В современной микросервисной разработке очень популярна чистая архитектура (она же луковая). Этот подход ясно отвечает на много архитектурных вопросов, а также хорошо подходит для сервисов с небольшой кодовой базой. Другая приятная особенность чистой архитектуры состоит в том, что она отлично сочетается с Domain Driven Development — они отлично дополняют друг друга.
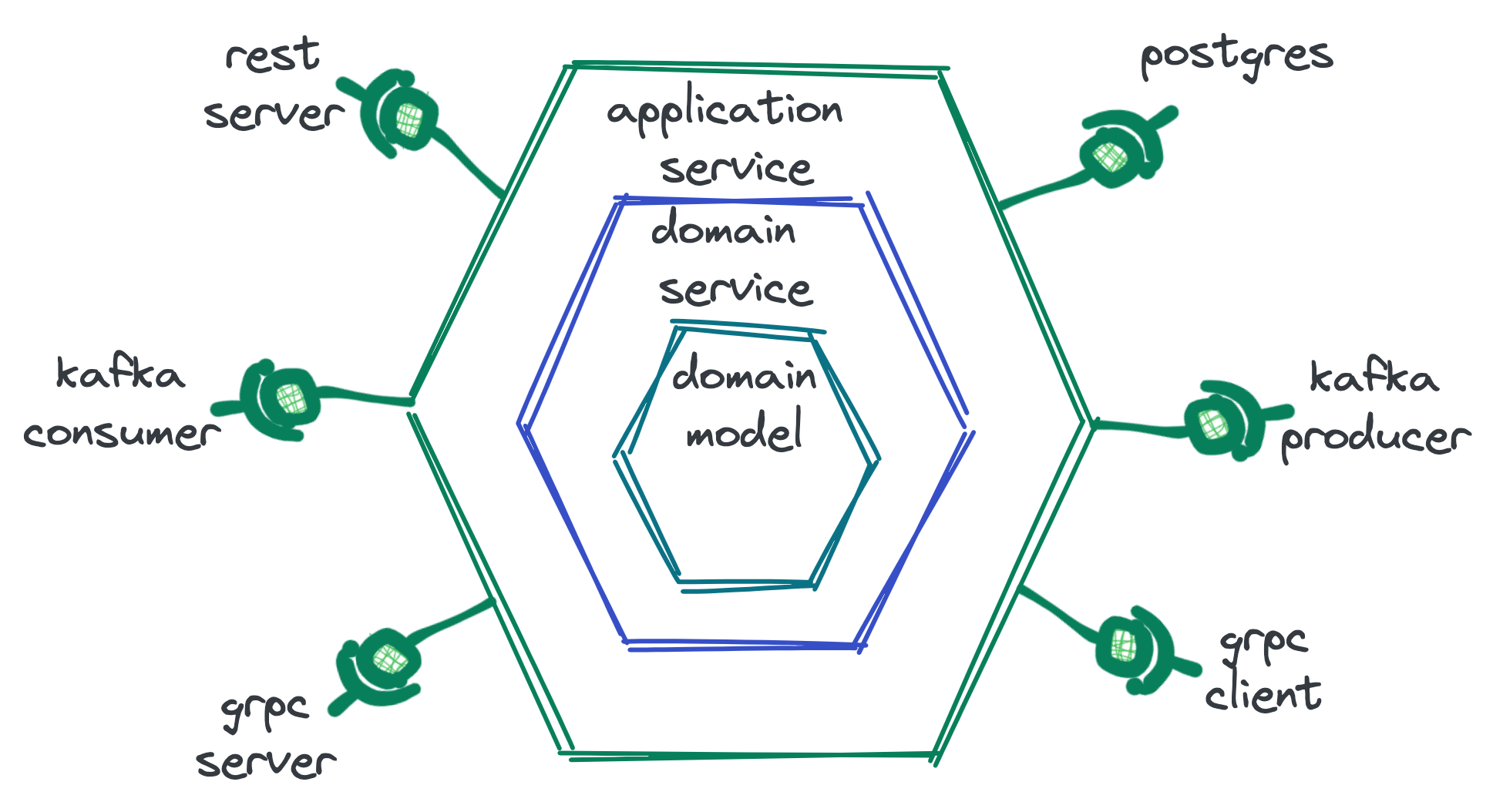
Одной из прикладных реализаций чистой архитектуры является гексагональная архитектура — подход, явно выделяющей слои, адаптеры и прочее. Данный подход заслуженно сыскал любовь среди разработчиков на Go — он не требует сложных абстракций или зубодробительных паттернов, а также почти ни в чем не противоречит сложной идиоматике языка — так называемому Go way.
