Я не буду здесь расписывать установку и настройку unraid. Это делается элементарно — просто закидываются файлы на флэшку, флэшка вставляется в сервер — можно пользоваться. Всё понятно расписано у них на сайте, плюс много полезной информации есть на youtube-канале Spaceinvader One. Какие-то ранние вещи там уже устарели, потому, если видите несколько видео на одну тему, выбирайте более свежее. Ещё понятные доки на эту тему у ibracorp, есть и youtube-канал, если буквы не любите.
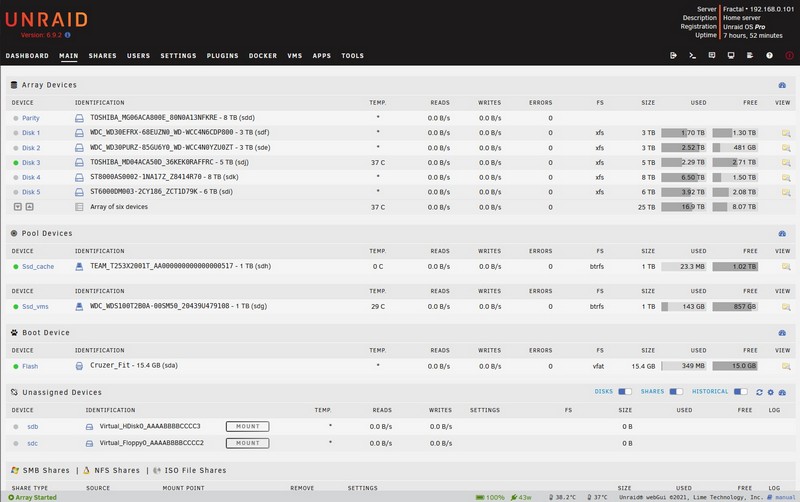
А я лучше просто опишу, как выглядят теперь перечисленные во второй части сервисы.
- Мой новый домашний сервер, часть 3: немного о сборке
- Мой новый домашний сервер, часть 2: выбор софта
- Мой новый домашний сервер, часть 1: выбор железа
Файлопомойка
Тут всё стандартно — samba. Я потерял возможность руления правами доступа на папки-файлы — из коробки тут только правами на шары можно управлять. То есть если раньше у меня была шара «пользователи», а в ней были папки «пользователь1», «пользователь2» и т.п. с разными владельцами, то теперь вместо этого надо создать шары «пользователь1», «пользователь2»…
Впрочем, это вполне обычно для самбы, ACL редко какой из дистрибутивов по-умолчанию включает и делает полноценную поддержку. Для дома это терпимо, у меня пользователей человек пять, так что можно просто шар добавить, не запутаемся.
Чисто теоретически, и тут можно попытаться включить ACL, но я читал на форумах про проблемы, с этим связанные. Большинство людей наоборот, отключают ACL и удаляют их хвосты, чтобы исправить проблемы с правами доступа. Но, как уже сказал — переживу и привыкну. Можно сказать, что почти ничего не изменилось. Было десять шар, станет двадцать. Не смертельно.

Не в тему: Truenas Scale у меня с полпинка вошел в виндовый домен и позволил раздавать права на файлы, используя доменных пользователей и группы. В своё время в OMV подобное потребовало гораздо больше телодвижений и общения с консолью.
Объединение дисков и отказоустойчивость
Одно прикручено к другому, так что одним пунктом пойдут. Длинным пунктом, потому что возможность объединять диски разного размера в один массив и свободно их добавлять и вынимать, без пересборки этого массива и копирования информации куда-то в сторону — это основное, что мне требуется от ОС для домашней файлопомойки. При этом надо иметь какую-то защиту от проблем с дисками массива, потому что бэкапы — бэкапами, но лучше, когда к ним прибегать не требуется. Третьим пунктом — много места отдавать на эту защиту не хочется.
Я знаю три решения, которые всё перечисленное позволяют без серьёзных танцев с бубнами:
- Windows + Drivepool (и аналоги). Это и использовал на старом сервере.
- Unraid. Это я начал использовать на новом сервере.
- Linux + aufs/mhddfs/… + snapraid. Это чисто теоретическое знание, но когда дойдут руки — хочу попробовать собрать такой массив на базе OMV и поиграть с ним.
Всё остальное либо позволяет только менять диски на такие же, либо только увеличивать массив, добавляя диски. А вот уменьшить массив с сохранением информации — это функция очень редкая.
Объединение дисков и эффективная ёмкость
На микросервере у меня было 4 диска общей ёмкостью 3+5+6+8=22 терабайта. Учитывая дублирование папок (около 5 терабайт), эффективная ёмкость была 22-5=17 терабайт. На новом сервере я (пока) смог добавить ещё два диска — 3 и 8, но при этом одна восьмёрка ушла под диск для контрольных сумм (парити-диск), то есть эффективная ёмкость стала 3+3+5+6+8+8-8=25 терабайт.
В drivepool я бы получил на этих же шести дисках 28 терабайт (учитывая дублирование папок). Но восьмитерабайтный диск в unraid у меня защищает весь массив, а не конкретные папки на нём. Плюс, если я в драйвпуле захочу защитить не пять терабайт, а десять, то эффективная ёмкость массива станет 23 терабайта (так как 10 уйдёт на дублирование). А на unraid ничего не изменится. Потому я не особо страдаю от того, что целый диск отдаётся под контрольные суммы (точнее, сперва было страдал, потом посчитал и успокоился).
Кстати, к вопросу об использовании SMR-дисков: массив вида JBOD — в отличие от разных RAID'ов — позволяет спокойно использовать любые диски с учётом их технологии. Просто не надо ставить SMR под активную запись — и все будут довольны. К примеру, у меня сигейты на 6ТБ и 8ТБ — SMR. И можно посмотреть по количеству READS и WRITES, как активность на массиве устроена. С SMR практически только чтение идёт, запись минимальна. А вот Toshiba 8ТБ — это CMR-диск, потому и стоит под парити. Потому что туда только запись идёт, чтение бывает только во время проверки массива или ребилда диска.

