Всем привет, я — Сергей Бобрецов, CTO в Wildberries.
Сегодня Wildberries — самый большой маркетплейс в России и мы так часто заняты повседневным хайлоадом, что не всегда успеваем рассказать что за всем этим стоит: какие технологии и решения под капотом, как мы справляемся с адом черной пятницы и ужасами киберпонедельника.
Стоит начать с того, что основным генератором прогресса в WB с самого начала и по сей день является фактор роста. По бизнес-метрикам мы растем примерно х2 каждый год уже много лет, а по техническим (количестуву запросов / транзакций / трафику / объему данных и т. д.) — рост может быть даже быстрее, и это создает множество вызовов: технических, архитектурных и организационных.
В итоге, чтобы запустить любую программу или систему в прод на мало-мальски долгий срок нужно обязательно учитывать кратный рост нагрузки, иначе совсем скоро придется вносить серьезные изменения в архитектуру или вообще все переделывать. Речь, конечно, не только про код – надо иметь стратегию масштабирования на уровне железа, сети, данных, самого приложения, команды и т. д.
Сегодня я хочу рассказать немного про нашу инфраструктуру.
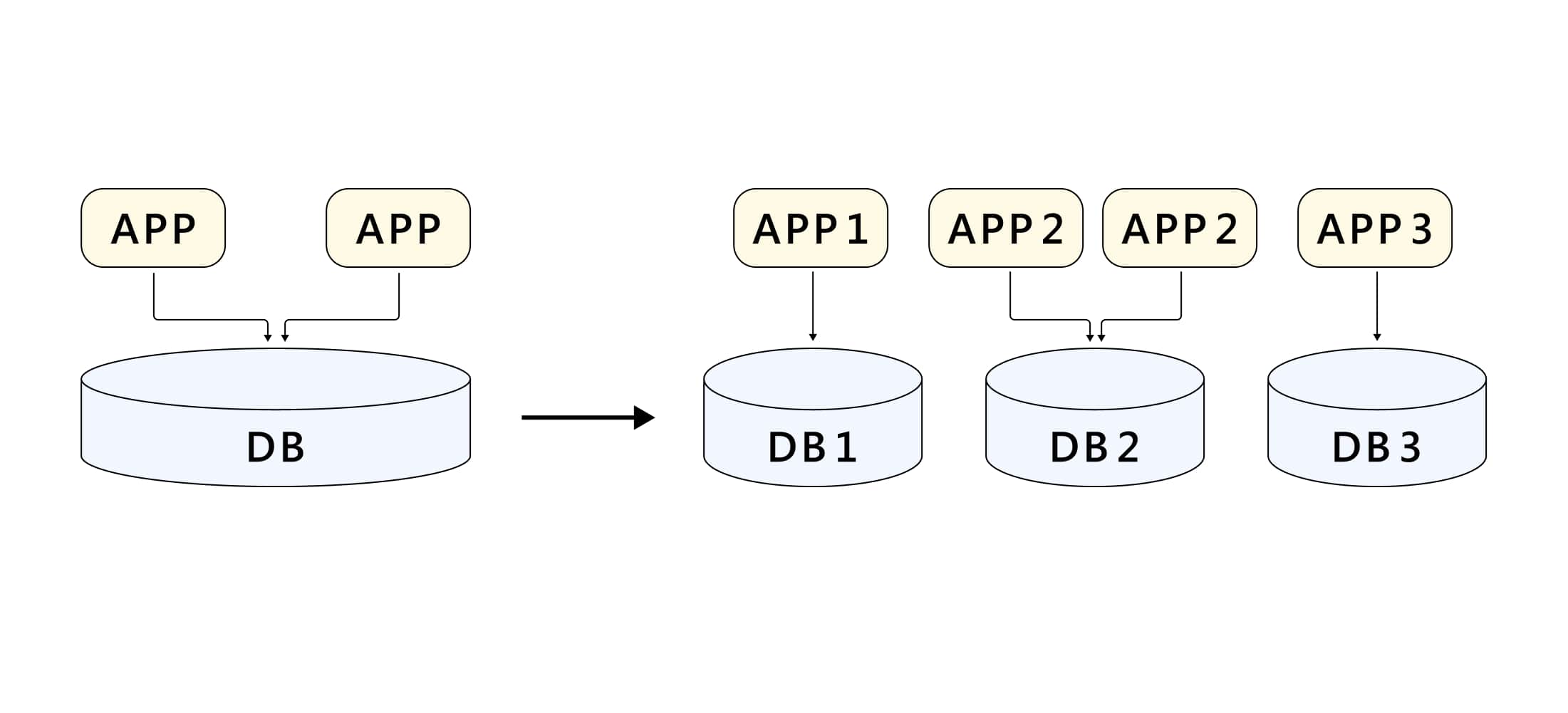
БД и микросервисы
Много лет назад рынок онлайн ритейла только набирал обороты и технически Wildberries походил на сотни компаний вокруг: у нас было несколько серверов в коммерческом датацентре, на которых крутились сайт, бэкенд мобильного приложения и реляционная БД, в которой лежали почти все наши данные, а на соседних серверах хостились корпоративные сервисы типа 1С.
Все это как-то работало до тех пор, пока количество клиентов и заказов не стало быстро расти – сразу после этого систему начало колбасить в разных местах (чаще всего узким местом становилась БД). Появились даунтаймы, которые вредили бизнесу, напрямую влияя на конверсию.
И если с ростом нагрузки на приложение мы просто добавляли больше серверов, то с БД все было несколько сложнее. Сначала мы пытались прокачать ее: добавляли реплики для чтения, подкладывали все более мощные серверы, приглашали специально обученных гуру для оптимизаций, но потом все же приняли очевидный факт – пытаться масштабировать сетап любой БД после определенного предела слишком дорого и бесполезно, и предел этот гораздо ниже, чем кажется на первый взгляд.
Через некоторое время мы разделили данные по функциональному признаку и разложили в разные БД, при этом появился интересный побочный эффект – оказалось, что с таким подходом можно очень просто и удобно разделить и само приложение. Так мы пришли к микросервисной архитектуре.
