История Bash Today - сервиса бронирования площадок для мероприятий в Москве и Санкт-Петербурге , основанного в 2015 г.
Серьёзная проблема для сервиса бронирований — прямые платежи от клиентов площадкам по заявкам, пришедшим через маркетплейс. Из-за этого компания лишается своей комиссии. Стандартные инструменты выявления подобных схем, такие как опрос пользователей, сбор обратной связи после мероприятий и так далее, имеют ограниченную эффективность, так как осуществляются случайным образом. Поэтому нашей R&D-команде ¹ была поставлена задача повысить эффективность проверок с помощью алгоритмов AI. ²
Процесс разработки и внедрения осуществлялся по стандартной схеме CRISP-DM: ³

Разработанная модель анализирует весь доступный массив данных по заявкам клиентов и рассчитывает вероятность оплаты. Если при высокой вероятности заявка уходит в «отказ», то к процессу подключается операционная команда и проводит проверку. Результатом таких проверок может стать выявление недобросовестных партнёров, которые убеждают клиентов производить оплаты, минуя сервис.
Внедрение данного инструмента позволило существенно повысить эффективность проверок, что, в свою очередь, положительно сказалось на комиссионной выручке компании.
Введение
В этой статье мы хотим рассказать про наш опыт использования машинного обучения для выявления мошенничества с заявками со стороны площадок, размещающихся на сервисе «Bash Today». При подготовке материала мы старались не только поделиться непосредственно нашим опытом решения данной задачи, но и подробнее описать процесс построения алгоритмов машинного обучения на общем уровне, чтобы статья могла оказаться полезной не только специалистам в сфере AI, ² но и тем, кто прежде не сталкивался с подобными вещами.
Стоит оговориться, что первые подходы к решению этой задачи были предприняты ещё в начале 2020 г., однако в связи с приходом пандемии и введением запретов на проведение массовых мероприятий пришлось полностью свернуть работы по данному направлению. Вернуться к разработке модели мы смогли уже только в начале 2021 г., когда снова появились ресурсы и стало ясно, что нового локдауна не будет.
Проблема и постановка задачи
Перед тем, как приступить к построению любого алгоритма машинного обучения, необходимо чётко определить бизнес-задачи, которые требуется решить с его помощью. Обычно задачи продиктованы потребностью бизнеса в оптимизации и увеличении эффективности существующих процессов в компании, что, в конечном итоге, положительно сказывается на выручке предприятия.
Серьёзной проблемой для Bash Today является ситуация, когда площадка, получившая заявку на бронирование помещения через сервис, убеждает клиента провести платёж напрямую (заявка при этом недобросовестным менеджером площадки переводится в статус «отказ» или «не удалось дозвониться»). Подобная практика — нарушение договорных отношений между площадкой и сервисом, и, попросту говоря, является мошенничеством. Из-за этого компания теряет существенную часть выручки, которую могла бы направить на развитие продукта. Кроме того, в случае спорной ситуации или даже конфликта между клиентом и площадкой сервис уже никак не сможет помочь в урегулировании проблемы.
У Bash Today имеется много инструментов для выявления недобросовестных партнёров. Например:
опрос пользователей;
сбор обратной связи после мероприятий;
анализ конверсии из заявки в оплату в разрезе площадок;
и ряд других.
Однако, так как ресурсы операционной команды ограничены и все заявки проверить не представляется возможным в силу их количества, перед нами стояла задача сделать выбор заявок на проверку более «осознанным», учитывая всю совокупность имеющихся факторов.
Наиболее очевидным решением данной задачи было бы создание модели, оценивающей вероятность того, что заявка будет проведена мимо сервиса. Однако подобный подход требовал бы от нас наличия существенной выборки заявок, где было бы точно известно, какая заявка была закрыта «в отказ» по причине обмана площадки, а какая — из-за того, что просто не подошла клиенту. К сожалению, у нас не было такой выборки и собрать её не представлялось возможным, так как далеко не все случаи удаётся выявлять. Поэтому мы решили пойти другим путём, а именно: построить модель, оценивающую вероятность конверсии заявки в оплату, и проверять только те заявки, которые получили высокую оценку вероятности, но не были в итоге оплачены.