Защита информации
При потере одного диска в drivepool я теряю информацию только с этого диска, за исключением дублированных папок — их копии остаются на других дисках массива.
При потере двух дисков теряется информация с двух дисков. С дублированием — как повезёт, смотря где именно были продублированы файлы. Но если боитесь вылета двух-трёх и более дисков — можно настроить хранение любимых файлов хоть на всех дисках массива. Но тогда они займут во столько же раз больше места.
Понятия «ребилд» у drivepool нет, так что потерять ещё один диск от повышения нагрузки на остальные шансы невелики.
В unraid защита работает не на конкретные папки, а вообще на весь массив. И при потере одного диска никакая информация не теряется.
При потере двух дисков теряете информацию с двух потерянных дисков, остальная остаётся целой. Есть возможность назначить два диска под парити, тогда массив выдержит потерю двух дисков. Больше двух дисков под парити не назначить. При желании можно жить вообще без парити — тогда получите только объединение дисков, без защиты.
Понятие «ребилд» тут имеется. Может ребилдится либо парити-диск, либо подменный диск взамен пропавшего из массива. Так что шансы потерять второй диск от повышения нагрузки имеются, как и на классических рейдах. Но на остальных дисках данные уцелеют.
Хотя всё это не повод полагаться на средства защиты разных видов массивов и не делать бэкапы. Бэкапы наше всё! Делайте бэкапы — и ваши файлы будут мягкими и шелковистыми.

Это была реклама бэкапов, за которую мне заплатили производители бэкапов.
Изменение массива
Добавление диска
В drivepool, чтобы добавить диск, вы вставляете в компьютер новый диск, нажимаете кнопку «добавить» и диск в массиве. Через некоторое время на него переедет часть информации с других дисков согласно правил балансировки. Если на диске была какая-то информация, то она там и останется. Просто будет «за пределами» массива и с ней можно будет работать прямым обращением к диску.
В unraid добавление диска — это деструктивное действие. При добавлении диск забивается нулями — чтобы не пересчитывать контрольные суммы и не терять.

Время, занимаемое на добавление диска, зависит от скорости записи на диск. Обычно примерно полтерабайта в час, то есть терабайтник будет добавляться около двух часов, десятитерабайтник — около 20. SMR-диски, наверное, будут добавляться дольше, но я таким способом ещё не пробовал их добавлять.
Потому что есть второй способ, который позволяет не чистить добавляемый диск. Надо подключить диск к системе, при помощи плагина Unassigned Devices отформатировать диск в файловую систему вашего массива (у меня — xfs), затем:
- Остановить массив, извлечь парити, запустить массив.
- Остановить массив, добавить новый диск, запустить массив.
- Остановить массив, вернуть парити, запустить массив, дождаться ребилда.
Это звучит страшно, но на деле делается довольно быстро — за исключением последнего пункта. Потому что ребилд парити тоже идёт со скоростью примерно полтерабайта в час. И при больших дисках занимает много времени, у меня на восьмитерабайтнике — от 16 до 18 часов.
Активность дисков в начале процесса ребилда парити-диска:

Если диски разного размера, то меньшие «освобождаются» раньше. Если же парити-диск больше, чем другие диски массива, то последние терабайты он дописывает нулями в гордом одиночестве.
Отчёт о завершении:
Notice [FRACTAL] — Parity sync / Data rebuild finished (0 errors)
Duration: 18 hours, 32 minutes, 31 seconds. Average speed: 119.9 MB/s
На время ребилда у вас массив остаётся без защиты. И на все диски идёт нагрузка на чтение, потому пользоваться сервером в этом время затруднительно. Я пробовал копировать в этом время файлы с массива на ssd — получалось 200-300 килобайт в секунду.
Но я так делал из-за того, что, во-первых, мне не хотелось мучать SMR-диски полной записью. А под парити у меня стоит CMR, он это всё проще переносит. Во-вторых, я переливал информацию со старого сервера через эти SMR-диски. То есть сперва их цеплял вне массива, форматировал в xfs, потом по сети туда перекачивал файлы и уже заполненный диск втыкал в массив.
Как вариант, чтобы не напрягать диски лишний раз — на первоначальное заполнение массива можно парити не назначать, а когда всё подключите-разложите как надо, тогда уже подцепите парити-диски, сделаете ребилд и будете жить в нормальном режиме. Я про это как-то слишком поздно подумал и не раз сделал ребилд.
Но наличие парити-дисков в массиве не обязательно, он вполне может только и из data-дисков состоять:

Будет только напоминать о том, что нет парити, но при этом будет спокойно работать:

Удаление диска
В drivepool диск удалялся нажатием кнопки «удалить диск». После этого информация автоматом переносилась на другие диски и диск удалялся из массива. Время зависело от объёма информации. Можно было сэкономить, не перенося дублированные файлы (потому что вторая копия оставалась на других дисках и потом во время прохода балансировщика дублирование восстановилось бы). Либо можно было принудительно извлечь диск, вообще ничего не перенося — если ждать не хотелось. Иногда были вопросы с открытыми в приложениях файлами, надо было их закрыть и повторно запустить извлечение диска.
В unraid, чтобы извлечь диск из массива, нужно: остановить массив, создать новый массив без извлекаемого диска (на забыв поставить галочку «сохранить настройки»), дождаться ребилда парити. Информация при этом остаётся на вынимаемом диске, потому, если он нужна, надо её куда-то перенести руками или специально обученными плагинами (unbalance, например).
Есть второй вариант, который позволяет извлечь диск без ребилда, но он требует зачистки извлекаемого диска и я его не пробовал. Описывается в вики на сайте.
Замена диска
В drivepool понятия замены диска нет, это решается через удаление старого диска и добавление нового. Можно наоборот, так быстрее будет. Учитывая простоту добавления-удаления, отсутствие «замены» проблемой не является. Объём дисков значения не имеет.
В unraid именно заменить диск можно только на такой же или больший по объёму. Замена на меньший — только через удаление старого и добавление нового.
- Остановить все сервисы, которые пишут на массив напрямую, отключить автозапуск докеров и виртуальных машин, если они живут на массиве, отключить автозапуск массива (не обязательно, но лучше перебдеть).
- Остановить массив, извлечь диск из массива, запустить массив — чтобы он понял, что диска у него нет.
- Выключить компьютер, заменить диск физически, включить компьютер (если у вас нет поддержки замены дисков на лету). После включения массив должен быть в состоянии «остановлен», если автозапуск не забыли отключить.
- Добавить диск в массив вместо вынутого, запустить массив, дождаться ребилда диска. Если диск больше по размеру, то файловая система будет автоматом растянута.
В целом, сами возможности остались такие же, как и были раньше — могу добавлять, удалять и заменять диски. Но это стало занимать заметно больше усилий. Взамен я получаю защиту на уровне всего массива (а не отдельных папок) и удобную работу со всякими докерами. Так что считаю, что по данному пункту тоже остался при своих.
Написал про всё это так много, потому что для меня подобная гибкость в управлении массивами — это определяющая функциональность файлопомойки. Варианты без этого даже не рассматриваю.
Качалка торрентов
Как уже писал, раньше у меня был Vuze. Мне вообще много не надо от торрентов сегодня — закинуть торрент-файл в папку и получить скачанное через некоторое время. Желательно ещё с алертом «скачалось». Это любой торрент-клиент умеет. Конкретно Vuze я выбрал из-за того, что у него есть плагин для поддержки нескольких пользователей, у остальных клиентов подобное поведение сложнее реализовывалось.
Здесь просто запустил личные контейнеры с качалками. Подозреваю, что они всей толпой будут памяти жрать не больше, чем это делал один единственный vuze.

Пока два, себе привычный deluge, не себе — красивый qbittorrent с упрощённой темой.

Медиасервер
Plex был, Plex остался. Запустил контейнер, подсунул ему базу со старого сервера, указал новые пути к библиотекам — и всё заработало по старому. Полёт нормальный. Транскодинг видеокартой не проверял, потому что нет её у меня пока что. Процессором транскодит не хуже, чем было раньше.

