Введение
Из всего многообразия задач, я, будучи только приступившим к работе в офисе, выбрал исследования поведения пользователей на сайте магазина. Данных от пользования интернет – магазином всегда много, у нас они пишутся в clickhouse, в несколько тематически разделённых таблиц. Порядок записи в день — до одного миллиарда строк. На первых этапах было интересно изучить, как разграничить или наоборот собрать в группы разных пользователей. Да, существуют абсолютно банальные признаки, например — город, useragent, они позволяют определить некоторые группы пользователей, у которых еще могут быть общие признаки, например, средний чек у человека в столице больше. Мне же хотелось пойти дальше.

Структура одной из таблиц предполагает наличие событий, то есть действия пользователей разбиты на идентификаторы. События эти – максимально просты, например, добавление и удаления товара из корзины, но в них, как, оказалось, содержится много полезного. Помимо этого, интерес представляет история заказов. Если агрегировать имеющуюся информацию, добавить немного машинного обучения, то можно создавать вполне полезные и интересные продукты, как для пользователей, так и для самого магазина. Идея похожа на рекомендательные системы, но использовать ее хочется в более широком смысле. В виде самостоятельных решений, как будет в примере далее по тексту, так и дополнением к уже имеющимся сервисам, особенно хорошо, когда присутствует необходимая статистика. В итоге — всё упирается в поставленную цель.
Постановка задачи
После исследования большей части имеющихся данных, на горизонте появились реальные задачи. Одна из них мне особо близка по специальности (безопасность и программная защита инфокоммуникаций), ее я и выбрал.
Вот так можно описать проблему: Существует энное количество внешних пользователей сайта, пытающихся заниматься мошенничеством, о чем становится известно постфактум. Задача состоит в том, чтобы как можно раньше выявить таких пользователей и принять меры.
Сложность обнаружения таких пользователей постфактум, с каждым следующим заказом – уменьшается. Формально, это посмотреть несколько метрик и принять решение. Моя же задача – отодвинуть эту планку выявления, как минимум после одного заказа, а в лучшем случае до первого заказа. То есть на этапе, когда первый заказ только оформлен.
Компания уже располагала набором данных о таких пользователях. Количество этого набора, относительно всех пользователей тысячные доли одного процента. Четко образуется задача бинарной классификации с сильным дисбалансом классов. Ее и будем решать.
Исследовательская часть
Пора переходить непосредственно к теме исследования. Сразу хочу сказать, что хотелось изучить все возможные вариации признаков. В итоговой генерации их было около 500 штук. Большая часть из них оказалась или совсем бесполезна или имела сильную линейную корреляцию. Поэтому, сначала были сокращения до 200 фич, а позже до 100. Самые интересные из признаков хотелось бы показать в разрезе — обычный пользователь и пользователь, которого мы ищем. Интерес в первую очередь вызывают такие признаки как — прайс, движение товаров, частота и скорость событий, статистика возврата товаров. Все признаки масштабированы в диапазоне [0:1] и некоторые трансформированы PowerTransformer. Также, после изучения статистики, были введены искусственные ограничения по суммам заказа из логических соображений, что полезность финансовых деяний при определенном пороге стремится к 0, а количество проверяемых пользователей значительно уменьшается.
Признаки:
- Максимальная сумма возврата

Один из ключевых признаков. По нему уже можно отсеять множество мошенников, но есть две особенности. Признак направлен только на постфактум определение, и он также отсеивает обычных пользователей, в масштабах количества пользователей – это мало, но для автоматической системы поиска мошенников – недопустимо. Также, стоит сказать, что разброс суммы возврата у обычных пользователей меньше, чем у мошенников.
- Максимальная сумма товара, добавленного в корзину

Тоже интересный признак. Во-первых, он работает и до и после заказа. Во-вторых, вполне логичный признак, человек кладет в корзину примерно те суммы, которые он может себе позволить выкупить. Эта фича сильно коррелирует с суммой заказа и суммой возврата. Такая же тенденция наблюдается и с удалением товаров из корзины.