Тут стоит заметить, что в нашем случае дробление приложения на более мелкие сервисы потребовалось не по техническим причинам: stateless-программа довольно просто и дешево масштабируется даже если это какой-то жирный монолит (кроме совсем уж запущенных случаев) – только успевай ставить серверы. А вот масштабировать команду — такой подход очень помогает: небольшим сервисом может заниматься небольшая команда разработчиков, в которой гораздо ниже накладные расходы на коммуникации. Кроме того сервис с ограниченным функционалом, как правило, проще и имеет более низкий порог входа, что тоже снижает расходы.
Итоги:
разделяйте данные и раскладывайте в разные места при первой же возможности, иначе будете страдать
разбивайте функционал по разным программам, если хотите быстро масштабировать команду
Про K8S
Число небольших сервисов быстро росло и когда оно перевалило за сотню, мы уперлись в доставку приложений в прод: в то время приложения деплоились прямиком на baremetal-серверы с помощью полуавтоматических систем доставки, и поддерживать нужный темп деплоя (а каждый сервис может выкладываться много раз в день) стало дорого.
Поэтому мы сначала сделали самодельную оркестрацию LXC-контейнеров, а затем перешли на docker и попробовали набирающий популярность Kubernetes. В итоге нам понравилось.
Сейчас мы крутим множество кластеров K8S и используем его для запуска почти всех наших программ. Тем не менее не обошлось и без нюансов — подробно описывать не буду (эта тема потянет на отдельную статью), вкратце подведу итоги:
-
мы хостим K8S исключительно с L3 Networking — т.е используем L3 CNI-плагины (конкретно у нас — calico, но существуют и другие варианты) и BGP. Это позволяет легко и прозрачно приземлять входящий трафик, предназначенный конкретному сервису, именно на те ноды, на которых запущены поды этого сервиса, так как адрес сервиса анонсируется только с нужных нод.
Под сервисом здесь я понимаю именно service в терминах K8S. В случае с L2 сделать такое сильно сложнее. Кроме того L3 Networking гораздо лучше масштабируется и позволяет делать трюки типа анонса pod network, что дает возможность гонять трафик внутри кластера без оверлеев вроде VXLAN и даже без DNAT/SNAT — это очень актуально, когда нагрузка велика, а количество нод переваливает за несколько сотен.

