Пора снять завесу, отворить дверцу и воочию взглянуть на таинственный алгоритм будоражащий умы и сердца, добро пожаловать на сеанс с разоблачением!
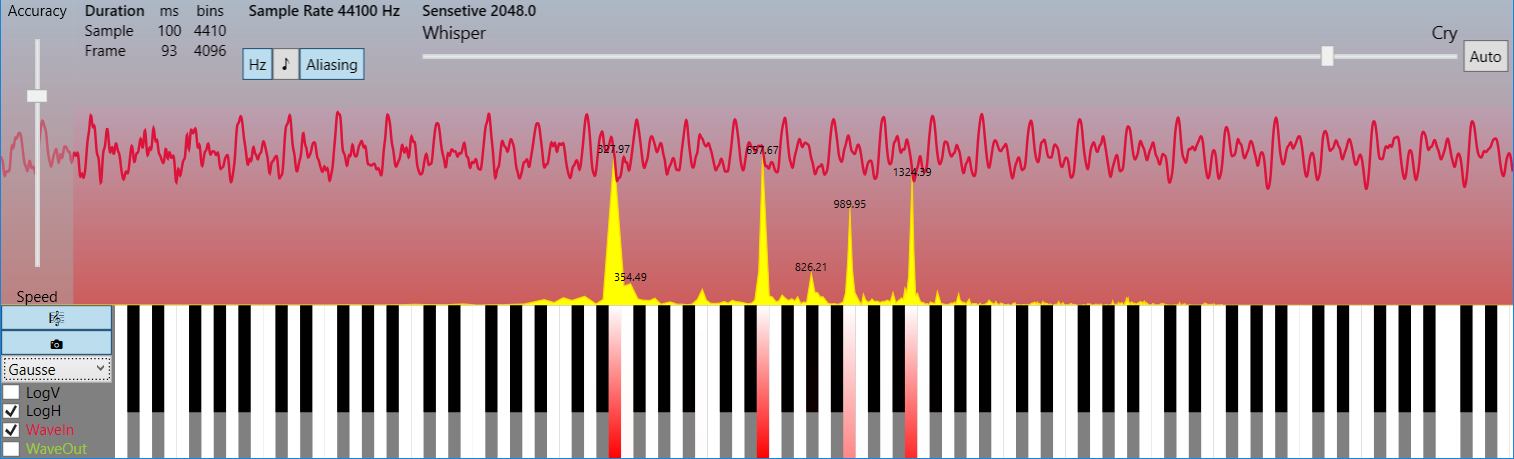
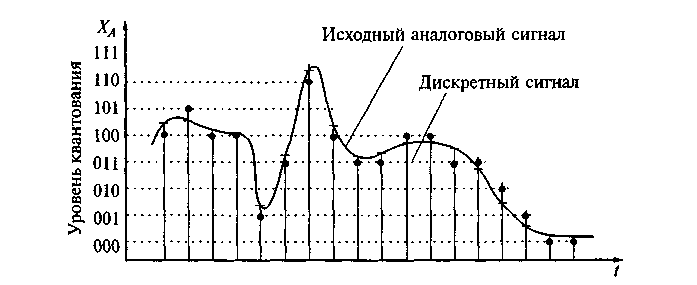
Несжатый аудиопоток — это массив целых чисел (C# short), к примеру, поступающий из буфера микрофона. Он представляет собой дискретный набор значений-амплитуд аналогового сигнала, взятых через равные промежутки времени (то есть с определённой частотой дискретизации и квантованием по уровню).
* для простоты здесь и далее будем рассматривать классический моносигнал
Если сразу записывать этот массив в файл, то даже короткий временной интервал получится весьма объёмным. Понятно, что, по всей видимости, в таком потоковом сигнале содержится много избыточных данных, поэтому резонно возникает вопрос, как отобрать нужное и удалить излишнее? Ответ на него прост и суров — использовать преобразование Фурье.
