Это история о том, как увеличить скорость выкатки фич, но сохранить качество продукта. О болевых точках, которые замедляют разработку, и новой «болезни» — микросервисе головного мозга, которую диагностировал Михаил Трифонов, техлид фронтов в SberСloud. Он утверждает, что она приводит к росту функциональности ML Space на 683% при увеличении команды разработки всего в 2 раза. Невероятно, но бизнес-аналитика это подтверждает. Так что давайте разбираться по порядку.

Постановка диагноза
Ошибки высокой связанности
Всё началось с того, что Михаил вместе со своей командой SberСloud обсуждал проблемы разработки и начал выделять болевые точки, первой из которых были ошибки высокой связанности.
Возьмём для примера монолит, у которого есть три абстрактные фичи со своими внутренними зависимостями. Бизнес хочет обновить фичу №1. Для этого понадобится обновить и некую зависимость. В крупных приложениях их так много, что у фичи №1 связь с зависимостью может сохраниться, а у фичи №2 частично или полностью пропасть.

Из-за этого ошибки высокой связанности генерируют два фактора, тормозящие разработку: увеличение количества багов и большое тестирование. Везде, где есть баги, приходится тестировать всё, что способно сломаться.
В микрофронтах вы можете разбить монолит на кусочки-сервисы, которые будут изолированы и независимы друг от друга. Если вам необходимо сделать внешнюю зависимость, вы делаете уже некий npm-пакет. А когда бизнес просит обновление, то создаете вторую версию пакета.
У команды разработки SberСloud зависимость одновременно существовала в двух версиях: новая фича использовала новую версию, а все старые фичи — старую, поэтому багов быть не могло. А если не может быть багов, то нет смысла всё это тестировать.
Merge conflicts
Следующая болевая точка, которая замедляет разработку — merge conflicts. Чтобы разработчики не тратили на это время, в микрофронтах каждый сервис можно поднять в отдельный репозиторий и назначить ему владельца. Тогда у разработчика будет несколько сервисов, которыми он владеет, но разработки не будут пересекаться. Следовательно, не будет merge conflicts, и разработка пойдет быстрее.

Релизные циклы
Они позволяют синхронизировать разработку и даже сотрудников разных отделов. Но в случае со SberСloud на микрофронтах они были лишние, потому что у их разработчиков были свои сервисы с малым количеством пересечений. Им было достаточно писать код, который проходил тестирование и отправлялся в прод. Это быстрее, чем ждать релиз для отправки каждой новой фичи, а баги можно быстро доустранить позже.
Если у вас есть релизные циклы, можно использовать Gitflow. Это архитектурный паттерн, который помогает реализовать синхронизацию взаимодействия. Если релизных циклов нет, можно пользоваться Github flow. Давайте их сравним:
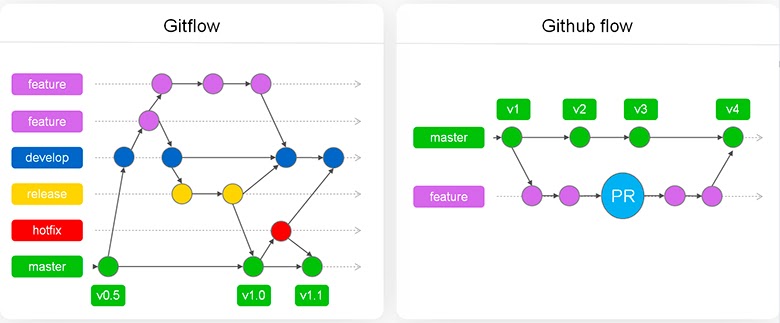
По схеме видно, что Gitflow сложнее. Путь появления фичи в нём бывает проще, ведь она готова к продакшен еще на develop, но из-за синхронизации разработки добавлено еще несколько итераций.
В Github после релиза фича сразу отправляется в мастер в прод. Но там есть другие проблемы, например, merge conflict.