- Относительное количество уникальных сессий при добавлении в корзину
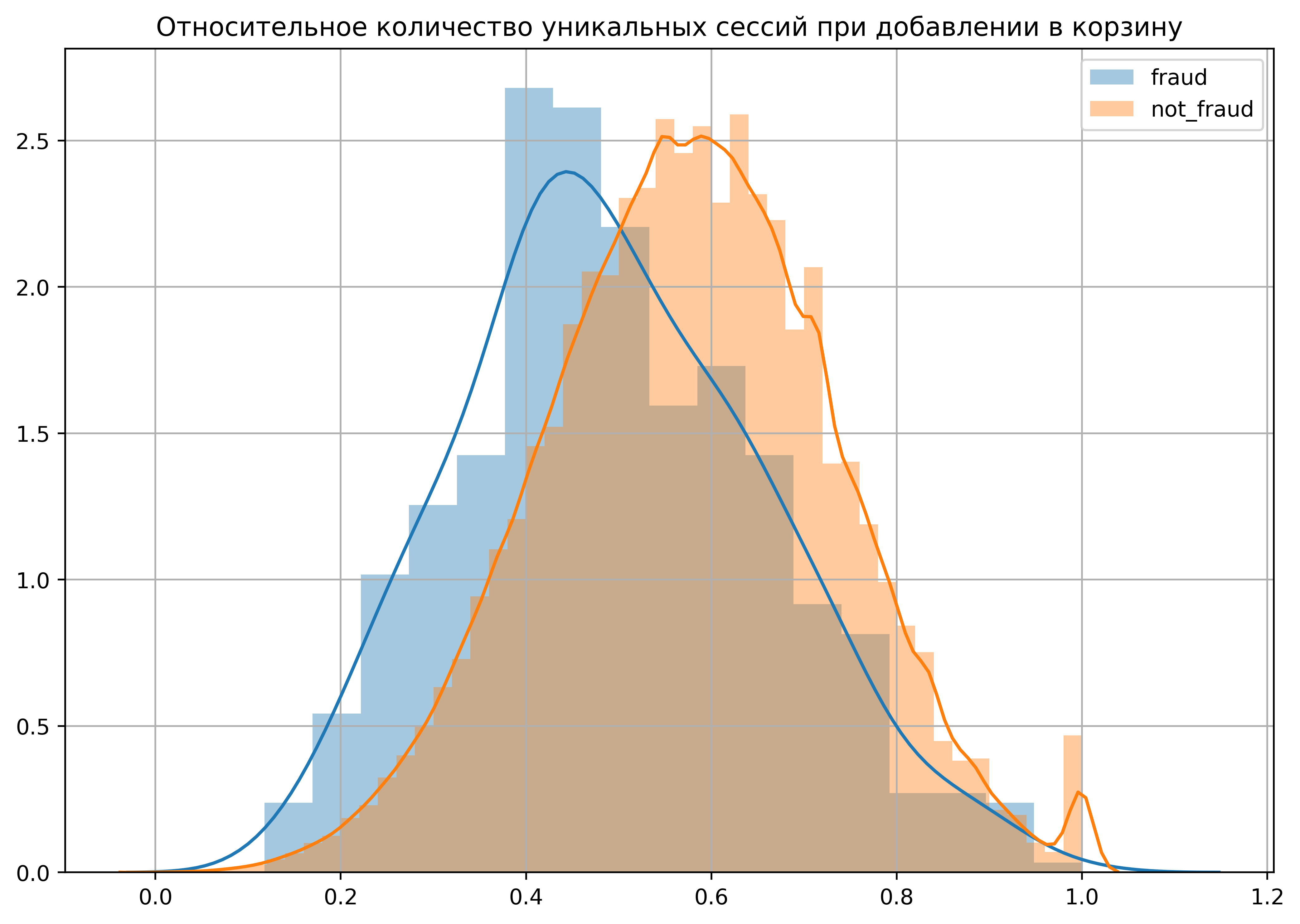
Необычный признак. Он показывает то, насколько пользователь «быстрый» в своем выборе. Меньше уникальных сессий — меньше растянутости при выборе товаров. Есть еще некоторое количество признаков, построенных по такому типу – они тоже довольно информативные.
Помимо «сырых» данных были созданы фичи основанные на долях и перемножениях. Штук 5 из них оказались действительно полезными. Эти и остальные признаки создают некую модель поведения одного пользователя. Безусловно, она не дает четко определить конкретного пользователя, но это и не нужно. Соответственно, такой набор статистики для модели машинного обучения с определённой вероятностью даст результат по новым или ранее не опознанным пользователям. Необходимо только сделать предобработку, подобрать параметры и обучить модель.
Предобработка
Вся часть предобработки включала в себя:
- Пропуски не убирались, такой вариант давал лучшие показатели. С точки зрения задачи – это логично. Если нет у пользователя какого-либо события – то его действительно нет, и стандартное кодирование по среднему тут не очень хорошо работает. Пробовал кодировать минимальными значениями по столбцу минус 1000 – тоже интересный вариант.