Спецификация модели
В машинном обучении существует два основных подхода к построению моделей — «обучение с учителем» и «обучение без учителя». В первом случае для настройки и обучения модели используется выборка с размеченными классами принадлежности объектов. Например, класс «0» — заявка не была оплачена, а класс «1» — заявка была оплачена. Модель пытается восстановить зависимость между набором различных признаков (например, тип мероприятия, время начала, продолжительность и так далее) и соответствующим классом.
Метод «обучение с учителем» является основным подходом для решения задач классификации объектов. В случае «обучения без учителя» алгоритм пытается самостоятельность сгруппировать объекты на основе их признаков. Основные задачи, решаемые подобным методом — кластеризация объектов и поиск аномалий. Так как наша задача — классифицировать приходящие заявки, нам понадобится размеченная выборка, где каждый объект (заявка) будет представлен набором признаков, характеризующих эту заявку, а также будет указан класс, к которому данная заявка относится («0» — не оплачена, «1» — оплачена).

Извлечение признаков
Набор признаков, описывающих целевые объекты, является специфичным для каждого конкретного бизнеса. Первичный отбор признаков для анализа производится на основе гипотезы, что между признаком и классом может существовать зависимость.
Для удобства мы выделили три группы признаков, которые, по нашей гипотезе, могут оказывать влияние на конверсию заявки:
Информация из заявки (расчётная стоимость аренды, дата мероприятия, способ оплаты, тип мероприятия и так далее), а также информация о пользователе, который оставил заявку (дата регистрации, сколько было оплаченных заявок раньше и пр.).
Информация, характеризующая площадку, на которую была оставлена заявка. Сюда относятся как описательные характеристики, например тип площадки, так и расчётные метрики вроде средней конверсии за прошедший период, среднего чека мероприятий, статистики работы со статусами и прочего.
Информация, характеризующая поведение пользователей на сайте до оставления заявки (число поисковых запросов в маркетплейсе, длительность сессий, точка входа на сайт и так далее).
Здесь стоит обратить внимание на такую важную проблему процесса извлечения признаков, как data leakage. ⁴ Под утечкой данных подразумевается попадание в данные информации «из будущего», то есть того, что не может быть известно модели на момент получения заявки для оценки. В нашем случае, так как мы планируем использовать модель для оценки вероятности конверсии новых заявок, нам важно не включить в признаки информацию, которая появляется уже после того, как была оставлена заявка, в том числе и признаки, которые характеризуют площадки. Например, если заявка была оставлена 2 дек, 20:00, все признаки, описывающие данную заявку, должны быть рассчитаны на основе информации, доступной строго до 2 дек, 20:00. В противном случае модель сможет настроиться на некорректно сформированные признаки и показать завышенные метрики качества.
Очистка и обработка данных
После извлечения сырых данных из базы следует этап их очистки и обработки. Это важнейший шаг, занимающий наибольшую часть времени процесса построения модели. Один из главных принципов машинного обучения — garbage in ∙ garbage out. ⁵ Суть этого принципа заключается в том, что, если подать в модель плохо подготовленные или нерелевантные признаки, результат скорее всего будет неудовлетворительным.
Чаще всего процесс очистки и обработки данных делится на следующие этапы:
Из сырых данных, извлечённых из базы, создаются признаки, которые будет удобно обрабатывать. К примеру, из даты начала мероприятия мы можем извлечь такие его признаки как месяц, день недели, вечернее ли оно и т. д. Также можно синтезировать признаки, комбинируя различным образом сырые данные. Простейший пример — расчёт длительности мероприятия путем вычисления разницы между временем окончания и временем начала мероприятия.
Далее идёт детальная проверка каждого признака: диапазон возможных значений, его распределение, связь с классами, correlation ⁶ с другими признаками и т. д. Этот этап также имеет очень важную побочную составляющую — выявление insights, ⁷ когда может быть найдена интересная зависимость между признаками и классами, о которой прежде не подозревали.