Виртуальные машины
Насколько я понял, в качестве движка виртуализации тут используется KVM. Вроде раньше был XEN, но некоторое время назад поменяли. Вообще, управление виртуалками — это не самое сильное место unraid, и если для вас это основное требование к домашнему серверу — то лучше глянуть на специализированный гипервизор.
А в unraid нет снапшотов, нет встроенных бэкапов, нет кластеров и т.п. Автоматизированные бэкапы можно организовать при помощи плагина, но он при создании копии останавливает машину. Снапшоты, в принципе, тоже можно скриптами сделать (или virt-manager прикрутив), но всё же это костыли, которые при регулярном использовании системы в качестве гипервизора смогут достать.
Свои старые виртуальные машины я пока не перетаскивал, всё равно основное всё на десктопе живёт и там ещё поживёт до тех пор, пока я не обживусь на сервере окончательно. Но особых сложностей я не жду — сконвертировать образы дисков из виртуалбокса да подсунуть их в новые конфигурации проблем не должно составить.
Тестовая виртуалка с десятой виндой работает без вопросов, линукс тоже без проблем запустился. Видеокарту пока же не пробрасывал за отсутствием таковой, но SATA-контроллер пробросился без проблем вместе со всеми дисками. А вот с пробросом usb-флэшки были вопросы, она не отображалась в списке доступных устройств — пришлось прокидывать её не как usb-устройство, а как raw-диск, прописыванием прямого пути в /dev/disk/.
Короче говоря, тут не всё так безмятежно, как хотелось бы, но вполне приемлемо, на мой взгляд. Эта задача для сервера тяжелая (частично из-за неё и был затеян апгрейд), но лично для меня не основная, потому возможностей unraid мне хватит.
Сервер бэкапов
Тут я попробовал перейти с veeam на urbackup. Мне давно хотелось централизованно видеть состояние бэкапов на разных своих компьютерах, а с бесплатным veeam этого было не увидеть. Пока мнения нет, пробую ещё.
Синхронизацию отдельных папок с декстопов-ноутов на сервер решил попробовать настроить на syncthing для единообразия, особенно в плане ноутов полезно, которые не обязательно дома могут быть, а настраивать-включать vpn и т.п. не всегда хочется. Я syncthing когда-то пользовался, но у меня тогда как-то его работа совпала с запиливанием диска на сервере, на котором у него папки хранились (несколько тысяч бэдов довольно быстро возникло), потому я от него отказался. Может и не он виноват был, но вот совпало.
Из непонятных вещей, которые сами прошли — сперва я unraid в ожидании заказанной материнки гонял на Athlon X4 940/A320/8GB. И там скорость передачи файлов по локалке через syncthing была заметно меньше 100 мегабит на гигабитной сети. При этом особенно загрузки процессора не наблюдалось. Потом я к вопросу вернулся уже после того, как закончил все железные разборки — и скорость стала приемлемой, в районе 800 мегабит. Но с того времени и дисков в массиве добавилось, и ссд под кэш появились, и материнка сменилась, и процессор трижды… Так что я не могу сказать, что конкретно это было.
В облако (onedrive) по прежнему бэкаплюсь duplicati — разве что поменял настройки времени хранения бэкапов (раньше просто стояло «последние Х версий», сейчас поставил правило «за неделю хранить ежедневные бэкапы, месяц — недельные, год — месячные, вечно — ежегодные». Но, конечно, это зависит от частоты изменения в файлах и всё строго индивидуально. Плюс у меня десятки заданий бэкапов (а не все терабайты одним заданием), так что где данные изменяются почаще, можно и другие правила поставить.
Мелкий лайфхак — если у вас много аналогичных заданий, отличающихся на какие-то мелочи (у меня это годы в названиях папок, к примеру) то создайте одно задание в вебинтерфейсе, экспортируйте в json, затем редактируйте в текстовом редакторе то, что будет отличаться и импортируйте.
Плюс размер файла бэкапа увеличил с умолчальных 50 мегабайт до 300 мегабайт, хотя, конечно, это тоже зависит от того, что именно бэкапишь. У меня основное содержимое — это фото в RAW'ах размером в районе 20 мегабайт. Так что в одном архиве получается 10-15 фото, вместо двух.
Из тонкостей касательно именно докера/unraid — duplicati сперва делает архивы в /tmp, затем только их качает. И, если при небольших файлах проблемы незаметны, то вот при более крупных у меня быстро забился docker.img. Пришлось прокинуть из хоста папочку для /tmp
Duplicati пока что перекачивает бэкапы в облако, потому стабильно кушает процессор на упаковку-шифрование (я отвёл четыре ядра) и будет кушать ещё неделю, не меньше. Закончит — успокоится.