- Трансформация признаков (распределения) – хуже или лучше по итогу не стало, но оставил. Хотя, после трансформации удалилось больше признаков при проверке корреляции, но на качество это никак не повлияло. Распределения приобрели человеческий вид.
- Кодирование категориальных признаков – обычным labelEncoder, не хотелось множить признаки onehot, хотя в будущем надо проверить и это.
- Добавление предиктов от кластеризации и поиска выбросов. Неплохой бонус получилось вытащить из структуры данных.
На этапе отбора подтвердились мои ожидания, по поводу сильной линейной корреляции. Функция подсчета корреляции удалила больше половины исходных фич. Далее оценка важности велась с помощью xgboost. Порог в 0.004 оставил около 100 фич.
Тут же было понятно, что часть «чистых» пользователей совсем не есть таковые. Точно известно, что все пользователи в наборе мошенников действительно являются мошенниками, но и в наборе обычных пользователей тоже присутствуют мошенники. Некоторое количество получилось определить с помощью ошибок первого рода. То есть те пользователи, которые попали в ошибки первого рода, были проверены и часть из них действительно оказались мошенниками.
Дорогостоящая часть — настройка гиперпараметров xgboost. Несколько эвристик позволило сократить число вариантов и время подбора с помощью GridSearchCV. А также применение расчетов на видеокарте (gpu_hist)– ускорило этот процесс в 10 раз. Эвристика заключалась в том, что изначально был прогон нескольких различных вариантов бустинга, около 10. Лучшие гиперпарамметры +- попали в GridSearchCV.
Из-за дисбаланса классов были настроены такие параметры как scale_pos_weight и max_delta_step. Без них бустинг давал примерно на 10% хуже результаты. Плюс к этому выдаваемые вероятности стали ближе к истине. Помимо этого, была попытка сбалансировать классы семплингом, но ничего хорошего из этого не вышло – не та задача. Всего понадобилось 1000 деревьев при 0.05 скорости обучения, глубина до 8 и несколько параметров для контроля сложности. Помимо бустинга проверялись другие алгоритмы, но все оказались хуже (не удивительно), хотя время подбора параметров и время кросс-валидации куда меньше на них нужно.