Все места, где потенциально может возникнуть merge conflict
В Github они могут возникнуть только в мастере. А в Gitflow при вливании в каждую итерацию (develop, release, hotfix и master). Из-за этого нужно дополнительное тестирование, которое увеличивает нагрузку на QA. Получается, что Gitflow создает несколько этапов, которые тормозят выкатку фич в прод. Поэтому, при наличии микросервисов, отсутствии релизных циклов и низкой синхронизации между разработчиками, выгоднее пойти по пути Github flow.
Долгий Pipeline и тестирование
В монолите не важно, разработали вы большую фичу или маленькую. Если выкатить её на прод, вы обязаны пересобрать приложение со всеми его зависимостями и тестированием. В некоторых компаниях это занимает от 25 минут.
В микрофронтах надо пересобрать один микросервис с зависимостями и протестировать только его. Например, у команды разработки SberСloud это занимает 3 минуты — и можно релизить в продакшен.
Сложное масштабирование команды разработки
Если на монолит приходит сторонняя команда или новый разработчик, им нужно рассказать, как работает приложение, что с ним можно делать и чего нельзя.
В микрофронтах нужно объяснить только про тот сервис, с которым человек будет непосредственно работать. Это намного быстрее.

Еще одна точка, тормозящая разработку — это отсутствие переиспользования функциональности.
Отсутствие переиспользования функциональности
Есть ML Space — MLOps (Machine Learning) платформа, которая содержит в себе 30 сервисов. Все они используются в ML, но часть сервисов может использоваться и не в ML. Поэтому иногда требуется разрабатывать, например, Docker registry. Он может использоваться отдельно или вообще в составе другого приложения.
В микрофронтах вы можете запустить свое приложение, как standalone, и встроить его в другой продукт. То есть вы разрабатываете единожды, а не каждый раз в новом продукте.
Review
Теперь давайте перейдём к боли многих — это ревью. Оно состоит из двух этапов. Первый, когда после разработки, перед релизом, вам необходимо получить ревью. Второй этап, когда к вам приходят за получением ревью.
Поскольку в микрофронтах есть свой репозиторий, выделенный владелец сервисов, у которого благодаря изолированности небольшое взаимодействие с другими разработчиками, ревью можно делать по расписанию. То есть не важно, когда владелец изменяет свой сервис. Главное, что его код оттестирован и стабильно работает. Тогда в моментальном ревью нет необходимости, и это можно делать, например, раз в два месяца. Благодаря такому подходу ревью становятся предсказуемыми, группируются и уменьшаются в объеме.
Нет частичной доставки техдолга
Следующая болевая точка — техдолг. Для примера возьмём таблицу, которая в монолите используется на каждой странице. Она — суперуниверсальный компонент, который требует настолько большого рефакторинга, что бизнес просто не даст вам этого сделать. Слишком сильно сдвинутся сроки.
В микрофронтах все распилено по-сервисно. В части приложения вы можете обновить по одному сервису или по два, и выделять на это столько времени, сколько нужно.
Мы определились с болями и теперь осталось решить, как их лечить.
Методы лечения
После обсуждения идеи перехода с монолита на микросервисную архитектуру, микросервис головного мозга распространился внутри команды разработки SberСloud. Поэтому было решено обратиться к пациенту №0.
Его зовут Joel Denning. Он написал фреймворк Single-spa. За его основу взял другую библиотеку SystemJS, чтобы асинхронно загружать модули (AMD или S6), в реалтайме в браузере. Фреймворк хорошо работает из коробки. Его и взяли за основу.
Подготовка bundles
Чтобы bundle читался SystemJS, его необходимо подготовить с помощью специальных преднастроенных Webpack-конфигов или rollup, кому как удобней. Под капотом может лежать любой фреймворк (React, Angular, View, Svelte).
