
В статье пойдёт речь о том, как можно автоматически разделить датасет изображений на кластеры, которые поделены по качественному контекстному признаку, благодаря эмбедингам из нашумевшей нейронной сети CLIP от компании Илона Маска. Расскажу на примере контента из нашего приложения iFunny.
Кластеризация считается unsupervised задачей — это значит, что нет никакой явной разметки целевых значений, то есть нет «учителя». В нашем случае мы загружаем некий датасет картинок и хотим произвольно, но качественно побить его на кластеры.
Например, набор изображений животных может разделиться на кластеры по виду, по полосатости, по количеству лап или другим признакам. В любом случае ожидается понятная логика разбивки, которую можно дальше использовать для других задач.
Под катом расскажу, как мы построили логичную кластеризацию с помощью библиотеки HDBSCAN и векторов из нейронной сети CLIP, и каких результатов добились на выходе.
Что такое нейросеть CLIP
В январе 2021 года компания Илона Маска OpenAI выпустила нейросеть CLIP (официальный сайт и код на GitHub). Её обучали обобщать огромное количество категорий, чтобы затем использовать в разных ML-задачах. Разметки классов под конкретную задачу в ней нет, зато есть пары изображений и их текстовые описания в одном пространстве. Отсюда вытекает главный плюс — данную сеть можно использовать в задачах классификации изображений даже без дообучения (zero-shot).
Нейросеть CLIP обучена на 400 миллионов пар изображений и текста, каждая из которых подается на вход нейросети и объединяется с другими парами в батч. Затем сеть обучается предсказывать, какие из пар картинок в батче действительно схожи друг с другом. Тем самым векторные представления в паре текста и изображения сближаются во время обучения.
Обученная модель позволяет одновременно получать эмбединги по произвольному тексту и изображению — то есть с ней можно сравнивать текст и картинки в едином пространстве. Фактически это позволяет комбинировать категории и классифицировать изображения по более сложным текстовым описаниям.Приведу пример. Раньше, используя обучение с «учителем», модели отличали в основном лишь односложные и крупные категории вроде «cat» или «dog». А сейчас могут отличать лежащих котов от прыгающих и не только. Можно отличать изображения по стилю, наличию известных личностей на кадре, количеству предметов — многие подобные комбинации работают без дополнительного обучения уже из коробки.
Работает это так: в нейросеть подаётся изображение и текст, а она возвращает векторы изображения и текста. Затем можно посчитать косинусное расстояние и понять, насколько данный текст похож на изображение. В задаче классификации изображений можно выбирать класс по наибольшей близости векторов картинки и текстового описания класса:

CLIP имеет кодировщик изображений (Image Encoder) и кодировщик текста (Text Encoder), которые преобразуют данные в векторное пространство и предсказывают, какие изображения с какими текстами были соединены.

Для кластеризации изображений в iFunny мы не используем тексты, но используем Image Encoder, который на выходе даёт высокосодержательные векторы, описывающие изображение в многомерном пространстве признаков.
По сути, берём только эту часть из CLIP:

Выполняем кластеризацию изображений
Нам нужно собрать вектор I(x) для каждого изображения в датасете и затем построить кластеризации этих векторов.
В общих чертах кластеризацию можно изобразить так:
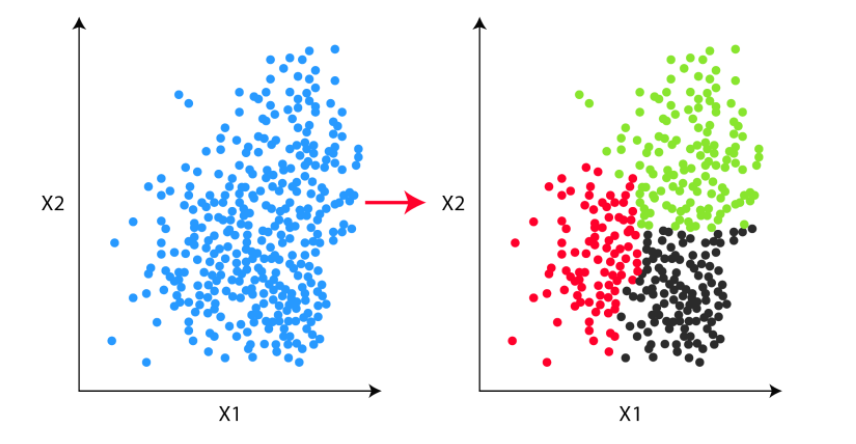
Есть набор точек/векторов в неком пространстве, который нужно разделить на n кластеров. В нашем случае берём векторы из картиночной модели CLIP. На картинке простой пример в двумерном пространстве, но модель из CLIP отдает вектор длиной 512 признаков — а это довольно много для обычных алгоритмов кластеризации.
В таких случаях стоит воспользоваться алгоритмами понижения размерности — например, PCA, TSNE или UMAP. Для кластеризации мы используем библиотеку HDBSCAN, основанную на базе одноименного алгоритма.
Не буду приводить весь код обучения, так как он специфичен под наши задачи, но опишу необходимые шаги, если захотите повторить кластеризацию на своих данных.
1. После сбора датасета, нужно собрать вектор из модели CLIP по каждой картинке. Для этого устанавливаем библиотеку CLIP и используем только функцию encode_image. Предварительно готовим изображения в torch.Tensor с помощью Pillow, как это делается в самой библиотеке CLIP.
image = prepare_pil_image(image, transform).to(device)
image_features = self.model.encode_image(image).cpu().numpy()На выходе получится массив размера [n, 512], где n — количество изображений в датасете, а 512 — число признаков для каждого изображения из модели CLIP. Затем делим полученный массив на набор для обучения (train_embeddings) и для теста (test_embeddings).
2. Далее используем библиотеку umap-learn. С её помощью учим и сокращаем размерность до 2-5 признаков. Гиперпараметры приведены для примера, скорее всего для вашего датасета лучший результат будет при других значениях.
dimension_model = umap.UMAP(n_neighbors=70,
n_epochs=300,
min_dist=0.03,
n_components=5,
random_state=35)
train_clusterable_embedding = dimension_model.fit_transform(train_embeddings)3. Затем на уменьшенных векторах строим кластеризацию. Для этого создаем модель HDBSCAN, обучаем и собираем информацию о том, какая картинка какому кластеру соответствует и с какой вероятностью.
cluster_model = hdbscan.HDBSCAN(
min_cluster_size=1000,
alpha=2.,
cluster_selection_method="leaf",
prediction_data=True
)
cluster_model.fit_predict(train_clusterable_embedding)
train_labels, train_probabilities = hdbscan.approximate_predict(cluster_model, train_clusterable_embedding)
test_labels, test_probabilities = hdbscan.approximate_predict(cluster_model, test_clusterable_embeddings)На тестовой выборке (test_clusterable_embeddings) можно оценить качество кластеризации на новых данных.
Результаты
Итого у нас был на руках датасет на 150 000 изображений после удаления дубликатов. По времени вышло примерно так:
Обучение umap и HDBSCAN — около 2 часов.
Кластеризация на проде — 1-2 секунды на 1 изображение.
Теперь посмотрим на получившиеся в наших экспериментах кластеры. Получились весьма интересные и показательные категории:
Мемы:

Еда:

Мотивационные картинки:

Также в виде отдельных кластеров выделились: животные, политика, 4chan, аниме, скриншоты твиттера, скриншоты приложения iFunny, шутки про США и другие страны, селфи.Из интересного — кластеризатор выделил в отдельную категорию мемы с Doge, знаменитой собакой породы сиба-ину:

Минусы подхода
Тяжело получить качественное разделение на кластеры. Мы экспериментировали с параметрами UMAP и HDBSCAN, но все равно ошибки остаются, и часть сложного контента попадает в кластер «другое».
Количество и логика кластеров может меняться от случайных параметров. Но если вы точно знаете, на какие классы хотите разделить изображения, то возможно лучшим решением будет разметить изображения и применить fine-tuning к той же модели CLIP.
Модели требуют времени и памяти на инференсе. Для ускорения в продакшене можно использовать GPU.
Где использовать подход
Но есть и плюсы. Вот некоторые примеры, где можно применять такой подход кластеризации контента:
Для исследование контента. Можно брать контент только одной категории (или от одной группы юзеров) и смотреть, на какие кластеры его стоит разделить. Так можно лучше понять свою аудиторию.
Для получения предварительных классов для дальнейшей разметки. Например, если вам нужны только животные, то можно брать их из кластера «животные», но удалять на стадии разметки ошибки кластеризации. Это ускорит время разметки.
Для получения признаков для других моделей, например, рекомендаций. Даже с ошибками в кластеризации разделение по большей части выглядит логичным и точным. Таким образом, можно улучшать метрики качества рекомендации контента в ленте.
Для быстрых экспериментов с одной категорией контента. Можно взять, скажем, кластер с едой и сделать кнопку поиска только по фотографиям еды.
Заключение
Модель CLIP отдает качественные признаки изображений, по которым можно получить кластеризацию, действительно отражающую логику и категории внутри вашего датасета. Сочетанием UMAP и HDBSCAN можно легко добиться среднего количества качественных кластеров (10-30) почти без пересечений.
Результаты нас в целом устроили. Эту кластеризацию можно делать без разметки, а затем полученные кластеры использовать в других задачах.
Комментарии (9)

nikolay_karelin
14.01.2022 14:11+2А в чем здесь смысл CLIP по сравнению с ResNet, например? Если вы не используете текстовой составляющей, так может более простой подход будет лучше?

skleg Автор
14.01.2022 16:54+2Хороший вопрос! ResNet не пробовали, но пробовали EfficientNet, который предобучен на ImageNet. Субъективно он делил достаточно грубо и не справлялся с категориями мультиков и подобного контента из соцсетей. Если говорить про self-supervised модельки (SimCLR и подобные), то их мы не пробовали до CLIP, но есть похожие эксперименты сейчас. Мне кажется, что они без обучения на наших данных будут одинаковы или хуже CLIP, то есть их надо учить, чтобы бы было заметно лучше.CLIP сам по себе довольно прост, он уже был подготовлен к проду в момент решения задачи. Это одна из причин, почему взяли именно его.
nikolay_karelin
14.01.2022 17:00+1Понял, интересно.
Кстати, я недавно тестировал несколько предобученных сеток, у меня тоже EfficientNet была визуально хуже ResNet (вылазили картинки явно непохожие один на другой).
pi-null-mezon
14.01.2022 16:54+1Не пробовали что-нибудь полегче CLIP использовать, для рассчёта векторов изображений? Почему решили взять именно CLIP, если векторы текста не используете?
skleg Автор
14.01.2022 18:31В целом по конечным результатам для нас CLIP был чуть лучше других вариантов без обучения модели. И он уже был на проде.

DaneSoul
14.01.2022 17:20+1Не понял один момент: CLIP умеет делить только по категориям которые она знает?
А если например задача разделить кучу специфических изображений на визуально похожие группы, без необходимости текстовых описаний? Например визуально рассортировать кучу фото каких-то деталей которые сеть не знает?skleg Автор
14.01.2022 18:35+2Нет, текст может быть произвольный, в этом прелесть. Но сами названия кластеров задавали постфактум, глядя на сами кластеры уже после обучения (никакие тексты и названия кластеров не нужно в данном подходе).
По вашей задаче: мне кажется, тут дело в деталях. CLIP более-менее нормально может поделить и по визуальным признакам, но также картинка со словом «яблоко» может оказаться рядом с реальными фотографиями яблок, и с мультяшными, и даже с айфонами. То есть если идея по большей части на визуальных признаках, то можно взять что-то вроде SimCLR или новых аналогов. И если есть данные, то возможно обучить или дообучить под ваши фотографии. Думаю, так лучше получится связать похожие элементы визуально, а значит и сами фотографии.
Я бы сравнил оба варианта для ваших задач и попробовал разные алгоритмы понижения размерности и кластеризации.
vitaliebureanu
Интересная статья, узнал кое-что новое. Пишите ещё :)