Но есть проблема, которую я часто вижу во многих командах, адаптирующих гексагоны, и с которой я сам столкнулся и успешно решил — реализация транзакций базы данных в рамках DDD и пресловутого гексагона. Что у меня вышло я и расскажу в этой заметке.
Статья оригинально размещена в моем блоге.
Проблема высоких абстракций
Гексагональная архитектура предполагает инверсию зависимостей следующим образом: в центре всего находится модель данных, вокруг нее строится (и зависит от нее) доменная логика, на нее накладывается слой логики сервиса, а дальше идут адаптеры, скрытые за интерфейсами, называемыми портами. Это может варьироваться, но основная идея в том, что зависимости расходятся от центра к периферии, остается.
Для примера на минуточку представим, что мы делаем микросервис, реализующий продажу б/у автомобилей.
Представим, что одним из адаптеров является модуль взаимодействия с базой данных. Но не какой-нибудь случайной, а базой, поддерживающей ACID транзакции. Взаимодействие с базой с точки зрения кода реализовать довольно легко — оборачиваем доменные модели в репозитории, каждый репозиторий прячем за интерфейс (порт), а внутри адаптера его реализуем. Выглядеть такой порт может как-то так:
package port
import ...
// CarRepository car persistence repository
type CarRepository interface {
UpsertCar(ctx context.Context, car *model.Car) error
GetCar(ctx context.Context, id string) (*model.Car, error)
GetCarsBatch(ctx context.Context, ids []string) ([]model.Car, error)
GetCarsByTimePeriod(ctx context.Context, from, to time.Time) ([]model.Car, error)
GetCarsByModel(ctx context.Context, model string) ([]model.Car, error)
DeleteCar(ctx context.Context, id string) error
}Со стороны доменной логики этот адаптер будет передаваться как DI через интерфейс.
package domain
import ...
type Car struct {
carRepo port.CarRepository
}
func NewCar(carRepo port.CarRepository) &Car {
return &Car{
carRepo: carRepo,
}
}Для примера логика поиска авто по году выпуска будет такой.
func (c *Car) GetNewCars(ctx context.Context, from time.Time) ([]model.Car, error) {
if err := c.someValidation(); err := nil {
return nil, fmt.Errorf("invalid request: %v", err)
}
// read latest cars
cars, err := c.carRepo.GetCarsByTimePeriod(ctx, from, time.Now())
if err := nil {
return nil, fmt.Errorf("newest cars read: %v", err)
}
return c.filterCars(cars), nil
}Это довольно хорошо работает с простыми атомарными операциями, как создание, удаление или чтение. Но довольно часто возникает необходимость выполнить сложную логику в рамках одной транзакции БД. Я не буду расписывать примеры, вы и так их отлично знаете.
Проблема тут в том, что с точки зрения архитектуры транзакция является частью адаптера по работе с базой данных — она открывается и закрывается определенными командами (BEGIN, COMMIT или ROLLBACK в SQL), и имеет привязку к порожденной сущности — транзакции. Транзакция сама по себе обычно тоже не витает в облаках глобального скоупа программы, а явно привязана к сессии подключения к базе данных поверх TCP соединения. Поэтому мы не можем (да и не хотим) абстрактно объявить "начало транзакции" и "конец транзакции" в бизнесовом коде — внутри домена. При открытии транзакции у нас появляется некая сущность — транзакция — которую в дальнейшем нужно передать в адаптер для выполнения операций БД непосредственно в этой транзакции.