Получив глубокое понимание имеющегося набора данных, приступаем к очистке. Из данных убираются выбросы и аномалии, обрабатываются отсутствующие и корректируются ошибочные значения. Затем из данных удаляются незначимые признаки. Незначимым признак может оказаться в случае высокой корреляции с другими признаками, или если он принимает в подавляющем большинстве случаев одно и то же значение. Также, в случае если признаки принимают определенные значения сравнительно редко, имеет смысл провести обобщение принимаемых значений признака. К примеру, в Bash Today на основные типы мероприятий («День рождения», «Вечеринки» и так далее) приходится свыше 90 % заявок. Весь остальной длинный хвост возможных, но редко встречающихся, типов имеет смысл заменить одним общем значением «Прочие». Подобные манипуляции могут помочь повысить эффективность модели, однако здесь следует действовать аккуратно, осознавая специфику бизнеса, чтобы случайно не избавиться от действительно ценной информации.
Очистив данные, мы преобразуем их к машиночитаемому (числовому) виду. Признаки, принимающие конечный список определённых значений, вроде типа мероприятия, города или типа площадки, преобразуются в бинарные признаки. Например, из признака типа мероприятия создаются такие признаки, как «День рождения» (принимает значение «1» или «0»), «Вечеринка» (принимает значения «1» или «0») и так далее. Изначально числовые признаки, такие как сумма заявки или количество заявленных людей на мероприятии, масштабируются в определённый диапазон значений. На практике данный этап, как правило, выполняется с оглядкой на специфику выбранной модели. Например, алгоритмы на основе decision tree ⁸ не требуют обязательного масштабирования числовых признаков (хотя, если корректно подобрать методику масштабирования, то можно повысить эффективность модели и в этом случае).
Метрика качества
Прежде чем приступать непосредственно к выбору и настройке модели, необходимо определиться с измерителем ее эффективности — метрикой. Выбор метрики в первую очередь зависит от того, какая решается задача (классификация, регрессия, кластеризация и пр.), и от того, насколько сбалансированы классы в выборке.
Предположим, что у нас уже есть обученный классификатор, который оценивает вероятность конверсии заявки в оплату в диапазоне от 0 до 1. Также предположим, что мы определили порог разделения классов на уровне 0.5. Это означает, что если классификатор выдает значение 0.3, то данная заявка будет отнесена к классу 0, а если 0.7, то к классу 1. Применив наш классификатор к отложенной выборке, мы получим прогнозы классов заявок, на основе которых можно построить confusion matrix: ⁹
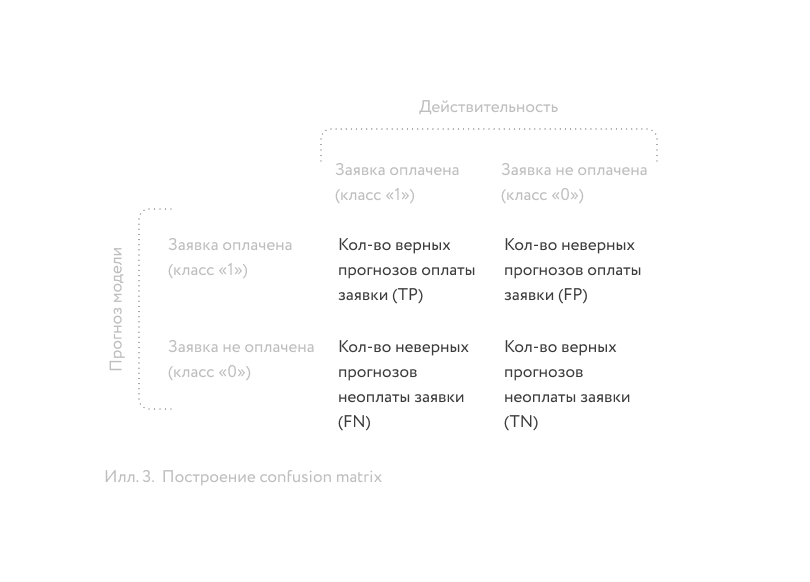
Confusion matrix ⁹ сопоставляет прогнозы модели (строки матрицы) с фактическими значениями классов (колонки матрицы), и на её основе можно рассчитывать различные метрики качества модели.