Плюс прикрутил через rclone свой терабайт на mail.ru и решил с ним синхронизировать некоторые вещи, к которым иногда хочется иметь доступ, не «компрометируя» домашний сервер. Музыка, книги, может какое-то видео… Расшаривать оттуда какие-то файлы, подцеплять через О: Драйв и т.п. Ну и лишняя копия не помешает, учитывая то, что эти данные не относятся к тому, что я регулярно бэкаплю.
Ну и сам анрейд тоже не стоит забывать бэкапить — это загрузочная флэшка и папки с данными контейнеров и виртуалок.
Удалённое рабочее место
Поскольку больше работать непосредственно на сервере не могу, придётся завести себе личную виртуалку для этой задачи, как и товарищу раньше, благо ресурсов теперь побольше стало. Как вариант — можно настроить guacamole для доступа к рабочим столам через веб, без vpn или проброса портов.

Хостинг
Здесь будет много изменений. Если раньше был просто прокинут порт на вебсервер в виртуалке, то теперь прокинутых портов будет много. Хотя про много проброшенных портов — это я загнул, вполне хватит 80/443 и nginx proxy manager'а. Но вот поднять дома несколько сервисов, типа bitwarden для паролей и т.п. я давно собирался. Теперь это всё делается гораздо проще, чем под виндой. Технически можно было и там, но тут всё же проще.

Заключение
Тут я думал было написать что-то про используемые плагины unraid, планы на добавление сервисов (всякие там автокачалки, конвертилки и т.п.), но решил, что смысла нет — это опять бы превратило пост в очередную инструкцию, чего мне не хочется. Взгрустнётся — напишу отдельно, как окончательно всё оформлю.
Так что просто кратенько подведу итог — я доволен получившимся решением. Конечно, у него есть и недостатки — куда без этого. Но, в комплексе, unraid меня полностью устраивает.
Основное, что «мешает» в сравнении со старым — это изменившаяся идеология использования, но тут ничего не поделаешь — я всё это знал, так что остаётся только привыкать и изучать. Тот же докер мне не только дома пригодится, по работе тоже не помешает. Слишком долго откладывал. Хотя, конечно, без опыта работы с докером ставить готовые контейнеры из библиотеки unraid гораздо проще, чем в консоли пытаться понять, каким концом надо воткнуть apache в php, чтобы оно потом заработало с mysql.
Комментарии (42)

bormanman
06.02.2022 00:33+1Сериалы на скрине как на подбор -- аж олдскулы сводит. Я уж и забыл, когда их смотрел :).

aik Автор
06.02.2022 00:49Что есть. Я сериалы вообще не особо люблю, потому современное вообще не смотрю, а старое откапываю иногда, когда ностальгия нападает на тему «вот в детстве смотрел».
Есть ещё всякого старья, но оно большей частью так валяется, за пределами плекса. Может сейчас хоть руки дойдут проиндексировать.

asolokha
06.02.2022 01:33+1А вы уверены что использование ФС xfs и btrfs - хороший выбор? Сам автор btrfs вроде засомневался в надежности, по крайне мере аналога raid5 - точно

gecube
06.02.2022 02:18А вы уверены что использование ФС xfs и btrfs - хороший выбор?
а что лучше - ext4fs? Отрицая - предлагай. Вообще с xfs опыт на серверах позитивный. С btrfs - на серверах не гонял, скорее zfs. Но вроде бы должна была уже стабилизироваться.