Здесь возникает проблема курицы и яйца. С одной стороны, адаптер требует, чтобы для каждого запроса в рамках транзакции была передана информация об этой самой транзакции — обычно используемая библиотека реализует транзакцию как некий объект, через который можно делать запросы. С другой стороны, слой домена или сервиса не может знать про реализацию адаптера в парадигме гексагона. Можно завернуть транзакцию в какой-нибудь интерфейс, этот интерфейс окажется монструозно огромным (с методами вроде Select, Insert, Delete и прочими — откройте любимую SQL библиотеку и посмотрите сколько там методов). Причем он не будет иметь никакого смысла для домена — эти методы будут использоваться внутри адаптера, где есть доступ к "незаабстракченой" транзакции.
Можно пойти иначе, и передать транзакцию как interface{}, а потом в адаптере через рефлексию привести к нужному типу, но я считаю такой подход несерьезным и негодным для продуктивного кода. Кроме того, очень не хочется замусоривать сигнатуру методов передачей дополнительно транзакции — ведь она не имеет прямого отношения к самому методу, а указывает на особенности всего процесса работы с бд в рамках операции. Что же делать?
Решение предметных реализаций
Теперь пару слов о контексте нашего решения. В поиске элегантной реализации я несколько раз сталкивался с решениями вроде UnitOfWork, представляющих транзакцию как некоторую бизнес-сущность (о которой знает ядро гексагона с бизнес-логикой). Действительно, транзакцию можно представить как некую бизнес-сущность — ведь бизнес логика может требовать атомарного и неконкурентного выполнения операции. Но проблема элегантных идей в неэлегантной реализации — абстрактные фабрики, рефлексия и некрасивая работа с методами самого адаптера.
Часто эти изощрения продиктованы желанием работать с несколькими базами данных, или иметь возможность переключаться с одной БД на другую, изменив лишь код адаптера (и не меняя бизнес логики).
Поняв, что это слишком "абстрактно", да и в целом не отвечает go way, я вывел несколько ограничений нашего проекта, которые должны были упростить эту задачу.
Сервис работает только с одной БД
И это PosgreSQL. Ну действительно, часто ли вы переключаетесь между БД? Многие стараются писать некий обобщенный код для работы с generic SQL базой данных, однако есть ли в этом смысл? Практика показывает, что переход с одной SQL базы данных на другую все равно заставит вас перелопатить весь проект, а про переход с SQL на NoSQL или наоборот даже говорить не приходится.
Мы используем конкретную библиотеку для работы с БД
И это go-pg. Лично мне она очень нравится, как билдер запросов (нежели как ORM), и отличается хорошей производительностью. У нее есть одна особенность, о которой я скажу дальше, без которой мне пришлось бы повозиться для реализации задуманного. Но такой функционал есть и в других библиотеках, так что не спешите переписывать свой код.
К чему пришли в итоге
Поэтому я с чистым сердцем взял за основу транзакции в go-pg. Мне хотелось с одной стороны оставить сигнатуры методов репозитория чистыми (только контекст и параметры вызова метода), но при этом сделать решение идиоматичным с точки зрения Go.