мы почти не используем persistent storage в K8S. Гиперконвергенция хорошо звучит в рекламных проспектах, но в реальной жизни нужна какая-то очень серьезная причина, чтобы рисковать данными, а для экономии на железе существуют другие техники. Есть небольшие исключения, для которых мы используем local storage, но только там, где потеря данных некритична.
мы делаем много кластеров. Изначально у нас было по одному кластеру на каждый дата-центр, а растянутых между дата-центрами кластеров мы не делали вовсе. K8S отказоустойчив и отлично масштабируется, но накладные расходы после определенного количества нод становятся тяжелее, а failure domain все больше и больше. В итоге мы начали создавать больше кластеров, а сейчас вообще встаем на путь наливания кластера под каждый сервис или группу сервисов, благо у нас есть собственный инструмент для деплоя K8S — deadbeat.
Про железо
Вопрос железа — всегда вопрос денег. Wildberries — частная компания, и для нас очень важна операционная прибыль. Парадокс в том, что самый простой путь сэкономить на железе — использовать больше железа.
Поясню: стандартный путь энтерпрайза, который ценит свои данные — покупать большие и надежные СХД, с резервируемыми контроллерами, проприетарными технологиями репликации данных между дата-центрами, самым умным в мире тирингом и прочими изобретениями вендоров.
Это крутые девайсы, и чаще всего на них можно положиться, но проблема в том, что они очень дорогие. По цене такой СХД можно купить кучу обычных серверов, а вопрос резервирования и шардирования данных решить на уровне самих приложений — в этом случае вы больше инвестируете в собственное приложение, но зато всю добавочную стоимость вендора оставите себе.
В некоторых случаях игра может стоить свеч даже если речь идет об одной-двух СХД, а если у вас большие объемы, то это то, о чем стоит всерьез задуматься. Аналогичная история — с разного рода блейд-системами и прочим. Да, блейд-система выигрывает по плотности у обычных серверов, но зачем вам плотность в 2021 году? Power budget процессора не зависит от форм-фактора платформы и вы скорее всего упретесь в электричество, особенно в условиях когда в коммерческих дата-центрах аренда одного стойкоместа на 15 КВт чаще всего будет стоить дороже, чем двух по 8 Квт, что делает ценность высокой плотности блейд-систем по меньшей мере спорной.
Vendor lock-in — это зло. Вендоры хотят, чтобы их добавочная стоимость не доставалась другим вендорам. У нас был случай, что СХД одного вендора работала только через коммутаторы этого же вендора, не говоря уже про то, что вы не можете просто заменить диск на любой другой. С другой стороны в обычных серверах такого себе почти никто не позволяет.
Унификация позволяет сэкономить: наше серверное многообразие свелось в итоге к двум типам нод — compute-нодам с горячими процессорами и большим кол-вом памяти и storage нодам c вместительными корзинами для дисков. Когда вам надо купить очень много одинаковых серверов вы, во-первых, получите более низкие цены, а во-вторых, снизите косты на поддержание зипа и резерва.
Все пункты применимы не только к серверному оборудованию, но и к любому другому — к сетевому, десктопам и т. д.
Про сеть
Чтобы размещать в нескольких датацентрах много железа – нужно обеспечить соответствующее количество сетевых портов. Тут все работает так же как и для серверов – лучше всего использовать много простых, но производительных устройств, а стратегию масштабирования основать на общедоступных протоколах, не полагаясь на вендорские ноу-хау.
Еще очень важно построить логическую схему сети максимально устойчивой к отказам отдельных элементов, поэтому из классической энтерпрайз L2-сети, плохо масштабируемой, имеющей кучу ограничений и сильно связанных компонентов мы закономерно пришли к классической сети Клоза (или как ее еще называют - Leaf & Spine, архитектуре в случае двухуровневой фабрики).
Было так:

Стало так:

Углубляться в рамках этой статьи не буду, но смысл в том, что такое решение по многим причинам гораздо лучше масштабируется и строится на стандартных протоколах и механизмах типа ECMP, которые хорошо поддерживаются устройствами всех вендоров, что опять же позволяет экономить на железе.
Кроме того мы используем следующие приемы оптимизации расходов на сеть:
почти во всех стойках только 1 ToR коммутатор, компенсируем риски распределенными приложениями (см. следующий раздел)
DAC-кабели вместо дорогих SFP-модулей
для максимальной унификации стараемся использовать взаимозаменяемые модели оборудования для разных уровней фабрики
диверсификация вендоров
разумная и контролируемая переподписка
Про программы
Для того, чтобы все перечисленные выше пункты работали, одной инфраструктуры недостаточно — нужно писать программы с учетом нашей специфики:
дата-центр может отвалиться — делайте приложение доступным в разных дата-центрах
стойка может отвалиться – делайте приложение доступным в разных стойках
все, что угодно может отвалиться или начать работать неустойчиво – делайте ретраи, curcuit breaker и т. д.
количество запросов будет расти намного быстрее, чем вы думаете – приложение должно легко масштабироваться добавлением инстансов
количество данных будет расти намного быстрее, чем вы думаете – разбивайте данные на куски любыми способами и раскладывайте в разные хранилища (см. раздел про БД и микросервисы)
там, где разбить не получается, предусмотрите шардирование, партиционирование, секционирование и другие подобные техники на этапе проектирования – потом будет слишком поздно
реплицируйте все, что можно. Если возможно и выбранное хранилище позволяет, то используйте разные реплики для разных целей – например, чтение с одних реплик, а запись в другие
Настоящая консистентность нужна гораздо реже, чем вы думаете, но за ее обеспечение платится высокая цена. Подумайте, может быть в вашем случае стоит вместо дополнительных гарантий купить дополнительную производительность
Не бойтесь велосипедов — часто вместо использования какой-то внешней системы/зависимости эффективней написать свою реализацию под конкретную задачу.
Например, в каких-то простых случаях вместо использования внешнего Redis можно закешировать что-то в памяти самостоятельно. Такое решение будет работать быстрее и обойдется дешевле в эксплуатации.
Сервис по банальному перекладыванию JSON-объектов, который кроме самого себя состоит еще из RabbitMQ для очередей, etcd для хранения конфигурации, Redis для кеша, sql-базы для хранения самих JSON-объектов, сайдкаров, Nginx для балансировки и еще пары-тройки других крайне нужных компонент, выглядит очень круто, но на этом его преимущества заканчиваютсяЧаще всего принцип Time-to-Market очень важен — не пытайтесь написать самый лучший и самый красивый код в мире и избегайте лишних абстракций и оверинжиниринга. Лучшее — враг хорошего, а отсутствие каких-то абстракций почти всегда меньший грех, чем появление ненужных
Самое главное
Все пункты выше очень важны. Без этих решений мы бы не смогли обрабатывать миллионы заказов в сутки и быстро расти.
Однако самое важное условие – это крутая и динамичная команда. Об этом в следующей статье.
Комментарии (37)

barloc
31.12.2021 16:20+23Странно писать такие статьи после достаточно свинского сокращения айти в вб в прошлом году.

sdurnov
31.12.2021 20:11+2Так что теперь, не писать статьи? Да уж такая трагедия, до сих пор обиженки по соцсетям носятся. В наши дни разработчику найти новую работу - даже за сутки можно успеть, с нынешней-то ситуацией на рынке, да еще и уровень оплаты сильно повысить. Сам попал под это сокращение, но совершенно никаких переживаний.

jenki
02.01.2022 19:09Красной нитью по тексту идёт мысль про экономию: отказались от того-то ради экономии, перешли на то решение ради экономии и т. п. Сокращение из той же оперы.

Naglec
02.01.2022 21:21Очень смешно, что учётом капитализации компании и стремительному росту благосостояния владелицы. Чую я, что в итоге эта экономия на ИТ приведет к большим проблемам, а виноваты будут инженеры


aegoroff
31.12.2021 16:21+10Чаще всего принцип Time-to-Market очень важен — не пытайтесь написать самый лучший и самый красивый код в мире и избегайте лишних абстракций и оверинжиниринга.
Вот так и накапливается технический долг, - экономия на качестве кода, - это как взять кредит. Отдавать все равно придется. Замедление будет потом, но будет расти как снежный ком.
Впрочем, если конечно ресурсы позволяют - можно все выкинуть и начать писать заново, но это, в итоге обойдется еще дороже.

yellow79
31.12.2021 19:47если речь про отдельно взятый микросервис, то на много дешевле выкинуть и написать новый. сервисы не всегда идеальны и не всегда можно найти того, кто разрабатывал именно тот сервис, который сейчас предстоит править тебе

Borz
31.12.2021 20:20+1-- что за рукожоп делал вам сантехнику/электрику/etc в квартире? Разве так делают? Надо переделывать всё с нуля
-- так это вы же и делали N лет назад
yellow79
01.01.2022 01:32если N достаточно велико, то это вполне нормально, за это время изобрели новые материалы, новые инструменты, новые подходы, зачем продолжать поддерживать старое, когда можно стильно-модно-молодёжное
Borz
01.01.2022 10:26+1в таких случаях не говорят что до этого были рукожопы и что надо всё переделать. Просто аргументированно озвучивается, что поддержка текущего выходит дороже чем переход на новые инструменты/подходы и уже владелец решает что он хочет - перекроить всё или нет
aegoroff
31.12.2021 20:32Ну так не бывает - все сервисы хорошие, а какой-то один плохой - плохое обычно ровным слоем размазано абсолютно везде. С микросервисами проблема в том, что в целом вся система НАМНОГО сложнее монолита.