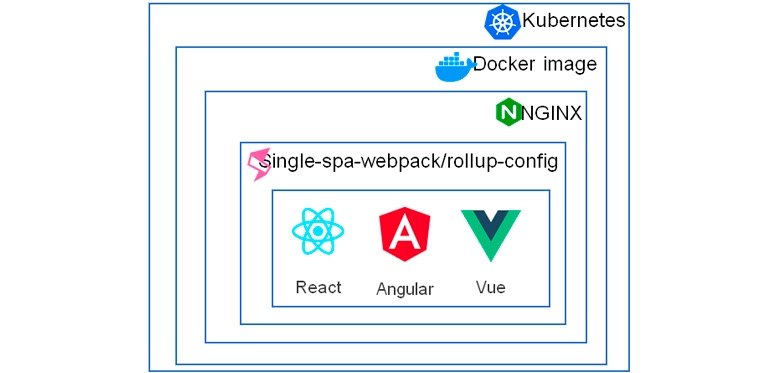
Конфиги генерируют bundle и проставляют специальные метаданные. Их хранение отдано на откуп разработчику. Например, у SberСloud в качестве HTTP-сервера используется NGINX для контейнеризации Docker, а DevOps-оркестрацией занимается Kubernetes. После того, как bundle готов, как раз ее и нужно настроить. Браузерная оркестрация делится на 3 этапа.
Расположение bundle
Сначала вы должны указать, где находится bundle. Настройка гибкая, и вы можете делать так, как вам нравится. В SberСloud реализовали следующие 4 варианта:
importmap.json (prod) — продовая версия, когда bundle берутся относительно домена, с которого они заходят.
{
“imports": {
"“@mlspace/root-config": "/mlspace/root-config.js",
“@mlspace/main-menu": "/main-menu/mlspace-main-menu. js",
“@mlspace/bootstrap": "/init/mlspace-bootstrap. js",
}
}importmap.json (localhost) — когда bundle берутся с локально поднятых сервисов с портов.
{
"imports": {
"@mlspace/root-config": "//localhost:9000/root-config. js",
"@mlspace/main-menu": "//localhost:8002/mlspace-main-menu.js",
"@mlspace/bootstrap": "//localhost:8004/mlspace-bootstrap. js"
}
}Специально для разработки SberСloud еще сделали так:
importmap.json (mix-prod)
{
“imports": {
@mlspace/root-config": "https://mlspace.aicloud.sbercloud.ru/mlspace/root-config.js",
“@mlspace/main-menu": "https://mlspace.aicloud.sbercloud.ru/mlspace/mlspace-main-menu. js",
“@mlspace/bootstrap": "//localhost:8004/mlspace-bootstrap. js"
}
}importmap.json (mix-test)
{
“imports": {
“@mlspace/root-config": "https://mlspace.poc.ai.sbercloud.dev/mlspace/root-config.js",
“@mlspace/main-menu": "https://mlspace.poc.ai.sbercloud.dev/mlspace/mlspace-main-menu. js",
“@mlspace/bootstrap": "//localhost:8004/mlspace-bootstrap. js"
}
}Логика у команды SberСloud была такая: всё поднимается либо с прода, либо с теста, кроме одного сервиса, в котором непосредственно работаешь. Он поднимается с localhost.
После этого оставалось научить ядро загружать данный bundle.
Загрузка bundle
Для этого в Single-spa есть API с гибкими настройками. Команда SberСloud разделила все сервисы на 4 типа:
Technical занимались подкапотной работой (store, bootstrap, ядро).
Events загружались по event. У них было диалоговое окно выбора файлов, полноценный сервис, который запускал много других сервисов из разных точек.
Common загружались везде (меню, sidebar, header).
Route загружались непосредственно по какому-то route.
Загрузки происходили только один раз. Команда SberСloud сделала так, что Technical, Events и Common сервисы грузились первым этапом, а Route-сервисы — по необходимости.
Верстка Wrappers
Последняя настройка браузерной оркестрации — это верстка самих фронтов. Для этого есть index.ejs. Разберем его на примере части кода ядра SberСloud:
index.ejs
<template id="mlspace-root">
<single-spa-router base="<%= (main_path) %>/">
<application name="@mlspace/bootstrap"></application>
<application name="@mlspace/fm-explorer"></application>
<div ids="mlspace-header" class="mlspace-header">
<application name="@mlspace/main-menu"></application>
<div class="mlspace-header__box">
<application name="@mlspace/header"></application>
</div>
</div>
<div id="mlspace-body" class="mlspace-body">
<div id="mlspace-sidebar" class="mlspace-sidebar">
<application name="@mlspace/sidebar"></application>
</div>
<div id="mlspace-content" class="mlspace-content">
<route path="inference-deploy">
<application name="@mlspace/inference-deploy"></application>
</route>
</div>
</div>
</single-spa-router>
</template>У них был application, сервис bootstrap (Technical-сервис) и fm-explorer (Events-сервис). Они загружались вне DOM пользовательского дерева и работали.