В го есть прекрасный инструмент, который позволяет передавать утилитарные данные, которые не касаются вызова конкретного метода, но касаются контекста операции — context.Context. Часто туда попадает телеметрия, логгеры, идентификаторы идемпотентности и прочее. С моей точки зрения информация о транзакции отлично подходит под определение "утилитарных данных" — это некий модификатор процесса, который не влияет на логику напрямую, но оказывает косвенное влияние. От слов — к делу!
package postgres
import ...
type txKey struct{}
// injectTx injects transaction to context
func injectTx(ctx context.Context, tx *pg.Tx) context.Context {
return context.WithValue(ctx, txKey{}, tx)
}
// extractTx extracts transaction from context
func extractTx(ctx context.Context) *pg.Tx {
if tx, ok := ctx.Value(txKey{}).(*pg.Tx); ok {
return tx
}
return nil
}Первый шаг — добавляем методы для добавления транзакции в контекст и извлечения транзакции из контекста. Методы неэкспортируемые, то есть вызывать их можно только внутри адаптера. Обратите внимание — здесь используется транзакция из пакета go-pg безо всяких оберток или абстракций. Можем себе позволить это внутри адаптера!
Далее, нам нужно научить сам адаптер (репозиторий) работать с транзакцией. И вот тут нам понадобится возможность, которая есть в go-pg, но нет в некоторых других библиотеках, например, в sqlx. Это — единый интерфейс для методов запросов, выполняемых библиотекой как в транзакции, так и без нее. Это Select, Insert, Delete и прочие — у них должна быть одинаковая сигнатура для транзакции и без, чтобы можно было вынести за интерфейс. Если нет — придется написать обертку. В случае go-pg и у объекта подключения к БД, и у транзакции есть метод ModelContext(c context.Context, model ...interface{}) *Query, который мы и использовали.
Получилась небольшая оберточка, которая проверяет, есть ли в контексте транзакция. Если есть — возвращает Query из транзакции, а если нет — возвращает Query из коннекта к БД.
package postgres
import ...
// model returns query model with context with or without transaction extracted from context
func (db *Database) model(ctx context.Context, model ...interface{}) *orm.Query {
tx := extractTx(ctx)
if tx != nil {
return tx.ModelContext(ctx, model...)
}
return db.conn.ModelContext(ctx, model...)
}Здесь Database — это непосредственно структура, реализующая CarRepository, в методах которой содержатся SQL запросы к PostgreSQL, а также коннект (пул конектов) к базе данных. Она может реализовывать и больше репозиториев, если у вас их много.
В итоге реализация метода, читающего машины из БД, будет выглядеть так:
package postgres
import ...
func (db *Database) GetCarsByTimePeriod(ctx context.Context, from, to time.Time) ([]model.Car, error) {
var m []model.Car
err := db.model(ctx, &m).
Where("manufacture_date BETWEEN ? AND ?", from, to).
Order("model").
Select()
if err != nil {
return nil, err
}
return m, nil
}При этом метод можно использовать как в транзакции, так и без нее — ни сигнатура, ни сам метод от этого не меняется. Причем решение, использовать транзакцию, или нет, принимает именно часть сервиса с бизнес-логикой. Давайте же посмотрим, как это сделано.
Транзакции в бизнесе и бизнес в транзакциях
Дело осталось за малым — реализовать метод создания транзакции внутри адаптера, который будет возвращать "заряженный" транзакцией контекст, добавить этот метод в интерфейс, вызывать его в бизнес логике и передавать во все вызовы репозитория, а в конце делать коммит или роллбэк.
Звучит логично, но как-то некрасиво. Может быть, в Go есть более элегантный инструмент?
И он есть! Это — замыкание. Реализуем метод, который позволит нам реализовать всю транзакцию, не отходя от кассы:
package postgres
import ...
// WithinTransaction runs function within transaction
//
// The transaction commits when function were finished without error
func (db *Database) WithinTransaction(ctx context.Context, tFunc func(ctx context.Context) error) error {
// begin transaction
tx, err := db.conn.Begin()
if err != nil {
return fmt.Errorf("begin transaction: %w", err)
}
// finalize transaction on panic, etc.
defer tx.Close()
// run callback
err = tFunc(injectTx(ctx, tx))
if err != nil {
// if error, rollback
tx.Rollback()
return err
}
// if no error, commit
tx.Commit()
return nil
}Для читабельности убрал обработку ошибок при коммите и роллбеке
Метод принимает контекст и функцию, которую нужно выполнить в транзакции. На основе контекста создается контекст с транзакцией, и передается в функцию. Это позволяет также прервать выполнение функции при отмене родительского контекста — например, при graceful shutdown.