Наиболее простой и интуитивно понятной метрикой является accuracy, ¹⁰ которая рассчитывается как соотношение верных прогнозов к общему числу объектов и говорит нам о том, как часто классификатор прав. Формула расчёта в терминах confusion matrix ⁹ следующая:

Однако, данная метрика имеет очень серьёзный недостаток. Продемонстрировать его проще всего на примере. Предположим, что мы имеем очень несбалансированный набор данных, где 97 % выборки — класс «0», а оставшиеся 3 % — класс «1». Таким образом, если всегда предсказывать класс «0», не осуществляя никаких вычислений, то accuracy ¹⁰ такого «предсказателя» составит в точности 97 %. Так как в реальной жизни данные, как правило, не сбалансированы по классам, то на практике эта метрика редко используется в качестве целевой.
Для того чтобы обойти указанную проблему, обычно используют такие метрики как precision ¹¹ и recall. ¹²
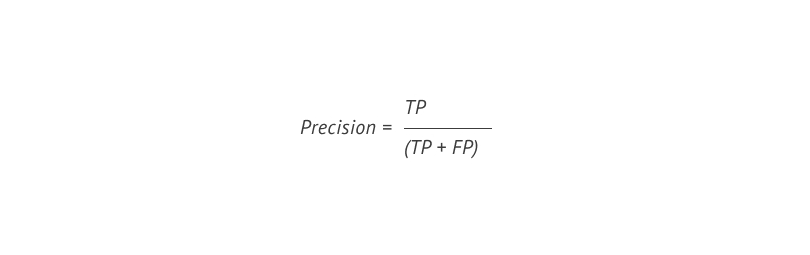
Precision ¹¹ показывает нам, как часто предсказание моделью класса «1» оказывается верным, и рассчитывается по следующей формуле:
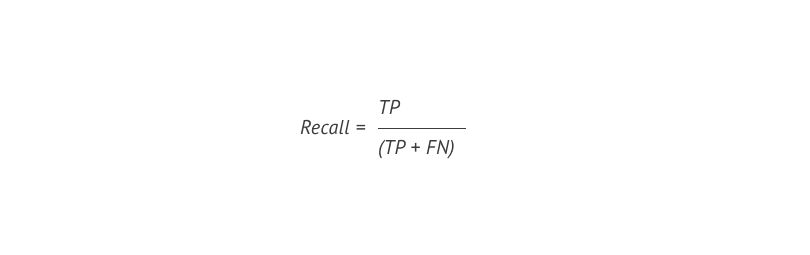
Recall, ¹² в свою очередь, показывает нам, как много классов «1» мы смогли определить из всей совокупности классов «1» в выборке, и рассчитывается по формуле:
Рассчитав вышеописанные метрики для примера с классификатором, который всегда предсказывает класс «0» на несбалансированном наборе данных, мы получим recall, ¹² равную нулю, а precision ¹¹ не сможем рассчитать вовсе из-за обращения знаменателя в ноль.
Что не менее важно, precision ¹¹ и recall ¹² позволяют настроить классификатор на минимизацию конкретного типа ошибки. В бизнесе, как правило, разные ошибки имеют разную значимость (или стоимость). В случае с классификацией заявок ошибка FP (false positive) (в статистике её называют ошибкой первого рода) показывает, сколько раз мы предсказали, что заявка будет оплачена, в то время как в действительности заявка оказалось не оплачена. Ошибка FN (false negative) (в статистике — ошибка второго рода) говорит нам о том, сколько заявок, которые реально были оплачены, мы не сумели определить с помощью модели. Так как мы хотим сфокусироваться только на тех заявках, по которым модель прогнозирует оплату с высокой уверенностью, и для нас не критично, если модель будет часто «пропускать» заявки, которые в итоге будут оплачены, нам необходимо минимизировать ошибку первого рода при допустимом уровне ошибки второго рода. Достигнуть этого можно путем выбора такого порога классификации (значение между «0» и «1»), при котором будет достигнута оптимальная precision ¹¹ при сохранении recall ¹² на приемлемом уровне.
Значения метрик precision ¹¹ и recall ¹² определяются конкретным пороговым значением, но на этапе выбора и настройки модели необходимо оценивать эффективность классификатора в целом для всех пороговых значений, что позволит сравнивать между собой разные модели. Наиболее популярной такой метрикой является ROC AUC, ¹³⁻¹⁴ которая принимает значение от 0.5 (бесполезная модель) до 1.0 (идеальная модель). Таким образом, сначала мы будем использовать в качестве целевой метрики ROC AUC, ¹³⁻¹⁴ улучшая эффективность модели в целом, а затем подберем порог классификации на основе precision ¹¹ и recall. ¹²
Выбор модели
Подготовив данные и определившись с метрикой, мы приступаем к выбору модели. В машинном обучении принято разделять линейные и нелинейные модели.