Да, именно то самое, о котором регулярно толкуют в технических университетах и которое, мы успешно успеваем позабыть. Однако это не беда — изучаем вводную презентацию и читаем статью, где вопрос рассматривается более чем подробно. Нам же потребуется лишь сам алгоритм размером всего в 32 строки кода на языке C#.
public static Complex[] DecimationInTime(this Complex[] frame, bool direct)
{
if (frame.Length == 1) return frame;
var frameHalfSize = frame.Length >> 1; // frame.Length/2
var frameFullSize = frame.Length;
var frameOdd = new Complex[frameHalfSize];
var frameEven = new Complex[frameHalfSize];
for (var i = 0; i < frameHalfSize; i++)
{
var j = i << 1; // i = 2*j;
frameOdd[i] = frame[j + 1];
frameEven[i] = frame[j];
}
var spectrumOdd = DecimationInTime(frameOdd, direct);
var spectrumEven = DecimationInTime(frameEven, direct);
var arg = direct ? -DoublePi / frameFullSize : DoublePi / frameFullSize;
var omegaPowBase = new Complex(Math.Cos(arg), Math.Sin(arg));
var omega = Complex.One;
var spectrum = new Complex[frameFullSize];
for (var j = 0; j < frameHalfSize; j++)
{
spectrum[j] = spectrumEven[j] + omega * spectrumOdd[j];
spectrum[j + frameHalfSize] = spectrumEven[j] - omega * spectrumOdd[j];
omega *= omegaPowBase;
}
return spectrum;
}
Преобразование применяется к небольшим порциям сигнала — кадрам с числом отсчётов кратным степени двойки, что обычно составляет 1024, 2048, 4096. При стандартной частоте дискретизации в 44100 Гц, которая согласно теореме Котельникова — Найквиста — Шеннона позволяет без искажений восстанавливать оригинальный сигнал с максимальной частотой в спектре до 22050 Гц, что соответствует максимальному частотному порогу слышимости человеческого уха, эти отрывки по длительности эквивалентны примерно 23, 46 и 93 мс соответственно. После чего мы получаем массив комплексных чисел (той же длины, что и кадр), который содержит информацию о фазовом и частотном спектрах данного фрагмента сигнала. Полученный массив состоит из двух зеркальных частей-копий, поэтому реальной информативностью обладает лишь половина его элементов.
На этом этапе как раз мы можем убрать информацию о тихих частотах, сохранив лишь громкие, например, в виде словаря, а во время воспроизведения восстановить утраченные элементы, заменив их на нулевые, после чего выполнить обратное преобразование Фурье и получить пригодный для воспроизведения сигнал. Именно на этом принципе зиждется работа огромного числа аудиокодеков, поскольку описанная операция даёт возможность производить компрессию в десятки и даже сотни раз (!). Безусловно, способ записи информации в файл тоже вносит свои коррективы в результирующий размер и далеко не лишним будет дополнительное использование алгоритмов архивирования без потерь, но наиболее весомый вклад обеспечивает именно заглушение неслышимых частот.
Поначалу не верится, что таким тривиальным образом можно достичь столь значимых степеней сжатия, но если взглянуть на спектральную картинку в линейном частотном масштабе, а не логарифмическом, то сразу станет ясно, что в реальном спектре обычно присутствует лишь узкий набор гармоник, несущих полезную информацию, а всё остальное — лёгкий шум, который лежит за пределами слышимости. И, как это ни парадоксально, при малых степенях сжатия сигнал не портится для восприятия, а наоборот лишь очищается от шума, то есть идеализируется!

* на картинках отображён кадр в 4096 отсчёта (93 мс) и спектр частот до 22050 Гц (см. LimitFrequency в исходных кодах). Это пример демонстрирует, насколько мало несущих гармоник в реальных сигналах
Чтобы не быть голословным предлагаю протестировать демо приложение (Rainbow Framework), где алгоритм сжатия тривиально прост, но вполне работоспособен. Заодно можно оценить искажения, которые возникают в зависимости от степени сжатия, а также изучить способы визуализации звука и многое другое…
var fftComplexFrequencyFrame = inputComplexTimeFrame.DecimationInTime(true);
var y = 0;
var original = fftComplexFrequencyFrame.ToDictionary(c => y++, c => c);
var compressed = original.OrderByDescending(p => p.Value.Magnitude).Take(CompressedFrameSize).ToList();
Да, конечно, существуют головоломные алгоритмы учитывающие психо-акустическую модель восприятия, вероятность появления тех или иных частот в спектре и прочее и прочее, но все они помогают лишь отчасти улучшить показатели при сохранении достойного качества, в то время как львиная доля компрессии достигается таким нехитрым способом, который на языке C# занимает буквально лишь несколько строк.
