Введение
Многие datascientists, желающие использовать ML на финансовых рынках, прочитали толстые книжки об инвестировании, может даже создавали модели с учетом прочитанного. И наверняка знают как правильно оценить полученные модели с точки зрения ML. Разобраться с этим необходимо, чтобы не было мучительно больно, когда прекрасная модель на бумаге, превращается в генератор убытков при практическом использовании. Однако оценка эффективности модели ML на бирже, довольно специфическая область, тонкости которой раскрываются только когда вы погружаетесь в процесс. Под процессом я понимаю трейдинг с частотой совершения сделок гораздо чаще "пара сделок в месяц, в течении полугода". Существует множество подводных камней, о наличии которых вы даже не подозреваете, пока смотрите на трейдинг извне. Я попробую вольно изложить свои мысли на данную тему, я покажу метрики, условно разбив их на 3 группы и обьясню их смысл, покажу свои любимые и о чем нужно подумать, если вы хотите практически использовать модели, а не повесить их на стеночку в красивой рамочке. Представлю метрики в табличном и графическом виде, показав их взаимосвязь. Сравню показатели моделей в виде "какую модель выбираю я" и "что выбираете вы" и кто тут больше ошибается. Для любителей кодов, приведу реализацию всего подсчитанного, так что можно сразу применить прочитанное для оценки своих моделей. Я не буду тут говорить о борьбе с переобучением или регуляризации или стратегиях кросвалидации - оставлю это на потом. Здесь мы начинаем со списка уже спрогнозированных сделок, с помощью transformer о которой я писал в прошлой статье. Поэтому данный текст будет его логическим продолжением, где я оценю модель с точки зрения ее практического использования.
1. Раздел где я собрал все оценки моделей на бирже и разбил их на 3 группы.
Существует несколько способов оценки эффективности модели, которые можно условно разбить по степени вовлеченности в реальный трейдинг. Не очень вовлеченные часто останавливаются на первом уровне, это метрики ML, в частности для задачи классификации это будет accuraсy и ее производные. Прямо скажем эти показатели далеки от того что действительно интересует людей которые приходят на биржу. Там знаете ли, всех интересует финансовый результат. Языком ML это можно назвать бизнес метрикой - то что мы получим при использовании модели в денежном выражении. Я мало смотрю на показатели типа accuracy, сразу конвертируя прогнозы в финансовый результат, а если datascientist демонстрирует accursay, roc-auc итд, но упорно отказывается продемонстрировать сколько можно было бы заработать используя модель, то скорей всего это говорит, о сомнительном финрезультате или о недопонимании для чего все это нужно. Или например приводят фактический и спрогнозированный график цен и умиляются их близостью, хотя все что модель делает - прогнозирует на завтра сегодняшнюю цену. Такая вот хорошечность. Такой подлог даже вооружившись лупой можно не разглядеть, а с приведенным финансовым результатом все сразу становится на свои места. Даже если вы не шарлатан от машинного обучение, и все посчитали корректно, показатели ML не говорит практически ни о чем. Например будет ли прибыльной модель угадывающая 80% движений на тик или минуту вперед? Нет, потому что за тик или минуту, цена просто не проходит такое расстояние чтобы покрыть комиссию и проскальзывание.
Говоря о "бизнес метриках" надо понимать, что уже существует широкий набор показателей, продемонстрировавшие свою эффективность при выборе алгоритмических моделей. И нейронщикам ничего придумывать не нужно, просто берем заботливо создано задолго до нас. Если говорить о концепции лежащей в основе, то многие из них вертятся вокруг идеи измерения соотношения риск-доход, чем меньший риск Y мы принимаем для того чтобы получить доход X - тем лучше. Тут же рядом как феникс появляются "безрисковый доход", "дисконтирование", "будущая стоимость", "корреляция активов", "портфельное инвестирование" и другие понятия из экономтеории. На этих идеях построены классические модели инвестирования, разной сомнительности, за которые тем не менее были получены Нобелевские премии. При этом допустимое соотношение риск-доходность это выбор каждого человека, но имея для каждой модели такое вот соотношение их можно сравнивать между собой, приведя к одному основанию и говорить что модель 1 позволяет получить прибыль больше чем модель 2 при одинаковом уровне рисков.
Так вот, показателей из разряда бизнес - метрик (которые я условно причислю к второй группе показателей) очень много: Sharp Ratio, Profit Factor, Recovery Factor, Payoff Ratio, Maximum Drawdown %, Max Consecutive Losses (Winners), Average Time Held, Loss Rate, Win Rate, Average Profit (Loss), Exposure, Net Profit, Profit Distribution. Казалось, зачем так много показателей, если можно например взять число сделок, умножить на среднюю прибыльность сделки и получить Net Profit - то куда мы придем используя модель. На самом деле все не так, двигаться из А в сторону Б можно очень по разному, на пути может существовать точка невозврата С, попав в которую до никакого Б мы уже не дойдем. Например в силу катастрофических просадках по счету, достигающих более 50% по счету. Это простая арифметика - если вы упали от локального максимума по своему счету на - 50%, то чтобы вернуться к достигнутому максимуму вам понадобиться сделать уже не +50%, а +100%, и я не говорю о более сильных просадках, которые уж точно являются точками невозврата. Точка невозврата может быть связанна с таким психологическим состоянием трейдера, которое никак не совместимо с трейдингом. По показателю Net Profit мы это никогда не увидим, тут надо считать все эти показатели, либо строить кривую изменения вашего счета по времени - Equity. Правильно сгенерированная Equity дает исчерпывающий ответ о эффективности вашей модели, а весь тот большой набор данных, который я привел выше, описывает разные аспекты этой кривой. Еще один вариант, это взять наши сделки и сгенерировать много выборок меняя очередность сделок, а затем посчитать долю случаев в которых неблагоприятный период в виде подряд шедших убыточных сделок настолько затянулся, что привел к попаданию в точку невозврата, когда до хорошей серии сделок мы уже не доживем. Говоря языком матстатистики - выдвигаем гипотезу H0, альтернативную, выбираем уровень значимости, строим статистику на основе верности гипотезы H0 и принимаем или отвергаем ее. И тут опять может так получиться что вполне пристойные модели с точки зрения Net Profit, с точки зрения матстатистики окажутся не хороши, например модели с небольшим числом сделок. И тут мы переходим к третьей группе показателей эффективности модели.