Далее если функция выполнена без ошибок, выполняется commit, в противном случае выполняется rollback, а ошибка возвращается из метода.
Этот метод выведем в отдельный порт — изоляцию нужно соблюдать!
package port
import ...
// Transactor runs logic inside a single database transaction
type Transactor interface {
// WithinTransaction runs a function within a database transaction.
//
// Transaction is propagated in the context,
// so it is important to propagate it to underlying repositories.
// Function commits if error is nil, and rollbacks if not.
// It returns the same error.
WithinTransaction(context.Context, func(ctx context.Context) error) error
}Добавим его через DI в домен:
package domain
import ...
type Car struct {
carRepo port.CarRepository
transactor port.Transactor
}
func NewCar(transactor port.Transactor, carRepo port.CarRepository) &Car {
return &Car{
carRepo: carRepo,
transactor: transactor,
}
}Это позволяет нам совсем не заморачиваться по поводу транзакций внутри бизнес логики, и упростить транзакционные операции до следующего:
package domain
import ...
func (c *Car) BuyCar(ctx context.Context, id string, price int, owner model.Owner) error {
if err := c.validateBuyer(ctx, price, owner); err != nil {
return err
}
return c.transactor.WithinTransaction(ctx, func(txCtx context.Context) error {
car, err := c.carRepo.GetCar(txCtx, id)
if err != nil {
return err
}
if err := c.validatePurchase(txCtx, car, owner); err != nil {
return err
}
car.Owner = owner
car.SellPrice = price
car.SellDate = time.Now()
if err := c.carRepo.UpsertCar(txCtx, car); err != nil {
return err
}
log.Printf("car %s model % sold to %s for %d",
car.Id, car.Model, owner.Name, price)
return nil
})
}В примере я несколько упростил код для лучшего понимания. На практике в гексагоне управление транзакцией должно происходить не в слое домена (domain service), а в слое приложения (application service), что я и делаю в реальной жизни.
При этом домен ничего не знает про транзакцию, да ему и не нужно. А слой приложения управляет как транзакциями, так и другими "бизнесовыми" сущностями, выходящими за рамки домена (как пример — идемпотентность команд в CQRS).
Утешительные итоги
В результате мы получили:
- простой с точки зрения слоя бизнес-логики механизм выполнения операций в транзакции;
- изоляция уровней, абстракции не протекают;
- отсутствие рефлексии, вся работа с транзакцией типизирована и отказоустойчива;
- чистые методы репозиториев, нет нужды пробрасывать транзакцию в сигнатуру;
- методы с запросами агностичны к наличию транзакции — если она есть, выполнятся в ней, если нет — напрямую в БД;
- commit и rollback выполняются автоматически по результату выполнения функции. Никаких defer.
- при панике выполнится rollback внутри
tx.Close().
Этот подход применим к любой базе данных, поддерживающий ACID транзакции, при условии общего интерфейса для запросов как в транзакции, так и без него. При желании можно дописать свою обертку, если в любимой библиотеке этого нет.
Этот подход не применим в ситуации, когда вы работаете с несколькими БД в одном сервисе, и вам нужно связать две транзакции в одну. В этом случае я вам не завидую.
Возможно, где-то я отошел от принципов DDD или пренебрег концепциями гексагональной архитектуры, однако результат вышел простым, красивым и читабельным.
А как бы сделали вы? Приглашаю в комментарии для обсуждения идей и критики!
Комментарии (29)

leporo
16.02.2022 12:20Не удобнее ли вместо контекста (где зачеркнуто)
func (db *Database) WithinTransaction(ctx context.Context, tFunc func(ctx context.Context) error) error
передавать копию Database с транзакцией в полеconn?
func (db *Database) WithinTransaction(ctx context.Context, tFunc func(db CarRepository) error) error
Метод model, функции injectTx, extractTx тогда, возможно, совсем не понадобятся.