Для header был HTML div (обычный тэг), в котором можно работать, и внутри загружались два сервиса: main-menu и header.
<application name="@mlspace/main-menu"></application>
<div class="mlspace-header__box">
<application name="@mlspace/header"></application>
</div>
</div>Дальше был body, в котором грузился сервис sidebar и по route (тэг route) загружался inference-deploy в сервис inference.
<div id="mlspace-body" class="mlspace-body">
<div id="mlspace-content" class="mlspace-content">
<route path="inference-deploy">
<application name="@mlspace/inference-deploy"></application>
</route>
</div>
</div>На самом деле все это заработало из коробки, но bundles стали выглядеть примерно так:

Впереди идёт браузер, а сзади, чтобы все загрузилось, подталкивает SystemJS. Чтобы это исправить, рассмотрим Shared-зависимости.
Shared Dependency
Чтобы их понять, разберём схему:
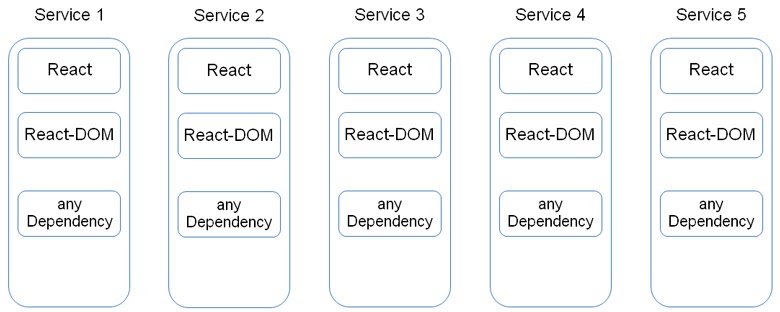
Все сервисы независимо от того, изолированные они или нет, грузят React и React-DOM. Конечно, хочется это исправить. Для того, чтобы они загружались только один раз, есть два способа.
Первый: с помощью SystemJS. В Webpack есть настройка (или свойство) externals. Она запрещает Webpack класть данный импорт в bundle, а говорит брать его из глобальных переменных. Благодаря этому, можно выразить React и React-DOM прямо из сервисов. После этого надо положить в глобальные переменные сгенерированные bundles. Создать сервис, а в нем через import-map будут лежать такие же ссылки, как делали на сервисы, только bundle — уже скомпилированные React и React-DOM.
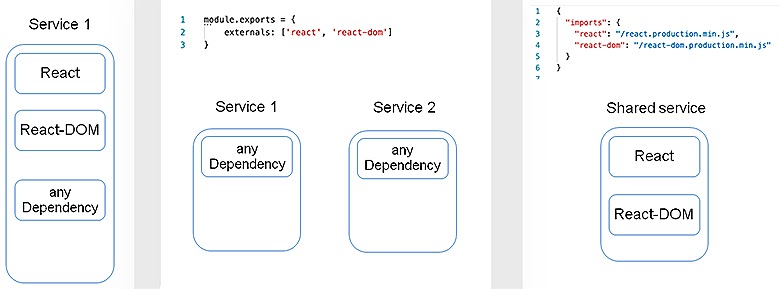
Способ подходит для редко обновляемых библиотек типа React и React-DOM. Но есть один нюанс: если в SystemJS (в глобальной переменной) лежит не та версия или произошла какая-то проблема с загрузкой — микрофронт упадет.
Второй вариант: сделать все то же самое с Module Federation. Он кладет React и React-DOM в ядро и непосредственно в свои сервисы. То есть, когда он собирает, то рядом с собой кладет сами bundles. Поэтому, если сервис пытается загрузить с ядра bundle React, но падает или получает не ту версию, он загрузит свой, уже имеющийся код.

