persistentVolumeClaim не относящимися к релизу и не станет их удалять.
10. Расширение функциональности Helm
Расширение функциональности Helm производится при помощи плагинов. Работа с ними очень проста и достаточно хорошо описана в официальной документации.
Подробно останавливаться на ней я, пожалуй, не буду. Просто приведу для примера несколько популярных плагинов из списка разработок Community.
Helm Diff — ещё одно достаточно полезное средство отладки, плагин, который позволяет подсветить изменения между новым и текущим релизом.
Helm S3 и Helm Git — плагины, позволяющие получать Helm-чарты, хранящиеся на S3 и Git.
Helm Secrets — плагин, позволяющий шифровать пароли в values.yaml и хранить их в репозиории в зашифрованном виде. Основан на проекте mozilla/sops и позволяет использовать много различных вариантов шифрования данных, например, PGP-ключи. Полезен, если вы практикуете GitOps.
Helm Tanka — наш ответ Чемберлену: если Grafana Tanka научилась поддерживать Helm-чарты, то при помощи этого плагина Helm может работать с манифестами для Tanka.
На этом, думаю, стоит закончить. Статья и так получилась объёмной, пусть в неё вошли и не все интересные функции Helm... Нет, всё-таки ещё об одной я вам расскажу.
Это возможность напрямую работать с файлами, используя объект .Files:

Можно расположить текстовый файл в папке в чарте,

а потом поместить его в текст шаблона, обратившись к нему через .Files.
Подробнее об этой и других полезных возможностях Helm вы можете узнать в достаточно детальной и отлично написанной документации Helm на официальном сайте.
Всем Happy Helming, коллеги!

gecube
Код картинками ужасно - поиск не работает, в блокнот не скопировать. Не делайте так, пожалуйста
gecube
интересно, а не лучше values.yaml для каждой среды готовить свой и в нем как раз и указывать значение requests, например. Аргументация простая. Если у вас меняется количество сред или их параметры - вам придется менять содержимое темплейтов и релизить новую версию чарта, а это больно, но кейс достаточно частый. Поэтому как в примере ДЕЛАТЬ НЕ НАДО.
seasadm Автор
Прошу прощения, но этот вариант описан буквально в следующем примере. (см. Впрочем, подобные конструкции можно оптимизировать при помощи функции toYaml)
seasadm Автор
Также хочу заметить что отдельный values.yaml для каждой среды, на мой взгляд, не очень хорошо. В этом случае теряется наглядность. В прошлой статье (https://habr.com/ru/company/dataart/blog/588258/) я давал пример каким образом можно создать один values.yaml для всех окружений при помощи go templates (см. 2.3. Хорошие практики values.yaml).
gecube
здесь дискуссионный вопрос - хотим ли мы все возможные среды описывать в одном values.yaml и подключать конкретные наборы ключей или мы хотим описывать их в отдельных values.yaml В любом случае валидации параметров и их значений нет ни там, ни там (кстати, какие-то рудиментарные функции в хельме для этого есть). И вот на эту тему было бы интересно подискутировать - как сделать удобный helm чарт, чтобы разработчики без особого погружения могли этим пользоваться и не ломать себе руки об острые углы инструмента. В статье каких-то конкретных рекомендаций, увы, нет. Описаны определенные практики, но вот когда и как их применять - нет.
seasadm Автор
По большому счету, программисту программисту нужно знать только место где можно описать свой параметр, и чтобы он при сборке попал в приложение. Что-то наподобие .env файла.
В случае хелма, values.yaml с разбивкой по энвайрментам с блоком кода для динамического формирования секции env, аналогичным тому который я привёл в пункте 2.3 первой части статьи, на 90% решают эту задачу (я даже сделал ремарку в статье: Этот способ описания очень любят разработчики, поскольку оно достаточно простое и наглядное.). Остальные 10% это секретные переменные, с которыми нужно чуть больше телодвижений.
seasadm Автор
К сожалению, возможности разметки на хабре не позволяют расставлять акценты в коде так как мне бы этого хотелось. В дисклеймере к статье это указано. Также там дана ссылка на репозиторий на гитхабе где эти примеры содержатся в текстовом виде, доступном для поиска.
telpos
Можно добавить в спойлеры (для поиска по тексту)