vsb
31.12.2021 20:52+4Не первый раз слышу от разработчиков из крупных компаний - делать даже не микросервисы, а что-то среднее между монолитов и сервисом. И деление делать по принципу достаточно больших команд. Т.е. пока в команде условно до 10-20 человек, делается монолит (ну или классическое разделение в виде бэкэнд/фронтэнд). А когда появляется вторая относительно независимая команда, то пилить вдвоём один монолит уже станет накладно и стоит подумать о переходе на отдельный сервис для каждой из команд.
У меня такого опыта не было, но звучит очень разумно.

mixsture
31.12.2021 17:22+3У вас в разделе «Про программы» пункт про оптимизацию Time-to-market противоречит почти всем остальным (кроме «велосипеда» и потери консистентности). Потому что эти пункты в кратком изложении будут «пожертвуйте time-to-market и инвестируйте в разработку на несколько шагов вперед».

saterenko
01.01.2022 13:19+2Там вроде больше про архитектуру, а не про код. Архитектуру надо продумать на несколько шагов вперёд, сделать её масштабируемой. А вот при написании кода можно придушить перфекциониста...
Я в одном проекте заморочился и сделал выбор баннера рекламной кампании (множество однотипных проверок) через битовые маски, скорость феноминальная, но на реальных объёмах и с учётом всех остальных действий, выигрыш принебредительно мал... Но у меня было время и мне давно хотелось это сделать.
mixsture
31.12.2021 17:25Парадокс в том, что самый простой путь сэкономить на железе — использовать больше железа.
(больше дешевого железа вместо меньшего числа крутого)
Кажется, вы переизобрели идеологию RAID — redundant array of inexpensive disks (избыточный массив недорогих дисков).

OkunevPY
31.12.2021 19:40Много написано, красочно, только не понятно что в этом особенного?
Идею собирать стстемы из кучи хлама первыми предложил гугл, у них правда другая мотивация была, но сути это не меняет.
Каких то реально продвинутых решений как у гугла я не заметил, так что в целом ничего сверх ординарного в архитектуре нет.
Такой лес городиться не так сложно, наш инженер спроектировал систему для хайлоада с автоскейлингом примерно за месяц на пресловутом k8s, там по сути всё уже придумано как говориться за нас, бери и пользуй.
Приложения под хайлоад проектируються так же почти по готовым сценариям, уже много об этом сказано, много написано и я уже давно не видел на этом поприще новых порывных идей.
Нихочу сказать что сервис хорош или плох, он есть и это факт, если сравнивать с решениями Ali express то безусловно на его фоне проигрывает, но там и немного другие ресурсы в разработке задействованы.

korsetlr473
31.12.2021 21:01+6где вы джойните данные из разных баз когда отдаете клиенту ?
на гэтевее ?
на бэкенде?
на клиенте в два запроса?
через пререндер кэш как через кафту стрим?
Интересный вопрос т.к. вы имеете кучу различных микросервисов с своей базой , но при этом получается предположу что 90% пользователей используют поиск + фильтры которые идут через фул сджойниные данные в эластиксеарче...

Pavel1114
01.01.2022 04:13+2Вот уже пару лет wildberries на главной странице рекомендует мне примерно одно и то же — несколько позиций мужских строго чёрных носков, какие то «нанопятки», немного женской косметики и одежды и мужское термобельё. Я никогда не покупал и не искал ничего подобного не только в их приложении, но и вообще. Ну ладно промахнулись с рекомендациями, но зачем показывать одно и то же, если не работает? Настаиваете что мне это нужно?

nikolayv81
01.01.2022 22:09Возможно это эксперимент, вы просто в группе на которой проверяют одну из теорий...