Color Автор
16.02.2022 12:30Нет, неудобно по двум причинам:
контекст все равно нужен, он не только для транзакций используется, но еще много для чего - от прерывания задач по таймауту до телеметрии;
если передавать копию Database, то придется протащить этот тип в интерфейсы ядра гексагона, а это нарушает принцип "зависимости от центра к периферии" - получается, что у нас бизнес логика знает о реализации адаптера для работы с БД, а этого быть не должно.
Работа через контекст позволяет сохранить изоляцию слоев и не нарушать направление зависимостей в гексагоне.
leporo
16.02.2022 13:30Контекст и так доступен в замыкании. Передавать его параметром нужно, если контекст изменяется. В варианте "замыкание получает экземпляр CarRepository, работающий внутри транзакции" это не нужно.
Копия (новый экземпляр, не тип) Database реализует уже объявленный интерфейс CarRepository, именно его я предлагаю передавать в замыкание.
Возможно, для conn придется использовать интерфейс, подобный приведенному ниже в комментариях QueryExecutor.Color Автор
16.02.2022 13:38В этом случае, как писал выше, нужно будет протащить интерфейс со всеми методами (Database, QueryExecutor или еще что) в ядро гексагона, где он никак не нужен, да и реализует специфичную для адаптера логику.
Поэтому это делается через контекст, который в этом случае меняется, поэтому передается в функцию.
leporo
16.02.2022 16:14+1В ветке ниже (где QueryExecutor)@andrdru, фактически, предложил тот же вариант - передавать в замыкание работающий внутри транзакции экземпляр CarReporisotory.
У вас там хороший, развернутый комментарий. По нему у меня ощущение, что мы упираемся в какие-то идеологические, а не практические соображения.
Ведь подходы с контекстом иtxRepo, в принципе, схожи. Внутри замыкания можно использоватьctxиtxCtx, а можно -repoиtxRepo. Транзакция в обоих случаях создаётся на уровне репо. И если управление транзакцией (интерфейс Transactor, реализуемый репо) пробрасывается выше - его ведь можно и, может, даже желательно прикрыть интерфейсом домена?
Так что, в принципе, всё сводится к тому как именно Transactor доступен выше уровня домена, и различию между
c.carRepo.GetCar(txCtx, id)
и
txRepo.GetCar(ctx, id)
Мне второй вариант кажется чуть более устойчивым (он даёт компилятору больше информации), но различие это не принципиально.Color Автор
16.02.2022 17:04Есть разница.
Первое - действительно есть некие идеологические соображения. А именно то, что для слоя бизнес-логики транзакция выглядит как-то так:
type Transaction interface { Commit() Rollback() }А вот всякие
QueryContextне имеют для бизнес логики никакого значения, потому что вызываться будет только в адаптере (репо и т.п.). Получается, что имплементация адаптера протекает в бизнес логику, то есть в противоположную сторону от направления зависимостей в гексагоне.И не важно, что это интерфейс а не тип. Эти методы исключительно для работы с БД, о чем уровень логики не знает.
Второе - в решении, которое я сделал, транзакция и запросы к репо разделены, и могут быть реализованы на разных уровнях. В гексагоне я выполняю транзакцию на слое приложения, а сами методы репо вызываю внутри слоя доменов. При этом я волен как одним репо пользоваться и в транзакции и вне ее явно, так и в одной транзакции пользоваться несколькими репо без лишних манипуляций.
Это не говорит о том, что инвертированный подход (не репо внутри транзакции, а транзакция внутри репо) хуже, но для меня он выглядит более ограничительным по функционалу.
leporo
16.02.2022 18:13Ой. Нет репо внутри транзакции или транзакции внутри репо. Есть атомарная операция. В статье она реализуется через транзакцию БД, но ведь транзакция БД и атомарная бизнес-операция - не одно и то же.