Третья группа, под некоторые можно подвести теорию, некоторые проистекают из здравого смысла, из моего опыта, а некоторые не имеют ни одного ни второго ни третьего, но они соответствуют моему психотипу. Под последним можно понимать, порог чувствительности при просадках, готовность сидеть весь день за компьютером, отслеживая ситуацию, приемлемое для вас соотношение риск-доходность, частота прибыльных сделок итп итд. Модель может быть эффективной по бизнес-метрикам, но вы не сможете ее торговать, потому что она для вас некомфортна. Например мне не комфортно торговать модели, которые каждый год надо полностью переучивать, или модели типа "ловля ножей". Эти никак не оценить ни метриками ML, ни "бизнес метриками", ни строя кривые equity, это из другой оперы. Вот есть модель, а есть трейдер ее использующий и эффективность будет зависеть и от модели и от того кто ее использует и если модель не является продолжением трейдера - вы используете чужую модель, или сомневаетесь в ней, то ничего хорошего может не получиться, хотя по отдельности все вроде бы и хорошо. Некоторые пытаются обходить этот момент, самоустраняясь, перепоручая все роботу. Такая обезличенность в некотором смысле оправданна. Я могу привести множество примеров когда успешная или неуспешная сделка накануне, подсознательно влияла на принятие решения о следующей сделке. Поэтому я старательно пытаюсь стирать из памяти (и фигурально и фактически) все прошлые сделки.
Или например добавлю немножко "кота Шредингера". Это о вашем влияние на рынок. Частично именно этим можно обьяснить почему на тесте и при использовании модели, ваши результаты разьезжаются. И влияние этого фактора тем больше чем большее влияние вы оказываете на котировку акции своими сделками. Вы получили модель тестируя ее на торгах где вас не было - одна реальность, когда вы начинаете торговать, вы изменяете действительность. Если совершая сделку, вы двигаете цену на десятые доли процента, то поздравляю - вы манипулятор. Опять же это не история о абсолютном зле, экономика это вообще не история о каких то предельных понятиях, это история о балансе (баланс между инфляцией и экономическим ростом). Двигая рынок, вы вполне можете оказаться тем камушком который опрокинет рынок в нужную вам сторону, или не в нужную. Направление этого влияния мы скорей всего никак не замерим, зато можем оценить "ликвидную емкость модели" (термин самопридуманный), который позволяет оценить эффективность модели с условием что мы не меняем реальность. Это критерий эффективности модели из здравого смысла, который многие начинают учитывать только когда визуально наблюдают как не могут набрать позицию одним кликом.
2. Раздел, вывод которого о Equity как исчерпывающе характеризующим эффективность системы.
Давайте начнем оценивать transformer, начнем с бизнес-метрик, но сначала о данных. Обучив несколько вариантов transformer, я прогнал их на новых данных, получив поток сделок, к которым добавил столбец с прогнозом роста, от каждой модели, в виде вероятности. В итоге имеем pandas dataframe, со следующими столбцами: ['Date', 'Symbol', 'profit_label', 'profit', forecast_model1, forecast_model2, ... forecast_modelN']. Теперь надо разобраться что нам делать сразу с несколькими прогнозами. В моих функциях реализовано несколько стратегий стакинга (по максимальной уверенности среди всех моделей, по средней уверенности, по минимальной, по числу голосов с каким то порогом уверенности). Разница в результатах не принципиальная, но чтобы не путаться, все последующие результаты взяты из правила - "покупаем если по акции сработал сигнал с уверенностью выше 0,6, от более чем 1 модели".
Самый простой вариант финансового результата, это Net Profit с разбивкой по количеству сделок и средним профитом на сделку, и в группировке по годам.

Однако не все так просто. Мы ведь торгуем не в сферическом вакууме, у нас есть обьективные ограничения в виде размера счета (с учетом маржинальной позиции), мы не можем одновременно на каждую сделку выделить 100% возможных средств. Приведу предельный пример несуразицы, после которого станет все понятно. Допустим у вас есть модель которая генерирует 40 сигналов в год и каждая сделка приносит в среднем по 1%. А теперь представим что все сигналы по этой модели срабатывают одновременно. И теперь вместо модели которая генерирует 40% годовых, мы становимся гордыми обладателями модели которая генерирует 1% годовых. То есть мы говорим о перекрещивание сделок. Я изобразил это на рисунке, не то чтобы без него было непонятно, но рисунки разнообразят текст да и может здесь кроме любителей читать есть любители рассматривать картинки. На картинке ниже, в формате "каракули" я изобразил 7 сигналов : 1 и 2, 3 и 4, 5 и 6 - сигналы появились одновременно, причем 1, 3 и 4 сигналы, по отношению к сигналам 2, 4 и 5, приоритетные, то есть по ним модель более уверенна. Время удержания позиции - длина черты.