Итак, общая схема компрессии следующая:
1. Разбиение сигнала на амплитудно-временные кадры*
2. Прямое преобразование Фурье — получение амплитудно-частотных кадров
3. Полное заглушение тихих частот и дополнительная опциональная обработка
4. Запись данных в файл
* часто кадры частично перекрывают друг друга, что помогает избежать щелчков, когда сигнал определённой гармоники начинается или оканчивается в одном кадре, но всё ещё слаб и будет заглушен в нём, хотя в другом кадре его звучание набирает полную силу и не заглушается. Из-за чего в зависимости от фазы синусоиды возможен резкий скачок амплитуды на границах неперекрытых кадров, воспринимаемый как пощёлкивание.
Обратный процесс включает такие этапы:
1. Чтение файла
2. Восстановление амплитудно-частотных кадров
3. Обратное преобразование Фурье — получение амплитудно-временных кадров
4. Формирование сигнала из амплитудно-временных кадров
Вот и всё. Наверное, вы ожидали чего-то гораздо более сложного?
Ссылки:
1. Вводная презентация
2. Статья по преобразованию Фурье
3. Демо-приложение с исходными кодами (Rainbow Framework)
(резервная ссылка)
Комментарии (27)

pehat
16.10.2015 19:47-2Кодек – это прежде всего, совместимое API, доступное плееру или программе для редактирования аудио. Наклепанный на коленке фильтр без внешних ручек кодеком как таковым не является. Если Ваш кодек допилить до состояния, когда его опознает за своего Winamp/AIMP/VLC/название_вашего_любимого_плеера, это уже будет куда интереснее.

Makeman
17.10.2015 02:58+1Совершенно согласен с вашим замечанием, но цель статьи — без лишних усложнений рассказать о фундаментальных принципах компрессии аудиосигналов, а также продемонстрировать их работоспособность. Углубляться же в эту тему можно очень и очень долго…

mkarev
16.10.2015 20:46+1львиная доля компрессии достигается таким нехитрым способом, который на языке C# занимает буквально лишь несколько строк
На ультра низких битрейтах используются более изощренные инструменты кодирования, например: Parametric Stereo (AAC-HEv2) и Spectral Band Replication (AAC-HE), первый позволяет кодировать моно сигнал, а при декодировании опционально восстанавливать стерео, второй — кодировать только половину спектра, а при декодировании опционально восстанавливать верхние частоты расчетным путем, в обоих случаях в поток кладется некоторая дополнительная информация.
ЕМНИП в аудиокодеках используется косинусное преобразование (модифицированное DCT-IV), у которого в спектре есть только действительная часть(в 2 раза меньше данных, чем у классического фурье).
А какие есть методы объективной оценки искажения аудиосигналов?
PSNR как я понимаю не подойдет, т.к. упадет ниже плинтуса, даже если просто сдвинуть исхродный сигнал по фазе.
homesoft
16.10.2015 22:11Вобще-то количество данных у FFT (вещественного) и DCT одинаково. В случае с FFT число спектральных компонент N/2. Плюс еще столько же на фазу. Выход у DCT — N компонент, фаза неявно интегрирована.
mkarev
17.10.2015 08:52У MDCT 2N-точечного сигнала, в спектре N действительных компонент, а у Фурье N комплексных компонент. Или я что-то путаю?
Makeman
17.10.2015 17:41+1Не знаю точно насчёт косинусного преобразования, но при переводе N целочисленных отсчётов из временной области в частотную с помощью преобразования Фурье после «бабочки» мы получим массив комплексных чисел тоже из N элементов, причём он будет состоять из двух зеркальных половин, поэтому для дальнейшей обработки достаточно N/2 элементов.
Если на входе у нас были целочисленные значения short размером 2 байта, то на выходе мы имеем комплексные числа, которые состоят из двух вещественных компонент (реальной и мнимой части). Чтобы не возникало большой избыточности, лучше сохранять значения этих компонент в виде float (4 байта), а не double (8 байт).