Меня несколько смутило использование контекста бизнес-операции для обмена данными между интерфейсами репо (я говорю о реализации в статье, где Database реализует и CarRepository и Transactor). Отсюда - предложение из моего первого комментария.Color Автор
16.02.2022 19:07но ведь транзакция БД и атомарная бизнес-операция - не одно и то же.
Не могу с этим спорить, но статья именно про транзакции БД, и я отвечал в этом контексте.

andrdru
16.02.2022 13:14+1Я выделил интерфейс
QueryExecutor interface { ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) QueryRowContext(ctx context.Context, query string, args ...interface{}) *sql.Row QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error) }Его имплементят sql.Tx и sql.DB, от него зависят репозитории, передается в конструктор
type CarRepository interface{ DB() QueryExecutor } type repo struct{ db QueryExecutor } func NewRepo(db QueryExecutor) CarRepository { return &repo{db: db} }Так в транзакции можно вызывать NewRepo(tx) где tx типа sql.Tx
Сделал вот такой хелпер https://github.com/andrdru/sqltx
Также использовал замыкание. В интерфейс репозитория добавляю методTX(action func(txRepo CarRepository) error) errorкоторый уже будет вызван в логике
Из недостатков - из репозитория торчит метод DB() QueryExecutor, который позволяет получить в замыкании sql.Tx.Color Автор
16.02.2022 13:48Да, тоже интересный подход. Но тут получается, что на уровне приложения нужно во-первых явно получить объект бд или транзакции (пусть и скрытый за интерфейсом QueryExecutor), а потом сконструировать на его основе инстанс CarRepository, который либо работает в транзакции, либо без нее.
Подход жизнеспособный, но кмк немного ограничивающий.
В моем случае логика управления транзакцией отделена от репозиториев, и я могу (при необходимости) делать часть запросов вне транзакции, а часть - в транзакции, используя один и тот же репозиторий.
Плюс чисто технически я делаю инициализацию зависимостей и пробрасывание их через DI в момент старта приложения, поэтому при обработке запроса у меня уже есть все необходимые репо. Такой код получается немного чище, т.к. инициализация репо вынесена далеко от бизнес-логики, а в самой бизнес логике происходят вызовы методов репо, управление транзакцией ну и сама логика.
Если быть точнее, слой приложения гексагона управляет транзакцией, а внутри он вызывает методы доменного слоя. А уже домен внутри дергает репозитории (спрятанные за интерфейсами-портами), при этом не зная ничего про транзакцию.
andrdru
16.02.2022 14:10Согласен, напрямую использовать не будет удобно. Для того хелпер: объект бд/транзакции скрыт за TX(), аналогично WithinTransaction(). Иницилизировать репозиторий придется только в случае, когда метод нужен внутри транзакции. В этом смысле реализация с контекстом возможно удобнее
carRepo.Tx(func(txRepo CarRepository)error{ err = txRepo.Method1() if err != nil { return err } customerTxRepo = NewCustomer(txRepo.DB()) return customerTxRepo.Method2() })


Ilusharulkov
17.02.2022 09:21+1Спасибо за статью. Применение паттернов и правил различных архитектур подразумевает улучшение читаемости, модульности и тестируемости кода.
Про последнее и будет вопрос. Как будут выглядеть юнит тесты? Смущает что большая часть реализации сценария лежит внутри замыкания
andrdru
18.02.2022 07:04Отвечу за автора. Замыкание вызывается для зависимости. Если тест unit, то зависимости будут замоканы. Инструменты вроде gomock позволяют мокать замыкания
Color Автор
18.02.2022 11:39Мы просто мокаем все интерфейсы. Так как
Transactor- интерфейс, мокаем и его.Ниже подробнее расписал тулинг.
Color Автор
18.02.2022 11:38Это отличный вопрос, спасибо.