Первые отличаются высокой скоростью вычислений и возможностью эффективно обрабатывать огромное число признаков. Однако, как следует из их названия, они способны выявлять лишь простые линейные зависимости (хотя существуют различные подходы по модификации линейных алгоритмов с целью выявления более сложных зависимостей, например, с помощью добавления полиномов признаков, но не будем усложнять).
Нелинейные модели, в свою очередь, могут выявлять более сложные зависимости, но при этом они более требовательны к вычислительным мощностям, и необходимые для их эффективной работы ресурсы стремительно увеличиваются с ростом числа признаков в модели.
Мы протестировали различные модели без глубокой настройки, как линейные, так и нелинейные, в том числе нейронные сети. Наилучший результат показал алгоритм gradient boosting ¹⁵ с ROC AUC ¹³⁻¹⁴ 0.727, и это значение мы фиксируем в качестве отправной точки для настройки модели. Gradient boosting ¹⁵ представляет из себя последовательность из простых базовых алгоритмов (как правило, коротких decision trees ⁸), где каждый последующий алгоритм корректирует ошибку предыдущих вычислений. Данный метод является достаточно популярным инструментом машинного обучения в силу своей эффективности — он достаточно легко настраивается (по сравнению с теми же нейронными сетями), но при этом способен выявлять сложные нелинейные зависимости в данных. Кроме того, существует немало мощных реализаций алгоритма gradient boosting ¹⁵ с открытым исходным кодом, таких как «XG ∙ Boost», «Light ∙ GBM», «Catboost». Для реализации нашей модели мы решили остановиться на первом.
Настройка модели
Определившись с моделью, мы приступаем к её настройке. Обычно в моделях машинного обучения есть весá, которые настраиваются оптимизационными алгоритмами на данных, и hyperparameters ¹⁶ — параметры, которые необходимо настраивать путём подбора вручную.
Основными верхнеуровневыми hyperparameters ¹⁶ в gradient boosting ¹⁵ являются скорость обучения и количество базовых алгоритмов. На следующем уровне идут hyperparameters, ¹⁶ связанные с базовым алгоритмом (в случае с decision trees ⁸ это глубина дерева; параметры, связанные с разбивкой по ветвям и так далее).
Для того, чтобы настроить hyperparameters, ¹⁶ набор данных делится на тренировочную и тестовую выборку. Тестовая выборка откладывается до того, как все этапы по настройке модели будут завершены на тренировочных данных. Результаты метрик на тестовой выборке и будут показателем результативности нашей модели. Настройка модели на тренировочной выборке происходит с помощью метода cross-validation: ¹⁷
Данные делятся на определенное количество folds ¹⁸ c сохранениям баланса классов, как во всей выборке.
Затем поочередно каждая folds ¹⁸ становится тестовой, а остальная совокупность данных — обучающей. Модель обучается на обучающей части данных и тестируется на тестовой fold ¹⁸ с расчётом целевой метрики.
Рассчитав целевую метрику для каждой итерации, мы усредняем их значения для получения одной результирующей оценки.
Описанная схема проиллюстрирована ниже:

Подобный подход позволяет бороться с переобучением, когда модель «заучивает» конкретную fold ¹⁸ вместо того, чтобы выявить обобщающие зависимости, и показывает плохие результаты на тестовой выборке.