Alexsey
06.02.2022 02:46https://btrfs.wiki.kernel.org/index.php/Status
RAID5/6 все еще unstable, по performance все еще есть вопросы. В общем лучше уж сразу ZFS.
gecube
06.02.2022 03:21а как насчет варианта btrfs + mdadm или это масло масляное?
В общем лучше уж сразу ZFS.
наверное (развожу руками).
Alexsey
06.02.2022 04:23а как насчет варианта btrfs + mdadm или это масло масляное?
Ну, я бы не стал такие выстрелы в ногу делать на каких-то важных данных. Если что-то пойдет не так то проще будет все снести, чем пытаться разрулить кто виноват и почему.
Опять же возникает вопрос как будет себя вести copy-on-write файловая система в связке с mdadm в плане производительности, я таких экспериментов не проводил. От checksumming/auto-repair тоже толку не будет, ну скажет он что данные битые, а не битой то копии в данной ситуации нет.
aik Автор
06.02.2022 07:55xfs — дубовая ОС времён чуть ли не ext2, если в ней какие-то баги и были, они давно уже сдохли от старости. И умолчальная ОС для массива именно она.
А btfs тут (по-умолчанию) используется только для кэширующих дисков, причём из её фишек только возможность создать зеркало применяется.
Так что если есть какие-то проблемы с raid5, то здесь их возникать не должно.asolokha
07.02.2022 23:08+2К сожалению на reddit'е неоднократно всплывали мольбы о помощи после проблем с btrfs и даже не в raid5 в основном массе после перевода Synology на эту ФС
xfs - субъективно, мне не нравится. Особых преимуществ перед ext4 нет и да я консерватор-пессимист все что связано с хранением данных. Для сервера с таким объемом хранилища и разнотипными дисками возможно имело бы смысл разбивать их на разделы по 900гб и из них собирать массив ZFS. Так делала к примеру Synology до DSM6 точно, сейчас не знаю
По поводу вашего выбора софта - не соглашусь, но предложить вам особо нечего, так как все возможные варианты вы отмели как неугодные, а что больше всего удивило - интерфейс не радует.
В своем опыте "домашнего серверостроения" перебрал очень много вариантов и не всегда последовательно:
HP Microserver Gen7 (hyper-v, xensever, omv4(5), proxmox, freenas, esxi)
DELL T20 (proxmox, truenas, hyper-v)
Самосбор на базе node 604, xeon-2136 (6 core) (truenas)
Массивы обычно до 6 дисков и максимум 20Тб и всегда память ТОЛЬКО ECC
Самое неприятное ощущение оставила hyper-v, максимальный позитив от решения в связке на хосте proxmox+omv (zfs), была очень хорошая статья на хабре
Финальный вариант - k3s в oracle cloud free tier и перешитый wd my cloud home под debian11 &OMV6 (для бекапов и автоматизации облака oracle)
В столе лежат 4 диска по 4tb - зачем они мне пока не решил, но собирать еще раз домашнюю хранилку не буду, тем самым избавил себя от синдрома Плюшкина.
Для лабы теперь только облака, фото и видео не болею, варез давно наскучил и пиратским софтом не пользуюсь из принципа.
aik Автор
08.02.2022 09:12мольбы о помощи после проблем с btrfs
Думаю, что потому её и не используют в основном массиве. А на дисках кэша к сохранности информации отношение проще. Можно так же reiserfs использовать, если вы любитель этого дела.xfs — субъективно, мне не нравится. Особых преимуществ перед ext4 нет
Да и не должно быть, всё же xfs постарше будет. Это у ext4 преимущества могут быть перед xfs.озможно имело бы смысл разбивать их на разделы по 900гб и из них собирать массив ZFS.
Ещё больше танцев с бубном при ещё меньшей возможности восстановить данные, если вдруг диски лететь начнут. zfs — это не панацея и нет смысла пытаться её присобачить к любой задаче.интерфейс не радует.
Мне этим регулярно пользоваться, так что интерфейс должен радовать. Ну или, как минимум, не огорчать. Я могу на работе пользоваться неудобным инструментом — потому что у него какие-то другие достоинства есть с точки зрения бизнеса, но для себя я имею возможность выбирать то, что мне удобно.память ТОЛЬКО ECC
По-моему, важность ЕСС тоже переоценена. Да, конечно, лучше, когда оно есть. Но снабжать ЕСС только сервер при том, что все клиенты работают с обычной памятью, да и надёжность каналов тоже может быть под вопросом, при этом мастер-копия рабочих данных хранится на клиенте… Смысла не вижу особого. Вот если данные с сервера не уходят или на рабочих станциях тоже о ЕСС позаботились — тогда да. Иначе же лучше будет взять больший объём памяти, к примеру.gecube
08.02.2022 09:44+1Вот если данные с сервера не уходят
проблемы надо предупреждать, а не бороться с ними
По-моему, важность ЕСС тоже переоценена
отчасти - да. С другой стороны, есть же ситуации, когда биты в памяти флипаются, тем более под большой нагрузкой. Для хранилки достаточно высокие требования к надежности, в отличии от бытового ПК. Любая ошибка в кэше в памяти, учитывая DMA и прочие оптимизации... и у нас будет фарш, а не данные. Причем вне зависимости от ФС.