Пусть первая сделка принесла +1%, а каждая следующая на 1% больше (то есть номер сигнала совпадает с прибыльностью сделки), вопрос сколько мы заработали в % к нашему счету (без реинвестирования)? Если сигналы появились одновременно, то мы должны выбрать какую то одну или взять все, но прибыль считать как взвешенную по доле участия капиталом в каждой сделке. Пока мы не выйдем из предыдущей сделки, высвободив кэш, в новую не входим. Если входим равными долями, тогда получается 3 сделки (все сделки совершенные в одно время я буду считать одной сделкой): (0,5%+1%) + (2,5%+3%) + (3,5%). А если например мы входим на 100%, по самому перспективному сигналу, тогда 3 сделки: 1%+3%+5%. А если например степень уверенности конвертировать в долю участия по этому сигналу, то третий вариант, А если например учитывать ликвидность, то четвертый вариант, я его рассмотрю ниже. Варианты разные и каждый раз мы будем получать разные итоги. А если вообще не думать, то получится 7 сделок 1+2+3+4+5+6+7.

Мы не думать не будем, поэтому подкорректируем результат, случай когда берем среднюю по сделкам - размазываем капитал по акция в равных долях:
И результат когда входим на 100% входим в сделку с наивысшим приоритетом:

Убрав эффект перекрещивающихся сделок, видим что эффективность модели упала - число сделок уменьшилось и средняя прибыльность снизилась, но не катастрофически. Кодик для подсчета Net Profit в данном виде:
def trade_list(df_data_conect, for_treshold, treshold, mean__, count_tresh, time_time4_dtime, time_list, name_profit):
print(f'Profit: {name_profit}, Feature: {for_treshold}')
if mean__ == 'mean':
mean__1 = df_data_conect[for_treshold].mean(axis = 1)
elif mean__ == 'max':
mean__1 = df_data_conect[for_treshold].max(axis = 1)
elif mean__ == 'min':
mean__1 = df_data_conect[for_treshold].min(axis = 1)
elif mean__ == 'count':
mean__1 = (df_data_conect[for_treshold] > count_tresh).sum(axis = 1)
df_data_conect.Date = pd.to_datetime(df_data_conect.Date)
df_data_conect['mean__'] = np.array(mean__1)
pivo_lon1 = pd.pivot_table(df_data_conect[df_data_conect['mean__'] >= treshold],
index = [df_data_conect.Date.dt.date, 'Symbol'],
values = ['mean__', name_profit],
).T.drop_duplicates().T
pivo_lon1.reset_index(inplace=True)
pivo_lon1 = pivo_lon1.sort_values(['Date', 'mean__'], ascending = [True, False], ignore_index=True)
pivo_lon1['Date'] = pd.to_datetime(pivo_lon1['Date'])
pivo_lon1['long1'] = np.where(pivo_lon1['Date'].shift(0) != pivo_lon1['Date'].shift(1), 1, 0)
print('all_trades')
all_trades = pd.pivot_table(pivo_lon1,
index = pivo_lon1['Date'].dt.year,
values = [name_profit],
aggfunc = ['count', 'mean'],
margins = True
)
all_trades.columns = ['count_trades', 'profit%_per_trade']
display(all_trades)
print('long1')
only_long1 = pivo_lon1[pivo_lon1['long1'] == 1]
temp = pd.pivot_table(only_long1,
index = pivo_lon1['Date'].dt.year,
values = [name_profit],
aggfunc = ['count', 'mean'],
margins = True
)
temp.columns = ['count_day', 'profit%_day']
display(temp)
# Mean_day
only_mean = df_data_conect[(mean__1 >= treshold)]
pivo_long = pd.pivot_table(only_mean,
index = [df_data_conect.Date.dt.date],
values = [name_profit],
aggfunc = ['mean', 'count'],
margins = True
).T.drop_duplicates().T
pivo_long.reset_index(inplace = True)
pivo_long.columns = ['Date', 'mean', 'count']
pivo_long = pivo_long.iloc[:-1,:]
pivo_long['Date'] = pd.to_datetime(pivo_long['Date'])
print('mean')
mean_profit = (pd.pivot_table(pivo_long,
index = pivo_long.Date.dt.year,
values = 'mean',
aggfunc = ['count', 'mean'],
margins = True
))
mean_profit.columns = ['count_day', 'profit%_day']
display(mean_profit)
# List_trades and mean_day
print('List_trades')
pivo_long = pd.pivot_table(df_data_conect[df_data_conect['mean__'] >= treshold],
index = [df_data_conect.Date.dt.date, 'Symbol'],
values = [name_profit, 'mean__', 'Volume_mean_10bars'],
aggfunc = ['mean'],
margins = True
).T.drop_duplicates().T
pivo_long.columns = pivo_long.columns.get_level_values(1)
pivo_long.reset_index(inplace = True)
pivo_long.sort_values(by = ['Date', 'mean__'], ascending = [True, False], inplace = True)
display(pivo_long.tail(29))
return only_long1, only_meanВ аргументах функции trade_list мы имеем возможность выбрать стратегию стакинга, после чего получаем все указанные выше таблички. Нужно сказать что в случаи c transformer код очень сильно упрощен, достаточно все отсортировать по времени и применить много, много pd.pivot_table, так как для данного transformer время входа и выхода из позиции унифицирован. Если это не выполняется, то тут уже необходимо пробегаться в цикле по всем сделкам, расставляя флаги 0 (нет позиций), 1 (вход в позицию), 2 (удержание позиции), 3 (выход из позиции), и исходя их этого считать Net Profit, по крайней мере так поступал я.