Шина данных
После настройки браузерной оркестрации команде SberСloud нужно было наладить обмен данными. Сначала они решили сделать реализацию своего store. Для этого в Single-spa есть такое понятие, как кросс-микрофронтовый импорт. Из сервиса можно экспортировать ссылки Store и функции, которые с ним работают. Они использовали RxJS, а вы можете взять то, что удобнее вам: Redux или MobX.

Дальше микрофронт импортирует данную ссылку, подписывается на Store, и уже с ним работает. После реализации Store команде потребовалось настроить обмен только сообщениями.
Events
Сервис Notify выводил тостеры. Это было сделано для консистентности, чтобы они не наслаивались друг на друга.
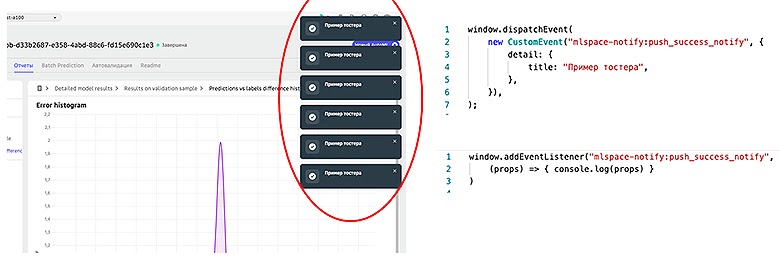
Команда SberСloud реализовала это через обычный Custom Events в Windows. Он генерировал и отправлял сообщения, а сервис Notify был на него подписан. Другие сервисы отсылали ему уведомления, а он уже выводил сообщения об ошибках или успешных действиях пользователя. Это обычный Pub/Sub. Но у него есть один недостаток: если в какой-то момент Notify лежал или просто не загрузился, то никакое сообщение вы не увидите.
Чтобы сделать гарантированную доставку, нужно реализовать брокер сообщений во фронте:

В SberСloud для этого взяли async/queue. Так ядро у них всегда поднято и всё работает. Так что можно сделать аналогично.
У нас остался последний метод лечения болевых точек.
Изолированность разработки
Все перечисленные методы связаны с изолированностью разработки, но у неё тоже есть минусы.
Когда у разработчика один сервис, как отдельное приложение, он сидит в header и не видит других сервисов. Может даже поднять его как standalone и только с ним работать.
Если посмотреть на то же самое со стороны пользователя, то он видит приложение целиком. Ему все равно, микросервисная у вас архитектура или нет. Пользователь работает с единым приложением, и для его удобства необходимо сделать консистентный дизайн, по крайней мере в микрофронте А и В, но лучше сразу делать UIKit.
То же самое касается конфигов. Но у SberСloud в ML Space было 30+ сервисов. Каждый использовал свой Webpack, linter, prettier, тест-конфиги. Поэтому, чтобы все это сделать консистентно, они подняли Nexus и отдельный пакет с конфигами, чтобы сервисы уже непосредственно оттуда забирали конфиги.
“dependecies”:{
“@mlspace/config”:”12.1.1”
}Еще одна проблема изолированности — это консистентность разработки. Например, у каждого разработчика в команде своя структура. Архитектура никак их не ограничивает. Каждый может сделать свою структуру папок, использовать свой фреймворк, другой стек технологий, и по-разному реализовывать — один в плоской, другой в компонентной части. И, если разработчик, например, уйдет в отпуск, то кроме него никто с этим разобраться не cможет. Поэтому в команде SberСloud заранее договорились с разработчиками:
Какой стек технологий;
Какая структура проекта;
Как работать с общими зависимостями;
Как делать Review;
Flow взаимодействия с git.
Всё, чего нет в списке, они оставили на усмотрение владельца. А если возникали новые особенности, их дописывали и регламентировали с помощью гайдов и т.д.
Так команда решила большинство проблем.
Болезнь эволюционировала
Прежде, чем двинуться дальше и рассказать, как в SberСloud появилась «монорепа», ещё раз вернёмся к техдолгу.
Пилим техдолг
Техдолг способен быстро разрастись, причем до таких больших объемов, что у разработчиков складывается ощущение, что легче выкинуть приложение и написать его с нуля.
Микрофронты не полностью решают эту проблему. Например, есть обычный микрофронт с кнопкой input, таблицей и хлебными крошками. Все компоненты из старой-старой версии UIKit, а бизнесу нужна новая кнопка из нового UIKit. И, когда разработчик обновляет UIKit, чтобы получить новую кнопку, то все другие компоненты тоже мажорно обновляются.
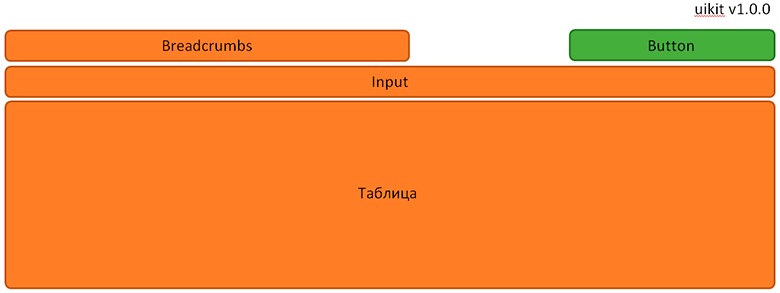
И получается, что разработчик вместо того, чтобы делать бизнес-фичу, занимается устранением техдолга. Пока в команде SberСloud обсуждали эту ситуацию, они получили еще один симптом — «монорепу».
Монорепозиторий
Это когда у вас есть один репозиторий с множеством подпроектов, каждый из которых может быть npm-пакетом. У него будет своя версия, с которой он отдельно работает. Поэтому, если нужно обновить одну кнопку, то можно обновить только её.