khajiit
08.02.2022 09:51+1Но снабжать ЕСС только сервер при том, что все клиенты работают с обычной памятью, да и надёжность каналов тоже может быть под вопросом, при этом мастер-копия рабочих данных хранится на клиенте…
В памяти сервера информация может храниться до ребута: тот же кэш метаданных. Иногда это годы, в то время как на клиенте после совершения работы закешированный блок с высокой вероятностью будет вымыт.
Матожидание повреждения данных в ОЗУ на клиенте, соответственно, на порядки ниже.Разными видами контроля ошибок снабжено буквально все: процессорные кэши, PCIE, SATA, Ethernet PHY, USB 3+.
Кроме ОЗУ клиента и мелких одноразовых буферов пересылки.ZFS, кроме всего прочего, не просто пишет чексуммы. Она их еще и сверяет. При каждом чтении. Для метаданных и данных пользователя.
Учитывая, что современный десктопный накопитель нельзя прочитать без ошибок (BER не позволяет) — это крайне важная функция, если вы дорожите своими данными.asolokha
08.02.2022 11:49Добавлю. Как мне объяснял как-то корифей по Unix, который собирал хранилки для банков на zfs. Самое главное для zfs - достоверность метаданных в памяти, которая как раз обеспечивается ECC, иначе каша чанков гарантирована.
aik Автор
08.02.2022 12:03Каша на zfs гарантирована даже в том случае, если ЕСС-память стоит, но вы не гоняете регулярную проверку контрольных сумм. Тут недавно одни хипстеры попали на это — не настроили scrub по расписанию при сборке массива. И через год, когда заметили, что у них из разных vdev по паре дисков пропало, zfs не смогла сделать ребилд.
Хотя это был raidz2 и потерю двух дисков она должна была переносить нормально.khajiit
08.02.2022 12:19А вот это, как раз, bitrot.
Не смогла, скорее всего, потому что те два диска просто отвалились раньше, а гнили все одновременно.aik Автор
08.02.2022 12:50У них там на сотни миллионов ошибок счёт шёл. Я сомневаюсь, что там всё настолько прогнило — это либо железо у них совсем кривое должно было быть, либо zfs настолько плохая файловая система, что без пересчёта контрольных сумм за год данные протухают.
Скорее, наложились друг на друга отсутствие проверок и отвал двух дисков. И испортились именно контрольные суммы, а не сами данные.khajiit
08.02.2022 13:17Контрольные суммы — это тоже данные, они принципиально от содержимого файла не отличаются. Scrub не пересчитывает записанные суммы, он их сверяет, так же, как и обычное чтение. только скраб делается для всех данных вообще, а не только для горячих.
К отвалу что-то должно было привести. Сами по себе диски не отваливаются, тем более пачками. Если парни поставили диски из одной партии (на практике мало кто заморачивается настолько, чтобы ставить диски разных партий или даже производителей — работало же раньше), то становится неудивительным групповой отказ. И очень вероятным то, что диски дохлые были все, изначально. Брак партии.
UPD: в принципе, не только брак: нестабильность питания, кривой шлейф, неисправный HBA…
Просто некоторые сдохли раньше.И в таких условиях никакой массив не обеспечит надежности при вменяемой избыточности.
aik Автор
08.02.2022 13:34Учитывая то, что у них там был массив из сотни дисков примерно, брать диски из разных партий было бы очень сложно. Физически у них сдохло вроде два диска, а остальные просто из массива вылетели, аппаратно же нормальные были.
А так вообще ребята те ещё любители ходить по граблям. Это сейчас у них архивный сервер посыпался, а несколько лет назад боевой развалился — «мы разобрали старый сервер бэкапов, собрали новый, начали заливать на него бэкап — и у нас сдох один из рейд-контроллеров на боевом сервере, а потом ещё и материнка добавила».
khajiit
08.02.2022 12:04+1Справедливости ради, это касается любой ФС, но в случае zfs мы имеем еще и огромный ARC, который не управляется ядром (в Linux) — и большую вероятность ошибок.
aik Автор
08.02.2022 11:59Если бы всё было настолько страшно, то поддержка ЕСС давно была бы везде, во всех файловых системах и в любых процессорах.
Да, я не отрицаю, что такие проблемы могут возникнуть. Но вероятность не настолько велика, чтобы вкладываться в их решение вотпрямощаз. Да, со временем я планирую поставить ЕСС — когда память расширять буду. Но сегодня у меня выбор либо 32 гига обычной памяти, либо 16 ЕСС — и тут я выберу 32 гигабайта.khajiit
08.02.2022 12:17+1В процессорах и так L1/L2 со времен 462 сокета с ECC. Профессиональные видеокарты с ECC. DDR-5 обещали сделать с обязательным ECC. То есть, буквально все железо уже давно может быть с ECC, просто в консьюмерском сегменте это не так остро-актуально, так пока работает принцип неуловимого Джо.
Разумеется, флипнувшийся бит с хранилки наверняка придется на пользовательские данные — их тупо больше. Вероятность того, что ошибка придется на суперблок еще кратно ниже.
Но, собственно, именно потому что легаси-фс не обеспечивают контроль целостности, те же БД тащат его с собой.Но если вы забэкапите ошибку в данных пользователя, не говоря уже о метаданных, — вам легче не станет. А обнаружить ее вы сумеете только когда попробуете восстановиться… вы же проверяете бэкапы?