Насколько перекрещивание сделок распространенно и насколько сильно учет их может ухудшить показатели модели?! Скажем так, в моей практике было несколько случаев когда я находил алгоритмы, которые а из разряда "перспективных" превращались в "неинтересные". Конечно пытливый ум человека сразу предлагал другой вариант - "если модель особо прибыльна когда по ней одновременно проходят сигналы по многим акциям, и таких случаев 10-12 раз а год, то может стоит глянуть что происходит на рынке после этого в среднесрочной перспективе?". Могу привести самый свежий пример по одному алгоритму, сигналы по которому я не использую, в силу большого числа перекрещивания. 18 января сего года по нему сработал сигнал сразу по 18 акциям. Смотрим на индекс МосБиржи и видим что это был локальное дно, после которого рынок перестал падать. 23 декабря прошлого года по этому алгоритму сработал сигнал сразу по 13 акциям. Смотрим на график индекса и видим - в следующие полторы недели рынок довольно активно рос. Отматываем историю дальше и опять видим такие случаи. Я такое не торгую, так как мало случаев, но может кому то идею подкину.
Eсли вы пользуетесь Take Profit, Stop Loss, может возникнуть следующий момент который может исказить эффективность вашей модели. В коде вы можете поставить приоритет Take Profit, но никакого приоритета он не имеет, приоритет имеет первое произошедшее по времени. Работая с баром, вы не знаете что первым наступит - первое или второе, а это большая разница когда вы выходите по Take Profit или закрываетесь по Stop Loss. Чем на большем таймфрейме вы тестируете систему, и чем меньше у вас разница между stop и take, тем больше вероятность попасть в ситуацию когда на одном баре происходит касание и линии take profit и линии stop loss. На рисунке я справа изобразил котировку в дневном представлении, а слева в 15 минутном

На левом баре мы не понимаем что сработало первым, на правом графике все понятно. Конечно и 15 минутного таймфремя может не хватить, абсолютное спасение это смотреть тики, но это какой то запредельный случай. Для моей модели это не актуально, но тем кто использует близкие стопы, стоит обратить внимание. То же самое касается цены открытия дня. Если кто то считает по ней входы-выходы, то он оперирует мифом, "цена открытия" это нечто иллюзорное, лучше вместо нее брать цену после 1 минуты торгов. Ну это так, к слову.
Следующие показатели мы будем рассматривать вместе с equity, по принципу "единство и борьба противоположностей". Как я уже писал, все бизнес метрики являются всего лишь табличным представлением особенностей кривой equity. Рассмотрев все вместе, мы лучше сможем понять что к чему и зачем. Многие сравнивают кривые equity с индексами, я от этого также не удержусь. Логика простая - существует класс участников биржи, которые называют себя гордым словом "инвесторы", они читают советы Уоррена Баффета и прочих гуру. Находятся в поиске "мало рискованных, стабильных, растущих компаний". Одним словом занимаются ерундой. Немножко поумнев, они бросают бесплодные занятие найти то чего нет и просто покупают какой то индекс, в расчете на общий рост рынка, и они правы, инфляция знаете ли. И сравнение equity какой то модели с индексом, это такое противопоставление активного и пассивного трейдинга (buy and hold). И если ваш активный трейдинг не позволяет опередить пассивный, если прибыль по нему меньше чем по пассивному, если просадки по нему глубже чем по пассивному, то к чему это вся суета с беготней по рынку?! Чтобы накормить комиссией брокера?! С другой стороны, есть момент некорректности в таком подходе, например если трейдер играет исключительно в шорт (такая у него специализация), то как сравнивать его результаты с buy and hold?! Ведь при buy and hold торговле вы получаете прибыль когда рынок растет, а по шортовой, чем глубже рынок падает, тем удачней вы реализуете шортовые стратегии. Или даже если не шортовые стратегии, а самые что ни на есть длинные. Кто сказал что найденные вами лонговые паттерны лучше всего отработают при бурно растущем рынке?! В общем есть тут обманка, натягивание совы на глобус, поэтому я уже давно не оцениваю свои модели сравнивая их с пассивным инвестированием, я оцениваю их с точки зрения собственных критериев, например возможности получения стабильно 50% в год при заданном уровне риска. Поэтому я буду наносить на один график equity и индекс IMOEX чтобы был понятен масштаб. Есть небольшой вопрос - как считать equity: с реинвестированием или без. Отсутствие реинвестирования здорово искажает результаты, однако с реинвестированием, кривая индекса растворяется где то внизу и наглядность теряется. Промежуточный вариант - с реинвестированием, но входим только на 50% от капитала:

Кусок кода, если кому хочетя проверить логику расчета:
from_year = 2012
comission = 0.1/100
share = 0.5
for i in range(len(equity)):
if i == 0:
equity[i] = 100 + share*100*(profit_hour_np_1[i]/100 - comission)
equity_reinvest[i] = 100 + share*100*(profit_hour_np_1[i]/100 - comission)
capital_year[i] = 100
equity_reinvest_year[i] = capital_year[i]*(1 + profit_hour_np_1[i]/100 - comission)
else:
equity[i] = equity[i-1] + 100*(profit_hour_np_1[i]/100 - comission)
equity_reinvest[i] = equity_reinvest[i-1] + share*equity_reinvest[i-1]*(profit_hour_np_1[i]/100 - comission)
if date_for_plot[i] == date_for_plot[i-1]:
capital_year[i] = capital_year[i-1]
equity_reinvest_year[i] = equity_reinvest_year[i-1] + capital_year[i]*(profit_hour_np_1[i]/100 - comission)
else:
per_last_year = (pivo_for_plot[pivo_for_plot.Date.dt.year == date_for_plot[i-1]][[enter_mean]].sum() - pivo_for_plot[pivo_for_plot.Date.dt.year == date_for_plot[i-1]][[enter_mean]].count()*comission)
capital_year[i] = capital_year[i-1]*(1 + per_last_year/100)
equity_reinvest_year[i] = equity_reinvest_year[i-1] + capital_year[i]*(profit_hour_np_1[i]/100 - comission)
А теперь попробуем на этих графиках обозначить табличные данные. Number of bars since last Equity High (число баров с последнего обновленного максимума equity). Очень полезный показатель характеризующий способность вашей модели стабильно приносить прибыль. Черными линиями указал некоторые наиболее длительные промежутки, когда роста счета не было.