Обучение и интерпретация
В качестве меры оценки была выбрана площадь под кривой полнота\точность. Ее можно использовать при дисбалансе классов. И f_beta с коэффициентами [0.5, 1].
На первом графике изображена зависимость f_beta от порога бинаризации. На втором – кривая полнота\точность. Площадь под кривой равняется 0.58. Не стал «мучиться» с выбиранием порога, поэтому для первого боевого теста найденные пользователи по порогу в 0.1 отправлялись на ручную проверку.
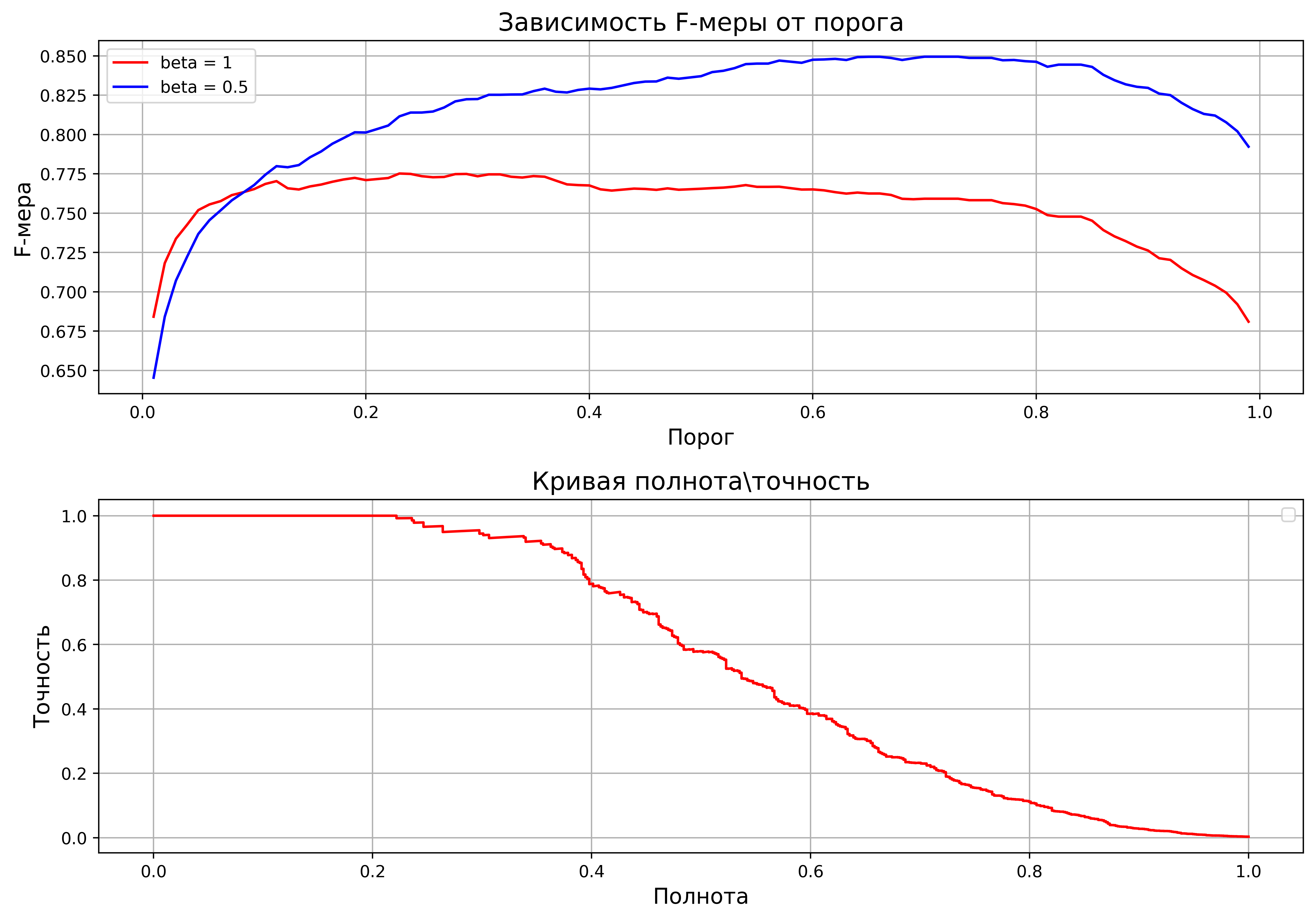
Нельзя сказать, что кросс-валидация прошла максимально гладко. Все-таки, это не соревнование, а реальная задача. Где есть свои особенности, в виде частой непредсказуемости поведения и нелогичности. В тоже время, на первых тестах было найдено довольно много новых мошенников, плюс к этому, были отловлены и старые.
С помощью библиотеки shap можно интерпретировать предсказание модели. Интерпретация результатов хорошо помогает понимать то, как алгоритм работает и почти всегда интерпретация подается логике. Возьмем два примера: обычный пользователь и пользователь, которого мы ищем.
Тут на графике обычный пользователь. Максимальная сумма возврата низкая, малое количество уникальных ссылок, с которых приходит пользователь, определенный тип оплаты, и соотношение максимального возврата к максимальному выкупу один к двум.

Тут мошенник. Быстрота выбора товаров, посещения сайта реже обычного пользователя и низкий разброс сумм возврата (разница сумм со скидкой и без скидки).

Корректировка поиска на основе фидбэка от экспертов
Было принято решение отдавать экспертам всех найденных пользователей по минимальному порогу классификатора в 0.1, для того, что бы в реальных условиях оценить, сколько можно найти нужных пользователей и сколько сделать ошибок. Так набралась интересная статистика. На графиках показаны относительные величины. Всех найденных пользователей можно поделить на три категории: мошенники, подозрительные пользователи и обычные пользователи.
На первом графике – относительная потеря пользователей по категориям в зависимости от порога классификатора. Второй график построен по такой формуле
в зависимости от порога классификатора.