Мы делаем так: генерируем через mockery моки для всех интерфейсов (портов), а в тестах заряжаем моки данными. Непосредственно мок транзактора выглядит в тесте вот так:
transactor := new(mocks.Transactor) transactor.On("WithinTransaction", any, any). Return( func(ctx context.Context, f func(context.Context) error) error { return f(ctx) }, )В целом получается тестировать так:
порты есть двух видов - входящие и исходящие. Входящие это хендлеры http, grpc серверов, консумер очереди и т.п. Исходящие - работа с БД, продьюсер очереди, клиенты http и grpc.
Исходящие порты мокаются, mockery позволяет нам не тратить на моки время.
Моки подсовываются через DI в ядро гексагона.
Методы входящих портов тестируются в тестах, в итоге ядро гексагона полностью изолировано.
Подробнее можно посмотреть тут.
RPG18
Теперь осталось красиво завернуть блокировки на уровне строк SELECT FOR UPDATE с обработкой сбоя сериализации.
Color Автор
С этим особых проблем нет, просто делаю в репо метод вида
GetCarWithLock(ctx context.Context, id string) (*model.Car, error), внутри которого SELECT FOR UPDATE.Сбоев сериализации пока не было, но при необходимости можно добавить в WithinTransaction функциональных опций с передачей уровня изоляции, например.
RPG18
Тут как раз имеет смысл через замыкания иначе как будешь делать ретрай?
Color Автор
Никак не буду делать ретрай, при локе первая транзакция проставит лок, а вторая будет ждать синхронно, пока лок будет отпущен.
Синхронных операций по 20 минут в одной транзакции принципиально нет, все отрабатывает за 20мс в худшем случае, поэтому необходимости в каких-то ретраях нету.
RPG18
Да же если возмем уровень Serializable:
Color Автор
Насколько помню, локи отрабатывают для всех уровней изоляции одинаково хорошо (если речь не про фантомы, конечно, но зачем нам локи на фантомы?).
Касательно того, что называют здесь "сбоями сериализации" - видимо имеется в виду Lost updates и Non-repeatable reads (ну и фантомы), но этого можно избежать, просто грамотно продумывая запросы, а не бездумно полагаясь на повышение уровня сериализации.
Пока у меня не было проблем с этим, т.к. пишу неконфликтные запросы, а где конфликты или конкуренция может быть, решаю локами или другими механизмами неконкурентной обработки. Поэтому дефолтного в Postgres Read Committed мне вполне хватает без мыслей о ретраях.
Впрочем, конкретный сервис построен так, что ретраи операции возможны при ошибках, но не на уровне транзакции, а на уровне обработки запроса - запрос или прийдет еще раз от балансировщика (реверс прокси), либо перечитается еще раз из очереди. В случае retryable ошибки, конечно.
mayorovp
Нет. Сбой сериализации тут — это ситуация, когда две транзакции заблокировали друг друга, из-за чего одна из них оказалась отменена.
Color Автор
Спасибо за пояснение.
У меня получается избегать этого через
написание неконфликтных запросов
пессимистичные блокировки там, где могут быть конфликты
RPG18
Там будет 40001 serialization_failure. Если используется pgx, то будет проверка
Из-за MVCC с Read Committed ты будешь читать значение из снепшота, на момент начала транзакции. Соответсвенно ты октрываешь новую транзакцию, что бы прочитать уже новые изменения.
Color Автор
Спасибо. В целом слежу за тем, чтобы таких запросов не было, а где нельзя - пользуюсь блокировками БД. Таких ошибок не было, да и отлавливаются они быстро.
Но если рассматривать подход как фреймворк, который отдается в руки программистам, плохо владеющим SQL, ретраи могут пригодиться.
Зависит от контекста задачи - можно и прямо всю функцию-замыкание ретраить, а можно ретраить на уровне отправки запроса/чтения сообщения (мы пошли по второму пути).