Чтобы это реализовать, команда SberСloud взяла Lerna за пакетный менеджер. Он позволял решить многие проблемы с версионностью и publition вручную. Например, когда Lerna не создавала новый пакет в их структуре и не писала в облако, они сделали скрипт для нового пакета, который генерировал store, структуру папок и readme.
Следующий момент — работа с зависимостями. Команда SberСloud столкнулась с тем, что если кнопки или внутренние зависимости для store и функционала Store Book мажорно обновлялись, Lerna думала, что надо обновить не только их, но и весь компонент. В этом не было необходимости потому, что кнопка использовалась только в store.
Сначала проблему решили через обычные alias TS. Но из-за этого появился человеческий фактор: разработчик мог вызвать обновление не через alias. Чтобы проверять, что импорты в store и версия внутри package.json указаны правильно, написали скрипты. Потому что, если прямо указать старую версию, Lerna ее не обновит, а решит, что это зависимость от старой версии.
Пока у них был один UIKit, это работало, но когда стало 43 пакета UIKit, чтобы отдельно не импортировать стили в каждый, сделали скрипт их автоматической подгрузки. Он добавлял стили на этапе сборки пакета прямо внутрь npm. Еще добавили интеграцию conventional-commits Lerna с Jira. Для этого переписали Changelog. В общей сложности получилось 4 скрипта, но их количество, скорее всего, будет расти.
Карта зависимостей
Сначала в SberСloud распилили монолит, потом конфиги, UIKit и в итоге карта зависимостей одного продукта стала выглядеть так:
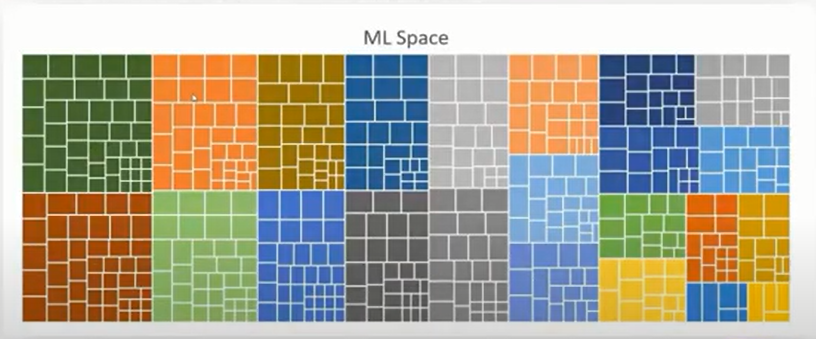
Каждый цвет — это отдельный сервис, каждый квадрат внутри — это какая-то зависимость только от внутреннего SberСloud пакета (есть еще внешние). Но надо следить за актуальностью версий и проверять лицензионные политики. Вручную это делать нереально, у одной только Lerna 547 зависимостей.
Автоматизация
Команде разработки помогли коллеги из DevOps. Сделали так, чтобы с помощью шедулера GitLab запускался скрипт, который с npm проверял актуальность версии. Если требовалось обновление, создавался MR на ответственного разработчика.
А для контроля лицензионных политик использовался плагин версий статического анализатора SonarQube. Он проверял код на этапе CI/CD, и, если что-то не так, не давал выкатить его в прод.
Клепаем сервисы как пирожки
Поднятие сервисов занимало лишнее время, а команда SberСloud хотела создавать их в 2 клика. Поэтому они разбили добавление нового сервиса на два этапа.
Сначала генерировали bundles: создавали новый репозиторий, оборачивали в Single-spa и делали настройки. Но после создания 5 сервисов стало ясно, что слишком много boilerplate, поэтому воспользовались Gitlab Templates. Сделали отдельный репозиторий как шаблон. По нему разработчик создавал свой репозиторий и поправлял только уникальные части кода.