А вот на кривой equity мы обозначаем наиболее крупные показатель Maximum Drawdown %: Находим локальный максимум и считаем в процентах откат до локального минимума.
Конечно нас интересует не выборочно самые большие значения, а некая динамика, поэтому разнесем показатели по шкале времени, для обоих графиков:

По нижнему графику мы можем видеть как купив индекс ММВБ в январе 2020 года мы могли получить просадку по счету в размере -45%. По второму снизу, как купив индекс в 2012 году, нам бы пришлось ждать долгих 500 дней (3 года) пока наконец то не была бы получена первая прибыль. Верхние два демонстрируют что риски по transformer в разы ниже, а стабильность в получении прибыли в разы выше. Фрагмент кода для расчета этих показателей:
for i in range(len(equity_max)):
if i == 0:
equity_max[i] = equity_from_plot[i]
else:
equity_max[i] = (equity_from_plot[:i+1]).max()
for_plot['equity_max'] = equity_max
ddown_bar = []
for i in range(len(for_plot)):
if i == 0:
k = 0
elif equity_max[i] == equity_max[i - 1]:
k += 1
else:
k = 1
ddown_bar.append(k)
for_plot['Number_bar'] = ddown_bar
for_plot['DrawDown_%'] = (for_plot['equity_max'] / equity_from_plot - 1) * 100Показатели соединяющие прибыль и риск: Recovery Factor - отношение прибыли в течении какого то временного промежутка к максимальной просадке и Profit Factor - рассчитывается как валовая прибыль, деленная на валовой убыток, таким образом, мы получаем число, которое показывает нашу прибыль, рассчитанную на единицу риска.

На графике с equity берем какой то интервал времени, например год, и делим годовую прибыль (зеленый столбик) на максимальную просадку (красный столбик).
То есть что такое Maximum Drawdown? Это показатель максимальных потер которые вы понесете если войдете в рынок в какой то промежуток времени (в данном случаи в 2015 году). В чем логика? Логика в том что мы не знаем в какое время мы попадем на рынок, поэтому берем самый неблагоприятный вариант. Если бы берем рынок с 2008 года, то Maximum Drawdown для пассивной торговли будет где то под -80%, именно столько бы вы потеряли если вас угораздило купить индекс летом 2008 года. Так что если у вас что то чешется глядя на биржевые индексы, выросшие на 50 - 100% за год, не забывайте и про год когда все упадет на 80%, а он неминуем, это только вопрос времени. Поэтому тем "математикам", которые строят оптимистические кривые роста, показывая как начав даже с небольшой суммы и даже имея всего 20% годовых, благодаря сложным процентом, вы неминуемо разбогатеете через каких то 20-25 лет, хочу напомнить, что по мере роста длины цепочки, вероятность получить год когда все рухнет, похоронив вашу цепочку - равна 100%. И про небольшой баг в расчете Maximum Drawdown - правильно было бы посчитать показатель с учетом просадок во время удержания позиции, в моем случаи я этот момент игнорирую.
Откуда взялись показатели сопоставляющие потери с прибылью, я уже писал, теперь напишу практическую ценность. Представим у вас есть две equity, разбив их по годам, мы получили средние по годам Net Profit 60% и 30% со средним Maximum Drawdown в 30% и 10% соответственно. Мы можем привести эти торговые системы в соответствие, перенормировав одну к другой, чтобы их максимальные просадки стали одинаковыми (или приравняв прибыли), после чего окажется что 2 модель эффективней. И это не только теория, мы это можем реализовать на практике воспользовавшись возможностями маржинальной торговли. Используя леверидж, мы можем реализовать модель с хорошим Recovery Factor или Profit Factor, пусть и небольшим Net Profit.
И в завершении раздела, некоторые показатели для Transformer и Buy and Hold:
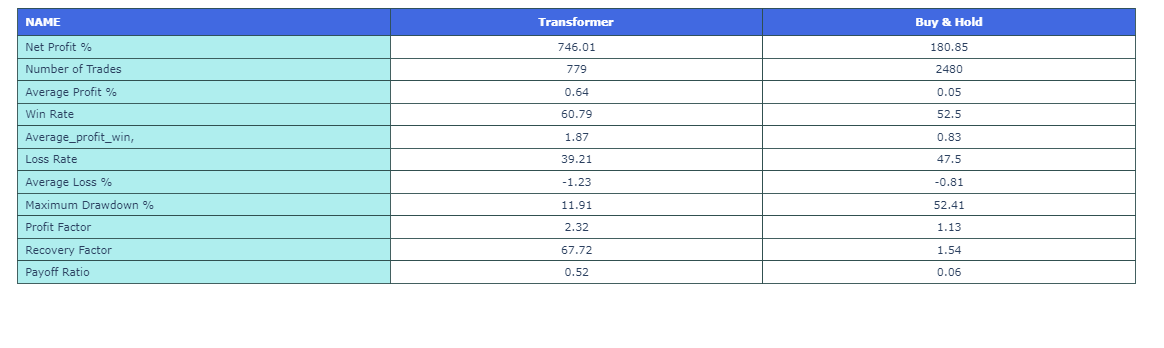
import plotly.graph_objects as go
def table_culc(equity_reinvest, only_long1, for_plot):