Goron_Dekar
06.02.2022 07:53А что получилось по производительности? Я вот очень сильно затыкаюсь в производительность samba-шары. Жена льёт равы сразу на сервер и оттуда обрабатывает, а это требует высокой скорости. И иногда приходится отключать qbittorent (хотя он и имеет nice 15 ionice idle) потому, что тот вызывает фризы в потоке. Коммуникация, очевидно, медный гигабит.
aik Автор
06.02.2022 08:06Сеть, конечно, является потенциально узким местом, но это не проблема unraid'a как такового. Тут больше вопрос организации процесса работы, чем технических ограничений.
Лично мне для комфортной работы с равами в лайтруме гигабита было мало (у меня тяжелые задачи — это массовая обработка), потому файлы у меня хранятся локально на десктопе, а на сервере только копия.

haga777
06.02.2022 08:40Можете посоветовать?
Я поставил на слабый ПК q9400, ssd 128, ОЗУ 4гб. Убунту,.только ради того, чтобы печатать на канон 810. Есть готовый скрипт по установке cup's на этот принтер ,но только убунту.
Есть ли возможность, установить в убунту или вообще отельный НАС поставить с поддержкой печати?
Или настроить убунту как нас?
aik Автор
06.02.2022 08:43Обычная методика — поднимается виртуальная машина с нужной ОС и туда пробрасывается устройство. Я подобное делал с virtualbox'ом, но не вижу каких-то причин, по которым бы подобное нельзя было сделать в любой другой виртуалке, которая позволяет проброс usb.
Если же у вас готовая убунта уже есть и ничего трогать не хочется, то, думаю, можно на неё сверху поставить какой-нибудь cockpit и делать вид, что у вас готовый NAS.haga777
06.02.2022 08:47Устанавливал на Винду вм варе 16, ставил убунту. После установки окно маленькое и вм тулс не устанавливается. Хотя до установки окно полного формата.
Решить проблему не смог в итоге.
aik Автор
06.02.2022 09:03Так сложно что-то диагностировать, но, обычно, когда guest tools не ставятся, то просто что-то делается не так. Они в линуксе из консоли ставятся, плюс, насколько помню, подкачивать ещё что-то хотят, типа компилятора.

winwood
06.02.2022 13:34Надо ставить dkms для сборки модулей ядра этих самых guet-tools, остальное он сам подтянет.

Gordon01
06.02.2022 13:43Спасибо за статью, тоже давно пользуюсь unraid, но узнал много нового и полезного!
Я тоже статью писал) https://habr.com/ru/post/478924/

VlaKor
06.02.2022 15:27-1Всё равно не понимаю зачем это всё нужно для дома? Какая практическая цель?
Сериалы можно и так посмотреть. В чём смысл? Сервер ради сервера?
aik Автор
06.02.2022 16:10+1Сериалы — это не основное. Основное — это то, что сервер — свой, а не дядин.
И меня на этом сервере не забанят, никакие сервисы не перестанут поддерживать, а тарифы на обслуживание только от меня зависят.

werter78
06.02.2022 19:04Спасибо.
Но Openmediavault (OMV) хватает для всего. Открыто, удобно, умеет в zfs, soft raid, docker. Умеет и жить на флешке.
Хочется энтерпрайза без денег? Truenas Scale вам подойдет.
Надо что-то проще? Filebrowser, filestash, sftpgo в помощь.aik Автор
06.02.2022 20:37Но Openmediavault (OMV) хватает для всего.
Как уже писал в предыдущих частях — как-то оно мне не очень в последних версиях. Совсем отказываться не планирую, но для дома хотелось чего-то более удобного.умеет в zfs, soft raid, docker
Из этого два первых пункта мне не интересны, но в zfs умеет и unraid при сильном на то желании, есть плагин. Подозреваю, что и из коробки могут как-нибудь добавить, юзеры нередко просят.Truenas Scale вам подойдет.
Мне он пока что кажется чистым NAS-решением. Впрочем, я его гоняю на таком калькуляторе, который и с zfs с трудом справляется, так что про дополнительные возможности ничего сказать не могу.

ForestQ
07.02.2022 10:36Urbackup - зачёт! Такого простого и интуитивно понятного решения еще не видел. И главное, что работает, поставил и на работе и дома.
gecube
круто! но было бы круто рассказать, зачем нужен UNRAID, я так навскидку не особо понял.
aik Автор
Про это было во второй части. Тащить ещё и сюда… Ну, кратенькое описание можно сделать.
PS. Добавил абзац в начале.
Ki10V01T
Лучше сделать ссылки на предыдущие части в начале статьи.
aik Автор
Они до ката есть, а выше картинки поднимать не хочу.