После этого оставалось настроить данный bundle в ядре и указать его расположение в importmap (importmap.json, importmap.local.json, importmap.mixprod.json, importmap.mixtest.json). Также нужно было сделать верстку данного сервиса в index.ejs и route-config.json (где находится каждый сервис). Но сразу в 6 местах поддерживать это было неудобно, поэтому команда взяла один конфиг, и с помощью JS-скриптов данные из него передавали во все остальные.
История болезни
Подведем итог. Команда SberСloud поставила цель — ускорить разработку и сохранить качество продукта. Для этого они распилили свой монолит на микрофронты и внедрили Single-spa. Это дало им прирост, но пришлось делать шину данных, шарить зависимости и работать с консистентностью. Для этого они внедрили Nexus, UIKit, Guides. Потом распилили техдолг, внедрили Lerna с монорепозиторием и автоматизировали отслеживание актуальности версий.
Болезнь распространилась и на рабочие процессы. Команду ML Space поделили на Environments, Deployments, Data Catalog. Теперь они работают независимо.
Бизнес-аналитики посчитали, что функциональность ML Space выросла на 683% по сравнению с предыдущим годом, при этом команда разработки увеличилась всего вдвое. Получается, что эффективность одного разработчика увеличилась в 3,5 раза!
Видео выступления Михаила Трифонова на конференции FrontendConf 2021:
Профессиональная конференция фронтенд-разработчиков FrontendConf 2022 пройдет в ноябре в Москве. Скоро откроется CFP, и, если вы хотите выступить, подумайте об этом. Пока можно забронировать билеты и купить записи выступлений с прошедшей конференции.
Комментарии (6)

souls_arch
17.01.2022 22:44-3Главное иностранцам не показывайте, а то если там найдутся сторонники BLM, master они вам не простят. О чем давно предупреждение висит на удаленных гитах. Корректно сегодня - main branch. Я не сторонник сей дурости, но презентацию лучше переделать, а слово мастер забыть, если работаете с "вредными" иностранцами.

desertkun
18.01.2022 02:23+1Хуже цензуры только самоцензура. Во всех репозиториях (в т. ч. с клиентом) мастер ветка называется исключительно master. Как говорится try me.

andreyverbin
18.01.2022 02:16+3>В микрофронтах нужно объяснить только про тот сервис, с которым человек будет непосредственно работать. Это намного быстрее.
А ещё все, с которыми он общается. Все как с монолитом, только головной боли на 686% больше.

rotlis
18.01.2022 13:17... и это можно делать, например, раз в два месяца. Благодаря такому подходу ревью становятся предсказуемыми, группируются и уменьшаются в объеме.
Эта фраза кажется мне противоречивой. Насколько я знаю, большая часть индустрии стремится к обратному - делать ревью как можно чаще (на каждый pull request) что примерно соответствует удобоваримому куску кода до 400 LOC.
muturgan
Плюсанул в карму просто прочитав название статьи