NetProfit = round(100*(equity_reinvest[-1]/equity_reinvest[0] - 1), 2)
NumberofTrade = len(only_long1)
win_rate = round(np.where(only_long1 >= 0, 1, 0).mean()*100,2)
loss_rate = round(100 - win_rate, 2)
Profit_trade = round(only_long1.mean(), 2)
Average_profit = round(only_long1.mean(), 2)
Average_profit_win = round(only_long1[only_long1 > 0].mean(), 2)
Average_loss = round(only_long1[only_long1 <= 0].mean(), 2)
profit_factor = (only_long1[only_long1 > 0].sum()/-only_long1[only_long1 <= 0].sum()).round(2)
MMd = round(for_plot['DrawDown_%'].max(), 2)
Recovery_factor = round((NetProfit / 100 - 1) * 100 / MMd, 2)
Payoff_ratio = round(Average_profit/-Average_loss, 2)
return [NetProfit, NumberofTrade, Average_profit, win_rate, Average_profit_win, loss_rate, Average_loss, MMd, profit_factor, \
Recovery_factor, Payoff_ratio]
date_tr = [NetProfit, NumberofTrade, Average_profit, win_rate, Average_profit_win, loss_rate, Average_loss, MMd, profit_factor, \
Recovery_factor, Payoff_ratio]
values = [['Net Profit %', 'Number of Trades', 'Average Profit %', 'Win Rate', 'Average_profit_win', 'Loss Rate', 'Average Loss %', 'Maximum Drawdown %','Profit Factor', \
'Recovery Factor', 'Payoff Ratio'],
date_tr, date_bh]
fig = go.Figure(data=[go.Table(
columnorder = [1,2,3],
columnwidth = [5,5],
header = dict(
values = [['<b>NAME</b>'],
['<b>Transformer</b>'], ['<b>Buy & Hold</b>']],
line_color='darkslategray',
fill_color='royalblue',
align=['left','center'],
font=dict(color='white', size=12),
height=10
),
cells=dict(
values=values,
line_color='darkslategray',
fill=dict(color=['paleturquoise', 'white']),
align=['left', 'center'],
font_size=12,
height=25)
)
])
fig.show()3. Неочевидные, но полезные показатели
Наконец показатели из третьей группы. Для меня одним из таких показателем является число сделок. Это можно увидеть на equity - если у вас сделок мало и большую часть времени вы находитесь вне рынка, то и кривая у вас будет со многими горизонтальными линиями. Для меня алгоритм генерирующий пару десятков сделок в год, это весьма сомнительное предприятие. Слов нет, по мере роста эффективности рынка, число сделок может уменьшится. Это не вопрос что за паттерном с небольшим числом реализаций ничего не стоит, вопрос в невозможности при небольшом числе сделок как то адекватно оценить практическую полезность алгоритма. Поэтому тестируя паттерн я всегда смотрю на число сделок, их не должно быть меньше 50-100 случаев за год. Обоснование можно найти в матстатистике. Допустим у нас есть фактическая вероятность, которую мы не знаем, но видим ее реализацию в виде выборки - наших сигналах. Это можно сгенерировать с помощью Монте-Карло, а можно воспользоваться формулой Бернулли для биноминального распределения. Чем длиннее выборка, тем "стройней" наша плотность распределения, тем меньше "случайности в случайности". Поэтому вероятность P(получить набор из 200 примеров с accuracy|при истинной вероятности 0,5) << P(получить набор из 50 примеров с accuracy|при какой то истинной вероятности 0.5). Можно высказаться еще проще - подкидывая монетку сериями много, много раз (описываем процесс поиска алгоритма, настраивания модели итп), вероятность получить 70% орлов при подкидывании монетки выше при меньшей длине серий. Мы начинаем сильней играть в рандом, получая более случайную оценку нашего истинного распределения, и это обязательно вылезет со временем. Обычно это не заставляет себя ждать, и как только вы выходите со своим паттерном с небольшим числом сделок в реальный трейдинг, вас сразу наказывают. Равномерность результата по акциям. Это дискуссионное, так как многие строят модели отдельно для каждой акции, и я никак не обсуждаю, не критикую, не осуждаю, но сам предпочитаю чтобы была стабильность в разрезе акций.