Прогоняя модель через перекрёстную проверку, на каждой итерации мы настраиваем hyperparameters¹⁶ модели, стараясь улучшить целевую метрику. Проведя настройку модели, нам удалось улучшить результат до 0.756 ROC AUC. ¹³⁻¹⁴
Выбор порога классификации
Теперь у нас имеется откалиброванная модель, оценивающая вероятность оплаты заявки. Далее необходимо выбрать порог классификации. Как уже было написано выше, для нас более важной является ошибка первого рода (если модель говорит, что заявка будет оплачена, у нее должны быть весомые основания для этого). Мы уже обсудили ранее метрики precision ¹¹ и recall, ¹² с помощью которых мы можем настроить модель на минимизацию конкретного вида ошибки, но хотелось бы свести две метрики в одну. Для этих целей часто используют F-score. ¹⁹
F-score ¹⁹ представляет собой гармоническое среднее precision ¹¹ и recall ¹² и принимает значение от 0 до 1. В базовой формуле расчета F-score ¹⁹ precision ¹¹ и recall ¹² имеют равный вес, однако можно придать им разные веса за счёт добавления коэффициента β. Итоговая формула выглядит следующим образом:
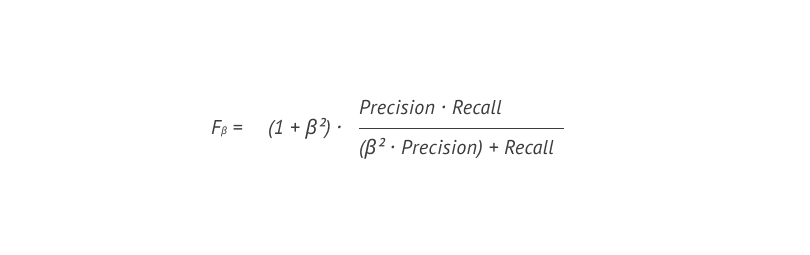
Мы задали коэффициент β равным 0.25, что снижает вес recall ¹² относительно веса precision. ¹¹ Рассчитав Fβ для разных величин порога, мы определили наиболее оптимальным значение на уровне 0.55. При таком пороге среднее значение F-score ¹⁹ на перекрёстной проверке составило 0.55 при precision ¹¹ 0.65 и recall ¹² 0.17.
Тестирование модели
Теперь у нас есть готовая модель, осталось протестировать её на тестовой выборке, предварительно обучив на всем имеющемся обучающем наборе данных. На тестовой выборке мы получили:

Результаты на тестовой выборке оказались схожи с тем, что было получено на обучающей выборке при перекрёстной проверке. Это говорит о том, что модель не переобучена и имеет прогнозную силу.
Послесловие
Несмотря на сильную зашумленность данных (у нас нет достоверной информации о всех заявках, которые были проведены мимо сервиса), мы в полной мере сумели решить поставленную перед нами задачу по выявлению заявок, требующих мониторинга и проверки. Построенная модель будет определять заявки, имеющие высокую вероятность оплаты, и в случае если такие заявки будут переводиться в статус «отказ», операционная команда будет проводить проверку таких заявок с целью выяснения причины отказа.
Приведём пример. Пришло 100 заявок, из которых классификатор прогнозирует 10 оплат (90 заявок были отнесены к классу «0» и 10 заявок к классу «1»). Опираясь на precision, ¹¹ которую показала модель на тестовой выборке, 7 заявок в итоге будут оплачены, а 3 по каким-то причинам окажутся в статусе «отказ» и будут подвергнуты проверке. Результатом таких проверок может стать выявление недобросовестных партнёров, которые убеждают клиентов производить оплаты, минуя сервис.
Мы ожидаем, что внедрение данного инструмента позволит существенно повысить эффективность проверок, что, в свою очередь, положительно скажется на комиссионной выручке сервиса благодаря очистке маркетплейса от площадок, не готовых работать честно.
Литературный список
¹ Research and development (R&D) — исследования и разработка
² Artificial intelligence (AI) — искусственный интеллект
³ Cross-industry standard process for data mining (CRISP-DM)
⁴ Data leakage — утечка данных
⁵ Garbage in ∙ garbage out — мусор в ∙ мусор из
⁶ Correlation — корреляция
⁷ Insight — инсайт
⁸ Decision tree — дерево решений
⁹ Confusion matrix — матрица ошибок
¹⁰ Accuracy — аккуратность
¹¹ Precision — точность
¹² Recall — полнота
¹³ Receiver operating characteristic (ROC)
¹⁴ Area under the curve (AUC)
¹⁵ Gradient boosting — градиентный бустинг
¹⁶ Hyperparameter — гиперпараметр
¹⁷ Cross-validation — перекрёстная проверка
¹⁸ Fold — подвыборка
¹⁹ F-score — F-мера
s_leleko
Спасибо за интересную статью. Есть вопрос - этап калибровки модели упущен?