vgogolin
01.01.2022 06:19А что у вас выступает триггером для автоскейлинга и как быстро получается поднимать новые контейнеры?
MaryRabinovich
01.01.2022 12:42+1В названии насторожило слово "крупнейший": "неужели крупнее (того, где я сейчас покупаю - чтобы не рекламировать)," - подумала я.
Когда-то давно я пользовалась вайлдберрис, я просто других не знала. Потом узнала других, сравнила с ними выбор и сервис. Недавно снова воспользовалась вайлдберрис, и сильно разочарована.При этом я, наверное, значусь среди клиентов - если вы по поголовью зарегистрированных вычисляете рост, а не по, скажем, выручке. По поголовью я у вас единица уже примерно лет десять. Выручка от меня сегодня примерно ноль.
Что меня не устраивает: в первую очередь, цены. Вернее, обозначение цен на сайте. Вот, например, это платьишко стоит 375 тысяч, но в данный момент только 2000 рублей. Очень хорошая скидка, берите же.
Отсюда вопрос: а как вы организуете базу по этим ценам? Откуда-то парсите, потом умножаете надвое? На сто? На тысячу? Исходные цены + 30% указываете как скидочные?
ЗЫ понятно, что это вопрос не то, чтобы к программистам. Вряд ли вы часто общаетесь с маркетологами и финансистами внутри компании. Просто надеюсь, что те это тоже увидят.korsetlr473
01.01.2022 12:45+1вы как маленький , есть общая база , а уже на неё накладываются своя маржа. а вы почему думаете если на айфон цена повышается во всех больших магазин (как эльдарода , мвидео и .тл.) в течении 10 минут одновременно? )
MaryRabinovich
01.01.2022 14:01+5Вы не заметили порядок цен - я настаиваю. Вайлдберрис я запомнила как посредника с сотнями доп.процентов в "исходных ценах". В том-то и дело. Сотня-другая процентов сверху в исходной цене может сделать только одно - заставить юзера сделать глубокий вдох, потом выдох, потом ещё раз, и дальше - пойти погуглить, а что вообще в мире с ценами на нужный товар.
Давайте, чтобы не быть голословной, добавлю из личного опыта: я покупала вещь, которая в целом стоит в районе десятки с хвостиком. В исходной цене на вайлдберрис значилось... 37 тысяч. 37000 рублей. Ага. Итоговая цена покупки была 12, "со скидкой". Я догадалась погуглить - на сайте производителя цены были в районе тех самых 12. И вообще на данный товар глобально цены в районе 10-15.
Я философию их подхода понимаю так: вот покупатель видит 12 на фоне 37, чует, что тут дико повезло и вот-вот товар разберут. Такое создание ажиотажа внутри страницы. Но если цифры в разумных пределах его создать могут, то вот такой разброс... Такой разброс приводит лишь к трезвому размышлению: "вот я погуглю сейчас, как в целом дела с этой штукой, ну и потом, если эти 12 меня устроят, тогда куплю тут". Я в тот момент нагуглила сайт производителя, увидела там примерно те же 12, и за доставку пришлось бы платить чуть больше. В итоге данный товар купила на вайлдберрис, но больше к ним даже не захожу - мне лень так возиться с ценами, каждый товар проверять. И мне не нравится, когда настолько открыто манипулируют информацией.

lestvt
02.01.2022 03:21wb.ru это ведь маркетплейс, а не магазин) из-за таких хитроумных поставщиков товаров, которые бросают пыль в глаза нашим покупателям своими "скидками" - мы начали разработку фичи истории цены, чтобы вы могли оценить действия поставщиков самостоятельно и выбрать более добросовестных
Borz
02.01.2022 14:41и даже добавите проверку на "удалил старый товар и запулил такой же товар, но с новой ценой"?

comerc
01.01.2022 17:58-2Купил поддельный одеколон Tom Ford Noir - зачем мне магазин, который торгует барахлом? :)
mekhan
А рекомендательный микросервис не использует ML или какие-то иные технологии? Что я вижу, будучи относительно давним клиентом с большим колчиеством покупок: если я смотрел лопату, значит возможно мне понравятся 10 других таких же лопат :)
скриншот
В этом плане Озон выглядит более технологической компанией, паказывая в подобном разделе действительно подборку на основании моих интересов и покупок.
lestvt
много хороших компаний и крутых решений) у всех свои
WILDBERRIES Автор
К слову сказать команда data science как раз готовит крупное обновление для этого раздела с использованием ML и аналитических инструментов. Будем посмотреть.
OGR_kha
Логично было бы после покупки лопаты предлагать купить сопутствующие товары - рабочие рукавицы, ведро и грабли. Но для этого для каждого вида товара надо прикрутить ссылки на другие сопутствующие товары.