Таким образом я борюсь с рандомом и тешу себя надеждой что нахожу более стабильные паттерны, которые будут существовать дольше, так как любой занимающийся алготрейдингом знает что найти работающий паттерн это четверть дела, еще половина дела найти паттерн который будет работать в какой то среднесрочной перспективе, и еще четверть дела вовремя соскочить когда неэффективность начинает исчезать. У меня есть несколько моделей, которые я не использую в виду большого влияния на результат, 3-4 фишек. Например на какой то Мечел приходится 15% сделок, а средняя прибыльность по нему в разы превосходила среднюю прибыльность по всем остальным акциям. Наверно можно было стать "специалистом по Мечелу" и торговать его, раз его движения так хорошо ловятся моделями, но я пас. Стабильность по годам (кварталам, месяцам), конечно чем меньше интервал тем лучше, но как минимум я буду добиваться положительного результата в разрезе годов. Если вы тестируете модель и видите что она из года в год (а лучше из месяц в месяц генерирует прибыль) то прекрасно. По ровности роста equity вы это сразу увидите или на графике "время в днях с последнего максимума". Почему это так важно? Ну вот представим перенеслись вы в 20.. год, тот самый, в который ваша, в целом прибыльная модель, стояла на месте. Допустим в этот самый год вы взяли кредит, чтобы большей суммой торговать, сосед вам дал денег, крупная компания в вас поверила итп итд. И по прошествии этого года возникает вопрос - что вы будете говорить заинтересованным людям, как будете возвращать кредит и какое будет ваше психологическое состояние после целого года стояния счета на одном месте? А потеряв психическую уверенность вы можете следующий год вообще не торговать, пропустив удачный 20..+1 год. А такое случается постоянно, ведь на рынке никто никому ничего не обещал и важно сохранить уверенность, поэтому для меня, модель которая регулярно, год от года (а еще лучше от месяца к месяцу) генерирует прибыль, пусть в среднем даже меньшую чем другая система, но по принципу "то густо то пусто", обладает большей привлекательностью. Торгующие, отлично понимают этот момент, для не торгующих это может показаться чем то абстрактным, ненужным, неважным...до момента пока они сами не начнут торговать. "Ликвидная емкость модели" не имеет значения, если вы мелкий трейдер. Во всех остальных случаях может возникнуть проблема: вы или просто не сможете сформировать нужную вам позицию, либо понесете дополнительные расходы которые связанные с проскальзыванием, которые мы можем выразить в процентах. Если при нехватке ликвидности вы формируете позицию увеличивая проскальзывание, то полбеды что надо как то учесть это при оценке эффективности модели, надо еще держать в голове кота Шредингера - ведь вы двигая цену своими заявками меняете реальность. Поэтому я выберу другой вариант оценки ликвидной эффективности модели, гораздо более жесткий - мы будем набирать позицию до тех пор пока остаемся "невидимыми" - как только новый лот потребует двигать цену, мы прекращаем формировать позицию. От чего будет зависеть "ликвидная емкость модели"? От доли ликвидных бумаг, количества акций по которому будет срабатывать сигнал на покупку, так же он будет зависеть от времени срабатывания сигнала, так как в первый и последний час торгов ликвидность максимальна, в разы превосходя ликвидность в обеденное время. В идеальном случаи лучше оперировать реальными лотами, которые стояли в стакане на момент сделки. Таких данных нет, в их отсутствии, мы воспользуемся проторгованными оборотами накануне, как некое отражение возможности остаться незаметным. Давайте посмотрим как будет уменьшаться прибыльность системы при увеличении размера счета, с этим условием. Осталось только придумать реализацию. У меня она выглядит следующим образом. Допустим в момент t сработал сигнал на покупку k бумаг. Мы начинаем формировать позицию начиная с ценной бумаги в которой модель наиболее уверенна, в размере не более 0,5% от оборота по этой акции за последние 10 часов (цифра в 0,5% дискуссионная, видел например цифру в 0,3%, но так как сделки совершаются в наиболее ликвидную часть торгов, округлим до этой цифры). Если позиция не сформирована в желаемом размере (100% от свободных денежных средств), спускаемся к следующему сигналу итд итп.
def liq(pivo, init_count):
data_for_liq = pivo.iloc[:-1,:].copy()
data_for_liq['Date'] = pd.to_datetime(data_for_liq['Date'])
shape_ = data_for_liq.shape[0]
Signal_liquidity = np.array(data_for_liq['Volume_mean_10bars']*10*0.5/100)
Day = np.array(data_for_liq['Date'].dt.date)
Profit = np.array(data_for_liq['profit_1hour'])
Cash_flow = np.zeros(shape=shape_)
Entry_eqiuty = np.zeros(shape=shape_)
Profit_toEquity = np.zeros(shape=shape_)
Profit_toEquity_sum = np.zeros(shape=shape_)
Equity = np.zeros(shape=shape_)
for i in range(data_for_liq.shape[0]):
if i == 0:
Cash_flow[i] = init_count
Entry_eqiuty[i] = min(Signal_liquidity[i], Cash_flow[i])
Profit_toEquity[i] = Profit[i] * Entry_eqiuty[i]/init_count
Profit_toEquity_sum[i] = Profit_toEquity[i]
else:
if Day[i] == Day[i-1]:
Cash_flow[i] = Cash_flow[i-1] - Entry_eqiuty[i-1]
Entry_eqiuty[i] = min(Signal_liquidity[i], Cash_flow[i])
Profit_toEquity[i] = Profit[i] * Entry_eqiuty[i]/init_count
Profit_toEquity_sum[i] = Profit_toEquity_sum[i-1] + Profit_toEquity[i]
else:
Cash_flow[i] = init_count
Entry_eqiuty[i] = min(Signal_liquidity[i], Cash_flow[i])
Profit_toEquity[i] = Profit[i] * Entry_eqiuty[i]/init_count
Profit_toEquity_sum[i] = Profit_toEquity[i]
names = ['Cash_flow', 'Entry_eqiuty', 'Profit_toEquity', 'Profit_toEquity_sum', 'Signal_liquidity', 'Equity']
arrays_ = [Cash_flow, Entry_eqiuty, Profit_toEquity, Profit_toEquity_sum, Signal_liquidity, Equity]
for name, array in zip(names, arrays_):
data_for_liq[str(name)] = array
data_for_liq = data_for_liq[data_for_liq['Cash_flow'] != 0]
data_for_liq.drop_duplicates(subset=['Date'], keep = 'last', inplace = True)
return data_for_liq Данная функция позволяет построить кривую эффективности системы в зависимости от размера счета при условии "невидимости". Меняется число сделок, средняя прибыль на сделку, а в итоге кривая equity. Все предыдущие результаты шли с фильтром по обьему в 400 млн рублей за последние 10 часов, то есть все прежние результаты были справедливы для размера счета до 2*400*0,5/100 = 4 млн рублей, ну и учетом курса 10 лет назад и сейчас средневзвешенную можно принять за 7-8 млн..

Для разных размеров счета получились следующие кривые:
Что они показывают? Они показывают накопленные проценты прибыли при предельном размере счета, то есть если вы начали с 10 миллионов, то чтобы сохраниться на красной кривой вам нужно все прибыль свыше 10 млн выводить со счета, иначе придется опуститься на более низкую кривую. В лоб это использовать нельзя, но если у вас несколько моделей, то сопоставив их графики вы можете сделать вывод что одна модель более зависима от ликвидности, а другая менее.