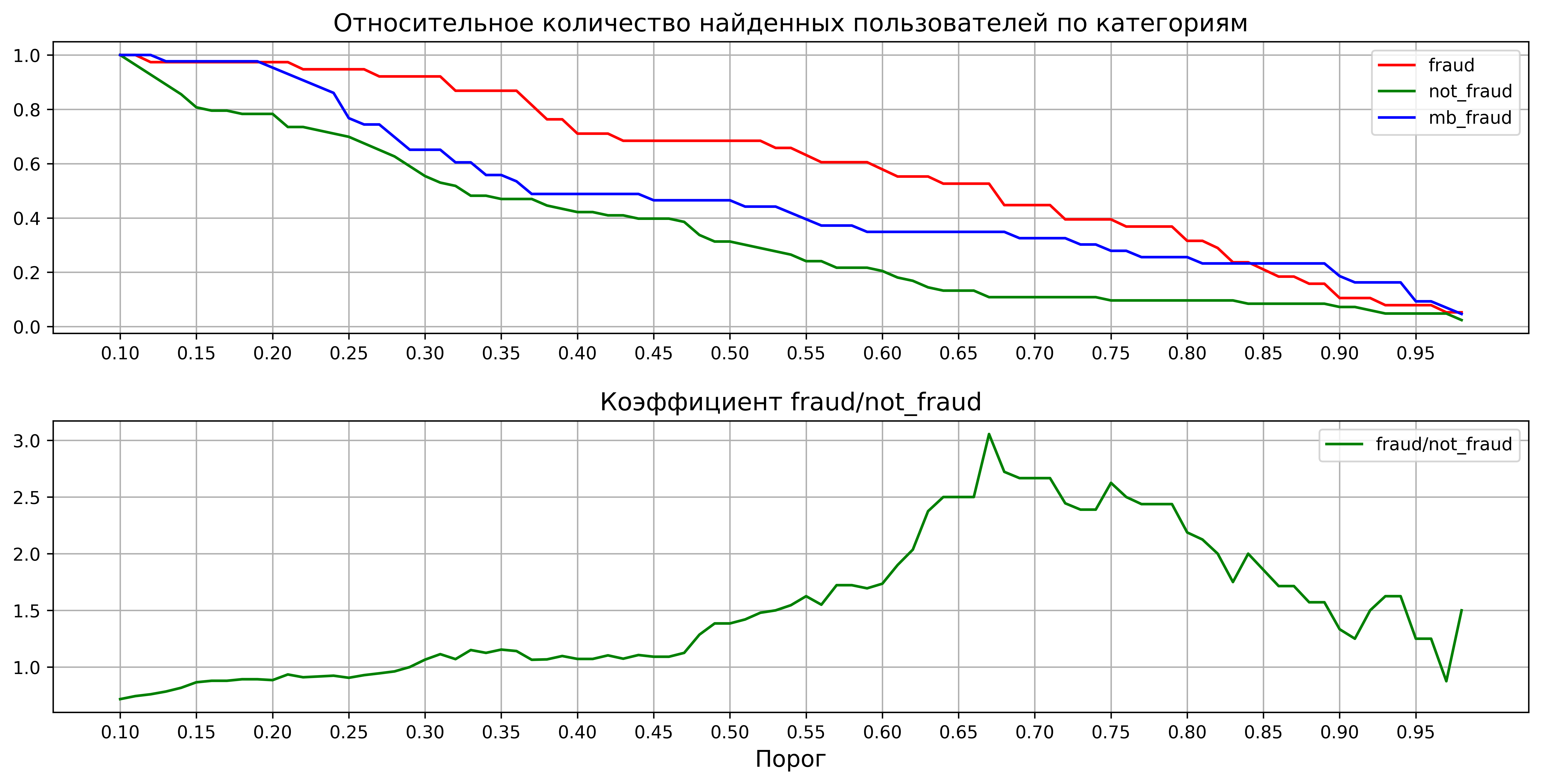
Явно видно, что порог можно сдвигать до 0.67. Для каждых найденных трех мошенников будет приходиться один найденный нормальный пользователь. Есть куда стремиться дальше.
Из того что надо еще попробовать:
- Обучить нейронку на keras, так как MLPC в sklearn дал близкие результаты к бустингу.
- Еще раз пройтись по бд в поисках фич. А точнее, попросить коллег это сделать, может у них получится найти интересные паттерны в поведении.
В следующей части постараюсь развить тему с анализом поведения пользователей, и еще больше углубиться в тонкости данной темы. Глобальных задач, на которые можно наложить эту модель — довольно много. А сама модель, учитывая многие признаки, способна выявлять нетипичное поведение на сайте. Также нельзя забывать, что можно найти похожих людей и выявить паттерны поведения.
nvv
Сложно описать алгоритм и не раскрыть детали, которые помогут мошенникам.
Вероятно вы рассматриваете сразу несколько типов возможного мошенничества, объединив их вместе для статьи.
WILDBERRIES Автор
Вы правы — есть такой момент. Хочется и наработками поделиться и мошенникам дать поменьше пищи для размышления — конечно же при таковой возможности. В целом же, как верно подмечено, имеется объединение нескольких разновидностей мошенничества.