см. размеры числовых типов
То есть на входе у нас было sizeof(short)*N=2N байт информации, а на выходе 2*sizeof(float)*(N/2)=4N, то есть мы не потеряли информации, а получили даже некоторую избыточность, но зато это даст нам возможность восстановить оригинальный сигнал без искажений обратным преобразованием.
Другими словами, должен соблюдаться закон сохранения неизбыточной информации (энтропии?), интуитивно, что-то вроде закона сохранения энергии. Если мы N неизбыточных бит преобразовываем в M бит, где N>M, то восстановить, без искажений эти изначальные N неизбыточных бит больше не получится.
Существут очень интересный принцип Ландауэра, который гласит, что в вычислительной системе при потере бита информации обязательно выделяется порция тепла (энергии), что в ближайшей перспективе накладывает серьёзные конструктивные ограничения по тепловыделению на нынешние распостранённые архитектуры микропроцессоров.
Сразу возникает вопрос, как же тогда работает архивирование без потерь, когда мы точно восстанавливаем файл по сжатой копии. А причина в том, во-первых, побайтовое кодирование (1 байт = 8 бит) зачастую является избыточным с информационной точки зрения. Просто работать с цифровой информацией побайтово, гораздо удобнее, чем побитово. Во-вторых, часто сама информация заключает в себе избыточность.
Но даже 1 бит, по-моему, не нужно воспринимать, как неделимый квант информации. Пускай, у нас есть файлы A и B равного размера (по 1Gb), которые нужно скопировать для возможности восстановления в случае повреждения. Классически можно создать Copy-A и Copy-B, затратив дополнительно 2Gb, но можно и создать файл C размером в 1Gb через операцию XOR. Парадокс заключается в том, что при утрате файла A мы с помощью B и С легко можем его восстановить, равно как и при утрате B с помощью A и C произведём восстановление. То есть файлы получаются информационно связаны (аля запутанны). Мы экономим 1Gb пространства на носителе за счёт некоторого снижения надёжности (если оба файла A и B будут одновременно повреждены, то мы не сможем их восстановить, опираясь только на C).
Возвращаясь к косинусному преобразованию, думаю, что должен соблюдаться этот закон сохранения неизбыточной информации :)
mkarev
17.10.2015 19:48MDCT: it has half as many outputs as inputs (instead of the same number)
…
The 2N real numbers X_0, ..., X_2N-1 are transformed into the N real numbers
То есть с точки зрения сжатия MDCT (не путать с DCT) как минимум в 2 раза выгоднее Фурье, т.к. не содерджит мнимой части.
interrupt
17.10.2015 22:11На самом деле, в той же статье написано:
The inverse MDCT is known as the IMDCT. Because there are different numbers of inputs and outputs, at first glance it might seem that the MDCT should not be invertible. However, perfect invertibility is achieved by adding the overlapped IMDCTs of subsequent overlapping blocks, causing the errors to cancel and the original data to be retrieved; this technique is known as time-domain aliasing cancellation (TDAC).
Т.e требуется перекрытие между фреймами. Без этого даже без квантования будут щелчки и слышимые искажения.mkarev
17.10.2015 22:21А при чем тут перекрытие?
Я про объем спектральных данных, которые потом будут квантоваться и кодироваться.
У MDCT их будет в 2 раза меньше, чем у Фурье.
Или Вы хотите сказать, что перекрытие на столько велико, что сводит на нет данное преимущество?interrupt
18.10.2015 01:59Преобразование в частотную область должно быть полностью обратимо (погрешности работы с вещественными числами оставим за кадром). А как без перекрытия из N спектральных коэффициентов восстановить все 2N исходных семпла?
Преимущества MDCT как раз в том, что перекрытие фреймов позволяет просто решить проблему блочных артефактов. И да, реализация mdct «в лоб» приведет к перекрытию в 50%.
Makeman
18.10.2015 13:34Модифицированное дискретное косинус-преобразование
Поскольку МДКП является преобразованием с перекрытием, оно немного отличается от других преобразований Фурье. В МДКП в два раза меньше выходов, чем входов (в отличие от других преобразований, где выходов ровно столько же, сколько входов).