Бонус.
Бонусом для моих читателей (как оказалось у меня уже появляются постоянные читатели, для которых я становлюсь источником некоторых оригинальных идей) напишу как я представляю процесс ценообразования на фондовых рынках. Недавно у меня была беседа в ходе которой был задан такой вопрос. Подозреваю мой ответ был несколько сумбурен, я начал приводить какие то аналогии с машиной, сейчас на спокойную голову я готов пофилософствовать на эту тему более подробно, на том же примере. Мы все знаем что существуют новости, на которые реагируют цены, есть реальная экономика, есть противоположно направленная денежно-кредитная политика центральных банков и министерств финансов (развития), есть люди которые приходят на фондовый рынок, причем с разными целями. Кто то покупает акции в целях извлечения прибыли, кто то выступает в качестве стратегических инвесторов. Для последних, прибыль не является целью, они будут держать акции даже при уверенности в падающих ценах. Ведь обладание акциями дает право голосовать на собраниях акционеров, и какие-нибудь условные немцы будут держать акции какого то условного Газпрома, в каком-нибудь условном 2008 году, потому что это необходимо для их геоэкономических стратегий по обеспечению национальной безопасности. Есть биржа - финансовый институт, который исполняет функцию перераспределения ресурсов, дублируя коммерческие банки, так по крайней мере нам рассказывали в финансовых Вузах. Есть страна где точно такое происходит - это США, где фондовый рынок действительно является, чем то большим чем в России, или любой другой стране мира, и изза истории и изза процента вовлеченных в торговлю населения, и изза активного перераспределения ресурсов. Я намешал все в кучу - новости, реальная экономика, биржа как институт, агенты действующие на рынке (причем у всех интересы разные), экономическая политика государства, регулирующие органы. Где тут причина, где следствие, как это все взаимодействует и где нужно искать прибыль? Представим машину - колеса эти котировки, двигатель это новости, и кабина, в которой сидит стратег. Стратег это тот кто и создает рынок своими решениями, в руках у него коробка передач, дергая рычаги он может подать движение двигателя на колеса или нет. А может подать, но в обратную сторону. А почему так может быть? Стратег точно также видит какую то неожиданную положительную новость, и при выходе ее у него возможность присоединиться к покупкам, но это затруднительно, потому что ему не хватит ликвидность, и тогда зачем ему вместе со всеми вставать в покупку чтобы по итоге набрать на 3% от своего капитала, задрав цену? Поэтому он может остаться в стороне, не подав движение от двигателя на колеса, а может подать реверсивно и рынок не вырастет, а упадет. Я уж не говорю о стратеге-инсайдере, который заранее знает о положительной новости и заранее был в рынке. На положительной новости он будет фиксировать свою прибыль, используя ту ликвидность которую создают мелкие игроки, пытающиеся отыграть положительную новость. Люди желающие торговать на новостях следят за двигателем, они оценивают его мощность, насколько он блестит, как там у него с маслицем и делают вывод что если двигатель в хорошем состоянии, то и колеса будут хорошо двигаться в нужную сторону. А для меня информативней подглядывать в кабину наблюдая за стратегом, потому что там принимается решение. Кроме того состояние двигателя знают все, а во вторых есть такое понятие подгонка решения под задачу - и торгующий на новостях задним числом всегда сможет подогнать под движение на рынке какую то новость, поэтому часто создается ложная иллюзия - "торговать на новостях можно, просто я неправильно проанализировал". Знающих какой то действительно важный инсайд очень мало, все остальные оперируют общедоступной информацией, а общедоступная информация не стоит ничего. А теперь по поводу стратега в кабине - нет никакого стратега, это упрощение, все мы сидим в этой кабине и все передаем движение двигателя на колеса. У кого то большой депозит у кого то маленький, у кого то один уровень страхов и притязаний, у кого то другой, и все слушают новости, перерабатывают их (или думают что перерабатывают), смотрят на котировки, и взаимодействуют друг с другом, с целью извлечения прибыли. Так что не сидит кабине какой то один большой манипулятор, который покручивает усик и думает как бы всех обмануть, все мы там сидим и все изменяем реальность своими действиями. И все наши желания, страхи, невежество перемешиваются и выливают в котировочки. Так что рынок это о теории игр.
Комментарии (4)

Maxx070707
18.02.2022 10:29Добрый день! Увидел в вышенаписанном себя) Только сам программы не писал, фрилансеров нанимал за 30$, время свое ценю. Правда, сейчас разочаровался в алготрейдинге, руками лучше получается, как ни странно. Мистика какая-то)
Предлагаю обменяться паттернами "редких ситуаций", как Вы их называете, где вероятность дальнейшего развития событий >0,5. Я их перелопатил гору и продолжаю этим заниматься, кое-где рыба вроде есть
StasTukalo
Спасибо за статью. Сейчас пойду искать вашу предыдущую.
Вот это очень странно. Переучивать раз в год? Я считаю, что в наш век наоборот нужно учить модели как можно чаще, чтобы учесть самые последние настроения рынка. Благо, для того чтобы поставить такое обучение "на поток" сейчас доступно абсолютно всё. Поэтому пусть переучиваются перманентно, с каким-то небольшим шагом по времени, привязанным даже не к рабочему таймфрейму, а исключительно к мощности ML-оборудования.
Интересно было бы узнать, почему вы не придерживаетесь такого мнения?
Успехов вам!
Marat1980 Автор
В данном случаи, я имел в виду, что если вы обучили модель, и без регулярного переобучения она показывает результат в последующие годы, это значит вы нейросеткой нашли более стабильный, долговечный паттерн.
StasTukalo
Ясно. Спасибо.