Обратное МДКП известно как ОМДКП. Поскольку они отличаются количеством входов и выходов, то на первый взгляд может показаться, что МДКП нельзя преобразовать в обратное. Однако наилучшая обратимость преобразования достигается применением (i) ОМДКП к перекрывающимся блокам, и является причиной устранения ошибок перед извлечением исходных данных. Этот способ известен как принцип устранения временных помех (ПУВП).

pwl
16.10.2015 22:29>> А какие есть методы объективной оценки искажения аудиосигналов?
посмотрите PEAQ и PESQ. Не панацея, но оценку дают. На финальной стадии всегда делается прослушивание группой экспертов.
>> PSNR как я понимаю не подойдет, т.к. упадет ниже плинтуса, даже если просто сдвинуть исхродный сигнал по фазе.
А вот не надо его по фазе двигать :)
SNR и Segmental SNR также активно используютя.
pwl
16.10.2015 22:16+6Мне, как разработчику аудиокодеков было очень забавно почитать…
Что-ж, не всё из приведенного в статье неправда.
Общий принцип именно таков:
— сделать преобразование из временного предствление в частотное (time domain to frequency domain). обычно используя MDCT.
— решить какие части спектра для нас наиболее важны
— совсем неважные части выкинуть полностью
— не очень важные пожать с низким качеством (скажем 2-3 бита на сэмпл)
— важные пожать с качеством получше (скажем, 8 бит на сэмпл)
— сложить все в файл так чтоб не сильно торчала избыточность кода. ну типа хаффманом пожать.
Если выполнить все эти шаги то вы полчучите приблизительно mpeg layer 2 codec. Современные кодеки выдают схожее качество на битрэйтах в разы меньше. Можно ли разницу в несколько раз назвать «но все они помогают лишь отчасти улучшить показатели»? Не знаю, наверное можно. Ибо там чуть-чуть, да здесь маленько… так и прогрессируем.
ну и еще пара моментов. Фурье именно для кодирования практически не используется, т.к. не позволяет эффективно сделать перекрывающиеся фреймы (а не из-за того, что оно комплексное как сказал mkarev). Без этого на границе фреймов будут постоянные щелчки. Иногда оно используется как вспомогательное преобразования для анализа сигнала.
Есть кодеки, особенно для кодирования речи, где преобразование в частотную область не делается вообще.
Если интересны некоторые подробности «дополнительной опциональной обработки», советую почитать про vector quantizer — забавная штука которую можно использовать в любой области где требуется сжатие с потерями.interrupt
17.10.2015 01:12Поправьте если я не прав. Но ведь mpeg1 layer2 (как и musepack) является чистым subband кодеком и делает FFT только для психоакустики, и хаффмана, кажется, там нет.
mdct после разбиения на полосы и хаффман появились в mpeg1 layer3pwl
17.10.2015 01:45+1да, всё правильно, там QMF фильтрбанк и без хаффмана. Я уже и подзабыл слегка, оказывается, как оно в layer 2 было…
Makeman
17.10.2015 03:24Спасибо за уточнения!
Не являюсь специалистом в данной области, всего лишь стало интересно, за счёт чего же получается такое ощутимое сжатие при кодировании аудио. Решил проверить базовые принципы и поделиться результатами, не уходя в глубокие дебри. Ведь алгоритмы работы кодеков и проблемы, возникающие при их проектировании, часто кажутся чем-то невероятно сложным и далёким, но, думаю, такая статья внесёт немного ясности.

dom1n1k
21.10.2015 00:15Почему же во всём абсолютно софте для анализа звука/спектра используется именно FFT? Я нигде не видел MDCT даже опционально (хотя допускаю, что плохо смотрел). FFT вычислительно дешевле?
pwl
21.10.2015 02:42+2FFT используется для анализа и визуализации. Он хорош тем, что дает картинку очень похожую на то, как мы слышим.
Но если его использовать так, как описано у автора, то мы получим большие искажения на границах блоков при обратном преобразовании.
MDCT хорош тем, что он работает с перекрывающимися блоками, потому четких границ блока нет — нет и искажений на этих границах. Но в плане разделения на отдельные частотные компоненты он не очень хорош.
Если пропутить чистую синусоиду через FFT мы получим или точку, или очень острый пик (зависит от «окна» (analysis window), и того делится ли частота дискретизации на частоту синусоиды).
Та-же синусоида пропущенная через MDCT даст хороший бугор соответствующий этой частоте, но хвосты этого бугра будут гораздо более пологие. Поэтому визуализировать результаты MDCT смысла мало.
В итоге многие аудиокодеки (например большинство mp3 кодеров) делают оба преобразования. На основе результатов FFT анализируют параметры сигнала, и пользуясь этими параметрами кодируют то что выдал MDCT.
Проигрыватель-же уже делает только обратное MDCT.Makeman
21.10.2015 21:44Всё верно, при использовании FFT на обратном преобразовании возникают щелчки на границах кадров, что хорошо заметно в демо-приложении. По сути, MDCT является видоизменённым FFT, применяемым для устранения описанного дефекта.
Чтобы осознать принцип работы MDCT, в первую очередь необходимо понимать, как работает FFT, что тоже нетривиальная задача для человека малознакомого с обработкой сигналов, поэтому в статье используется упрощённая схема.
interrupt
17.10.2015 01:51+1Наверно, стоит упомянуть про общий tradeoff преобразований в частотную область. А именно временная точность против частотной.
Предположим вы взяли 4096 сэмплов, сдалали mdct, получили 4096 спектральных коэффициентов, отбросили часть их них. В результате, грубо говоря, на протяжении почти 100 ms вы внесли искажения в какой то частотной области. С другой стороны если взять 64 семпла, получить 64 коэффициента и отбросить один из них то искажения затронут уже достаточно широкий частотный участок, хотя и на совсем короткое время. Поэтому практически все кодеки, умеют переключать размер фрейма в зависимости от характера входного сигнала, но проблема в том что иногда нам нужно и то и другое одновременно.

stranger777
17.10.2015 20:18-1Как человек на слух отличающий mp3 от wav могу сказать, что это:
И, как это ни парадоксально, при малых степенях сжатия сигнал не портится для восприятия, а наоборот лишь очищается от шума, то есть идеализируется!
… мягко говоря не соответствует действительности. А за статью спасибо. Желающим ознакомиться поближе с сутью ->можно оставить ссылку на исходники lame.Makeman
17.10.2015 21:57Это, по логике вещей, соблюдается лишь при маленьких степенях сжатия, когда удаляются лишь частоты, которых совершенно нет в сигнале. Дальше уже начинается появление искажений. Тут многое зависит и от рода сигнала, понятно, если мы запишем «тишину», а потом отбросим все гармоники, то на выходи и получим тишину, а степень сжатия будет максимальной, и человеческим ухом тут мало что различишь :)
zim32
Т.е получается что весь этот сыр бор с кучей разных алгоритмов и патентов это все из-за борьбы за какие-то проценты сжатия?
dom1n1k
Ключевая разница сидит во фразе «убрать тихие малозначимые частоты, оставив громкие». Какие именно убирать, а какие оставлять? Где проходит граница? Это называется психоакустическая модель и её устройство и настройки могут быть существенно различными. И борьба идет не только за сжатие, но за максимальный баланс сжатия и качества.
Это примерно как с шахматами — организовать перебор ходов довольно тривиально, но нифига не тривиально настроить функцию оценки позиции.
Makeman
В некоторой степени получается так. Самый значимый вклад, не побоюсь предположить, не менее 50-70% сжатия происходит благодаря удалению очевидно тихих гармоник. Дальше уже борьба идёт за качество звучания и дополнительную компрессию, а также скорость кодирования/декодирования сигнала.
Makeman
Стоит учитывать тот факт, что разработка первых кодеков велась во времена, когда ещё не было гигабайтных винчестеров и скоростного интернета, поэтому война шла за каждый килобайт, из-за чего появлялось много форматов, патентов, алгоритмов. Поэтому над аудиокомпрессией навис ореол архисложности, который держится до сих пор, хотя основную суть способен понять человек даже мало-мальски знакомый с преобразованием Фурье.